mirror of
https://github.com/willmiao/ComfyUI-Lora-Manager.git
synced 2026-03-22 13:42:12 -03:00
Compare commits
282 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
18cdaabf5e | ||
|
|
787e37b7c6 | ||
|
|
4e5c8b2dd0 | ||
|
|
d8ddacde38 | ||
|
|
bb1e42f0d3 | ||
|
|
923669c495 | ||
|
|
7a4139544c | ||
|
|
4d6ea0236b | ||
|
|
e872a06f22 | ||
|
|
647bda2160 | ||
|
|
c1e93d23f3 | ||
|
|
c96550cc68 | ||
|
|
b1015ecdc5 | ||
|
|
f1b928a037 | ||
|
|
16c312c90b | ||
|
|
110ffd0118 | ||
|
|
35ad872419 | ||
|
|
9b943cf2b8 | ||
|
|
9d1b357e64 | ||
|
|
9fc2fb4d17 | ||
|
|
641fa8a3d9 | ||
|
|
add9269706 | ||
|
|
1a01c4a344 | ||
|
|
b4e7feed06 | ||
|
|
4b96c650eb | ||
|
|
107aef3785 | ||
|
|
b49807824f | ||
|
|
e5ef2ef8b5 | ||
|
|
88779ed56c | ||
|
|
8b59fb6adc | ||
|
|
7945647b0b | ||
|
|
2d39b84806 | ||
|
|
e151a19fcf | ||
|
|
99d2ba26b9 | ||
|
|
396924f4cc | ||
|
|
7545312229 | ||
|
|
26f9779fbf | ||
|
|
0bd62eef3a | ||
|
|
e06d15f508 | ||
|
|
aa1ee96bc9 | ||
|
|
355c73512d | ||
|
|
0daf9d92ff | ||
|
|
37de26ce25 | ||
|
|
0eaef7e7a0 | ||
|
|
8063cee3cd | ||
|
|
cbb25b4ac0 | ||
|
|
c62206a157 | ||
|
|
09832141d0 | ||
|
|
bf8e121a10 | ||
|
|
68568073ec | ||
|
|
ec36524c35 | ||
|
|
67acd9fd2c | ||
|
|
f7be5c8d25 | ||
|
|
ceacac75e0 | ||
|
|
bae66f94e8 | ||
|
|
ddf132bd78 | ||
|
|
afb012029f | ||
|
|
651e14c8c3 | ||
|
|
e7c626eb5f | ||
|
|
a0b0d40a19 | ||
|
|
42e3ab9e27 | ||
|
|
6e5f333364 | ||
|
|
f33a9abe60 | ||
|
|
7f1bbdd615 | ||
|
|
d3bf8eaceb | ||
|
|
b9c9d602de | ||
|
|
b25fbd6e24 | ||
|
|
6052608a4e | ||
|
|
a073b82751 | ||
|
|
8250acdfb5 | ||
|
|
8e1f73a34e | ||
|
|
50704bc882 | ||
|
|
35d34e3513 | ||
|
|
ea834f3de6 | ||
|
|
11aedde72f | ||
|
|
488654abc8 | ||
|
|
da1be0dc65 | ||
|
|
d0c728a339 | ||
|
|
66c66c4d9b | ||
|
|
4882721387 | ||
|
|
06a8850c0c | ||
|
|
370aa06c67 | ||
|
|
c9fa0564e7 | ||
|
|
2ba7a0ceba | ||
|
|
276aedfbb9 | ||
|
|
c193c75674 | ||
|
|
a562ba3746 | ||
|
|
2fedd572ff | ||
|
|
db0b49c427 | ||
|
|
03a6f8111c | ||
|
|
925ad7b3e0 | ||
|
|
bf793d5b8b | ||
|
|
64a906ca5e | ||
|
|
99b36442bb | ||
|
|
3c5164d510 | ||
|
|
ec4b5a4d45 | ||
|
|
78e1901779 | ||
|
|
cb539314de | ||
|
|
c7627fe0de | ||
|
|
84bfad7ce5 | ||
|
|
3e06938b05 | ||
|
|
4f712fec14 | ||
|
|
c5c9659c76 | ||
|
|
d6e175c1f1 | ||
|
|
88088e1071 | ||
|
|
958ddbca86 | ||
|
|
6670fd28f4 | ||
|
|
1e59c31de3 | ||
|
|
c966dbbbbc | ||
|
|
af8f5ba04e | ||
|
|
b741ed0b3b | ||
|
|
01ba3c14f8 | ||
|
|
d13b1a83ad | ||
|
|
303477db70 | ||
|
|
311e89e9e7 | ||
|
|
8546cfe714 | ||
|
|
e6f4d84b9a | ||
|
|
ce7e422169 | ||
|
|
e5aec80984 | ||
|
|
6d97817390 | ||
|
|
d516f22159 | ||
|
|
e918c18ca2 | ||
|
|
5dd8d905fa | ||
|
|
1121d1ee6c | ||
|
|
4793f096af | ||
|
|
7b5b4ce082 | ||
|
|
fa08c9c3e4 | ||
|
|
d0d5eb956a | ||
|
|
969f949330 | ||
|
|
9169bbd04d | ||
|
|
99463ad01c | ||
|
|
f1d6b0feda | ||
|
|
e33da50278 | ||
|
|
4034eb3221 | ||
|
|
75a95f0109 | ||
|
|
92fdc16fe6 | ||
|
|
23fa2995c8 | ||
|
|
59aefdff77 | ||
|
|
e92ab9e3cc | ||
|
|
e3bf1f763c | ||
|
|
1c6e9d0b69 | ||
|
|
bfd4eb3e11 | ||
|
|
c9f902a8af | ||
|
|
0b67510ec9 | ||
|
|
b5cd320e8b | ||
|
|
deb25b4987 | ||
|
|
4612da264a | ||
|
|
59b67e1e10 | ||
|
|
5fad936b27 | ||
|
|
e376a45dea | ||
|
|
fd593bb61d | ||
|
|
71b97d5974 | ||
|
|
2b405ae164 | ||
|
|
2fe4736b69 | ||
|
|
184f8ca6cf | ||
|
|
1ff2019dde | ||
|
|
a3d8261686 | ||
|
|
7d0600976e | ||
|
|
e1e6e4f3dc | ||
|
|
fba2853773 | ||
|
|
48df7e1078 | ||
|
|
235dcd5fa6 | ||
|
|
2027db7411 | ||
|
|
611dd33c75 | ||
|
|
ec1c92a714 | ||
|
|
6ac78156ac | ||
|
|
e94b74e92d | ||
|
|
2bbec47f63 | ||
|
|
b5ddf4c953 | ||
|
|
44be75aeef | ||
|
|
2c03759b5d | ||
|
|
2e3da03723 | ||
|
|
6e96fbcda7 | ||
|
|
d1fd5b7f27 | ||
|
|
9dbcc105e7 | ||
|
|
5cd5a82ddc | ||
|
|
88c1892dc9 | ||
|
|
3c1b181675 | ||
|
|
6777dc16ca | ||
|
|
3833647dfe | ||
|
|
b6c47f0cce | ||
|
|
d308c7ac60 | ||
|
|
947c757aa5 | ||
|
|
5ee5bd7d36 | ||
|
|
d9c4ae92cd | ||
|
|
e1efff19f0 | ||
|
|
61f723a1f5 | ||
|
|
b32756932b | ||
|
|
cb5e64d26b | ||
|
|
f36febf10a | ||
|
|
26d9a9caa6 | ||
|
|
cb876cf77e | ||
|
|
4789711910 | ||
|
|
4064980505 | ||
|
|
f9b8f2d22c | ||
|
|
6a95aadc53 | ||
|
|
f9f08f082d | ||
|
|
0817901bef | ||
|
|
ac22172e53 | ||
|
|
fd87fbf31e | ||
|
|
554be0908f | ||
|
|
eaec4e5f13 | ||
|
|
0e7ba27a7d | ||
|
|
c551f5c23b | ||
|
|
5159657ae5 | ||
|
|
d35db7df72 | ||
|
|
2b5399c559 | ||
|
|
9e61bbbd8e | ||
|
|
7ce5857cd5 | ||
|
|
38fbae99fd | ||
|
|
b0a9d44b0c | ||
|
|
b4e22cd375 | ||
|
|
9bc92736a7 | ||
|
|
111b34d05c | ||
|
|
07d9599a2f | ||
|
|
d8194f211d | ||
|
|
51a6374c33 | ||
|
|
aa6c6035b6 | ||
|
|
44b4a7ffbb | ||
|
|
e5bb018d22 | ||
|
|
79b8a6536e | ||
|
|
3de31cd06a | ||
|
|
c579b54d40 | ||
|
|
0a52575e8b | ||
|
|
23c9a98f66 | ||
|
|
796fc33b5b | ||
|
|
dc4c11ddd2 | ||
|
|
d389e4d5d4 | ||
|
|
8cb78ad931 | ||
|
|
85f987d15c | ||
|
|
b12079e0f6 | ||
|
|
dcf5c6167a | ||
|
|
b395d3f487 | ||
|
|
37662cad10 | ||
|
|
aa1673063d | ||
|
|
f51f49eb60 | ||
|
|
54c9bac961 | ||
|
|
e70fd73bdd | ||
|
|
9bb9e7b64d | ||
|
|
f64c03543a | ||
|
|
51374de1a1 | ||
|
|
afcc12f263 | ||
|
|
88c5482366 | ||
|
|
bbf7295c32 | ||
|
|
ca5e23e68c | ||
|
|
eadb1487ae | ||
|
|
1faa70fc77 | ||
|
|
30d7c007de | ||
|
|
f54f6a4402 | ||
|
|
7b41cdec65 | ||
|
|
fb6a652a57 | ||
|
|
ea34d753c1 | ||
|
|
2bc46e708e | ||
|
|
96e3b5b7b3 | ||
|
|
fafbafa5e1 | ||
|
|
be8605d8c6 | ||
|
|
061660d47a | ||
|
|
2ed6dbb344 | ||
|
|
4766b45746 | ||
|
|
0734252e98 | ||
|
|
91b4827c1d | ||
|
|
df6d56ce66 | ||
|
|
f0203c96ab | ||
|
|
bccabe40c0 | ||
|
|
c2f599b4ff | ||
|
|
5fd069d70d | ||
|
|
32d34d1748 | ||
|
|
18eb605605 | ||
|
|
4fdc88e9e1 | ||
|
|
4c69d8d3a8 | ||
|
|
d4b2dd0ec1 | ||
|
|
181f78421b | ||
|
|
8ed38527d0 | ||
|
|
c4c926070d | ||
|
|
ed87411e0d | ||
|
|
4ec2a448ab | ||
|
|
73d01da94e | ||
|
|
df8e02157a | ||
|
|
6e513ed32a | ||
|
|
325ef6327d | ||
|
|
46700e5ad0 | ||
|
|
d1e21fa345 |
4
.github/FUNDING.yml
vendored
Normal file
4
.github/FUNDING.yml
vendored
Normal file
@@ -0,0 +1,4 @@
|
||||
# These are supported funding model platforms
|
||||
|
||||
ko_fi: pixelpawsai
|
||||
custom: ['paypal.me/pixelpawsai']
|
||||
1
.gitignore
vendored
1
.gitignore
vendored
@@ -3,3 +3,4 @@ settings.json
|
||||
output/*
|
||||
py/run_test.py
|
||||
.vscode/
|
||||
cache/
|
||||
|
||||
687
LICENSE
687
LICENSE
@@ -1,21 +1,674 @@
|
||||
MIT License
|
||||
GNU GENERAL PUBLIC LICENSE
|
||||
Version 3, 29 June 2007
|
||||
|
||||
Copyright (c) 2023 Will Miao
|
||||
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
|
||||
Everyone is permitted to copy and distribute verbatim copies
|
||||
of this license document, but changing it is not allowed.
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
Preamble
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
The GNU General Public License is a free, copyleft license for
|
||||
software and other kinds of works.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
The licenses for most software and other practical works are designed
|
||||
to take away your freedom to share and change the works. By contrast,
|
||||
the GNU General Public License is intended to guarantee your freedom to
|
||||
share and change all versions of a program--to make sure it remains free
|
||||
software for all its users. We, the Free Software Foundation, use the
|
||||
GNU General Public License for most of our software; it applies also to
|
||||
any other work released this way by its authors. You can apply it to
|
||||
your programs, too.
|
||||
|
||||
When we speak of free software, we are referring to freedom, not
|
||||
price. Our General Public Licenses are designed to make sure that you
|
||||
have the freedom to distribute copies of free software (and charge for
|
||||
them if you wish), that you receive source code or can get it if you
|
||||
want it, that you can change the software or use pieces of it in new
|
||||
free programs, and that you know you can do these things.
|
||||
|
||||
To protect your rights, we need to prevent others from denying you
|
||||
these rights or asking you to surrender the rights. Therefore, you have
|
||||
certain responsibilities if you distribute copies of the software, or if
|
||||
you modify it: responsibilities to respect the freedom of others.
|
||||
|
||||
For example, if you distribute copies of such a program, whether
|
||||
gratis or for a fee, you must pass on to the recipients the same
|
||||
freedoms that you received. You must make sure that they, too, receive
|
||||
or can get the source code. And you must show them these terms so they
|
||||
know their rights.
|
||||
|
||||
Developers that use the GNU GPL protect your rights with two steps:
|
||||
(1) assert copyright on the software, and (2) offer you this License
|
||||
giving you legal permission to copy, distribute and/or modify it.
|
||||
|
||||
For the developers' and authors' protection, the GPL clearly explains
|
||||
that there is no warranty for this free software. For both users' and
|
||||
authors' sake, the GPL requires that modified versions be marked as
|
||||
changed, so that their problems will not be attributed erroneously to
|
||||
authors of previous versions.
|
||||
|
||||
Some devices are designed to deny users access to install or run
|
||||
modified versions of the software inside them, although the manufacturer
|
||||
can do so. This is fundamentally incompatible with the aim of
|
||||
protecting users' freedom to change the software. The systematic
|
||||
pattern of such abuse occurs in the area of products for individuals to
|
||||
use, which is precisely where it is most unacceptable. Therefore, we
|
||||
have designed this version of the GPL to prohibit the practice for those
|
||||
products. If such problems arise substantially in other domains, we
|
||||
stand ready to extend this provision to those domains in future versions
|
||||
of the GPL, as needed to protect the freedom of users.
|
||||
|
||||
Finally, every program is threatened constantly by software patents.
|
||||
States should not allow patents to restrict development and use of
|
||||
software on general-purpose computers, but in those that do, we wish to
|
||||
avoid the special danger that patents applied to a free program could
|
||||
make it effectively proprietary. To prevent this, the GPL assures that
|
||||
patents cannot be used to render the program non-free.
|
||||
|
||||
The precise terms and conditions for copying, distribution and
|
||||
modification follow.
|
||||
|
||||
TERMS AND CONDITIONS
|
||||
|
||||
0. Definitions.
|
||||
|
||||
"This License" refers to version 3 of the GNU General Public License.
|
||||
|
||||
"Copyright" also means copyright-like laws that apply to other kinds of
|
||||
works, such as semiconductor masks.
|
||||
|
||||
"The Program" refers to any copyrightable work licensed under this
|
||||
License. Each licensee is addressed as "you". "Licensees" and
|
||||
"recipients" may be individuals or organizations.
|
||||
|
||||
To "modify" a work means to copy from or adapt all or part of the work
|
||||
in a fashion requiring copyright permission, other than the making of an
|
||||
exact copy. The resulting work is called a "modified version" of the
|
||||
earlier work or a work "based on" the earlier work.
|
||||
|
||||
A "covered work" means either the unmodified Program or a work based
|
||||
on the Program.
|
||||
|
||||
To "propagate" a work means to do anything with it that, without
|
||||
permission, would make you directly or secondarily liable for
|
||||
infringement under applicable copyright law, except executing it on a
|
||||
computer or modifying a private copy. Propagation includes copying,
|
||||
distribution (with or without modification), making available to the
|
||||
public, and in some countries other activities as well.
|
||||
|
||||
To "convey" a work means any kind of propagation that enables other
|
||||
parties to make or receive copies. Mere interaction with a user through
|
||||
a computer network, with no transfer of a copy, is not conveying.
|
||||
|
||||
An interactive user interface displays "Appropriate Legal Notices"
|
||||
to the extent that it includes a convenient and prominently visible
|
||||
feature that (1) displays an appropriate copyright notice, and (2)
|
||||
tells the user that there is no warranty for the work (except to the
|
||||
extent that warranties are provided), that licensees may convey the
|
||||
work under this License, and how to view a copy of this License. If
|
||||
the interface presents a list of user commands or options, such as a
|
||||
menu, a prominent item in the list meets this criterion.
|
||||
|
||||
1. Source Code.
|
||||
|
||||
The "source code" for a work means the preferred form of the work
|
||||
for making modifications to it. "Object code" means any non-source
|
||||
form of a work.
|
||||
|
||||
A "Standard Interface" means an interface that either is an official
|
||||
standard defined by a recognized standards body, or, in the case of
|
||||
interfaces specified for a particular programming language, one that
|
||||
is widely used among developers working in that language.
|
||||
|
||||
The "System Libraries" of an executable work include anything, other
|
||||
than the work as a whole, that (a) is included in the normal form of
|
||||
packaging a Major Component, but which is not part of that Major
|
||||
Component, and (b) serves only to enable use of the work with that
|
||||
Major Component, or to implement a Standard Interface for which an
|
||||
implementation is available to the public in source code form. A
|
||||
"Major Component", in this context, means a major essential component
|
||||
(kernel, window system, and so on) of the specific operating system
|
||||
(if any) on which the executable work runs, or a compiler used to
|
||||
produce the work, or an object code interpreter used to run it.
|
||||
|
||||
The "Corresponding Source" for a work in object code form means all
|
||||
the source code needed to generate, install, and (for an executable
|
||||
work) run the object code and to modify the work, including scripts to
|
||||
control those activities. However, it does not include the work's
|
||||
System Libraries, or general-purpose tools or generally available free
|
||||
programs which are used unmodified in performing those activities but
|
||||
which are not part of the work. For example, Corresponding Source
|
||||
includes interface definition files associated with source files for
|
||||
the work, and the source code for shared libraries and dynamically
|
||||
linked subprograms that the work is specifically designed to require,
|
||||
such as by intimate data communication or control flow between those
|
||||
subprograms and other parts of the work.
|
||||
|
||||
The Corresponding Source need not include anything that users
|
||||
can regenerate automatically from other parts of the Corresponding
|
||||
Source.
|
||||
|
||||
The Corresponding Source for a work in source code form is that
|
||||
same work.
|
||||
|
||||
2. Basic Permissions.
|
||||
|
||||
All rights granted under this License are granted for the term of
|
||||
copyright on the Program, and are irrevocable provided the stated
|
||||
conditions are met. This License explicitly affirms your unlimited
|
||||
permission to run the unmodified Program. The output from running a
|
||||
covered work is covered by this License only if the output, given its
|
||||
content, constitutes a covered work. This License acknowledges your
|
||||
rights of fair use or other equivalent, as provided by copyright law.
|
||||
|
||||
You may make, run and propagate covered works that you do not
|
||||
convey, without conditions so long as your license otherwise remains
|
||||
in force. You may convey covered works to others for the sole purpose
|
||||
of having them make modifications exclusively for you, or provide you
|
||||
with facilities for running those works, provided that you comply with
|
||||
the terms of this License in conveying all material for which you do
|
||||
not control copyright. Those thus making or running the covered works
|
||||
for you must do so exclusively on your behalf, under your direction
|
||||
and control, on terms that prohibit them from making any copies of
|
||||
your copyrighted material outside their relationship with you.
|
||||
|
||||
Conveying under any other circumstances is permitted solely under
|
||||
the conditions stated below. Sublicensing is not allowed; section 10
|
||||
makes it unnecessary.
|
||||
|
||||
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
||||
|
||||
No covered work shall be deemed part of an effective technological
|
||||
measure under any applicable law fulfilling obligations under article
|
||||
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
||||
similar laws prohibiting or restricting circumvention of such
|
||||
measures.
|
||||
|
||||
When you convey a covered work, you waive any legal power to forbid
|
||||
circumvention of technological measures to the extent such circumvention
|
||||
is effected by exercising rights under this License with respect to
|
||||
the covered work, and you disclaim any intention to limit operation or
|
||||
modification of the work as a means of enforcing, against the work's
|
||||
users, your or third parties' legal rights to forbid circumvention of
|
||||
technological measures.
|
||||
|
||||
4. Conveying Verbatim Copies.
|
||||
|
||||
You may convey verbatim copies of the Program's source code as you
|
||||
receive it, in any medium, provided that you conspicuously and
|
||||
appropriately publish on each copy an appropriate copyright notice;
|
||||
keep intact all notices stating that this License and any
|
||||
non-permissive terms added in accord with section 7 apply to the code;
|
||||
keep intact all notices of the absence of any warranty; and give all
|
||||
recipients a copy of this License along with the Program.
|
||||
|
||||
You may charge any price or no price for each copy that you convey,
|
||||
and you may offer support or warranty protection for a fee.
|
||||
|
||||
5. Conveying Modified Source Versions.
|
||||
|
||||
You may convey a work based on the Program, or the modifications to
|
||||
produce it from the Program, in the form of source code under the
|
||||
terms of section 4, provided that you also meet all of these conditions:
|
||||
|
||||
a) The work must carry prominent notices stating that you modified
|
||||
it, and giving a relevant date.
|
||||
|
||||
b) The work must carry prominent notices stating that it is
|
||||
released under this License and any conditions added under section
|
||||
7. This requirement modifies the requirement in section 4 to
|
||||
"keep intact all notices".
|
||||
|
||||
c) You must license the entire work, as a whole, under this
|
||||
License to anyone who comes into possession of a copy. This
|
||||
License will therefore apply, along with any applicable section 7
|
||||
additional terms, to the whole of the work, and all its parts,
|
||||
regardless of how they are packaged. This License gives no
|
||||
permission to license the work in any other way, but it does not
|
||||
invalidate such permission if you have separately received it.
|
||||
|
||||
d) If the work has interactive user interfaces, each must display
|
||||
Appropriate Legal Notices; however, if the Program has interactive
|
||||
interfaces that do not display Appropriate Legal Notices, your
|
||||
work need not make them do so.
|
||||
|
||||
A compilation of a covered work with other separate and independent
|
||||
works, which are not by their nature extensions of the covered work,
|
||||
and which are not combined with it such as to form a larger program,
|
||||
in or on a volume of a storage or distribution medium, is called an
|
||||
"aggregate" if the compilation and its resulting copyright are not
|
||||
used to limit the access or legal rights of the compilation's users
|
||||
beyond what the individual works permit. Inclusion of a covered work
|
||||
in an aggregate does not cause this License to apply to the other
|
||||
parts of the aggregate.
|
||||
|
||||
6. Conveying Non-Source Forms.
|
||||
|
||||
You may convey a covered work in object code form under the terms
|
||||
of sections 4 and 5, provided that you also convey the
|
||||
machine-readable Corresponding Source under the terms of this License,
|
||||
in one of these ways:
|
||||
|
||||
a) Convey the object code in, or embodied in, a physical product
|
||||
(including a physical distribution medium), accompanied by the
|
||||
Corresponding Source fixed on a durable physical medium
|
||||
customarily used for software interchange.
|
||||
|
||||
b) Convey the object code in, or embodied in, a physical product
|
||||
(including a physical distribution medium), accompanied by a
|
||||
written offer, valid for at least three years and valid for as
|
||||
long as you offer spare parts or customer support for that product
|
||||
model, to give anyone who possesses the object code either (1) a
|
||||
copy of the Corresponding Source for all the software in the
|
||||
product that is covered by this License, on a durable physical
|
||||
medium customarily used for software interchange, for a price no
|
||||
more than your reasonable cost of physically performing this
|
||||
conveying of source, or (2) access to copy the
|
||||
Corresponding Source from a network server at no charge.
|
||||
|
||||
c) Convey individual copies of the object code with a copy of the
|
||||
written offer to provide the Corresponding Source. This
|
||||
alternative is allowed only occasionally and noncommercially, and
|
||||
only if you received the object code with such an offer, in accord
|
||||
with subsection 6b.
|
||||
|
||||
d) Convey the object code by offering access from a designated
|
||||
place (gratis or for a charge), and offer equivalent access to the
|
||||
Corresponding Source in the same way through the same place at no
|
||||
further charge. You need not require recipients to copy the
|
||||
Corresponding Source along with the object code. If the place to
|
||||
copy the object code is a network server, the Corresponding Source
|
||||
may be on a different server (operated by you or a third party)
|
||||
that supports equivalent copying facilities, provided you maintain
|
||||
clear directions next to the object code saying where to find the
|
||||
Corresponding Source. Regardless of what server hosts the
|
||||
Corresponding Source, you remain obligated to ensure that it is
|
||||
available for as long as needed to satisfy these requirements.
|
||||
|
||||
e) Convey the object code using peer-to-peer transmission, provided
|
||||
you inform other peers where the object code and Corresponding
|
||||
Source of the work are being offered to the general public at no
|
||||
charge under subsection 6d.
|
||||
|
||||
A separable portion of the object code, whose source code is excluded
|
||||
from the Corresponding Source as a System Library, need not be
|
||||
included in conveying the object code work.
|
||||
|
||||
A "User Product" is either (1) a "consumer product", which means any
|
||||
tangible personal property which is normally used for personal, family,
|
||||
or household purposes, or (2) anything designed or sold for incorporation
|
||||
into a dwelling. In determining whether a product is a consumer product,
|
||||
doubtful cases shall be resolved in favor of coverage. For a particular
|
||||
product received by a particular user, "normally used" refers to a
|
||||
typical or common use of that class of product, regardless of the status
|
||||
of the particular user or of the way in which the particular user
|
||||
actually uses, or expects or is expected to use, the product. A product
|
||||
is a consumer product regardless of whether the product has substantial
|
||||
commercial, industrial or non-consumer uses, unless such uses represent
|
||||
the only significant mode of use of the product.
|
||||
|
||||
"Installation Information" for a User Product means any methods,
|
||||
procedures, authorization keys, or other information required to install
|
||||
and execute modified versions of a covered work in that User Product from
|
||||
a modified version of its Corresponding Source. The information must
|
||||
suffice to ensure that the continued functioning of the modified object
|
||||
code is in no case prevented or interfered with solely because
|
||||
modification has been made.
|
||||
|
||||
If you convey an object code work under this section in, or with, or
|
||||
specifically for use in, a User Product, and the conveying occurs as
|
||||
part of a transaction in which the right of possession and use of the
|
||||
User Product is transferred to the recipient in perpetuity or for a
|
||||
fixed term (regardless of how the transaction is characterized), the
|
||||
Corresponding Source conveyed under this section must be accompanied
|
||||
by the Installation Information. But this requirement does not apply
|
||||
if neither you nor any third party retains the ability to install
|
||||
modified object code on the User Product (for example, the work has
|
||||
been installed in ROM).
|
||||
|
||||
The requirement to provide Installation Information does not include a
|
||||
requirement to continue to provide support service, warranty, or updates
|
||||
for a work that has been modified or installed by the recipient, or for
|
||||
the User Product in which it has been modified or installed. Access to a
|
||||
network may be denied when the modification itself materially and
|
||||
adversely affects the operation of the network or violates the rules and
|
||||
protocols for communication across the network.
|
||||
|
||||
Corresponding Source conveyed, and Installation Information provided,
|
||||
in accord with this section must be in a format that is publicly
|
||||
documented (and with an implementation available to the public in
|
||||
source code form), and must require no special password or key for
|
||||
unpacking, reading or copying.
|
||||
|
||||
7. Additional Terms.
|
||||
|
||||
"Additional permissions" are terms that supplement the terms of this
|
||||
License by making exceptions from one or more of its conditions.
|
||||
Additional permissions that are applicable to the entire Program shall
|
||||
be treated as though they were included in this License, to the extent
|
||||
that they are valid under applicable law. If additional permissions
|
||||
apply only to part of the Program, that part may be used separately
|
||||
under those permissions, but the entire Program remains governed by
|
||||
this License without regard to the additional permissions.
|
||||
|
||||
When you convey a copy of a covered work, you may at your option
|
||||
remove any additional permissions from that copy, or from any part of
|
||||
it. (Additional permissions may be written to require their own
|
||||
removal in certain cases when you modify the work.) You may place
|
||||
additional permissions on material, added by you to a covered work,
|
||||
for which you have or can give appropriate copyright permission.
|
||||
|
||||
Notwithstanding any other provision of this License, for material you
|
||||
add to a covered work, you may (if authorized by the copyright holders of
|
||||
that material) supplement the terms of this License with terms:
|
||||
|
||||
a) Disclaiming warranty or limiting liability differently from the
|
||||
terms of sections 15 and 16 of this License; or
|
||||
|
||||
b) Requiring preservation of specified reasonable legal notices or
|
||||
author attributions in that material or in the Appropriate Legal
|
||||
Notices displayed by works containing it; or
|
||||
|
||||
c) Prohibiting misrepresentation of the origin of that material, or
|
||||
requiring that modified versions of such material be marked in
|
||||
reasonable ways as different from the original version; or
|
||||
|
||||
d) Limiting the use for publicity purposes of names of licensors or
|
||||
authors of the material; or
|
||||
|
||||
e) Declining to grant rights under trademark law for use of some
|
||||
trade names, trademarks, or service marks; or
|
||||
|
||||
f) Requiring indemnification of licensors and authors of that
|
||||
material by anyone who conveys the material (or modified versions of
|
||||
it) with contractual assumptions of liability to the recipient, for
|
||||
any liability that these contractual assumptions directly impose on
|
||||
those licensors and authors.
|
||||
|
||||
All other non-permissive additional terms are considered "further
|
||||
restrictions" within the meaning of section 10. If the Program as you
|
||||
received it, or any part of it, contains a notice stating that it is
|
||||
governed by this License along with a term that is a further
|
||||
restriction, you may remove that term. If a license document contains
|
||||
a further restriction but permits relicensing or conveying under this
|
||||
License, you may add to a covered work material governed by the terms
|
||||
of that license document, provided that the further restriction does
|
||||
not survive such relicensing or conveying.
|
||||
|
||||
If you add terms to a covered work in accord with this section, you
|
||||
must place, in the relevant source files, a statement of the
|
||||
additional terms that apply to those files, or a notice indicating
|
||||
where to find the applicable terms.
|
||||
|
||||
Additional terms, permissive or non-permissive, may be stated in the
|
||||
form of a separately written license, or stated as exceptions;
|
||||
the above requirements apply either way.
|
||||
|
||||
8. Termination.
|
||||
|
||||
You may not propagate or modify a covered work except as expressly
|
||||
provided under this License. Any attempt otherwise to propagate or
|
||||
modify it is void, and will automatically terminate your rights under
|
||||
this License (including any patent licenses granted under the third
|
||||
paragraph of section 11).
|
||||
|
||||
However, if you cease all violation of this License, then your
|
||||
license from a particular copyright holder is reinstated (a)
|
||||
provisionally, unless and until the copyright holder explicitly and
|
||||
finally terminates your license, and (b) permanently, if the copyright
|
||||
holder fails to notify you of the violation by some reasonable means
|
||||
prior to 60 days after the cessation.
|
||||
|
||||
Moreover, your license from a particular copyright holder is
|
||||
reinstated permanently if the copyright holder notifies you of the
|
||||
violation by some reasonable means, this is the first time you have
|
||||
received notice of violation of this License (for any work) from that
|
||||
copyright holder, and you cure the violation prior to 30 days after
|
||||
your receipt of the notice.
|
||||
|
||||
Termination of your rights under this section does not terminate the
|
||||
licenses of parties who have received copies or rights from you under
|
||||
this License. If your rights have been terminated and not permanently
|
||||
reinstated, you do not qualify to receive new licenses for the same
|
||||
material under section 10.
|
||||
|
||||
9. Acceptance Not Required for Having Copies.
|
||||
|
||||
You are not required to accept this License in order to receive or
|
||||
run a copy of the Program. Ancillary propagation of a covered work
|
||||
occurring solely as a consequence of using peer-to-peer transmission
|
||||
to receive a copy likewise does not require acceptance. However,
|
||||
nothing other than this License grants you permission to propagate or
|
||||
modify any covered work. These actions infringe copyright if you do
|
||||
not accept this License. Therefore, by modifying or propagating a
|
||||
covered work, you indicate your acceptance of this License to do so.
|
||||
|
||||
10. Automatic Licensing of Downstream Recipients.
|
||||
|
||||
Each time you convey a covered work, the recipient automatically
|
||||
receives a license from the original licensors, to run, modify and
|
||||
propagate that work, subject to this License. You are not responsible
|
||||
for enforcing compliance by third parties with this License.
|
||||
|
||||
An "entity transaction" is a transaction transferring control of an
|
||||
organization, or substantially all assets of one, or subdividing an
|
||||
organization, or merging organizations. If propagation of a covered
|
||||
work results from an entity transaction, each party to that
|
||||
transaction who receives a copy of the work also receives whatever
|
||||
licenses to the work the party's predecessor in interest had or could
|
||||
give under the previous paragraph, plus a right to possession of the
|
||||
Corresponding Source of the work from the predecessor in interest, if
|
||||
the predecessor has it or can get it with reasonable efforts.
|
||||
|
||||
You may not impose any further restrictions on the exercise of the
|
||||
rights granted or affirmed under this License. For example, you may
|
||||
not impose a license fee, royalty, or other charge for exercise of
|
||||
rights granted under this License, and you may not initiate litigation
|
||||
(including a cross-claim or counterclaim in a lawsuit) alleging that
|
||||
any patent claim is infringed by making, using, selling, offering for
|
||||
sale, or importing the Program or any portion of it.
|
||||
|
||||
11. Patents.
|
||||
|
||||
A "contributor" is a copyright holder who authorizes use under this
|
||||
License of the Program or a work on which the Program is based. The
|
||||
work thus licensed is called the contributor's "contributor version".
|
||||
|
||||
A contributor's "essential patent claims" are all patent claims
|
||||
owned or controlled by the contributor, whether already acquired or
|
||||
hereafter acquired, that would be infringed by some manner, permitted
|
||||
by this License, of making, using, or selling its contributor version,
|
||||
but do not include claims that would be infringed only as a
|
||||
consequence of further modification of the contributor version. For
|
||||
purposes of this definition, "control" includes the right to grant
|
||||
patent sublicenses in a manner consistent with the requirements of
|
||||
this License.
|
||||
|
||||
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
||||
patent license under the contributor's essential patent claims, to
|
||||
make, use, sell, offer for sale, import and otherwise run, modify and
|
||||
propagate the contents of its contributor version.
|
||||
|
||||
In the following three paragraphs, a "patent license" is any express
|
||||
agreement or commitment, however denominated, not to enforce a patent
|
||||
(such as an express permission to practice a patent or covenant not to
|
||||
sue for patent infringement). To "grant" such a patent license to a
|
||||
party means to make such an agreement or commitment not to enforce a
|
||||
patent against the party.
|
||||
|
||||
If you convey a covered work, knowingly relying on a patent license,
|
||||
and the Corresponding Source of the work is not available for anyone
|
||||
to copy, free of charge and under the terms of this License, through a
|
||||
publicly available network server or other readily accessible means,
|
||||
then you must either (1) cause the Corresponding Source to be so
|
||||
available, or (2) arrange to deprive yourself of the benefit of the
|
||||
patent license for this particular work, or (3) arrange, in a manner
|
||||
consistent with the requirements of this License, to extend the patent
|
||||
license to downstream recipients. "Knowingly relying" means you have
|
||||
actual knowledge that, but for the patent license, your conveying the
|
||||
covered work in a country, or your recipient's use of the covered work
|
||||
in a country, would infringe one or more identifiable patents in that
|
||||
country that you have reason to believe are valid.
|
||||
|
||||
If, pursuant to or in connection with a single transaction or
|
||||
arrangement, you convey, or propagate by procuring conveyance of, a
|
||||
covered work, and grant a patent license to some of the parties
|
||||
receiving the covered work authorizing them to use, propagate, modify
|
||||
or convey a specific copy of the covered work, then the patent license
|
||||
you grant is automatically extended to all recipients of the covered
|
||||
work and works based on it.
|
||||
|
||||
A patent license is "discriminatory" if it does not include within
|
||||
the scope of its coverage, prohibits the exercise of, or is
|
||||
conditioned on the non-exercise of one or more of the rights that are
|
||||
specifically granted under this License. You may not convey a covered
|
||||
work if you are a party to an arrangement with a third party that is
|
||||
in the business of distributing software, under which you make payment
|
||||
to the third party based on the extent of your activity of conveying
|
||||
the work, and under which the third party grants, to any of the
|
||||
parties who would receive the covered work from you, a discriminatory
|
||||
patent license (a) in connection with copies of the covered work
|
||||
conveyed by you (or copies made from those copies), or (b) primarily
|
||||
for and in connection with specific products or compilations that
|
||||
contain the covered work, unless you entered into that arrangement,
|
||||
or that patent license was granted, prior to 28 March 2007.
|
||||
|
||||
Nothing in this License shall be construed as excluding or limiting
|
||||
any implied license or other defenses to infringement that may
|
||||
otherwise be available to you under applicable patent law.
|
||||
|
||||
12. No Surrender of Others' Freedom.
|
||||
|
||||
If conditions are imposed on you (whether by court order, agreement or
|
||||
otherwise) that contradict the conditions of this License, they do not
|
||||
excuse you from the conditions of this License. If you cannot convey a
|
||||
covered work so as to satisfy simultaneously your obligations under this
|
||||
License and any other pertinent obligations, then as a consequence you may
|
||||
not convey it at all. For example, if you agree to terms that obligate you
|
||||
to collect a royalty for further conveying from those to whom you convey
|
||||
the Program, the only way you could satisfy both those terms and this
|
||||
License would be to refrain entirely from conveying the Program.
|
||||
|
||||
13. Use with the GNU Affero General Public License.
|
||||
|
||||
Notwithstanding any other provision of this License, you have
|
||||
permission to link or combine any covered work with a work licensed
|
||||
under version 3 of the GNU Affero General Public License into a single
|
||||
combined work, and to convey the resulting work. The terms of this
|
||||
License will continue to apply to the part which is the covered work,
|
||||
but the special requirements of the GNU Affero General Public License,
|
||||
section 13, concerning interaction through a network will apply to the
|
||||
combination as such.
|
||||
|
||||
14. Revised Versions of this License.
|
||||
|
||||
The Free Software Foundation may publish revised and/or new versions of
|
||||
the GNU General Public License from time to time. Such new versions will
|
||||
be similar in spirit to the present version, but may differ in detail to
|
||||
address new problems or concerns.
|
||||
|
||||
Each version is given a distinguishing version number. If the
|
||||
Program specifies that a certain numbered version of the GNU General
|
||||
Public License "or any later version" applies to it, you have the
|
||||
option of following the terms and conditions either of that numbered
|
||||
version or of any later version published by the Free Software
|
||||
Foundation. If the Program does not specify a version number of the
|
||||
GNU General Public License, you may choose any version ever published
|
||||
by the Free Software Foundation.
|
||||
|
||||
If the Program specifies that a proxy can decide which future
|
||||
versions of the GNU General Public License can be used, that proxy's
|
||||
public statement of acceptance of a version permanently authorizes you
|
||||
to choose that version for the Program.
|
||||
|
||||
Later license versions may give you additional or different
|
||||
permissions. However, no additional obligations are imposed on any
|
||||
author or copyright holder as a result of your choosing to follow a
|
||||
later version.
|
||||
|
||||
15. Disclaimer of Warranty.
|
||||
|
||||
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
||||
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
||||
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
||||
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
||||
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
||||
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
||||
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
||||
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
||||
|
||||
16. Limitation of Liability.
|
||||
|
||||
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
||||
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
||||
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
||||
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
||||
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
|
||||
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
|
||||
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
|
||||
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
||||
SUCH DAMAGES.
|
||||
|
||||
17. Interpretation of Sections 15 and 16.
|
||||
|
||||
If the disclaimer of warranty and limitation of liability provided
|
||||
above cannot be given local legal effect according to their terms,
|
||||
reviewing courts shall apply local law that most closely approximates
|
||||
an absolute waiver of all civil liability in connection with the
|
||||
Program, unless a warranty or assumption of liability accompanies a
|
||||
copy of the Program in return for a fee.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
How to Apply These Terms to Your New Programs
|
||||
|
||||
If you develop a new program, and you want it to be of the greatest
|
||||
possible use to the public, the best way to achieve this is to make it
|
||||
free software which everyone can redistribute and change under these terms.
|
||||
|
||||
To do so, attach the following notices to the program. It is safest
|
||||
to attach them to the start of each source file to most effectively
|
||||
state the exclusion of warranty; and each file should have at least
|
||||
the "copyright" line and a pointer to where the full notice is found.
|
||||
|
||||
ComfyUI Lora Manager - A ComfyUI custom node for managing models
|
||||
Copyright (C) 2025 Will Miao
|
||||
|
||||
This program is free software: you can redistribute it and/or modify
|
||||
it under the terms of the GNU General Public License as published by
|
||||
the Free Software Foundation, either version 3 of the License, or
|
||||
(at your option) any later version.
|
||||
|
||||
This program is distributed in the hope that it will be useful,
|
||||
but WITHOUT ANY WARRANTY; without even the implied warranty of
|
||||
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
||||
GNU General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License
|
||||
along with this program. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
Also add information on how to contact you by electronic and paper mail.
|
||||
|
||||
If the program does terminal interaction, make it output a short
|
||||
notice like this when it starts in an interactive mode:
|
||||
|
||||
ComfyUI Lora Manager Copyright (C) 2025 Will Miao
|
||||
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
|
||||
This is free software, and you are welcome to redistribute it
|
||||
under certain conditions; type `show c' for details.
|
||||
|
||||
The hypothetical commands `show w' and `show c' should show the appropriate
|
||||
parts of the General Public License. Of course, your program's commands
|
||||
might be different; for a GUI interface, you would use an "about box".
|
||||
|
||||
You should also get your employer (if you work as a programmer) or school,
|
||||
if any, to sign a "copyright disclaimer" for the program, if necessary.
|
||||
For more information on this, and how to apply and follow the GNU GPL, see
|
||||
<https://www.gnu.org/licenses/>.
|
||||
|
||||
The GNU General Public License does not permit incorporating your program
|
||||
into proprietary programs. If your program is a subroutine library, you
|
||||
may consider it more useful to permit linking proprietary applications with
|
||||
the library. If this is what you want to do, use the GNU Lesser General
|
||||
Public License instead of this License. But first, please read
|
||||
<https://www.gnu.org/licenses/why-not-lgpl.html>.
|
||||
189
README.md
189
README.md
@@ -10,60 +10,71 @@ A comprehensive toolset that streamlines organizing, downloading, and applying L
|
||||
|
||||

|
||||
|
||||
One-click Integration:
|
||||

|
||||
|
||||
## 📺 Tutorial: One-Click LoRA Integration
|
||||
Watch this quick tutorial to learn how to use the new one-click LoRA integration feature:
|
||||
|
||||
[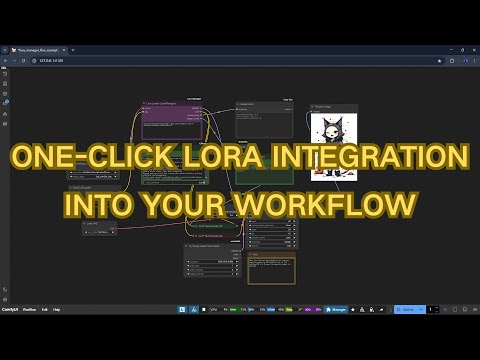](https://youtu.be/qS95OjX3e70)
|
||||
[](https://youtu.be/noN7f_ER7yo)
|
||||
[](https://youtu.be/hvKw31YpE-U)
|
||||
|
||||
---
|
||||
|
||||
## Release Notes
|
||||
|
||||
### v0.8.6 Major Update
|
||||
* **Checkpoint Management** - Added comprehensive management for model checkpoints including scanning, searching, filtering, and deletion
|
||||
* **Enhanced Metadata Support** - New capabilities for retrieving and managing checkpoint metadata with improved operations
|
||||
* **Improved Initial Loading** - Optimized cache initialization with visual progress indicators for better user experience
|
||||
### v0.8.17
|
||||
* **Duplicate Model Detection** - Added "Find Duplicates" functionality for LoRAs and checkpoints using model file hash detection, enabling convenient viewing and batch deletion of duplicate models
|
||||
* **Enhanced URL Recipe Imports** - Optimized import recipe via URL functionality using CivitAI API calls instead of web scraping, now supporting all rated images (including NSFW) for recipe imports
|
||||
* **Improved TriggerWord Control** - Enhanced TriggerWord Toggle node with new default_active switch to set the initial state (active/inactive) when trigger words are added
|
||||
* **Centralized Example Management** - Added "Migrate Existing Example Images" feature to consolidate downloaded example images from model folders into central storage with customizable naming patterns
|
||||
* **Intelligent Word Suggestions** - Implemented smart trigger word suggestions by reading class tokens and tag frequency from safetensors files, displaying recommendations when editing trigger words
|
||||
* **Model Version Management** - Added "Re-link to CivitAI" context menu option for connecting models to different CivitAI versions when needed
|
||||
|
||||
### v0.8.5
|
||||
* **Enhanced LoRA & Recipe Connectivity** - Added Recipes tab in LoRA details to see all recipes using a specific LoRA
|
||||
* **Improved Navigation** - New shortcuts to jump between related LoRAs and Recipes with one-click navigation
|
||||
* **Video Preview Controls** - Added "Autoplay Videos on Hover" setting to optimize performance and reduce resource usage
|
||||
* **UI Experience Refinements** - Smoother transitions between related content pages
|
||||
### v0.8.16
|
||||
* **Dramatic Startup Speed Improvement** - Added cache serialization mechanism for significantly faster loading times, especially beneficial for large model collections
|
||||
* **Enhanced Refresh Options** - Extended functionality with "Full Rebuild (complete)" option alongside "Quick Refresh (incremental)" to fix potential memory cache issues without requiring application restart
|
||||
* **Customizable Display Density** - Replaced compact mode with adjustable display density settings for personalized layout customization
|
||||
* **Model Creator Information** - Added creator details to model information panels for better attribution
|
||||
* **Improved WebP Support** - Enhanced Save Image node with workflow embedding capability for WebP format images
|
||||
* **Direct Example Access** - Added "Open Example Images Folder" button to card interfaces for convenient browsing of downloaded model examples
|
||||
* **Enhanced Compatibility** - Full ComfyUI Desktop support for "Send lora or recipe to workflow" functionality
|
||||
* **Cache Management** - Added settings to clear existing cache files when needed
|
||||
* **Bug Fixes & Stability** - Various improvements for overall reliability and performance
|
||||
|
||||
### v0.8.4
|
||||
* **Node Layout Improvements** - Fixed layout issues with LoRA Loader and Trigger Words Toggle nodes in newer ComfyUI frontend versions
|
||||
* **Recipe LoRA Reconnection** - Added ability to reconnect deleted LoRAs in recipes by clicking the "deleted" badge in recipe details
|
||||
* **Bug Fixes & Stability** - Resolved various issues for improved reliability
|
||||
### v0.8.15
|
||||
* **Enhanced One-Click Integration** - Replaced copy button with direct send button allowing LoRAs/recipes to be sent directly to your current ComfyUI workflow without needing to paste
|
||||
* **Flexible Workflow Integration** - Click to append LoRAs/recipes to existing loader nodes or Shift+click to replace content, with additional right-click menu options for "Send to Workflow (Append)" or "Send to Workflow (Replace)"
|
||||
* **Improved LoRA Loader Controls** - Added header drag functionality for proportional strength adjustment of all LoRAs simultaneously (including CLIP strengths when expanded)
|
||||
* **Keyboard Navigation Support** - Implemented Page Up/Down for page scrolling, Home key to jump to top, and End key to jump to bottom for faster browsing through large collections
|
||||
|
||||
### v0.8.3
|
||||
* **Enhanced Workflow Parser** - Rebuilt workflow analysis engine with improved support for ComfyUI core nodes and easier extensibility
|
||||
* **Improved Recipe System** - Refined the experimental Save Recipe functionality with better workflow integration
|
||||
* **New Save Image Node** - Added experimental node with metadata support for perfect CivitAI compatibility
|
||||
* Supports dynamic filename prefixes with variables [1](https://github.com/nkchocoai/ComfyUI-SaveImageWithMetaData?tab=readme-ov-file#filename_prefix)
|
||||
* **Default LoRA Root Setting** - Added configuration option for setting your preferred LoRA directory
|
||||
### v0.8.14
|
||||
* **Virtualized Scrolling** - Completely rebuilt rendering mechanism for smooth browsing with no lag or freezing, now supporting virtually unlimited model collections with optimized layouts for large displays, improving space utilization and user experience
|
||||
* **Compact Display Mode** - Added space-efficient view option that displays more cards per row (7 on 1080p, 8 on 2K, 10 on 4K)
|
||||
* **Enhanced LoRA Node Functionality** - Comprehensive improvements to LoRA loader/stacker nodes including real-time trigger word updates (reflecting any change anywhere in the LoRA chain for precise updates) and expanded context menu with "Copy Notes" and "Copy Trigger Words" options for faster workflow
|
||||
|
||||
### v0.8.2
|
||||
* **Faster Initialization for Forge Users** - Improved first-run efficiency by utilizing existing `.json` and `.civitai.info` files from Forge’s CivitAI helper extension, making migration smoother.
|
||||
* **LoRA Filename Editing** - Added support for renaming LoRA files directly within LoRA Manager.
|
||||
* **Recipe Editing** - Users can now edit recipe names and tags.
|
||||
* **Retain Deleted LoRAs in Recipes** - Deleted LoRAs will remain listed in recipes, allowing future functionality to reconnect them once re-obtained.
|
||||
* **Download Missing LoRAs from Recipes** - Easily fetch missing LoRAs associated with a recipe.
|
||||
### v0.8.13
|
||||
* **Enhanced Recipe Management** - Added "Find duplicates" feature to identify and batch delete duplicate recipes with duplicate detection notifications during imports
|
||||
* **Improved Source Tracking** - Source URLs are now saved with recipes imported via URL, allowing users to view original content with one click or manually edit links
|
||||
* **Advanced LoRA Control** - Double-click LoRAs in Loader/Stacker nodes to access expanded CLIP strength controls for more precise adjustments of model and CLIP strength separately
|
||||
* **Lycoris Model Support** - Added compatibility with Lycoris models for expanded creative options
|
||||
* **Bug Fixes & UX Improvements** - Resolved various issues and enhanced overall user experience with numerous optimizations
|
||||
|
||||
### v0.8.1
|
||||
* **Base Model Correction** - Added support for modifying base model associations to fix incorrect metadata for non-CivitAI LoRAs
|
||||
* **LoRA Loader Flexibility** - Made CLIP input optional for model-only workflows like Hunyuan video generation
|
||||
* **Expanded Recipe Support** - Added compatibility with 3 additional recipe metadata formats
|
||||
* **Enhanced Showcase Images** - Generation parameters now displayed alongside LoRA preview images
|
||||
* **UI Improvements & Bug Fixes** - Various interface refinements and stability enhancements
|
||||
### v0.8.12
|
||||
* **Enhanced Model Discovery** - Added alphabetical navigation bar to LoRAs page for faster browsing through large collections
|
||||
* **Optimized Example Images** - Improved download logic to automatically refresh stale metadata before fetching example images
|
||||
* **Model Exclusion System** - New right-click option to exclude specific LoRAs or checkpoints from management
|
||||
* **Improved Showcase Experience** - Enhanced interaction in LoRA and checkpoint showcase areas for better usability
|
||||
|
||||
### v0.8.0
|
||||
* **Introduced LoRA Recipes** - Create, import, save, and share your favorite LoRA combinations
|
||||
* **Recipe Management System** - Easily browse, search, and organize your LoRA recipes
|
||||
* **Workflow Integration** - Save recipes directly from your workflow with generation parameters preserved
|
||||
* **Simplified Workflow Application** - Quickly apply saved recipes to new projects
|
||||
* **Enhanced UI & UX** - Improved interface design and user experience
|
||||
* **Bug Fixes & Stability** - Resolved various issues and enhanced overall performance
|
||||
### v0.8.11
|
||||
* **Offline Image Support** - Added functionality to download and save all model example images locally, ensuring access even when offline or if images are removed from CivitAI or the site is down
|
||||
* **Resilient Download System** - Implemented pause/resume capability with checkpoint recovery that persists through restarts or unexpected exits
|
||||
* **Bug Fixes & Stability** - Resolved various issues to enhance overall reliability and performance
|
||||
|
||||
### v0.8.10
|
||||
* **Standalone Mode** - Run LoRA Manager independently from ComfyUI for a lightweight experience that works even with other stable diffusion interfaces
|
||||
* **Portable Edition** - New one-click portable version for easy startup and updates in standalone mode
|
||||
* **Enhanced Metadata Collection** - Added support for SamplerCustomAdvanced node in the metadata collector module
|
||||
* **Improved UI Organization** - Optimized Lora Loader node height to display up to 5 LoRAs at once with scrolling capability for larger collections
|
||||
|
||||
[View Update History](./update_logs.md)
|
||||
|
||||
@@ -120,19 +131,26 @@ Watch this quick tutorial to learn how to use the new one-click LoRA integration
|
||||
|
||||
## Installation
|
||||
|
||||
### Option 1: **ComfyUI Manager** (Recommended)
|
||||
### Option 1: **ComfyUI Manager** (Recommended for ComfyUI users)
|
||||
|
||||
1. Open **ComfyUI**.
|
||||
2. Go to **Manager > Custom Node Manager**.
|
||||
3. Search for `lora-manager`.
|
||||
4. Click **Install**.
|
||||
|
||||
### Option 2: **Manual Installation**
|
||||
### Option 2: **Portable Standalone Edition** (No ComfyUI required)
|
||||
|
||||
1. Download the [Portable Package](https://github.com/willmiao/ComfyUI-Lora-Manager/releases/download/v0.8.15/lora_manager_portable.7z)
|
||||
2. Copy the provided `settings.json.example` file to create a new file named `settings.json` in `comfyui-lora-manager` folder
|
||||
3. Edit `settings.json` to include your correct model folder paths and CivitAI API key
|
||||
4. Run run.bat
|
||||
|
||||
### Option 3: **Manual Installation**
|
||||
|
||||
```bash
|
||||
git clone https://github.com/willmiao/ComfyUI-Lora-Manager.git
|
||||
cd ComfyUI-Lora-Manager
|
||||
pip install requirements.txt
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
## Usage
|
||||
@@ -153,29 +171,100 @@ pip install requirements.txt
|
||||
- Paste into the Lora Loader node's text input
|
||||
- The node will automatically apply preset strength and trigger words
|
||||
|
||||
### Filename Format Patterns for Save Image Node
|
||||
|
||||
The Save Image Node supports dynamic filename generation using pattern codes. You can customize how your images are named using the following format patterns:
|
||||
|
||||
#### Available Pattern Codes
|
||||
|
||||
- `%seed%` - Inserts the generation seed number
|
||||
- `%width%` - Inserts the image width
|
||||
- `%height%` - Inserts the image height
|
||||
- `%pprompt:N%` - Inserts the positive prompt (limited to N characters)
|
||||
- `%nprompt:N%` - Inserts the negative prompt (limited to N characters)
|
||||
- `%model:N%` - Inserts the model/checkpoint name (limited to N characters)
|
||||
- `%date%` - Inserts current date/time as "yyyyMMddhhmmss"
|
||||
- `%date:FORMAT%` - Inserts date using custom format with:
|
||||
- `yyyy` - 4-digit year
|
||||
- `yy` - 2-digit year
|
||||
- `MM` - 2-digit month
|
||||
- `dd` - 2-digit day
|
||||
- `hh` - 2-digit hour
|
||||
- `mm` - 2-digit minute
|
||||
- `ss` - 2-digit second
|
||||
|
||||
#### Examples
|
||||
|
||||
- `image_%seed%` → `image_1234567890`
|
||||
- `gen_%width%x%height%` → `gen_512x768`
|
||||
- `%model:10%_%seed%` → `dreamshape_1234567890`
|
||||
- `%date:yyyy-MM-dd%` → `2025-04-28`
|
||||
- `%pprompt:20%_%seed%` → `beautiful landscape_1234567890`
|
||||
- `%model%_%date:yyMMdd%_%seed%` → `dreamshaper_v8_250428_1234567890`
|
||||
|
||||
You can combine multiple patterns to create detailed, organized filenames for your generated images.
|
||||
|
||||
### Standalone Mode
|
||||
|
||||
You can now run LoRA Manager independently from ComfyUI:
|
||||
|
||||
1. **For ComfyUI users**:
|
||||
- Launch ComfyUI with LoRA Manager at least once to initialize the necessary path information in the `settings.json` file.
|
||||
- Make sure dependencies are installed: `pip install -r requirements.txt`
|
||||
- From your ComfyUI root directory, run:
|
||||
```bash
|
||||
python custom_nodes\comfyui-lora-manager\standalone.py
|
||||
```
|
||||
- Access the interface at: `http://localhost:8188/loras`
|
||||
- You can specify a different host or port with arguments:
|
||||
```bash
|
||||
python custom_nodes\comfyui-lora-manager\standalone.py --host 127.0.0.1 --port 9000
|
||||
```
|
||||
|
||||
2. **For non-ComfyUI users**:
|
||||
- Copy the provided `settings.json.example` file to create a new file named `settings.json`
|
||||
- Edit `settings.json` to include your correct model folder paths and CivitAI API key
|
||||
- Install required dependencies: `pip install -r requirements.txt`
|
||||
- Run standalone mode:
|
||||
```bash
|
||||
python standalone.py
|
||||
```
|
||||
- Access the interface through your browser at: `http://localhost:8188/loras`
|
||||
|
||||
This standalone mode provides a lightweight option for managing your model and recipe collection without needing to run the full ComfyUI environment, making it useful even for users who primarily use other stable diffusion interfaces.
|
||||
|
||||
---
|
||||
|
||||
## Contributing
|
||||
|
||||
Thank you for your interest in contributing to ComfyUI LoRA Manager! As this project is currently in its early stages and undergoing rapid development and refactoring, we are temporarily not accepting pull requests.
|
||||
|
||||
However, your feedback and ideas are extremely valuable to us:
|
||||
- Please feel free to open issues for any bugs you encounter
|
||||
- Submit feature requests through GitHub issues
|
||||
- Share your suggestions for improvements
|
||||
|
||||
We appreciate your understanding and look forward to potentially accepting code contributions once the project architecture stabilizes.
|
||||
|
||||
---
|
||||
|
||||
## Credits
|
||||
|
||||
This project has been inspired by and benefited from other excellent ComfyUI extensions:
|
||||
|
||||
- [ComfyUI-SaveImageWithMetaData](https://github.com/Comfy-Community/ComfyUI-SaveImageWithMetaData) - For the image metadata functionality
|
||||
- [ComfyUI-SaveImageWithMetaData](https://github.com/nkchocoai/ComfyUI-SaveImageWithMetaData) - For the image metadata functionality
|
||||
- [rgthree-comfy](https://github.com/rgthree/rgthree-comfy) - For the lora loader functionality
|
||||
|
||||
---
|
||||
|
||||
## Contributing
|
||||
|
||||
If you have suggestions, bug reports, or improvements, feel free to open an issue or contribute directly to the codebase. Pull requests are always welcome!
|
||||
|
||||
---
|
||||
|
||||
## ☕ Support
|
||||
|
||||
If you find this project helpful, consider supporting its development:
|
||||
|
||||
[](https://ko-fi.com/pixelpawsai)
|
||||
|
||||
WeChat: [Click to view QR code](https://raw.githubusercontent.com/willmiao/ComfyUI-Lora-Manager/main/static/images/wechat-qr.webp)
|
||||
|
||||
## 💬 Community
|
||||
|
||||
Join our Discord community for support, discussions, and updates:
|
||||
|
||||
@@ -3,16 +3,23 @@ from .py.nodes.lora_loader import LoraManagerLoader
|
||||
from .py.nodes.trigger_word_toggle import TriggerWordToggle
|
||||
from .py.nodes.lora_stacker import LoraStacker
|
||||
from .py.nodes.save_image import SaveImage
|
||||
from .py.nodes.debug_metadata import DebugMetadata
|
||||
# Import metadata collector to install hooks on startup
|
||||
from .py.metadata_collector import init as init_metadata_collector
|
||||
|
||||
NODE_CLASS_MAPPINGS = {
|
||||
LoraManagerLoader.NAME: LoraManagerLoader,
|
||||
TriggerWordToggle.NAME: TriggerWordToggle,
|
||||
LoraStacker.NAME: LoraStacker,
|
||||
SaveImage.NAME: SaveImage
|
||||
SaveImage.NAME: SaveImage,
|
||||
DebugMetadata.NAME: DebugMetadata
|
||||
}
|
||||
|
||||
WEB_DIRECTORY = "./web/comfyui"
|
||||
|
||||
# Initialize metadata collector
|
||||
init_metadata_collector()
|
||||
|
||||
# Register routes on import
|
||||
LoraManager.add_routes()
|
||||
__all__ = ['NODE_CLASS_MAPPINGS', 'WEB_DIRECTORY']
|
||||
|
||||
BIN
example_workflows/Flux Example.jpg
Normal file
BIN
example_workflows/Flux Example.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 669 KiB |
1
example_workflows/Flux Example.json
Normal file
1
example_workflows/Flux Example.json
Normal file
File diff suppressed because one or more lines are too long
BIN
example_workflows/Illustrious Pony Example.jpg
Normal file
BIN
example_workflows/Illustrious Pony Example.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 669 KiB |
1
example_workflows/Illustrious Pony Example.json
Normal file
1
example_workflows/Illustrious Pony Example.json
Normal file
File diff suppressed because one or more lines are too long
140
py/config.py
140
py/config.py
@@ -3,6 +3,11 @@ import platform
|
||||
import folder_paths # type: ignore
|
||||
from typing import List
|
||||
import logging
|
||||
import sys
|
||||
import json
|
||||
|
||||
# Check if running in standalone mode
|
||||
standalone_mode = 'nodes' not in sys.modules
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@@ -18,9 +23,46 @@ class Config:
|
||||
self._route_mappings = {}
|
||||
self.loras_roots = self._init_lora_paths()
|
||||
self.checkpoints_roots = self._init_checkpoint_paths()
|
||||
self.temp_directory = folder_paths.get_temp_directory()
|
||||
# 在初始化时扫描符号链接
|
||||
self._scan_symbolic_links()
|
||||
|
||||
if not standalone_mode:
|
||||
# Save the paths to settings.json when running in ComfyUI mode
|
||||
self.save_folder_paths_to_settings()
|
||||
|
||||
def save_folder_paths_to_settings(self):
|
||||
"""Save folder paths to settings.json for standalone mode to use later"""
|
||||
try:
|
||||
# Check if we're running in ComfyUI mode (not standalone)
|
||||
if hasattr(folder_paths, "get_folder_paths") and not isinstance(folder_paths, type):
|
||||
# Get all relevant paths
|
||||
lora_paths = folder_paths.get_folder_paths("loras")
|
||||
checkpoint_paths = folder_paths.get_folder_paths("checkpoints")
|
||||
diffuser_paths = folder_paths.get_folder_paths("diffusers")
|
||||
unet_paths = folder_paths.get_folder_paths("unet")
|
||||
|
||||
# Load existing settings
|
||||
settings_path = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'settings.json')
|
||||
settings = {}
|
||||
if os.path.exists(settings_path):
|
||||
with open(settings_path, 'r', encoding='utf-8') as f:
|
||||
settings = json.load(f)
|
||||
|
||||
# Update settings with paths
|
||||
settings['folder_paths'] = {
|
||||
'loras': lora_paths,
|
||||
'checkpoints': checkpoint_paths,
|
||||
'diffusers': diffuser_paths,
|
||||
'unet': unet_paths
|
||||
}
|
||||
|
||||
# Save settings
|
||||
with open(settings_path, 'w', encoding='utf-8') as f:
|
||||
json.dump(settings, f, indent=2)
|
||||
|
||||
logger.info("Saved folder paths to settings.json")
|
||||
except Exception as e:
|
||||
logger.warning(f"Failed to save folder paths: {e}")
|
||||
|
||||
def _is_link(self, path: str) -> bool:
|
||||
try:
|
||||
@@ -103,50 +145,66 @@ class Config:
|
||||
|
||||
def _init_lora_paths(self) -> List[str]:
|
||||
"""Initialize and validate LoRA paths from ComfyUI settings"""
|
||||
paths = sorted(set(path.replace(os.sep, "/")
|
||||
for path in folder_paths.get_folder_paths("loras")
|
||||
if os.path.exists(path)), key=lambda p: p.lower())
|
||||
print("Found LoRA roots:", "\n - " + "\n - ".join(paths))
|
||||
|
||||
if not paths:
|
||||
raise ValueError("No valid loras folders found in ComfyUI configuration")
|
||||
|
||||
# 初始化路径映射
|
||||
for path in paths:
|
||||
real_path = os.path.normpath(os.path.realpath(path)).replace(os.sep, '/')
|
||||
if real_path != path:
|
||||
self.add_path_mapping(path, real_path)
|
||||
|
||||
return paths
|
||||
try:
|
||||
raw_paths = folder_paths.get_folder_paths("loras")
|
||||
|
||||
# Normalize and resolve symlinks, store mapping from resolved -> original
|
||||
path_map = {}
|
||||
for path in raw_paths:
|
||||
if os.path.exists(path):
|
||||
real_path = os.path.normpath(os.path.realpath(path)).replace(os.sep, '/')
|
||||
path_map[real_path] = path_map.get(real_path, path.replace(os.sep, "/")) # preserve first seen
|
||||
|
||||
# Now sort and use only the deduplicated real paths
|
||||
unique_paths = sorted(path_map.values(), key=lambda p: p.lower())
|
||||
logger.info("Found LoRA roots:" + ("\n - " + "\n - ".join(unique_paths) if unique_paths else "[]"))
|
||||
|
||||
if not unique_paths:
|
||||
logger.warning("No valid loras folders found in ComfyUI configuration")
|
||||
return []
|
||||
|
||||
for original_path in unique_paths:
|
||||
real_path = os.path.normpath(os.path.realpath(original_path)).replace(os.sep, '/')
|
||||
if real_path != original_path:
|
||||
self.add_path_mapping(original_path, real_path)
|
||||
|
||||
return unique_paths
|
||||
except Exception as e:
|
||||
logger.warning(f"Error initializing LoRA paths: {e}")
|
||||
return []
|
||||
|
||||
def _init_checkpoint_paths(self) -> List[str]:
|
||||
"""Initialize and validate checkpoint paths from ComfyUI settings"""
|
||||
# Get checkpoint paths from folder_paths
|
||||
checkpoint_paths = folder_paths.get_folder_paths("checkpoints")
|
||||
diffusion_paths = folder_paths.get_folder_paths("diffusers")
|
||||
unet_paths = folder_paths.get_folder_paths("unet")
|
||||
|
||||
# Combine all checkpoint-related paths
|
||||
all_paths = checkpoint_paths + diffusion_paths + unet_paths
|
||||
|
||||
# Filter and normalize paths
|
||||
paths = sorted(set(path.replace(os.sep, "/")
|
||||
for path in all_paths
|
||||
if os.path.exists(path)), key=lambda p: p.lower())
|
||||
|
||||
print("Found checkpoint roots:", paths)
|
||||
|
||||
if not paths:
|
||||
logger.warning("No valid checkpoint folders found in ComfyUI configuration")
|
||||
try:
|
||||
# Get checkpoint paths from folder_paths
|
||||
checkpoint_paths = folder_paths.get_folder_paths("checkpoints")
|
||||
diffusion_paths = folder_paths.get_folder_paths("diffusers")
|
||||
unet_paths = folder_paths.get_folder_paths("unet")
|
||||
|
||||
# Combine all checkpoint-related paths
|
||||
all_paths = checkpoint_paths + diffusion_paths + unet_paths
|
||||
|
||||
# Filter and normalize paths
|
||||
paths = sorted(set(path.replace(os.sep, "/")
|
||||
for path in all_paths
|
||||
if os.path.exists(path)), key=lambda p: p.lower())
|
||||
|
||||
logger.info("Found checkpoint roots:" + ("\n - " + "\n - ".join(paths) if paths else "[]"))
|
||||
|
||||
if not paths:
|
||||
logger.warning("No valid checkpoint folders found in ComfyUI configuration")
|
||||
return []
|
||||
|
||||
# 初始化路径映射,与 LoRA 路径处理方式相同
|
||||
for path in paths:
|
||||
real_path = os.path.normpath(os.path.realpath(path)).replace(os.sep, '/')
|
||||
if real_path != path:
|
||||
self.add_path_mapping(path, real_path)
|
||||
|
||||
return paths
|
||||
except Exception as e:
|
||||
logger.warning(f"Error initializing checkpoint paths: {e}")
|
||||
return []
|
||||
|
||||
# 初始化路径映射,与 LoRA 路径处理方式相同
|
||||
for path in paths:
|
||||
real_path = os.path.normpath(os.path.realpath(path)).replace(os.sep, '/')
|
||||
if real_path != path:
|
||||
self.add_path_mapping(path, real_path)
|
||||
|
||||
return paths
|
||||
|
||||
def get_preview_static_url(self, preview_path: str) -> str:
|
||||
"""Convert local preview path to static URL"""
|
||||
|
||||
@@ -5,11 +5,20 @@ from .routes.lora_routes import LoraRoutes
|
||||
from .routes.api_routes import ApiRoutes
|
||||
from .routes.recipe_routes import RecipeRoutes
|
||||
from .routes.checkpoints_routes import CheckpointsRoutes
|
||||
from .routes.update_routes import UpdateRoutes
|
||||
from .routes.misc_routes import MiscRoutes
|
||||
from .routes.example_images_routes import ExampleImagesRoutes
|
||||
from .services.service_registry import ServiceRegistry
|
||||
from .services.settings_manager import settings
|
||||
import logging
|
||||
import sys
|
||||
import os
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# Check if we're in standalone mode
|
||||
STANDALONE_MODE = 'nodes' not in sys.modules
|
||||
|
||||
class LoraManager:
|
||||
"""Main entry point for LoRA Manager plugin"""
|
||||
|
||||
@@ -18,8 +27,18 @@ class LoraManager:
|
||||
"""Initialize and register all routes"""
|
||||
app = PromptServer.instance.app
|
||||
|
||||
# Configure aiohttp access logger to be less verbose
|
||||
logging.getLogger('aiohttp.access').setLevel(logging.WARNING)
|
||||
|
||||
added_targets = set() # Track already added target paths
|
||||
|
||||
# Add static route for example images if the path exists in settings
|
||||
example_images_path = settings.get('example_images_path')
|
||||
logger.info(f"Example images path: {example_images_path}")
|
||||
if example_images_path and os.path.exists(example_images_path):
|
||||
app.router.add_static('/example_images_static', example_images_path)
|
||||
logger.info(f"Added static route for example images: /example_images_static -> {example_images_path}")
|
||||
|
||||
# Add static routes for each lora root
|
||||
for idx, root in enumerate(config.loras_roots, start=1):
|
||||
preview_path = f'/loras_static/root{idx}/preview'
|
||||
@@ -92,6 +111,9 @@ class LoraManager:
|
||||
checkpoints_routes.setup_routes(app)
|
||||
ApiRoutes.setup_routes(app)
|
||||
RecipeRoutes.setup_routes(app)
|
||||
UpdateRoutes.setup_routes(app)
|
||||
MiscRoutes.setup_routes(app) # Register miscellaneous routes
|
||||
ExampleImagesRoutes.setup_routes(app) # Register example images routes
|
||||
|
||||
# Schedule service initialization
|
||||
app.on_startup.append(lambda app: cls._initialize_services())
|
||||
@@ -104,7 +126,8 @@ class LoraManager:
|
||||
async def _initialize_services(cls):
|
||||
"""Initialize all services using the ServiceRegistry"""
|
||||
try:
|
||||
logger.info("LoRA Manager: Initializing services via ServiceRegistry")
|
||||
# Ensure aiohttp access logger is configured with reduced verbosity
|
||||
logging.getLogger('aiohttp.access').setLevel(logging.WARNING)
|
||||
|
||||
# Initialize CivitaiClient first to ensure it's ready for other services
|
||||
civitai_client = await ServiceRegistry.get_civitai_client()
|
||||
@@ -115,12 +138,12 @@ class LoraManager:
|
||||
|
||||
# Start monitors
|
||||
lora_monitor.start()
|
||||
logger.info("Lora monitor started")
|
||||
logger.debug("Lora monitor started")
|
||||
|
||||
# Make sure checkpoint monitor has paths before starting
|
||||
await checkpoint_monitor.initialize_paths()
|
||||
checkpoint_monitor.start()
|
||||
logger.info("Checkpoint monitor started")
|
||||
logger.debug("Checkpoint monitor started")
|
||||
|
||||
# Register DownloadManager with ServiceRegistry
|
||||
download_manager = await ServiceRegistry.get_download_manager()
|
||||
@@ -135,6 +158,12 @@ class LoraManager:
|
||||
# Initialize recipe scanner if needed
|
||||
recipe_scanner = await ServiceRegistry.get_recipe_scanner()
|
||||
|
||||
# Initialize metadata collector if not in standalone mode
|
||||
if not STANDALONE_MODE:
|
||||
from .metadata_collector import init as init_metadata
|
||||
init_metadata()
|
||||
logger.debug("Metadata collector initialized")
|
||||
|
||||
# Create low-priority initialization tasks
|
||||
asyncio.create_task(lora_scanner.initialize_in_background(), name='lora_cache_init')
|
||||
asyncio.create_task(checkpoint_scanner.initialize_in_background(), name='checkpoint_cache_init')
|
||||
|
||||
32
py/metadata_collector/__init__.py
Normal file
32
py/metadata_collector/__init__.py
Normal file
@@ -0,0 +1,32 @@
|
||||
import os
|
||||
import importlib
|
||||
import sys
|
||||
|
||||
# Check if running in standalone mode
|
||||
standalone_mode = 'nodes' not in sys.modules
|
||||
|
||||
if not standalone_mode:
|
||||
from .metadata_hook import MetadataHook
|
||||
from .metadata_registry import MetadataRegistry
|
||||
|
||||
def init():
|
||||
# Install hooks to collect metadata during execution
|
||||
MetadataHook.install()
|
||||
|
||||
# Initialize registry
|
||||
registry = MetadataRegistry()
|
||||
|
||||
print("ComfyUI Metadata Collector initialized")
|
||||
|
||||
def get_metadata(prompt_id=None):
|
||||
"""Helper function to get metadata from the registry"""
|
||||
registry = MetadataRegistry()
|
||||
return registry.get_metadata(prompt_id)
|
||||
else:
|
||||
# Standalone mode - provide dummy implementations
|
||||
def init():
|
||||
print("ComfyUI Metadata Collector disabled in standalone mode")
|
||||
|
||||
def get_metadata(prompt_id=None):
|
||||
"""Dummy implementation for standalone mode"""
|
||||
return {}
|
||||
13
py/metadata_collector/constants.py
Normal file
13
py/metadata_collector/constants.py
Normal file
@@ -0,0 +1,13 @@
|
||||
"""Constants used by the metadata collector"""
|
||||
|
||||
# Metadata categories
|
||||
MODELS = "models"
|
||||
PROMPTS = "prompts"
|
||||
SAMPLING = "sampling"
|
||||
LORAS = "loras"
|
||||
SIZE = "size"
|
||||
IMAGES = "images"
|
||||
IS_SAMPLER = "is_sampler" # New constant to mark sampler nodes
|
||||
|
||||
# Complete list of categories to track
|
||||
METADATA_CATEGORIES = [MODELS, PROMPTS, SAMPLING, LORAS, SIZE, IMAGES]
|
||||
123
py/metadata_collector/metadata_hook.py
Normal file
123
py/metadata_collector/metadata_hook.py
Normal file
@@ -0,0 +1,123 @@
|
||||
import sys
|
||||
import inspect
|
||||
from .metadata_registry import MetadataRegistry
|
||||
|
||||
class MetadataHook:
|
||||
"""Install hooks for metadata collection"""
|
||||
|
||||
@staticmethod
|
||||
def install():
|
||||
"""Install hooks to collect metadata during execution"""
|
||||
try:
|
||||
# Import ComfyUI's execution module
|
||||
execution = None
|
||||
try:
|
||||
# Try direct import first
|
||||
import execution # type: ignore
|
||||
except ImportError:
|
||||
# Try to locate from system modules
|
||||
for module_name in sys.modules:
|
||||
if module_name.endswith('.execution'):
|
||||
execution = sys.modules[module_name]
|
||||
break
|
||||
|
||||
# If we can't find the execution module, we can't install hooks
|
||||
if execution is None:
|
||||
print("Could not locate ComfyUI execution module, metadata collection disabled")
|
||||
return
|
||||
|
||||
# Store the original _map_node_over_list function
|
||||
original_map_node_over_list = execution._map_node_over_list
|
||||
|
||||
# Define the wrapped _map_node_over_list function
|
||||
def map_node_over_list_with_metadata(obj, input_data_all, func, allow_interrupt=False, execution_block_cb=None, pre_execute_cb=None):
|
||||
# Only collect metadata when calling the main function of nodes
|
||||
if func == obj.FUNCTION and hasattr(obj, '__class__'):
|
||||
try:
|
||||
# Get the current prompt_id from the registry
|
||||
registry = MetadataRegistry()
|
||||
prompt_id = registry.current_prompt_id
|
||||
|
||||
if prompt_id is not None:
|
||||
# Get node class type
|
||||
class_type = obj.__class__.__name__
|
||||
|
||||
# Unique ID might be available through the obj if it has a unique_id field
|
||||
node_id = getattr(obj, 'unique_id', None)
|
||||
if node_id is None and pre_execute_cb:
|
||||
# Try to extract node_id through reflection on GraphBuilder.set_default_prefix
|
||||
frame = inspect.currentframe()
|
||||
while frame:
|
||||
if 'unique_id' in frame.f_locals:
|
||||
node_id = frame.f_locals['unique_id']
|
||||
break
|
||||
frame = frame.f_back
|
||||
|
||||
# Record inputs before execution
|
||||
if node_id is not None:
|
||||
registry.record_node_execution(node_id, class_type, input_data_all, None)
|
||||
except Exception as e:
|
||||
print(f"Error collecting metadata (pre-execution): {str(e)}")
|
||||
|
||||
# Execute the original function
|
||||
results = original_map_node_over_list(obj, input_data_all, func, allow_interrupt, execution_block_cb, pre_execute_cb)
|
||||
|
||||
# After execution, collect outputs for relevant nodes
|
||||
if func == obj.FUNCTION and hasattr(obj, '__class__'):
|
||||
try:
|
||||
# Get the current prompt_id from the registry
|
||||
registry = MetadataRegistry()
|
||||
prompt_id = registry.current_prompt_id
|
||||
|
||||
if prompt_id is not None:
|
||||
# Get node class type
|
||||
class_type = obj.__class__.__name__
|
||||
|
||||
# Unique ID might be available through the obj if it has a unique_id field
|
||||
node_id = getattr(obj, 'unique_id', None)
|
||||
if node_id is None and pre_execute_cb:
|
||||
# Try to extract node_id through reflection
|
||||
frame = inspect.currentframe()
|
||||
while frame:
|
||||
if 'unique_id' in frame.f_locals:
|
||||
node_id = frame.f_locals['unique_id']
|
||||
break
|
||||
frame = frame.f_back
|
||||
|
||||
# Record outputs after execution
|
||||
if node_id is not None:
|
||||
registry.update_node_execution(node_id, class_type, results)
|
||||
except Exception as e:
|
||||
print(f"Error collecting metadata (post-execution): {str(e)}")
|
||||
|
||||
return results
|
||||
|
||||
# Also hook the execute function to track the current prompt_id
|
||||
original_execute = execution.execute
|
||||
|
||||
def execute_with_prompt_tracking(*args, **kwargs):
|
||||
if len(args) >= 7: # Check if we have enough arguments
|
||||
server, prompt, caches, node_id, extra_data, executed, prompt_id = args[:7]
|
||||
registry = MetadataRegistry()
|
||||
|
||||
# Start collection if this is a new prompt
|
||||
if not registry.current_prompt_id or registry.current_prompt_id != prompt_id:
|
||||
registry.start_collection(prompt_id)
|
||||
|
||||
# Store the dynprompt reference for node lookups
|
||||
if hasattr(prompt, 'original_prompt'):
|
||||
registry.set_current_prompt(prompt)
|
||||
|
||||
# Execute the original function
|
||||
return original_execute(*args, **kwargs)
|
||||
|
||||
# Replace the functions
|
||||
execution._map_node_over_list = map_node_over_list_with_metadata
|
||||
execution.execute = execute_with_prompt_tracking
|
||||
# Make map_node_over_list public to avoid it being hidden by hooks
|
||||
execution.map_node_over_list = original_map_node_over_list
|
||||
|
||||
print("Metadata collection hooks installed for runtime values")
|
||||
|
||||
except Exception as e:
|
||||
print(f"Error installing metadata hooks: {str(e)}")
|
||||
379
py/metadata_collector/metadata_processor.py
Normal file
379
py/metadata_collector/metadata_processor.py
Normal file
@@ -0,0 +1,379 @@
|
||||
import json
|
||||
import sys
|
||||
|
||||
# Check if running in standalone mode
|
||||
standalone_mode = 'nodes' not in sys.modules
|
||||
|
||||
from .constants import MODELS, PROMPTS, SAMPLING, LORAS, SIZE, IS_SAMPLER
|
||||
|
||||
class MetadataProcessor:
|
||||
"""Process and format collected metadata"""
|
||||
|
||||
@staticmethod
|
||||
def find_primary_sampler(metadata, downstream_id=None):
|
||||
"""
|
||||
Find the primary KSampler node that executed before the given downstream node
|
||||
|
||||
Parameters:
|
||||
- metadata: The workflow metadata
|
||||
- downstream_id: Optional ID of a downstream node to help identify the specific primary sampler
|
||||
"""
|
||||
# If we have a downstream_id and execution_order, use it to narrow down potential samplers
|
||||
if downstream_id and "execution_order" in metadata:
|
||||
execution_order = metadata["execution_order"]
|
||||
|
||||
# Find the index of the downstream node in the execution order
|
||||
if downstream_id in execution_order:
|
||||
downstream_index = execution_order.index(downstream_id)
|
||||
|
||||
# Extract all sampler nodes that executed before the downstream node
|
||||
candidate_samplers = {}
|
||||
for i in range(downstream_index):
|
||||
node_id = execution_order[i]
|
||||
# Use IS_SAMPLER flag to identify true sampler nodes
|
||||
if node_id in metadata.get(SAMPLING, {}) and metadata[SAMPLING][node_id].get(IS_SAMPLER, False):
|
||||
candidate_samplers[node_id] = metadata[SAMPLING][node_id]
|
||||
|
||||
# If we found candidate samplers, apply primary sampler logic to these candidates only
|
||||
if candidate_samplers:
|
||||
# Collect potential primary samplers based on different criteria
|
||||
custom_advanced_samplers = []
|
||||
advanced_add_noise_samplers = []
|
||||
high_denoise_samplers = []
|
||||
max_denoise = -1
|
||||
high_denoise_id = None
|
||||
|
||||
# First, check for SamplerCustomAdvanced among candidates
|
||||
prompt = metadata.get("current_prompt")
|
||||
if prompt and prompt.original_prompt:
|
||||
for node_id in candidate_samplers:
|
||||
node_info = prompt.original_prompt.get(node_id, {})
|
||||
if node_info.get("class_type") == "SamplerCustomAdvanced":
|
||||
custom_advanced_samplers.append(node_id)
|
||||
|
||||
# Next, check for KSamplerAdvanced with add_noise="enable" among candidates
|
||||
for node_id, sampler_info in candidate_samplers.items():
|
||||
parameters = sampler_info.get("parameters", {})
|
||||
add_noise = parameters.get("add_noise")
|
||||
if add_noise == "enable":
|
||||
advanced_add_noise_samplers.append(node_id)
|
||||
|
||||
# Find the sampler with highest denoise value among candidates
|
||||
for node_id, sampler_info in candidate_samplers.items():
|
||||
parameters = sampler_info.get("parameters", {})
|
||||
denoise = parameters.get("denoise")
|
||||
if denoise is not None and denoise > max_denoise:
|
||||
max_denoise = denoise
|
||||
high_denoise_id = node_id
|
||||
|
||||
if high_denoise_id:
|
||||
high_denoise_samplers.append(high_denoise_id)
|
||||
|
||||
# Combine all potential primary samplers
|
||||
potential_samplers = custom_advanced_samplers + advanced_add_noise_samplers + high_denoise_samplers
|
||||
|
||||
# Find the most recent potential primary sampler (closest to downstream node)
|
||||
for i in range(downstream_index - 1, -1, -1):
|
||||
node_id = execution_order[i]
|
||||
if node_id in potential_samplers:
|
||||
return node_id, candidate_samplers[node_id]
|
||||
|
||||
# If no potential sampler found from our criteria, return the most recent sampler
|
||||
if candidate_samplers:
|
||||
for i in range(downstream_index - 1, -1, -1):
|
||||
node_id = execution_order[i]
|
||||
if node_id in candidate_samplers:
|
||||
return node_id, candidate_samplers[node_id]
|
||||
|
||||
# If no downstream_id provided or no suitable sampler found, fall back to original logic
|
||||
primary_sampler = None
|
||||
primary_sampler_id = None
|
||||
max_denoise = -1
|
||||
|
||||
# First, check for SamplerCustomAdvanced
|
||||
prompt = metadata.get("current_prompt")
|
||||
if prompt and prompt.original_prompt:
|
||||
for node_id, node_info in prompt.original_prompt.items():
|
||||
if node_info.get("class_type") == "SamplerCustomAdvanced":
|
||||
# Check if the node is in SAMPLING and has IS_SAMPLER flag
|
||||
if node_id in metadata.get(SAMPLING, {}) and metadata[SAMPLING][node_id].get(IS_SAMPLER, False):
|
||||
return node_id, metadata[SAMPLING][node_id]
|
||||
|
||||
# Next, check for KSamplerAdvanced with add_noise="enable" using IS_SAMPLER flag
|
||||
for node_id, sampler_info in metadata.get(SAMPLING, {}).items():
|
||||
# Skip if not marked as a sampler
|
||||
if not sampler_info.get(IS_SAMPLER, False):
|
||||
continue
|
||||
|
||||
parameters = sampler_info.get("parameters", {})
|
||||
add_noise = parameters.get("add_noise")
|
||||
if add_noise == "enable":
|
||||
primary_sampler = sampler_info
|
||||
primary_sampler_id = node_id
|
||||
break
|
||||
|
||||
# If no specialized sampler found, find the sampler with highest denoise value
|
||||
if primary_sampler is None:
|
||||
for node_id, sampler_info in metadata.get(SAMPLING, {}).items():
|
||||
# Skip if not marked as a sampler
|
||||
if not sampler_info.get(IS_SAMPLER, False):
|
||||
continue
|
||||
|
||||
parameters = sampler_info.get("parameters", {})
|
||||
denoise = parameters.get("denoise")
|
||||
if denoise is not None and denoise > max_denoise:
|
||||
max_denoise = denoise
|
||||
primary_sampler = sampler_info
|
||||
primary_sampler_id = node_id
|
||||
|
||||
return primary_sampler_id, primary_sampler
|
||||
|
||||
@staticmethod
|
||||
def trace_node_input(prompt, node_id, input_name, target_class=None, max_depth=10):
|
||||
"""
|
||||
Trace an input connection from a node to find the source node
|
||||
|
||||
Parameters:
|
||||
- prompt: The prompt object containing node connections
|
||||
- node_id: ID of the starting node
|
||||
- input_name: Name of the input to trace
|
||||
- target_class: Optional class name to search for (e.g., "CLIPTextEncode")
|
||||
- max_depth: Maximum depth to follow the node chain to prevent infinite loops
|
||||
|
||||
Returns:
|
||||
- node_id of the found node, or None if not found
|
||||
"""
|
||||
if not prompt or not prompt.original_prompt or node_id not in prompt.original_prompt:
|
||||
return None
|
||||
|
||||
# For depth tracking
|
||||
current_depth = 0
|
||||
|
||||
current_node_id = node_id
|
||||
current_input = input_name
|
||||
|
||||
# If we're just tracing to origin (no target_class), keep track of the last valid node
|
||||
last_valid_node = None
|
||||
|
||||
while current_depth < max_depth:
|
||||
if current_node_id not in prompt.original_prompt:
|
||||
return last_valid_node if not target_class else None
|
||||
|
||||
node_inputs = prompt.original_prompt[current_node_id].get("inputs", {})
|
||||
if current_input not in node_inputs:
|
||||
# We've reached a node without the specified input - this is our origin node
|
||||
# if we're not looking for a specific target_class
|
||||
return current_node_id if not target_class else None
|
||||
|
||||
input_value = node_inputs[current_input]
|
||||
# Input connections are formatted as [node_id, output_index]
|
||||
if isinstance(input_value, list) and len(input_value) >= 2:
|
||||
found_node_id = input_value[0] # Connected node_id
|
||||
|
||||
# If we're looking for a specific node class
|
||||
if target_class and prompt.original_prompt[found_node_id].get("class_type") == target_class:
|
||||
return found_node_id
|
||||
|
||||
# If we're not looking for a specific class, update the last valid node
|
||||
if not target_class:
|
||||
last_valid_node = found_node_id
|
||||
|
||||
# Continue tracing through intermediate nodes
|
||||
current_node_id = found_node_id
|
||||
# For most conditioning nodes, the input we want to follow is named "conditioning"
|
||||
if "conditioning" in prompt.original_prompt[current_node_id].get("inputs", {}):
|
||||
current_input = "conditioning"
|
||||
else:
|
||||
# If there's no "conditioning" input, return the current node
|
||||
# if we're not looking for a specific target_class
|
||||
return found_node_id if not target_class else None
|
||||
else:
|
||||
# We've reached a node with no further connections
|
||||
return last_valid_node if not target_class else None
|
||||
|
||||
current_depth += 1
|
||||
|
||||
# If we've reached max depth without finding target_class
|
||||
return last_valid_node if not target_class else None
|
||||
|
||||
@staticmethod
|
||||
def find_primary_checkpoint(metadata):
|
||||
"""Find the primary checkpoint model in the workflow"""
|
||||
if not metadata.get(MODELS):
|
||||
return None
|
||||
|
||||
# In most workflows, there's only one checkpoint, so we can just take the first one
|
||||
for node_id, model_info in metadata.get(MODELS, {}).items():
|
||||
if model_info.get("type") == "checkpoint":
|
||||
return model_info.get("name")
|
||||
|
||||
return None
|
||||
|
||||
@staticmethod
|
||||
def extract_generation_params(metadata, id=None):
|
||||
"""
|
||||
Extract generation parameters from metadata using node relationships
|
||||
|
||||
Parameters:
|
||||
- metadata: The workflow metadata
|
||||
- id: Optional ID of a downstream node to help identify the specific primary sampler
|
||||
"""
|
||||
params = {
|
||||
"prompt": "",
|
||||
"negative_prompt": "",
|
||||
"seed": None,
|
||||
"steps": None,
|
||||
"cfg_scale": None,
|
||||
"guidance": None, # Add guidance parameter
|
||||
"sampler": None,
|
||||
"scheduler": None,
|
||||
"checkpoint": None,
|
||||
"loras": "",
|
||||
"size": None,
|
||||
"clip_skip": None
|
||||
}
|
||||
|
||||
# Get the prompt object for node relationship tracing
|
||||
prompt = metadata.get("current_prompt")
|
||||
|
||||
# Find the primary KSampler node
|
||||
primary_sampler_id, primary_sampler = MetadataProcessor.find_primary_sampler(metadata, id)
|
||||
|
||||
# Directly get checkpoint from metadata instead of tracing
|
||||
checkpoint = MetadataProcessor.find_primary_checkpoint(metadata)
|
||||
if checkpoint:
|
||||
params["checkpoint"] = checkpoint
|
||||
|
||||
# Check if guidance parameter exists in any sampling node
|
||||
for node_id, sampler_info in metadata.get(SAMPLING, {}).items():
|
||||
parameters = sampler_info.get("parameters", {})
|
||||
if "guidance" in parameters and parameters["guidance"] is not None:
|
||||
params["guidance"] = parameters["guidance"]
|
||||
break
|
||||
|
||||
if primary_sampler:
|
||||
# Extract sampling parameters
|
||||
sampling_params = primary_sampler.get("parameters", {})
|
||||
# Handle both seed and noise_seed
|
||||
params["seed"] = sampling_params.get("seed") if sampling_params.get("seed") is not None else sampling_params.get("noise_seed")
|
||||
params["steps"] = sampling_params.get("steps")
|
||||
params["cfg_scale"] = sampling_params.get("cfg")
|
||||
params["sampler"] = sampling_params.get("sampler_name")
|
||||
params["scheduler"] = sampling_params.get("scheduler")
|
||||
|
||||
# Trace connections from the primary sampler
|
||||
if prompt and primary_sampler_id:
|
||||
# Check if this is a SamplerCustomAdvanced node
|
||||
is_custom_advanced = False
|
||||
if prompt.original_prompt and primary_sampler_id in prompt.original_prompt:
|
||||
is_custom_advanced = prompt.original_prompt[primary_sampler_id].get("class_type") == "SamplerCustomAdvanced"
|
||||
|
||||
if is_custom_advanced:
|
||||
# For SamplerCustomAdvanced, trace specific inputs
|
||||
|
||||
# 1. Trace sigmas input to find BasicScheduler
|
||||
scheduler_node_id = MetadataProcessor.trace_node_input(prompt, primary_sampler_id, "sigmas", "BasicScheduler", max_depth=5)
|
||||
if scheduler_node_id and scheduler_node_id in metadata.get(SAMPLING, {}):
|
||||
scheduler_params = metadata[SAMPLING][scheduler_node_id].get("parameters", {})
|
||||
params["steps"] = scheduler_params.get("steps")
|
||||
params["scheduler"] = scheduler_params.get("scheduler")
|
||||
|
||||
# 2. Trace sampler input to find KSamplerSelect
|
||||
sampler_node_id = MetadataProcessor.trace_node_input(prompt, primary_sampler_id, "sampler", "KSamplerSelect", max_depth=5)
|
||||
if sampler_node_id and sampler_node_id in metadata.get(SAMPLING, {}):
|
||||
sampler_params = metadata[SAMPLING][sampler_node_id].get("parameters", {})
|
||||
params["sampler"] = sampler_params.get("sampler_name")
|
||||
|
||||
# 3. Trace guider input for CFGGuider and CLIPTextEncode
|
||||
guider_node_id = MetadataProcessor.trace_node_input(prompt, primary_sampler_id, "guider", max_depth=5)
|
||||
if guider_node_id and guider_node_id in prompt.original_prompt:
|
||||
# Check if the guider node is a CFGGuider
|
||||
if prompt.original_prompt[guider_node_id].get("class_type") == "CFGGuider":
|
||||
# Extract cfg value from the CFGGuider
|
||||
if guider_node_id in metadata.get(SAMPLING, {}):
|
||||
cfg_params = metadata[SAMPLING][guider_node_id].get("parameters", {})
|
||||
params["cfg_scale"] = cfg_params.get("cfg")
|
||||
|
||||
# Find CLIPTextEncode for positive prompt
|
||||
positive_node_id = MetadataProcessor.trace_node_input(prompt, guider_node_id, "positive", "CLIPTextEncode", max_depth=10)
|
||||
if positive_node_id and positive_node_id in metadata.get(PROMPTS, {}):
|
||||
params["prompt"] = metadata[PROMPTS][positive_node_id].get("text", "")
|
||||
|
||||
# Find CLIPTextEncode for negative prompt
|
||||
negative_node_id = MetadataProcessor.trace_node_input(prompt, guider_node_id, "negative", "CLIPTextEncode", max_depth=10)
|
||||
if negative_node_id and negative_node_id in metadata.get(PROMPTS, {}):
|
||||
params["negative_prompt"] = metadata[PROMPTS][negative_node_id].get("text", "")
|
||||
else:
|
||||
positive_node_id = MetadataProcessor.trace_node_input(prompt, guider_node_id, "conditioning", max_depth=10)
|
||||
if positive_node_id and positive_node_id in metadata.get(PROMPTS, {}):
|
||||
params["prompt"] = metadata[PROMPTS][positive_node_id].get("text", "")
|
||||
|
||||
else:
|
||||
# Original tracing for standard samplers
|
||||
# Trace positive prompt - look specifically for CLIPTextEncode
|
||||
positive_node_id = MetadataProcessor.trace_node_input(prompt, primary_sampler_id, "positive", max_depth=10)
|
||||
if positive_node_id and positive_node_id in metadata.get(PROMPTS, {}):
|
||||
params["prompt"] = metadata[PROMPTS][positive_node_id].get("text", "")
|
||||
else:
|
||||
# If CLIPTextEncode is not found, try to find CLIPTextEncodeFlux
|
||||
positive_flux_node_id = MetadataProcessor.trace_node_input(prompt, primary_sampler_id, "positive", "CLIPTextEncodeFlux", max_depth=10)
|
||||
if positive_flux_node_id and positive_flux_node_id in metadata.get(PROMPTS, {}):
|
||||
params["prompt"] = metadata[PROMPTS][positive_flux_node_id].get("text", "")
|
||||
|
||||
# Trace negative prompt - look specifically for CLIPTextEncode
|
||||
negative_node_id = MetadataProcessor.trace_node_input(prompt, primary_sampler_id, "negative", max_depth=10)
|
||||
if negative_node_id and negative_node_id in metadata.get(PROMPTS, {}):
|
||||
params["negative_prompt"] = metadata[PROMPTS][negative_node_id].get("text", "")
|
||||
|
||||
# Size extraction is same for all sampler types
|
||||
# Check if the sampler itself has size information (from latent_image)
|
||||
if primary_sampler_id in metadata.get(SIZE, {}):
|
||||
width = metadata[SIZE][primary_sampler_id].get("width")
|
||||
height = metadata[SIZE][primary_sampler_id].get("height")
|
||||
if width and height:
|
||||
params["size"] = f"{width}x{height}"
|
||||
|
||||
# Extract LoRAs using the standardized format
|
||||
lora_parts = []
|
||||
for node_id, lora_info in metadata.get(LORAS, {}).items():
|
||||
# Access the lora_list from the standardized format
|
||||
lora_list = lora_info.get("lora_list", [])
|
||||
for lora in lora_list:
|
||||
name = lora.get("name", "unknown")
|
||||
strength = lora.get("strength", 1.0)
|
||||
lora_parts.append(f"<lora:{name}:{strength}>")
|
||||
|
||||
params["loras"] = " ".join(lora_parts)
|
||||
|
||||
# Set default clip_skip value
|
||||
params["clip_skip"] = "1" # Common default
|
||||
|
||||
return params
|
||||
|
||||
@staticmethod
|
||||
def to_dict(metadata, id=None):
|
||||
"""
|
||||
Convert extracted metadata to the ComfyUI output.json format
|
||||
|
||||
Parameters:
|
||||
- metadata: The workflow metadata
|
||||
- id: Optional ID of a downstream node to help identify the specific primary sampler
|
||||
"""
|
||||
if standalone_mode:
|
||||
# Return empty dictionary in standalone mode
|
||||
return {}
|
||||
|
||||
params = MetadataProcessor.extract_generation_params(metadata, id)
|
||||
|
||||
# Convert all values to strings to match output.json format
|
||||
for key in params:
|
||||
if params[key] is not None:
|
||||
params[key] = str(params[key])
|
||||
|
||||
return params
|
||||
|
||||
@staticmethod
|
||||
def to_json(metadata, id=None):
|
||||
"""Convert metadata to JSON string"""
|
||||
params = MetadataProcessor.to_dict(metadata, id)
|
||||
return json.dumps(params, indent=4)
|
||||
275
py/metadata_collector/metadata_registry.py
Normal file
275
py/metadata_collector/metadata_registry.py
Normal file
@@ -0,0 +1,275 @@
|
||||
import time
|
||||
from nodes import NODE_CLASS_MAPPINGS
|
||||
from .node_extractors import NODE_EXTRACTORS, GenericNodeExtractor
|
||||
from .constants import METADATA_CATEGORIES, IMAGES
|
||||
|
||||
class MetadataRegistry:
|
||||
"""A singleton registry to store and retrieve workflow metadata"""
|
||||
_instance = None
|
||||
|
||||
def __new__(cls):
|
||||
if cls._instance is None:
|
||||
cls._instance = super().__new__(cls)
|
||||
cls._instance._reset()
|
||||
return cls._instance
|
||||
|
||||
def _reset(self):
|
||||
self.current_prompt_id = None
|
||||
self.current_prompt = None
|
||||
self.metadata = {}
|
||||
self.prompt_metadata = {}
|
||||
self.executed_nodes = set()
|
||||
|
||||
# Node-level cache for metadata
|
||||
self.node_cache = {}
|
||||
|
||||
# Limit the number of stored prompts
|
||||
self.max_prompt_history = 3
|
||||
|
||||
# Categories we want to track and retrieve from cache
|
||||
self.metadata_categories = METADATA_CATEGORIES
|
||||
|
||||
def _clean_old_prompts(self):
|
||||
"""Clean up old prompt metadata, keeping only recent ones"""
|
||||
if len(self.prompt_metadata) <= self.max_prompt_history:
|
||||
return
|
||||
|
||||
# Sort all prompt_ids by timestamp
|
||||
sorted_prompts = sorted(
|
||||
self.prompt_metadata.keys(),
|
||||
key=lambda pid: self.prompt_metadata[pid].get("timestamp", 0)
|
||||
)
|
||||
|
||||
# Remove oldest records
|
||||
prompts_to_remove = sorted_prompts[:len(sorted_prompts) - self.max_prompt_history]
|
||||
for pid in prompts_to_remove:
|
||||
del self.prompt_metadata[pid]
|
||||
|
||||
def start_collection(self, prompt_id):
|
||||
"""Begin metadata collection for a new prompt"""
|
||||
self.current_prompt_id = prompt_id
|
||||
self.executed_nodes = set()
|
||||
self.prompt_metadata[prompt_id] = {
|
||||
category: {} for category in METADATA_CATEGORIES
|
||||
}
|
||||
# Add additional metadata fields
|
||||
self.prompt_metadata[prompt_id].update({
|
||||
"execution_order": [],
|
||||
"current_prompt": None, # Will store the prompt object
|
||||
"timestamp": time.time()
|
||||
})
|
||||
|
||||
# Clean up old prompt data
|
||||
self._clean_old_prompts()
|
||||
|
||||
def set_current_prompt(self, prompt):
|
||||
"""Set the current prompt object reference"""
|
||||
self.current_prompt = prompt
|
||||
if self.current_prompt_id and self.current_prompt_id in self.prompt_metadata:
|
||||
# Store the prompt in the metadata for later relationship tracing
|
||||
self.prompt_metadata[self.current_prompt_id]["current_prompt"] = prompt
|
||||
|
||||
def get_metadata(self, prompt_id=None):
|
||||
"""Get collected metadata for a prompt"""
|
||||
key = prompt_id if prompt_id is not None else self.current_prompt_id
|
||||
if key not in self.prompt_metadata:
|
||||
return {}
|
||||
|
||||
metadata = self.prompt_metadata[key]
|
||||
|
||||
# If we have a current prompt object, check for non-executed nodes
|
||||
prompt_obj = metadata.get("current_prompt")
|
||||
if prompt_obj and hasattr(prompt_obj, "original_prompt"):
|
||||
original_prompt = prompt_obj.original_prompt
|
||||
|
||||
# Fill in missing metadata from cache for nodes that weren't executed
|
||||
self._fill_missing_metadata(key, original_prompt)
|
||||
|
||||
return self.prompt_metadata.get(key, {})
|
||||
|
||||
def _fill_missing_metadata(self, prompt_id, original_prompt):
|
||||
"""Fill missing metadata from cache for non-executed nodes"""
|
||||
if not original_prompt:
|
||||
return
|
||||
|
||||
executed_nodes = self.executed_nodes
|
||||
metadata = self.prompt_metadata[prompt_id]
|
||||
|
||||
# Iterate through nodes in the original prompt
|
||||
for node_id, node_data in original_prompt.items():
|
||||
# Skip if already executed in this run
|
||||
if node_id in executed_nodes:
|
||||
continue
|
||||
|
||||
# Get the node type from the prompt (this is the key in NODE_CLASS_MAPPINGS)
|
||||
prompt_class_type = node_data.get("class_type")
|
||||
if not prompt_class_type:
|
||||
continue
|
||||
|
||||
# Convert to actual class name (which is what we use in our cache)
|
||||
class_type = prompt_class_type
|
||||
if prompt_class_type in NODE_CLASS_MAPPINGS:
|
||||
class_obj = NODE_CLASS_MAPPINGS[prompt_class_type]
|
||||
class_type = class_obj.__name__
|
||||
|
||||
# Create cache key using the actual class name
|
||||
cache_key = f"{node_id}:{class_type}"
|
||||
|
||||
# Check if this node type is relevant for metadata collection
|
||||
if class_type in NODE_EXTRACTORS:
|
||||
# Check if we have cached metadata for this node
|
||||
if cache_key in self.node_cache:
|
||||
cached_data = self.node_cache[cache_key]
|
||||
|
||||
# Apply cached metadata to the current metadata
|
||||
for category in self.metadata_categories:
|
||||
if category in cached_data and node_id in cached_data[category]:
|
||||
if node_id not in metadata[category]:
|
||||
metadata[category][node_id] = cached_data[category][node_id]
|
||||
|
||||
def record_node_execution(self, node_id, class_type, inputs, outputs):
|
||||
"""Record information about a node's execution"""
|
||||
if not self.current_prompt_id:
|
||||
return
|
||||
|
||||
# Add to execution order and mark as executed
|
||||
if node_id not in self.executed_nodes:
|
||||
self.executed_nodes.add(node_id)
|
||||
self.prompt_metadata[self.current_prompt_id]["execution_order"].append(node_id)
|
||||
|
||||
# Process inputs to simplify working with them
|
||||
processed_inputs = {}
|
||||
for input_name, input_values in inputs.items():
|
||||
if isinstance(input_values, list) and len(input_values) > 0:
|
||||
# For single values, just use the first one (most common case)
|
||||
processed_inputs[input_name] = input_values[0]
|
||||
else:
|
||||
processed_inputs[input_name] = input_values
|
||||
|
||||
# Extract node-specific metadata
|
||||
extractor = NODE_EXTRACTORS.get(class_type, GenericNodeExtractor)
|
||||
extractor.extract(
|
||||
node_id,
|
||||
processed_inputs,
|
||||
outputs,
|
||||
self.prompt_metadata[self.current_prompt_id]
|
||||
)
|
||||
|
||||
# Cache this node's metadata
|
||||
self._cache_node_metadata(node_id, class_type)
|
||||
|
||||
def update_node_execution(self, node_id, class_type, outputs):
|
||||
"""Update node metadata with output information"""
|
||||
if not self.current_prompt_id:
|
||||
return
|
||||
|
||||
# Process outputs to make them more usable
|
||||
processed_outputs = outputs
|
||||
|
||||
# Use the same extractor to update with outputs
|
||||
extractor = NODE_EXTRACTORS.get(class_type, GenericNodeExtractor)
|
||||
if hasattr(extractor, 'update'):
|
||||
extractor.update(
|
||||
node_id,
|
||||
processed_outputs,
|
||||
self.prompt_metadata[self.current_prompt_id]
|
||||
)
|
||||
|
||||
# Update the cached metadata for this node
|
||||
self._cache_node_metadata(node_id, class_type)
|
||||
|
||||
def _cache_node_metadata(self, node_id, class_type):
|
||||
"""Cache the metadata for a specific node"""
|
||||
if not self.current_prompt_id or not node_id or not class_type:
|
||||
return
|
||||
|
||||
# Create a cache key combining node_id and class_type
|
||||
cache_key = f"{node_id}:{class_type}"
|
||||
|
||||
# Create a shallow copy of the node's metadata
|
||||
node_metadata = {}
|
||||
current_metadata = self.prompt_metadata[self.current_prompt_id]
|
||||
|
||||
for category in self.metadata_categories:
|
||||
if category in current_metadata and node_id in current_metadata[category]:
|
||||
if category not in node_metadata:
|
||||
node_metadata[category] = {}
|
||||
node_metadata[category][node_id] = current_metadata[category][node_id]
|
||||
|
||||
# Save to cache if we have any metadata for this node
|
||||
if any(node_metadata.values()):
|
||||
self.node_cache[cache_key] = node_metadata
|
||||
|
||||
def clear_unused_cache(self):
|
||||
"""Clean up node_cache entries that are no longer in use"""
|
||||
# Collect all node_ids currently in prompt_metadata
|
||||
active_node_ids = set()
|
||||
for prompt_data in self.prompt_metadata.values():
|
||||
for category in self.metadata_categories:
|
||||
if category in prompt_data:
|
||||
active_node_ids.update(prompt_data[category].keys())
|
||||
|
||||
# Find cache keys that are no longer needed
|
||||
keys_to_remove = []
|
||||
for cache_key in self.node_cache:
|
||||
node_id = cache_key.split(':')[0]
|
||||
if node_id not in active_node_ids:
|
||||
keys_to_remove.append(cache_key)
|
||||
|
||||
# Remove cache entries that are no longer needed
|
||||
for key in keys_to_remove:
|
||||
del self.node_cache[key]
|
||||
|
||||
def clear_metadata(self, prompt_id=None):
|
||||
"""Clear metadata for a specific prompt or reset all data"""
|
||||
if prompt_id is not None:
|
||||
if prompt_id in self.prompt_metadata:
|
||||
del self.prompt_metadata[prompt_id]
|
||||
# Clean up cache after removing prompt
|
||||
self.clear_unused_cache()
|
||||
else:
|
||||
# Reset all data
|
||||
self._reset()
|
||||
|
||||
def get_first_decoded_image(self, prompt_id=None):
|
||||
"""Get the first decoded image result"""
|
||||
key = prompt_id if prompt_id is not None else self.current_prompt_id
|
||||
if key not in self.prompt_metadata:
|
||||
return None
|
||||
|
||||
metadata = self.prompt_metadata[key]
|
||||
if IMAGES in metadata and "first_decode" in metadata[IMAGES]:
|
||||
image_data = metadata[IMAGES]["first_decode"]["image"]
|
||||
|
||||
# If it's an image batch or tuple, handle various formats
|
||||
if isinstance(image_data, (list, tuple)) and len(image_data) > 0:
|
||||
# Return first element of list/tuple
|
||||
return image_data[0]
|
||||
|
||||
# If it's a tensor, return as is for processing in the route handler
|
||||
return image_data
|
||||
|
||||
# If no image is found in the current metadata, try to find it in the cache
|
||||
# This handles the case where VAEDecode was cached by ComfyUI and not executed
|
||||
prompt_obj = metadata.get("current_prompt")
|
||||
if prompt_obj and hasattr(prompt_obj, "original_prompt"):
|
||||
original_prompt = prompt_obj.original_prompt
|
||||
for node_id, node_data in original_prompt.items():
|
||||
class_type = node_data.get("class_type")
|
||||
if class_type and class_type in NODE_CLASS_MAPPINGS:
|
||||
class_obj = NODE_CLASS_MAPPINGS[class_type]
|
||||
class_name = class_obj.__name__
|
||||
# Check if this is a VAEDecode node
|
||||
if class_name == "VAEDecode":
|
||||
# Try to find this node in the cache
|
||||
cache_key = f"{node_id}:{class_name}"
|
||||
if cache_key in self.node_cache:
|
||||
cached_data = self.node_cache[cache_key]
|
||||
if IMAGES in cached_data and node_id in cached_data[IMAGES]:
|
||||
image_data = cached_data[IMAGES][node_id]["image"]
|
||||
# Handle different image formats
|
||||
if isinstance(image_data, (list, tuple)) and len(image_data) > 0:
|
||||
return image_data[0]
|
||||
return image_data
|
||||
|
||||
return None
|
||||
423
py/metadata_collector/node_extractors.py
Normal file
423
py/metadata_collector/node_extractors.py
Normal file
@@ -0,0 +1,423 @@
|
||||
import os
|
||||
|
||||
from .constants import MODELS, PROMPTS, SAMPLING, LORAS, SIZE, IMAGES, IS_SAMPLER
|
||||
|
||||
|
||||
class NodeMetadataExtractor:
|
||||
"""Base class for node-specific metadata extraction"""
|
||||
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
"""Extract metadata from node inputs/outputs"""
|
||||
pass
|
||||
|
||||
@staticmethod
|
||||
def update(node_id, outputs, metadata):
|
||||
"""Update metadata with node outputs after execution"""
|
||||
pass
|
||||
|
||||
class GenericNodeExtractor(NodeMetadataExtractor):
|
||||
"""Default extractor for nodes without specific handling"""
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
pass
|
||||
|
||||
class CheckpointLoaderExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs or "ckpt_name" not in inputs:
|
||||
return
|
||||
|
||||
model_name = inputs.get("ckpt_name")
|
||||
if model_name:
|
||||
metadata[MODELS][node_id] = {
|
||||
"name": model_name,
|
||||
"type": "checkpoint",
|
||||
"node_id": node_id
|
||||
}
|
||||
|
||||
class CLIPTextEncodeExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs or "text" not in inputs:
|
||||
return
|
||||
|
||||
text = inputs.get("text", "")
|
||||
metadata[PROMPTS][node_id] = {
|
||||
"text": text,
|
||||
"node_id": node_id
|
||||
}
|
||||
|
||||
class SamplerExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs:
|
||||
return
|
||||
|
||||
sampling_params = {}
|
||||
for key in ["seed", "steps", "cfg", "sampler_name", "scheduler", "denoise"]:
|
||||
if key in inputs:
|
||||
sampling_params[key] = inputs[key]
|
||||
|
||||
metadata[SAMPLING][node_id] = {
|
||||
"parameters": sampling_params,
|
||||
"node_id": node_id,
|
||||
IS_SAMPLER: True # Add sampler flag
|
||||
}
|
||||
|
||||
# Extract latent image dimensions if available
|
||||
if "latent_image" in inputs and inputs["latent_image"] is not None:
|
||||
latent = inputs["latent_image"]
|
||||
if isinstance(latent, dict) and "samples" in latent:
|
||||
# Extract dimensions from latent tensor
|
||||
samples = latent["samples"]
|
||||
if hasattr(samples, "shape") and len(samples.shape) >= 3:
|
||||
# Correct shape interpretation: [batch_size, channels, height/8, width/8]
|
||||
# Multiply by 8 to get actual pixel dimensions
|
||||
height = int(samples.shape[2] * 8)
|
||||
width = int(samples.shape[3] * 8)
|
||||
|
||||
if SIZE not in metadata:
|
||||
metadata[SIZE] = {}
|
||||
|
||||
metadata[SIZE][node_id] = {
|
||||
"width": width,
|
||||
"height": height,
|
||||
"node_id": node_id
|
||||
}
|
||||
|
||||
class KSamplerAdvancedExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs:
|
||||
return
|
||||
|
||||
sampling_params = {}
|
||||
for key in ["noise_seed", "steps", "cfg", "sampler_name", "scheduler", "add_noise"]:
|
||||
if key in inputs:
|
||||
sampling_params[key] = inputs[key]
|
||||
|
||||
metadata[SAMPLING][node_id] = {
|
||||
"parameters": sampling_params,
|
||||
"node_id": node_id,
|
||||
IS_SAMPLER: True # Add sampler flag
|
||||
}
|
||||
|
||||
# Extract latent image dimensions if available
|
||||
if "latent_image" in inputs and inputs["latent_image"] is not None:
|
||||
latent = inputs["latent_image"]
|
||||
if isinstance(latent, dict) and "samples" in latent:
|
||||
# Extract dimensions from latent tensor
|
||||
samples = latent["samples"]
|
||||
if hasattr(samples, "shape") and len(samples.shape) >= 3:
|
||||
# Correct shape interpretation: [batch_size, channels, height/8, width/8]
|
||||
# Multiply by 8 to get actual pixel dimensions
|
||||
height = int(samples.shape[2] * 8)
|
||||
width = int(samples.shape[3] * 8)
|
||||
|
||||
if SIZE not in metadata:
|
||||
metadata[SIZE] = {}
|
||||
|
||||
metadata[SIZE][node_id] = {
|
||||
"width": width,
|
||||
"height": height,
|
||||
"node_id": node_id
|
||||
}
|
||||
|
||||
class LoraLoaderExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs or "lora_name" not in inputs:
|
||||
return
|
||||
|
||||
lora_name = inputs.get("lora_name")
|
||||
# Extract base filename without extension from path
|
||||
lora_name = os.path.splitext(os.path.basename(lora_name))[0]
|
||||
strength_model = round(float(inputs.get("strength_model", 1.0)), 2)
|
||||
|
||||
# Use the standardized format with lora_list
|
||||
metadata[LORAS][node_id] = {
|
||||
"lora_list": [
|
||||
{
|
||||
"name": lora_name,
|
||||
"strength": strength_model
|
||||
}
|
||||
],
|
||||
"node_id": node_id
|
||||
}
|
||||
|
||||
class ImageSizeExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs:
|
||||
return
|
||||
|
||||
width = inputs.get("width", 512)
|
||||
height = inputs.get("height", 512)
|
||||
|
||||
if SIZE not in metadata:
|
||||
metadata[SIZE] = {}
|
||||
|
||||
metadata[SIZE][node_id] = {
|
||||
"width": width,
|
||||
"height": height,
|
||||
"node_id": node_id
|
||||
}
|
||||
|
||||
class LoraLoaderManagerExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs:
|
||||
return
|
||||
|
||||
active_loras = []
|
||||
|
||||
# Process lora_stack if available
|
||||
if "lora_stack" in inputs:
|
||||
lora_stack = inputs.get("lora_stack", [])
|
||||
for lora_path, model_strength, clip_strength in lora_stack:
|
||||
# Extract lora name from path (following the format in lora_loader.py)
|
||||
lora_name = os.path.splitext(os.path.basename(lora_path))[0]
|
||||
active_loras.append({
|
||||
"name": lora_name,
|
||||
"strength": model_strength
|
||||
})
|
||||
|
||||
# Process loras from inputs
|
||||
if "loras" in inputs:
|
||||
loras_data = inputs.get("loras", [])
|
||||
|
||||
# Handle new format: {'loras': {'__value__': [...]}}
|
||||
if isinstance(loras_data, dict) and '__value__' in loras_data:
|
||||
loras_list = loras_data['__value__']
|
||||
# Handle old format: {'loras': [...]}
|
||||
elif isinstance(loras_data, list):
|
||||
loras_list = loras_data
|
||||
else:
|
||||
loras_list = []
|
||||
|
||||
# Filter for active loras
|
||||
for lora in loras_list:
|
||||
if isinstance(lora, dict) and lora.get("active", True) and not lora.get("_isDummy", False):
|
||||
active_loras.append({
|
||||
"name": lora.get("name", ""),
|
||||
"strength": float(lora.get("strength", 1.0))
|
||||
})
|
||||
|
||||
if active_loras:
|
||||
metadata[LORAS][node_id] = {
|
||||
"lora_list": active_loras,
|
||||
"node_id": node_id
|
||||
}
|
||||
|
||||
class FluxGuidanceExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs or "guidance" not in inputs:
|
||||
return
|
||||
|
||||
guidance_value = inputs.get("guidance")
|
||||
|
||||
# Store the guidance value in SAMPLING category
|
||||
if node_id not in metadata[SAMPLING]:
|
||||
metadata[SAMPLING][node_id] = {"parameters": {}, "node_id": node_id}
|
||||
|
||||
metadata[SAMPLING][node_id]["parameters"]["guidance"] = guidance_value
|
||||
|
||||
class UNETLoaderExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs or "unet_name" not in inputs:
|
||||
return
|
||||
|
||||
model_name = inputs.get("unet_name")
|
||||
if model_name:
|
||||
metadata[MODELS][node_id] = {
|
||||
"name": model_name,
|
||||
"type": "checkpoint",
|
||||
"node_id": node_id
|
||||
}
|
||||
|
||||
class VAEDecodeExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
pass
|
||||
|
||||
@staticmethod
|
||||
def update(node_id, outputs, metadata):
|
||||
# Ensure IMAGES category exists
|
||||
if IMAGES not in metadata:
|
||||
metadata[IMAGES] = {}
|
||||
|
||||
# Save image data under node ID index to be captured by caching mechanism
|
||||
metadata[IMAGES][node_id] = {
|
||||
"node_id": node_id,
|
||||
"image": outputs
|
||||
}
|
||||
|
||||
# Only set first_decode if it hasn't been recorded yet
|
||||
if "first_decode" not in metadata[IMAGES]:
|
||||
metadata[IMAGES]["first_decode"] = metadata[IMAGES][node_id]
|
||||
|
||||
class KSamplerSelectExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs or "sampler_name" not in inputs:
|
||||
return
|
||||
|
||||
sampling_params = {}
|
||||
if "sampler_name" in inputs:
|
||||
sampling_params["sampler_name"] = inputs["sampler_name"]
|
||||
|
||||
metadata[SAMPLING][node_id] = {
|
||||
"parameters": sampling_params,
|
||||
"node_id": node_id,
|
||||
IS_SAMPLER: False # Mark as non-primary sampler
|
||||
}
|
||||
|
||||
class BasicSchedulerExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs:
|
||||
return
|
||||
|
||||
sampling_params = {}
|
||||
for key in ["scheduler", "steps", "denoise"]:
|
||||
if key in inputs:
|
||||
sampling_params[key] = inputs[key]
|
||||
|
||||
metadata[SAMPLING][node_id] = {
|
||||
"parameters": sampling_params,
|
||||
"node_id": node_id,
|
||||
IS_SAMPLER: False # Mark as non-primary sampler
|
||||
}
|
||||
|
||||
class SamplerCustomAdvancedExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs:
|
||||
return
|
||||
|
||||
sampling_params = {}
|
||||
|
||||
# Handle noise.seed as seed
|
||||
if "noise" in inputs and inputs["noise"] is not None and hasattr(inputs["noise"], "seed"):
|
||||
noise = inputs["noise"]
|
||||
sampling_params["seed"] = noise.seed
|
||||
|
||||
metadata[SAMPLING][node_id] = {
|
||||
"parameters": sampling_params,
|
||||
"node_id": node_id,
|
||||
IS_SAMPLER: True # Add sampler flag
|
||||
}
|
||||
|
||||
# Extract latent image dimensions if available
|
||||
if "latent_image" in inputs and inputs["latent_image"] is not None:
|
||||
latent = inputs["latent_image"]
|
||||
if isinstance(latent, dict) and "samples" in latent:
|
||||
# Extract dimensions from latent tensor
|
||||
samples = latent["samples"]
|
||||
if hasattr(samples, "shape") and len(samples.shape) >= 3:
|
||||
# Correct shape interpretation: [batch_size, channels, height/8, width/8]
|
||||
# Multiply by 8 to get actual pixel dimensions
|
||||
height = int(samples.shape[2] * 8)
|
||||
width = int(samples.shape[3] * 8)
|
||||
|
||||
if SIZE not in metadata:
|
||||
metadata[SIZE] = {}
|
||||
|
||||
metadata[SIZE][node_id] = {
|
||||
"width": width,
|
||||
"height": height,
|
||||
"node_id": node_id
|
||||
}
|
||||
|
||||
import json
|
||||
|
||||
class CLIPTextEncodeFluxExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs or "clip_l" not in inputs or "t5xxl" not in inputs:
|
||||
return
|
||||
|
||||
clip_l_text = inputs.get("clip_l", "")
|
||||
t5xxl_text = inputs.get("t5xxl", "")
|
||||
|
||||
# If both are empty, use empty string
|
||||
if not clip_l_text and not t5xxl_text:
|
||||
combined_text = ""
|
||||
# If one is empty, use the non-empty one
|
||||
elif not clip_l_text:
|
||||
combined_text = t5xxl_text
|
||||
elif not t5xxl_text:
|
||||
combined_text = clip_l_text
|
||||
# If both have content, use JSON format
|
||||
else:
|
||||
combined_text = json.dumps({
|
||||
"T5": t5xxl_text,
|
||||
"CLIP-L": clip_l_text
|
||||
})
|
||||
|
||||
metadata[PROMPTS][node_id] = {
|
||||
"text": combined_text,
|
||||
"node_id": node_id
|
||||
}
|
||||
|
||||
# Extract guidance value if available
|
||||
if "guidance" in inputs:
|
||||
guidance_value = inputs.get("guidance")
|
||||
|
||||
# Store the guidance value in SAMPLING category
|
||||
if SAMPLING not in metadata:
|
||||
metadata[SAMPLING] = {}
|
||||
|
||||
if node_id not in metadata[SAMPLING]:
|
||||
metadata[SAMPLING][node_id] = {"parameters": {}, "node_id": node_id}
|
||||
|
||||
metadata[SAMPLING][node_id]["parameters"]["guidance"] = guidance_value
|
||||
|
||||
class CFGGuiderExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs or "cfg" not in inputs:
|
||||
return
|
||||
|
||||
cfg_value = inputs.get("cfg")
|
||||
|
||||
# Store the cfg value in SAMPLING category
|
||||
if SAMPLING not in metadata:
|
||||
metadata[SAMPLING] = {}
|
||||
|
||||
if node_id not in metadata[SAMPLING]:
|
||||
metadata[SAMPLING][node_id] = {"parameters": {}, "node_id": node_id}
|
||||
|
||||
metadata[SAMPLING][node_id]["parameters"]["cfg"] = cfg_value
|
||||
|
||||
# Registry of node-specific extractors
|
||||
NODE_EXTRACTORS = {
|
||||
# Sampling
|
||||
"KSampler": SamplerExtractor,
|
||||
"KSamplerAdvanced": KSamplerAdvancedExtractor,
|
||||
"SamplerCustomAdvanced": SamplerCustomAdvancedExtractor, # Updated to use dedicated extractor
|
||||
# Sampling Selectors
|
||||
"KSamplerSelect": KSamplerSelectExtractor, # Add KSamplerSelect
|
||||
"BasicScheduler": BasicSchedulerExtractor, # Add BasicScheduler
|
||||
# Loaders
|
||||
"CheckpointLoaderSimple": CheckpointLoaderExtractor,
|
||||
"UNETLoader": UNETLoaderExtractor, # Updated to use dedicated extractor
|
||||
"UnetLoaderGGUF": UNETLoaderExtractor, # Updated to use dedicated extractor
|
||||
"LoraLoader": LoraLoaderExtractor,
|
||||
"LoraManagerLoader": LoraLoaderManagerExtractor,
|
||||
# Conditioning
|
||||
"CLIPTextEncode": CLIPTextEncodeExtractor,
|
||||
"CLIPTextEncodeFlux": CLIPTextEncodeFluxExtractor, # Add CLIPTextEncodeFlux
|
||||
"WAS_Text_to_Conditioning": CLIPTextEncodeExtractor,
|
||||
# Latent
|
||||
"EmptyLatentImage": ImageSizeExtractor,
|
||||
# Flux
|
||||
"FluxGuidance": FluxGuidanceExtractor, # Add FluxGuidance
|
||||
"CFGGuider": CFGGuiderExtractor, # Add CFGGuider
|
||||
# Image
|
||||
"VAEDecode": VAEDecodeExtractor, # Added VAEDecode extractor
|
||||
# Add other nodes as needed
|
||||
}
|
||||
38
py/nodes/debug_metadata.py
Normal file
38
py/nodes/debug_metadata.py
Normal file
@@ -0,0 +1,38 @@
|
||||
import logging
|
||||
from ..metadata_collector.metadata_processor import MetadataProcessor
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class DebugMetadata:
|
||||
NAME = "Debug Metadata (LoraManager)"
|
||||
CATEGORY = "Lora Manager/utils"
|
||||
DESCRIPTION = "Debug node to verify metadata_processor functionality"
|
||||
|
||||
@classmethod
|
||||
def INPUT_TYPES(cls):
|
||||
return {
|
||||
"required": {
|
||||
"images": ("IMAGE",),
|
||||
},
|
||||
"hidden": {
|
||||
"id": "UNIQUE_ID",
|
||||
},
|
||||
}
|
||||
|
||||
RETURN_TYPES = ("STRING",)
|
||||
RETURN_NAMES = ("metadata_json",)
|
||||
FUNCTION = "process_metadata"
|
||||
|
||||
def process_metadata(self, images, id):
|
||||
try:
|
||||
# Get the current execution context's metadata
|
||||
from ..metadata_collector import get_metadata
|
||||
metadata = get_metadata()
|
||||
|
||||
# Use the MetadataProcessor to convert it to JSON string
|
||||
metadata_json = MetadataProcessor.to_json(metadata, id)
|
||||
|
||||
return (metadata_json,)
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing metadata: {e}")
|
||||
return ("{}",) # Return empty JSON object in case of error
|
||||
@@ -1,11 +1,8 @@
|
||||
import logging
|
||||
from nodes import LoraLoader
|
||||
from comfy.comfy_types import IO # type: ignore
|
||||
from ..services.lora_scanner import LoraScanner
|
||||
from ..config import config
|
||||
import asyncio
|
||||
import os
|
||||
from .utils import FlexibleOptionalInputType, any_type
|
||||
from .utils import FlexibleOptionalInputType, any_type, get_lora_info, extract_lora_name, get_loras_list
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@@ -32,48 +29,6 @@ class LoraManagerLoader:
|
||||
RETURN_TYPES = ("MODEL", "CLIP", IO.STRING, IO.STRING)
|
||||
RETURN_NAMES = ("MODEL", "CLIP", "trigger_words", "loaded_loras")
|
||||
FUNCTION = "load_loras"
|
||||
|
||||
async def get_lora_info(self, lora_name):
|
||||
"""Get the lora path and trigger words from cache"""
|
||||
scanner = await LoraScanner.get_instance()
|
||||
cache = await scanner.get_cached_data()
|
||||
|
||||
for item in cache.raw_data:
|
||||
if item.get('file_name') == lora_name:
|
||||
file_path = item.get('file_path')
|
||||
if file_path:
|
||||
for root in config.loras_roots:
|
||||
root = root.replace(os.sep, '/')
|
||||
if file_path.startswith(root):
|
||||
relative_path = os.path.relpath(file_path, root).replace(os.sep, '/')
|
||||
# Get trigger words from civitai metadata
|
||||
civitai = item.get('civitai', {})
|
||||
trigger_words = civitai.get('trainedWords', []) if civitai else []
|
||||
return relative_path, trigger_words
|
||||
return lora_name, [] # Fallback if not found
|
||||
|
||||
def extract_lora_name(self, lora_path):
|
||||
"""Extract the lora name from a lora path (e.g., 'IL\\aorunIllstrious.safetensors' -> 'aorunIllstrious')"""
|
||||
# Get the basename without extension
|
||||
basename = os.path.basename(lora_path)
|
||||
return os.path.splitext(basename)[0]
|
||||
|
||||
def _get_loras_list(self, kwargs):
|
||||
"""Helper to extract loras list from either old or new kwargs format"""
|
||||
if 'loras' not in kwargs:
|
||||
return []
|
||||
|
||||
loras_data = kwargs['loras']
|
||||
# Handle new format: {'loras': {'__value__': [...]}}
|
||||
if isinstance(loras_data, dict) and '__value__' in loras_data:
|
||||
return loras_data['__value__']
|
||||
# Handle old format: {'loras': [...]}
|
||||
elif isinstance(loras_data, list):
|
||||
return loras_data
|
||||
# Unexpected format
|
||||
else:
|
||||
logger.warning(f"Unexpected loras format: {type(loras_data)}")
|
||||
return []
|
||||
|
||||
def load_loras(self, model, text, **kwargs):
|
||||
"""Loads multiple LoRAs based on the kwargs input and lora_stack."""
|
||||
@@ -89,27 +44,38 @@ class LoraManagerLoader:
|
||||
model, clip = LoraLoader().load_lora(model, clip, lora_path, model_strength, clip_strength)
|
||||
|
||||
# Extract lora name for trigger words lookup
|
||||
lora_name = self.extract_lora_name(lora_path)
|
||||
_, trigger_words = asyncio.run(self.get_lora_info(lora_name))
|
||||
lora_name = extract_lora_name(lora_path)
|
||||
_, trigger_words = asyncio.run(get_lora_info(lora_name))
|
||||
|
||||
all_trigger_words.extend(trigger_words)
|
||||
loaded_loras.append(f"{lora_name}: {model_strength}")
|
||||
# Add clip strength to output if different from model strength
|
||||
if abs(model_strength - clip_strength) > 0.001:
|
||||
loaded_loras.append(f"{lora_name}: {model_strength},{clip_strength}")
|
||||
else:
|
||||
loaded_loras.append(f"{lora_name}: {model_strength}")
|
||||
|
||||
# Then process loras from kwargs with support for both old and new formats
|
||||
loras_list = self._get_loras_list(kwargs)
|
||||
loras_list = get_loras_list(kwargs)
|
||||
for lora in loras_list:
|
||||
if not lora.get('active', False):
|
||||
continue
|
||||
|
||||
lora_name = lora['name']
|
||||
strength = float(lora['strength'])
|
||||
model_strength = float(lora['strength'])
|
||||
# Get clip strength - use model strength as default if not specified
|
||||
clip_strength = float(lora.get('clipStrength', model_strength))
|
||||
|
||||
# Get lora path and trigger words
|
||||
lora_path, trigger_words = asyncio.run(self.get_lora_info(lora_name))
|
||||
lora_path, trigger_words = asyncio.run(get_lora_info(lora_name))
|
||||
|
||||
# Apply the LoRA using the resolved path
|
||||
model, clip = LoraLoader().load_lora(model, clip, lora_path, strength, strength)
|
||||
loaded_loras.append(f"{lora_name}: {strength}")
|
||||
# Apply the LoRA using the resolved path with separate strengths
|
||||
model, clip = LoraLoader().load_lora(model, clip, lora_path, model_strength, clip_strength)
|
||||
|
||||
# Include clip strength in output if different from model strength
|
||||
if abs(model_strength - clip_strength) > 0.001:
|
||||
loaded_loras.append(f"{lora_name}: {model_strength},{clip_strength}")
|
||||
else:
|
||||
loaded_loras.append(f"{lora_name}: {model_strength}")
|
||||
|
||||
# Add trigger words to collection
|
||||
all_trigger_words.extend(trigger_words)
|
||||
@@ -117,8 +83,23 @@ class LoraManagerLoader:
|
||||
# use ',, ' to separate trigger words for group mode
|
||||
trigger_words_text = ",, ".join(all_trigger_words) if all_trigger_words else ""
|
||||
|
||||
# Format loaded_loras as <lora:lora_name:strength> separated by spaces
|
||||
formatted_loras = " ".join([f"<lora:{name.split(':')[0].strip()}:{str(strength).strip()}>"
|
||||
for name, strength in [item.split(':') for item in loaded_loras]])
|
||||
# Format loaded_loras with support for both formats
|
||||
formatted_loras = []
|
||||
for item in loaded_loras:
|
||||
parts = item.split(":")
|
||||
lora_name = parts[0].strip()
|
||||
strength_parts = parts[1].strip().split(",")
|
||||
|
||||
if len(strength_parts) > 1:
|
||||
# Different model and clip strengths
|
||||
model_str = strength_parts[0].strip()
|
||||
clip_str = strength_parts[1].strip()
|
||||
formatted_loras.append(f"<lora:{lora_name}:{model_str}:{clip_str}>")
|
||||
else:
|
||||
# Same strength for both
|
||||
model_str = strength_parts[0].strip()
|
||||
formatted_loras.append(f"<lora:{lora_name}:{model_str}>")
|
||||
|
||||
formatted_loras_text = " ".join(formatted_loras)
|
||||
|
||||
return (model, clip, trigger_words_text, formatted_loras)
|
||||
return (model, clip, trigger_words_text, formatted_loras_text)
|
||||
@@ -3,7 +3,7 @@ from ..services.lora_scanner import LoraScanner
|
||||
from ..config import config
|
||||
import asyncio
|
||||
import os
|
||||
from .utils import FlexibleOptionalInputType, any_type
|
||||
from .utils import FlexibleOptionalInputType, any_type, get_lora_info, extract_lora_name, get_loras_list
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
@@ -29,48 +29,6 @@ class LoraStacker:
|
||||
RETURN_TYPES = ("LORA_STACK", IO.STRING, IO.STRING)
|
||||
RETURN_NAMES = ("LORA_STACK", "trigger_words", "active_loras")
|
||||
FUNCTION = "stack_loras"
|
||||
|
||||
async def get_lora_info(self, lora_name):
|
||||
"""Get the lora path and trigger words from cache"""
|
||||
scanner = await LoraScanner.get_instance()
|
||||
cache = await scanner.get_cached_data()
|
||||
|
||||
for item in cache.raw_data:
|
||||
if item.get('file_name') == lora_name:
|
||||
file_path = item.get('file_path')
|
||||
if file_path:
|
||||
for root in config.loras_roots:
|
||||
root = root.replace(os.sep, '/')
|
||||
if file_path.startswith(root):
|
||||
relative_path = os.path.relpath(file_path, root).replace(os.sep, '/')
|
||||
# Get trigger words from civitai metadata
|
||||
civitai = item.get('civitai', {})
|
||||
trigger_words = civitai.get('trainedWords', []) if civitai else []
|
||||
return relative_path, trigger_words
|
||||
return lora_name, [] # Fallback if not found
|
||||
|
||||
def extract_lora_name(self, lora_path):
|
||||
"""Extract the lora name from a lora path (e.g., 'IL\\aorunIllstrious.safetensors' -> 'aorunIllstrious')"""
|
||||
# Get the basename without extension
|
||||
basename = os.path.basename(lora_path)
|
||||
return os.path.splitext(basename)[0]
|
||||
|
||||
def _get_loras_list(self, kwargs):
|
||||
"""Helper to extract loras list from either old or new kwargs format"""
|
||||
if 'loras' not in kwargs:
|
||||
return []
|
||||
|
||||
loras_data = kwargs['loras']
|
||||
# Handle new format: {'loras': {'__value__': [...]}}
|
||||
if isinstance(loras_data, dict) and '__value__' in loras_data:
|
||||
return loras_data['__value__']
|
||||
# Handle old format: {'loras': [...]}
|
||||
elif isinstance(loras_data, list):
|
||||
return loras_data
|
||||
# Unexpected format
|
||||
else:
|
||||
logger.warning(f"Unexpected loras format: {type(loras_data)}")
|
||||
return []
|
||||
|
||||
def stack_loras(self, text, **kwargs):
|
||||
"""Stacks multiple LoRAs based on the kwargs input without loading them."""
|
||||
@@ -80,39 +38,49 @@ class LoraStacker:
|
||||
|
||||
# Process existing lora_stack if available
|
||||
lora_stack = kwargs.get('lora_stack', None)
|
||||
if lora_stack:
|
||||
if (lora_stack):
|
||||
stack.extend(lora_stack)
|
||||
# Get trigger words from existing stack entries
|
||||
for lora_path, _, _ in lora_stack:
|
||||
lora_name = self.extract_lora_name(lora_path)
|
||||
_, trigger_words = asyncio.run(self.get_lora_info(lora_name))
|
||||
lora_name = extract_lora_name(lora_path)
|
||||
_, trigger_words = asyncio.run(get_lora_info(lora_name))
|
||||
all_trigger_words.extend(trigger_words)
|
||||
|
||||
# Process loras from kwargs with support for both old and new formats
|
||||
loras_list = self._get_loras_list(kwargs)
|
||||
loras_list = get_loras_list(kwargs)
|
||||
for lora in loras_list:
|
||||
if not lora.get('active', False):
|
||||
continue
|
||||
|
||||
lora_name = lora['name']
|
||||
model_strength = float(lora['strength'])
|
||||
clip_strength = model_strength # Using same strength for both as in the original loader
|
||||
# Get clip strength - use model strength as default if not specified
|
||||
clip_strength = float(lora.get('clipStrength', model_strength))
|
||||
|
||||
# Get lora path and trigger words
|
||||
lora_path, trigger_words = asyncio.run(self.get_lora_info(lora_name))
|
||||
lora_path, trigger_words = asyncio.run(get_lora_info(lora_name))
|
||||
|
||||
# Add to stack without loading
|
||||
# replace '/' with os.sep to avoid different OS path format
|
||||
stack.append((lora_path.replace('/', os.sep), model_strength, clip_strength))
|
||||
active_loras.append((lora_name, model_strength))
|
||||
active_loras.append((lora_name, model_strength, clip_strength))
|
||||
|
||||
# Add trigger words to collection
|
||||
all_trigger_words.extend(trigger_words)
|
||||
|
||||
# use ',, ' to separate trigger words for group mode
|
||||
trigger_words_text = ",, ".join(all_trigger_words) if all_trigger_words else ""
|
||||
# Format active_loras as <lora:lora_name:strength> separated by spaces
|
||||
active_loras_text = " ".join([f"<lora:{name}:{str(strength).strip()}>"
|
||||
for name, strength in active_loras])
|
||||
|
||||
# Format active_loras with support for both formats
|
||||
formatted_loras = []
|
||||
for name, model_strength, clip_strength in active_loras:
|
||||
if abs(model_strength - clip_strength) > 0.001:
|
||||
# Different model and clip strengths
|
||||
formatted_loras.append(f"<lora:{name}:{str(model_strength).strip()}:{str(clip_strength).strip()}>")
|
||||
else:
|
||||
# Same strength for both
|
||||
formatted_loras.append(f"<lora:{name}:{str(model_strength).strip()}>")
|
||||
|
||||
active_loras_text = " ".join(formatted_loras)
|
||||
|
||||
return (stack, trigger_words_text, active_loras_text)
|
||||
|
||||
@@ -5,10 +5,11 @@ import re
|
||||
import numpy as np
|
||||
import folder_paths # type: ignore
|
||||
from ..services.lora_scanner import LoraScanner
|
||||
from ..workflow.parser import WorkflowParser
|
||||
from ..services.checkpoint_scanner import CheckpointScanner
|
||||
from ..metadata_collector.metadata_processor import MetadataProcessor
|
||||
from ..metadata_collector import get_metadata
|
||||
from PIL import Image, PngImagePlugin
|
||||
import piexif
|
||||
from io import BytesIO
|
||||
|
||||
class SaveImage:
|
||||
NAME = "Save Image (LoraManager)"
|
||||
@@ -30,17 +31,36 @@ class SaveImage:
|
||||
return {
|
||||
"required": {
|
||||
"images": ("IMAGE",),
|
||||
"filename_prefix": ("STRING", {"default": "ComfyUI"}),
|
||||
"file_format": (["png", "jpeg", "webp"],),
|
||||
"filename_prefix": ("STRING", {
|
||||
"default": "ComfyUI",
|
||||
"tooltip": "Base filename for saved images. Supports format patterns like %seed%, %width%, %height%, %model%, etc."
|
||||
}),
|
||||
"file_format": (["png", "jpeg", "webp"], {
|
||||
"tooltip": "Image format to save as. PNG preserves quality, JPEG is smaller, WebP balances size and quality."
|
||||
}),
|
||||
},
|
||||
"optional": {
|
||||
"custom_prompt": ("STRING", {"default": "", "forceInput": True}),
|
||||
"lossless_webp": ("BOOLEAN", {"default": True}),
|
||||
"quality": ("INT", {"default": 100, "min": 1, "max": 100}),
|
||||
"embed_workflow": ("BOOLEAN", {"default": False}),
|
||||
"add_counter_to_filename": ("BOOLEAN", {"default": True}),
|
||||
"lossless_webp": ("BOOLEAN", {
|
||||
"default": False,
|
||||
"tooltip": "When enabled, saves WebP images with lossless compression. Results in larger files but no quality loss."
|
||||
}),
|
||||
"quality": ("INT", {
|
||||
"default": 100,
|
||||
"min": 1,
|
||||
"max": 100,
|
||||
"tooltip": "Compression quality for JPEG and lossy WebP formats (1-100). Higher values mean better quality but larger files."
|
||||
}),
|
||||
"embed_workflow": ("BOOLEAN", {
|
||||
"default": False,
|
||||
"tooltip": "Embeds the complete workflow data into the image metadata. Only works with PNG and WebP formats."
|
||||
}),
|
||||
"add_counter_to_filename": ("BOOLEAN", {
|
||||
"default": True,
|
||||
"tooltip": "Adds an incremental counter to filenames to prevent overwriting previous images."
|
||||
}),
|
||||
},
|
||||
"hidden": {
|
||||
"id": "UNIQUE_ID",
|
||||
"prompt": "PROMPT",
|
||||
"extra_pnginfo": "EXTRA_PNGINFO",
|
||||
},
|
||||
@@ -54,28 +74,61 @@ class SaveImage:
|
||||
async def get_lora_hash(self, lora_name):
|
||||
"""Get the lora hash from cache"""
|
||||
scanner = await LoraScanner.get_instance()
|
||||
cache = await scanner.get_cached_data()
|
||||
|
||||
# Use the new direct filename lookup method
|
||||
hash_value = scanner.get_hash_by_filename(lora_name)
|
||||
if hash_value:
|
||||
return hash_value
|
||||
|
||||
# Fallback to old method for compatibility
|
||||
cache = await scanner.get_cached_data()
|
||||
for item in cache.raw_data:
|
||||
if item.get('file_name') == lora_name:
|
||||
return item.get('sha256')
|
||||
return None
|
||||
|
||||
async def format_metadata(self, parsed_workflow, custom_prompt=None):
|
||||
async def get_checkpoint_hash(self, checkpoint_path):
|
||||
"""Get the checkpoint hash from cache"""
|
||||
scanner = await CheckpointScanner.get_instance()
|
||||
|
||||
if not checkpoint_path:
|
||||
return None
|
||||
|
||||
# Extract basename without extension
|
||||
checkpoint_name = os.path.basename(checkpoint_path)
|
||||
checkpoint_name = os.path.splitext(checkpoint_name)[0]
|
||||
|
||||
# Try direct filename lookup first
|
||||
hash_value = scanner.get_hash_by_filename(checkpoint_name)
|
||||
if hash_value:
|
||||
return hash_value
|
||||
|
||||
# Fallback to old method for compatibility
|
||||
cache = await scanner.get_cached_data()
|
||||
normalized_path = checkpoint_path.replace('\\', '/')
|
||||
|
||||
for item in cache.raw_data:
|
||||
if item.get('file_name') == checkpoint_name and item.get('file_path').endswith(normalized_path):
|
||||
return item.get('sha256')
|
||||
|
||||
return None
|
||||
|
||||
async def format_metadata(self, metadata_dict):
|
||||
"""Format metadata in the requested format similar to userComment example"""
|
||||
if not parsed_workflow:
|
||||
if not metadata_dict:
|
||||
return ""
|
||||
|
||||
# Extract the prompt and negative prompt
|
||||
prompt = parsed_workflow.get('prompt', '')
|
||||
negative_prompt = parsed_workflow.get('negative_prompt', '')
|
||||
# Helper function to only add parameter if value is not None
|
||||
def add_param_if_not_none(param_list, label, value):
|
||||
if value is not None:
|
||||
param_list.append(f"{label}: {value}")
|
||||
|
||||
# Override prompt with custom_prompt if provided
|
||||
if custom_prompt:
|
||||
prompt = custom_prompt
|
||||
# Extract the prompt and negative prompt
|
||||
prompt = metadata_dict.get('prompt', '')
|
||||
negative_prompt = metadata_dict.get('negative_prompt', '')
|
||||
|
||||
# Extract loras from the prompt if present
|
||||
loras_text = parsed_workflow.get('loras', '')
|
||||
loras_text = metadata_dict.get('loras', '')
|
||||
lora_hashes = {}
|
||||
|
||||
# If loras are found, add them on a new line after the prompt
|
||||
@@ -104,11 +157,15 @@ class SaveImage:
|
||||
params = []
|
||||
|
||||
# Add standard parameters in the correct order
|
||||
if 'steps' in parsed_workflow:
|
||||
params.append(f"Steps: {parsed_workflow.get('steps')}")
|
||||
if 'steps' in metadata_dict:
|
||||
add_param_if_not_none(params, "Steps", metadata_dict.get('steps'))
|
||||
|
||||
if 'sampler' in parsed_workflow:
|
||||
sampler = parsed_workflow.get('sampler')
|
||||
# Combine sampler and scheduler information
|
||||
sampler_name = None
|
||||
scheduler_name = None
|
||||
|
||||
if 'sampler' in metadata_dict:
|
||||
sampler = metadata_dict.get('sampler')
|
||||
# Convert ComfyUI sampler names to user-friendly names
|
||||
sampler_mapping = {
|
||||
'euler': 'Euler',
|
||||
@@ -128,10 +185,9 @@ class SaveImage:
|
||||
'ddim': 'DDIM'
|
||||
}
|
||||
sampler_name = sampler_mapping.get(sampler, sampler)
|
||||
params.append(f"Sampler: {sampler_name}")
|
||||
|
||||
if 'scheduler' in parsed_workflow:
|
||||
scheduler = parsed_workflow.get('scheduler')
|
||||
if 'scheduler' in metadata_dict:
|
||||
scheduler = metadata_dict.get('scheduler')
|
||||
scheduler_mapping = {
|
||||
'normal': 'Simple',
|
||||
'karras': 'Karras',
|
||||
@@ -140,35 +196,54 @@ class SaveImage:
|
||||
'sgm_quadratic': 'SGM Quadratic'
|
||||
}
|
||||
scheduler_name = scheduler_mapping.get(scheduler, scheduler)
|
||||
params.append(f"Schedule type: {scheduler_name}")
|
||||
|
||||
# CFG scale (cfg in parsed_workflow)
|
||||
if 'cfg_scale' in parsed_workflow:
|
||||
params.append(f"CFG scale: {parsed_workflow.get('cfg_scale')}")
|
||||
elif 'cfg' in parsed_workflow:
|
||||
params.append(f"CFG scale: {parsed_workflow.get('cfg')}")
|
||||
# Add combined sampler and scheduler information
|
||||
if sampler_name:
|
||||
if scheduler_name:
|
||||
params.append(f"Sampler: {sampler_name} {scheduler_name}")
|
||||
else:
|
||||
params.append(f"Sampler: {sampler_name}")
|
||||
|
||||
# CFG scale (Use guidance if available, otherwise fall back to cfg_scale or cfg)
|
||||
if 'guidance' in metadata_dict:
|
||||
add_param_if_not_none(params, "CFG scale", metadata_dict.get('guidance'))
|
||||
elif 'cfg_scale' in metadata_dict:
|
||||
add_param_if_not_none(params, "CFG scale", metadata_dict.get('cfg_scale'))
|
||||
elif 'cfg' in metadata_dict:
|
||||
add_param_if_not_none(params, "CFG scale", metadata_dict.get('cfg'))
|
||||
|
||||
# Seed
|
||||
if 'seed' in parsed_workflow:
|
||||
params.append(f"Seed: {parsed_workflow.get('seed')}")
|
||||
if 'seed' in metadata_dict:
|
||||
add_param_if_not_none(params, "Seed", metadata_dict.get('seed'))
|
||||
|
||||
# Size
|
||||
if 'size' in parsed_workflow:
|
||||
params.append(f"Size: {parsed_workflow.get('size')}")
|
||||
if 'size' in metadata_dict:
|
||||
add_param_if_not_none(params, "Size", metadata_dict.get('size'))
|
||||
|
||||
# Model info
|
||||
if 'checkpoint' in parsed_workflow:
|
||||
# Extract basename without path
|
||||
checkpoint = os.path.basename(parsed_workflow.get('checkpoint', ''))
|
||||
# Remove extension if present
|
||||
checkpoint = os.path.splitext(checkpoint)[0]
|
||||
params.append(f"Model: {checkpoint}")
|
||||
if 'checkpoint' in metadata_dict:
|
||||
# Ensure checkpoint is a string before processing
|
||||
checkpoint = metadata_dict.get('checkpoint')
|
||||
if checkpoint is not None:
|
||||
# Get model hash
|
||||
model_hash = await self.get_checkpoint_hash(checkpoint)
|
||||
|
||||
# Extract basename without path
|
||||
checkpoint_name = os.path.basename(checkpoint)
|
||||
# Remove extension if present
|
||||
checkpoint_name = os.path.splitext(checkpoint_name)[0]
|
||||
|
||||
# Add model hash if available
|
||||
if model_hash:
|
||||
params.append(f"Model hash: {model_hash[:10]}, Model: {checkpoint_name}")
|
||||
else:
|
||||
params.append(f"Model: {checkpoint_name}")
|
||||
|
||||
# Add LoRA hashes if available
|
||||
if lora_hashes:
|
||||
lora_hash_parts = []
|
||||
for lora_name, hash_value in lora_hashes.items():
|
||||
lora_hash_parts.append(f"{lora_name}: {hash_value}")
|
||||
lora_hash_parts.append(f"{lora_name}: {hash_value[:10]}")
|
||||
|
||||
if lora_hash_parts:
|
||||
params.append(f"Lora hashes: \"{', '.join(lora_hash_parts)}\"")
|
||||
@@ -181,9 +256,9 @@ class SaveImage:
|
||||
|
||||
# credit to nkchocoai
|
||||
# Add format_filename method to handle pattern substitution
|
||||
def format_filename(self, filename, parsed_workflow):
|
||||
def format_filename(self, filename, metadata_dict):
|
||||
"""Format filename with metadata values"""
|
||||
if not parsed_workflow:
|
||||
if not metadata_dict:
|
||||
return filename
|
||||
|
||||
result = re.findall(self.pattern_format, filename)
|
||||
@@ -191,30 +266,30 @@ class SaveImage:
|
||||
parts = segment.replace("%", "").split(":")
|
||||
key = parts[0]
|
||||
|
||||
if key == "seed" and 'seed' in parsed_workflow:
|
||||
filename = filename.replace(segment, str(parsed_workflow.get('seed', '')))
|
||||
elif key == "width" and 'size' in parsed_workflow:
|
||||
size = parsed_workflow.get('size', 'x')
|
||||
if key == "seed" and 'seed' in metadata_dict:
|
||||
filename = filename.replace(segment, str(metadata_dict.get('seed', '')))
|
||||
elif key == "width" and 'size' in metadata_dict:
|
||||
size = metadata_dict.get('size', 'x')
|
||||
w = size.split('x')[0] if isinstance(size, str) else size[0]
|
||||
filename = filename.replace(segment, str(w))
|
||||
elif key == "height" and 'size' in parsed_workflow:
|
||||
size = parsed_workflow.get('size', 'x')
|
||||
elif key == "height" and 'size' in metadata_dict:
|
||||
size = metadata_dict.get('size', 'x')
|
||||
h = size.split('x')[1] if isinstance(size, str) else size[1]
|
||||
filename = filename.replace(segment, str(h))
|
||||
elif key == "pprompt" and 'prompt' in parsed_workflow:
|
||||
prompt = parsed_workflow.get('prompt', '').replace("\n", " ")
|
||||
elif key == "pprompt" and 'prompt' in metadata_dict:
|
||||
prompt = metadata_dict.get('prompt', '').replace("\n", " ")
|
||||
if len(parts) >= 2:
|
||||
length = int(parts[1])
|
||||
prompt = prompt[:length]
|
||||
filename = filename.replace(segment, prompt.strip())
|
||||
elif key == "nprompt" and 'negative_prompt' in parsed_workflow:
|
||||
prompt = parsed_workflow.get('negative_prompt', '').replace("\n", " ")
|
||||
elif key == "nprompt" and 'negative_prompt' in metadata_dict:
|
||||
prompt = metadata_dict.get('negative_prompt', '').replace("\n", " ")
|
||||
if len(parts) >= 2:
|
||||
length = int(parts[1])
|
||||
prompt = prompt[:length]
|
||||
filename = filename.replace(segment, prompt.strip())
|
||||
elif key == "model" and 'checkpoint' in parsed_workflow:
|
||||
model = parsed_workflow.get('checkpoint', '')
|
||||
elif key == "model" and 'checkpoint' in metadata_dict:
|
||||
model = metadata_dict.get('checkpoint', '')
|
||||
model = os.path.splitext(os.path.basename(model))[0]
|
||||
if len(parts) >= 2:
|
||||
length = int(parts[1])
|
||||
@@ -224,12 +299,13 @@ class SaveImage:
|
||||
from datetime import datetime
|
||||
now = datetime.now()
|
||||
date_table = {
|
||||
"yyyy": str(now.year),
|
||||
"MM": str(now.month).zfill(2),
|
||||
"dd": str(now.day).zfill(2),
|
||||
"hh": str(now.hour).zfill(2),
|
||||
"mm": str(now.minute).zfill(2),
|
||||
"ss": str(now.second).zfill(2),
|
||||
"yyyy": f"{now.year:04d}",
|
||||
"yy": f"{now.year % 100:02d}",
|
||||
"MM": f"{now.month:02d}",
|
||||
"dd": f"{now.day:02d}",
|
||||
"hh": f"{now.hour:02d}",
|
||||
"mm": f"{now.minute:02d}",
|
||||
"ss": f"{now.second:02d}",
|
||||
}
|
||||
if len(parts) >= 2:
|
||||
date_format = parts[1]
|
||||
@@ -244,24 +320,20 @@ class SaveImage:
|
||||
|
||||
return filename
|
||||
|
||||
def save_images(self, images, filename_prefix, file_format, prompt=None, extra_pnginfo=None,
|
||||
lossless_webp=True, quality=100, embed_workflow=False, add_counter_to_filename=True,
|
||||
custom_prompt=None):
|
||||
def save_images(self, images, filename_prefix, file_format, id, prompt=None, extra_pnginfo=None,
|
||||
lossless_webp=True, quality=100, embed_workflow=False, add_counter_to_filename=True):
|
||||
"""Save images with metadata"""
|
||||
results = []
|
||||
|
||||
# Parse the workflow using the WorkflowParser
|
||||
parser = WorkflowParser()
|
||||
if prompt:
|
||||
parsed_workflow = parser.parse_workflow(prompt)
|
||||
else:
|
||||
parsed_workflow = {}
|
||||
|
||||
# Get metadata using the metadata collector
|
||||
raw_metadata = get_metadata()
|
||||
metadata_dict = MetadataProcessor.to_dict(raw_metadata, id)
|
||||
|
||||
# Get or create metadata asynchronously
|
||||
metadata = asyncio.run(self.format_metadata(parsed_workflow, custom_prompt))
|
||||
metadata = asyncio.run(self.format_metadata(metadata_dict))
|
||||
|
||||
# Process filename_prefix with pattern substitution
|
||||
filename_prefix = self.format_filename(filename_prefix, parsed_workflow)
|
||||
filename_prefix = self.format_filename(filename_prefix, metadata_dict)
|
||||
|
||||
# Get initial save path info once for the batch
|
||||
full_output_folder, filename, counter, subfolder, processed_prefix = folder_paths.get_save_image_path(
|
||||
@@ -283,13 +355,14 @@ class SaveImage:
|
||||
if add_counter_to_filename:
|
||||
# Use counter + i to ensure unique filenames for all images in batch
|
||||
current_counter = counter + i
|
||||
base_filename += f"_{current_counter:05}"
|
||||
base_filename += f"_{current_counter:05}_"
|
||||
|
||||
# Set file extension and prepare saving parameters
|
||||
if file_format == "png":
|
||||
file = base_filename + ".png"
|
||||
file_extension = ".png"
|
||||
save_kwargs = {"optimize": True, "compress_level": self.compress_level}
|
||||
# Remove "optimize": True to match built-in node behavior
|
||||
save_kwargs = {"compress_level": self.compress_level}
|
||||
pnginfo = PngImagePlugin.PngInfo()
|
||||
elif file_format == "jpeg":
|
||||
file = base_filename + ".jpg"
|
||||
@@ -298,7 +371,8 @@ class SaveImage:
|
||||
elif file_format == "webp":
|
||||
file = base_filename + ".webp"
|
||||
file_extension = ".webp"
|
||||
save_kwargs = {"quality": quality, "lossless": lossless_webp}
|
||||
# Add optimization param to control performance
|
||||
save_kwargs = {"quality": quality, "lossless": lossless_webp, "method": 0}
|
||||
|
||||
# Full save path
|
||||
file_path = os.path.join(full_output_folder, file)
|
||||
@@ -324,14 +398,23 @@ class SaveImage:
|
||||
print(f"Error adding EXIF data: {e}")
|
||||
img.save(file_path, format="JPEG", **save_kwargs)
|
||||
elif file_format == "webp":
|
||||
# For WebP, also use piexif for metadata
|
||||
if metadata:
|
||||
try:
|
||||
exif_dict = {'Exif': {piexif.ExifIFD.UserComment: b'UNICODE\0' + metadata.encode('utf-16be')}}
|
||||
exif_bytes = piexif.dump(exif_dict)
|
||||
save_kwargs["exif"] = exif_bytes
|
||||
except Exception as e:
|
||||
print(f"Error adding EXIF data: {e}")
|
||||
try:
|
||||
# For WebP, use piexif for metadata
|
||||
exif_dict = {}
|
||||
|
||||
if metadata:
|
||||
exif_dict['Exif'] = {piexif.ExifIFD.UserComment: b'UNICODE\0' + metadata.encode('utf-16be')}
|
||||
|
||||
# Add workflow if needed
|
||||
if embed_workflow and extra_pnginfo is not None:
|
||||
workflow_json = json.dumps(extra_pnginfo["workflow"])
|
||||
exif_dict['0th'] = {piexif.ImageIFD.ImageDescription: "Workflow:" + workflow_json}
|
||||
|
||||
exif_bytes = piexif.dump(exif_dict)
|
||||
save_kwargs["exif"] = exif_bytes
|
||||
except Exception as e:
|
||||
print(f"Error adding EXIF data: {e}")
|
||||
|
||||
img.save(file_path, format="WEBP", **save_kwargs)
|
||||
|
||||
results.append({
|
||||
@@ -345,9 +428,8 @@ class SaveImage:
|
||||
|
||||
return results
|
||||
|
||||
def process_image(self, images, filename_prefix="ComfyUI", file_format="png", prompt=None, extra_pnginfo=None,
|
||||
lossless_webp=True, quality=100, embed_workflow=False, add_counter_to_filename=True,
|
||||
custom_prompt=""):
|
||||
def process_image(self, images, id, filename_prefix="ComfyUI", file_format="png", prompt=None, extra_pnginfo=None,
|
||||
lossless_webp=True, quality=100, embed_workflow=False, add_counter_to_filename=True):
|
||||
"""Process and save image with metadata"""
|
||||
# Make sure the output directory exists
|
||||
os.makedirs(self.output_dir, exist_ok=True)
|
||||
@@ -363,13 +445,13 @@ class SaveImage:
|
||||
images,
|
||||
filename_prefix,
|
||||
file_format,
|
||||
id,
|
||||
prompt,
|
||||
extra_pnginfo,
|
||||
lossless_webp,
|
||||
quality,
|
||||
embed_workflow,
|
||||
add_counter_to_filename,
|
||||
custom_prompt if custom_prompt.strip() else None
|
||||
add_counter_to_filename
|
||||
)
|
||||
|
||||
return (images,)
|
||||
@@ -16,11 +16,18 @@ class TriggerWordToggle:
|
||||
def INPUT_TYPES(cls):
|
||||
return {
|
||||
"required": {
|
||||
"group_mode": ("BOOLEAN", {"default": True}),
|
||||
"group_mode": ("BOOLEAN", {
|
||||
"default": True,
|
||||
"tooltip": "When enabled, treats each group of trigger words as a single toggleable unit."
|
||||
}),
|
||||
"default_active": ("BOOLEAN", {
|
||||
"default": True,
|
||||
"tooltip": "Sets the default initial state (active or inactive) when trigger words are added."
|
||||
}),
|
||||
},
|
||||
"optional": FlexibleOptionalInputType(any_type),
|
||||
"hidden": {
|
||||
"id": "UNIQUE_ID", # 会被 ComfyUI 自动替换为唯一ID
|
||||
"id": "UNIQUE_ID",
|
||||
},
|
||||
}
|
||||
|
||||
@@ -41,16 +48,16 @@ class TriggerWordToggle:
|
||||
else:
|
||||
return data
|
||||
|
||||
def process_trigger_words(self, id, group_mode, **kwargs):
|
||||
def process_trigger_words(self, id, group_mode, default_active, **kwargs):
|
||||
# Handle both old and new formats for trigger_words
|
||||
trigger_words_data = self._get_toggle_data(kwargs, 'trigger_words')
|
||||
trigger_words = trigger_words_data if isinstance(trigger_words_data, str) else ""
|
||||
|
||||
# Send trigger words to frontend
|
||||
PromptServer.instance.send_sync("trigger_word_update", {
|
||||
"id": id,
|
||||
"message": trigger_words
|
||||
})
|
||||
# PromptServer.instance.send_sync("trigger_word_update", {
|
||||
# "id": id,
|
||||
# "message": trigger_words
|
||||
# })
|
||||
|
||||
filtered_triggers = trigger_words
|
||||
|
||||
|
||||
@@ -30,4 +30,55 @@ class FlexibleOptionalInputType(dict):
|
||||
return True
|
||||
|
||||
|
||||
any_type = AnyType("*")
|
||||
any_type = AnyType("*")
|
||||
|
||||
# Common methods extracted from lora_loader.py and lora_stacker.py
|
||||
import os
|
||||
import logging
|
||||
import asyncio
|
||||
from ..services.lora_scanner import LoraScanner
|
||||
from ..config import config
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
async def get_lora_info(lora_name):
|
||||
"""Get the lora path and trigger words from cache"""
|
||||
scanner = await LoraScanner.get_instance()
|
||||
cache = await scanner.get_cached_data()
|
||||
|
||||
for item in cache.raw_data:
|
||||
if item.get('file_name') == lora_name:
|
||||
file_path = item.get('file_path')
|
||||
if file_path:
|
||||
for root in config.loras_roots:
|
||||
root = root.replace(os.sep, '/')
|
||||
if file_path.startswith(root):
|
||||
relative_path = os.path.relpath(file_path, root).replace(os.sep, '/')
|
||||
# Get trigger words from civitai metadata
|
||||
civitai = item.get('civitai', {})
|
||||
trigger_words = civitai.get('trainedWords', []) if civitai else []
|
||||
return relative_path, trigger_words
|
||||
return lora_name, [] # Fallback if not found
|
||||
|
||||
def extract_lora_name(lora_path):
|
||||
"""Extract the lora name from a lora path (e.g., 'IL\\aorunIllstrious.safetensors' -> 'aorunIllstrious')"""
|
||||
# Get the basename without extension
|
||||
basename = os.path.basename(lora_path)
|
||||
return os.path.splitext(basename)[0]
|
||||
|
||||
def get_loras_list(kwargs):
|
||||
"""Helper to extract loras list from either old or new kwargs format"""
|
||||
if 'loras' not in kwargs:
|
||||
return []
|
||||
|
||||
loras_data = kwargs['loras']
|
||||
# Handle new format: {'loras': {'__value__': [...]}}
|
||||
if isinstance(loras_data, dict) and '__value__' in loras_data:
|
||||
return loras_data['__value__']
|
||||
# Handle old format: {'loras': [...]}
|
||||
elif isinstance(loras_data, list):
|
||||
return loras_data
|
||||
# Unexpected format
|
||||
else:
|
||||
logger.warning(f"Unexpected loras format: {type(loras_data)}")
|
||||
return []
|
||||
24
py/recipes/__init__.py
Normal file
24
py/recipes/__init__.py
Normal file
@@ -0,0 +1,24 @@
|
||||
"""Recipe metadata parser package for ComfyUI-Lora-Manager."""
|
||||
|
||||
from .base import RecipeMetadataParser
|
||||
from .factory import RecipeParserFactory
|
||||
from .constants import GEN_PARAM_KEYS, VALID_LORA_TYPES
|
||||
from .parsers import (
|
||||
RecipeFormatParser,
|
||||
ComfyMetadataParser,
|
||||
MetaFormatParser,
|
||||
AutomaticMetadataParser,
|
||||
CivitaiApiMetadataParser
|
||||
)
|
||||
|
||||
__all__ = [
|
||||
'RecipeMetadataParser',
|
||||
'RecipeParserFactory',
|
||||
'GEN_PARAM_KEYS',
|
||||
'VALID_LORA_TYPES',
|
||||
'RecipeFormatParser',
|
||||
'ComfyMetadataParser',
|
||||
'MetaFormatParser',
|
||||
'AutomaticMetadataParser',
|
||||
'CivitaiApiMetadataParser'
|
||||
]
|
||||
181
py/recipes/base.py
Normal file
181
py/recipes/base.py
Normal file
@@ -0,0 +1,181 @@
|
||||
"""Base classes for recipe parsers."""
|
||||
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
from typing import Dict, List, Any, Optional, Tuple
|
||||
from abc import ABC, abstractmethod
|
||||
from ..config import config
|
||||
from .constants import VALID_LORA_TYPES
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class RecipeMetadataParser(ABC):
|
||||
"""Interface for parsing recipe metadata from image user comments"""
|
||||
|
||||
METADATA_MARKER = None
|
||||
|
||||
@abstractmethod
|
||||
def is_metadata_matching(self, user_comment: str) -> bool:
|
||||
"""Check if the user comment matches the metadata format"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
async def parse_metadata(self, user_comment: str, recipe_scanner=None, civitai_client=None) -> Dict[str, Any]:
|
||||
"""
|
||||
Parse metadata from user comment and return structured recipe data
|
||||
|
||||
Args:
|
||||
user_comment: The EXIF UserComment string from the image
|
||||
recipe_scanner: Optional recipe scanner instance for local LoRA lookup
|
||||
civitai_client: Optional Civitai client for fetching model information
|
||||
|
||||
Returns:
|
||||
Dict containing parsed recipe data with standardized format
|
||||
"""
|
||||
pass
|
||||
|
||||
async def populate_lora_from_civitai(self, lora_entry: Dict[str, Any], civitai_info_tuple: Tuple[Dict[str, Any], Optional[str]],
|
||||
recipe_scanner=None, base_model_counts=None, hash_value=None) -> Optional[Dict[str, Any]]:
|
||||
"""
|
||||
Populate a lora entry with information from Civitai API response
|
||||
|
||||
Args:
|
||||
lora_entry: The lora entry to populate
|
||||
civitai_info_tuple: The response tuple from Civitai API (data, error_msg)
|
||||
recipe_scanner: Optional recipe scanner for local file lookup
|
||||
base_model_counts: Optional dict to track base model counts
|
||||
hash_value: Optional hash value to use if not available in civitai_info
|
||||
|
||||
Returns:
|
||||
The populated lora_entry dict if type is valid, None otherwise
|
||||
"""
|
||||
try:
|
||||
# Unpack the tuple to get the actual data
|
||||
civitai_info, error_msg = civitai_info_tuple if isinstance(civitai_info_tuple, tuple) else (civitai_info_tuple, None)
|
||||
|
||||
if not civitai_info or civitai_info.get("error") == "Model not found":
|
||||
# Model not found or deleted
|
||||
lora_entry['isDeleted'] = True
|
||||
lora_entry['thumbnailUrl'] = '/loras_static/images/no-preview.png'
|
||||
return lora_entry
|
||||
|
||||
# Get model type and validate
|
||||
model_type = civitai_info.get('model', {}).get('type', '').lower()
|
||||
lora_entry['type'] = model_type
|
||||
if model_type not in VALID_LORA_TYPES:
|
||||
logger.debug(f"Skipping non-LoRA model type: {model_type}")
|
||||
return None
|
||||
|
||||
# Check if this is an early access lora
|
||||
if civitai_info.get('earlyAccessEndsAt'):
|
||||
# Convert earlyAccessEndsAt to a human-readable date
|
||||
early_access_date = civitai_info.get('earlyAccessEndsAt', '')
|
||||
lora_entry['isEarlyAccess'] = True
|
||||
lora_entry['earlyAccessEndsAt'] = early_access_date
|
||||
|
||||
# Update model name if available
|
||||
if 'model' in civitai_info and 'name' in civitai_info['model']:
|
||||
lora_entry['name'] = civitai_info['model']['name']
|
||||
|
||||
# Update version if available
|
||||
if 'name' in civitai_info:
|
||||
lora_entry['version'] = civitai_info.get('name', '')
|
||||
|
||||
# Get thumbnail URL from first image
|
||||
if 'images' in civitai_info and civitai_info['images']:
|
||||
lora_entry['thumbnailUrl'] = civitai_info['images'][0].get('url', '')
|
||||
|
||||
# Get base model
|
||||
current_base_model = civitai_info.get('baseModel', '')
|
||||
lora_entry['baseModel'] = current_base_model
|
||||
|
||||
# Update base model counts if tracking them
|
||||
if base_model_counts is not None and current_base_model:
|
||||
base_model_counts[current_base_model] = base_model_counts.get(current_base_model, 0) + 1
|
||||
|
||||
# Get download URL
|
||||
lora_entry['downloadUrl'] = civitai_info.get('downloadUrl', '')
|
||||
|
||||
# Process file information if available
|
||||
if 'files' in civitai_info:
|
||||
# Find the primary model file (type="Model" and primary=true) in the files list
|
||||
model_file = next((file for file in civitai_info.get('files', [])
|
||||
if file.get('type') == 'Model' and file.get('primary') == True), None)
|
||||
|
||||
if model_file:
|
||||
# Get size
|
||||
lora_entry['size'] = model_file.get('sizeKB', 0) * 1024
|
||||
|
||||
# Get SHA256 hash
|
||||
sha256 = model_file.get('hashes', {}).get('SHA256', hash_value)
|
||||
if sha256:
|
||||
lora_entry['hash'] = sha256.lower()
|
||||
|
||||
# Check if exists locally
|
||||
if recipe_scanner and lora_entry['hash']:
|
||||
lora_scanner = recipe_scanner._lora_scanner
|
||||
exists_locally = lora_scanner.has_lora_hash(lora_entry['hash'])
|
||||
if exists_locally:
|
||||
try:
|
||||
local_path = lora_scanner.get_lora_path_by_hash(lora_entry['hash'])
|
||||
lora_entry['existsLocally'] = True
|
||||
lora_entry['localPath'] = local_path
|
||||
lora_entry['file_name'] = os.path.splitext(os.path.basename(local_path))[0]
|
||||
|
||||
# Get thumbnail from local preview if available
|
||||
lora_cache = await lora_scanner.get_cached_data()
|
||||
lora_item = next((item for item in lora_cache.raw_data
|
||||
if item['sha256'].lower() == lora_entry['hash'].lower()), None)
|
||||
if lora_item and 'preview_url' in lora_item:
|
||||
lora_entry['thumbnailUrl'] = config.get_preview_static_url(lora_item['preview_url'])
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting local lora path: {e}")
|
||||
else:
|
||||
# For missing LoRAs, get file_name from model_file.name
|
||||
file_name = model_file.get('name', '')
|
||||
lora_entry['file_name'] = os.path.splitext(file_name)[0] if file_name else ''
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error populating lora from Civitai info: {e}")
|
||||
|
||||
return lora_entry
|
||||
|
||||
async def populate_checkpoint_from_civitai(self, checkpoint: Dict[str, Any], civitai_info: Dict[str, Any]) -> Dict[str, Any]:
|
||||
"""
|
||||
Populate checkpoint information from Civitai API response
|
||||
|
||||
Args:
|
||||
checkpoint: The checkpoint entry to populate
|
||||
civitai_info: The response from Civitai API
|
||||
|
||||
Returns:
|
||||
The populated checkpoint dict
|
||||
"""
|
||||
try:
|
||||
if civitai_info and civitai_info.get("error") != "Model not found":
|
||||
# Update model name if available
|
||||
if 'model' in civitai_info and 'name' in civitai_info['model']:
|
||||
checkpoint['name'] = civitai_info['model']['name']
|
||||
|
||||
# Update version if available
|
||||
if 'name' in civitai_info:
|
||||
checkpoint['version'] = civitai_info.get('name', '')
|
||||
|
||||
# Get thumbnail URL from first image
|
||||
if 'images' in civitai_info and civitai_info['images']:
|
||||
checkpoint['thumbnailUrl'] = civitai_info['images'][0].get('url', '')
|
||||
|
||||
# Get base model
|
||||
checkpoint['baseModel'] = civitai_info.get('baseModel', '')
|
||||
|
||||
# Get download URL
|
||||
checkpoint['downloadUrl'] = civitai_info.get('downloadUrl', '')
|
||||
else:
|
||||
# Model not found or deleted
|
||||
checkpoint['isDeleted'] = True
|
||||
except Exception as e:
|
||||
logger.error(f"Error populating checkpoint from Civitai info: {e}")
|
||||
|
||||
return checkpoint
|
||||
16
py/recipes/constants.py
Normal file
16
py/recipes/constants.py
Normal file
@@ -0,0 +1,16 @@
|
||||
"""Constants used across recipe parsers."""
|
||||
|
||||
# Constants for generation parameters
|
||||
GEN_PARAM_KEYS = [
|
||||
'prompt',
|
||||
'negative_prompt',
|
||||
'steps',
|
||||
'sampler',
|
||||
'cfg_scale',
|
||||
'seed',
|
||||
'size',
|
||||
'clip_skip',
|
||||
]
|
||||
|
||||
# Valid Lora types
|
||||
VALID_LORA_TYPES = ['lora', 'locon']
|
||||
64
py/recipes/factory.py
Normal file
64
py/recipes/factory.py
Normal file
@@ -0,0 +1,64 @@
|
||||
"""Factory for creating recipe metadata parsers."""
|
||||
|
||||
import logging
|
||||
from .parsers import (
|
||||
RecipeFormatParser,
|
||||
ComfyMetadataParser,
|
||||
MetaFormatParser,
|
||||
AutomaticMetadataParser,
|
||||
CivitaiApiMetadataParser
|
||||
)
|
||||
from .base import RecipeMetadataParser
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class RecipeParserFactory:
|
||||
"""Factory for creating recipe metadata parsers"""
|
||||
|
||||
@staticmethod
|
||||
def create_parser(metadata) -> RecipeMetadataParser:
|
||||
"""
|
||||
Create appropriate parser based on the metadata content
|
||||
|
||||
Args:
|
||||
metadata: The metadata from the image (dict or str)
|
||||
|
||||
Returns:
|
||||
Appropriate RecipeMetadataParser implementation
|
||||
"""
|
||||
# First, try CivitaiApiMetadataParser for dict input
|
||||
if isinstance(metadata, dict):
|
||||
try:
|
||||
if CivitaiApiMetadataParser().is_metadata_matching(metadata):
|
||||
return CivitaiApiMetadataParser()
|
||||
except Exception as e:
|
||||
logger.debug(f"CivitaiApiMetadataParser check failed: {e}")
|
||||
pass
|
||||
|
||||
# Convert dict to string for other parsers that expect string input
|
||||
try:
|
||||
import json
|
||||
metadata_str = json.dumps(metadata)
|
||||
except Exception as e:
|
||||
logger.debug(f"Failed to convert dict to JSON string: {e}")
|
||||
return None
|
||||
else:
|
||||
metadata_str = metadata
|
||||
|
||||
# Try ComfyMetadataParser which requires valid JSON
|
||||
try:
|
||||
if ComfyMetadataParser().is_metadata_matching(metadata_str):
|
||||
return ComfyMetadataParser()
|
||||
except Exception:
|
||||
# If JSON parsing fails, move on to other parsers
|
||||
pass
|
||||
|
||||
# Check other parsers that expect string input
|
||||
if RecipeFormatParser().is_metadata_matching(metadata_str):
|
||||
return RecipeFormatParser()
|
||||
elif AutomaticMetadataParser().is_metadata_matching(metadata_str):
|
||||
return AutomaticMetadataParser()
|
||||
elif MetaFormatParser().is_metadata_matching(metadata_str):
|
||||
return MetaFormatParser()
|
||||
else:
|
||||
return None
|
||||
15
py/recipes/parsers/__init__.py
Normal file
15
py/recipes/parsers/__init__.py
Normal file
@@ -0,0 +1,15 @@
|
||||
"""Recipe parsers package."""
|
||||
|
||||
from .recipe_format import RecipeFormatParser
|
||||
from .comfy import ComfyMetadataParser
|
||||
from .meta_format import MetaFormatParser
|
||||
from .automatic import AutomaticMetadataParser
|
||||
from .civitai_image import CivitaiApiMetadataParser
|
||||
|
||||
__all__ = [
|
||||
'RecipeFormatParser',
|
||||
'ComfyMetadataParser',
|
||||
'MetaFormatParser',
|
||||
'AutomaticMetadataParser',
|
||||
'CivitaiApiMetadataParser',
|
||||
]
|
||||
304
py/recipes/parsers/automatic.py
Normal file
304
py/recipes/parsers/automatic.py
Normal file
@@ -0,0 +1,304 @@
|
||||
"""Parser for Automatic1111 metadata format."""
|
||||
|
||||
import re
|
||||
import json
|
||||
import logging
|
||||
from typing import Dict, Any
|
||||
from ..base import RecipeMetadataParser
|
||||
from ..constants import GEN_PARAM_KEYS
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class AutomaticMetadataParser(RecipeMetadataParser):
|
||||
"""Parser for Automatic1111 metadata format"""
|
||||
|
||||
METADATA_MARKER = r"Steps: \d+"
|
||||
|
||||
# Regular expressions for extracting specific metadata
|
||||
HASHES_REGEX = r', Hashes:\s*({[^}]+})'
|
||||
LORA_HASHES_REGEX = r', Lora hashes:\s*"([^"]+)"'
|
||||
CIVITAI_RESOURCES_REGEX = r', Civitai resources:\s*(\[\{.*?\}\])'
|
||||
CIVITAI_METADATA_REGEX = r', Civitai metadata:\s*(\{.*?\})'
|
||||
EXTRANETS_REGEX = r'<(lora|hypernet):([a-zA-Z0-9_\.\-]+):([0-9.]+)>'
|
||||
MODEL_HASH_PATTERN = r'Model hash: ([a-zA-Z0-9]+)'
|
||||
VAE_HASH_PATTERN = r'VAE hash: ([a-zA-Z0-9]+)'
|
||||
|
||||
def is_metadata_matching(self, user_comment: str) -> bool:
|
||||
"""Check if the user comment matches the Automatic1111 format"""
|
||||
return re.search(self.METADATA_MARKER, user_comment) is not None
|
||||
|
||||
async def parse_metadata(self, user_comment: str, recipe_scanner=None, civitai_client=None) -> Dict[str, Any]:
|
||||
"""Parse metadata from Automatic1111 format"""
|
||||
try:
|
||||
# Split on Negative prompt if it exists
|
||||
if "Negative prompt:" in user_comment:
|
||||
parts = user_comment.split('Negative prompt:', 1)
|
||||
prompt = parts[0].strip()
|
||||
negative_and_params = parts[1] if len(parts) > 1 else ""
|
||||
else:
|
||||
# No negative prompt section
|
||||
param_start = re.search(self.METADATA_MARKER, user_comment)
|
||||
if param_start:
|
||||
prompt = user_comment[:param_start.start()].strip()
|
||||
negative_and_params = user_comment[param_start.start():]
|
||||
else:
|
||||
prompt = user_comment.strip()
|
||||
negative_and_params = ""
|
||||
|
||||
# Initialize metadata
|
||||
metadata = {
|
||||
"prompt": prompt,
|
||||
"loras": []
|
||||
}
|
||||
|
||||
# Extract negative prompt and parameters
|
||||
if negative_and_params:
|
||||
# If we split on "Negative prompt:", check for params section
|
||||
if "Negative prompt:" in user_comment:
|
||||
param_start = re.search(r'Steps: ', negative_and_params)
|
||||
if param_start:
|
||||
neg_prompt = negative_and_params[:param_start.start()].strip()
|
||||
metadata["negative_prompt"] = neg_prompt
|
||||
params_section = negative_and_params[param_start.start():]
|
||||
else:
|
||||
metadata["negative_prompt"] = negative_and_params.strip()
|
||||
params_section = ""
|
||||
else:
|
||||
# No negative prompt, entire section is params
|
||||
params_section = negative_and_params
|
||||
|
||||
# Extract generation parameters
|
||||
if params_section:
|
||||
# Extract Civitai resources
|
||||
civitai_resources_match = re.search(self.CIVITAI_RESOURCES_REGEX, params_section)
|
||||
if civitai_resources_match:
|
||||
try:
|
||||
civitai_resources = json.loads(civitai_resources_match.group(1))
|
||||
metadata["civitai_resources"] = civitai_resources
|
||||
params_section = params_section.replace(civitai_resources_match.group(0), '')
|
||||
except json.JSONDecodeError:
|
||||
logger.error("Error parsing Civitai resources JSON")
|
||||
|
||||
# Extract Hashes
|
||||
hashes_match = re.search(self.HASHES_REGEX, params_section)
|
||||
if hashes_match:
|
||||
try:
|
||||
hashes = json.loads(hashes_match.group(1))
|
||||
# Process hash keys
|
||||
processed_hashes = {}
|
||||
for key, value in hashes.items():
|
||||
# Convert Model: or LORA: prefix to lowercase if present
|
||||
if ':' in key:
|
||||
prefix, name = key.split(':', 1)
|
||||
prefix = prefix.lower()
|
||||
else:
|
||||
prefix = ''
|
||||
name = key
|
||||
|
||||
# Clean up the name part
|
||||
if '/' in name:
|
||||
name = name.split('/')[-1] # Get last part after /
|
||||
if '.safetensors' in name:
|
||||
name = name.split('.safetensors')[0] # Remove .safetensors
|
||||
|
||||
# Reconstruct the key
|
||||
new_key = f"{prefix}:{name}" if prefix else name
|
||||
processed_hashes[new_key] = value
|
||||
|
||||
metadata["hashes"] = processed_hashes
|
||||
# Remove hashes from params section to not interfere with other parsing
|
||||
params_section = params_section.replace(hashes_match.group(0), '')
|
||||
except json.JSONDecodeError:
|
||||
logger.error("Error parsing hashes JSON")
|
||||
|
||||
# Extract Lora hashes in alternative format
|
||||
lora_hashes_match = re.search(self.LORA_HASHES_REGEX, params_section)
|
||||
if not hashes_match and lora_hashes_match:
|
||||
try:
|
||||
lora_hashes_str = lora_hashes_match.group(1)
|
||||
lora_hash_entries = lora_hashes_str.split(', ')
|
||||
|
||||
# Initialize hashes dict if it doesn't exist
|
||||
if "hashes" not in metadata:
|
||||
metadata["hashes"] = {}
|
||||
|
||||
# Parse each lora hash entry (format: "name: hash")
|
||||
for entry in lora_hash_entries:
|
||||
if ': ' in entry:
|
||||
lora_name, lora_hash = entry.split(': ', 1)
|
||||
# Add as lora type in the same format as regular hashes
|
||||
metadata["hashes"][f"lora:{lora_name}"] = lora_hash.strip()
|
||||
|
||||
# Remove lora hashes from params section
|
||||
params_section = params_section.replace(lora_hashes_match.group(0), '')
|
||||
except Exception as e:
|
||||
logger.error(f"Error parsing Lora hashes: {e}")
|
||||
|
||||
# Extract basic parameters
|
||||
param_pattern = r'([A-Za-z\s]+): ([^,]+)'
|
||||
params = re.findall(param_pattern, params_section)
|
||||
gen_params = {}
|
||||
|
||||
for key, value in params:
|
||||
clean_key = key.strip().lower().replace(' ', '_')
|
||||
|
||||
# Skip if not in recognized gen param keys
|
||||
if clean_key not in GEN_PARAM_KEYS:
|
||||
continue
|
||||
|
||||
# Convert numeric values
|
||||
if clean_key in ['steps', 'seed']:
|
||||
try:
|
||||
gen_params[clean_key] = int(value.strip())
|
||||
except ValueError:
|
||||
gen_params[clean_key] = value.strip()
|
||||
elif clean_key in ['cfg_scale']:
|
||||
try:
|
||||
gen_params[clean_key] = float(value.strip())
|
||||
except ValueError:
|
||||
gen_params[clean_key] = value.strip()
|
||||
else:
|
||||
gen_params[clean_key] = value.strip()
|
||||
|
||||
# Extract size if available and add to gen_params if a recognized key
|
||||
size_match = re.search(r'Size: (\d+)x(\d+)', params_section)
|
||||
if size_match and 'size' in GEN_PARAM_KEYS:
|
||||
width, height = size_match.groups()
|
||||
gen_params['size'] = f"{width}x{height}"
|
||||
|
||||
# Add prompt and negative_prompt to gen_params if they're in GEN_PARAM_KEYS
|
||||
if 'prompt' in GEN_PARAM_KEYS and 'prompt' in metadata:
|
||||
gen_params['prompt'] = metadata['prompt']
|
||||
if 'negative_prompt' in GEN_PARAM_KEYS and 'negative_prompt' in metadata:
|
||||
gen_params['negative_prompt'] = metadata['negative_prompt']
|
||||
|
||||
metadata["gen_params"] = gen_params
|
||||
|
||||
# Extract LoRA information
|
||||
loras = []
|
||||
base_model_counts = {}
|
||||
|
||||
# First use Civitai resources if available (more reliable source)
|
||||
if metadata.get("civitai_resources"):
|
||||
for resource in metadata.get("civitai_resources", []):
|
||||
if resource.get("type") in ["lora", "lycoris", "hypernet"] and resource.get("modelVersionId"):
|
||||
# Initialize lora entry
|
||||
lora_entry = {
|
||||
'id': str(resource.get("modelVersionId")),
|
||||
'modelId': str(resource.get("modelId")) if resource.get("modelId") else None,
|
||||
'name': resource.get("modelName", "Unknown LoRA"),
|
||||
'version': resource.get("modelVersionName", ""),
|
||||
'type': resource.get("type", "lora"),
|
||||
'weight': round(float(resource.get("weight", 1.0)), 2),
|
||||
'existsLocally': False,
|
||||
'thumbnailUrl': '/loras_static/images/no-preview.png',
|
||||
'baseModel': '',
|
||||
'size': 0,
|
||||
'downloadUrl': '',
|
||||
'isDeleted': False
|
||||
}
|
||||
|
||||
# Get additional info from Civitai
|
||||
if civitai_client:
|
||||
try:
|
||||
civitai_info = await civitai_client.get_model_version_info(resource.get("modelVersionId"))
|
||||
populated_entry = await self.populate_lora_from_civitai(
|
||||
lora_entry,
|
||||
civitai_info,
|
||||
recipe_scanner,
|
||||
base_model_counts
|
||||
)
|
||||
if populated_entry is None:
|
||||
continue # Skip invalid LoRA types
|
||||
lora_entry = populated_entry
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching Civitai info for LoRA {lora_entry['name']}: {e}")
|
||||
|
||||
loras.append(lora_entry)
|
||||
|
||||
# If no LoRAs from Civitai resources or to supplement, extract from metadata["hashes"]
|
||||
if not loras or len(loras) == 0:
|
||||
# Extract lora weights from extranet tags in prompt (for later use)
|
||||
lora_weights = {}
|
||||
lora_matches = re.findall(self.EXTRANETS_REGEX, prompt)
|
||||
for lora_type, lora_name, lora_weight in lora_matches:
|
||||
key = f"{lora_type}:{lora_name}"
|
||||
lora_weights[key] = round(float(lora_weight), 2)
|
||||
|
||||
# Use hashes from metadata as the primary source
|
||||
if metadata.get("hashes"):
|
||||
for hash_key, lora_hash in metadata.get("hashes", {}).items():
|
||||
# Only process lora or hypernet types
|
||||
if not hash_key.startswith(("lora:", "hypernet:")):
|
||||
continue
|
||||
|
||||
lora_type, lora_name = hash_key.split(':', 1)
|
||||
|
||||
# Get weight from extranet tags if available, else default to 1.0
|
||||
weight = lora_weights.get(hash_key, 1.0)
|
||||
|
||||
# Initialize lora entry
|
||||
lora_entry = {
|
||||
'name': lora_name,
|
||||
'type': lora_type, # 'lora' or 'hypernet'
|
||||
'weight': weight,
|
||||
'hash': lora_hash,
|
||||
'existsLocally': False,
|
||||
'localPath': None,
|
||||
'file_name': lora_name,
|
||||
'thumbnailUrl': '/loras_static/images/no-preview.png',
|
||||
'baseModel': '',
|
||||
'size': 0,
|
||||
'downloadUrl': '',
|
||||
'isDeleted': False
|
||||
}
|
||||
|
||||
# Try to get info from Civitai
|
||||
if civitai_client:
|
||||
try:
|
||||
if lora_hash:
|
||||
# If we have hash, use it for lookup
|
||||
civitai_info = await civitai_client.get_model_by_hash(lora_hash)
|
||||
else:
|
||||
civitai_info = None
|
||||
|
||||
populated_entry = await self.populate_lora_from_civitai(
|
||||
lora_entry,
|
||||
civitai_info,
|
||||
recipe_scanner,
|
||||
base_model_counts,
|
||||
lora_hash
|
||||
)
|
||||
if populated_entry is None:
|
||||
continue # Skip invalid LoRA types
|
||||
lora_entry = populated_entry
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching Civitai info for LoRA {lora_name}: {e}")
|
||||
|
||||
loras.append(lora_entry)
|
||||
|
||||
# Try to get base model from resources or make educated guess
|
||||
base_model = None
|
||||
if base_model_counts:
|
||||
# Use the most common base model from the loras
|
||||
base_model = max(base_model_counts.items(), key=lambda x: x[1])[0]
|
||||
|
||||
# Prepare final result structure
|
||||
# Make sure gen_params only contains recognized keys
|
||||
filtered_gen_params = {}
|
||||
for key in GEN_PARAM_KEYS:
|
||||
if key in metadata.get("gen_params", {}):
|
||||
filtered_gen_params[key] = metadata["gen_params"][key]
|
||||
|
||||
result = {
|
||||
'base_model': base_model,
|
||||
'loras': loras,
|
||||
'gen_params': filtered_gen_params,
|
||||
'from_automatic_metadata': True
|
||||
}
|
||||
|
||||
return result
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error parsing Automatic1111 metadata: {e}", exc_info=True)
|
||||
return {"error": str(e), "loras": []}
|
||||
248
py/recipes/parsers/civitai_image.py
Normal file
248
py/recipes/parsers/civitai_image.py
Normal file
@@ -0,0 +1,248 @@
|
||||
"""Parser for Civitai image metadata format."""
|
||||
|
||||
import json
|
||||
import logging
|
||||
from typing import Dict, Any, Union
|
||||
from ..base import RecipeMetadataParser
|
||||
from ..constants import GEN_PARAM_KEYS
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class CivitaiApiMetadataParser(RecipeMetadataParser):
|
||||
"""Parser for Civitai image metadata format"""
|
||||
|
||||
def is_metadata_matching(self, metadata) -> bool:
|
||||
"""Check if the metadata matches the Civitai image metadata format
|
||||
|
||||
Args:
|
||||
metadata: The metadata from the image (dict)
|
||||
|
||||
Returns:
|
||||
bool: True if this parser can handle the metadata
|
||||
"""
|
||||
if not metadata or not isinstance(metadata, dict):
|
||||
return False
|
||||
|
||||
# Check for key markers specific to Civitai image metadata
|
||||
return any([
|
||||
"resources" in metadata,
|
||||
"civitaiResources" in metadata,
|
||||
"additionalResources" in metadata
|
||||
])
|
||||
|
||||
async def parse_metadata(self, metadata, recipe_scanner=None, civitai_client=None) -> Dict[str, Any]:
|
||||
"""Parse metadata from Civitai image format
|
||||
|
||||
Args:
|
||||
metadata: The metadata from the image (dict)
|
||||
recipe_scanner: Optional recipe scanner service
|
||||
civitai_client: Optional Civitai API client
|
||||
|
||||
Returns:
|
||||
Dict containing parsed recipe data
|
||||
"""
|
||||
try:
|
||||
# Initialize result structure
|
||||
result = {
|
||||
'base_model': None,
|
||||
'loras': [],
|
||||
'gen_params': {},
|
||||
'from_civitai_image': True
|
||||
}
|
||||
|
||||
# Extract prompt and negative prompt
|
||||
if "prompt" in metadata:
|
||||
result["gen_params"]["prompt"] = metadata["prompt"]
|
||||
|
||||
if "negativePrompt" in metadata:
|
||||
result["gen_params"]["negative_prompt"] = metadata["negativePrompt"]
|
||||
|
||||
# Extract other generation parameters
|
||||
param_mapping = {
|
||||
"steps": "steps",
|
||||
"sampler": "sampler",
|
||||
"cfgScale": "cfg_scale",
|
||||
"seed": "seed",
|
||||
"Size": "size",
|
||||
"clipSkip": "clip_skip",
|
||||
}
|
||||
|
||||
for civitai_key, our_key in param_mapping.items():
|
||||
if civitai_key in metadata and our_key in GEN_PARAM_KEYS:
|
||||
result["gen_params"][our_key] = metadata[civitai_key]
|
||||
|
||||
# Extract base model information - directly if available
|
||||
if "baseModel" in metadata:
|
||||
result["base_model"] = metadata["baseModel"]
|
||||
elif "Model hash" in metadata and civitai_client:
|
||||
model_hash = metadata["Model hash"]
|
||||
model_info = await civitai_client.get_model_by_hash(model_hash)
|
||||
if model_info:
|
||||
result["base_model"] = model_info.get("baseModel", "")
|
||||
elif "Model" in metadata and isinstance(metadata.get("resources"), list):
|
||||
# Try to find base model in resources
|
||||
for resource in metadata.get("resources", []):
|
||||
if resource.get("type") == "model" and resource.get("name") == metadata.get("Model"):
|
||||
# This is likely the checkpoint model
|
||||
if civitai_client and resource.get("hash"):
|
||||
model_info = await civitai_client.get_model_by_hash(resource.get("hash"))
|
||||
if model_info:
|
||||
result["base_model"] = model_info.get("baseModel", "")
|
||||
|
||||
base_model_counts = {}
|
||||
|
||||
# Process standard resources array
|
||||
if "resources" in metadata and isinstance(metadata["resources"], list):
|
||||
for resource in metadata["resources"]:
|
||||
# Modified to process resources without a type field as potential LoRAs
|
||||
if resource.get("type", "lora") == "lora":
|
||||
lora_entry = {
|
||||
'name': resource.get("name", "Unknown LoRA"),
|
||||
'type': "lora",
|
||||
'weight': float(resource.get("weight", 1.0)),
|
||||
'hash': resource.get("hash", ""),
|
||||
'existsLocally': False,
|
||||
'localPath': None,
|
||||
'file_name': resource.get("name", "Unknown"),
|
||||
'thumbnailUrl': '/loras_static/images/no-preview.png',
|
||||
'baseModel': '',
|
||||
'size': 0,
|
||||
'downloadUrl': '',
|
||||
'isDeleted': False
|
||||
}
|
||||
|
||||
# Try to get info from Civitai if hash is available
|
||||
if lora_entry['hash'] and civitai_client:
|
||||
try:
|
||||
lora_hash = lora_entry['hash']
|
||||
civitai_info = await civitai_client.get_model_by_hash(lora_hash)
|
||||
|
||||
populated_entry = await self.populate_lora_from_civitai(
|
||||
lora_entry,
|
||||
civitai_info,
|
||||
recipe_scanner,
|
||||
base_model_counts,
|
||||
lora_hash
|
||||
)
|
||||
|
||||
if populated_entry is None:
|
||||
continue # Skip invalid LoRA types
|
||||
|
||||
lora_entry = populated_entry
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching Civitai info for LoRA hash {lora_entry['hash']}: {e}")
|
||||
|
||||
result["loras"].append(lora_entry)
|
||||
|
||||
# Process civitaiResources array
|
||||
if "civitaiResources" in metadata and isinstance(metadata["civitaiResources"], list):
|
||||
for resource in metadata["civitaiResources"]:
|
||||
# Modified to process resources without a type field as potential LoRAs
|
||||
if resource.get("type") in ["lora", "lycoris"] or "type" not in resource:
|
||||
# Initialize lora entry with the same structure as in automatic.py
|
||||
lora_entry = {
|
||||
'id': str(resource.get("modelVersionId")),
|
||||
'modelId': str(resource.get("modelId")) if resource.get("modelId") else None,
|
||||
'name': resource.get("modelName", "Unknown LoRA"),
|
||||
'version': resource.get("modelVersionName", ""),
|
||||
'type': resource.get("type", "lora"),
|
||||
'weight': round(float(resource.get("weight", 1.0)), 2),
|
||||
'existsLocally': False,
|
||||
'thumbnailUrl': '/loras_static/images/no-preview.png',
|
||||
'baseModel': '',
|
||||
'size': 0,
|
||||
'downloadUrl': '',
|
||||
'isDeleted': False
|
||||
}
|
||||
|
||||
# Try to get info from Civitai if modelVersionId is available
|
||||
if resource.get('modelVersionId') and civitai_client:
|
||||
try:
|
||||
version_id = str(resource.get('modelVersionId'))
|
||||
# Use get_model_version_info instead of get_model_version
|
||||
civitai_info, error = await civitai_client.get_model_version_info(version_id)
|
||||
|
||||
if error:
|
||||
logger.warning(f"Error getting model version info: {error}")
|
||||
continue
|
||||
|
||||
populated_entry = await self.populate_lora_from_civitai(
|
||||
lora_entry,
|
||||
civitai_info,
|
||||
recipe_scanner,
|
||||
base_model_counts
|
||||
)
|
||||
|
||||
if populated_entry is None:
|
||||
continue # Skip invalid LoRA types
|
||||
|
||||
lora_entry = populated_entry
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching Civitai info for model version {resource.get('modelVersionId')}: {e}")
|
||||
|
||||
result["loras"].append(lora_entry)
|
||||
|
||||
# Process additionalResources array
|
||||
if "additionalResources" in metadata and isinstance(metadata["additionalResources"], list):
|
||||
for resource in metadata["additionalResources"]:
|
||||
# Modified to process resources without a type field as potential LoRAs
|
||||
if resource.get("type") in ["lora", "lycoris"] or "type" not in resource:
|
||||
lora_type = resource.get("type", "lora")
|
||||
name = resource.get("name", "")
|
||||
|
||||
# Extract ID from URN format if available
|
||||
model_id = None
|
||||
if name and "civitai:" in name:
|
||||
parts = name.split("@")
|
||||
if len(parts) > 1:
|
||||
model_id = parts[1]
|
||||
|
||||
lora_entry = {
|
||||
'name': name,
|
||||
'type': lora_type,
|
||||
'weight': float(resource.get("strength", 1.0)),
|
||||
'hash': "",
|
||||
'existsLocally': False,
|
||||
'localPath': None,
|
||||
'file_name': name,
|
||||
'thumbnailUrl': '/loras_static/images/no-preview.png',
|
||||
'baseModel': '',
|
||||
'size': 0,
|
||||
'downloadUrl': '',
|
||||
'isDeleted': False
|
||||
}
|
||||
|
||||
# If we have a model ID and civitai client, try to get more info
|
||||
if model_id and civitai_client:
|
||||
try:
|
||||
# Use get_model_version_info with the model ID
|
||||
civitai_info, error = await civitai_client.get_model_version_info(model_id)
|
||||
|
||||
if error:
|
||||
logger.warning(f"Error getting model version info: {error}")
|
||||
else:
|
||||
populated_entry = await self.populate_lora_from_civitai(
|
||||
lora_entry,
|
||||
civitai_info,
|
||||
recipe_scanner,
|
||||
base_model_counts
|
||||
)
|
||||
|
||||
if populated_entry is None:
|
||||
continue # Skip invalid LoRA types
|
||||
|
||||
lora_entry = populated_entry
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching Civitai info for model ID {model_id}: {e}")
|
||||
|
||||
result["loras"].append(lora_entry)
|
||||
|
||||
# If base model wasn't found earlier, use the most common one from LoRAs
|
||||
if not result["base_model"] and base_model_counts:
|
||||
result["base_model"] = max(base_model_counts.items(), key=lambda x: x[1])[0]
|
||||
|
||||
return result
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error parsing Civitai image metadata: {e}", exc_info=True)
|
||||
return {"error": str(e), "loras": []}
|
||||
216
py/recipes/parsers/comfy.py
Normal file
216
py/recipes/parsers/comfy.py
Normal file
@@ -0,0 +1,216 @@
|
||||
"""Parser for ComfyUI metadata format."""
|
||||
|
||||
import re
|
||||
import json
|
||||
import logging
|
||||
from typing import Dict, Any
|
||||
from ..base import RecipeMetadataParser
|
||||
from ..constants import GEN_PARAM_KEYS
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class ComfyMetadataParser(RecipeMetadataParser):
|
||||
"""Parser for Civitai ComfyUI metadata JSON format"""
|
||||
|
||||
METADATA_MARKER = r"class_type"
|
||||
|
||||
def is_metadata_matching(self, user_comment: str) -> bool:
|
||||
"""Check if the user comment matches the ComfyUI metadata format"""
|
||||
try:
|
||||
data = json.loads(user_comment)
|
||||
# Check if it contains class_type nodes typical of ComfyUI workflow
|
||||
return isinstance(data, dict) and any(isinstance(v, dict) and 'class_type' in v for v in data.values())
|
||||
except (json.JSONDecodeError, TypeError):
|
||||
return False
|
||||
|
||||
async def parse_metadata(self, user_comment: str, recipe_scanner=None, civitai_client=None) -> Dict[str, Any]:
|
||||
"""Parse metadata from Civitai ComfyUI metadata format"""
|
||||
try:
|
||||
data = json.loads(user_comment)
|
||||
loras = []
|
||||
|
||||
# Find all LoraLoader nodes
|
||||
lora_nodes = {k: v for k, v in data.items() if isinstance(v, dict) and v.get('class_type') == 'LoraLoader'}
|
||||
|
||||
if not lora_nodes:
|
||||
return {"error": "No LoRA information found in this ComfyUI workflow", "loras": []}
|
||||
|
||||
# Process each LoraLoader node
|
||||
for node_id, node in lora_nodes.items():
|
||||
if 'inputs' not in node or 'lora_name' not in node['inputs']:
|
||||
continue
|
||||
|
||||
lora_name = node['inputs'].get('lora_name', '')
|
||||
|
||||
# Parse the URN to extract model ID and version ID
|
||||
# Format: "urn:air:sdxl:lora:civitai:1107767@1253442"
|
||||
lora_id_match = re.search(r'civitai:(\d+)@(\d+)', lora_name)
|
||||
if not lora_id_match:
|
||||
continue
|
||||
|
||||
model_id = lora_id_match.group(1)
|
||||
model_version_id = lora_id_match.group(2)
|
||||
|
||||
# Get strength from node inputs
|
||||
weight = node['inputs'].get('strength_model', 1.0)
|
||||
|
||||
# Initialize lora entry with default values
|
||||
lora_entry = {
|
||||
'id': model_version_id,
|
||||
'modelId': model_id,
|
||||
'name': f"Lora {model_id}", # Default name
|
||||
'version': '',
|
||||
'type': 'lora',
|
||||
'weight': weight,
|
||||
'existsLocally': False,
|
||||
'localPath': None,
|
||||
'file_name': '',
|
||||
'hash': '',
|
||||
'thumbnailUrl': '/loras_static/images/no-preview.png',
|
||||
'baseModel': '',
|
||||
'size': 0,
|
||||
'downloadUrl': '',
|
||||
'isDeleted': False
|
||||
}
|
||||
|
||||
# Get additional info from Civitai if client is available
|
||||
if civitai_client:
|
||||
try:
|
||||
civitai_info_tuple = await civitai_client.get_model_version_info(model_version_id)
|
||||
# Populate lora entry with Civitai info
|
||||
populated_entry = await self.populate_lora_from_civitai(
|
||||
lora_entry,
|
||||
civitai_info_tuple,
|
||||
recipe_scanner
|
||||
)
|
||||
if populated_entry is None:
|
||||
continue # Skip invalid LoRA types
|
||||
lora_entry = populated_entry
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching Civitai info for LoRA: {e}")
|
||||
|
||||
loras.append(lora_entry)
|
||||
|
||||
# Find checkpoint info
|
||||
checkpoint_nodes = {k: v for k, v in data.items() if isinstance(v, dict) and v.get('class_type') == 'CheckpointLoaderSimple'}
|
||||
checkpoint = None
|
||||
checkpoint_id = None
|
||||
checkpoint_version_id = None
|
||||
|
||||
if checkpoint_nodes:
|
||||
# Get the first checkpoint node
|
||||
checkpoint_node = next(iter(checkpoint_nodes.values()))
|
||||
if 'inputs' in checkpoint_node and 'ckpt_name' in checkpoint_node['inputs']:
|
||||
checkpoint_name = checkpoint_node['inputs']['ckpt_name']
|
||||
# Parse checkpoint URN
|
||||
checkpoint_match = re.search(r'civitai:(\d+)@(\d+)', checkpoint_name)
|
||||
if checkpoint_match:
|
||||
checkpoint_id = checkpoint_match.group(1)
|
||||
checkpoint_version_id = checkpoint_match.group(2)
|
||||
checkpoint = {
|
||||
'id': checkpoint_version_id,
|
||||
'modelId': checkpoint_id,
|
||||
'name': f"Checkpoint {checkpoint_id}",
|
||||
'version': '',
|
||||
'type': 'checkpoint'
|
||||
}
|
||||
|
||||
# Get additional checkpoint info from Civitai
|
||||
if civitai_client:
|
||||
try:
|
||||
civitai_info_tuple = await civitai_client.get_model_version_info(checkpoint_version_id)
|
||||
civitai_info, _ = civitai_info_tuple if isinstance(civitai_info_tuple, tuple) else (civitai_info_tuple, None)
|
||||
# Populate checkpoint with Civitai info
|
||||
checkpoint = await self.populate_checkpoint_from_civitai(checkpoint, civitai_info)
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching Civitai info for checkpoint: {e}")
|
||||
|
||||
# Extract generation parameters
|
||||
gen_params = {}
|
||||
|
||||
# First try to get from extraMetadata
|
||||
if 'extraMetadata' in data:
|
||||
try:
|
||||
# extraMetadata is a JSON string that needs to be parsed
|
||||
extra_metadata = json.loads(data['extraMetadata'])
|
||||
|
||||
# Map fields from extraMetadata to our standard format
|
||||
mapping = {
|
||||
'prompt': 'prompt',
|
||||
'negativePrompt': 'negative_prompt',
|
||||
'steps': 'steps',
|
||||
'sampler': 'sampler',
|
||||
'cfgScale': 'cfg_scale',
|
||||
'seed': 'seed'
|
||||
}
|
||||
|
||||
for src_key, dest_key in mapping.items():
|
||||
if src_key in extra_metadata:
|
||||
gen_params[dest_key] = extra_metadata[src_key]
|
||||
|
||||
# If size info is available, format as "width x height"
|
||||
if 'width' in extra_metadata and 'height' in extra_metadata:
|
||||
gen_params['size'] = f"{extra_metadata['width']}x{extra_metadata['height']}"
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error parsing extraMetadata: {e}")
|
||||
|
||||
# If extraMetadata doesn't have all the info, try to get from nodes
|
||||
if not gen_params or len(gen_params) < 3: # At least we want prompt, negative_prompt, and steps
|
||||
# Find positive prompt node
|
||||
positive_nodes = {k: v for k, v in data.items() if isinstance(v, dict) and
|
||||
v.get('class_type', '').endswith('CLIPTextEncode') and
|
||||
v.get('_meta', {}).get('title') == 'Positive'}
|
||||
|
||||
if positive_nodes:
|
||||
positive_node = next(iter(positive_nodes.values()))
|
||||
if 'inputs' in positive_node and 'text' in positive_node['inputs']:
|
||||
gen_params['prompt'] = positive_node['inputs']['text']
|
||||
|
||||
# Find negative prompt node
|
||||
negative_nodes = {k: v for k, v in data.items() if isinstance(v, dict) and
|
||||
v.get('class_type', '').endswith('CLIPTextEncode') and
|
||||
v.get('_meta', {}).get('title') == 'Negative'}
|
||||
|
||||
if negative_nodes:
|
||||
negative_node = next(iter(negative_nodes.values()))
|
||||
if 'inputs' in negative_node and 'text' in negative_node['inputs']:
|
||||
gen_params['negative_prompt'] = negative_node['inputs']['text']
|
||||
|
||||
# Find KSampler node for other parameters
|
||||
ksampler_nodes = {k: v for k, v in data.items() if isinstance(v, dict) and v.get('class_type') == 'KSampler'}
|
||||
|
||||
if ksampler_nodes:
|
||||
ksampler_node = next(iter(ksampler_nodes.values()))
|
||||
if 'inputs' in ksampler_node:
|
||||
inputs = ksampler_node['inputs']
|
||||
if 'sampler_name' in inputs:
|
||||
gen_params['sampler'] = inputs['sampler_name']
|
||||
if 'steps' in inputs:
|
||||
gen_params['steps'] = inputs['steps']
|
||||
if 'cfg' in inputs:
|
||||
gen_params['cfg_scale'] = inputs['cfg']
|
||||
if 'seed' in inputs:
|
||||
gen_params['seed'] = inputs['seed']
|
||||
|
||||
# Determine base model from loras info
|
||||
base_model = None
|
||||
if loras:
|
||||
# Use the most common base model from loras
|
||||
base_models = [lora['baseModel'] for lora in loras if lora.get('baseModel')]
|
||||
if base_models:
|
||||
from collections import Counter
|
||||
base_model_counts = Counter(base_models)
|
||||
base_model = base_model_counts.most_common(1)[0][0]
|
||||
|
||||
return {
|
||||
'base_model': base_model,
|
||||
'loras': loras,
|
||||
'checkpoint': checkpoint,
|
||||
'gen_params': gen_params,
|
||||
'from_comfy_metadata': True
|
||||
}
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error parsing ComfyUI metadata: {e}", exc_info=True)
|
||||
return {"error": str(e), "loras": []}
|
||||
174
py/recipes/parsers/meta_format.py
Normal file
174
py/recipes/parsers/meta_format.py
Normal file
@@ -0,0 +1,174 @@
|
||||
"""Parser for meta format (Lora_N Model hash) metadata."""
|
||||
|
||||
import re
|
||||
import logging
|
||||
from typing import Dict, Any
|
||||
from ..base import RecipeMetadataParser
|
||||
from ..constants import GEN_PARAM_KEYS
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class MetaFormatParser(RecipeMetadataParser):
|
||||
"""Parser for images with meta format metadata (Lora_N Model hash format)"""
|
||||
|
||||
METADATA_MARKER = r'Lora_\d+ Model hash:'
|
||||
|
||||
def is_metadata_matching(self, user_comment: str) -> bool:
|
||||
"""Check if the user comment matches the metadata format"""
|
||||
return re.search(self.METADATA_MARKER, user_comment, re.IGNORECASE | re.DOTALL) is not None
|
||||
|
||||
async def parse_metadata(self, user_comment: str, recipe_scanner=None, civitai_client=None) -> Dict[str, Any]:
|
||||
"""Parse metadata from images with meta format metadata"""
|
||||
try:
|
||||
# Extract prompt and negative prompt
|
||||
parts = user_comment.split('Negative prompt:', 1)
|
||||
prompt = parts[0].strip()
|
||||
|
||||
# Initialize metadata
|
||||
metadata = {"prompt": prompt, "loras": []}
|
||||
|
||||
# Extract negative prompt and parameters if available
|
||||
if len(parts) > 1:
|
||||
negative_and_params = parts[1]
|
||||
|
||||
# Extract negative prompt - everything until the first parameter (usually "Steps:")
|
||||
param_start = re.search(r'([A-Za-z]+): ', negative_and_params)
|
||||
if param_start:
|
||||
neg_prompt = negative_and_params[:param_start.start()].strip()
|
||||
metadata["negative_prompt"] = neg_prompt
|
||||
params_section = negative_and_params[param_start.start():]
|
||||
else:
|
||||
params_section = negative_and_params
|
||||
|
||||
# Extract key-value parameters (Steps, Sampler, Seed, etc.)
|
||||
param_pattern = r'([A-Za-z_0-9 ]+): ([^,]+)'
|
||||
params = re.findall(param_pattern, params_section)
|
||||
for key, value in params:
|
||||
clean_key = key.strip().lower().replace(' ', '_')
|
||||
metadata[clean_key] = value.strip()
|
||||
|
||||
# Extract LoRA information
|
||||
# Pattern to match lora entries: Lora_0 Model name: ArtVador I.safetensors, Lora_0 Model hash: 08f7133a58, etc.
|
||||
lora_pattern = r'Lora_(\d+) Model name: ([^,]+), Lora_\1 Model hash: ([^,]+), Lora_\1 Strength model: ([^,]+), Lora_\1 Strength clip: ([^,]+)'
|
||||
lora_matches = re.findall(lora_pattern, user_comment)
|
||||
|
||||
# If the regular pattern doesn't match, try a more flexible approach
|
||||
if not lora_matches:
|
||||
# First find all Lora indices
|
||||
lora_indices = set(re.findall(r'Lora_(\d+)', user_comment))
|
||||
|
||||
# For each index, extract the information
|
||||
for idx in lora_indices:
|
||||
lora_info = {}
|
||||
|
||||
# Extract model name
|
||||
name_match = re.search(f'Lora_{idx} Model name: ([^,]+)', user_comment)
|
||||
if name_match:
|
||||
lora_info['name'] = name_match.group(1).strip()
|
||||
|
||||
# Extract model hash
|
||||
hash_match = re.search(f'Lora_{idx} Model hash: ([^,]+)', user_comment)
|
||||
if hash_match:
|
||||
lora_info['hash'] = hash_match.group(1).strip()
|
||||
|
||||
# Extract strength model
|
||||
strength_model_match = re.search(f'Lora_{idx} Strength model: ([^,]+)', user_comment)
|
||||
if strength_model_match:
|
||||
lora_info['strength_model'] = float(strength_model_match.group(1).strip())
|
||||
|
||||
# Extract strength clip
|
||||
strength_clip_match = re.search(f'Lora_{idx} Strength clip: ([^,]+)', user_comment)
|
||||
if strength_clip_match:
|
||||
lora_info['strength_clip'] = float(strength_clip_match.group(1).strip())
|
||||
|
||||
# Only add if we have at least name and hash
|
||||
if 'name' in lora_info and 'hash' in lora_info:
|
||||
lora_matches.append((idx, lora_info['name'], lora_info['hash'],
|
||||
str(lora_info.get('strength_model', 1.0)),
|
||||
str(lora_info.get('strength_clip', 1.0))))
|
||||
|
||||
# Process LoRAs
|
||||
base_model_counts = {}
|
||||
loras = []
|
||||
|
||||
for match in lora_matches:
|
||||
if len(match) == 5: # Regular pattern match
|
||||
idx, name, hash_value, strength_model, strength_clip = match
|
||||
else: # Flexible approach match
|
||||
continue # Should not happen now
|
||||
|
||||
# Clean up the values
|
||||
name = name.strip()
|
||||
if name.endswith('.safetensors'):
|
||||
name = name[:-12] # Remove .safetensors extension
|
||||
|
||||
hash_value = hash_value.strip()
|
||||
weight = float(strength_model) # Use model strength as weight
|
||||
|
||||
# Initialize lora entry with default values
|
||||
lora_entry = {
|
||||
'name': name,
|
||||
'type': 'lora',
|
||||
'weight': weight,
|
||||
'existsLocally': False,
|
||||
'localPath': None,
|
||||
'file_name': name,
|
||||
'hash': hash_value,
|
||||
'thumbnailUrl': '/loras_static/images/no-preview.png',
|
||||
'baseModel': '',
|
||||
'size': 0,
|
||||
'downloadUrl': '',
|
||||
'isDeleted': False
|
||||
}
|
||||
|
||||
# Get info from Civitai by hash if available
|
||||
if civitai_client and hash_value:
|
||||
try:
|
||||
civitai_info = await civitai_client.get_model_by_hash(hash_value)
|
||||
# Populate lora entry with Civitai info
|
||||
populated_entry = await self.populate_lora_from_civitai(
|
||||
lora_entry,
|
||||
civitai_info,
|
||||
recipe_scanner,
|
||||
base_model_counts,
|
||||
hash_value
|
||||
)
|
||||
if populated_entry is None:
|
||||
continue # Skip invalid LoRA types
|
||||
lora_entry = populated_entry
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching Civitai info for LoRA hash {hash_value}: {e}")
|
||||
|
||||
loras.append(lora_entry)
|
||||
|
||||
# Extract model information
|
||||
model = None
|
||||
if 'model' in metadata:
|
||||
model = metadata['model']
|
||||
|
||||
# Set base_model to the most common one from civitai_info
|
||||
base_model = None
|
||||
if base_model_counts:
|
||||
base_model = max(base_model_counts.items(), key=lambda x: x[1])[0]
|
||||
|
||||
# Extract generation parameters for recipe metadata
|
||||
gen_params = {}
|
||||
for key in GEN_PARAM_KEYS:
|
||||
if key in metadata:
|
||||
gen_params[key] = metadata.get(key, '')
|
||||
|
||||
# Try to extract size information if available
|
||||
if 'width' in metadata and 'height' in metadata:
|
||||
gen_params['size'] = f"{metadata['width']}x{metadata['height']}"
|
||||
|
||||
return {
|
||||
'base_model': base_model,
|
||||
'loras': loras,
|
||||
'gen_params': gen_params,
|
||||
'raw_metadata': metadata,
|
||||
'from_meta_format': True
|
||||
}
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error parsing meta format metadata: {e}", exc_info=True)
|
||||
return {"error": str(e), "loras": []}
|
||||
114
py/recipes/parsers/recipe_format.py
Normal file
114
py/recipes/parsers/recipe_format.py
Normal file
@@ -0,0 +1,114 @@
|
||||
"""Parser for dedicated recipe metadata format."""
|
||||
|
||||
import re
|
||||
import json
|
||||
import logging
|
||||
from typing import Dict, Any
|
||||
from ...config import config
|
||||
from ..base import RecipeMetadataParser
|
||||
from ..constants import GEN_PARAM_KEYS
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class RecipeFormatParser(RecipeMetadataParser):
|
||||
"""Parser for images with dedicated recipe metadata format"""
|
||||
|
||||
# Regular expression pattern for extracting recipe metadata
|
||||
METADATA_MARKER = r'Recipe metadata: (\{.*\})'
|
||||
|
||||
def is_metadata_matching(self, user_comment: str) -> bool:
|
||||
"""Check if the user comment matches the metadata format"""
|
||||
return re.search(self.METADATA_MARKER, user_comment, re.IGNORECASE | re.DOTALL) is not None
|
||||
|
||||
async def parse_metadata(self, user_comment: str, recipe_scanner=None, civitai_client=None) -> Dict[str, Any]:
|
||||
"""Parse metadata from images with dedicated recipe metadata format"""
|
||||
try:
|
||||
# Extract recipe metadata from user comment
|
||||
try:
|
||||
# Look for recipe metadata section
|
||||
recipe_match = re.search(self.METADATA_MARKER, user_comment, re.IGNORECASE | re.DOTALL)
|
||||
if not recipe_match:
|
||||
recipe_metadata = None
|
||||
else:
|
||||
recipe_json = recipe_match.group(1)
|
||||
recipe_metadata = json.loads(recipe_json)
|
||||
except Exception as e:
|
||||
logger.error(f"Error extracting recipe metadata: {e}")
|
||||
recipe_metadata = None
|
||||
if not recipe_metadata:
|
||||
return {"error": "No recipe metadata found", "loras": []}
|
||||
|
||||
# Process the recipe metadata
|
||||
loras = []
|
||||
for lora in recipe_metadata.get('loras', []):
|
||||
# Convert recipe lora format to frontend format
|
||||
lora_entry = {
|
||||
'id': lora.get('modelVersionId', ''),
|
||||
'name': lora.get('modelName', ''),
|
||||
'version': lora.get('modelVersionName', ''),
|
||||
'type': 'lora',
|
||||
'weight': lora.get('strength', 1.0),
|
||||
'file_name': lora.get('file_name', ''),
|
||||
'hash': lora.get('hash', '')
|
||||
}
|
||||
|
||||
# Check if this LoRA exists locally by SHA256 hash
|
||||
if lora.get('hash') and recipe_scanner:
|
||||
lora_scanner = recipe_scanner._lora_scanner
|
||||
exists_locally = lora_scanner.has_lora_hash(lora['hash'])
|
||||
if exists_locally:
|
||||
lora_cache = await lora_scanner.get_cached_data()
|
||||
lora_item = next((item for item in lora_cache.raw_data if item['sha256'].lower() == lora['hash'].lower()), None)
|
||||
if lora_item:
|
||||
lora_entry['existsLocally'] = True
|
||||
lora_entry['localPath'] = lora_item['file_path']
|
||||
lora_entry['file_name'] = lora_item['file_name']
|
||||
lora_entry['size'] = lora_item['size']
|
||||
lora_entry['thumbnailUrl'] = config.get_preview_static_url(lora_item['preview_url'])
|
||||
|
||||
else:
|
||||
lora_entry['existsLocally'] = False
|
||||
lora_entry['localPath'] = None
|
||||
|
||||
# Try to get additional info from Civitai if we have a model version ID
|
||||
if lora.get('modelVersionId') and civitai_client:
|
||||
try:
|
||||
civitai_info_tuple = await civitai_client.get_model_version_info(lora['modelVersionId'])
|
||||
# Populate lora entry with Civitai info
|
||||
populated_entry = await self.populate_lora_from_civitai(
|
||||
lora_entry,
|
||||
civitai_info_tuple,
|
||||
recipe_scanner,
|
||||
None, # No need to track base model counts
|
||||
lora['hash']
|
||||
)
|
||||
if populated_entry is None:
|
||||
continue # Skip invalid LoRA types
|
||||
lora_entry = populated_entry
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching Civitai info for LoRA: {e}")
|
||||
lora_entry['thumbnailUrl'] = '/loras_static/images/no-preview.png'
|
||||
|
||||
loras.append(lora_entry)
|
||||
|
||||
logger.info(f"Found {len(loras)} loras in recipe metadata")
|
||||
|
||||
# Filter gen_params to only include recognized keys
|
||||
filtered_gen_params = {}
|
||||
if 'gen_params' in recipe_metadata:
|
||||
for key, value in recipe_metadata['gen_params'].items():
|
||||
if key in GEN_PARAM_KEYS:
|
||||
filtered_gen_params[key] = value
|
||||
|
||||
return {
|
||||
'base_model': recipe_metadata.get('base_model', ''),
|
||||
'loras': loras,
|
||||
'gen_params': filtered_gen_params,
|
||||
'tags': recipe_metadata.get('tags', []),
|
||||
'title': recipe_metadata.get('title', ''),
|
||||
'from_recipe_metadata': True
|
||||
}
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error parsing recipe format metadata: {e}", exc_info=True)
|
||||
return {"error": str(e), "loras": []}
|
||||
@@ -3,8 +3,10 @@ import json
|
||||
import logging
|
||||
from aiohttp import web
|
||||
from typing import Dict
|
||||
from server import PromptServer # type: ignore
|
||||
|
||||
from ..utils.routes_common import ModelRouteUtils
|
||||
from ..nodes.utils import get_lora_info
|
||||
|
||||
from ..config import config
|
||||
from ..services.websocket_manager import ws_manager
|
||||
@@ -41,7 +43,9 @@ class ApiRoutes:
|
||||
app.on_startup.append(lambda _: routes.initialize_services())
|
||||
|
||||
app.router.add_post('/api/delete_model', routes.delete_model)
|
||||
app.router.add_post('/api/loras/exclude', routes.exclude_model) # Add new exclude endpoint
|
||||
app.router.add_post('/api/fetch-civitai', routes.fetch_civitai)
|
||||
app.router.add_post('/api/relink-civitai', routes.relink_civitai) # Add new relink endpoint
|
||||
app.router.add_post('/api/replace_preview', routes.replace_preview)
|
||||
app.router.add_get('/api/loras', routes.get_loras)
|
||||
app.router.add_post('/api/fetch-all-civitai', routes.fetch_all_civitai)
|
||||
@@ -50,10 +54,9 @@ class ApiRoutes:
|
||||
app.router.add_get('/api/lora-roots', routes.get_lora_roots)
|
||||
app.router.add_get('/api/folders', routes.get_folders)
|
||||
app.router.add_get('/api/civitai/versions/{model_id}', routes.get_civitai_versions)
|
||||
app.router.add_get('/api/civitai/model/{modelVersionId}', routes.get_civitai_model)
|
||||
app.router.add_get('/api/civitai/model/{hash}', routes.get_civitai_model)
|
||||
app.router.add_get('/api/civitai/model/version/{modelVersionId}', routes.get_civitai_model_by_version)
|
||||
app.router.add_get('/api/civitai/model/hash/{hash}', routes.get_civitai_model_by_hash)
|
||||
app.router.add_post('/api/download-lora', routes.download_lora)
|
||||
app.router.add_post('/api/settings', routes.update_settings)
|
||||
app.router.add_post('/api/move_model', routes.move_model)
|
||||
app.router.add_get('/api/lora-model-description', routes.get_lora_model_description) # Add new route
|
||||
app.router.add_post('/api/loras/save-metadata', routes.save_metadata)
|
||||
@@ -64,16 +67,39 @@ class ApiRoutes:
|
||||
app.router.add_get('/api/lora-civitai-url', routes.get_lora_civitai_url) # Add new route for Civitai URL
|
||||
app.router.add_post('/api/rename_lora', routes.rename_lora) # Add new route for renaming LoRA files
|
||||
app.router.add_get('/api/loras/scan', routes.scan_loras) # Add new route for scanning LoRA files
|
||||
|
||||
# Add the new trigger words route
|
||||
app.router.add_post('/loramanager/get_trigger_words', routes.get_trigger_words)
|
||||
|
||||
# Add new endpoint for letter counts
|
||||
app.router.add_get('/api/loras/letter-counts', routes.get_letter_counts)
|
||||
|
||||
# Add new endpoints for copying lora data
|
||||
app.router.add_get('/api/loras/get-notes', routes.get_lora_notes)
|
||||
app.router.add_get('/api/loras/get-trigger-words', routes.get_lora_trigger_words)
|
||||
|
||||
# Add update check routes
|
||||
UpdateRoutes.setup_routes(app)
|
||||
|
||||
# Add new endpoints for finding duplicates
|
||||
app.router.add_get('/api/loras/find-duplicates', routes.find_duplicate_loras)
|
||||
app.router.add_get('/api/loras/find-filename-conflicts', routes.find_filename_conflicts)
|
||||
|
||||
# Add new endpoint for bulk deleting loras
|
||||
app.router.add_post('/api/loras/bulk-delete', routes.bulk_delete_loras)
|
||||
|
||||
async def delete_model(self, request: web.Request) -> web.Response:
|
||||
"""Handle model deletion request"""
|
||||
if self.scanner is None:
|
||||
self.scanner = await ServiceRegistry.get_lora_scanner()
|
||||
return await ModelRouteUtils.handle_delete_model(request, self.scanner)
|
||||
|
||||
async def exclude_model(self, request: web.Request) -> web.Response:
|
||||
"""Handle model exclusion request"""
|
||||
if self.scanner is None:
|
||||
self.scanner = await ServiceRegistry.get_lora_scanner()
|
||||
return await ModelRouteUtils.handle_exclude_model(request, self.scanner)
|
||||
|
||||
async def fetch_civitai(self, request: web.Request) -> web.Response:
|
||||
"""Handle CivitAI metadata fetch request"""
|
||||
if self.scanner is None:
|
||||
@@ -88,8 +114,11 @@ class ApiRoutes:
|
||||
|
||||
async def scan_loras(self, request: web.Request) -> web.Response:
|
||||
"""Force a rescan of LoRA files"""
|
||||
try:
|
||||
await self.scanner.get_cached_data(force_refresh=True)
|
||||
try:
|
||||
# Get full_rebuild parameter from query string, default to false
|
||||
full_rebuild = request.query.get('full_rebuild', 'false').lower() == 'true'
|
||||
|
||||
await self.scanner.get_cached_data(force_refresh=True, rebuild_cache=full_rebuild)
|
||||
return web.json_response({"status": "success", "message": "LoRA scan completed"})
|
||||
except Exception as e:
|
||||
logger.error(f"Error in scan_loras: {e}", exc_info=True)
|
||||
@@ -120,6 +149,10 @@ class ApiRoutes:
|
||||
# Get filter parameters
|
||||
base_models = request.query.get('base_models', None)
|
||||
tags = request.query.get('tags', None)
|
||||
favorites_only = request.query.get('favorites_only', 'false').lower() == 'true' # New parameter
|
||||
|
||||
# New parameter for alphabet filtering
|
||||
first_letter = request.query.get('first_letter', None)
|
||||
|
||||
# New parameters for recipe filtering
|
||||
lora_hash = request.query.get('lora_hash', None)
|
||||
@@ -150,7 +183,9 @@ class ApiRoutes:
|
||||
base_models=filters.get('base_model', None),
|
||||
tags=filters.get('tags', None),
|
||||
search_options=search_options,
|
||||
hash_filters=hash_filters
|
||||
hash_filters=hash_filters,
|
||||
favorites_only=favorites_only, # Pass favorites_only parameter
|
||||
first_letter=first_letter # Pass the new first_letter parameter
|
||||
)
|
||||
|
||||
# Get all available folders from cache
|
||||
@@ -190,6 +225,7 @@ class ApiRoutes:
|
||||
"from_civitai": lora.get("from_civitai", True),
|
||||
"usage_tips": lora.get("usage_tips", ""),
|
||||
"notes": lora.get("notes", ""),
|
||||
"favorite": lora.get("favorite", False), # Include favorite status in response
|
||||
"civitai": ModelRouteUtils.filter_civitai_data(lora.get("civitai", {}))
|
||||
}
|
||||
|
||||
@@ -226,7 +262,7 @@ class ApiRoutes:
|
||||
target_width=CARD_PREVIEW_WIDTH,
|
||||
format='webp',
|
||||
quality=85,
|
||||
preserve_metadata=True
|
||||
preserve_metadata=False
|
||||
)
|
||||
extension = '.webp' # Use .webp without .preview part
|
||||
|
||||
@@ -365,10 +401,10 @@ class ApiRoutes:
|
||||
versions = response.get('modelVersions', [])
|
||||
model_type = response.get('type', '')
|
||||
|
||||
# Check model type - should be LORA
|
||||
if model_type.lower() != 'lora':
|
||||
# Check model type - should be LORA or LoCon
|
||||
if model_type.lower() not in ['lora', 'locon']:
|
||||
return web.json_response({
|
||||
'error': f"Model type mismatch. Expected LORA, got {model_type}"
|
||||
'error': f"Model type mismatch. Expected LORA or LoCon, got {model_type}"
|
||||
}, status=400)
|
||||
|
||||
# Check local availability for each version
|
||||
@@ -396,25 +432,52 @@ class ApiRoutes:
|
||||
logger.error(f"Error fetching model versions: {e}")
|
||||
return web.Response(status=500, text=str(e))
|
||||
|
||||
async def get_civitai_model(self, request: web.Request) -> web.Response:
|
||||
"""Get CivitAI model details by model version ID or hash"""
|
||||
async def get_civitai_model_by_version(self, request: web.Request) -> web.Response:
|
||||
"""Get CivitAI model details by model version ID"""
|
||||
try:
|
||||
if self.civitai_client is None:
|
||||
self.civitai_client = await ServiceRegistry.get_civitai_client()
|
||||
|
||||
model_version_id = request.match_info.get('modelVersionId')
|
||||
if not model_version_id:
|
||||
hash = request.match_info.get('hash')
|
||||
model = await self.civitai_client.get_model_by_hash(hash)
|
||||
return web.json_response(model)
|
||||
|
||||
# Get model details from Civitai API
|
||||
model = await self.civitai_client.get_model_version_info(model_version_id)
|
||||
model, error_msg = await self.civitai_client.get_model_version_info(model_version_id)
|
||||
|
||||
if not model:
|
||||
# Log warning for failed model retrieval
|
||||
logger.warning(f"Failed to fetch model version {model_version_id}: {error_msg}")
|
||||
|
||||
# Determine status code based on error message
|
||||
status_code = 404 if error_msg and "not found" in error_msg.lower() else 500
|
||||
|
||||
return web.json_response({
|
||||
"success": False,
|
||||
"error": error_msg or "Failed to fetch model information"
|
||||
}, status=status_code)
|
||||
|
||||
return web.json_response(model)
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching model details: {e}")
|
||||
return web.Response(status=500, text=str(e))
|
||||
|
||||
return web.json_response({
|
||||
"success": False,
|
||||
"error": str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_civitai_model_by_hash(self, request: web.Request) -> web.Response:
|
||||
"""Get CivitAI model details by hash"""
|
||||
try:
|
||||
if self.civitai_client is None:
|
||||
self.civitai_client = await ServiceRegistry.get_civitai_client()
|
||||
|
||||
hash = request.match_info.get('hash')
|
||||
model = await self.civitai_client.get_model_by_hash(hash)
|
||||
return web.json_response(model)
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching model details by hash: {e}")
|
||||
return web.json_response({
|
||||
"success": False,
|
||||
"error": str(e)
|
||||
}, status=500)
|
||||
|
||||
async def download_lora(self, request: web.Request) -> web.Response:
|
||||
async with self._download_lock:
|
||||
@@ -460,7 +523,7 @@ class ApiRoutes:
|
||||
logger.warning(f"Early access download failed: {error_message}")
|
||||
return web.Response(
|
||||
status=401, # Use 401 status code to match Civitai's response
|
||||
text=f"Early Access Restriction: {error_message}"
|
||||
text=error_message
|
||||
)
|
||||
|
||||
return web.Response(status=500, text=error_message)
|
||||
@@ -480,21 +543,6 @@ class ApiRoutes:
|
||||
logger.error(f"Error downloading LoRA: {error_message}")
|
||||
return web.Response(status=500, text=error_message)
|
||||
|
||||
async def update_settings(self, request: web.Request) -> web.Response:
|
||||
"""Update application settings"""
|
||||
try:
|
||||
data = await request.json()
|
||||
|
||||
# Validate and update settings
|
||||
if 'civitai_api_key' in data:
|
||||
settings.set('civitai_api_key', data['civitai_api_key'])
|
||||
if 'show_only_sfw' in data:
|
||||
settings.set('show_only_sfw', data['show_only_sfw'])
|
||||
|
||||
return web.json_response({'success': True})
|
||||
except Exception as e:
|
||||
logger.error(f"Error updating settings: {e}", exc_info=True)
|
||||
return web.Response(status=500, text=str(e))
|
||||
|
||||
async def move_model(self, request: web.Request) -> web.Response:
|
||||
"""Handle model move request"""
|
||||
@@ -762,20 +810,23 @@ class ApiRoutes:
|
||||
# Check if we already have the description stored in metadata
|
||||
description = None
|
||||
tags = []
|
||||
creator = {}
|
||||
if file_path:
|
||||
metadata_path = os.path.splitext(file_path)[0] + '.metadata.json'
|
||||
metadata = await ModelRouteUtils.load_local_metadata(metadata_path)
|
||||
description = metadata.get('modelDescription')
|
||||
tags = metadata.get('tags', [])
|
||||
creator = metadata.get('creator', {})
|
||||
|
||||
# If description is not in metadata, fetch from CivitAI
|
||||
if not description:
|
||||
logger.info(f"Fetching model metadata for model ID: {model_id}")
|
||||
model_metadata, _ = await self.civitai_client.get_model_metadata(model_id)
|
||||
|
||||
if model_metadata:
|
||||
if (model_metadata):
|
||||
description = model_metadata.get('description')
|
||||
tags = model_metadata.get('tags', [])
|
||||
creator = model_metadata.get('creator', {})
|
||||
|
||||
# Save the metadata to file if we have a file path and got metadata
|
||||
if file_path:
|
||||
@@ -785,6 +836,7 @@ class ApiRoutes:
|
||||
|
||||
metadata['modelDescription'] = description
|
||||
metadata['tags'] = tags
|
||||
metadata['creator'] = creator
|
||||
|
||||
with open(metadata_path, 'w', encoding='utf-8') as f:
|
||||
json.dump(metadata, f, indent=2, ensure_ascii=False)
|
||||
@@ -795,7 +847,8 @@ class ApiRoutes:
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'description': description or "<p>No model description available.</p>",
|
||||
'tags': tags
|
||||
'tags': tags,
|
||||
'creator': creator
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
@@ -994,4 +1047,248 @@ class ApiRoutes:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
}, status=500)
|
||||
|
||||
async def get_trigger_words(self, request: web.Request) -> web.Response:
|
||||
"""Get trigger words for specified LoRA models"""
|
||||
try:
|
||||
json_data = await request.json()
|
||||
lora_names = json_data.get("lora_names", [])
|
||||
node_ids = json_data.get("node_ids", [])
|
||||
|
||||
all_trigger_words = []
|
||||
for lora_name in lora_names:
|
||||
_, trigger_words = await get_lora_info(lora_name)
|
||||
all_trigger_words.extend(trigger_words)
|
||||
|
||||
# Format the trigger words
|
||||
trigger_words_text = ",, ".join(all_trigger_words) if all_trigger_words else ""
|
||||
|
||||
# Send update to all connected trigger word toggle nodes
|
||||
for node_id in node_ids:
|
||||
PromptServer.instance.send_sync("trigger_word_update", {
|
||||
"id": node_id,
|
||||
"message": trigger_words_text
|
||||
})
|
||||
|
||||
return web.json_response({"success": True})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting trigger words: {e}")
|
||||
return web.json_response({
|
||||
"success": False,
|
||||
"error": str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_letter_counts(self, request: web.Request) -> web.Response:
|
||||
"""Get count of loras for each letter of the alphabet"""
|
||||
try:
|
||||
if self.scanner is None:
|
||||
self.scanner = await ServiceRegistry.get_lora_scanner()
|
||||
|
||||
# Get letter counts
|
||||
letter_counts = await self.scanner.get_letter_counts()
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'letter_counts': letter_counts
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting letter counts: {e}")
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_lora_notes(self, request: web.Request) -> web.Response:
|
||||
"""Get notes for a specific LoRA file"""
|
||||
try:
|
||||
if self.scanner is None:
|
||||
self.scanner = await ServiceRegistry.get_lora_scanner()
|
||||
|
||||
# Get lora file name from query parameters
|
||||
lora_name = request.query.get('name')
|
||||
if not lora_name:
|
||||
return web.Response(text='Lora file name is required', status=400)
|
||||
|
||||
# Get cache data
|
||||
cache = await self.scanner.get_cached_data()
|
||||
|
||||
# Search for the lora in cache data
|
||||
for lora in cache.raw_data:
|
||||
file_name = lora['file_name']
|
||||
if file_name == lora_name:
|
||||
notes = lora.get('notes', '')
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'notes': notes
|
||||
})
|
||||
|
||||
# If lora not found
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'LoRA not found in cache'
|
||||
}, status=404)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting lora notes: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_lora_trigger_words(self, request: web.Request) -> web.Response:
|
||||
"""Get trigger words for a specific LoRA file"""
|
||||
try:
|
||||
if self.scanner is None:
|
||||
self.scanner = await ServiceRegistry.get_lora_scanner()
|
||||
|
||||
# Get lora file name from query parameters
|
||||
lora_name = request.query.get('name')
|
||||
if not lora_name:
|
||||
return web.Response(text='Lora file name is required', status=400)
|
||||
|
||||
# Get cache data
|
||||
cache = await self.scanner.get_cached_data()
|
||||
|
||||
# Search for the lora in cache data
|
||||
for lora in cache.raw_data:
|
||||
file_name = lora['file_name']
|
||||
if file_name == lora_name:
|
||||
# Get trigger words from civitai data
|
||||
civitai_data = lora.get('civitai', {})
|
||||
trigger_words = civitai_data.get('trainedWords', [])
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'trigger_words': trigger_words
|
||||
})
|
||||
|
||||
# If lora not found
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'LoRA not found in cache'
|
||||
}, status=404)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting lora trigger words: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def find_duplicate_loras(self, request: web.Request) -> web.Response:
|
||||
"""Find loras with duplicate SHA256 hashes"""
|
||||
try:
|
||||
if self.scanner is None:
|
||||
self.scanner = await ServiceRegistry.get_lora_scanner()
|
||||
|
||||
# Get duplicate hashes from hash index
|
||||
duplicates = self.scanner._hash_index.get_duplicate_hashes()
|
||||
|
||||
# Format the response
|
||||
result = []
|
||||
cache = await self.scanner.get_cached_data()
|
||||
|
||||
for sha256, paths in duplicates.items():
|
||||
group = {
|
||||
"hash": sha256,
|
||||
"models": []
|
||||
}
|
||||
# Find matching models for each duplicate path
|
||||
for path in paths:
|
||||
model = next((m for m in cache.raw_data if m['file_path'] == path), None)
|
||||
if model:
|
||||
group["models"].append(self._format_lora_response(model))
|
||||
|
||||
# Add the primary model too
|
||||
primary_path = self.scanner._hash_index.get_path(sha256)
|
||||
if primary_path and primary_path not in paths:
|
||||
primary_model = next((m for m in cache.raw_data if m['file_path'] == primary_path), None)
|
||||
if primary_model:
|
||||
group["models"].insert(0, self._format_lora_response(primary_model))
|
||||
|
||||
if group["models"]: # Only include if we found models
|
||||
result.append(group)
|
||||
|
||||
return web.json_response({
|
||||
"success": True,
|
||||
"duplicates": result,
|
||||
"count": len(result)
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error finding duplicate loras: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
"success": False,
|
||||
"error": str(e)
|
||||
}, status=500)
|
||||
|
||||
async def find_filename_conflicts(self, request: web.Request) -> web.Response:
|
||||
"""Find loras with conflicting filenames"""
|
||||
try:
|
||||
if self.scanner is None:
|
||||
self.scanner = await ServiceRegistry.get_lora_scanner()
|
||||
|
||||
# Get duplicate filenames from hash index
|
||||
duplicates = self.scanner._hash_index.get_duplicate_filenames()
|
||||
|
||||
# Format the response
|
||||
result = []
|
||||
cache = await self.scanner.get_cached_data()
|
||||
|
||||
for filename, paths in duplicates.items():
|
||||
group = {
|
||||
"filename": filename,
|
||||
"models": []
|
||||
}
|
||||
# Find matching models for each path
|
||||
for path in paths:
|
||||
model = next((m for m in cache.raw_data if m['file_path'] == path), None)
|
||||
if model:
|
||||
group["models"].append(self._format_lora_response(model))
|
||||
|
||||
# Find the model from the main index too
|
||||
hash_val = self.scanner._hash_index.get_hash_by_filename(filename)
|
||||
if hash_val:
|
||||
main_path = self.scanner._hash_index.get_path(hash_val)
|
||||
if main_path and main_path not in paths:
|
||||
main_model = next((m for m in cache.raw_data if m['file_path'] == main_path), None)
|
||||
if main_model:
|
||||
group["models"].insert(0, self._format_lora_response(main_model))
|
||||
|
||||
if group["models"]: # Only include if we found models
|
||||
result.append(group)
|
||||
|
||||
return web.json_response({
|
||||
"success": True,
|
||||
"conflicts": result,
|
||||
"count": len(result)
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error finding filename conflicts: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
"success": False,
|
||||
"error": str(e)
|
||||
}, status=500)
|
||||
|
||||
async def bulk_delete_loras(self, request: web.Request) -> web.Response:
|
||||
"""Handle bulk deletion of lora models"""
|
||||
try:
|
||||
if self.scanner is None:
|
||||
self.scanner = await ServiceRegistry.get_lora_scanner()
|
||||
|
||||
return await ModelRouteUtils.handle_bulk_delete_models(request, self.scanner)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error in bulk delete loras: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def relink_civitai(self, request: web.Request) -> web.Response:
|
||||
"""Handle CivitAI metadata re-linking request by model version ID for LoRAs"""
|
||||
if self.scanner is None:
|
||||
self.scanner = await ServiceRegistry.get_lora_scanner()
|
||||
return await ModelRouteUtils.handle_relink_civitai(request, self.scanner)
|
||||
|
||||
@@ -49,7 +49,9 @@ class CheckpointsRoutes:
|
||||
|
||||
# Add new routes for model management similar to LoRA routes
|
||||
app.router.add_post('/api/checkpoints/delete', self.delete_model)
|
||||
app.router.add_post('/api/checkpoints/exclude', self.exclude_model) # Add new exclude endpoint
|
||||
app.router.add_post('/api/checkpoints/fetch-civitai', self.fetch_civitai)
|
||||
app.router.add_post('/api/checkpoints/relink-civitai', self.relink_civitai) # Add new relink endpoint
|
||||
app.router.add_post('/api/checkpoints/replace-preview', self.replace_preview)
|
||||
app.router.add_post('/api/checkpoints/download', self.download_checkpoint)
|
||||
app.router.add_post('/api/checkpoints/save-metadata', self.save_metadata) # Add new route
|
||||
@@ -57,6 +59,13 @@ class CheckpointsRoutes:
|
||||
# Add new WebSocket endpoint for checkpoint progress
|
||||
app.router.add_get('/ws/checkpoint-progress', ws_manager.handle_checkpoint_connection)
|
||||
|
||||
# Add new routes for finding duplicates and filename conflicts
|
||||
app.router.add_get('/api/checkpoints/find-duplicates', self.find_duplicate_checkpoints)
|
||||
app.router.add_get('/api/checkpoints/find-filename-conflicts', self.find_filename_conflicts)
|
||||
|
||||
# Add new endpoint for bulk deleting checkpoints
|
||||
app.router.add_post('/api/checkpoints/bulk-delete', self.bulk_delete_checkpoints)
|
||||
|
||||
async def get_checkpoints(self, request):
|
||||
"""Get paginated checkpoint data"""
|
||||
try:
|
||||
@@ -69,6 +78,7 @@ class CheckpointsRoutes:
|
||||
fuzzy_search = request.query.get('fuzzy_search', 'false').lower() == 'true'
|
||||
base_models = request.query.getall('base_model', [])
|
||||
tags = request.query.getall('tag', [])
|
||||
favorites_only = request.query.get('favorites_only', 'false').lower() == 'true' # Add favorites_only parameter
|
||||
|
||||
# Process search options
|
||||
search_options = {
|
||||
@@ -101,7 +111,8 @@ class CheckpointsRoutes:
|
||||
base_models=base_models,
|
||||
tags=tags,
|
||||
search_options=search_options,
|
||||
hash_filters=hash_filters
|
||||
hash_filters=hash_filters,
|
||||
favorites_only=favorites_only # Pass favorites_only parameter
|
||||
)
|
||||
|
||||
# Format response items
|
||||
@@ -123,7 +134,8 @@ class CheckpointsRoutes:
|
||||
async def get_paginated_data(self, page, page_size, sort_by='name',
|
||||
folder=None, search=None, fuzzy_search=False,
|
||||
base_models=None, tags=None,
|
||||
search_options=None, hash_filters=None):
|
||||
search_options=None, hash_filters=None,
|
||||
favorites_only=False): # Add favorites_only parameter with default False
|
||||
"""Get paginated and filtered checkpoint data"""
|
||||
cache = await self.scanner.get_cached_data()
|
||||
|
||||
@@ -181,6 +193,13 @@ class CheckpointsRoutes:
|
||||
if not cp.get('preview_nsfw_level') or cp.get('preview_nsfw_level') < NSFW_LEVELS['R']
|
||||
]
|
||||
|
||||
# Apply favorites filtering if enabled
|
||||
if favorites_only:
|
||||
filtered_data = [
|
||||
cp for cp in filtered_data
|
||||
if cp.get('favorite', False) is True
|
||||
]
|
||||
|
||||
# Apply folder filtering
|
||||
if folder is not None:
|
||||
if search_options.get('recursive', False):
|
||||
@@ -276,6 +295,7 @@ class CheckpointsRoutes:
|
||||
"from_civitai": checkpoint.get("from_civitai", True),
|
||||
"notes": checkpoint.get("notes", ""),
|
||||
"model_type": checkpoint.get("model_type", "checkpoint"),
|
||||
"favorite": checkpoint.get("favorite", False),
|
||||
"civitai": ModelRouteUtils.filter_civitai_data(checkpoint.get("civitai", {}))
|
||||
}
|
||||
|
||||
@@ -408,7 +428,10 @@ class CheckpointsRoutes:
|
||||
async def scan_checkpoints(self, request):
|
||||
"""Force a rescan of checkpoint files"""
|
||||
try:
|
||||
await self.scanner.get_cached_data(force_refresh=True)
|
||||
# Get the full_rebuild parameter and convert to bool, default to False
|
||||
full_rebuild = request.query.get('full_rebuild', 'false').lower() == 'true'
|
||||
|
||||
await self.scanner.get_cached_data(force_refresh=True, rebuild_cache=full_rebuild)
|
||||
return web.json_response({"status": "success", "message": "Checkpoint scan completed"})
|
||||
except Exception as e:
|
||||
logger.error(f"Error in scan_checkpoints: {e}", exc_info=True)
|
||||
@@ -418,7 +441,7 @@ class CheckpointsRoutes:
|
||||
"""Get detailed information for a specific checkpoint by name"""
|
||||
try:
|
||||
name = request.match_info.get('name', '')
|
||||
checkpoint_info = await self.scanner.get_checkpoint_info_by_name(name)
|
||||
checkpoint_info = await self.scanner.get_model_info_by_name(name)
|
||||
|
||||
if checkpoint_info:
|
||||
return web.json_response(checkpoint_info)
|
||||
@@ -488,6 +511,10 @@ class CheckpointsRoutes:
|
||||
async def delete_model(self, request: web.Request) -> web.Response:
|
||||
"""Handle checkpoint model deletion request"""
|
||||
return await ModelRouteUtils.handle_delete_model(request, self.scanner)
|
||||
|
||||
async def exclude_model(self, request: web.Request) -> web.Response:
|
||||
"""Handle checkpoint model exclusion request"""
|
||||
return await ModelRouteUtils.handle_exclude_model(request, self.scanner)
|
||||
|
||||
async def fetch_civitai(self, request: web.Request) -> web.Response:
|
||||
"""Handle CivitAI metadata fetch request for checkpoints"""
|
||||
@@ -642,7 +669,7 @@ class CheckpointsRoutes:
|
||||
model_type = response.get('type', '')
|
||||
|
||||
# Check model type - should be Checkpoint
|
||||
if model_type.lower() != 'checkpoint':
|
||||
if (model_type.lower() != 'checkpoint'):
|
||||
return web.json_response({
|
||||
'error': f"Model type mismatch. Expected Checkpoint, got {model_type}"
|
||||
}, status=400)
|
||||
@@ -676,3 +703,116 @@ class CheckpointsRoutes:
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching checkpoint model versions: {e}")
|
||||
return web.Response(status=500, text=str(e))
|
||||
|
||||
async def find_duplicate_checkpoints(self, request: web.Request) -> web.Response:
|
||||
"""Find checkpoints with duplicate SHA256 hashes"""
|
||||
try:
|
||||
if self.scanner is None:
|
||||
self.scanner = await ServiceRegistry.get_checkpoint_scanner()
|
||||
|
||||
# Get duplicate hashes from hash index
|
||||
duplicates = self.scanner._hash_index.get_duplicate_hashes()
|
||||
|
||||
# Format the response
|
||||
result = []
|
||||
cache = await self.scanner.get_cached_data()
|
||||
|
||||
for sha256, paths in duplicates.items():
|
||||
group = {
|
||||
"hash": sha256,
|
||||
"models": []
|
||||
}
|
||||
# Find matching models for each path
|
||||
for path in paths:
|
||||
model = next((m for m in cache.raw_data if m['file_path'] == path), None)
|
||||
if model:
|
||||
group["models"].append(self._format_checkpoint_response(model))
|
||||
|
||||
# Add the primary model too
|
||||
primary_path = self.scanner._hash_index.get_path(sha256)
|
||||
if primary_path and primary_path not in paths:
|
||||
primary_model = next((m for m in cache.raw_data if m['file_path'] == primary_path), None)
|
||||
if primary_model:
|
||||
group["models"].insert(0, self._format_checkpoint_response(primary_model))
|
||||
|
||||
if group["models"]:
|
||||
result.append(group)
|
||||
|
||||
return web.json_response({
|
||||
"success": True,
|
||||
"duplicates": result,
|
||||
"count": len(result)
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error finding duplicate checkpoints: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
"success": False,
|
||||
"error": str(e)
|
||||
}, status=500)
|
||||
|
||||
async def find_filename_conflicts(self, request: web.Request) -> web.Response:
|
||||
"""Find checkpoints with conflicting filenames"""
|
||||
try:
|
||||
if self.scanner is None:
|
||||
self.scanner = await ServiceRegistry.get_checkpoint_scanner()
|
||||
|
||||
# Get duplicate filenames from hash index
|
||||
duplicates = self.scanner._hash_index.get_duplicate_filenames()
|
||||
|
||||
# Format the response
|
||||
result = []
|
||||
cache = await self.scanner.get_cached_data()
|
||||
|
||||
for filename, paths in duplicates.items():
|
||||
group = {
|
||||
"filename": filename,
|
||||
"models": []
|
||||
}
|
||||
# Find matching models for each path
|
||||
for path in paths:
|
||||
model = next((m for m in cache.raw_data if m['file_path'] == path), None)
|
||||
if model:
|
||||
group["models"].append(self._format_checkpoint_response(model))
|
||||
|
||||
# Find the model from the main index too
|
||||
hash_val = self.scanner._hash_index.get_hash_by_filename(filename)
|
||||
if hash_val:
|
||||
main_path = self.scanner._hash_index.get_path(hash_val)
|
||||
if main_path and main_path not in paths:
|
||||
main_model = next((m for m in cache.raw_data if m['file_path'] == main_path), None)
|
||||
if main_model:
|
||||
group["models"].insert(0, self._format_checkpoint_response(main_model))
|
||||
|
||||
if group["models"]:
|
||||
result.append(group)
|
||||
|
||||
return web.json_response({
|
||||
"success": True,
|
||||
"conflicts": result,
|
||||
"count": len(result)
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error finding filename conflicts: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
"success": False,
|
||||
"error": str(e)
|
||||
}, status=500)
|
||||
|
||||
async def bulk_delete_checkpoints(self, request: web.Request) -> web.Response:
|
||||
"""Handle bulk deletion of checkpoint models"""
|
||||
try:
|
||||
if self.scanner is None:
|
||||
self.scanner = await ServiceRegistry.get_checkpoint_scanner()
|
||||
|
||||
return await ModelRouteUtils.handle_bulk_delete_models(request, self.scanner)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error in bulk delete checkpoints: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def relink_civitai(self, request: web.Request) -> web.Response:
|
||||
"""Handle CivitAI metadata re-linking request by model version ID for checkpoints"""
|
||||
return await ModelRouteUtils.handle_relink_civitai(request, self.scanner)
|
||||
|
||||
1428
py/routes/example_images_routes.py
Normal file
1428
py/routes/example_images_routes.py
Normal file
File diff suppressed because it is too large
Load Diff
405
py/routes/misc_routes.py
Normal file
405
py/routes/misc_routes.py
Normal file
@@ -0,0 +1,405 @@
|
||||
import logging
|
||||
import os
|
||||
from server import PromptServer # type: ignore
|
||||
from aiohttp import web
|
||||
from ..services.settings_manager import settings
|
||||
from ..utils.usage_stats import UsageStats
|
||||
from ..utils.lora_metadata import extract_trained_words
|
||||
from ..config import config
|
||||
from ..utils.constants import SUPPORTED_MEDIA_EXTENSIONS
|
||||
import re
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# Download status tracking
|
||||
download_task = None
|
||||
is_downloading = False
|
||||
download_progress = {
|
||||
'total': 0,
|
||||
'completed': 0,
|
||||
'current_model': '',
|
||||
'status': 'idle', # idle, running, paused, completed, error
|
||||
'errors': [],
|
||||
'last_error': None,
|
||||
'start_time': None,
|
||||
'end_time': None,
|
||||
'processed_models': set(), # Track models that have been processed
|
||||
'refreshed_models': set() # Track models that had metadata refreshed
|
||||
}
|
||||
|
||||
class MiscRoutes:
|
||||
"""Miscellaneous routes for various utility functions"""
|
||||
|
||||
@staticmethod
|
||||
def setup_routes(app):
|
||||
"""Register miscellaneous routes"""
|
||||
app.router.add_post('/api/settings', MiscRoutes.update_settings)
|
||||
|
||||
# Add new route for clearing cache
|
||||
app.router.add_post('/api/clear-cache', MiscRoutes.clear_cache)
|
||||
|
||||
# Usage stats routes
|
||||
app.router.add_post('/api/update-usage-stats', MiscRoutes.update_usage_stats)
|
||||
app.router.add_get('/api/get-usage-stats', MiscRoutes.get_usage_stats)
|
||||
|
||||
# Lora code update endpoint
|
||||
app.router.add_post('/api/update-lora-code', MiscRoutes.update_lora_code)
|
||||
|
||||
# Add new route for getting trained words
|
||||
app.router.add_get('/api/trained-words', MiscRoutes.get_trained_words)
|
||||
|
||||
# Add new route for getting model example files
|
||||
app.router.add_get('/api/model-example-files', MiscRoutes.get_model_example_files)
|
||||
|
||||
@staticmethod
|
||||
async def clear_cache(request):
|
||||
"""Clear all cache files from the cache folder"""
|
||||
try:
|
||||
# Get the cache folder path (relative to project directory)
|
||||
project_dir = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
|
||||
cache_folder = os.path.join(project_dir, 'cache')
|
||||
|
||||
# Check if cache folder exists
|
||||
if not os.path.exists(cache_folder):
|
||||
logger.info("Cache folder does not exist, nothing to clear")
|
||||
return web.json_response({'success': True, 'message': 'No cache folder found'})
|
||||
|
||||
# Get list of cache files before deleting for reporting
|
||||
cache_files = [f for f in os.listdir(cache_folder) if os.path.isfile(os.path.join(cache_folder, f))]
|
||||
deleted_files = []
|
||||
|
||||
# Delete each .msgpack file in the cache folder
|
||||
for filename in cache_files:
|
||||
if filename.endswith('.msgpack'):
|
||||
file_path = os.path.join(cache_folder, filename)
|
||||
try:
|
||||
os.remove(file_path)
|
||||
deleted_files.append(filename)
|
||||
logger.info(f"Deleted cache file: {filename}")
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to delete {filename}: {e}")
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': f"Failed to delete {filename}: {str(e)}"
|
||||
}, status=500)
|
||||
|
||||
# If we want to completely remove the cache folder too (optional,
|
||||
# but we'll keep the folder structure in place here)
|
||||
# shutil.rmtree(cache_folder)
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'message': f"Successfully cleared {len(deleted_files)} cache files",
|
||||
'deleted_files': deleted_files
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error clearing cache files: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
@staticmethod
|
||||
async def update_settings(request):
|
||||
"""Update application settings"""
|
||||
try:
|
||||
data = await request.json()
|
||||
|
||||
# Validate and update settings
|
||||
for key, value in data.items():
|
||||
# Special handling for example_images_path - verify path exists
|
||||
if key == 'example_images_path' and value:
|
||||
if not os.path.exists(value):
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': f"Path does not exist: {value}"
|
||||
})
|
||||
|
||||
# Path changed - server restart required for new path to take effect
|
||||
old_path = settings.get('example_images_path')
|
||||
if old_path != value:
|
||||
logger.info(f"Example images path changed to {value} - server restart required")
|
||||
|
||||
# Save to settings
|
||||
settings.set(key, value)
|
||||
|
||||
return web.json_response({'success': True})
|
||||
except Exception as e:
|
||||
logger.error(f"Error updating settings: {e}", exc_info=True)
|
||||
return web.Response(status=500, text=str(e))
|
||||
|
||||
@staticmethod
|
||||
async def update_usage_stats(request):
|
||||
"""
|
||||
Update usage statistics based on a prompt_id
|
||||
|
||||
Expects a JSON body with:
|
||||
{
|
||||
"prompt_id": "string"
|
||||
}
|
||||
"""
|
||||
try:
|
||||
# Parse the request body
|
||||
data = await request.json()
|
||||
prompt_id = data.get('prompt_id')
|
||||
|
||||
if not prompt_id:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Missing prompt_id'
|
||||
}, status=400)
|
||||
|
||||
# Call the UsageStats to process this prompt_id synchronously
|
||||
usage_stats = UsageStats()
|
||||
await usage_stats.process_execution(prompt_id)
|
||||
|
||||
return web.json_response({
|
||||
'success': True
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to update usage stats: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
@staticmethod
|
||||
async def get_usage_stats(request):
|
||||
"""Get current usage statistics"""
|
||||
try:
|
||||
usage_stats = UsageStats()
|
||||
stats = await usage_stats.get_stats()
|
||||
|
||||
# Add version information to help clients handle format changes
|
||||
stats_response = {
|
||||
'success': True,
|
||||
'data': stats,
|
||||
'format_version': 2 # Indicate this is the new format with history
|
||||
}
|
||||
|
||||
return web.json_response(stats_response)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to get usage stats: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
@staticmethod
|
||||
async def update_lora_code(request):
|
||||
"""
|
||||
Update Lora code in ComfyUI nodes
|
||||
|
||||
Expects a JSON body with:
|
||||
{
|
||||
"node_ids": [123, 456], # Optional - List of node IDs to update (for browser mode)
|
||||
"lora_code": "<lora:modelname:1.0>", # The Lora code to send
|
||||
"mode": "append" # or "replace" - whether to append or replace existing code
|
||||
}
|
||||
"""
|
||||
try:
|
||||
# Parse the request body
|
||||
data = await request.json()
|
||||
node_ids = data.get('node_ids')
|
||||
lora_code = data.get('lora_code', '')
|
||||
mode = data.get('mode', 'append')
|
||||
|
||||
if not lora_code:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Missing lora_code parameter'
|
||||
}, status=400)
|
||||
|
||||
results = []
|
||||
|
||||
# Desktop mode: no specific node_ids provided
|
||||
if node_ids is None:
|
||||
try:
|
||||
# Send broadcast message with id=-1 to all Lora Loader nodes
|
||||
PromptServer.instance.send_sync("lora_code_update", {
|
||||
"id": -1,
|
||||
"lora_code": lora_code,
|
||||
"mode": mode
|
||||
})
|
||||
results.append({
|
||||
'node_id': 'broadcast',
|
||||
'success': True
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error broadcasting lora code: {e}")
|
||||
results.append({
|
||||
'node_id': 'broadcast',
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
})
|
||||
else:
|
||||
# Browser mode: send to specific nodes
|
||||
for node_id in node_ids:
|
||||
try:
|
||||
# Send the message to the frontend
|
||||
PromptServer.instance.send_sync("lora_code_update", {
|
||||
"id": node_id,
|
||||
"lora_code": lora_code,
|
||||
"mode": mode
|
||||
})
|
||||
results.append({
|
||||
'node_id': node_id,
|
||||
'success': True
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error sending lora code to node {node_id}: {e}")
|
||||
results.append({
|
||||
'node_id': node_id,
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
})
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'results': results
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to update lora code: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
@staticmethod
|
||||
async def get_trained_words(request):
|
||||
"""
|
||||
Get trained words from a safetensors file, sorted by frequency
|
||||
|
||||
Expects a query parameter:
|
||||
file_path: Path to the safetensors file
|
||||
"""
|
||||
try:
|
||||
# Get file path from query parameters
|
||||
file_path = request.query.get('file_path')
|
||||
|
||||
if not file_path:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Missing file_path parameter'
|
||||
}, status=400)
|
||||
|
||||
# Check if file exists and is a safetensors file
|
||||
if not os.path.exists(file_path):
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': f"File not found: {file_path}"
|
||||
}, status=404)
|
||||
|
||||
if not file_path.lower().endswith('.safetensors'):
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'File is not a safetensors file'
|
||||
}, status=400)
|
||||
|
||||
# Extract trained words and class_tokens
|
||||
trained_words, class_tokens = await extract_trained_words(file_path)
|
||||
|
||||
# Return result with both trained words and class tokens
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'trained_words': trained_words,
|
||||
'class_tokens': class_tokens
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to get trained words: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
@staticmethod
|
||||
async def get_model_example_files(request):
|
||||
"""
|
||||
Get list of example image files for a specific model based on file path
|
||||
|
||||
Expects:
|
||||
- file_path in query parameters
|
||||
|
||||
Returns:
|
||||
- List of image files with their paths as static URLs
|
||||
"""
|
||||
try:
|
||||
# Get the model file path from query parameters
|
||||
file_path = request.query.get('file_path')
|
||||
|
||||
if not file_path:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Missing file_path parameter'
|
||||
}, status=400)
|
||||
|
||||
# Extract directory and base filename
|
||||
model_dir = os.path.dirname(file_path)
|
||||
model_filename = os.path.basename(file_path)
|
||||
model_name = os.path.splitext(model_filename)[0]
|
||||
|
||||
# Check if the directory exists
|
||||
if not os.path.exists(model_dir):
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Model directory not found',
|
||||
'files': []
|
||||
}, status=404)
|
||||
|
||||
# Look for files matching the pattern modelname.example.<index>.<ext>
|
||||
files = []
|
||||
pattern = f"{model_name}.example."
|
||||
|
||||
for file in os.listdir(model_dir):
|
||||
file_lower = file.lower()
|
||||
if file_lower.startswith(pattern.lower()):
|
||||
file_full_path = os.path.join(model_dir, file)
|
||||
if os.path.isfile(file_full_path):
|
||||
# Check if the file is a supported media file
|
||||
file_ext = os.path.splitext(file)[1].lower()
|
||||
if (file_ext in SUPPORTED_MEDIA_EXTENSIONS['images'] or
|
||||
file_ext in SUPPORTED_MEDIA_EXTENSIONS['videos']):
|
||||
|
||||
# Extract the index from the filename
|
||||
try:
|
||||
# Extract the part after '.example.' and before file extension
|
||||
index_part = file[len(pattern):].split('.')[0]
|
||||
# Try to parse it as an integer
|
||||
index = int(index_part)
|
||||
except (ValueError, IndexError):
|
||||
# If we can't parse the index, use infinity to sort at the end
|
||||
index = float('inf')
|
||||
|
||||
# Convert file path to static URL
|
||||
static_url = config.get_preview_static_url(file_full_path)
|
||||
|
||||
files.append({
|
||||
'name': file,
|
||||
'path': static_url,
|
||||
'extension': file_ext,
|
||||
'is_video': file_ext in SUPPORTED_MEDIA_EXTENSIONS['videos'],
|
||||
'index': index
|
||||
})
|
||||
|
||||
# Sort files by their index for consistent ordering
|
||||
files.sort(key=lambda x: x['index'])
|
||||
# Remove the index field as it's only used for sorting
|
||||
for file in files:
|
||||
file.pop('index', None)
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'files': files
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to get model example files: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
@@ -1,20 +1,36 @@
|
||||
import os
|
||||
import time
|
||||
import base64
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
import torch
|
||||
import io
|
||||
import logging
|
||||
from aiohttp import web
|
||||
from typing import Dict
|
||||
import tempfile
|
||||
import json
|
||||
import asyncio
|
||||
import sys
|
||||
from ..utils.exif_utils import ExifUtils
|
||||
from ..utils.recipe_parsers import RecipeParserFactory
|
||||
from ..recipes import RecipeParserFactory
|
||||
from ..utils.constants import CARD_PREVIEW_WIDTH
|
||||
|
||||
from ..config import config
|
||||
from ..workflow.parser import WorkflowParser
|
||||
|
||||
# Check if running in standalone mode
|
||||
standalone_mode = 'nodes' not in sys.modules
|
||||
|
||||
from ..utils.utils import download_civitai_image
|
||||
from ..services.service_registry import ServiceRegistry # Add ServiceRegistry import
|
||||
|
||||
# Only import MetadataRegistry in non-standalone mode
|
||||
if not standalone_mode:
|
||||
# Import metadata_collector functions and classes conditionally
|
||||
from ..metadata_collector import get_metadata # Add MetadataCollector import
|
||||
from ..metadata_collector.metadata_processor import MetadataProcessor # Add MetadataProcessor import
|
||||
from ..metadata_collector.metadata_registry import MetadataRegistry
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class RecipeRoutes:
|
||||
@@ -24,7 +40,7 @@ class RecipeRoutes:
|
||||
# Initialize service references as None, will be set during async init
|
||||
self.recipe_scanner = None
|
||||
self.civitai_client = None
|
||||
self.parser = WorkflowParser()
|
||||
# Remove WorkflowParser instance
|
||||
|
||||
# Pre-warm the cache
|
||||
self._init_cache_task = None
|
||||
@@ -41,6 +57,7 @@ class RecipeRoutes:
|
||||
app.router.add_get('/api/recipes', routes.get_recipes)
|
||||
app.router.add_get('/api/recipe/{recipe_id}', routes.get_recipe_detail)
|
||||
app.router.add_post('/api/recipes/analyze-image', routes.analyze_recipe_image)
|
||||
app.router.add_post('/api/recipes/analyze-local-image', routes.analyze_local_image)
|
||||
app.router.add_post('/api/recipes/save', routes.save_recipe)
|
||||
app.router.add_delete('/api/recipe/{recipe_id}', routes.delete_recipe)
|
||||
|
||||
@@ -55,12 +72,18 @@ class RecipeRoutes:
|
||||
# Add new endpoint for getting recipe syntax
|
||||
app.router.add_get('/api/recipe/{recipe_id}/syntax', routes.get_recipe_syntax)
|
||||
|
||||
# Add new endpoint for updating recipe metadata (name and tags)
|
||||
# Add new endpoint for updating recipe metadata (name, tags and source_path)
|
||||
app.router.add_put('/api/recipe/{recipe_id}/update', routes.update_recipe)
|
||||
|
||||
# Add new endpoint for reconnecting deleted LoRAs
|
||||
app.router.add_post('/api/recipe/lora/reconnect', routes.reconnect_lora)
|
||||
|
||||
# Add new endpoint for finding duplicate recipes
|
||||
app.router.add_get('/api/recipes/find-duplicates', routes.find_duplicates)
|
||||
|
||||
# Add new endpoint for bulk deletion of recipes
|
||||
app.router.add_post('/api/recipes/bulk-delete', routes.bulk_delete)
|
||||
|
||||
# Start cache initialization
|
||||
app.on_startup.append(routes._init_cache)
|
||||
|
||||
@@ -68,6 +91,9 @@ class RecipeRoutes:
|
||||
|
||||
# Add route to get recipes for a specific Lora
|
||||
app.router.add_get('/api/recipes/for-lora', routes.get_recipes_for_lora)
|
||||
|
||||
# Add new endpoint for scanning and rebuilding the recipe cache
|
||||
app.router.add_get('/api/recipes/scan', routes.scan_recipes)
|
||||
|
||||
async def _init_cache(self, app):
|
||||
"""Initialize cache on startup"""
|
||||
@@ -228,6 +254,7 @@ class RecipeRoutes:
|
||||
content_type = request.headers.get('Content-Type', '')
|
||||
|
||||
is_url_mode = False
|
||||
metadata = None # Initialize metadata variable
|
||||
|
||||
if 'multipart/form-data' in content_type:
|
||||
# Handle image upload
|
||||
@@ -261,17 +288,63 @@ class RecipeRoutes:
|
||||
"loras": []
|
||||
}, status=400)
|
||||
|
||||
# Download image from URL
|
||||
temp_path = download_civitai_image(url)
|
||||
# Check if this is a Civitai image URL
|
||||
import re
|
||||
civitai_image_match = re.match(r'https://civitai\.com/images/(\d+)', url)
|
||||
|
||||
if not temp_path:
|
||||
return web.json_response({
|
||||
"error": "Failed to download image from URL",
|
||||
"loras": []
|
||||
}, status=400)
|
||||
if civitai_image_match:
|
||||
# Extract image ID and fetch image info using get_image_info
|
||||
image_id = civitai_image_match.group(1)
|
||||
image_info = await self.civitai_client.get_image_info(image_id)
|
||||
|
||||
if not image_info:
|
||||
return web.json_response({
|
||||
"error": "Failed to fetch image information from Civitai",
|
||||
"loras": []
|
||||
}, status=400)
|
||||
|
||||
# Get image URL from response
|
||||
image_url = image_info.get('url')
|
||||
if not image_url:
|
||||
return web.json_response({
|
||||
"error": "No image URL found in Civitai response",
|
||||
"loras": []
|
||||
}, status=400)
|
||||
|
||||
# Download image directly from URL
|
||||
session = await self.civitai_client.session
|
||||
# Create a temporary file to save the downloaded image
|
||||
with tempfile.NamedTemporaryFile(delete=False, suffix='.jpg') as temp_file:
|
||||
temp_path = temp_file.name
|
||||
|
||||
async with session.get(image_url) as response:
|
||||
if response.status != 200:
|
||||
return web.json_response({
|
||||
"error": f"Failed to download image from URL: HTTP {response.status}",
|
||||
"loras": []
|
||||
}, status=400)
|
||||
|
||||
with open(temp_path, 'wb') as f:
|
||||
f.write(await response.read())
|
||||
|
||||
# Use meta field from image_info as metadata
|
||||
if 'meta' in image_info:
|
||||
metadata = image_info['meta']
|
||||
|
||||
else:
|
||||
# Not a Civitai image URL, use the original download method
|
||||
temp_path = download_civitai_image(url)
|
||||
|
||||
if not temp_path:
|
||||
return web.json_response({
|
||||
"error": "Failed to download image from URL",
|
||||
"loras": []
|
||||
}, status=400)
|
||||
|
||||
# Extract metadata from the image using ExifUtils
|
||||
metadata = ExifUtils.extract_image_metadata(temp_path)
|
||||
# If metadata wasn't obtained from Civitai API, extract it from the image
|
||||
if metadata is None:
|
||||
# Extract metadata from the image using ExifUtils
|
||||
metadata = ExifUtils.extract_image_metadata(temp_path)
|
||||
|
||||
# If no metadata found, return a more specific error
|
||||
if not metadata:
|
||||
@@ -282,7 +355,6 @@ class RecipeRoutes:
|
||||
|
||||
# For URL mode, include the image data as base64
|
||||
if is_url_mode and temp_path:
|
||||
import base64
|
||||
with open(temp_path, "rb") as image_file:
|
||||
result["image_base64"] = base64.b64encode(image_file.read()).decode('utf-8')
|
||||
|
||||
@@ -299,7 +371,6 @@ class RecipeRoutes:
|
||||
|
||||
# For URL mode, include the image data as base64
|
||||
if is_url_mode and temp_path:
|
||||
import base64
|
||||
with open(temp_path, "rb") as image_file:
|
||||
result["image_base64"] = base64.b64encode(image_file.read()).decode('utf-8')
|
||||
|
||||
@@ -314,7 +385,6 @@ class RecipeRoutes:
|
||||
|
||||
# For URL mode, include the image data as base64
|
||||
if is_url_mode and temp_path:
|
||||
import base64
|
||||
with open(temp_path, "rb") as image_file:
|
||||
result["image_base64"] = base64.b64encode(image_file.read()).decode('utf-8')
|
||||
|
||||
@@ -322,6 +392,21 @@ class RecipeRoutes:
|
||||
if "error" in result and not result.get("loras"):
|
||||
return web.json_response(result, status=200)
|
||||
|
||||
# Calculate fingerprint from parsed loras
|
||||
from ..utils.utils import calculate_recipe_fingerprint
|
||||
fingerprint = calculate_recipe_fingerprint(result.get("loras", []))
|
||||
|
||||
# Add fingerprint to result
|
||||
result["fingerprint"] = fingerprint
|
||||
|
||||
# Find matching recipes with the same fingerprint
|
||||
matching_recipes = []
|
||||
if fingerprint:
|
||||
matching_recipes = await self.recipe_scanner.find_recipes_by_fingerprint(fingerprint)
|
||||
|
||||
# Add matching recipes to result
|
||||
result["matching_recipes"] = matching_recipes
|
||||
|
||||
return web.json_response(result)
|
||||
|
||||
except Exception as e:
|
||||
@@ -337,7 +422,100 @@ class RecipeRoutes:
|
||||
os.unlink(temp_path)
|
||||
except Exception as e:
|
||||
logger.error(f"Error deleting temporary file: {e}")
|
||||
|
||||
async def analyze_local_image(self, request: web.Request) -> web.Response:
|
||||
"""Analyze a local image file for recipe metadata"""
|
||||
try:
|
||||
# Ensure services are initialized
|
||||
await self.init_services()
|
||||
|
||||
# Get JSON data from request
|
||||
data = await request.json()
|
||||
file_path = data.get('path')
|
||||
|
||||
if not file_path:
|
||||
return web.json_response({
|
||||
'error': 'No file path provided',
|
||||
'loras': []
|
||||
}, status=400)
|
||||
|
||||
# Normalize file path for cross-platform compatibility
|
||||
file_path = os.path.normpath(file_path.strip('"').strip("'"))
|
||||
|
||||
# Validate that the file exists
|
||||
if not os.path.isfile(file_path):
|
||||
return web.json_response({
|
||||
'error': 'File not found',
|
||||
'loras': []
|
||||
}, status=404)
|
||||
|
||||
# Extract metadata from the image using ExifUtils
|
||||
metadata = ExifUtils.extract_image_metadata(file_path)
|
||||
|
||||
# If no metadata found, return error
|
||||
if not metadata:
|
||||
# Get base64 image data
|
||||
with open(file_path, "rb") as image_file:
|
||||
image_base64 = base64.b64encode(image_file.read()).decode('utf-8')
|
||||
|
||||
return web.json_response({
|
||||
"error": "No metadata found in this image",
|
||||
"loras": [], # Return empty loras array to prevent client-side errors
|
||||
"image_base64": image_base64
|
||||
}, status=200)
|
||||
|
||||
# Use the parser factory to get the appropriate parser
|
||||
parser = RecipeParserFactory.create_parser(metadata)
|
||||
|
||||
if parser is None:
|
||||
# Get base64 image data
|
||||
with open(file_path, "rb") as image_file:
|
||||
image_base64 = base64.b64encode(image_file.read()).decode('utf-8')
|
||||
|
||||
return web.json_response({
|
||||
"error": "No parser found for this image",
|
||||
"loras": [], # Return empty loras array to prevent client-side errors
|
||||
"image_base64": image_base64
|
||||
}, status=200)
|
||||
|
||||
# Parse the metadata
|
||||
result = await parser.parse_metadata(
|
||||
metadata,
|
||||
recipe_scanner=self.recipe_scanner,
|
||||
civitai_client=self.civitai_client
|
||||
)
|
||||
|
||||
# Add base64 image data to result
|
||||
with open(file_path, "rb") as image_file:
|
||||
result["image_base64"] = base64.b64encode(image_file.read()).decode('utf-8')
|
||||
|
||||
# Check for errors
|
||||
if "error" in result and not result.get("loras"):
|
||||
return web.json_response(result, status=200)
|
||||
|
||||
# Calculate fingerprint from parsed loras
|
||||
from ..utils.utils import calculate_recipe_fingerprint
|
||||
fingerprint = calculate_recipe_fingerprint(result.get("loras", []))
|
||||
|
||||
# Add fingerprint to result
|
||||
result["fingerprint"] = fingerprint
|
||||
|
||||
# Find matching recipes with the same fingerprint
|
||||
matching_recipes = []
|
||||
if fingerprint:
|
||||
matching_recipes = await self.recipe_scanner.find_recipes_by_fingerprint(fingerprint)
|
||||
|
||||
# Add matching recipes to result
|
||||
result["matching_recipes"] = matching_recipes
|
||||
|
||||
return web.json_response(result)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error analyzing local image: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'error': str(e),
|
||||
'loras': [] # Return empty loras array to prevent client-side errors
|
||||
}, status=500)
|
||||
|
||||
async def save_recipe(self, request: web.Request) -> web.Response:
|
||||
"""Save a recipe to the recipes folder"""
|
||||
@@ -407,7 +585,6 @@ class RecipeRoutes:
|
||||
if not image:
|
||||
if image_base64:
|
||||
# Convert base64 to binary
|
||||
import base64
|
||||
try:
|
||||
# Remove potential data URL prefix
|
||||
if ',' in image_base64:
|
||||
@@ -456,7 +633,7 @@ class RecipeRoutes:
|
||||
with open(image_path, 'wb') as f:
|
||||
f.write(optimized_image)
|
||||
|
||||
# Create the recipe JSON
|
||||
# Create the recipe data structure
|
||||
current_time = time.time()
|
||||
|
||||
# Format loras data according to the recipe.json format
|
||||
@@ -496,6 +673,10 @@ class RecipeRoutes:
|
||||
"clip_skip": raw_metadata.get("clip_skip", "")
|
||||
}
|
||||
|
||||
# Calculate recipe fingerprint
|
||||
from ..utils.utils import calculate_recipe_fingerprint
|
||||
fingerprint = calculate_recipe_fingerprint(loras_data)
|
||||
|
||||
# Create the recipe data structure
|
||||
recipe_data = {
|
||||
"id": recipe_id,
|
||||
@@ -505,13 +686,18 @@ class RecipeRoutes:
|
||||
"created_date": current_time,
|
||||
"base_model": metadata.get("base_model", ""),
|
||||
"loras": loras_data,
|
||||
"gen_params": gen_params
|
||||
"gen_params": gen_params,
|
||||
"fingerprint": fingerprint
|
||||
}
|
||||
|
||||
# Add tags if provided
|
||||
if tags:
|
||||
recipe_data["tags"] = tags
|
||||
|
||||
# Add source_path if provided in metadata
|
||||
if metadata.get("source_path"):
|
||||
recipe_data["source_path"] = metadata.get("source_path")
|
||||
|
||||
# Save the recipe JSON
|
||||
json_filename = f"{recipe_id}.recipe.json"
|
||||
json_path = os.path.join(recipes_dir, json_filename)
|
||||
@@ -521,6 +707,14 @@ class RecipeRoutes:
|
||||
# Add recipe metadata to the image
|
||||
ExifUtils.append_recipe_metadata(image_path, recipe_data)
|
||||
|
||||
# Check for duplicates
|
||||
matching_recipes = []
|
||||
if fingerprint:
|
||||
matching_recipes = await self.recipe_scanner.find_recipes_by_fingerprint(fingerprint)
|
||||
# Remove current recipe from matches
|
||||
if recipe_id in matching_recipes:
|
||||
matching_recipes.remove(recipe_id)
|
||||
|
||||
# Simplified cache update approach
|
||||
# Instead of trying to update the cache directly, just set it to None
|
||||
# to force a refresh on the next get_cached_data call
|
||||
@@ -536,7 +730,8 @@ class RecipeRoutes:
|
||||
'success': True,
|
||||
'recipe_id': recipe_id,
|
||||
'image_path': image_path,
|
||||
'json_path': json_path
|
||||
'json_path': json_path,
|
||||
'matching_recipes': matching_recipes
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
@@ -656,8 +851,8 @@ class RecipeRoutes:
|
||||
logger.error(f"Error retrieving base models: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
'error': str(e)}
|
||||
, status=500)
|
||||
|
||||
async def share_recipe(self, request: web.Request) -> web.Response:
|
||||
"""Process a recipe image for sharing by adding metadata to EXIF"""
|
||||
@@ -786,50 +981,75 @@ class RecipeRoutes:
|
||||
# Ensure services are initialized
|
||||
await self.init_services()
|
||||
|
||||
reader = await request.multipart()
|
||||
# Get metadata using the metadata collector instead of workflow parsing
|
||||
raw_metadata = get_metadata()
|
||||
metadata_dict = MetadataProcessor.to_dict(raw_metadata)
|
||||
|
||||
# Process form data
|
||||
workflow_json = None
|
||||
# Check if we have valid metadata
|
||||
if not metadata_dict:
|
||||
return web.json_response({"error": "No generation metadata found"}, status=400)
|
||||
|
||||
while True:
|
||||
field = await reader.next()
|
||||
if field is None:
|
||||
break
|
||||
# Get the most recent image from metadata registry instead of temp directory
|
||||
if not standalone_mode:
|
||||
metadata_registry = MetadataRegistry()
|
||||
latest_image = metadata_registry.get_first_decoded_image()
|
||||
else:
|
||||
latest_image = None
|
||||
|
||||
if not latest_image:
|
||||
return web.json_response({"error": "No recent images found to use for recipe. Try generating an image first."}, status=400)
|
||||
|
||||
# Convert the image data to bytes - handle tuple and tensor cases
|
||||
logger.debug(f"Image type: {type(latest_image)}")
|
||||
|
||||
try:
|
||||
# Handle the tuple case first
|
||||
if isinstance(latest_image, tuple):
|
||||
# Extract the tensor from the tuple
|
||||
if len(latest_image) > 0:
|
||||
tensor_image = latest_image[0]
|
||||
else:
|
||||
return web.json_response({"error": "Empty image tuple received"}, status=400)
|
||||
else:
|
||||
tensor_image = latest_image
|
||||
|
||||
if field.name == 'workflow_json':
|
||||
workflow_text = await field.text()
|
||||
try:
|
||||
workflow_json = json.loads(workflow_text)
|
||||
except:
|
||||
return web.json_response({"error": "Invalid workflow JSON"}, status=400)
|
||||
# Get the shape info for debugging
|
||||
if hasattr(tensor_image, 'shape'):
|
||||
shape_info = tensor_image.shape
|
||||
logger.debug(f"Tensor shape: {shape_info}, dtype: {tensor_image.dtype}")
|
||||
|
||||
# Convert tensor to numpy array
|
||||
if isinstance(tensor_image, torch.Tensor):
|
||||
image_np = tensor_image.cpu().numpy()
|
||||
else:
|
||||
image_np = np.array(tensor_image)
|
||||
|
||||
# Handle different tensor shapes
|
||||
# Case: (1, 1, H, W, 3) or (1, H, W, 3) - batch or multi-batch
|
||||
if len(image_np.shape) > 3:
|
||||
# Remove batch dimensions until we get to (H, W, 3)
|
||||
while len(image_np.shape) > 3:
|
||||
image_np = image_np[0]
|
||||
|
||||
# If values are in [0, 1] range, convert to [0, 255]
|
||||
if image_np.dtype == np.float32 or image_np.dtype == np.float64:
|
||||
if image_np.max() <= 1.0:
|
||||
image_np = (image_np * 255).astype(np.uint8)
|
||||
|
||||
# Ensure image is in the right format (HWC with RGB channels)
|
||||
if len(image_np.shape) == 3 and image_np.shape[2] == 3:
|
||||
pil_image = Image.fromarray(image_np)
|
||||
img_byte_arr = io.BytesIO()
|
||||
pil_image.save(img_byte_arr, format='PNG')
|
||||
image = img_byte_arr.getvalue()
|
||||
else:
|
||||
return web.json_response({"error": f"Cannot handle this data shape: {image_np.shape}, {image_np.dtype}"}, status=400)
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing image data: {str(e)}", exc_info=True)
|
||||
return web.json_response({"error": f"Error processing image: {str(e)}"}, status=400)
|
||||
|
||||
if not workflow_json:
|
||||
return web.json_response({"error": "Missing workflow JSON"}, status=400)
|
||||
|
||||
# Find the latest image in the temp directory
|
||||
temp_dir = config.temp_directory
|
||||
image_files = []
|
||||
|
||||
for file in os.listdir(temp_dir):
|
||||
if file.lower().endswith(('.png', '.jpg', '.jpeg', '.webp')):
|
||||
file_path = os.path.join(temp_dir, file)
|
||||
image_files.append((file_path, os.path.getmtime(file_path)))
|
||||
|
||||
if not image_files:
|
||||
return web.json_response({"error": "No recent images found to use for recipe"}, status=400)
|
||||
|
||||
# Sort by modification time (newest first)
|
||||
image_files.sort(key=lambda x: x[1], reverse=True)
|
||||
latest_image_path = image_files[0][0]
|
||||
|
||||
# Parse the workflow to extract generation parameters and loras
|
||||
parsed_workflow = self.parser.parse_workflow(workflow_json)
|
||||
|
||||
if not parsed_workflow:
|
||||
return web.json_response({"error": "Could not extract parameters from workflow"}, status=400)
|
||||
|
||||
# Get the lora stack from the parsed workflow
|
||||
lora_stack = parsed_workflow.get("loras", "")
|
||||
# Get the lora stack from the metadata
|
||||
lora_stack = metadata_dict.get("loras", "")
|
||||
|
||||
# Parse the lora stack format: "<lora:name:strength> <lora:name2:strength2> ..."
|
||||
import re
|
||||
@@ -837,7 +1057,7 @@ class RecipeRoutes:
|
||||
|
||||
# Check if any loras were found
|
||||
if not lora_matches:
|
||||
return web.json_response({"error": "No LoRAs found in the workflow"}, status=400)
|
||||
return web.json_response({"error": "No LoRAs found in the generation metadata"}, status=400)
|
||||
|
||||
# Generate recipe name from the first 3 loras (or less if fewer are available)
|
||||
loras_for_name = lora_matches[:3] # Take at most 3 loras for the name
|
||||
@@ -851,10 +1071,6 @@ class RecipeRoutes:
|
||||
|
||||
recipe_name = " ".join(recipe_name_parts)
|
||||
|
||||
# Read the image
|
||||
with open(latest_image_path, 'rb') as f:
|
||||
image = f.read()
|
||||
|
||||
# Create recipes directory if it doesn't exist
|
||||
recipes_dir = self.recipe_scanner.recipes_dir
|
||||
os.makedirs(recipes_dir, exist_ok=True)
|
||||
@@ -922,8 +1138,8 @@ class RecipeRoutes:
|
||||
"created_date": time.time(),
|
||||
"base_model": most_common_base_model,
|
||||
"loras": loras_data,
|
||||
"checkpoint": parsed_workflow.get("checkpoint", ""),
|
||||
"gen_params": {key: value for key, value in parsed_workflow.items()
|
||||
"checkpoint": metadata_dict.get("checkpoint", ""),
|
||||
"gen_params": {key: value for key, value in metadata_dict.items()
|
||||
if key not in ['checkpoint', 'loras']},
|
||||
"loras_stack": lora_stack # Include the original lora stack string
|
||||
}
|
||||
@@ -1050,9 +1266,9 @@ class RecipeRoutes:
|
||||
data = await request.json()
|
||||
|
||||
# Validate required fields
|
||||
if 'title' not in data and 'tags' not in data:
|
||||
if 'title' not in data and 'tags' not in data and 'source_path' not in data:
|
||||
return web.json_response({
|
||||
"error": "At least one field to update must be provided (title or tags)"
|
||||
"error": "At least one field to update must be provided (title or tags or source_path)"
|
||||
}, status=400)
|
||||
|
||||
# Use the recipe scanner's update method
|
||||
@@ -1147,6 +1363,10 @@ class RecipeRoutes:
|
||||
|
||||
if not found:
|
||||
return web.json_response({"error": "Could not find matching deleted LoRA in recipe"}, status=404)
|
||||
|
||||
# Recalculate recipe fingerprint after updating LoRA
|
||||
from ..utils.utils import calculate_recipe_fingerprint
|
||||
recipe_data['fingerprint'] = calculate_recipe_fingerprint(recipe_data.get('loras', []))
|
||||
|
||||
# Save updated recipe
|
||||
with open(recipe_path, 'w', encoding='utf-8') as f:
|
||||
@@ -1162,6 +1382,8 @@ class RecipeRoutes:
|
||||
if cache_item.get('id') == recipe_id:
|
||||
# Replace loras array with updated version
|
||||
cache_item['loras'] = recipe_data['loras']
|
||||
# Update fingerprint in cache
|
||||
cache_item['fingerprint'] = recipe_data['fingerprint']
|
||||
|
||||
# Resort the cache
|
||||
asyncio.create_task(scanner._cache.resort())
|
||||
@@ -1172,11 +1394,20 @@ class RecipeRoutes:
|
||||
if image_path and os.path.exists(image_path):
|
||||
from ..utils.exif_utils import ExifUtils
|
||||
ExifUtils.append_recipe_metadata(image_path, recipe_data)
|
||||
|
||||
# Find other recipes with the same fingerprint
|
||||
matching_recipes = []
|
||||
if 'fingerprint' in recipe_data:
|
||||
matching_recipes = await scanner.find_recipes_by_fingerprint(recipe_data['fingerprint'])
|
||||
# Remove current recipe from matches
|
||||
if recipe_id in matching_recipes:
|
||||
matching_recipes.remove(recipe_id)
|
||||
|
||||
return web.json_response({
|
||||
"success": True,
|
||||
"recipe_id": recipe_id,
|
||||
"updated_lora": updated_lora
|
||||
"updated_lora": updated_lora,
|
||||
"matching_recipes": matching_recipes
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
@@ -1231,3 +1462,171 @@ class RecipeRoutes:
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting recipes for Lora: {str(e)}")
|
||||
return web.json_response({'success': False, 'error': str(e)}, status=500)
|
||||
|
||||
async def scan_recipes(self, request: web.Request) -> web.Response:
|
||||
"""API endpoint for scanning and rebuilding the recipe cache"""
|
||||
try:
|
||||
# Ensure services are initialized
|
||||
await self.init_services()
|
||||
|
||||
# Force refresh the recipe cache
|
||||
logger.info("Manually triggering recipe cache rebuild")
|
||||
await self.recipe_scanner.get_cached_data(force_refresh=True)
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'message': 'Recipe cache refreshed successfully'
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error refreshing recipe cache: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def find_duplicates(self, request: web.Request) -> web.Response:
|
||||
"""Find all duplicate recipes based on fingerprints"""
|
||||
try:
|
||||
# Ensure services are initialized
|
||||
await self.init_services()
|
||||
|
||||
# Get all duplicate recipes
|
||||
duplicate_groups = await self.recipe_scanner.find_all_duplicate_recipes()
|
||||
|
||||
# Create response data with additional recipe information
|
||||
response_data = []
|
||||
|
||||
for fingerprint, recipe_ids in duplicate_groups.items():
|
||||
# Skip groups with only one recipe (not duplicates)
|
||||
if len(recipe_ids) <= 1:
|
||||
continue
|
||||
|
||||
# Get recipe details for each recipe in the group
|
||||
recipes = []
|
||||
for recipe_id in recipe_ids:
|
||||
recipe = await self.recipe_scanner.get_recipe_by_id(recipe_id)
|
||||
if recipe:
|
||||
# Add only needed fields to keep response size manageable
|
||||
recipes.append({
|
||||
'id': recipe.get('id'),
|
||||
'title': recipe.get('title'),
|
||||
'file_url': recipe.get('file_url') or self._format_recipe_file_url(recipe.get('file_path', '')),
|
||||
'modified': recipe.get('modified'),
|
||||
'created_date': recipe.get('created_date'),
|
||||
'lora_count': len(recipe.get('loras', [])),
|
||||
})
|
||||
|
||||
# Only include groups with at least 2 valid recipes
|
||||
if len(recipes) >= 2:
|
||||
# Sort recipes by modified date (newest first)
|
||||
recipes.sort(key=lambda x: x.get('modified', 0), reverse=True)
|
||||
|
||||
response_data.append({
|
||||
'fingerprint': fingerprint,
|
||||
'count': len(recipes),
|
||||
'recipes': recipes
|
||||
})
|
||||
|
||||
# Sort groups by count (highest first)
|
||||
response_data.sort(key=lambda x: x['count'], reverse=True)
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'duplicate_groups': response_data
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error finding duplicate recipes: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def bulk_delete(self, request: web.Request) -> web.Response:
|
||||
"""Delete multiple recipes by ID"""
|
||||
try:
|
||||
# Ensure services are initialized
|
||||
await self.init_services()
|
||||
|
||||
# Parse request data
|
||||
data = await request.json()
|
||||
recipe_ids = data.get('recipe_ids', [])
|
||||
|
||||
if not recipe_ids:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'No recipe IDs provided'
|
||||
}, status=400)
|
||||
|
||||
# Get recipes directory
|
||||
recipes_dir = self.recipe_scanner.recipes_dir
|
||||
if not recipes_dir or not os.path.exists(recipes_dir):
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Recipes directory not found'
|
||||
}, status=404)
|
||||
|
||||
# Track deleted and failed recipes
|
||||
deleted_recipes = []
|
||||
failed_recipes = []
|
||||
|
||||
# Process each recipe ID
|
||||
for recipe_id in recipe_ids:
|
||||
# Find recipe JSON file
|
||||
recipe_json_path = os.path.join(recipes_dir, f"{recipe_id}.recipe.json")
|
||||
|
||||
if not os.path.exists(recipe_json_path):
|
||||
failed_recipes.append({
|
||||
'id': recipe_id,
|
||||
'reason': 'Recipe not found'
|
||||
})
|
||||
continue
|
||||
|
||||
try:
|
||||
# Load recipe data to get image path
|
||||
with open(recipe_json_path, 'r', encoding='utf-8') as f:
|
||||
recipe_data = json.load(f)
|
||||
|
||||
# Get image path
|
||||
image_path = recipe_data.get('file_path')
|
||||
|
||||
# Delete recipe JSON file
|
||||
os.remove(recipe_json_path)
|
||||
|
||||
# Delete recipe image if it exists
|
||||
if image_path and os.path.exists(image_path):
|
||||
os.remove(image_path)
|
||||
|
||||
deleted_recipes.append(recipe_id)
|
||||
|
||||
except Exception as e:
|
||||
failed_recipes.append({
|
||||
'id': recipe_id,
|
||||
'reason': str(e)
|
||||
})
|
||||
|
||||
# Update cache if any recipes were deleted
|
||||
if deleted_recipes and self.recipe_scanner._cache is not None:
|
||||
# Remove deleted recipes from raw_data
|
||||
self.recipe_scanner._cache.raw_data = [
|
||||
r for r in self.recipe_scanner._cache.raw_data
|
||||
if r.get('id') not in deleted_recipes
|
||||
]
|
||||
# Resort the cache
|
||||
asyncio.create_task(self.recipe_scanner._cache.resort())
|
||||
logger.info(f"Removed {len(deleted_recipes)} recipes from cache")
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'deleted': deleted_recipes,
|
||||
'failed': failed_recipes,
|
||||
'total_deleted': len(deleted_recipes),
|
||||
'total_failed': len(failed_recipes)
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error performing bulk delete: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
@@ -150,11 +150,16 @@ class UpdateRoutes:
|
||||
"""
|
||||
Compare two semantic version strings
|
||||
Returns True if version2 is newer than version1
|
||||
Ignores any suffixes after '-' (e.g., -bugfix, -alpha)
|
||||
"""
|
||||
try:
|
||||
# Clean version strings - remove any suffix after '-'
|
||||
v1_clean = version1.split('-')[0]
|
||||
v2_clean = version2.split('-')[0]
|
||||
|
||||
# Split versions into components
|
||||
v1_parts = [int(x) for x in version1.split('.')]
|
||||
v2_parts = [int(x) for x in version2.split('.')]
|
||||
v1_parts = [int(x) for x in v1_clean.split('.')]
|
||||
v2_parts = [int(x) for x in v2_clean.split('.')]
|
||||
|
||||
# Ensure both have 3 components (major.minor.patch)
|
||||
while len(v1_parts) < 3:
|
||||
|
||||
@@ -34,6 +34,7 @@ class CivitaiClient:
|
||||
'User-Agent': 'ComfyUI-LoRA-Manager/1.0'
|
||||
}
|
||||
self._session = None
|
||||
self._session_created_at = None
|
||||
# Set default buffer size to 1MB for higher throughput
|
||||
self.chunk_size = 1024 * 1024
|
||||
|
||||
@@ -44,8 +45,8 @@ class CivitaiClient:
|
||||
# Optimize TCP connection parameters
|
||||
connector = aiohttp.TCPConnector(
|
||||
ssl=True,
|
||||
limit=10, # Increase parallel connections
|
||||
ttl_dns_cache=300, # DNS cache time
|
||||
limit=3, # Further reduced from 5 to 3
|
||||
ttl_dns_cache=0, # Disabled DNS caching completely
|
||||
force_close=False, # Keep connections for reuse
|
||||
enable_cleanup_closed=True
|
||||
)
|
||||
@@ -57,7 +58,18 @@ class CivitaiClient:
|
||||
trust_env=trust_env,
|
||||
timeout=timeout
|
||||
)
|
||||
self._session_created_at = datetime.now()
|
||||
return self._session
|
||||
|
||||
async def _ensure_fresh_session(self):
|
||||
"""Refresh session if it's been open too long"""
|
||||
if self._session is not None:
|
||||
if not hasattr(self, '_session_created_at') or \
|
||||
(datetime.now() - self._session_created_at).total_seconds() > 300: # 5 minutes
|
||||
await self.close()
|
||||
self._session = None
|
||||
|
||||
return await self.session
|
||||
|
||||
def _parse_content_disposition(self, header: str) -> str:
|
||||
"""Parse filename from content-disposition header"""
|
||||
@@ -103,13 +115,15 @@ class CivitaiClient:
|
||||
Returns:
|
||||
Tuple[bool, str]: (success, save_path or error message)
|
||||
"""
|
||||
session = await self.session
|
||||
logger.debug(f"Resolving DNS for: {url}")
|
||||
session = await self._ensure_fresh_session()
|
||||
try:
|
||||
headers = self._get_request_headers()
|
||||
|
||||
# Add Range header to allow resumable downloads
|
||||
headers['Accept-Encoding'] = 'identity' # Disable compression for better chunked downloads
|
||||
|
||||
logger.debug(f"Starting download from: {url}")
|
||||
async with session.get(url, headers=headers, allow_redirects=True) as response:
|
||||
if response.status != 200:
|
||||
# Handle 401 unauthorized responses
|
||||
@@ -124,6 +138,7 @@ class CivitaiClient:
|
||||
return False, "Access forbidden: You don't have permission to download this file."
|
||||
|
||||
# Generic error response for other status codes
|
||||
logger.error(f"Download failed for {url} with status {response.status}")
|
||||
return False, f"Download failed with status {response.status}"
|
||||
|
||||
# Get filename from content-disposition header
|
||||
@@ -170,7 +185,7 @@ class CivitaiClient:
|
||||
|
||||
async def get_model_by_hash(self, model_hash: str) -> Optional[Dict]:
|
||||
try:
|
||||
session = await self.session
|
||||
session = await self._ensure_fresh_session()
|
||||
async with session.get(f"{self.base_url}/model-versions/by-hash/{model_hash}") as response:
|
||||
if response.status == 200:
|
||||
return await response.json()
|
||||
@@ -181,7 +196,7 @@ class CivitaiClient:
|
||||
|
||||
async def download_preview_image(self, image_url: str, save_path: str):
|
||||
try:
|
||||
session = await self.session
|
||||
session = await self._ensure_fresh_session()
|
||||
async with session.get(image_url) as response:
|
||||
if response.status == 200:
|
||||
content = await response.read()
|
||||
@@ -196,7 +211,7 @@ class CivitaiClient:
|
||||
async def get_model_versions(self, model_id: str) -> List[Dict]:
|
||||
"""Get all versions of a model with local availability info"""
|
||||
try:
|
||||
session = await self.session # 等待获取 session
|
||||
session = await self._ensure_fresh_session() # Use fresh session
|
||||
async with session.get(f"{self.base_url}/models/{model_id}") as response:
|
||||
if response.status != 200:
|
||||
return None
|
||||
@@ -210,23 +225,49 @@ class CivitaiClient:
|
||||
logger.error(f"Error fetching model versions: {e}")
|
||||
return None
|
||||
|
||||
async def get_model_version_info(self, version_id: str) -> Optional[Dict]:
|
||||
"""Fetch model version metadata from Civitai"""
|
||||
async def get_model_version_info(self, version_id: str) -> Tuple[Optional[Dict], Optional[str]]:
|
||||
"""Fetch model version metadata from Civitai
|
||||
|
||||
Args:
|
||||
version_id: The Civitai model version ID
|
||||
|
||||
Returns:
|
||||
Tuple[Optional[Dict], Optional[str]]: A tuple containing:
|
||||
- The model version data or None if not found
|
||||
- An error message if there was an error, or None on success
|
||||
"""
|
||||
try:
|
||||
session = await self.session
|
||||
session = await self._ensure_fresh_session()
|
||||
url = f"{self.base_url}/model-versions/{version_id}"
|
||||
headers = self._get_request_headers()
|
||||
|
||||
logger.debug(f"Resolving DNS for model version info: {url}")
|
||||
async with session.get(url, headers=headers) as response:
|
||||
if response.status == 200:
|
||||
return await response.json()
|
||||
return None
|
||||
logger.debug(f"Successfully fetched model version info for: {version_id}")
|
||||
return await response.json(), None
|
||||
|
||||
# Handle specific error cases
|
||||
if response.status == 404:
|
||||
# Try to parse the error message
|
||||
try:
|
||||
error_data = await response.json()
|
||||
error_msg = error_data.get('error', f"Model not found (status 404)")
|
||||
logger.warning(f"Model version not found: {version_id} - {error_msg}")
|
||||
return None, error_msg
|
||||
except:
|
||||
return None, "Model not found (status 404)"
|
||||
|
||||
# Other error cases
|
||||
logger.error(f"Failed to fetch model info for {version_id} (status {response.status})")
|
||||
return None, f"Failed to fetch model info (status {response.status})"
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching model version info: {e}")
|
||||
return None
|
||||
error_msg = f"Error fetching model version info: {e}"
|
||||
logger.error(error_msg)
|
||||
return None, error_msg
|
||||
|
||||
async def get_model_metadata(self, model_id: str) -> Tuple[Optional[Dict], int]:
|
||||
"""Fetch model metadata (description and tags) from Civitai API
|
||||
"""Fetch model metadata (description, tags, and creator info) from Civitai API
|
||||
|
||||
Args:
|
||||
model_id: The Civitai model ID
|
||||
@@ -237,7 +278,7 @@ class CivitaiClient:
|
||||
- The HTTP status code from the request
|
||||
"""
|
||||
try:
|
||||
session = await self.session
|
||||
session = await self._ensure_fresh_session()
|
||||
headers = self._get_request_headers()
|
||||
url = f"{self.base_url}/models/{model_id}"
|
||||
|
||||
@@ -253,10 +294,14 @@ class CivitaiClient:
|
||||
# Extract relevant metadata
|
||||
metadata = {
|
||||
"description": data.get("description") or "No model description available",
|
||||
"tags": data.get("tags", [])
|
||||
"tags": data.get("tags", []),
|
||||
"creator": {
|
||||
"username": data.get("creator", {}).get("username"),
|
||||
"image": data.get("creator", {}).get("image")
|
||||
}
|
||||
}
|
||||
|
||||
if metadata["description"] or metadata["tags"]:
|
||||
if metadata["description"] or metadata["tags"] or metadata["creator"]["username"]:
|
||||
return metadata, status_code
|
||||
else:
|
||||
logger.warning(f"No metadata found for model {model_id}")
|
||||
@@ -281,10 +326,11 @@ class CivitaiClient:
|
||||
async def _get_hash_from_civitai(self, model_version_id: str) -> Optional[str]:
|
||||
"""Get hash from Civitai API"""
|
||||
try:
|
||||
if not self._session:
|
||||
session = await self._ensure_fresh_session()
|
||||
if not session:
|
||||
return None
|
||||
|
||||
version_info = await self._session.get(f"{self.base_url}/model-versions/{model_version_id}")
|
||||
version_info = await session.get(f"{self.base_url}/model-versions/{model_version_id}")
|
||||
|
||||
if not version_info or not version_info.json().get('files'):
|
||||
return None
|
||||
@@ -300,3 +346,34 @@ class CivitaiClient:
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting hash from Civitai: {e}")
|
||||
return None
|
||||
|
||||
async def get_image_info(self, image_id: str) -> Optional[Dict]:
|
||||
"""Fetch image information from Civitai API
|
||||
|
||||
Args:
|
||||
image_id: The Civitai image ID
|
||||
|
||||
Returns:
|
||||
Optional[Dict]: The image data or None if not found
|
||||
"""
|
||||
try:
|
||||
session = await self._ensure_fresh_session()
|
||||
headers = self._get_request_headers()
|
||||
url = f"{self.base_url}/images?imageId={image_id}&nsfw=X"
|
||||
|
||||
logger.debug(f"Fetching image info for ID: {image_id}")
|
||||
async with session.get(url, headers=headers) as response:
|
||||
if response.status == 200:
|
||||
data = await response.json()
|
||||
if data and "items" in data and len(data["items"]) > 0:
|
||||
logger.debug(f"Successfully fetched image info for ID: {image_id}")
|
||||
return data["items"][0]
|
||||
logger.warning(f"No image found with ID: {image_id}")
|
||||
return None
|
||||
|
||||
logger.error(f"Failed to fetch image info for ID: {image_id} (status {response.status})")
|
||||
return None
|
||||
except Exception as e:
|
||||
error_msg = f"Error fetching image info: {e}"
|
||||
logger.error(error_msg)
|
||||
return None
|
||||
|
||||
@@ -2,8 +2,7 @@ import logging
|
||||
import os
|
||||
import json
|
||||
import asyncio
|
||||
from typing import Optional, Dict, Any
|
||||
from .civitai_client import CivitaiClient
|
||||
from typing import Dict
|
||||
from ..utils.models import LoraMetadata, CheckpointMetadata
|
||||
from ..utils.constants import CARD_PREVIEW_WIDTH
|
||||
from ..utils.exif_utils import ExifUtils
|
||||
@@ -86,21 +85,24 @@ class DownloadManager:
|
||||
|
||||
# Get version info based on the provided identifier
|
||||
version_info = None
|
||||
error_msg = None
|
||||
|
||||
if download_url:
|
||||
# Extract version ID from download URL
|
||||
version_id = download_url.split('/')[-1]
|
||||
version_info = await civitai_client.get_model_version_info(version_id)
|
||||
elif model_version_id:
|
||||
# Use model version ID directly
|
||||
version_info = await civitai_client.get_model_version_info(model_version_id)
|
||||
elif model_hash:
|
||||
if model_hash:
|
||||
# Get model by hash
|
||||
version_info = await civitai_client.get_model_by_hash(model_hash)
|
||||
elif model_version_id:
|
||||
# Use model version ID directly
|
||||
version_info, error_msg = await civitai_client.get_model_version_info(model_version_id)
|
||||
elif download_url:
|
||||
# Extract version ID from download URL
|
||||
version_id = download_url.split('/')[-1]
|
||||
version_info, error_msg = await civitai_client.get_model_version_info(version_id)
|
||||
|
||||
|
||||
if not version_info:
|
||||
return {'success': False, 'error': 'Failed to fetch model metadata'}
|
||||
if error_msg and "model not found" in error_msg.lower():
|
||||
return {'success': False, 'error': f'Model not found on Civitai: {error_msg}'}
|
||||
return {'success': False, 'error': error_msg or 'Failed to fetch model metadata'}
|
||||
|
||||
# Check if this is an early access model
|
||||
if version_info.get('earlyAccessEndsAt'):
|
||||
@@ -133,15 +135,9 @@ class DownloadManager:
|
||||
# 3. Prepare download
|
||||
file_name = file_info['name']
|
||||
save_path = os.path.join(save_dir, file_name)
|
||||
file_size = file_info.get('sizeKB', 0) * 1024
|
||||
|
||||
# 4. Notify file monitor - use normalized path and file size
|
||||
file_monitor = await self._get_lora_monitor() if model_type == "lora" else await self._get_checkpoint_monitor()
|
||||
if file_monitor and file_monitor.handler:
|
||||
file_monitor.handler.add_ignore_path(
|
||||
save_path.replace(os.sep, '/'),
|
||||
file_size
|
||||
)
|
||||
# file monitor is despreted, so we don't need to use it
|
||||
|
||||
# 5. Prepare metadata based on model type
|
||||
if model_type == "checkpoint":
|
||||
@@ -151,7 +147,7 @@ class DownloadManager:
|
||||
metadata = LoraMetadata.from_civitai_info(version_info, file_info, save_path)
|
||||
logger.info(f"Creating LoraMetadata for {file_name}")
|
||||
|
||||
# 5.1 Get and update model tags and description
|
||||
# 5.1 Get and update model tags, description and creator info
|
||||
model_id = version_info.get('modelId')
|
||||
if model_id:
|
||||
model_metadata, _ = await civitai_client.get_model_metadata(str(model_id))
|
||||
@@ -160,6 +156,8 @@ class DownloadManager:
|
||||
metadata.tags = model_metadata.get("tags", [])
|
||||
if model_metadata.get("description"):
|
||||
metadata.modelDescription = model_metadata.get("description", "")
|
||||
if model_metadata.get("creator"):
|
||||
metadata.civitai["creator"] = model_metadata.get("creator")
|
||||
|
||||
# 6. Start download process
|
||||
result = await self._execute_download(
|
||||
@@ -202,7 +200,7 @@ class DownloadManager:
|
||||
# Check if it's a video or an image
|
||||
is_video = images[0].get('type') == 'video'
|
||||
|
||||
if is_video:
|
||||
if (is_video):
|
||||
# For videos, use .mp4 extension
|
||||
preview_ext = '.mp4'
|
||||
preview_path = os.path.splitext(save_path)[0] + preview_ext
|
||||
@@ -229,7 +227,7 @@ class DownloadManager:
|
||||
target_width=CARD_PREVIEW_WIDTH,
|
||||
format='webp',
|
||||
quality=85,
|
||||
preserve_metadata=True
|
||||
preserve_metadata=False
|
||||
)
|
||||
|
||||
# Save the optimized image
|
||||
@@ -282,17 +280,11 @@ class DownloadManager:
|
||||
scanner = await self._get_lora_scanner()
|
||||
logger.info(f"Updating lora cache for {save_path}")
|
||||
|
||||
cache = await scanner.get_cached_data()
|
||||
# Convert metadata to dictionary
|
||||
metadata_dict = metadata.to_dict()
|
||||
metadata_dict['folder'] = relative_path
|
||||
cache.raw_data.append(metadata_dict)
|
||||
await cache.resort()
|
||||
all_folders = set(cache.folders)
|
||||
all_folders.add(relative_path)
|
||||
cache.folders = sorted(list(all_folders), key=lambda x: x.lower())
|
||||
|
||||
# Update the hash index with the new model entry
|
||||
scanner._hash_index.add_entry(metadata_dict['sha256'], metadata_dict['file_path'])
|
||||
|
||||
# Add model to cache and save to disk in a single operation
|
||||
await scanner.add_model_to_cache(metadata_dict, relative_path)
|
||||
|
||||
# Report 100% completion
|
||||
if progress_callback:
|
||||
|
||||
@@ -408,7 +408,7 @@ class BaseFileMonitor:
|
||||
def start(self):
|
||||
"""Start file monitoring"""
|
||||
if not ENABLE_FILE_MONITORING:
|
||||
logger.info("File monitoring is disabled via ENABLE_FILE_MONITORING setting")
|
||||
logger.debug("File monitoring is disabled via ENABLE_FILE_MONITORING setting")
|
||||
return
|
||||
|
||||
for path in self.monitor_paths:
|
||||
@@ -525,18 +525,18 @@ class CheckpointFileMonitor(BaseFileMonitor):
|
||||
def start(self):
|
||||
"""Override start to check global enable flag"""
|
||||
if not ENABLE_FILE_MONITORING:
|
||||
logger.info("Checkpoint file monitoring is disabled via ENABLE_FILE_MONITORING setting")
|
||||
logger.debug("Checkpoint file monitoring is disabled via ENABLE_FILE_MONITORING setting")
|
||||
return
|
||||
|
||||
logger.info("Checkpoint file monitoring is temporarily disabled")
|
||||
logger.debug("Checkpoint file monitoring is temporarily disabled")
|
||||
# Skip the actual monitoring setup
|
||||
pass
|
||||
|
||||
async def initialize_paths(self):
|
||||
"""Initialize monitor paths from scanner - currently disabled"""
|
||||
if not ENABLE_FILE_MONITORING:
|
||||
logger.info("Checkpoint path initialization skipped (monitoring disabled)")
|
||||
logger.debug("Checkpoint path initialization skipped (monitoring disabled)")
|
||||
return
|
||||
|
||||
logger.info("Checkpoint file path initialization skipped (monitoring disabled)")
|
||||
logger.debug("Checkpoint file path initialization skipped (monitoring disabled)")
|
||||
pass
|
||||
@@ -2,6 +2,7 @@ import asyncio
|
||||
from typing import List, Dict
|
||||
from dataclasses import dataclass
|
||||
from operator import itemgetter
|
||||
from natsort import natsorted
|
||||
|
||||
@dataclass
|
||||
class LoraCache:
|
||||
@@ -17,7 +18,7 @@ class LoraCache:
|
||||
async def resort(self, name_only: bool = False):
|
||||
"""Resort all cached data views"""
|
||||
async with self._lock:
|
||||
self.sorted_by_name = sorted(
|
||||
self.sorted_by_name = natsorted(
|
||||
self.raw_data,
|
||||
key=lambda x: x['model_name'].lower() # Case-insensitive sort
|
||||
)
|
||||
|
||||
@@ -1,54 +0,0 @@
|
||||
from typing import Dict, Optional
|
||||
import logging
|
||||
from dataclasses import dataclass
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@dataclass
|
||||
class LoraHashIndex:
|
||||
"""Index for mapping LoRA file hashes to their file paths"""
|
||||
|
||||
def __init__(self):
|
||||
self._hash_to_path: Dict[str, str] = {}
|
||||
|
||||
def add_entry(self, sha256: str, file_path: str) -> None:
|
||||
"""Add or update a hash -> path mapping"""
|
||||
if not sha256 or not file_path:
|
||||
return
|
||||
# Always store lowercase hashes for consistency
|
||||
self._hash_to_path[sha256.lower()] = file_path
|
||||
|
||||
def remove_entry(self, sha256: str) -> None:
|
||||
"""Remove a hash entry"""
|
||||
if sha256:
|
||||
self._hash_to_path.pop(sha256.lower(), None)
|
||||
|
||||
def remove_by_path(self, file_path: str) -> None:
|
||||
"""Remove entry by file path"""
|
||||
for sha256, path in list(self._hash_to_path.items()):
|
||||
if path == file_path:
|
||||
del self._hash_to_path[sha256]
|
||||
break
|
||||
|
||||
def get_path(self, sha256: str) -> Optional[str]:
|
||||
"""Get file path for a given hash"""
|
||||
if not sha256:
|
||||
return None
|
||||
return self._hash_to_path.get(sha256.lower())
|
||||
|
||||
def get_hash(self, file_path: str) -> Optional[str]:
|
||||
"""Get hash for a given file path"""
|
||||
for sha256, path in self._hash_to_path.items():
|
||||
if path == file_path:
|
||||
return sha256
|
||||
return None
|
||||
|
||||
def has_hash(self, sha256: str) -> bool:
|
||||
"""Check if hash exists in index"""
|
||||
if not sha256:
|
||||
return False
|
||||
return sha256.lower() in self._hash_to_path
|
||||
|
||||
def clear(self) -> None:
|
||||
"""Clear all entries"""
|
||||
self._hash_to_path.clear()
|
||||
@@ -4,12 +4,13 @@ import logging
|
||||
import asyncio
|
||||
import shutil
|
||||
import time
|
||||
import re
|
||||
from typing import List, Dict, Optional, Set
|
||||
|
||||
from ..utils.models import LoraMetadata
|
||||
from ..config import config
|
||||
from .model_scanner import ModelScanner
|
||||
from .lora_hash_index import LoraHashIndex
|
||||
from .model_hash_index import ModelHashIndex # Changed from LoraHashIndex to ModelHashIndex
|
||||
from .settings_manager import settings
|
||||
from ..utils.constants import NSFW_LEVELS
|
||||
from ..utils.utils import fuzzy_match
|
||||
@@ -35,12 +36,12 @@ class LoraScanner(ModelScanner):
|
||||
# Define supported file extensions
|
||||
file_extensions = {'.safetensors'}
|
||||
|
||||
# Initialize parent class
|
||||
# Initialize parent class with ModelHashIndex
|
||||
super().__init__(
|
||||
model_type="lora",
|
||||
model_class=LoraMetadata,
|
||||
file_extensions=file_extensions,
|
||||
hash_index=LoraHashIndex()
|
||||
hash_index=ModelHashIndex() # Changed from LoraHashIndex to ModelHashIndex
|
||||
)
|
||||
self._initialized = True
|
||||
|
||||
@@ -122,7 +123,8 @@ class LoraScanner(ModelScanner):
|
||||
async def get_paginated_data(self, page: int, page_size: int, sort_by: str = 'name',
|
||||
folder: str = None, search: str = None, fuzzy_search: bool = False,
|
||||
base_models: list = None, tags: list = None,
|
||||
search_options: dict = None, hash_filters: dict = None) -> Dict:
|
||||
search_options: dict = None, hash_filters: dict = None,
|
||||
favorites_only: bool = False, first_letter: str = None) -> Dict:
|
||||
"""Get paginated and filtered lora data
|
||||
|
||||
Args:
|
||||
@@ -136,6 +138,8 @@ class LoraScanner(ModelScanner):
|
||||
tags: List of tags to filter by
|
||||
search_options: Dictionary with search options (filename, modelname, tags, recursive)
|
||||
hash_filters: Dictionary with hash filtering options (single_hash or multiple_hashes)
|
||||
favorites_only: Filter for favorite models only
|
||||
first_letter: Filter by first letter of model name
|
||||
"""
|
||||
cache = await self.get_cached_data()
|
||||
|
||||
@@ -194,6 +198,17 @@ class LoraScanner(ModelScanner):
|
||||
if not lora.get('preview_nsfw_level') or lora.get('preview_nsfw_level') < NSFW_LEVELS['R']
|
||||
]
|
||||
|
||||
# Apply favorites filtering if enabled
|
||||
if favorites_only:
|
||||
filtered_data = [
|
||||
lora for lora in filtered_data
|
||||
if lora.get('favorite', False) is True
|
||||
]
|
||||
|
||||
# Apply first letter filtering
|
||||
if first_letter:
|
||||
filtered_data = self._filter_by_first_letter(filtered_data, first_letter)
|
||||
|
||||
# Apply folder filtering
|
||||
if folder is not None:
|
||||
if search_options.get('recursive', False):
|
||||
@@ -264,6 +279,101 @@ class LoraScanner(ModelScanner):
|
||||
|
||||
return result
|
||||
|
||||
def _filter_by_first_letter(self, data, letter):
|
||||
"""Filter data by first letter of model name
|
||||
|
||||
Special handling:
|
||||
- '#': Numbers (0-9)
|
||||
- '@': Special characters (not alphanumeric)
|
||||
- '漢': CJK characters
|
||||
"""
|
||||
filtered_data = []
|
||||
|
||||
for lora in data:
|
||||
model_name = lora.get('model_name', '')
|
||||
if not model_name:
|
||||
continue
|
||||
|
||||
first_char = model_name[0].upper()
|
||||
|
||||
if letter == '#' and first_char.isdigit():
|
||||
filtered_data.append(lora)
|
||||
elif letter == '@' and not first_char.isalnum():
|
||||
# Special characters (not alphanumeric)
|
||||
filtered_data.append(lora)
|
||||
elif letter == '漢' and self._is_cjk_character(first_char):
|
||||
# CJK characters
|
||||
filtered_data.append(lora)
|
||||
elif letter.upper() == first_char:
|
||||
# Regular alphabet matching
|
||||
filtered_data.append(lora)
|
||||
|
||||
return filtered_data
|
||||
|
||||
def _is_cjk_character(self, char):
|
||||
"""Check if character is a CJK character"""
|
||||
# Define Unicode ranges for CJK characters
|
||||
cjk_ranges = [
|
||||
(0x4E00, 0x9FFF), # CJK Unified Ideographs
|
||||
(0x3400, 0x4DBF), # CJK Unified Ideographs Extension A
|
||||
(0x20000, 0x2A6DF), # CJK Unified Ideographs Extension B
|
||||
(0x2A700, 0x2B73F), # CJK Unified Ideographs Extension C
|
||||
(0x2B740, 0x2B81F), # CJK Unified Ideographs Extension D
|
||||
(0x2B820, 0x2CEAF), # CJK Unified Ideographs Extension E
|
||||
(0x2CEB0, 0x2EBEF), # CJK Unified Ideographs Extension F
|
||||
(0x30000, 0x3134F), # CJK Unified Ideographs Extension G
|
||||
(0xF900, 0xFAFF), # CJK Compatibility Ideographs
|
||||
(0x3300, 0x33FF), # CJK Compatibility
|
||||
(0x3200, 0x32FF), # Enclosed CJK Letters and Months
|
||||
(0x3100, 0x312F), # Bopomofo
|
||||
(0x31A0, 0x31BF), # Bopomofo Extended
|
||||
(0x3040, 0x309F), # Hiragana
|
||||
(0x30A0, 0x30FF), # Katakana
|
||||
(0x31F0, 0x31FF), # Katakana Phonetic Extensions
|
||||
(0xAC00, 0xD7AF), # Hangul Syllables
|
||||
(0x1100, 0x11FF), # Hangul Jamo
|
||||
(0xA960, 0xA97F), # Hangul Jamo Extended-A
|
||||
(0xD7B0, 0xD7FF), # Hangul Jamo Extended-B
|
||||
]
|
||||
|
||||
code_point = ord(char)
|
||||
return any(start <= code_point <= end for start, end in cjk_ranges)
|
||||
|
||||
async def get_letter_counts(self):
|
||||
"""Get count of models for each letter of the alphabet"""
|
||||
cache = await self.get_cached_data()
|
||||
data = cache.sorted_by_name
|
||||
|
||||
# Define letter categories
|
||||
letters = {
|
||||
'#': 0, # Numbers
|
||||
'A': 0, 'B': 0, 'C': 0, 'D': 0, 'E': 0, 'F': 0, 'G': 0, 'H': 0,
|
||||
'I': 0, 'J': 0, 'K': 0, 'L': 0, 'M': 0, 'N': 0, 'O': 0, 'P': 0,
|
||||
'Q': 0, 'R': 0, 'S': 0, 'T': 0, 'U': 0, 'V': 0, 'W': 0, 'X': 0,
|
||||
'Y': 0, 'Z': 0,
|
||||
'@': 0, # Special characters
|
||||
'漢': 0 # CJK characters
|
||||
}
|
||||
|
||||
# Count models for each letter
|
||||
for lora in data:
|
||||
model_name = lora.get('model_name', '')
|
||||
if not model_name:
|
||||
continue
|
||||
|
||||
first_char = model_name[0].upper()
|
||||
|
||||
if first_char.isdigit():
|
||||
letters['#'] += 1
|
||||
elif first_char in letters:
|
||||
letters[first_char] += 1
|
||||
elif self._is_cjk_character(first_char):
|
||||
letters['漢'] += 1
|
||||
elif not first_char.isalnum():
|
||||
letters['@'] += 1
|
||||
|
||||
return letters
|
||||
|
||||
async def _update_metadata_paths(self, metadata_path: str, lora_path: str) -> Dict:
|
||||
"""Update file paths in metadata file"""
|
||||
try:
|
||||
|
||||
@@ -2,6 +2,7 @@ import asyncio
|
||||
from typing import List, Dict
|
||||
from dataclasses import dataclass
|
||||
from operator import itemgetter
|
||||
from natsort import natsorted
|
||||
|
||||
@dataclass
|
||||
class ModelCache:
|
||||
@@ -17,7 +18,7 @@ class ModelCache:
|
||||
async def resort(self, name_only: bool = False):
|
||||
"""Resort all cached data views"""
|
||||
async with self._lock:
|
||||
self.sorted_by_name = sorted(
|
||||
self.sorted_by_name = natsorted(
|
||||
self.raw_data,
|
||||
key=lambda x: x['model_name'].lower() # Case-insensitive sort
|
||||
)
|
||||
|
||||
@@ -1,11 +1,15 @@
|
||||
from typing import Dict, Optional, Set
|
||||
from typing import Dict, Optional, Set, List
|
||||
import os
|
||||
|
||||
class ModelHashIndex:
|
||||
"""Index for looking up models by hash or path"""
|
||||
"""Index for looking up models by hash or filename"""
|
||||
|
||||
def __init__(self):
|
||||
self._hash_to_path: Dict[str, str] = {}
|
||||
self._path_to_hash: Dict[str, str] = {}
|
||||
self._filename_to_hash: Dict[str, str] = {}
|
||||
# New data structures for tracking duplicates
|
||||
self._duplicate_hashes: Dict[str, List[str]] = {} # sha256 -> list of paths
|
||||
self._duplicate_filenames: Dict[str, List[str]] = {} # filename -> list of paths
|
||||
|
||||
def add_entry(self, sha256: str, file_path: str) -> None:
|
||||
"""Add or update hash index entry"""
|
||||
@@ -15,38 +19,170 @@ class ModelHashIndex:
|
||||
# Ensure hash is lowercase for consistency
|
||||
sha256 = sha256.lower()
|
||||
|
||||
# Extract filename without extension
|
||||
filename = self._get_filename_from_path(file_path)
|
||||
|
||||
# Track duplicates by hash
|
||||
if sha256 in self._hash_to_path:
|
||||
old_path = self._hash_to_path[sha256]
|
||||
if old_path != file_path: # Only record if it's actually a different path
|
||||
if sha256 not in self._duplicate_hashes:
|
||||
self._duplicate_hashes[sha256] = [old_path]
|
||||
if file_path not in self._duplicate_hashes.get(sha256, []):
|
||||
self._duplicate_hashes.setdefault(sha256, []).append(file_path)
|
||||
|
||||
# Track duplicates by filename
|
||||
if filename in self._filename_to_hash:
|
||||
old_hash = self._filename_to_hash[filename]
|
||||
if old_hash != sha256: # Different models with the same name
|
||||
old_path = self._hash_to_path.get(old_hash)
|
||||
if old_path:
|
||||
if filename not in self._duplicate_filenames:
|
||||
self._duplicate_filenames[filename] = [old_path]
|
||||
if file_path not in self._duplicate_filenames.get(filename, []):
|
||||
self._duplicate_filenames.setdefault(filename, []).append(file_path)
|
||||
|
||||
# Remove old path mapping if hash exists
|
||||
if sha256 in self._hash_to_path:
|
||||
old_path = self._hash_to_path[sha256]
|
||||
if old_path in self._path_to_hash:
|
||||
del self._path_to_hash[old_path]
|
||||
old_filename = self._get_filename_from_path(old_path)
|
||||
if old_filename in self._filename_to_hash:
|
||||
del self._filename_to_hash[old_filename]
|
||||
|
||||
# Remove old hash mapping if path exists
|
||||
if file_path in self._path_to_hash:
|
||||
old_hash = self._path_to_hash[file_path]
|
||||
# Remove old hash mapping if filename exists
|
||||
if filename in self._filename_to_hash:
|
||||
old_hash = self._filename_to_hash[filename]
|
||||
if old_hash in self._hash_to_path:
|
||||
del self._hash_to_path[old_hash]
|
||||
|
||||
# Add new mappings
|
||||
self._hash_to_path[sha256] = file_path
|
||||
self._path_to_hash[file_path] = sha256
|
||||
self._filename_to_hash[filename] = sha256
|
||||
|
||||
def _get_filename_from_path(self, file_path: str) -> str:
|
||||
"""Extract filename without extension from path"""
|
||||
return os.path.splitext(os.path.basename(file_path))[0]
|
||||
|
||||
def remove_by_path(self, file_path: str) -> None:
|
||||
"""Remove entry by file path"""
|
||||
if file_path in self._path_to_hash:
|
||||
hash_val = self._path_to_hash[file_path]
|
||||
if hash_val in self._hash_to_path:
|
||||
filename = self._get_filename_from_path(file_path)
|
||||
hash_val = None
|
||||
|
||||
# Find the hash for this file path
|
||||
for h, p in self._hash_to_path.items():
|
||||
if p == file_path:
|
||||
hash_val = h
|
||||
break
|
||||
|
||||
# If we didn't find a hash, nothing to do
|
||||
if not hash_val:
|
||||
return
|
||||
|
||||
# Update duplicates tracking for hash
|
||||
if hash_val in self._duplicate_hashes:
|
||||
# Remove the current path from duplicates
|
||||
self._duplicate_hashes[hash_val] = [p for p in self._duplicate_hashes[hash_val] if p != file_path]
|
||||
|
||||
# Update or remove hash mapping based on remaining duplicates
|
||||
if len(self._duplicate_hashes[hash_val]) > 0:
|
||||
# Replace with one of the remaining paths
|
||||
new_path = self._duplicate_hashes[hash_val][0]
|
||||
new_filename = self._get_filename_from_path(new_path)
|
||||
|
||||
# Update hash-to-path mapping
|
||||
self._hash_to_path[hash_val] = new_path
|
||||
|
||||
# IMPORTANT: Update filename-to-hash mapping for consistency
|
||||
# Remove old filename mapping if it points to this hash
|
||||
if filename in self._filename_to_hash and self._filename_to_hash[filename] == hash_val:
|
||||
del self._filename_to_hash[filename]
|
||||
|
||||
# Add new filename mapping
|
||||
self._filename_to_hash[new_filename] = hash_val
|
||||
|
||||
# If only one duplicate left, remove from duplicates tracking
|
||||
if len(self._duplicate_hashes[hash_val]) == 1:
|
||||
del self._duplicate_hashes[hash_val]
|
||||
else:
|
||||
# No duplicates left, remove hash entry completely
|
||||
del self._duplicate_hashes[hash_val]
|
||||
del self._hash_to_path[hash_val]
|
||||
del self._path_to_hash[file_path]
|
||||
|
||||
# Remove corresponding filename entry if it points to this hash
|
||||
if filename in self._filename_to_hash and self._filename_to_hash[filename] == hash_val:
|
||||
del self._filename_to_hash[filename]
|
||||
else:
|
||||
# No duplicates, simply remove the hash entry
|
||||
del self._hash_to_path[hash_val]
|
||||
|
||||
# Remove corresponding filename entry if it points to this hash
|
||||
if filename in self._filename_to_hash and self._filename_to_hash[filename] == hash_val:
|
||||
del self._filename_to_hash[filename]
|
||||
|
||||
# Update duplicates tracking for filename
|
||||
if filename in self._duplicate_filenames:
|
||||
# Remove the current path from duplicates
|
||||
self._duplicate_filenames[filename] = [p for p in self._duplicate_filenames[filename] if p != file_path]
|
||||
|
||||
# Update or remove filename mapping based on remaining duplicates
|
||||
if len(self._duplicate_filenames[filename]) > 0:
|
||||
# Get the hash for the first remaining duplicate path
|
||||
first_dup_path = self._duplicate_filenames[filename][0]
|
||||
first_dup_hash = None
|
||||
for h, p in self._hash_to_path.items():
|
||||
if p == first_dup_path:
|
||||
first_dup_hash = h
|
||||
break
|
||||
|
||||
# Update the filename to hash mapping if we found a hash
|
||||
if first_dup_hash:
|
||||
self._filename_to_hash[filename] = first_dup_hash
|
||||
|
||||
# If only one duplicate left, remove from duplicates tracking
|
||||
if len(self._duplicate_filenames[filename]) == 1:
|
||||
del self._duplicate_filenames[filename]
|
||||
else:
|
||||
# No duplicates left, remove filename entry completely
|
||||
del self._duplicate_filenames[filename]
|
||||
if filename in self._filename_to_hash:
|
||||
del self._filename_to_hash[filename]
|
||||
|
||||
def remove_by_hash(self, sha256: str) -> None:
|
||||
"""Remove entry by hash"""
|
||||
sha256 = sha256.lower()
|
||||
if sha256 in self._hash_to_path:
|
||||
path = self._hash_to_path[sha256]
|
||||
if path in self._path_to_hash:
|
||||
del self._path_to_hash[path]
|
||||
del self._hash_to_path[sha256]
|
||||
if sha256 not in self._hash_to_path:
|
||||
return
|
||||
|
||||
# Get the path and filename
|
||||
path = self._hash_to_path[sha256]
|
||||
filename = self._get_filename_from_path(path)
|
||||
|
||||
# Get all paths for this hash (including duplicates)
|
||||
paths_to_remove = [path]
|
||||
if sha256 in self._duplicate_hashes:
|
||||
paths_to_remove.extend(self._duplicate_hashes[sha256])
|
||||
del self._duplicate_hashes[sha256]
|
||||
|
||||
# Remove hash-to-path mapping
|
||||
del self._hash_to_path[sha256]
|
||||
|
||||
# Update filename-to-hash and duplicate filenames for all paths
|
||||
for path_to_remove in paths_to_remove:
|
||||
fname = self._get_filename_from_path(path_to_remove)
|
||||
|
||||
# If this filename maps to the hash we're removing, remove it
|
||||
if fname in self._filename_to_hash and self._filename_to_hash[fname] == sha256:
|
||||
del self._filename_to_hash[fname]
|
||||
|
||||
# Update duplicate filenames tracking
|
||||
if fname in self._duplicate_filenames:
|
||||
self._duplicate_filenames[fname] = [p for p in self._duplicate_filenames[fname] if p != path_to_remove]
|
||||
|
||||
if not self._duplicate_filenames[fname]:
|
||||
del self._duplicate_filenames[fname]
|
||||
elif len(self._duplicate_filenames[fname]) == 1:
|
||||
# If only one entry remains, it's no longer a duplicate
|
||||
del self._duplicate_filenames[fname]
|
||||
|
||||
def has_hash(self, sha256: str) -> bool:
|
||||
"""Check if hash exists in index"""
|
||||
@@ -58,20 +194,37 @@ class ModelHashIndex:
|
||||
|
||||
def get_hash(self, file_path: str) -> Optional[str]:
|
||||
"""Get hash for a file path"""
|
||||
return self._path_to_hash.get(file_path)
|
||||
filename = self._get_filename_from_path(file_path)
|
||||
return self._filename_to_hash.get(filename)
|
||||
|
||||
def get_hash_by_filename(self, filename: str) -> Optional[str]:
|
||||
"""Get hash for a filename without extension"""
|
||||
# Strip extension if present to make the function more flexible
|
||||
filename = os.path.splitext(filename)[0]
|
||||
return self._filename_to_hash.get(filename)
|
||||
|
||||
def clear(self) -> None:
|
||||
"""Clear all entries"""
|
||||
self._hash_to_path.clear()
|
||||
self._path_to_hash.clear()
|
||||
self._filename_to_hash.clear()
|
||||
self._duplicate_hashes.clear()
|
||||
self._duplicate_filenames.clear()
|
||||
|
||||
def get_all_hashes(self) -> Set[str]:
|
||||
"""Get all hashes in the index"""
|
||||
return set(self._hash_to_path.keys())
|
||||
|
||||
def get_all_paths(self) -> Set[str]:
|
||||
"""Get all file paths in the index"""
|
||||
return set(self._path_to_hash.keys())
|
||||
def get_all_filenames(self) -> Set[str]:
|
||||
"""Get all filenames in the index"""
|
||||
return set(self._filename_to_hash.keys())
|
||||
|
||||
def get_duplicate_hashes(self) -> Dict[str, List[str]]:
|
||||
"""Get dictionary of duplicate hashes and their paths"""
|
||||
return self._duplicate_hashes
|
||||
|
||||
def get_duplicate_filenames(self) -> Dict[str, List[str]]:
|
||||
"""Get dictionary of duplicate filenames and their paths"""
|
||||
return self._duplicate_filenames
|
||||
|
||||
def __len__(self) -> int:
|
||||
"""Get number of entries"""
|
||||
|
||||
@@ -5,6 +5,7 @@ import asyncio
|
||||
import time
|
||||
import shutil
|
||||
from typing import List, Dict, Optional, Type, Set
|
||||
import msgpack # Add MessagePack import for efficient serialization
|
||||
|
||||
from ..utils.models import BaseModelMetadata
|
||||
from ..config import config
|
||||
@@ -17,6 +18,13 @@ from .websocket_manager import ws_manager
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# Define cache version to handle future format changes
|
||||
# Version history:
|
||||
# 1 - Initial version
|
||||
# 2 - Added duplicate_filenames and duplicate_hashes tracking
|
||||
# 3 - Added _excluded_models list to cache
|
||||
CACHE_VERSION = 3
|
||||
|
||||
class ModelScanner:
|
||||
"""Base service for scanning and managing model files"""
|
||||
|
||||
@@ -38,6 +46,8 @@ class ModelScanner:
|
||||
self._hash_index = hash_index or ModelHashIndex()
|
||||
self._tags_count = {} # Dictionary to store tag counts
|
||||
self._is_initializing = False # Flag to track initialization state
|
||||
self._excluded_models = [] # List to track excluded models
|
||||
self._dirs_last_modified = {} # Track directory modification times
|
||||
|
||||
# Register this service
|
||||
asyncio.create_task(self._register_service())
|
||||
@@ -47,6 +57,183 @@ class ModelScanner:
|
||||
service_name = f"{self.model_type}_scanner"
|
||||
await ServiceRegistry.register_service(service_name, self)
|
||||
|
||||
def _get_cache_file_path(self) -> Optional[str]:
|
||||
"""Get the path to the cache file"""
|
||||
# Get the directory where this module is located
|
||||
current_dir = os.path.dirname(os.path.dirname(os.path.dirname(os.path.realpath(__file__))))
|
||||
|
||||
# Create a cache directory within the project if it doesn't exist
|
||||
cache_dir = os.path.join(current_dir, "cache")
|
||||
os.makedirs(cache_dir, exist_ok=True)
|
||||
|
||||
# Create filename based on model type
|
||||
cache_filename = f"lm_{self.model_type}_cache.msgpack"
|
||||
return os.path.join(cache_dir, cache_filename)
|
||||
|
||||
def _prepare_for_msgpack(self, data):
|
||||
"""Preprocess data to accommodate MessagePack serialization limitations
|
||||
|
||||
Converts integers exceeding safe range to strings
|
||||
|
||||
Args:
|
||||
data: Any type of data structure
|
||||
|
||||
Returns:
|
||||
Preprocessed data structure with large integers converted to strings
|
||||
"""
|
||||
if isinstance(data, dict):
|
||||
return {k: self._prepare_for_msgpack(v) for k, v in data.items()}
|
||||
elif isinstance(data, list):
|
||||
return [self._prepare_for_msgpack(item) for item in data]
|
||||
elif isinstance(data, int) and (data > 9007199254740991 or data < -9007199254740991):
|
||||
# Convert integers exceeding JavaScript's safe integer range (2^53-1) to strings
|
||||
return str(data)
|
||||
else:
|
||||
return data
|
||||
|
||||
async def _save_cache_to_disk(self) -> bool:
|
||||
"""Save cache data to disk using MessagePack"""
|
||||
if self._cache is None or not self._cache.raw_data:
|
||||
logger.debug(f"No {self.model_type} cache data to save")
|
||||
return False
|
||||
|
||||
cache_path = self._get_cache_file_path()
|
||||
if not cache_path:
|
||||
logger.warning(f"Cannot determine {self.model_type} cache file location")
|
||||
return False
|
||||
|
||||
try:
|
||||
# Create cache data structure
|
||||
cache_data = {
|
||||
"version": CACHE_VERSION,
|
||||
"timestamp": time.time(),
|
||||
"model_type": self.model_type,
|
||||
"raw_data": self._cache.raw_data,
|
||||
"hash_index": {
|
||||
"hash_to_path": self._hash_index._hash_to_path,
|
||||
"filename_to_hash": self._hash_index._filename_to_hash, # Fix: changed from path_to_hash to filename_to_hash
|
||||
"duplicate_hashes": self._hash_index._duplicate_hashes,
|
||||
"duplicate_filenames": self._hash_index._duplicate_filenames
|
||||
},
|
||||
"tags_count": self._tags_count,
|
||||
"dirs_last_modified": self._get_dirs_last_modified(),
|
||||
"excluded_models": self._excluded_models # Add excluded_models to cache data
|
||||
}
|
||||
|
||||
# Preprocess data to handle large integers
|
||||
processed_cache_data = self._prepare_for_msgpack(cache_data)
|
||||
|
||||
# Write to temporary file first (atomic operation)
|
||||
temp_path = f"{cache_path}.tmp"
|
||||
with open(temp_path, 'wb') as f:
|
||||
msgpack.pack(processed_cache_data, f)
|
||||
|
||||
# Replace the old file with the new one
|
||||
if os.path.exists(cache_path):
|
||||
os.replace(temp_path, cache_path)
|
||||
else:
|
||||
os.rename(temp_path, cache_path)
|
||||
|
||||
logger.info(f"Saved {self.model_type} cache with {len(self._cache.raw_data)} models to {cache_path}")
|
||||
logger.debug(f"Hash index stats - hash_to_path: {len(self._hash_index._hash_to_path)}, filename_to_hash: {len(self._hash_index._filename_to_hash)}, duplicate_hashes: {len(self._hash_index._duplicate_hashes)}, duplicate_filenames: {len(self._hash_index._duplicate_filenames)}")
|
||||
return True
|
||||
except Exception as e:
|
||||
logger.error(f"Error saving {self.model_type} cache to disk: {e}")
|
||||
# Try to clean up temp file if it exists
|
||||
if 'temp_path' in locals() and os.path.exists(temp_path):
|
||||
try:
|
||||
os.remove(temp_path)
|
||||
except:
|
||||
pass
|
||||
return False
|
||||
|
||||
def _get_dirs_last_modified(self) -> Dict[str, float]:
|
||||
"""Get last modified time for all model directories"""
|
||||
dirs_info = {}
|
||||
for root in self.get_model_roots():
|
||||
if os.path.exists(root):
|
||||
dirs_info[root] = os.path.getmtime(root)
|
||||
# Also check immediate subdirectories for changes
|
||||
try:
|
||||
with os.scandir(root) as it:
|
||||
for entry in it:
|
||||
if entry.is_dir(follow_symlinks=True):
|
||||
dirs_info[entry.path] = entry.stat().st_mtime
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting directory info for {root}: {e}")
|
||||
return dirs_info
|
||||
|
||||
def _is_cache_valid(self, cache_data: Dict) -> bool:
|
||||
"""Validate if the loaded cache is still valid"""
|
||||
if not cache_data or cache_data.get("version") != CACHE_VERSION:
|
||||
logger.info(f"Cache invalid - version mismatch. Got: {cache_data.get('version')}, Expected: {CACHE_VERSION}")
|
||||
return False
|
||||
|
||||
if cache_data.get("model_type") != self.model_type:
|
||||
logger.info(f"Cache invalid - model type mismatch. Got: {cache_data.get('model_type')}, Expected: {self.model_type}")
|
||||
return False
|
||||
|
||||
# Check if directories have changed
|
||||
# stored_dirs = cache_data.get("dirs_last_modified", {})
|
||||
# current_dirs = self._get_dirs_last_modified()
|
||||
|
||||
# If directory structure has changed, cache is invalid
|
||||
# if set(stored_dirs.keys()) != set(current_dirs.keys()):
|
||||
# logger.info(f"Cache invalid - directory structure changed. Stored: {set(stored_dirs.keys())}, Current: {set(current_dirs.keys())}")
|
||||
# return False
|
||||
|
||||
# Remove the modification time check to make cache validation less strict
|
||||
# This allows the cache to be valid even when files have changed
|
||||
# Users can explicitly refresh the cache when needed
|
||||
|
||||
return True
|
||||
|
||||
async def _load_cache_from_disk(self) -> bool:
|
||||
"""Load cache data from disk using MessagePack"""
|
||||
start_time = time.time()
|
||||
cache_path = self._get_cache_file_path()
|
||||
if not cache_path or not os.path.exists(cache_path):
|
||||
return False
|
||||
|
||||
try:
|
||||
with open(cache_path, 'rb') as f:
|
||||
cache_data = msgpack.unpack(f)
|
||||
|
||||
# Validate cache data
|
||||
if not self._is_cache_valid(cache_data):
|
||||
logger.info(f"{self.model_type.capitalize()} cache file found but invalid or outdated")
|
||||
return False
|
||||
|
||||
# Load data into memory
|
||||
self._cache = ModelCache(
|
||||
raw_data=cache_data["raw_data"],
|
||||
sorted_by_name=[],
|
||||
sorted_by_date=[],
|
||||
folders=[]
|
||||
)
|
||||
|
||||
# Load hash index
|
||||
hash_index_data = cache_data.get("hash_index", {})
|
||||
self._hash_index._hash_to_path = hash_index_data.get("hash_to_path", {})
|
||||
self._hash_index._filename_to_hash = hash_index_data.get("filename_to_hash", {}) # Fix: changed from path_to_hash to filename_to_hash
|
||||
self._hash_index._duplicate_hashes = hash_index_data.get("duplicate_hashes", {})
|
||||
self._hash_index._duplicate_filenames = hash_index_data.get("duplicate_filenames", {})
|
||||
|
||||
# Load tags count
|
||||
self._tags_count = cache_data.get("tags_count", {})
|
||||
|
||||
# Load excluded models
|
||||
self._excluded_models = cache_data.get("excluded_models", [])
|
||||
|
||||
# Resort the cache
|
||||
await self._cache.resort()
|
||||
|
||||
logger.info(f"Loaded {self.model_type} cache from disk with {len(self._cache.raw_data)} models in {time.time() - start_time:.2f} seconds")
|
||||
return True
|
||||
except Exception as e:
|
||||
logger.error(f"Error loading {self.model_type} cache from disk: {e}")
|
||||
return False
|
||||
|
||||
async def initialize_in_background(self) -> None:
|
||||
"""Initialize cache in background using thread pool"""
|
||||
try:
|
||||
@@ -65,7 +252,31 @@ class ModelScanner:
|
||||
# Determine the page type based on model type
|
||||
page_type = 'loras' if self.model_type == 'lora' else 'checkpoints'
|
||||
|
||||
# First, count all model files to track progress
|
||||
# First, try to load from cache
|
||||
await ws_manager.broadcast_init_progress({
|
||||
'stage': 'loading_cache',
|
||||
'progress': 0,
|
||||
'details': f"Loading {self.model_type} cache...",
|
||||
'scanner_type': self.model_type,
|
||||
'pageType': page_type
|
||||
})
|
||||
|
||||
cache_loaded = await self._load_cache_from_disk()
|
||||
|
||||
if cache_loaded:
|
||||
# Cache loaded successfully, broadcast complete message
|
||||
await ws_manager.broadcast_init_progress({
|
||||
'stage': 'finalizing',
|
||||
'progress': 100,
|
||||
'status': 'complete',
|
||||
'details': f"Loaded {len(self._cache.raw_data)} {self.model_type} files from cache.",
|
||||
'scanner_type': self.model_type,
|
||||
'pageType': page_type
|
||||
})
|
||||
self._is_initializing = False
|
||||
return
|
||||
|
||||
# If cache loading failed, proceed with full scan
|
||||
await ws_manager.broadcast_init_progress({
|
||||
'stage': 'scan_folders',
|
||||
'progress': 0,
|
||||
@@ -110,6 +321,9 @@ class ModelScanner:
|
||||
|
||||
logger.info(f"{self.model_type.capitalize()} cache initialized in {time.time() - start_time:.2f} seconds. Found {len(self._cache.raw_data)} models")
|
||||
|
||||
# Save the cache to disk after initialization
|
||||
await self._save_cache_to_disk()
|
||||
|
||||
# Send completion message
|
||||
await asyncio.sleep(0.5) # Small delay to ensure final progress message is sent
|
||||
await ws_manager.broadcast_init_progress({
|
||||
@@ -279,8 +493,13 @@ class ModelScanner:
|
||||
# Clean up the event loop
|
||||
loop.close()
|
||||
|
||||
async def get_cached_data(self, force_refresh: bool = False) -> ModelCache:
|
||||
"""Get cached model data, refresh if needed"""
|
||||
async def get_cached_data(self, force_refresh: bool = False, rebuild_cache: bool = False) -> ModelCache:
|
||||
"""Get cached model data, refresh if needed
|
||||
|
||||
Args:
|
||||
force_refresh: Whether to refresh the cache
|
||||
rebuild_cache: Whether to completely rebuild the cache by reloading from disk first
|
||||
"""
|
||||
# If cache is not initialized, return an empty cache
|
||||
# Actual initialization should be done via initialize_in_background
|
||||
if self._cache is None and not force_refresh:
|
||||
@@ -293,9 +512,24 @@ class ModelScanner:
|
||||
|
||||
# If force refresh is requested, initialize the cache directly
|
||||
if force_refresh:
|
||||
# If rebuild_cache is True, try to reload from disk before reconciliation
|
||||
if rebuild_cache:
|
||||
logger.info(f"{self.model_type.capitalize()} Scanner: Attempting to rebuild cache from disk...")
|
||||
cache_loaded = await self._load_cache_from_disk()
|
||||
if cache_loaded:
|
||||
logger.info(f"{self.model_type.capitalize()} Scanner: Successfully reloaded cache from disk")
|
||||
else:
|
||||
logger.info(f"{self.model_type.capitalize()} Scanner: Could not reload cache from disk, proceeding with complete rebuild")
|
||||
# If loading from disk failed, do a complete rebuild and save to disk
|
||||
await self._initialize_cache()
|
||||
await self._save_cache_to_disk()
|
||||
return self._cache
|
||||
|
||||
if self._cache is None:
|
||||
# For initial creation, do a full initialization
|
||||
await self._initialize_cache()
|
||||
# Save the newly built cache
|
||||
await self._save_cache_to_disk()
|
||||
else:
|
||||
# For subsequent refreshes, use fast reconciliation
|
||||
await self._reconcile_cache()
|
||||
@@ -394,6 +628,9 @@ class ModelScanner:
|
||||
if file_path in cached_paths:
|
||||
found_paths.add(file_path)
|
||||
continue
|
||||
|
||||
if file_path in self._excluded_models:
|
||||
continue
|
||||
|
||||
# Try case-insensitive match on Windows
|
||||
if os.name == 'nt':
|
||||
@@ -406,7 +643,7 @@ class ModelScanner:
|
||||
break
|
||||
if matched:
|
||||
continue
|
||||
|
||||
|
||||
# This is a new file to process
|
||||
new_files.append(file_path)
|
||||
|
||||
@@ -480,6 +717,9 @@ class ModelScanner:
|
||||
# Resort cache
|
||||
await self._cache.resort()
|
||||
|
||||
# Save updated cache to disk
|
||||
await self._save_cache_to_disk()
|
||||
|
||||
logger.info(f"{self.model_type.capitalize()} Scanner: Cache reconciliation completed in {time.time() - start_time:.2f} seconds. Added {total_added}, removed {total_removed} models.")
|
||||
except Exception as e:
|
||||
logger.error(f"{self.model_type.capitalize()} Scanner: Error reconciling cache: {e}", exc_info=True)
|
||||
@@ -553,12 +793,44 @@ class ModelScanner:
|
||||
logger.debug(f"Created metadata from .civitai.info for {file_path}")
|
||||
except Exception as e:
|
||||
logger.error(f"Error creating metadata from .civitai.info for {file_path}: {e}")
|
||||
else:
|
||||
# Check if metadata exists but civitai field is empty - try to restore from civitai.info
|
||||
if metadata.civitai is None or metadata.civitai == {}:
|
||||
civitai_info_path = f"{os.path.splitext(file_path)[0]}.civitai.info"
|
||||
if os.path.exists(civitai_info_path):
|
||||
try:
|
||||
with open(civitai_info_path, 'r', encoding='utf-8') as f:
|
||||
version_info = json.load(f)
|
||||
|
||||
logger.debug(f"Restoring missing civitai data from .civitai.info for {file_path}")
|
||||
metadata.civitai = version_info
|
||||
|
||||
# Ensure tags are also updated if they're missing
|
||||
if (not metadata.tags or len(metadata.tags) == 0) and 'model' in version_info:
|
||||
if 'tags' in version_info['model']:
|
||||
metadata.tags = version_info['model']['tags']
|
||||
|
||||
# Also restore description if missing
|
||||
if (not metadata.modelDescription or metadata.modelDescription == "") and 'model' in version_info:
|
||||
if 'description' in version_info['model']:
|
||||
metadata.modelDescription = version_info['model']['description']
|
||||
|
||||
# Save the updated metadata
|
||||
await save_metadata(file_path, metadata)
|
||||
logger.debug(f"Updated metadata with civitai info for {file_path}")
|
||||
except Exception as e:
|
||||
logger.error(f"Error restoring civitai data from .civitai.info for {file_path}: {e}")
|
||||
|
||||
if metadata is None:
|
||||
metadata = await self._get_file_info(file_path)
|
||||
if metadata is None:
|
||||
metadata = await self._get_file_info(file_path)
|
||||
|
||||
model_data = metadata.to_dict()
|
||||
|
||||
# Skip excluded models
|
||||
if model_data.get('exclude', False):
|
||||
self._excluded_models.append(model_data['file_path'])
|
||||
return None
|
||||
|
||||
await self._fetch_missing_metadata(file_path, model_data)
|
||||
rel_path = os.path.relpath(file_path, root_path)
|
||||
folder = os.path.dirname(rel_path)
|
||||
@@ -583,7 +855,10 @@ class ModelScanner:
|
||||
model_id = str(model_id)
|
||||
tags_missing = not model_data.get('tags') or len(model_data.get('tags', [])) == 0
|
||||
desc_missing = not model_data.get('modelDescription') or model_data.get('modelDescription') in (None, "")
|
||||
needs_metadata_update = tags_missing or desc_missing
|
||||
# TODO: not for now, but later we should check if the creator is missing
|
||||
# creator_missing = not model_data.get('civitai', {}).get('creator')
|
||||
creator_missing = False
|
||||
needs_metadata_update = tags_missing or desc_missing or creator_missing
|
||||
|
||||
if needs_metadata_update and model_id:
|
||||
logger.debug(f"Fetching missing metadata for {file_path} with model ID {model_id}")
|
||||
@@ -609,6 +884,8 @@ class ModelScanner:
|
||||
|
||||
if model_metadata.get('description') and (not model_data.get('modelDescription') or model_data.get('modelDescription') in (None, "")):
|
||||
model_data['modelDescription'] = model_metadata['description']
|
||||
|
||||
model_data['civitai']['creator'] = model_metadata['creator']
|
||||
|
||||
metadata_path = os.path.splitext(file_path)[0] + '.metadata.json'
|
||||
with open(metadata_path, 'w', encoding='utf-8') as f:
|
||||
@@ -657,6 +934,44 @@ class ModelScanner:
|
||||
models_list.append(result)
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing {file_path}: {e}")
|
||||
|
||||
async def add_model_to_cache(self, metadata_dict: Dict, folder: str = '') -> bool:
|
||||
"""Add a model to the cache and save to disk
|
||||
|
||||
Args:
|
||||
metadata_dict: The model metadata dictionary
|
||||
folder: The relative folder path for the model
|
||||
|
||||
Returns:
|
||||
bool: True if successful, False otherwise
|
||||
"""
|
||||
try:
|
||||
if self._cache is None:
|
||||
await self.get_cached_data()
|
||||
|
||||
# Update folder in metadata
|
||||
metadata_dict['folder'] = folder
|
||||
|
||||
# Add to cache
|
||||
self._cache.raw_data.append(metadata_dict)
|
||||
|
||||
# Resort cache data
|
||||
await self._cache.resort()
|
||||
|
||||
# Update folders list
|
||||
all_folders = set(self._cache.folders)
|
||||
all_folders.add(folder)
|
||||
self._cache.folders = sorted(list(all_folders), key=lambda x: x.lower())
|
||||
|
||||
# Update the hash index
|
||||
self._hash_index.add_entry(metadata_dict['sha256'], metadata_dict['file_path'])
|
||||
|
||||
# Save to disk
|
||||
await self._save_cache_to_disk()
|
||||
return True
|
||||
except Exception as e:
|
||||
logger.error(f"Error adding model to cache: {e}")
|
||||
return False
|
||||
|
||||
async def move_model(self, source_path: str, target_path: str) -> bool:
|
||||
"""Move a model and its associated files to a new location"""
|
||||
@@ -702,19 +1017,40 @@ class ModelScanner:
|
||||
|
||||
shutil.move(real_source, real_target)
|
||||
|
||||
source_metadata = os.path.join(source_dir, f"{base_name}.metadata.json")
|
||||
metadata = None
|
||||
if os.path.exists(source_metadata):
|
||||
target_metadata = os.path.join(target_path, f"{base_name}.metadata.json")
|
||||
shutil.move(source_metadata, target_metadata)
|
||||
metadata = await self._update_metadata_paths(target_metadata, target_file)
|
||||
# Move all associated files with the same base name
|
||||
source_metadata = None
|
||||
moved_metadata_path = None
|
||||
|
||||
for ext in PREVIEW_EXTENSIONS:
|
||||
source_preview = os.path.join(source_dir, f"{base_name}{ext}")
|
||||
if os.path.exists(source_preview):
|
||||
target_preview = os.path.join(target_path, f"{base_name}{ext}")
|
||||
shutil.move(source_preview, target_preview)
|
||||
break
|
||||
# Find all files with the same base name in the source directory
|
||||
files_to_move = []
|
||||
try:
|
||||
for file in os.listdir(source_dir):
|
||||
if file.startswith(base_name + ".") and file != os.path.basename(source_path):
|
||||
source_file_path = os.path.join(source_dir, file)
|
||||
# Store metadata file path for special handling
|
||||
if file == f"{base_name}.metadata.json":
|
||||
source_metadata = source_file_path
|
||||
moved_metadata_path = os.path.join(target_path, file)
|
||||
else:
|
||||
files_to_move.append((source_file_path, os.path.join(target_path, file)))
|
||||
except Exception as e:
|
||||
logger.error(f"Error listing files in {source_dir}: {e}")
|
||||
|
||||
# Move all associated files
|
||||
metadata = None
|
||||
for source_file, target_file_path in files_to_move:
|
||||
try:
|
||||
shutil.move(source_file, target_file_path)
|
||||
except Exception as e:
|
||||
logger.error(f"Error moving associated file {source_file}: {e}")
|
||||
|
||||
# Handle metadata file specially to update paths
|
||||
if source_metadata and os.path.exists(source_metadata):
|
||||
try:
|
||||
shutil.move(source_metadata, moved_metadata_path)
|
||||
metadata = await self._update_metadata_paths(moved_metadata_path, target_file)
|
||||
except Exception as e:
|
||||
logger.error(f"Error moving metadata file: {e}")
|
||||
|
||||
await self.update_single_model_cache(source_path, target_file, metadata)
|
||||
|
||||
@@ -792,6 +1128,9 @@ class ModelScanner:
|
||||
|
||||
await cache.resort()
|
||||
|
||||
# Save the updated cache
|
||||
await self._save_cache_to_disk()
|
||||
|
||||
return True
|
||||
|
||||
def has_hash(self, sha256: str) -> bool:
|
||||
@@ -805,6 +1144,10 @@ class ModelScanner:
|
||||
def get_hash_by_path(self, file_path: str) -> Optional[str]:
|
||||
"""Get hash for a model by its file path"""
|
||||
return self._hash_index.get_hash(file_path)
|
||||
|
||||
def get_hash_by_filename(self, filename: str) -> Optional[str]:
|
||||
"""Get hash for a model by its filename without path"""
|
||||
return self._hash_index.get_hash_by_filename(filename)
|
||||
|
||||
# TODO: Adjust this method to use metadata instead of finding the file
|
||||
def get_preview_url_by_hash(self, sha256: str) -> Optional[str]:
|
||||
@@ -863,6 +1206,10 @@ class ModelScanner:
|
||||
logger.error(f"Error getting model info by name: {e}", exc_info=True)
|
||||
return None
|
||||
|
||||
def get_excluded_models(self) -> List[str]:
|
||||
"""Get list of excluded model file paths"""
|
||||
return self._excluded_models.copy()
|
||||
|
||||
async def update_preview_in_cache(self, file_path: str, preview_url: str) -> bool:
|
||||
"""Update preview URL in cache for a specific lora
|
||||
|
||||
@@ -876,4 +1223,171 @@ class ModelScanner:
|
||||
if self._cache is None:
|
||||
return False
|
||||
|
||||
return await self._cache.update_preview_url(file_path, preview_url)
|
||||
updated = await self._cache.update_preview_url(file_path, preview_url)
|
||||
if updated:
|
||||
# Save updated cache to disk
|
||||
await self._save_cache_to_disk()
|
||||
return updated
|
||||
|
||||
async def bulk_delete_models(self, file_paths: List[str]) -> Dict:
|
||||
"""Delete multiple models and update cache in a batch operation
|
||||
|
||||
Args:
|
||||
file_paths: List of file paths to delete
|
||||
|
||||
Returns:
|
||||
Dict containing results of the operation
|
||||
"""
|
||||
try:
|
||||
if not file_paths:
|
||||
return {
|
||||
'success': False,
|
||||
'error': 'No file paths provided for deletion',
|
||||
'results': []
|
||||
}
|
||||
|
||||
# Get the file monitor
|
||||
file_monitor = getattr(self, 'file_monitor', None)
|
||||
|
||||
# Keep track of success and failures
|
||||
results = []
|
||||
total_deleted = 0
|
||||
cache_updated = False
|
||||
|
||||
# Get cache data
|
||||
cache = await self.get_cached_data()
|
||||
|
||||
# Track deleted models to update cache once
|
||||
deleted_models = []
|
||||
|
||||
for file_path in file_paths:
|
||||
try:
|
||||
target_dir = os.path.dirname(file_path)
|
||||
file_name = os.path.splitext(os.path.basename(file_path))[0]
|
||||
|
||||
# Delete all associated files for the model
|
||||
from ..utils.routes_common import ModelRouteUtils
|
||||
deleted_files = await ModelRouteUtils.delete_model_files(
|
||||
target_dir,
|
||||
file_name,
|
||||
file_monitor
|
||||
)
|
||||
|
||||
if deleted_files:
|
||||
deleted_models.append(file_path)
|
||||
results.append({
|
||||
'file_path': file_path,
|
||||
'success': True,
|
||||
'deleted_files': deleted_files
|
||||
})
|
||||
total_deleted += 1
|
||||
else:
|
||||
results.append({
|
||||
'file_path': file_path,
|
||||
'success': False,
|
||||
'error': 'No files deleted'
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error deleting file {file_path}: {e}")
|
||||
results.append({
|
||||
'file_path': file_path,
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
})
|
||||
|
||||
# Batch update cache if any models were deleted
|
||||
if deleted_models:
|
||||
# Update the cache in a batch operation
|
||||
cache_updated = await self._batch_update_cache_for_deleted_models(deleted_models)
|
||||
|
||||
return {
|
||||
'success': True,
|
||||
'total_deleted': total_deleted,
|
||||
'total_attempted': len(file_paths),
|
||||
'cache_updated': cache_updated,
|
||||
'results': results
|
||||
}
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error in bulk delete: {e}", exc_info=True)
|
||||
return {
|
||||
'success': False,
|
||||
'error': str(e),
|
||||
'results': []
|
||||
}
|
||||
|
||||
async def _batch_update_cache_for_deleted_models(self, file_paths: List[str]) -> bool:
|
||||
"""Update cache after multiple models have been deleted
|
||||
|
||||
Args:
|
||||
file_paths: List of file paths that were deleted
|
||||
|
||||
Returns:
|
||||
bool: True if cache was updated and saved successfully
|
||||
"""
|
||||
if not file_paths or self._cache is None:
|
||||
return False
|
||||
|
||||
try:
|
||||
# Get all models that need to be removed from cache
|
||||
models_to_remove = [item for item in self._cache.raw_data if item['file_path'] in file_paths]
|
||||
|
||||
if not models_to_remove:
|
||||
return False
|
||||
|
||||
# Update tag counts
|
||||
for model in models_to_remove:
|
||||
for tag in model.get('tags', []):
|
||||
if tag in self._tags_count:
|
||||
self._tags_count[tag] = max(0, self._tags_count[tag] - 1)
|
||||
if self._tags_count[tag] == 0:
|
||||
del self._tags_count[tag]
|
||||
|
||||
# Update hash index
|
||||
for model in models_to_remove:
|
||||
file_path = model['file_path']
|
||||
if hasattr(self, '_hash_index') and self._hash_index:
|
||||
# Get the hash and filename before removal for duplicate checking
|
||||
file_name = os.path.splitext(os.path.basename(file_path))[0]
|
||||
hash_val = model.get('sha256', '').lower()
|
||||
|
||||
# Remove from hash index
|
||||
self._hash_index.remove_by_path(file_path)
|
||||
|
||||
# Check and clean up duplicates
|
||||
self._cleanup_duplicates_after_removal(hash_val, file_name)
|
||||
|
||||
# Update cache data
|
||||
self._cache.raw_data = [item for item in self._cache.raw_data if item['file_path'] not in file_paths]
|
||||
|
||||
# Resort cache
|
||||
await self._cache.resort()
|
||||
|
||||
# Save updated cache to disk
|
||||
await self._save_cache_to_disk()
|
||||
|
||||
return True
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error updating cache after bulk delete: {e}", exc_info=True)
|
||||
return False
|
||||
|
||||
def _cleanup_duplicates_after_removal(self, hash_val: str, file_name: str) -> None:
|
||||
"""Clean up duplicate entries in hash index after removing a model
|
||||
|
||||
Args:
|
||||
hash_val: SHA256 hash of the removed model
|
||||
file_name: File name of the removed model without extension
|
||||
"""
|
||||
if not hash_val or not file_name or not hasattr(self, '_hash_index'):
|
||||
return
|
||||
|
||||
# Clean up hash duplicates if only 0 or 1 entries remain
|
||||
if hash_val in self._hash_index._duplicate_hashes:
|
||||
if len(self._hash_index._duplicate_hashes[hash_val]) <= 1:
|
||||
del self._hash_index._duplicate_hashes[hash_val]
|
||||
|
||||
# Clean up filename duplicates if only 0 or 1 entries remain
|
||||
if file_name in self._hash_index._duplicate_filenames:
|
||||
if len(self._hash_index._duplicate_filenames[file_name]) <= 1:
|
||||
del self._hash_index._duplicate_filenames[file_name]
|
||||
|
||||
@@ -2,6 +2,7 @@ import asyncio
|
||||
from typing import List, Dict
|
||||
from dataclasses import dataclass
|
||||
from operator import itemgetter
|
||||
from natsort import natsorted
|
||||
|
||||
@dataclass
|
||||
class RecipeCache:
|
||||
@@ -16,7 +17,7 @@ class RecipeCache:
|
||||
async def resort(self, name_only: bool = False):
|
||||
"""Resort all cached data views"""
|
||||
async with self._lock:
|
||||
self.sorted_by_name = sorted(
|
||||
self.sorted_by_name = natsorted(
|
||||
self.raw_data,
|
||||
key=lambda x: x.get('title', '').lower() # Case-insensitive sort
|
||||
)
|
||||
|
||||
@@ -9,6 +9,7 @@ from .recipe_cache import RecipeCache
|
||||
from .service_registry import ServiceRegistry
|
||||
from .lora_scanner import LoraScanner
|
||||
from ..utils.utils import fuzzy_match
|
||||
from natsort import natsorted
|
||||
import sys
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
@@ -164,7 +165,7 @@ class RecipeScanner:
|
||||
if hasattr(self._cache, "resort"):
|
||||
try:
|
||||
# Sort by name
|
||||
self._cache.sorted_by_name = sorted(
|
||||
self._cache.sorted_by_name = natsorted(
|
||||
self._cache.raw_data,
|
||||
key=lambda x: x.get('title', '').lower()
|
||||
)
|
||||
@@ -321,6 +322,20 @@ class RecipeScanner:
|
||||
|
||||
# Update lora information with local paths and availability
|
||||
await self._update_lora_information(recipe_data)
|
||||
|
||||
# Calculate and update fingerprint if missing
|
||||
if 'loras' in recipe_data and 'fingerprint' not in recipe_data:
|
||||
from ..utils.utils import calculate_recipe_fingerprint
|
||||
fingerprint = calculate_recipe_fingerprint(recipe_data['loras'])
|
||||
recipe_data['fingerprint'] = fingerprint
|
||||
|
||||
# Write updated recipe data back to file
|
||||
try:
|
||||
with open(recipe_path, 'w', encoding='utf-8') as f:
|
||||
json.dump(recipe_data, f, indent=4, ensure_ascii=False)
|
||||
logger.info(f"Added fingerprint to recipe: {recipe_path}")
|
||||
except Exception as e:
|
||||
logger.error(f"Error writing updated recipe with fingerprint: {e}")
|
||||
|
||||
return recipe_data
|
||||
except Exception as e:
|
||||
@@ -341,6 +356,10 @@ class RecipeScanner:
|
||||
metadata_updated = False
|
||||
|
||||
for lora in recipe_data['loras']:
|
||||
# Skip deleted loras that were already marked
|
||||
if lora.get('isDeleted', False):
|
||||
continue
|
||||
|
||||
# Skip if already has complete information
|
||||
if 'hash' in lora and 'file_name' in lora and lora['file_name']:
|
||||
continue
|
||||
@@ -356,10 +375,17 @@ class RecipeScanner:
|
||||
metadata_updated = True
|
||||
else:
|
||||
# If not in cache, fetch from Civitai
|
||||
hash_from_civitai = await self._get_hash_from_civitai(model_version_id)
|
||||
if hash_from_civitai:
|
||||
lora['hash'] = hash_from_civitai
|
||||
metadata_updated = True
|
||||
result = await self._get_hash_from_civitai(model_version_id)
|
||||
if isinstance(result, tuple):
|
||||
hash_from_civitai, is_deleted = result
|
||||
if hash_from_civitai:
|
||||
lora['hash'] = hash_from_civitai
|
||||
metadata_updated = True
|
||||
elif is_deleted:
|
||||
# Mark the lora as deleted if it was not found on Civitai
|
||||
lora['isDeleted'] = True
|
||||
logger.warning(f"Marked lora with modelVersionId {model_version_id} as deleted")
|
||||
metadata_updated = True
|
||||
else:
|
||||
logger.debug(f"Could not get hash for modelVersionId {model_version_id}")
|
||||
|
||||
@@ -411,41 +437,26 @@ class RecipeScanner:
|
||||
logger.error("Failed to get CivitaiClient from ServiceRegistry")
|
||||
return None
|
||||
|
||||
version_info = await civitai_client.get_model_version_info(model_version_id)
|
||||
version_info, error_msg = await civitai_client.get_model_version_info(model_version_id)
|
||||
|
||||
if not version_info or not version_info.get('files'):
|
||||
logger.debug(f"No files found in version info for ID: {model_version_id}")
|
||||
return None
|
||||
|
||||
if not version_info:
|
||||
if error_msg and "model not found" in error_msg.lower():
|
||||
logger.warning(f"Model with version ID {model_version_id} was not found on Civitai - marking as deleted")
|
||||
return None, True # Return None hash and True for isDeleted flag
|
||||
else:
|
||||
logger.debug(f"Could not get hash for modelVersionId {model_version_id}: {error_msg}")
|
||||
return None, False # Return None hash but not marked as deleted
|
||||
|
||||
# Get hash from the first file
|
||||
for file_info in version_info.get('files', []):
|
||||
if file_info.get('hashes', {}).get('SHA256'):
|
||||
return file_info['hashes']['SHA256']
|
||||
return file_info['hashes']['SHA256'], False # Return hash with False for isDeleted flag
|
||||
|
||||
logger.debug(f"No SHA256 hash found in version info for ID: {model_version_id}")
|
||||
return None
|
||||
return None, False
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting hash from Civitai: {e}")
|
||||
return None
|
||||
|
||||
async def _get_model_version_name(self, model_version_id: str) -> Optional[str]:
|
||||
"""Get model version name from Civitai API"""
|
||||
try:
|
||||
# Get CivitaiClient from ServiceRegistry
|
||||
civitai_client = await self._get_civitai_client()
|
||||
if not civitai_client:
|
||||
return None
|
||||
|
||||
version_info = await civitai_client.get_model_version_info(model_version_id)
|
||||
|
||||
if version_info and 'name' in version_info:
|
||||
return version_info['name']
|
||||
|
||||
logger.debug(f"No version name found for modelVersionId {model_version_id}")
|
||||
return None
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting model version name from Civitai: {e}")
|
||||
return None
|
||||
return None, False
|
||||
|
||||
async def _determine_base_model(self, loras: List[Dict]) -> Optional[str]:
|
||||
"""Determine the most common base model among LoRAs"""
|
||||
@@ -805,3 +816,60 @@ class RecipeScanner:
|
||||
logger.info(f"Resorted recipe cache after updating {cache_updated_count} items")
|
||||
|
||||
return file_updated_count, cache_updated_count
|
||||
|
||||
async def find_recipes_by_fingerprint(self, fingerprint: str) -> list:
|
||||
"""Find recipes with a matching fingerprint
|
||||
|
||||
Args:
|
||||
fingerprint: The recipe fingerprint to search for
|
||||
|
||||
Returns:
|
||||
List of recipe details that match the fingerprint
|
||||
"""
|
||||
if not fingerprint:
|
||||
return []
|
||||
|
||||
# Get all recipes from cache
|
||||
cache = await self.get_cached_data()
|
||||
|
||||
# Find recipes with matching fingerprint
|
||||
matching_recipes = []
|
||||
for recipe in cache.raw_data:
|
||||
if recipe.get('fingerprint') == fingerprint:
|
||||
recipe_details = {
|
||||
'id': recipe.get('id'),
|
||||
'title': recipe.get('title'),
|
||||
'file_url': self._format_file_url(recipe.get('file_path')),
|
||||
'modified': recipe.get('modified'),
|
||||
'created_date': recipe.get('created_date'),
|
||||
'lora_count': len(recipe.get('loras', []))
|
||||
}
|
||||
matching_recipes.append(recipe_details)
|
||||
|
||||
return matching_recipes
|
||||
|
||||
async def find_all_duplicate_recipes(self) -> dict:
|
||||
"""Find all recipe duplicates based on fingerprints
|
||||
|
||||
Returns:
|
||||
Dictionary where keys are fingerprints and values are lists of recipe IDs
|
||||
"""
|
||||
# Get all recipes from cache
|
||||
cache = await self.get_cached_data()
|
||||
|
||||
# Group recipes by fingerprint
|
||||
fingerprint_groups = {}
|
||||
for recipe in cache.raw_data:
|
||||
fingerprint = recipe.get('fingerprint')
|
||||
if not fingerprint:
|
||||
continue
|
||||
|
||||
if fingerprint not in fingerprint_groups:
|
||||
fingerprint_groups[fingerprint] = []
|
||||
|
||||
fingerprint_groups[fingerprint].append(recipe.get('id'))
|
||||
|
||||
# Filter to only include groups with more than one recipe
|
||||
duplicate_groups = {k: v for k, v in fingerprint_groups.items() if len(v) > 1}
|
||||
|
||||
return duplicate_groups
|
||||
|
||||
@@ -11,15 +11,24 @@ NSFW_LEVELS = {
|
||||
PREVIEW_EXTENSIONS = [
|
||||
'.webp',
|
||||
'.preview.webp',
|
||||
'.preview.png',
|
||||
'.preview.jpeg',
|
||||
'.preview.jpg',
|
||||
'.preview.png',
|
||||
'.preview.jpeg',
|
||||
'.preview.jpg',
|
||||
'.preview.mp4',
|
||||
'.png',
|
||||
'.jpeg',
|
||||
'.jpg',
|
||||
'.png',
|
||||
'.jpeg',
|
||||
'.jpg',
|
||||
'.mp4'
|
||||
]
|
||||
|
||||
# Card preview image width
|
||||
CARD_PREVIEW_WIDTH = 480
|
||||
CARD_PREVIEW_WIDTH = 480
|
||||
|
||||
# Width for optimized example images
|
||||
EXAMPLE_IMAGE_WIDTH = 832
|
||||
|
||||
# Supported media extensions for example downloads
|
||||
SUPPORTED_MEDIA_EXTENSIONS = {
|
||||
'images': ['.jpg', '.jpeg', '.png', '.webp', '.gif'],
|
||||
'videos': ['.mp4', '.webm']
|
||||
}
|
||||
@@ -203,7 +203,7 @@ class ExifUtils:
|
||||
return user_comment[:recipe_marker_index] + user_comment[next_line_index:]
|
||||
|
||||
@staticmethod
|
||||
def optimize_image(image_data, target_width=250, format='webp', quality=85, preserve_metadata=True):
|
||||
def optimize_image(image_data, target_width=250, format='webp', quality=85, preserve_metadata=False):
|
||||
"""
|
||||
Optimize an image by resizing and converting to WebP format
|
||||
|
||||
@@ -218,98 +218,144 @@ class ExifUtils:
|
||||
Tuple of (optimized_image_data, extension)
|
||||
"""
|
||||
try:
|
||||
# Extract metadata if needed
|
||||
# First validate the image data is usable
|
||||
img = None
|
||||
if isinstance(image_data, str) and os.path.exists(image_data):
|
||||
# It's a file path - validate file
|
||||
try:
|
||||
with Image.open(image_data) as test_img:
|
||||
# Verify the image can be fully loaded by accessing its size
|
||||
width, height = test_img.size
|
||||
# If we got here, the image is valid
|
||||
img = Image.open(image_data)
|
||||
except (IOError, OSError) as e:
|
||||
logger.error(f"Invalid or corrupt image file: {image_data}: {e}")
|
||||
raise ValueError(f"Cannot process corrupt image: {e}")
|
||||
else:
|
||||
# It's binary data - validate data
|
||||
try:
|
||||
with BytesIO(image_data) as temp_buf:
|
||||
test_img = Image.open(temp_buf)
|
||||
# Verify the image can be fully loaded
|
||||
width, height = test_img.size
|
||||
# If successful, reopen for processing
|
||||
img = Image.open(BytesIO(image_data))
|
||||
except Exception as e:
|
||||
logger.error(f"Invalid binary image data: {e}")
|
||||
raise ValueError(f"Cannot process corrupt image data: {e}")
|
||||
|
||||
# Extract metadata if needed and valid
|
||||
metadata = None
|
||||
if preserve_metadata:
|
||||
if isinstance(image_data, str) and os.path.exists(image_data):
|
||||
# It's a file path
|
||||
metadata = ExifUtils.extract_image_metadata(image_data)
|
||||
img = Image.open(image_data)
|
||||
else:
|
||||
# It's binary data
|
||||
temp_img = BytesIO(image_data)
|
||||
img = Image.open(temp_img)
|
||||
# Save to a temporary file to extract metadata
|
||||
import tempfile
|
||||
with tempfile.NamedTemporaryFile(suffix='.jpg', delete=False) as temp_file:
|
||||
temp_path = temp_file.name
|
||||
temp_file.write(image_data)
|
||||
metadata = ExifUtils.extract_image_metadata(temp_path)
|
||||
os.unlink(temp_path)
|
||||
else:
|
||||
# Just open the image without extracting metadata
|
||||
if isinstance(image_data, str) and os.path.exists(image_data):
|
||||
img = Image.open(image_data)
|
||||
else:
|
||||
img = Image.open(BytesIO(image_data))
|
||||
|
||||
try:
|
||||
if isinstance(image_data, str) and os.path.exists(image_data):
|
||||
# For file path, extract directly
|
||||
metadata = ExifUtils.extract_image_metadata(image_data)
|
||||
else:
|
||||
# For binary data, save to temp file first
|
||||
import tempfile
|
||||
with tempfile.NamedTemporaryFile(suffix='.jpg', delete=False) as temp_file:
|
||||
temp_path = temp_file.name
|
||||
temp_file.write(image_data)
|
||||
try:
|
||||
metadata = ExifUtils.extract_image_metadata(temp_path)
|
||||
except Exception as e:
|
||||
logger.warning(f"Failed to extract metadata from temp file: {e}")
|
||||
finally:
|
||||
# Clean up temp file
|
||||
try:
|
||||
os.unlink(temp_path)
|
||||
except Exception:
|
||||
pass
|
||||
except Exception as e:
|
||||
logger.warning(f"Failed to extract metadata, continuing without it: {e}")
|
||||
# Continue without metadata
|
||||
|
||||
# Calculate new height to maintain aspect ratio
|
||||
width, height = img.size
|
||||
new_height = int(height * (target_width / width))
|
||||
|
||||
# Resize the image
|
||||
resized_img = img.resize((target_width, new_height), Image.LANCZOS)
|
||||
# Resize the image with error handling
|
||||
try:
|
||||
resized_img = img.resize((target_width, new_height), Image.LANCZOS)
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to resize image: {e}")
|
||||
# Return original image if resize fails
|
||||
return image_data, '.jpg' if not isinstance(image_data, str) else os.path.splitext(image_data)[1]
|
||||
|
||||
# Save to BytesIO in the specified format
|
||||
output = BytesIO()
|
||||
|
||||
# WebP format
|
||||
# Set format and extension
|
||||
if format.lower() == 'webp':
|
||||
resized_img.save(output, format='WEBP', quality=quality)
|
||||
extension = '.webp'
|
||||
# JPEG format
|
||||
save_format, extension = 'WEBP', '.webp'
|
||||
elif format.lower() in ('jpg', 'jpeg'):
|
||||
resized_img.save(output, format='JPEG', quality=quality)
|
||||
extension = '.jpg'
|
||||
# PNG format
|
||||
save_format, extension = 'JPEG', '.jpg'
|
||||
elif format.lower() == 'png':
|
||||
resized_img.save(output, format='PNG', optimize=True)
|
||||
extension = '.png'
|
||||
save_format, extension = 'PNG', '.png'
|
||||
else:
|
||||
# Default to WebP
|
||||
resized_img.save(output, format='WEBP', quality=quality)
|
||||
extension = '.webp'
|
||||
save_format, extension = 'WEBP', '.webp'
|
||||
|
||||
# Save with error handling
|
||||
try:
|
||||
if save_format == 'PNG':
|
||||
resized_img.save(output, format=save_format, optimize=True)
|
||||
else:
|
||||
resized_img.save(output, format=save_format, quality=quality)
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to save optimized image: {e}")
|
||||
# Return original image if save fails
|
||||
return image_data, '.jpg' if not isinstance(image_data, str) else os.path.splitext(image_data)[1]
|
||||
|
||||
# Get the optimized image data
|
||||
optimized_data = output.getvalue()
|
||||
|
||||
# If we need to preserve metadata, write it to a temporary file
|
||||
# Handle metadata preservation if requested and available
|
||||
if preserve_metadata and metadata:
|
||||
# For WebP format, we'll directly save with metadata
|
||||
if format.lower() == 'webp':
|
||||
# Create a new BytesIO with metadata
|
||||
output_with_metadata = BytesIO()
|
||||
|
||||
# Create EXIF data with user comment
|
||||
exif_dict = {'Exif': {piexif.ExifIFD.UserComment: b'UNICODE\0' + metadata.encode('utf-16be')}}
|
||||
exif_bytes = piexif.dump(exif_dict)
|
||||
|
||||
# Save with metadata
|
||||
resized_img.save(output_with_metadata, format='WEBP', exif=exif_bytes, quality=quality)
|
||||
optimized_data = output_with_metadata.getvalue()
|
||||
else:
|
||||
# For other formats, use the temporary file approach
|
||||
import tempfile
|
||||
with tempfile.NamedTemporaryFile(suffix=extension, delete=False) as temp_file:
|
||||
temp_path = temp_file.name
|
||||
temp_file.write(optimized_data)
|
||||
|
||||
# Add the metadata back
|
||||
ExifUtils.update_image_metadata(temp_path, metadata)
|
||||
|
||||
# Read the file with metadata
|
||||
with open(temp_path, 'rb') as f:
|
||||
optimized_data = f.read()
|
||||
|
||||
# Clean up
|
||||
os.unlink(temp_path)
|
||||
try:
|
||||
if save_format == 'WEBP':
|
||||
# For WebP format, directly save with metadata
|
||||
try:
|
||||
output_with_metadata = BytesIO()
|
||||
exif_dict = {'Exif': {piexif.ExifIFD.UserComment: b'UNICODE\0' + metadata.encode('utf-16be')}}
|
||||
exif_bytes = piexif.dump(exif_dict)
|
||||
resized_img.save(output_with_metadata, format='WEBP', exif=exif_bytes, quality=quality)
|
||||
optimized_data = output_with_metadata.getvalue()
|
||||
except Exception as e:
|
||||
logger.warning(f"Failed to add metadata to WebP, continuing without it: {e}")
|
||||
else:
|
||||
# For other formats, use temporary file
|
||||
import tempfile
|
||||
with tempfile.NamedTemporaryFile(suffix=extension, delete=False) as temp_file:
|
||||
temp_path = temp_file.name
|
||||
temp_file.write(optimized_data)
|
||||
|
||||
try:
|
||||
# Add metadata
|
||||
ExifUtils.update_image_metadata(temp_path, metadata)
|
||||
# Read back the file
|
||||
with open(temp_path, 'rb') as f:
|
||||
optimized_data = f.read()
|
||||
except Exception as e:
|
||||
logger.warning(f"Failed to add metadata to image, continuing without it: {e}")
|
||||
finally:
|
||||
# Clean up temp file
|
||||
try:
|
||||
os.unlink(temp_path)
|
||||
except Exception:
|
||||
pass
|
||||
except Exception as e:
|
||||
logger.warning(f"Failed to preserve metadata: {e}, continuing with unmodified output")
|
||||
|
||||
return optimized_data, extension
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error optimizing image: {e}", exc_info=True)
|
||||
# Return original data if optimization fails
|
||||
# Return original data if optimization completely fails
|
||||
if isinstance(image_data, str) and os.path.exists(image_data):
|
||||
with open(image_data, 'rb') as f:
|
||||
return f.read(), os.path.splitext(image_data)[1]
|
||||
try:
|
||||
with open(image_data, 'rb') as f:
|
||||
return f.read(), os.path.splitext(image_data)[1]
|
||||
except Exception:
|
||||
return image_data, '.jpg' # Last resort fallback
|
||||
return image_data, '.jpg'
|
||||
@@ -42,7 +42,7 @@ def find_preview_file(base_name: str, dir_path: str) -> str:
|
||||
target_width=CARD_PREVIEW_WIDTH,
|
||||
format='webp',
|
||||
quality=85,
|
||||
preserve_metadata=True
|
||||
preserve_metadata=False # Changed from True to False
|
||||
)
|
||||
|
||||
# Save the optimized webp file
|
||||
@@ -233,6 +233,17 @@ async def load_metadata(file_path: str, model_class: Type[BaseModelMetadata] = L
|
||||
data['usage_tips'] = "{}"
|
||||
needs_update = True
|
||||
|
||||
# Update preview_nsfw_level if needed
|
||||
civitai_data = data.get('civitai', {})
|
||||
civitai_images = civitai_data.get('images', []) if civitai_data else []
|
||||
if (data.get('preview_url') and
|
||||
data.get('preview_nsfw_level', 0) == 0 and
|
||||
civitai_images and
|
||||
civitai_images[0].get('nsfwLevel', 0) != 0):
|
||||
data['preview_nsfw_level'] = civitai_images[0]['nsfwLevel']
|
||||
# TODO: write to metadata file
|
||||
# needs_update = True
|
||||
|
||||
if needs_update:
|
||||
with open(metadata_path, 'w', encoding='utf-8') as f:
|
||||
json.dump(data, f, indent=2, ensure_ascii=False)
|
||||
|
||||
@@ -1,7 +1,11 @@
|
||||
from safetensors import safe_open
|
||||
from typing import Dict
|
||||
from typing import Dict, List, Tuple
|
||||
from .model_utils import determine_base_model
|
||||
import os
|
||||
import logging
|
||||
import json
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
async def extract_lora_metadata(file_path: str) -> Dict:
|
||||
"""Extract essential metadata from safetensors file"""
|
||||
@@ -77,4 +81,53 @@ async def extract_checkpoint_metadata(file_path: str) -> dict:
|
||||
except Exception as e:
|
||||
logger.error(f"Error extracting checkpoint metadata for {file_path}: {e}")
|
||||
# Return default values
|
||||
return {'base_model': 'Unknown', 'model_type': 'checkpoint'}
|
||||
return {'base_model': 'Unknown', 'model_type': 'checkpoint'}
|
||||
|
||||
async def extract_trained_words(file_path: str) -> Tuple[List[Tuple[str, int]], str]:
|
||||
"""Extract trained words from a safetensors file and sort by frequency
|
||||
|
||||
Args:
|
||||
file_path: Path to the safetensors file
|
||||
|
||||
Returns:
|
||||
Tuple of:
|
||||
- List of (word, frequency) tuples sorted by frequency (highest first)
|
||||
- class_tokens value (or None if not found)
|
||||
"""
|
||||
class_tokens = None
|
||||
|
||||
try:
|
||||
with safe_open(file_path, framework="pt", device="cpu") as f:
|
||||
metadata = f.metadata()
|
||||
|
||||
# Extract class_tokens from ss_datasets if present
|
||||
if metadata and "ss_datasets" in metadata:
|
||||
try:
|
||||
datasets_data = json.loads(metadata["ss_datasets"])
|
||||
# Look for class_tokens in the first subset
|
||||
if datasets_data and isinstance(datasets_data, list) and datasets_data[0].get("subsets"):
|
||||
subsets = datasets_data[0].get("subsets", [])
|
||||
if subsets and isinstance(subsets, list) and len(subsets) > 0:
|
||||
class_tokens = subsets[0].get("class_tokens")
|
||||
except Exception as e:
|
||||
logger.error(f"Error parsing ss_datasets for class_tokens: {str(e)}")
|
||||
|
||||
# Extract tag frequency as before
|
||||
if metadata and "ss_tag_frequency" in metadata:
|
||||
# Parse the JSON string into a dictionary
|
||||
tag_data = json.loads(metadata["ss_tag_frequency"])
|
||||
|
||||
# The structure may have an outer key (like "image_dir" or "img")
|
||||
# We need to get the inner dictionary with the actual word frequencies
|
||||
if tag_data:
|
||||
# Get the first key (usually "image_dir" or "img")
|
||||
first_key = list(tag_data.keys())[0]
|
||||
words_dict = tag_data[first_key]
|
||||
|
||||
# Sort words by frequency (highest first)
|
||||
sorted_words = sorted(words_dict.items(), key=lambda x: x[1], reverse=True)
|
||||
return sorted_words, class_tokens
|
||||
except Exception as e:
|
||||
logger.error(f"Error extracting trained words from {file_path}: {str(e)}")
|
||||
|
||||
return [], class_tokens
|
||||
@@ -21,6 +21,9 @@ class BaseModelMetadata:
|
||||
civitai: Optional[Dict] = None # Civitai API data if available
|
||||
tags: List[str] = None # Model tags
|
||||
modelDescription: str = "" # Full model description
|
||||
civitai_deleted: bool = False # Whether deleted from Civitai
|
||||
favorite: bool = False # Whether the model is a favorite
|
||||
exclude: bool = False # Whether to exclude this model from the cache
|
||||
|
||||
def __post_init__(self):
|
||||
# Initialize empty lists to avoid mutable default parameter issue
|
||||
@@ -64,6 +67,15 @@ class LoraMetadata(BaseModelMetadata):
|
||||
file_name = file_info['name']
|
||||
base_model = determine_base_model(version_info.get('baseModel', ''))
|
||||
|
||||
# Extract tags and description if available
|
||||
tags = []
|
||||
description = ""
|
||||
if 'model' in version_info:
|
||||
if 'tags' in version_info['model']:
|
||||
tags = version_info['model']['tags']
|
||||
if 'description' in version_info['model']:
|
||||
description = version_info['model']['description']
|
||||
|
||||
return cls(
|
||||
file_name=os.path.splitext(file_name)[0],
|
||||
model_name=version_info.get('model').get('name', os.path.splitext(file_name)[0]),
|
||||
@@ -75,7 +87,9 @@ class LoraMetadata(BaseModelMetadata):
|
||||
preview_url=None, # Will be updated after preview download
|
||||
preview_nsfw_level=0, # Will be updated after preview download
|
||||
from_civitai=True,
|
||||
civitai=version_info
|
||||
civitai=version_info,
|
||||
tags=tags,
|
||||
modelDescription=description
|
||||
)
|
||||
|
||||
@dataclass
|
||||
@@ -90,6 +104,15 @@ class CheckpointMetadata(BaseModelMetadata):
|
||||
base_model = determine_base_model(version_info.get('baseModel', ''))
|
||||
model_type = version_info.get('type', 'checkpoint')
|
||||
|
||||
# Extract tags and description if available
|
||||
tags = []
|
||||
description = ""
|
||||
if 'model' in version_info:
|
||||
if 'tags' in version_info['model']:
|
||||
tags = version_info['model']['tags']
|
||||
if 'description' in version_info['model']:
|
||||
description = version_info['model']['description']
|
||||
|
||||
return cls(
|
||||
file_name=os.path.splitext(file_name)[0],
|
||||
model_name=version_info.get('model').get('name', os.path.splitext(file_name)[0]),
|
||||
@@ -102,6 +125,8 @@ class CheckpointMetadata(BaseModelMetadata):
|
||||
preview_nsfw_level=0,
|
||||
from_civitai=True,
|
||||
civitai=version_info,
|
||||
model_type=model_type
|
||||
model_type=model_type,
|
||||
tags=tags,
|
||||
modelDescription=description
|
||||
)
|
||||
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -40,6 +40,7 @@ class ModelRouteUtils:
|
||||
civitai_metadata: Dict, client: CivitaiClient) -> None:
|
||||
"""Update local metadata with CivitAI data"""
|
||||
local_metadata['civitai'] = civitai_metadata
|
||||
local_metadata['from_civitai'] = True
|
||||
|
||||
# Update model name if available
|
||||
if 'model' in civitai_metadata:
|
||||
@@ -50,9 +51,10 @@ class ModelRouteUtils:
|
||||
model_id = civitai_metadata['modelId']
|
||||
if model_id:
|
||||
model_metadata, _ = await client.get_model_metadata(str(model_id))
|
||||
if model_metadata:
|
||||
if (model_metadata):
|
||||
local_metadata['modelDescription'] = model_metadata.get('description', '')
|
||||
local_metadata['tags'] = model_metadata.get('tags', [])
|
||||
local_metadata['civitai']['creator'] = model_metadata['creator']
|
||||
|
||||
# Update base model
|
||||
local_metadata['base_model'] = determine_base_model(civitai_metadata.get('baseModel'))
|
||||
@@ -60,7 +62,7 @@ class ModelRouteUtils:
|
||||
# Update preview if needed
|
||||
if not local_metadata.get('preview_url') or not os.path.exists(local_metadata['preview_url']):
|
||||
first_preview = next((img for img in civitai_metadata.get('images', [])), None)
|
||||
if first_preview:
|
||||
if (first_preview):
|
||||
# Determine if content is video or image
|
||||
is_video = first_preview['type'] == 'video'
|
||||
|
||||
@@ -95,7 +97,7 @@ class ModelRouteUtils:
|
||||
target_width=CARD_PREVIEW_WIDTH,
|
||||
format='webp',
|
||||
quality=85,
|
||||
preserve_metadata=True
|
||||
preserve_metadata=False
|
||||
)
|
||||
|
||||
# Save the optimized WebP image
|
||||
@@ -142,6 +144,11 @@ class ModelRouteUtils:
|
||||
"""
|
||||
client = CivitaiClient()
|
||||
try:
|
||||
# Validate input parameters
|
||||
if not isinstance(model_data, dict):
|
||||
logger.error(f"Invalid model_data type: {type(model_data)}")
|
||||
return False
|
||||
|
||||
metadata_path = os.path.splitext(file_path)[0] + '.metadata.json'
|
||||
|
||||
# Check if model metadata exists
|
||||
@@ -165,21 +172,25 @@ class ModelRouteUtils:
|
||||
client
|
||||
)
|
||||
|
||||
# Update cache object directly
|
||||
model_data.update({
|
||||
# Update cache object directly using safe .get() method
|
||||
update_dict = {
|
||||
'model_name': local_metadata.get('model_name'),
|
||||
'preview_url': local_metadata.get('preview_url'),
|
||||
'from_civitai': True,
|
||||
'civitai': civitai_metadata
|
||||
})
|
||||
}
|
||||
model_data.update(update_dict)
|
||||
|
||||
# Update cache using the provided function
|
||||
await update_cache_func(file_path, file_path, local_metadata)
|
||||
|
||||
return True
|
||||
|
||||
except KeyError as e:
|
||||
logger.error(f"Error fetching CivitAI data - Missing key: {e} in model_data={model_data}")
|
||||
return False
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching CivitAI data: {e}")
|
||||
logger.error(f"Error fetching CivitAI data: {str(e)}", exc_info=True) # Include stack trace
|
||||
return False
|
||||
finally:
|
||||
await client.close()
|
||||
@@ -193,7 +204,7 @@ class ModelRouteUtils:
|
||||
fields = [
|
||||
"id", "modelId", "name", "createdAt", "updatedAt",
|
||||
"publishedAt", "trainedWords", "baseModel", "description",
|
||||
"model", "images"
|
||||
"model", "images", "creator"
|
||||
]
|
||||
return {k: data[k] for k in fields if k in data}
|
||||
|
||||
@@ -292,6 +303,8 @@ class ModelRouteUtils:
|
||||
# Update hash index if available
|
||||
if hasattr(scanner, '_hash_index') and scanner._hash_index:
|
||||
scanner._hash_index.remove_by_path(file_path)
|
||||
|
||||
await scanner._save_cache_to_disk()
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
@@ -387,7 +400,7 @@ class ModelRouteUtils:
|
||||
target_width=CARD_PREVIEW_WIDTH,
|
||||
format='webp',
|
||||
quality=85,
|
||||
preserve_metadata=True
|
||||
preserve_metadata=False
|
||||
)
|
||||
extension = '.webp' # Use .webp without .preview part
|
||||
|
||||
@@ -424,6 +437,67 @@ class ModelRouteUtils:
|
||||
logger.error(f"Error replacing preview: {e}", exc_info=True)
|
||||
return web.Response(text=str(e), status=500)
|
||||
|
||||
@staticmethod
|
||||
async def handle_exclude_model(request: web.Request, scanner) -> web.Response:
|
||||
"""Handle model exclusion request
|
||||
|
||||
Args:
|
||||
request: The aiohttp request
|
||||
scanner: The model scanner instance with cache management methods
|
||||
|
||||
Returns:
|
||||
web.Response: The HTTP response
|
||||
"""
|
||||
try:
|
||||
data = await request.json()
|
||||
file_path = data.get('file_path')
|
||||
if not file_path:
|
||||
return web.Response(text='Model path is required', status=400)
|
||||
|
||||
# Update metadata to mark as excluded
|
||||
metadata_path = os.path.splitext(file_path)[0] + '.metadata.json'
|
||||
metadata = await ModelRouteUtils.load_local_metadata(metadata_path)
|
||||
metadata['exclude'] = True
|
||||
|
||||
# Save updated metadata
|
||||
with open(metadata_path, 'w', encoding='utf-8') as f:
|
||||
json.dump(metadata, f, indent=2, ensure_ascii=False)
|
||||
|
||||
# Update cache
|
||||
cache = await scanner.get_cached_data()
|
||||
|
||||
# Find and remove model from cache
|
||||
model_to_remove = next((item for item in cache.raw_data if item['file_path'] == file_path), None)
|
||||
if model_to_remove:
|
||||
# Update tags count
|
||||
for tag in model_to_remove.get('tags', []):
|
||||
if tag in scanner._tags_count:
|
||||
scanner._tags_count[tag] = max(0, scanner._tags_count[tag] - 1)
|
||||
if scanner._tags_count[tag] == 0:
|
||||
del scanner._tags_count[tag]
|
||||
|
||||
# Remove from hash index if available
|
||||
if hasattr(scanner, '_hash_index') and scanner._hash_index:
|
||||
scanner._hash_index.remove_by_path(file_path)
|
||||
|
||||
# Remove from cache data
|
||||
cache.raw_data = [item for item in cache.raw_data if item['file_path'] != file_path]
|
||||
await cache.resort()
|
||||
|
||||
# Add to excluded models list
|
||||
scanner._excluded_models.append(file_path)
|
||||
|
||||
await scanner._save_cache_to_disk()
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'message': f"Model {os.path.basename(file_path)} excluded"
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error excluding model: {e}", exc_info=True)
|
||||
return web.Response(text=str(e), status=500)
|
||||
|
||||
@staticmethod
|
||||
async def handle_download_model(request: web.Request, download_manager: DownloadManager, model_type="lora") -> web.Response:
|
||||
"""Handle model download request
|
||||
@@ -500,4 +574,107 @@ class ModelRouteUtils:
|
||||
)
|
||||
|
||||
logger.error(f"Error downloading {model_type}: {error_message}")
|
||||
return web.Response(status=500, text=error_message)
|
||||
return web.Response(status=500, text=error_message)
|
||||
|
||||
@staticmethod
|
||||
async def handle_bulk_delete_models(request: web.Request, scanner) -> web.Response:
|
||||
"""Handle bulk deletion of models
|
||||
|
||||
Args:
|
||||
request: The aiohttp request
|
||||
scanner: The model scanner instance with cache management methods
|
||||
|
||||
Returns:
|
||||
web.Response: The HTTP response
|
||||
"""
|
||||
try:
|
||||
data = await request.json()
|
||||
file_paths = data.get('file_paths', [])
|
||||
|
||||
if not file_paths:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'No file paths provided for deletion'
|
||||
}, status=400)
|
||||
|
||||
# Use the scanner's bulk delete method to handle all cache and file operations
|
||||
result = await scanner.bulk_delete_models(file_paths)
|
||||
|
||||
return web.json_response({
|
||||
'success': result.get('success', False),
|
||||
'total_deleted': result.get('total_deleted', 0),
|
||||
'total_attempted': result.get('total_attempted', len(file_paths)),
|
||||
'results': result.get('results', [])
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error in bulk delete: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
@staticmethod
|
||||
async def handle_relink_civitai(request: web.Request, scanner) -> web.Response:
|
||||
"""Handle CivitAI metadata re-linking request by model version ID
|
||||
|
||||
Args:
|
||||
request: The aiohttp request
|
||||
scanner: The model scanner instance with cache management methods
|
||||
|
||||
Returns:
|
||||
web.Response: The HTTP response
|
||||
"""
|
||||
try:
|
||||
data = await request.json()
|
||||
file_path = data.get('file_path')
|
||||
model_version_id = data.get('model_version_id')
|
||||
|
||||
if not file_path or not model_version_id:
|
||||
return web.json_response({"success": False, "error": "Both file_path and model_version_id are required"}, status=400)
|
||||
|
||||
metadata_path = os.path.splitext(file_path)[0] + '.metadata.json'
|
||||
|
||||
# Check if model metadata exists
|
||||
local_metadata = await ModelRouteUtils.load_local_metadata(metadata_path)
|
||||
|
||||
# Create a client for fetching from Civitai
|
||||
client = await CivitaiClient.get_instance()
|
||||
try:
|
||||
# Fetch metadata by model version ID
|
||||
civitai_metadata, error = await client.get_model_version_info(model_version_id)
|
||||
if not civitai_metadata:
|
||||
error_msg = error or "Model version not found on CivitAI"
|
||||
return web.json_response({"success": False, "error": error_msg}, status=404)
|
||||
|
||||
# Find the primary model file to get the correct SHA256 hash
|
||||
primary_model_file = None
|
||||
for file in civitai_metadata.get('files', []):
|
||||
if file.get('primary', False) and file.get('type') == 'Model':
|
||||
primary_model_file = file
|
||||
break
|
||||
|
||||
if not primary_model_file or not primary_model_file.get('hashes', {}).get('SHA256'):
|
||||
return web.json_response({"success": False, "error": "No SHA256 hash found in model metadata"}, status=404)
|
||||
|
||||
# Update the SHA256 hash in local metadata (convert to lowercase)
|
||||
local_metadata['sha256'] = primary_model_file['hashes']['SHA256'].lower()
|
||||
|
||||
# Update metadata with CivitAI information
|
||||
await ModelRouteUtils.update_model_metadata(metadata_path, local_metadata, civitai_metadata, client)
|
||||
|
||||
# Update the cache
|
||||
await scanner.update_single_model_cache(file_path, file_path, local_metadata)
|
||||
|
||||
return web.json_response({
|
||||
"success": True,
|
||||
"message": f"Model successfully re-linked to Civitai version {model_version_id}",
|
||||
"hash": local_metadata['sha256']
|
||||
})
|
||||
|
||||
finally:
|
||||
await client.close()
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error re-linking to CivitAI: {e}", exc_info=True)
|
||||
return web.json_response({"success": False, "error": str(e)}, status=500)
|
||||
|
||||
376
py/utils/usage_stats.py
Normal file
376
py/utils/usage_stats.py
Normal file
@@ -0,0 +1,376 @@
|
||||
import os
|
||||
import json
|
||||
import sys
|
||||
import time
|
||||
import asyncio
|
||||
import logging
|
||||
import datetime
|
||||
import shutil
|
||||
from typing import Dict, Set
|
||||
|
||||
from ..config import config
|
||||
from ..services.service_registry import ServiceRegistry
|
||||
|
||||
# Check if running in standalone mode
|
||||
standalone_mode = 'nodes' not in sys.modules
|
||||
|
||||
if not standalone_mode:
|
||||
from ..metadata_collector.metadata_registry import MetadataRegistry
|
||||
from ..metadata_collector.constants import MODELS, LORAS
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class UsageStats:
|
||||
"""Track usage statistics for models and save to JSON"""
|
||||
|
||||
_instance = None
|
||||
_lock = asyncio.Lock() # For thread safety
|
||||
|
||||
# Default stats file name
|
||||
STATS_FILENAME = "lora_manager_stats.json"
|
||||
BACKUP_SUFFIX = ".backup"
|
||||
|
||||
def __new__(cls):
|
||||
if cls._instance is None:
|
||||
cls._instance = super().__new__(cls)
|
||||
cls._instance._initialized = False
|
||||
return cls._instance
|
||||
|
||||
def __init__(self):
|
||||
if self._initialized:
|
||||
return
|
||||
|
||||
# Initialize stats storage
|
||||
self.stats = {
|
||||
"checkpoints": {}, # sha256 -> { total: count, history: { date: count } }
|
||||
"loras": {}, # sha256 -> { total: count, history: { date: count } }
|
||||
"total_executions": 0,
|
||||
"last_save_time": 0
|
||||
}
|
||||
|
||||
# Queue for prompt_ids to process
|
||||
self.pending_prompt_ids = set()
|
||||
|
||||
# Load existing stats if available
|
||||
self._stats_file_path = self._get_stats_file_path()
|
||||
self._load_stats()
|
||||
|
||||
# Save interval in seconds
|
||||
self.save_interval = 90 # 1.5 minutes
|
||||
|
||||
# Start background task to process queued prompt_ids
|
||||
self._bg_task = asyncio.create_task(self._background_processor())
|
||||
|
||||
self._initialized = True
|
||||
logger.info("Usage statistics tracker initialized")
|
||||
|
||||
def _get_stats_file_path(self) -> str:
|
||||
"""Get the path to the stats JSON file"""
|
||||
if not config.loras_roots or len(config.loras_roots) == 0:
|
||||
# Fallback to temporary directory if no lora roots
|
||||
return os.path.join(config.temp_directory, self.STATS_FILENAME)
|
||||
|
||||
# Use the first lora root
|
||||
return os.path.join(config.loras_roots[0], self.STATS_FILENAME)
|
||||
|
||||
def _backup_old_stats(self):
|
||||
"""Backup the old stats file before conversion"""
|
||||
if os.path.exists(self._stats_file_path):
|
||||
backup_path = f"{self._stats_file_path}{self.BACKUP_SUFFIX}"
|
||||
try:
|
||||
shutil.copy2(self._stats_file_path, backup_path)
|
||||
logger.info(f"Backed up old stats file to {backup_path}")
|
||||
return True
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to backup stats file: {e}")
|
||||
return False
|
||||
|
||||
def _convert_old_format(self, old_stats):
|
||||
"""Convert old stats format to new format with history"""
|
||||
new_stats = {
|
||||
"checkpoints": {},
|
||||
"loras": {},
|
||||
"total_executions": old_stats.get("total_executions", 0),
|
||||
"last_save_time": old_stats.get("last_save_time", time.time())
|
||||
}
|
||||
|
||||
# Get today's date in YYYY-MM-DD format
|
||||
today = datetime.datetime.now().strftime("%Y-%m-%d")
|
||||
|
||||
# Convert checkpoint stats
|
||||
if "checkpoints" in old_stats and isinstance(old_stats["checkpoints"], dict):
|
||||
for hash_id, count in old_stats["checkpoints"].items():
|
||||
new_stats["checkpoints"][hash_id] = {
|
||||
"total": count,
|
||||
"history": {
|
||||
today: count
|
||||
}
|
||||
}
|
||||
|
||||
# Convert lora stats
|
||||
if "loras" in old_stats and isinstance(old_stats["loras"], dict):
|
||||
for hash_id, count in old_stats["loras"].items():
|
||||
new_stats["loras"][hash_id] = {
|
||||
"total": count,
|
||||
"history": {
|
||||
today: count
|
||||
}
|
||||
}
|
||||
|
||||
logger.info("Successfully converted stats from old format to new format with history")
|
||||
return new_stats
|
||||
|
||||
def _is_old_format(self, stats):
|
||||
"""Check if the stats are in the old format (direct count values)"""
|
||||
# Check if any lora or checkpoint entry is a direct number instead of an object
|
||||
if "loras" in stats and isinstance(stats["loras"], dict):
|
||||
for hash_id, data in stats["loras"].items():
|
||||
if isinstance(data, (int, float)):
|
||||
return True
|
||||
|
||||
if "checkpoints" in stats and isinstance(stats["checkpoints"], dict):
|
||||
for hash_id, data in stats["checkpoints"].items():
|
||||
if isinstance(data, (int, float)):
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
def _load_stats(self):
|
||||
"""Load existing statistics from file"""
|
||||
try:
|
||||
if os.path.exists(self._stats_file_path):
|
||||
with open(self._stats_file_path, 'r', encoding='utf-8') as f:
|
||||
loaded_stats = json.load(f)
|
||||
|
||||
# Check if old format and needs conversion
|
||||
if self._is_old_format(loaded_stats):
|
||||
logger.info("Detected old stats format, performing conversion")
|
||||
self._backup_old_stats()
|
||||
self.stats = self._convert_old_format(loaded_stats)
|
||||
else:
|
||||
# Update our stats with loaded data (already in new format)
|
||||
if isinstance(loaded_stats, dict):
|
||||
# Update individual sections to maintain structure
|
||||
if "checkpoints" in loaded_stats and isinstance(loaded_stats["checkpoints"], dict):
|
||||
self.stats["checkpoints"] = loaded_stats["checkpoints"]
|
||||
|
||||
if "loras" in loaded_stats and isinstance(loaded_stats["loras"], dict):
|
||||
self.stats["loras"] = loaded_stats["loras"]
|
||||
|
||||
if "total_executions" in loaded_stats:
|
||||
self.stats["total_executions"] = loaded_stats["total_executions"]
|
||||
|
||||
if "last_save_time" in loaded_stats:
|
||||
self.stats["last_save_time"] = loaded_stats["last_save_time"]
|
||||
|
||||
logger.info(f"Loaded usage statistics from {self._stats_file_path}")
|
||||
except Exception as e:
|
||||
logger.error(f"Error loading usage statistics: {e}")
|
||||
|
||||
async def save_stats(self, force=False):
|
||||
"""Save statistics to file"""
|
||||
try:
|
||||
# Only save if it's been at least save_interval since last save or force is True
|
||||
current_time = time.time()
|
||||
if not force and (current_time - self.stats.get("last_save_time", 0)) < self.save_interval:
|
||||
return False
|
||||
|
||||
# Use a lock to prevent concurrent writes
|
||||
async with self._lock:
|
||||
# Update last save time
|
||||
self.stats["last_save_time"] = current_time
|
||||
|
||||
# Create directory if it doesn't exist
|
||||
os.makedirs(os.path.dirname(self._stats_file_path), exist_ok=True)
|
||||
|
||||
# Write to a temporary file first, then move it to avoid corruption
|
||||
temp_path = f"{self._stats_file_path}.tmp"
|
||||
with open(temp_path, 'w', encoding='utf-8') as f:
|
||||
json.dump(self.stats, f, indent=2, ensure_ascii=False)
|
||||
|
||||
# Replace the old file with the new one
|
||||
os.replace(temp_path, self._stats_file_path)
|
||||
|
||||
logger.debug(f"Saved usage statistics to {self._stats_file_path}")
|
||||
return True
|
||||
except Exception as e:
|
||||
logger.error(f"Error saving usage statistics: {e}", exc_info=True)
|
||||
return False
|
||||
|
||||
def register_execution(self, prompt_id):
|
||||
"""Register a completed execution by prompt_id for later processing"""
|
||||
if prompt_id:
|
||||
self.pending_prompt_ids.add(prompt_id)
|
||||
|
||||
async def _background_processor(self):
|
||||
"""Background task to process queued prompt_ids"""
|
||||
try:
|
||||
while True:
|
||||
# Wait a short interval before checking for new prompt_ids
|
||||
await asyncio.sleep(5) # Check every 5 seconds
|
||||
|
||||
# Process any pending prompt_ids
|
||||
if self.pending_prompt_ids:
|
||||
async with self._lock:
|
||||
# Get a copy of the set and clear original
|
||||
prompt_ids = self.pending_prompt_ids.copy()
|
||||
self.pending_prompt_ids.clear()
|
||||
|
||||
# Process each prompt_id
|
||||
registry = MetadataRegistry()
|
||||
for prompt_id in prompt_ids:
|
||||
try:
|
||||
metadata = registry.get_metadata(prompt_id)
|
||||
await self._process_metadata(metadata)
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing prompt_id {prompt_id}: {e}")
|
||||
|
||||
# Periodically save stats
|
||||
await self.save_stats()
|
||||
except asyncio.CancelledError:
|
||||
# Task was cancelled, clean up
|
||||
await self.save_stats(force=True)
|
||||
except Exception as e:
|
||||
logger.error(f"Error in background processing task: {e}", exc_info=True)
|
||||
# Restart the task after a delay if it fails
|
||||
asyncio.create_task(self._restart_background_task())
|
||||
|
||||
async def _restart_background_task(self):
|
||||
"""Restart the background task after a delay"""
|
||||
await asyncio.sleep(30) # Wait 30 seconds before restarting
|
||||
self._bg_task = asyncio.create_task(self._background_processor())
|
||||
|
||||
async def _process_metadata(self, metadata):
|
||||
"""Process metadata from an execution"""
|
||||
if not metadata or not isinstance(metadata, dict):
|
||||
return
|
||||
|
||||
# Increment total executions count
|
||||
self.stats["total_executions"] += 1
|
||||
|
||||
# Get today's date in YYYY-MM-DD format
|
||||
today = datetime.datetime.now().strftime("%Y-%m-%d")
|
||||
|
||||
# Process checkpoints
|
||||
if MODELS in metadata and isinstance(metadata[MODELS], dict):
|
||||
await self._process_checkpoints(metadata[MODELS], today)
|
||||
|
||||
# Process loras
|
||||
if LORAS in metadata and isinstance(metadata[LORAS], dict):
|
||||
await self._process_loras(metadata[LORAS], today)
|
||||
|
||||
async def _process_checkpoints(self, models_data, today_date):
|
||||
"""Process checkpoint models from metadata"""
|
||||
try:
|
||||
# Get checkpoint scanner service
|
||||
checkpoint_scanner = await ServiceRegistry.get_checkpoint_scanner()
|
||||
if not checkpoint_scanner:
|
||||
logger.warning("Checkpoint scanner not available for usage tracking")
|
||||
return
|
||||
|
||||
for node_id, model_info in models_data.items():
|
||||
if not isinstance(model_info, dict):
|
||||
continue
|
||||
|
||||
# Check if this is a checkpoint model
|
||||
model_type = model_info.get("type")
|
||||
if model_type == "checkpoint":
|
||||
model_name = model_info.get("name")
|
||||
if not model_name:
|
||||
continue
|
||||
|
||||
# Clean up filename (remove extension if present)
|
||||
model_filename = os.path.splitext(os.path.basename(model_name))[0]
|
||||
|
||||
# Get hash for this checkpoint
|
||||
model_hash = checkpoint_scanner.get_hash_by_filename(model_filename)
|
||||
if model_hash:
|
||||
# Update stats for this checkpoint with date tracking
|
||||
if model_hash not in self.stats["checkpoints"]:
|
||||
self.stats["checkpoints"][model_hash] = {
|
||||
"total": 0,
|
||||
"history": {}
|
||||
}
|
||||
|
||||
# Increment total count
|
||||
self.stats["checkpoints"][model_hash]["total"] += 1
|
||||
|
||||
# Increment today's count
|
||||
if today_date not in self.stats["checkpoints"][model_hash]["history"]:
|
||||
self.stats["checkpoints"][model_hash]["history"][today_date] = 0
|
||||
self.stats["checkpoints"][model_hash]["history"][today_date] += 1
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing checkpoint usage: {e}", exc_info=True)
|
||||
|
||||
async def _process_loras(self, loras_data, today_date):
|
||||
"""Process LoRA models from metadata"""
|
||||
try:
|
||||
# Get LoRA scanner service
|
||||
lora_scanner = await ServiceRegistry.get_lora_scanner()
|
||||
if not lora_scanner:
|
||||
logger.warning("LoRA scanner not available for usage tracking")
|
||||
return
|
||||
|
||||
for node_id, lora_info in loras_data.items():
|
||||
if not isinstance(lora_info, dict):
|
||||
continue
|
||||
|
||||
# Get the list of LoRAs from standardized format
|
||||
lora_list = lora_info.get("lora_list", [])
|
||||
for lora in lora_list:
|
||||
if not isinstance(lora, dict):
|
||||
continue
|
||||
|
||||
lora_name = lora.get("name")
|
||||
if not lora_name:
|
||||
continue
|
||||
|
||||
# Get hash for this LoRA
|
||||
lora_hash = lora_scanner.get_hash_by_filename(lora_name)
|
||||
if lora_hash:
|
||||
# Update stats for this LoRA with date tracking
|
||||
if lora_hash not in self.stats["loras"]:
|
||||
self.stats["loras"][lora_hash] = {
|
||||
"total": 0,
|
||||
"history": {}
|
||||
}
|
||||
|
||||
# Increment total count
|
||||
self.stats["loras"][lora_hash]["total"] += 1
|
||||
|
||||
# Increment today's count
|
||||
if today_date not in self.stats["loras"][lora_hash]["history"]:
|
||||
self.stats["loras"][lora_hash]["history"][today_date] = 0
|
||||
self.stats["loras"][lora_hash]["history"][today_date] += 1
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing LoRA usage: {e}", exc_info=True)
|
||||
|
||||
async def get_stats(self):
|
||||
"""Get current usage statistics"""
|
||||
return self.stats
|
||||
|
||||
async def get_model_usage_count(self, model_type, sha256):
|
||||
"""Get usage count for a specific model by hash"""
|
||||
if model_type == "checkpoint":
|
||||
if sha256 in self.stats["checkpoints"]:
|
||||
return self.stats["checkpoints"][sha256]["total"]
|
||||
elif model_type == "lora":
|
||||
if sha256 in self.stats["loras"]:
|
||||
return self.stats["loras"][sha256]["total"]
|
||||
return 0
|
||||
|
||||
async def process_execution(self, prompt_id):
|
||||
"""Process a prompt execution immediately (synchronous approach)"""
|
||||
if not prompt_id:
|
||||
return
|
||||
|
||||
try:
|
||||
# Process metadata for this prompt_id
|
||||
registry = MetadataRegistry()
|
||||
metadata = registry.get_metadata(prompt_id)
|
||||
if metadata:
|
||||
await self._process_metadata(metadata)
|
||||
# Save stats if needed
|
||||
await self.save_stats()
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing prompt_id {prompt_id}: {e}", exc_info=True)
|
||||
@@ -114,3 +114,49 @@ def fuzzy_match(text: str, pattern: str, threshold: float = 0.7) -> bool:
|
||||
|
||||
# All words found either as substrings or fuzzy matches
|
||||
return True
|
||||
|
||||
def calculate_recipe_fingerprint(loras):
|
||||
"""
|
||||
Calculate a unique fingerprint for a recipe based on its LoRAs.
|
||||
|
||||
The fingerprint is created by sorting LoRA hashes, filtering invalid entries,
|
||||
normalizing strength values to 2 decimal places, and joining in format:
|
||||
hash1:strength1|hash2:strength2|...
|
||||
|
||||
Args:
|
||||
loras (list): List of LoRA dictionaries with hash and strength values
|
||||
|
||||
Returns:
|
||||
str: The calculated fingerprint
|
||||
"""
|
||||
if not loras:
|
||||
return ""
|
||||
|
||||
# Filter valid entries and extract hash and strength
|
||||
valid_loras = []
|
||||
for lora in loras:
|
||||
# Skip excluded loras
|
||||
if lora.get("exclude", False):
|
||||
continue
|
||||
|
||||
# Get the hash - use modelVersionId as fallback if hash is empty
|
||||
hash_value = lora.get("hash", "").lower()
|
||||
if not hash_value and lora.get("isDeleted", False) and lora.get("modelVersionId"):
|
||||
hash_value = lora.get("modelVersionId")
|
||||
|
||||
# Skip entries without a valid hash
|
||||
if not hash_value:
|
||||
continue
|
||||
|
||||
# Normalize strength to 2 decimal places (check both strength and weight fields)
|
||||
strength = round(float(lora.get("strength", lora.get("weight", 1.0))), 2)
|
||||
|
||||
valid_loras.append((hash_value, strength))
|
||||
|
||||
# Sort by hash
|
||||
valid_loras.sort()
|
||||
|
||||
# Join in format hash1:strength1|hash2:strength2|...
|
||||
fingerprint = "|".join([f"{hash_value}:{strength}" for hash_value, strength in valid_loras])
|
||||
|
||||
return fingerprint
|
||||
|
||||
@@ -1,3 +0,0 @@
|
||||
"""
|
||||
ComfyUI workflow parsing module to extract generation parameters
|
||||
"""
|
||||
@@ -1,58 +0,0 @@
|
||||
"""
|
||||
Command-line interface for the ComfyUI workflow parser
|
||||
"""
|
||||
import argparse
|
||||
import json
|
||||
import os
|
||||
import logging
|
||||
import sys
|
||||
from .parser import parse_workflow
|
||||
|
||||
logging.basicConfig(
|
||||
level=logging.INFO,
|
||||
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
|
||||
handlers=[logging.StreamHandler()]
|
||||
)
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
def main():
|
||||
"""Entry point for the CLI"""
|
||||
parser = argparse.ArgumentParser(description='Parse ComfyUI workflow files')
|
||||
parser.add_argument('input', help='Input workflow JSON file path')
|
||||
parser.add_argument('-o', '--output', help='Output JSON file path')
|
||||
parser.add_argument('-p', '--pretty', action='store_true', help='Pretty print JSON output')
|
||||
parser.add_argument('--debug', action='store_true', help='Enable debug logging')
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
# Set logging level
|
||||
if args.debug:
|
||||
logging.getLogger().setLevel(logging.DEBUG)
|
||||
|
||||
# Validate input file
|
||||
if not os.path.isfile(args.input):
|
||||
logger.error(f"Input file not found: {args.input}")
|
||||
sys.exit(1)
|
||||
|
||||
# Parse workflow
|
||||
try:
|
||||
result = parse_workflow(args.input, args.output)
|
||||
|
||||
# Print result to console if output file not specified
|
||||
if not args.output:
|
||||
if args.pretty:
|
||||
print(json.dumps(result, indent=4))
|
||||
else:
|
||||
print(json.dumps(result))
|
||||
else:
|
||||
logger.info(f"Output saved to: {args.output}")
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error parsing workflow: {e}")
|
||||
if args.debug:
|
||||
import traceback
|
||||
traceback.print_exc()
|
||||
sys.exit(1)
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@@ -1,3 +0,0 @@
|
||||
"""
|
||||
Extension directory for custom node mappers
|
||||
"""
|
||||
@@ -1,285 +0,0 @@
|
||||
"""
|
||||
ComfyUI Core nodes mappers extension for workflow parsing
|
||||
"""
|
||||
import logging
|
||||
from typing import Dict, Any, List
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# =============================================================================
|
||||
# Transform Functions
|
||||
# =============================================================================
|
||||
|
||||
def transform_random_noise(inputs: Dict) -> Dict:
|
||||
"""Transform function for RandomNoise node"""
|
||||
return {"seed": str(inputs.get("noise_seed", ""))}
|
||||
|
||||
def transform_ksampler_select(inputs: Dict) -> Dict:
|
||||
"""Transform function for KSamplerSelect node"""
|
||||
return {"sampler": inputs.get("sampler_name", "")}
|
||||
|
||||
def transform_basic_scheduler(inputs: Dict) -> Dict:
|
||||
"""Transform function for BasicScheduler node"""
|
||||
result = {
|
||||
"scheduler": inputs.get("scheduler", ""),
|
||||
"denoise": str(inputs.get("denoise", "1.0"))
|
||||
}
|
||||
|
||||
# Get steps from inputs or steps input
|
||||
if "steps" in inputs:
|
||||
if isinstance(inputs["steps"], str):
|
||||
result["steps"] = inputs["steps"]
|
||||
elif isinstance(inputs["steps"], dict) and "value" in inputs["steps"]:
|
||||
result["steps"] = str(inputs["steps"]["value"])
|
||||
else:
|
||||
result["steps"] = str(inputs["steps"])
|
||||
|
||||
return result
|
||||
|
||||
def transform_basic_guider(inputs: Dict) -> Dict:
|
||||
"""Transform function for BasicGuider node"""
|
||||
result = {}
|
||||
|
||||
# Process conditioning
|
||||
if "conditioning" in inputs:
|
||||
if isinstance(inputs["conditioning"], str):
|
||||
result["prompt"] = inputs["conditioning"]
|
||||
elif isinstance(inputs["conditioning"], dict):
|
||||
result["conditioning"] = inputs["conditioning"]
|
||||
|
||||
# Get model information if needed
|
||||
if "model" in inputs and isinstance(inputs["model"], dict):
|
||||
result["model"] = inputs["model"]
|
||||
|
||||
return result
|
||||
|
||||
def transform_model_sampling_flux(inputs: Dict) -> Dict:
|
||||
"""Transform function for ModelSamplingFlux - mostly a pass-through node"""
|
||||
# This node is primarily used for routing, so we mostly pass through values
|
||||
|
||||
return inputs["model"]
|
||||
|
||||
def transform_sampler_custom_advanced(inputs: Dict) -> Dict:
|
||||
"""Transform function for SamplerCustomAdvanced node"""
|
||||
result = {}
|
||||
|
||||
# Extract seed from noise
|
||||
if "noise" in inputs and isinstance(inputs["noise"], dict):
|
||||
result["seed"] = str(inputs["noise"].get("seed", ""))
|
||||
|
||||
# Extract sampler info
|
||||
if "sampler" in inputs and isinstance(inputs["sampler"], dict):
|
||||
sampler = inputs["sampler"].get("sampler", "")
|
||||
if sampler:
|
||||
result["sampler"] = sampler
|
||||
|
||||
# Extract scheduler, steps, denoise from sigmas
|
||||
if "sigmas" in inputs and isinstance(inputs["sigmas"], dict):
|
||||
sigmas = inputs["sigmas"]
|
||||
result["scheduler"] = sigmas.get("scheduler", "")
|
||||
result["steps"] = str(sigmas.get("steps", ""))
|
||||
result["denoise"] = str(sigmas.get("denoise", "1.0"))
|
||||
|
||||
# Extract prompt and guidance from guider
|
||||
if "guider" in inputs and isinstance(inputs["guider"], dict):
|
||||
guider = inputs["guider"]
|
||||
|
||||
# Get prompt from conditioning
|
||||
if "conditioning" in guider and isinstance(guider["conditioning"], str):
|
||||
result["prompt"] = guider["conditioning"]
|
||||
elif "conditioning" in guider and isinstance(guider["conditioning"], dict):
|
||||
result["guidance"] = guider["conditioning"].get("guidance", "")
|
||||
result["prompt"] = guider["conditioning"].get("prompt", "")
|
||||
|
||||
if "model" in guider and isinstance(guider["model"], dict):
|
||||
result["checkpoint"] = guider["model"].get("checkpoint", "")
|
||||
result["loras"] = guider["model"].get("loras", "")
|
||||
result["clip_skip"] = str(int(guider["model"].get("clip_skip", "-1")) * -1)
|
||||
|
||||
# Extract dimensions from latent_image
|
||||
if "latent_image" in inputs and isinstance(inputs["latent_image"], dict):
|
||||
latent = inputs["latent_image"]
|
||||
width = latent.get("width", 0)
|
||||
height = latent.get("height", 0)
|
||||
if width and height:
|
||||
result["width"] = width
|
||||
result["height"] = height
|
||||
result["size"] = f"{width}x{height}"
|
||||
|
||||
return result
|
||||
|
||||
def transform_ksampler(inputs: Dict) -> Dict:
|
||||
"""Transform function for KSampler nodes"""
|
||||
result = {
|
||||
"seed": str(inputs.get("seed", "")),
|
||||
"steps": str(inputs.get("steps", "")),
|
||||
"cfg": str(inputs.get("cfg", "")),
|
||||
"sampler": inputs.get("sampler_name", ""),
|
||||
"scheduler": inputs.get("scheduler", ""),
|
||||
}
|
||||
|
||||
# Process positive prompt
|
||||
if "positive" in inputs:
|
||||
result["prompt"] = inputs["positive"]
|
||||
|
||||
# Process negative prompt
|
||||
if "negative" in inputs:
|
||||
result["negative_prompt"] = inputs["negative"]
|
||||
|
||||
# Get dimensions from latent image
|
||||
if "latent_image" in inputs and isinstance(inputs["latent_image"], dict):
|
||||
width = inputs["latent_image"].get("width", 0)
|
||||
height = inputs["latent_image"].get("height", 0)
|
||||
if width and height:
|
||||
result["size"] = f"{width}x{height}"
|
||||
|
||||
# Add clip_skip if present
|
||||
if "clip_skip" in inputs:
|
||||
result["clip_skip"] = str(inputs.get("clip_skip", ""))
|
||||
|
||||
# Add guidance if present
|
||||
if "guidance" in inputs:
|
||||
result["guidance"] = str(inputs.get("guidance", ""))
|
||||
|
||||
# Add model if present
|
||||
if "model" in inputs:
|
||||
result["checkpoint"] = inputs.get("model", {}).get("checkpoint", "")
|
||||
result["loras"] = inputs.get("model", {}).get("loras", "")
|
||||
result["clip_skip"] = str(inputs.get("model", {}).get("clip_skip", -1) * -1)
|
||||
|
||||
return result
|
||||
|
||||
def transform_empty_latent(inputs: Dict) -> Dict:
|
||||
"""Transform function for EmptyLatentImage nodes"""
|
||||
width = inputs.get("width", 0)
|
||||
height = inputs.get("height", 0)
|
||||
return {"width": width, "height": height, "size": f"{width}x{height}"}
|
||||
|
||||
def transform_clip_text(inputs: Dict) -> Any:
|
||||
"""Transform function for CLIPTextEncode nodes"""
|
||||
return inputs.get("text", "")
|
||||
|
||||
def transform_flux_guidance(inputs: Dict) -> Dict:
|
||||
"""Transform function for FluxGuidance nodes"""
|
||||
result = {}
|
||||
|
||||
if "guidance" in inputs:
|
||||
result["guidance"] = inputs["guidance"]
|
||||
|
||||
if "conditioning" in inputs:
|
||||
conditioning = inputs["conditioning"]
|
||||
if isinstance(conditioning, str):
|
||||
result["prompt"] = conditioning
|
||||
else:
|
||||
result["prompt"] = "Unknown prompt"
|
||||
|
||||
return result
|
||||
|
||||
def transform_unet_loader(inputs: Dict) -> Dict:
|
||||
"""Transform function for UNETLoader node"""
|
||||
unet_name = inputs.get("unet_name", "")
|
||||
return {"checkpoint": unet_name} if unet_name else {}
|
||||
|
||||
def transform_checkpoint_loader(inputs: Dict) -> Dict:
|
||||
"""Transform function for CheckpointLoaderSimple node"""
|
||||
ckpt_name = inputs.get("ckpt_name", "")
|
||||
return {"checkpoint": ckpt_name} if ckpt_name else {}
|
||||
|
||||
def transform_latent_upscale_by(inputs: Dict) -> Dict:
|
||||
"""Transform function for LatentUpscaleBy node"""
|
||||
result = {}
|
||||
|
||||
width = inputs["samples"].get("width", 0) * inputs["scale_by"]
|
||||
height = inputs["samples"].get("height", 0) * inputs["scale_by"]
|
||||
result["width"] = width
|
||||
result["height"] = height
|
||||
result["size"] = f"{width}x{height}"
|
||||
|
||||
return result
|
||||
|
||||
def transform_clip_set_last_layer(inputs: Dict) -> Dict:
|
||||
"""Transform function for CLIPSetLastLayer node"""
|
||||
result = {}
|
||||
|
||||
if "stop_at_clip_layer" in inputs:
|
||||
result["clip_skip"] = inputs["stop_at_clip_layer"]
|
||||
|
||||
return result
|
||||
|
||||
# =============================================================================
|
||||
# Node Mapper Definitions
|
||||
# =============================================================================
|
||||
|
||||
# Define the mappers for ComfyUI core nodes not in main mapper
|
||||
NODE_MAPPERS_EXT = {
|
||||
# KSamplers
|
||||
"SamplerCustomAdvanced": {
|
||||
"inputs_to_track": ["noise", "guider", "sampler", "sigmas", "latent_image"],
|
||||
"transform_func": transform_sampler_custom_advanced
|
||||
},
|
||||
"KSampler": {
|
||||
"inputs_to_track": [
|
||||
"seed", "steps", "cfg", "sampler_name", "scheduler",
|
||||
"denoise", "positive", "negative", "latent_image",
|
||||
"model", "clip_skip"
|
||||
],
|
||||
"transform_func": transform_ksampler
|
||||
},
|
||||
# ComfyUI core nodes
|
||||
"EmptyLatentImage": {
|
||||
"inputs_to_track": ["width", "height", "batch_size"],
|
||||
"transform_func": transform_empty_latent
|
||||
},
|
||||
"EmptySD3LatentImage": {
|
||||
"inputs_to_track": ["width", "height", "batch_size"],
|
||||
"transform_func": transform_empty_latent
|
||||
},
|
||||
"CLIPTextEncode": {
|
||||
"inputs_to_track": ["text", "clip"],
|
||||
"transform_func": transform_clip_text
|
||||
},
|
||||
"FluxGuidance": {
|
||||
"inputs_to_track": ["guidance", "conditioning"],
|
||||
"transform_func": transform_flux_guidance
|
||||
},
|
||||
"RandomNoise": {
|
||||
"inputs_to_track": ["noise_seed"],
|
||||
"transform_func": transform_random_noise
|
||||
},
|
||||
"KSamplerSelect": {
|
||||
"inputs_to_track": ["sampler_name"],
|
||||
"transform_func": transform_ksampler_select
|
||||
},
|
||||
"BasicScheduler": {
|
||||
"inputs_to_track": ["scheduler", "steps", "denoise", "model"],
|
||||
"transform_func": transform_basic_scheduler
|
||||
},
|
||||
"BasicGuider": {
|
||||
"inputs_to_track": ["model", "conditioning"],
|
||||
"transform_func": transform_basic_guider
|
||||
},
|
||||
"ModelSamplingFlux": {
|
||||
"inputs_to_track": ["max_shift", "base_shift", "width", "height", "model"],
|
||||
"transform_func": transform_model_sampling_flux
|
||||
},
|
||||
"UNETLoader": {
|
||||
"inputs_to_track": ["unet_name"],
|
||||
"transform_func": transform_unet_loader
|
||||
},
|
||||
"CheckpointLoaderSimple": {
|
||||
"inputs_to_track": ["ckpt_name"],
|
||||
"transform_func": transform_checkpoint_loader
|
||||
},
|
||||
"LatentUpscale": {
|
||||
"inputs_to_track": ["width", "height"],
|
||||
"transform_func": transform_empty_latent
|
||||
},
|
||||
"LatentUpscaleBy": {
|
||||
"inputs_to_track": ["samples", "scale_by"],
|
||||
"transform_func": transform_latent_upscale_by
|
||||
},
|
||||
"CLIPSetLastLayer": {
|
||||
"inputs_to_track": ["clip", "stop_at_clip_layer"],
|
||||
"transform_func": transform_clip_set_last_layer
|
||||
}
|
||||
}
|
||||
@@ -1,74 +0,0 @@
|
||||
"""
|
||||
KJNodes mappers extension for ComfyUI workflow parsing
|
||||
"""
|
||||
import logging
|
||||
import re
|
||||
from typing import Dict, Any
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# =============================================================================
|
||||
# Transform Functions
|
||||
# =============================================================================
|
||||
|
||||
def transform_join_strings(inputs: Dict) -> str:
|
||||
"""Transform function for JoinStrings nodes"""
|
||||
string1 = inputs.get("string1", "")
|
||||
string2 = inputs.get("string2", "")
|
||||
delimiter = inputs.get("delimiter", "")
|
||||
return f"{string1}{delimiter}{string2}"
|
||||
|
||||
def transform_string_constant(inputs: Dict) -> str:
|
||||
"""Transform function for StringConstant nodes"""
|
||||
return inputs.get("string", "")
|
||||
|
||||
def transform_empty_latent_presets(inputs: Dict) -> Dict:
|
||||
"""Transform function for EmptyLatentImagePresets nodes"""
|
||||
dimensions = inputs.get("dimensions", "")
|
||||
invert = inputs.get("invert", False)
|
||||
|
||||
# Extract width and height from dimensions string
|
||||
# Expected format: "width x height (ratio)" or similar
|
||||
width = 0
|
||||
height = 0
|
||||
|
||||
if dimensions:
|
||||
# Try to extract dimensions using regex
|
||||
match = re.search(r'(\d+)\s*x\s*(\d+)', dimensions)
|
||||
if match:
|
||||
width = int(match.group(1))
|
||||
height = int(match.group(2))
|
||||
|
||||
# If invert is True, swap width and height
|
||||
if invert and width and height:
|
||||
width, height = height, width
|
||||
|
||||
return {"width": width, "height": height, "size": f"{width}x{height}"}
|
||||
|
||||
def transform_int_constant(inputs: Dict) -> int:
|
||||
"""Transform function for INTConstant nodes"""
|
||||
return inputs.get("value", 0)
|
||||
|
||||
# =============================================================================
|
||||
# Node Mapper Definitions
|
||||
# =============================================================================
|
||||
|
||||
# Define the mappers for KJNodes
|
||||
NODE_MAPPERS_EXT = {
|
||||
"JoinStrings": {
|
||||
"inputs_to_track": ["string1", "string2", "delimiter"],
|
||||
"transform_func": transform_join_strings
|
||||
},
|
||||
"StringConstantMultiline": {
|
||||
"inputs_to_track": ["string"],
|
||||
"transform_func": transform_string_constant
|
||||
},
|
||||
"EmptyLatentImagePresets": {
|
||||
"inputs_to_track": ["dimensions", "invert", "batch_size"],
|
||||
"transform_func": transform_empty_latent_presets
|
||||
},
|
||||
"INTConstant": {
|
||||
"inputs_to_track": ["value"],
|
||||
"transform_func": transform_int_constant
|
||||
}
|
||||
}
|
||||
@@ -1,37 +0,0 @@
|
||||
"""
|
||||
Main entry point for the workflow parser module
|
||||
"""
|
||||
import os
|
||||
import sys
|
||||
import logging
|
||||
from typing import Dict, Optional, Union
|
||||
|
||||
# Add the parent directory to sys.path to enable imports
|
||||
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
|
||||
ROOT_DIR = os.path.abspath(os.path.join(SCRIPT_DIR, '..', '..'))
|
||||
sys.path.insert(0, os.path.dirname(SCRIPT_DIR))
|
||||
|
||||
from .parser import parse_workflow
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
def parse_comfyui_workflow(
|
||||
workflow_path: str,
|
||||
output_path: Optional[str] = None
|
||||
) -> Dict:
|
||||
"""
|
||||
Parse a ComfyUI workflow file and extract generation parameters
|
||||
|
||||
Args:
|
||||
workflow_path: Path to the workflow JSON file
|
||||
output_path: Optional path to save the output JSON
|
||||
|
||||
Returns:
|
||||
Dictionary containing extracted parameters
|
||||
"""
|
||||
return parse_workflow(workflow_path, output_path)
|
||||
|
||||
if __name__ == "__main__":
|
||||
# If run directly, use the CLI
|
||||
from .cli import main
|
||||
main()
|
||||
@@ -1,282 +0,0 @@
|
||||
"""
|
||||
Node mappers for ComfyUI workflow parsing
|
||||
"""
|
||||
import logging
|
||||
import os
|
||||
import importlib.util
|
||||
import inspect
|
||||
from typing import Dict, List, Any, Optional, Union, Type, Callable, Tuple
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# Global mapper registry
|
||||
_MAPPER_REGISTRY: Dict[str, Dict] = {}
|
||||
|
||||
# =============================================================================
|
||||
# Mapper Definition Functions
|
||||
# =============================================================================
|
||||
|
||||
def create_mapper(
|
||||
node_type: str,
|
||||
inputs_to_track: List[str],
|
||||
transform_func: Callable[[Dict], Any] = None
|
||||
) -> Dict:
|
||||
"""Create a mapper definition for a node type"""
|
||||
mapper = {
|
||||
"node_type": node_type,
|
||||
"inputs_to_track": inputs_to_track,
|
||||
"transform": transform_func or (lambda inputs: inputs)
|
||||
}
|
||||
return mapper
|
||||
|
||||
def register_mapper(mapper: Dict) -> None:
|
||||
"""Register a node mapper in the global registry"""
|
||||
_MAPPER_REGISTRY[mapper["node_type"]] = mapper
|
||||
logger.debug(f"Registered mapper for node type: {mapper['node_type']}")
|
||||
|
||||
def get_mapper(node_type: str) -> Optional[Dict]:
|
||||
"""Get a mapper for the specified node type"""
|
||||
return _MAPPER_REGISTRY.get(node_type)
|
||||
|
||||
def get_all_mappers() -> Dict[str, Dict]:
|
||||
"""Get all registered mappers"""
|
||||
return _MAPPER_REGISTRY.copy()
|
||||
|
||||
# =============================================================================
|
||||
# Node Processing Function
|
||||
# =============================================================================
|
||||
|
||||
def process_node(node_id: str, node_data: Dict, workflow: Dict, parser: 'WorkflowParser') -> Any: # type: ignore
|
||||
"""Process a node using its mapper and extract relevant information"""
|
||||
node_type = node_data.get("class_type")
|
||||
mapper = get_mapper(node_type)
|
||||
|
||||
if not mapper:
|
||||
logger.warning(f"No mapper found for node type: {node_type}")
|
||||
return None
|
||||
|
||||
result = {}
|
||||
|
||||
# Extract inputs based on the mapper's tracked inputs
|
||||
for input_name in mapper["inputs_to_track"]:
|
||||
if input_name in node_data.get("inputs", {}):
|
||||
input_value = node_data["inputs"][input_name]
|
||||
|
||||
# Check if input is a reference to another node's output
|
||||
if isinstance(input_value, list) and len(input_value) == 2:
|
||||
try:
|
||||
# Format is [node_id, output_slot]
|
||||
ref_node_id, output_slot = input_value
|
||||
# Convert node_id to string if it's an integer
|
||||
if isinstance(ref_node_id, int):
|
||||
ref_node_id = str(ref_node_id)
|
||||
|
||||
# Recursively process the referenced node
|
||||
ref_value = parser.process_node(ref_node_id, workflow)
|
||||
|
||||
if ref_value is not None:
|
||||
result[input_name] = ref_value
|
||||
else:
|
||||
# If we couldn't get a value from the reference, store the raw value
|
||||
result[input_name] = input_value
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing reference in node {node_id}, input {input_name}: {e}")
|
||||
result[input_name] = input_value
|
||||
else:
|
||||
# Direct value
|
||||
result[input_name] = input_value
|
||||
|
||||
# Apply the transform function
|
||||
try:
|
||||
return mapper["transform"](result)
|
||||
except Exception as e:
|
||||
logger.error(f"Error in transform function for node {node_id} of type {node_type}: {e}")
|
||||
return result
|
||||
|
||||
# =============================================================================
|
||||
# Transform Functions
|
||||
# =============================================================================
|
||||
|
||||
|
||||
|
||||
def transform_lora_loader(inputs: Dict) -> Dict:
|
||||
"""Transform function for LoraLoader nodes"""
|
||||
loras_data = inputs.get("loras", [])
|
||||
lora_stack = inputs.get("lora_stack", {}).get("lora_stack", [])
|
||||
|
||||
lora_texts = []
|
||||
|
||||
# Process loras array
|
||||
if isinstance(loras_data, dict) and "__value__" in loras_data:
|
||||
loras_list = loras_data["__value__"]
|
||||
elif isinstance(loras_data, list):
|
||||
loras_list = loras_data
|
||||
else:
|
||||
loras_list = []
|
||||
|
||||
# Process each active lora entry
|
||||
for lora in loras_list:
|
||||
if isinstance(lora, dict) and lora.get("active", False):
|
||||
lora_name = lora.get("name", "")
|
||||
strength = lora.get("strength", 1.0)
|
||||
lora_texts.append(f"<lora:{lora_name}:{strength}>")
|
||||
|
||||
# Process lora_stack if valid
|
||||
if lora_stack and isinstance(lora_stack, list):
|
||||
if not (len(lora_stack) == 2 and isinstance(lora_stack[0], (str, int)) and isinstance(lora_stack[1], int)):
|
||||
for stack_entry in lora_stack:
|
||||
lora_name = stack_entry[0]
|
||||
strength = stack_entry[1]
|
||||
lora_texts.append(f"<lora:{lora_name}:{strength}>")
|
||||
|
||||
result = {
|
||||
"checkpoint": inputs.get("model", {}).get("checkpoint", ""),
|
||||
"loras": " ".join(lora_texts)
|
||||
}
|
||||
|
||||
if "clip" in inputs and isinstance(inputs["clip"], dict):
|
||||
result["clip_skip"] = inputs["clip"].get("clip_skip", "-1")
|
||||
|
||||
return result
|
||||
|
||||
def transform_lora_stacker(inputs: Dict) -> Dict:
|
||||
"""Transform function for LoraStacker nodes"""
|
||||
loras_data = inputs.get("loras", [])
|
||||
result_stack = []
|
||||
|
||||
# Handle existing stack entries
|
||||
existing_stack = []
|
||||
lora_stack_input = inputs.get("lora_stack", [])
|
||||
|
||||
if isinstance(lora_stack_input, dict) and "lora_stack" in lora_stack_input:
|
||||
existing_stack = lora_stack_input["lora_stack"]
|
||||
elif isinstance(lora_stack_input, list):
|
||||
if not (len(lora_stack_input) == 2 and isinstance(lora_stack_input[0], (str, int)) and
|
||||
isinstance(lora_stack_input[1], int)):
|
||||
existing_stack = lora_stack_input
|
||||
|
||||
# Add existing entries
|
||||
if existing_stack:
|
||||
result_stack.extend(existing_stack)
|
||||
|
||||
# Process new loras
|
||||
if isinstance(loras_data, dict) and "__value__" in loras_data:
|
||||
loras_list = loras_data["__value__"]
|
||||
elif isinstance(loras_data, list):
|
||||
loras_list = loras_data
|
||||
else:
|
||||
loras_list = []
|
||||
|
||||
for lora in loras_list:
|
||||
if isinstance(lora, dict) and lora.get("active", False):
|
||||
lora_name = lora.get("name", "")
|
||||
strength = float(lora.get("strength", 1.0))
|
||||
result_stack.append((lora_name, strength))
|
||||
|
||||
return {"lora_stack": result_stack}
|
||||
|
||||
def transform_trigger_word_toggle(inputs: Dict) -> str:
|
||||
"""Transform function for TriggerWordToggle nodes"""
|
||||
toggle_data = inputs.get("toggle_trigger_words", [])
|
||||
|
||||
if isinstance(toggle_data, dict) and "__value__" in toggle_data:
|
||||
toggle_words = toggle_data["__value__"]
|
||||
elif isinstance(toggle_data, list):
|
||||
toggle_words = toggle_data
|
||||
else:
|
||||
toggle_words = []
|
||||
|
||||
# Filter active trigger words
|
||||
active_words = []
|
||||
for item in toggle_words:
|
||||
if isinstance(item, dict) and item.get("active", False):
|
||||
word = item.get("text", "")
|
||||
if word and not word.startswith("__dummy"):
|
||||
active_words.append(word)
|
||||
|
||||
return ", ".join(active_words)
|
||||
|
||||
# =============================================================================
|
||||
# Node Mapper Definitions
|
||||
# =============================================================================
|
||||
|
||||
# Central definition of all supported node types and their configurations
|
||||
NODE_MAPPERS = {
|
||||
|
||||
# LoraManager nodes
|
||||
"Lora Loader (LoraManager)": {
|
||||
"inputs_to_track": ["model", "clip", "loras", "lora_stack"],
|
||||
"transform_func": transform_lora_loader
|
||||
},
|
||||
"Lora Stacker (LoraManager)": {
|
||||
"inputs_to_track": ["loras", "lora_stack"],
|
||||
"transform_func": transform_lora_stacker
|
||||
},
|
||||
"TriggerWord Toggle (LoraManager)": {
|
||||
"inputs_to_track": ["toggle_trigger_words"],
|
||||
"transform_func": transform_trigger_word_toggle
|
||||
}
|
||||
}
|
||||
|
||||
def register_all_mappers() -> None:
|
||||
"""Register all mappers from the NODE_MAPPERS dictionary"""
|
||||
for node_type, config in NODE_MAPPERS.items():
|
||||
mapper = create_mapper(
|
||||
node_type=node_type,
|
||||
inputs_to_track=config["inputs_to_track"],
|
||||
transform_func=config["transform_func"]
|
||||
)
|
||||
register_mapper(mapper)
|
||||
logger.info(f"Registered {len(NODE_MAPPERS)} node mappers")
|
||||
|
||||
# =============================================================================
|
||||
# Extension Loading
|
||||
# =============================================================================
|
||||
|
||||
def load_extensions(ext_dir: str = None) -> None:
|
||||
"""
|
||||
Load mapper extensions from the specified directory
|
||||
|
||||
Extension files should define a NODE_MAPPERS_EXT dictionary containing mapper configurations.
|
||||
These will be added to the global NODE_MAPPERS dictionary and registered automatically.
|
||||
"""
|
||||
# Use default path if none provided
|
||||
if ext_dir is None:
|
||||
# Get the directory of this file
|
||||
current_dir = os.path.dirname(os.path.abspath(__file__))
|
||||
ext_dir = os.path.join(current_dir, 'ext')
|
||||
|
||||
# Ensure the extension directory exists
|
||||
if not os.path.exists(ext_dir):
|
||||
os.makedirs(ext_dir, exist_ok=True)
|
||||
logger.info(f"Created extension directory: {ext_dir}")
|
||||
return
|
||||
|
||||
# Load each Python file in the extension directory
|
||||
for filename in os.listdir(ext_dir):
|
||||
if filename.endswith('.py') and not filename.startswith('_'):
|
||||
module_path = os.path.join(ext_dir, filename)
|
||||
module_name = f"workflow.ext.{filename[:-3]}" # Remove .py
|
||||
|
||||
try:
|
||||
# Load the module
|
||||
spec = importlib.util.spec_from_file_location(module_name, module_path)
|
||||
if spec and spec.loader:
|
||||
module = importlib.util.module_from_spec(spec)
|
||||
spec.loader.exec_module(module)
|
||||
|
||||
# Check if the module defines NODE_MAPPERS_EXT
|
||||
if hasattr(module, 'NODE_MAPPERS_EXT'):
|
||||
# Add the extension mappers to the global NODE_MAPPERS dictionary
|
||||
NODE_MAPPERS.update(module.NODE_MAPPERS_EXT)
|
||||
logger.info(f"Added {len(module.NODE_MAPPERS_EXT)} mappers from extension: {filename}")
|
||||
else:
|
||||
logger.warning(f"Extension {filename} does not define NODE_MAPPERS_EXT dictionary")
|
||||
except Exception as e:
|
||||
logger.warning(f"Error loading extension {filename}: {e}")
|
||||
|
||||
# Re-register all mappers after loading extensions
|
||||
register_all_mappers()
|
||||
|
||||
# Initialize the registry with default mappers
|
||||
# register_default_mappers()
|
||||
@@ -1,181 +0,0 @@
|
||||
"""
|
||||
Main workflow parser implementation for ComfyUI
|
||||
"""
|
||||
import json
|
||||
import logging
|
||||
from typing import Dict, List, Any, Optional, Union, Set
|
||||
from .mappers import get_mapper, get_all_mappers, load_extensions, process_node
|
||||
from .utils import (
|
||||
load_workflow, save_output, find_node_by_type,
|
||||
trace_model_path
|
||||
)
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class WorkflowParser:
|
||||
"""Parser for ComfyUI workflows"""
|
||||
|
||||
def __init__(self):
|
||||
"""Initialize the parser with mappers"""
|
||||
self.processed_nodes: Set[str] = set() # Track processed nodes to avoid cycles
|
||||
self.node_results_cache: Dict[str, Any] = {} # Cache for processed node results
|
||||
|
||||
# Load extensions
|
||||
load_extensions()
|
||||
|
||||
def process_node(self, node_id: str, workflow: Dict) -> Any:
|
||||
"""Process a single node and extract relevant information"""
|
||||
# Return cached result if available
|
||||
if node_id in self.node_results_cache:
|
||||
return self.node_results_cache[node_id]
|
||||
|
||||
# Check if we're in a cycle
|
||||
if node_id in self.processed_nodes:
|
||||
return None
|
||||
|
||||
# Mark this node as being processed (to detect cycles)
|
||||
self.processed_nodes.add(node_id)
|
||||
|
||||
if node_id not in workflow:
|
||||
self.processed_nodes.remove(node_id)
|
||||
return None
|
||||
|
||||
node_data = workflow[node_id]
|
||||
node_type = node_data.get("class_type")
|
||||
|
||||
result = None
|
||||
if get_mapper(node_type):
|
||||
try:
|
||||
result = process_node(node_id, node_data, workflow, self)
|
||||
# Cache the result
|
||||
self.node_results_cache[node_id] = result
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing node {node_id} of type {node_type}: {e}", exc_info=True)
|
||||
# Return a partial result or None depending on how we want to handle errors
|
||||
result = {}
|
||||
|
||||
# Remove node from processed set to allow it to be processed again in a different context
|
||||
self.processed_nodes.remove(node_id)
|
||||
return result
|
||||
|
||||
def find_primary_sampler_node(self, workflow: Dict) -> Optional[str]:
|
||||
"""
|
||||
Find the primary sampler node in the workflow.
|
||||
|
||||
Priority:
|
||||
1. First try to find a SamplerCustomAdvanced node
|
||||
2. If not found, look for KSampler nodes with denoise=1.0
|
||||
3. If still not found, use the first KSampler node
|
||||
|
||||
Args:
|
||||
workflow: The workflow data as a dictionary
|
||||
|
||||
Returns:
|
||||
The node ID of the primary sampler node, or None if not found
|
||||
"""
|
||||
# First check for SamplerCustomAdvanced nodes
|
||||
sampler_advanced_nodes = []
|
||||
ksampler_nodes = []
|
||||
|
||||
# Scan workflow for sampler nodes
|
||||
for node_id, node_data in workflow.items():
|
||||
node_type = node_data.get("class_type")
|
||||
|
||||
if node_type == "SamplerCustomAdvanced":
|
||||
sampler_advanced_nodes.append(node_id)
|
||||
elif node_type == "KSampler":
|
||||
ksampler_nodes.append(node_id)
|
||||
|
||||
# If we found SamplerCustomAdvanced nodes, return the first one
|
||||
if sampler_advanced_nodes:
|
||||
logger.debug(f"Found SamplerCustomAdvanced node: {sampler_advanced_nodes[0]}")
|
||||
return sampler_advanced_nodes[0]
|
||||
|
||||
# If we have KSampler nodes, look for one with denoise=1.0
|
||||
if ksampler_nodes:
|
||||
for node_id in ksampler_nodes:
|
||||
node_data = workflow[node_id]
|
||||
inputs = node_data.get("inputs", {})
|
||||
denoise = inputs.get("denoise", 0)
|
||||
|
||||
# Check if denoise is 1.0 (allowing for small floating point differences)
|
||||
if abs(float(denoise) - 1.0) < 0.001:
|
||||
logger.debug(f"Found KSampler node with denoise=1.0: {node_id}")
|
||||
return node_id
|
||||
|
||||
# If no KSampler with denoise=1.0 found, use the first one
|
||||
logger.debug(f"No KSampler with denoise=1.0 found, using first KSampler: {ksampler_nodes[0]}")
|
||||
return ksampler_nodes[0]
|
||||
|
||||
# No sampler nodes found
|
||||
logger.warning("No sampler nodes found in workflow")
|
||||
return None
|
||||
|
||||
def parse_workflow(self, workflow_data: Union[str, Dict], output_path: Optional[str] = None) -> Dict:
|
||||
"""
|
||||
Parse the workflow and extract generation parameters
|
||||
|
||||
Args:
|
||||
workflow_data: The workflow data as a dictionary or a file path
|
||||
output_path: Optional path to save the output JSON
|
||||
|
||||
Returns:
|
||||
Dictionary containing extracted parameters
|
||||
"""
|
||||
# Load workflow from file if needed
|
||||
if isinstance(workflow_data, str):
|
||||
workflow = load_workflow(workflow_data)
|
||||
else:
|
||||
workflow = workflow_data
|
||||
|
||||
# Reset the processed nodes tracker and cache
|
||||
self.processed_nodes = set()
|
||||
self.node_results_cache = {}
|
||||
|
||||
# Find the primary sampler node
|
||||
sampler_node_id = self.find_primary_sampler_node(workflow)
|
||||
if not sampler_node_id:
|
||||
logger.warning("No suitable sampler node found in workflow")
|
||||
return {}
|
||||
|
||||
# Process sampler node to extract parameters
|
||||
sampler_result = self.process_node(sampler_node_id, workflow)
|
||||
if not sampler_result:
|
||||
return {}
|
||||
|
||||
# Return the sampler result directly - it's already in the format we need
|
||||
# This simplifies the structure and makes it easier to use in recipe_routes.py
|
||||
|
||||
# Handle standard ComfyUI names vs our output format
|
||||
if "cfg" in sampler_result:
|
||||
sampler_result["cfg_scale"] = sampler_result.pop("cfg")
|
||||
|
||||
# Add clip_skip = 1 to match reference output if not already present
|
||||
if "clip_skip" not in sampler_result:
|
||||
sampler_result["clip_skip"] = "1"
|
||||
|
||||
# Ensure the prompt is a string and not a nested dictionary
|
||||
if "prompt" in sampler_result and isinstance(sampler_result["prompt"], dict):
|
||||
if "prompt" in sampler_result["prompt"]:
|
||||
sampler_result["prompt"] = sampler_result["prompt"]["prompt"]
|
||||
|
||||
# Save the result if requested
|
||||
if output_path:
|
||||
save_output(sampler_result, output_path)
|
||||
|
||||
return sampler_result
|
||||
|
||||
|
||||
def parse_workflow(workflow_path: str, output_path: Optional[str] = None) -> Dict:
|
||||
"""
|
||||
Parse a ComfyUI workflow file and extract generation parameters
|
||||
|
||||
Args:
|
||||
workflow_path: Path to the workflow JSON file
|
||||
output_path: Optional path to save the output JSON
|
||||
|
||||
Returns:
|
||||
Dictionary containing extracted parameters
|
||||
"""
|
||||
parser = WorkflowParser()
|
||||
return parser.parse_workflow(workflow_path, output_path)
|
||||
@@ -1,63 +0,0 @@
|
||||
"""
|
||||
Test script for the ComfyUI workflow parser
|
||||
"""
|
||||
import os
|
||||
import json
|
||||
import logging
|
||||
from .parser import parse_workflow
|
||||
|
||||
logging.basicConfig(
|
||||
level=logging.INFO,
|
||||
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
|
||||
handlers=[logging.StreamHandler()]
|
||||
)
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# Configure paths
|
||||
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
|
||||
ROOT_DIR = os.path.abspath(os.path.join(SCRIPT_DIR, '..', '..'))
|
||||
REFS_DIR = os.path.join(ROOT_DIR, 'refs')
|
||||
OUTPUT_DIR = os.path.join(ROOT_DIR, 'output')
|
||||
|
||||
def test_parse_flux_workflow():
|
||||
"""Test parsing the flux example workflow"""
|
||||
# Ensure output directory exists
|
||||
os.makedirs(OUTPUT_DIR, exist_ok=True)
|
||||
|
||||
# Define input and output paths
|
||||
input_path = os.path.join(REFS_DIR, 'flux_prompt.json')
|
||||
output_path = os.path.join(OUTPUT_DIR, 'parsed_flux_output.json')
|
||||
|
||||
# Parse workflow
|
||||
logger.info(f"Parsing workflow: {input_path}")
|
||||
result = parse_workflow(input_path, output_path)
|
||||
|
||||
# Print result summary
|
||||
logger.info(f"Output saved to: {output_path}")
|
||||
logger.info(f"Parsing completed. Result summary:")
|
||||
logger.info(f" LoRAs: {result.get('loras', '')}")
|
||||
|
||||
gen_params = result.get('gen_params', {})
|
||||
logger.info(f" Prompt: {gen_params.get('prompt', '')[:50]}...")
|
||||
logger.info(f" Steps: {gen_params.get('steps', '')}")
|
||||
logger.info(f" Sampler: {gen_params.get('sampler', '')}")
|
||||
logger.info(f" Size: {gen_params.get('size', '')}")
|
||||
|
||||
# Compare with reference output
|
||||
ref_output_path = os.path.join(REFS_DIR, 'flux_output.json')
|
||||
try:
|
||||
with open(ref_output_path, 'r') as f:
|
||||
ref_output = json.load(f)
|
||||
|
||||
# Simple validation
|
||||
loras_match = result.get('loras', '') == ref_output.get('loras', '')
|
||||
prompt_match = gen_params.get('prompt', '') == ref_output.get('gen_params', {}).get('prompt', '')
|
||||
|
||||
logger.info(f"Validation against reference:")
|
||||
logger.info(f" LoRAs match: {loras_match}")
|
||||
logger.info(f" Prompt match: {prompt_match}")
|
||||
except Exception as e:
|
||||
logger.warning(f"Failed to compare with reference output: {e}")
|
||||
|
||||
if __name__ == "__main__":
|
||||
test_parse_flux_workflow()
|
||||
@@ -1,120 +0,0 @@
|
||||
"""
|
||||
Utility functions for ComfyUI workflow parsing
|
||||
"""
|
||||
import json
|
||||
import os
|
||||
import logging
|
||||
from typing import Dict, List, Any, Optional, Union, Set, Tuple
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
def load_workflow(workflow_path: str) -> Dict:
|
||||
"""Load a workflow from a JSON file"""
|
||||
try:
|
||||
with open(workflow_path, 'r', encoding='utf-8') as f:
|
||||
return json.load(f)
|
||||
except Exception as e:
|
||||
logger.error(f"Error loading workflow from {workflow_path}: {e}")
|
||||
raise
|
||||
|
||||
def save_output(output: Dict, output_path: str) -> None:
|
||||
"""Save the parsed output to a JSON file"""
|
||||
os.makedirs(os.path.dirname(os.path.abspath(output_path)), exist_ok=True)
|
||||
try:
|
||||
with open(output_path, 'w', encoding='utf-8') as f:
|
||||
json.dump(output, f, indent=4)
|
||||
except Exception as e:
|
||||
logger.error(f"Error saving output to {output_path}: {e}")
|
||||
raise
|
||||
|
||||
def find_node_by_type(workflow: Dict, node_type: str) -> Optional[str]:
|
||||
"""Find a node of the specified type in the workflow"""
|
||||
for node_id, node_data in workflow.items():
|
||||
if node_data.get("class_type") == node_type:
|
||||
return node_id
|
||||
return None
|
||||
|
||||
def find_nodes_by_type(workflow: Dict, node_type: str) -> List[str]:
|
||||
"""Find all nodes of the specified type in the workflow"""
|
||||
return [node_id for node_id, node_data in workflow.items()
|
||||
if node_data.get("class_type") == node_type]
|
||||
|
||||
def get_input_node_ids(workflow: Dict, node_id: str) -> Dict[str, Tuple[str, int]]:
|
||||
"""
|
||||
Get the node IDs for all inputs of the given node
|
||||
|
||||
Returns a dictionary mapping input names to (node_id, output_slot) tuples
|
||||
"""
|
||||
result = {}
|
||||
if node_id not in workflow:
|
||||
return result
|
||||
|
||||
node_data = workflow[node_id]
|
||||
for input_name, input_value in node_data.get("inputs", {}).items():
|
||||
# Check if this input is connected to another node
|
||||
if isinstance(input_value, list) and len(input_value) == 2:
|
||||
# Input is connected to another node's output
|
||||
# Format: [node_id, output_slot]
|
||||
ref_node_id, output_slot = input_value
|
||||
result[input_name] = (str(ref_node_id), output_slot)
|
||||
|
||||
return result
|
||||
|
||||
def trace_model_path(workflow: Dict, start_node_id: str) -> List[str]:
|
||||
"""
|
||||
Trace the model path backward from KSampler to find all LoRA nodes
|
||||
|
||||
Args:
|
||||
workflow: The workflow data
|
||||
start_node_id: The starting node ID (usually KSampler)
|
||||
|
||||
Returns:
|
||||
List of node IDs in the model path
|
||||
"""
|
||||
model_path_nodes = []
|
||||
|
||||
# Get the model input from the start node
|
||||
if start_node_id not in workflow:
|
||||
return model_path_nodes
|
||||
|
||||
# Track visited nodes to avoid cycles
|
||||
visited = set()
|
||||
|
||||
# Stack for depth-first search
|
||||
stack = []
|
||||
|
||||
# Get model input reference if available
|
||||
start_node = workflow[start_node_id]
|
||||
if "inputs" in start_node and "model" in start_node["inputs"] and isinstance(start_node["inputs"]["model"], list):
|
||||
model_ref = start_node["inputs"]["model"]
|
||||
stack.append(str(model_ref[0]))
|
||||
|
||||
# Perform depth-first search
|
||||
while stack:
|
||||
node_id = stack.pop()
|
||||
|
||||
# Skip if already visited
|
||||
if node_id in visited:
|
||||
continue
|
||||
|
||||
# Mark as visited
|
||||
visited.add(node_id)
|
||||
|
||||
# Skip if node doesn't exist
|
||||
if node_id not in workflow:
|
||||
continue
|
||||
|
||||
node = workflow[node_id]
|
||||
node_type = node.get("class_type", "")
|
||||
|
||||
# Add current node to result list if it's a LoRA node
|
||||
if "Lora" in node_type:
|
||||
model_path_nodes.append(node_id)
|
||||
|
||||
# Add all input nodes that have a "model" or "lora_stack" output to the stack
|
||||
if "inputs" in node:
|
||||
for input_name, input_value in node["inputs"].items():
|
||||
if input_name in ["model", "lora_stack"] and isinstance(input_value, list) and len(input_value) == 2:
|
||||
stack.append(str(input_value[0]))
|
||||
|
||||
return model_path_nodes
|
||||
@@ -1,7 +1,7 @@
|
||||
[project]
|
||||
name = "comfyui-lora-manager"
|
||||
description = "LoRA Manager for ComfyUI - Access it at http://localhost:8188/loras for managing LoRA models with previews and metadata integration."
|
||||
version = "0.8.6"
|
||||
version = "0.8.17"
|
||||
license = {file = "LICENSE"}
|
||||
dependencies = [
|
||||
"aiohttp",
|
||||
@@ -12,7 +12,10 @@ dependencies = [
|
||||
"piexif",
|
||||
"Pillow",
|
||||
"olefile", # for getting rid of warning message
|
||||
"requests"
|
||||
"requests",
|
||||
"toml",
|
||||
"natsort",
|
||||
"msgpack"
|
||||
]
|
||||
|
||||
[project.urls]
|
||||
@@ -22,4 +25,4 @@ Repository = "https://github.com/willmiao/ComfyUI-Lora-Manager"
|
||||
[tool.comfy]
|
||||
PublisherId = "willmiao"
|
||||
DisplayName = "ComfyUI-Lora-Manager"
|
||||
Icon = ""
|
||||
Icon = "https://github.com/willmiao/ComfyUI-Lora-Manager/blob/main/static/images/android-chrome-512x512.png?raw=true"
|
||||
|
||||
@@ -1,294 +0,0 @@
|
||||
Loading workflow from D:\Workspace\ComfyUI\custom_nodes\ComfyUI-Lora-Manager\refs\prompt.json
|
||||
Expected output from D:\Workspace\ComfyUI\custom_nodes\ComfyUI-Lora-Manager\refs\output.json
|
||||
|
||||
Expected output:
|
||||
{
|
||||
"loras": "<lora:ck-neon-retrowave-IL-000012:0.8> <lora:aorunIllstrious:1> <lora:ck-shadow-circuit-IL-000012:0.78> <lora:MoriiMee_Gothic_Niji_Style_Illustrious_r1:0.45> <lora:ck-nc-cyberpunk-IL-000011:0.4>",
|
||||
"gen_params": {
|
||||
"prompt": "in the style of ck-rw, aorun, scales, makeup, bare shoulders, pointy ears, dress, claws, in the style of cksc, artist:moriimee, in the style of cknc, masterpiece, best quality, good quality, very aesthetic, absurdres, newest, 8K, depth of field, focused subject, close up, stylized, in gold and neon shades, wabi sabi, 1girl, rainbow angel wings, looking at viewer, dynamic angle, from below, from side, relaxing",
|
||||
"negative_prompt": "bad quality, worst quality, worst detail, sketch ,signature, watermark, patreon logo, nsfw",
|
||||
"steps": "20",
|
||||
"sampler": "euler_ancestral",
|
||||
"cfg_scale": "8",
|
||||
"seed": "241",
|
||||
"size": "832x1216",
|
||||
"clip_skip": "2"
|
||||
}
|
||||
}
|
||||
|
||||
Sampler node:
|
||||
{
|
||||
"inputs": {
|
||||
"seed": 241,
|
||||
"steps": 20,
|
||||
"cfg": 8,
|
||||
"sampler_name": "euler_ancestral",
|
||||
"scheduler": "karras",
|
||||
"denoise": 1,
|
||||
"model": [
|
||||
"56",
|
||||
0
|
||||
],
|
||||
"positive": [
|
||||
"6",
|
||||
0
|
||||
],
|
||||
"negative": [
|
||||
"7",
|
||||
0
|
||||
],
|
||||
"latent_image": [
|
||||
"5",
|
||||
0
|
||||
]
|
||||
},
|
||||
"class_type": "KSampler",
|
||||
"_meta": {
|
||||
"title": "KSampler"
|
||||
}
|
||||
}
|
||||
|
||||
Extracted parameters:
|
||||
seed: 241
|
||||
steps: 20
|
||||
cfg_scale: 8
|
||||
|
||||
Positive node (6):
|
||||
{
|
||||
"inputs": {
|
||||
"text": [
|
||||
"22",
|
||||
0
|
||||
],
|
||||
"clip": [
|
||||
"56",
|
||||
1
|
||||
]
|
||||
},
|
||||
"class_type": "CLIPTextEncode",
|
||||
"_meta": {
|
||||
"title": "CLIP Text Encode (Prompt)"
|
||||
}
|
||||
}
|
||||
|
||||
Text node (22):
|
||||
{
|
||||
"inputs": {
|
||||
"string1": [
|
||||
"55",
|
||||
0
|
||||
],
|
||||
"string2": [
|
||||
"21",
|
||||
0
|
||||
],
|
||||
"delimiter": ", "
|
||||
},
|
||||
"class_type": "JoinStrings",
|
||||
"_meta": {
|
||||
"title": "Join Strings"
|
||||
}
|
||||
}
|
||||
|
||||
String1 node (55):
|
||||
{
|
||||
"inputs": {
|
||||
"group_mode": true,
|
||||
"toggle_trigger_words": [
|
||||
{
|
||||
"text": "in the style of ck-rw",
|
||||
"active": true
|
||||
},
|
||||
{
|
||||
"text": "aorun, scales, makeup, bare shoulders, pointy ears",
|
||||
"active": true
|
||||
},
|
||||
{
|
||||
"text": "dress",
|
||||
"active": true
|
||||
},
|
||||
{
|
||||
"text": "claws",
|
||||
"active": true
|
||||
},
|
||||
{
|
||||
"text": "in the style of cksc",
|
||||
"active": true
|
||||
},
|
||||
{
|
||||
"text": "artist:moriimee",
|
||||
"active": true
|
||||
},
|
||||
{
|
||||
"text": "in the style of cknc",
|
||||
"active": true
|
||||
},
|
||||
{
|
||||
"text": "__dummy_item__",
|
||||
"active": false,
|
||||
"_isDummy": true
|
||||
},
|
||||
{
|
||||
"text": "__dummy_item__",
|
||||
"active": false,
|
||||
"_isDummy": true
|
||||
}
|
||||
],
|
||||
"orinalMessage": "in the style of ck-rw,, aorun, scales, makeup, bare shoulders, pointy ears,, dress,, claws,, in the style of cksc,, artist:moriimee,, in the style of cknc",
|
||||
"trigger_words": [
|
||||
"56",
|
||||
2
|
||||
]
|
||||
},
|
||||
"class_type": "TriggerWord Toggle (LoraManager)",
|
||||
"_meta": {
|
||||
"title": "TriggerWord Toggle (LoraManager)"
|
||||
}
|
||||
}
|
||||
|
||||
String2 node (21):
|
||||
{
|
||||
"inputs": {
|
||||
"string": "masterpiece, best quality, good quality, very aesthetic, absurdres, newest, 8K, depth of field, focused subject, close up, stylized, in gold and neon shades, wabi sabi, 1girl, rainbow angel wings, looking at viewer, dynamic angle, from below, from side, relaxing",
|
||||
"strip_newlines": false
|
||||
},
|
||||
"class_type": "StringConstantMultiline",
|
||||
"_meta": {
|
||||
"title": "positive"
|
||||
}
|
||||
}
|
||||
|
||||
Negative node (7):
|
||||
{
|
||||
"inputs": {
|
||||
"text": "bad quality, worst quality, worst detail, sketch ,signature, watermark, patreon logo, nsfw",
|
||||
"clip": [
|
||||
"56",
|
||||
1
|
||||
]
|
||||
},
|
||||
"class_type": "CLIPTextEncode",
|
||||
"_meta": {
|
||||
"title": "CLIP Text Encode (Prompt)"
|
||||
}
|
||||
}
|
||||
|
||||
LoRA nodes (3):
|
||||
|
||||
LoRA node 56:
|
||||
{
|
||||
"inputs": {
|
||||
"text": "<lora:ck-shadow-circuit-IL-000012:0.78> <lora:MoriiMee_Gothic_Niji_Style_Illustrious_r1:0.45> <lora:ck-nc-cyberpunk-IL-000011:0.4>",
|
||||
"loras": [
|
||||
{
|
||||
"name": "ck-shadow-circuit-IL-000012",
|
||||
"strength": 0.78,
|
||||
"active": true
|
||||
},
|
||||
{
|
||||
"name": "MoriiMee_Gothic_Niji_Style_Illustrious_r1",
|
||||
"strength": 0.45,
|
||||
"active": true
|
||||
},
|
||||
{
|
||||
"name": "ck-nc-cyberpunk-IL-000011",
|
||||
"strength": 0.4,
|
||||
"active": true
|
||||
},
|
||||
{
|
||||
"name": "__dummy_item1__",
|
||||
"strength": 0,
|
||||
"active": false,
|
||||
"_isDummy": true
|
||||
},
|
||||
{
|
||||
"name": "__dummy_item2__",
|
||||
"strength": 0,
|
||||
"active": false,
|
||||
"_isDummy": true
|
||||
}
|
||||
],
|
||||
"model": [
|
||||
"4",
|
||||
0
|
||||
],
|
||||
"clip": [
|
||||
"4",
|
||||
1
|
||||
],
|
||||
"lora_stack": [
|
||||
"57",
|
||||
0
|
||||
]
|
||||
},
|
||||
"class_type": "Lora Loader (LoraManager)",
|
||||
"_meta": {
|
||||
"title": "Lora Loader (LoraManager)"
|
||||
}
|
||||
}
|
||||
|
||||
LoRA node 57:
|
||||
{
|
||||
"inputs": {
|
||||
"text": "<lora:aorunIllstrious:1>",
|
||||
"loras": [
|
||||
{
|
||||
"name": "aorunIllstrious",
|
||||
"strength": "0.90",
|
||||
"active": true
|
||||
},
|
||||
{
|
||||
"name": "__dummy_item1__",
|
||||
"strength": 0,
|
||||
"active": false,
|
||||
"_isDummy": true
|
||||
},
|
||||
{
|
||||
"name": "__dummy_item2__",
|
||||
"strength": 0,
|
||||
"active": false,
|
||||
"_isDummy": true
|
||||
}
|
||||
],
|
||||
"lora_stack": [
|
||||
"59",
|
||||
0
|
||||
]
|
||||
},
|
||||
"class_type": "Lora Stacker (LoraManager)",
|
||||
"_meta": {
|
||||
"title": "Lora Stacker (LoraManager)"
|
||||
}
|
||||
}
|
||||
|
||||
LoRA node 59:
|
||||
{
|
||||
"inputs": {
|
||||
"text": "<lora:ck-neon-retrowave-IL-000012:0.8>",
|
||||
"loras": [
|
||||
{
|
||||
"name": "ck-neon-retrowave-IL-000012",
|
||||
"strength": 0.8,
|
||||
"active": true
|
||||
},
|
||||
{
|
||||
"name": "__dummy_item1__",
|
||||
"strength": 0,
|
||||
"active": false,
|
||||
"_isDummy": true
|
||||
},
|
||||
{
|
||||
"name": "__dummy_item2__",
|
||||
"strength": 0,
|
||||
"active": false,
|
||||
"_isDummy": true
|
||||
}
|
||||
]
|
||||
},
|
||||
"class_type": "Lora Stacker (LoraManager)",
|
||||
"_meta": {
|
||||
"title": "Lora Stacker (LoraManager)"
|
||||
}
|
||||
}
|
||||
|
||||
Test completed.
|
||||
@@ -6,4 +6,9 @@ beautifulsoup4
|
||||
piexif
|
||||
Pillow
|
||||
olefile
|
||||
requests
|
||||
requests
|
||||
toml
|
||||
numpy
|
||||
torch
|
||||
natsort
|
||||
msgpack
|
||||
14
settings.json.example
Normal file
14
settings.json.example
Normal file
@@ -0,0 +1,14 @@
|
||||
{
|
||||
"civitai_api_key": "your_civitai_api_key_here",
|
||||
"show_only_sfw": false,
|
||||
"folder_paths": {
|
||||
"loras": [
|
||||
"C:/path/to/your/loras_folder",
|
||||
"C:/path/to/another/loras_folder"
|
||||
],
|
||||
"checkpoints": [
|
||||
"C:/path/to/your/checkpoints_folder",
|
||||
"C:/path/to/another/checkpoints_folder"
|
||||
]
|
||||
}
|
||||
}
|
||||
360
standalone.py
Normal file
360
standalone.py
Normal file
@@ -0,0 +1,360 @@
|
||||
import os
|
||||
import sys
|
||||
import json
|
||||
|
||||
# Create mock folder_paths module BEFORE any other imports
|
||||
class MockFolderPaths:
|
||||
@staticmethod
|
||||
def get_folder_paths(folder_name):
|
||||
# Load paths from settings.json
|
||||
settings_path = os.path.join(os.path.dirname(__file__), 'settings.json')
|
||||
try:
|
||||
if os.path.exists(settings_path):
|
||||
with open(settings_path, 'r', encoding='utf-8') as f:
|
||||
settings = json.load(f)
|
||||
|
||||
# For diffusion_models, combine unet and diffusers paths
|
||||
if folder_name == "diffusion_models":
|
||||
paths = []
|
||||
if 'folder_paths' in settings:
|
||||
if 'unet' in settings['folder_paths']:
|
||||
paths.extend(settings['folder_paths']['unet'])
|
||||
if 'diffusers' in settings['folder_paths']:
|
||||
paths.extend(settings['folder_paths']['diffusers'])
|
||||
# Filter out paths that don't exist
|
||||
valid_paths = [p for p in paths if os.path.exists(p)]
|
||||
if valid_paths:
|
||||
return valid_paths
|
||||
else:
|
||||
print(f"Warning: No valid paths found for {folder_name}")
|
||||
# For other folder names, return their paths directly
|
||||
elif 'folder_paths' in settings and folder_name in settings['folder_paths']:
|
||||
paths = settings['folder_paths'][folder_name]
|
||||
valid_paths = [p for p in paths if os.path.exists(p)]
|
||||
if valid_paths:
|
||||
return valid_paths
|
||||
else:
|
||||
print(f"Warning: No valid paths found for {folder_name}")
|
||||
except Exception as e:
|
||||
print(f"Error loading folder paths from settings: {e}")
|
||||
|
||||
# Fallback to empty list if no paths found
|
||||
return []
|
||||
|
||||
@staticmethod
|
||||
def get_temp_directory():
|
||||
return os.path.join(os.path.dirname(__file__), 'temp')
|
||||
|
||||
@staticmethod
|
||||
def set_temp_directory(path):
|
||||
os.makedirs(path, exist_ok=True)
|
||||
return path
|
||||
|
||||
# Create mock server module with PromptServer
|
||||
class MockPromptServer:
|
||||
def __init__(self):
|
||||
self.app = None
|
||||
|
||||
def send_sync(self, *args, **kwargs):
|
||||
pass
|
||||
|
||||
# Create mock metadata_collector module
|
||||
class MockMetadataCollector:
|
||||
def init(self):
|
||||
pass
|
||||
|
||||
def get_metadata(self, prompt_id=None):
|
||||
return {}
|
||||
|
||||
# Initialize basic mocks before any imports
|
||||
sys.modules['folder_paths'] = MockFolderPaths()
|
||||
sys.modules['server'] = type('server', (), {'PromptServer': MockPromptServer()})
|
||||
sys.modules['py.metadata_collector'] = MockMetadataCollector()
|
||||
|
||||
# Now we can safely import modules that depend on folder_paths and server
|
||||
import argparse
|
||||
import asyncio
|
||||
import logging
|
||||
from aiohttp import web
|
||||
|
||||
# Setup logging
|
||||
logging.basicConfig(level=logging.INFO,
|
||||
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
|
||||
logger = logging.getLogger("lora-manager-standalone")
|
||||
|
||||
# Configure aiohttp access logger to be less verbose
|
||||
logging.getLogger('aiohttp.access').setLevel(logging.WARNING)
|
||||
|
||||
# Now we can import the global config from our local modules
|
||||
from py.config import config
|
||||
|
||||
class StandaloneServer:
|
||||
"""Server implementation for standalone mode"""
|
||||
|
||||
def __init__(self):
|
||||
self.app = web.Application(logger=logger)
|
||||
self.instance = self # Make it compatible with PromptServer.instance pattern
|
||||
|
||||
# Ensure the app's access logger is configured to reduce verbosity
|
||||
self.app._subapps = [] # Ensure this exists to avoid AttributeError
|
||||
|
||||
# Configure access logging for the app
|
||||
self.app.on_startup.append(self._configure_access_logger)
|
||||
|
||||
async def _configure_access_logger(self, app):
|
||||
"""Configure access logger to reduce verbosity"""
|
||||
logging.getLogger('aiohttp.access').setLevel(logging.WARNING)
|
||||
|
||||
# If using aiohttp>=3.8.0, configure access logger through app directly
|
||||
if hasattr(app, 'access_logger'):
|
||||
app.access_logger.setLevel(logging.WARNING)
|
||||
|
||||
async def setup(self):
|
||||
"""Set up the standalone server"""
|
||||
# Create placeholders for compatibility with ComfyUI's implementation
|
||||
self.last_prompt_id = None
|
||||
self.last_node_id = None
|
||||
self.client_id = None
|
||||
|
||||
# Set up routes
|
||||
self.setup_routes()
|
||||
|
||||
# Add startup and shutdown handlers
|
||||
self.app.on_startup.append(self.on_startup)
|
||||
self.app.on_shutdown.append(self.on_shutdown)
|
||||
|
||||
def setup_routes(self):
|
||||
"""Set up basic routes"""
|
||||
# Add a simple status endpoint
|
||||
self.app.router.add_get('/', self.handle_status)
|
||||
|
||||
# Add static route for example images if the path exists in settings
|
||||
settings_path = os.path.join(os.path.dirname(__file__), 'settings.json')
|
||||
if os.path.exists(settings_path):
|
||||
with open(settings_path, 'r', encoding='utf-8') as f:
|
||||
settings = json.load(f)
|
||||
example_images_path = settings.get('example_images_path')
|
||||
logger.info(f"Example images path: {example_images_path}")
|
||||
if example_images_path and os.path.exists(example_images_path):
|
||||
self.app.router.add_static('/example_images_static', example_images_path)
|
||||
logger.info(f"Added static route for example images: /example_images_static -> {example_images_path}")
|
||||
|
||||
async def handle_status(self, request):
|
||||
"""Handle status request by redirecting to loras page"""
|
||||
# Redirect to loras page instead of showing status
|
||||
raise web.HTTPFound('/loras')
|
||||
|
||||
# Original JSON response (commented out)
|
||||
# return web.json_response({
|
||||
# "status": "running",
|
||||
# "mode": "standalone",
|
||||
# "loras_roots": config.loras_roots,
|
||||
# "checkpoints_roots": config.checkpoints_roots
|
||||
# })
|
||||
|
||||
async def on_startup(self, app):
|
||||
"""Startup handler"""
|
||||
logger.info("LoRA Manager standalone server starting...")
|
||||
|
||||
async def on_shutdown(self, app):
|
||||
"""Shutdown handler"""
|
||||
logger.info("LoRA Manager standalone server shutting down...")
|
||||
|
||||
def send_sync(self, event_type, data, sid=None):
|
||||
"""Stub for compatibility with PromptServer"""
|
||||
# In standalone mode, we don't have the same websocket system
|
||||
pass
|
||||
|
||||
async def start(self, host='127.0.0.1', port=8188):
|
||||
"""Start the server"""
|
||||
runner = web.AppRunner(self.app)
|
||||
await runner.setup()
|
||||
site = web.TCPSite(runner, host, port)
|
||||
await site.start()
|
||||
|
||||
# Log the server address with a clickable localhost URL regardless of the actual binding
|
||||
logger.info(f"Server started at http://127.0.0.1:{port}")
|
||||
|
||||
# Keep the server running
|
||||
while True:
|
||||
await asyncio.sleep(3600) # Sleep for a long time
|
||||
|
||||
async def publish_loop(self):
|
||||
"""Stub for compatibility with PromptServer"""
|
||||
# This method exists in ComfyUI's server but we don't need it
|
||||
pass
|
||||
|
||||
# After all mocks are in place, import LoraManager
|
||||
from py.lora_manager import LoraManager
|
||||
|
||||
class StandaloneLoraManager(LoraManager):
|
||||
"""Extended LoraManager for standalone mode"""
|
||||
|
||||
@classmethod
|
||||
def add_routes(cls, server_instance):
|
||||
"""Initialize and register all routes for standalone mode"""
|
||||
app = server_instance.app
|
||||
|
||||
# Store app in a global-like location for compatibility
|
||||
sys.modules['server'].PromptServer.instance = server_instance
|
||||
|
||||
# Configure aiohttp access logger to be less verbose
|
||||
logging.getLogger('aiohttp.access').setLevel(logging.WARNING)
|
||||
|
||||
added_targets = set() # Track already added target paths
|
||||
|
||||
# Add static routes for each lora root
|
||||
for idx, root in enumerate(config.loras_roots, start=1):
|
||||
if not os.path.exists(root):
|
||||
logger.warning(f"Lora root path does not exist: {root}")
|
||||
continue
|
||||
|
||||
preview_path = f'/loras_static/root{idx}/preview'
|
||||
|
||||
# Check if this root is a link path in the mappings
|
||||
real_root = root
|
||||
for target, link in config._path_mappings.items():
|
||||
if os.path.normpath(link) == os.path.normpath(root):
|
||||
# If so, route should point to the target (real path)
|
||||
real_root = target
|
||||
break
|
||||
|
||||
# Normalize and standardize path display for consistency
|
||||
display_root = real_root.replace('\\', '/')
|
||||
|
||||
# Add static route for original path - use the normalized path
|
||||
app.router.add_static(preview_path, real_root)
|
||||
logger.info(f"Added static route {preview_path} -> {display_root}")
|
||||
|
||||
# Record route mapping with normalized path
|
||||
config.add_route_mapping(real_root, preview_path)
|
||||
added_targets.add(os.path.normpath(real_root))
|
||||
|
||||
# Add static routes for each checkpoint root
|
||||
for idx, root in enumerate(config.checkpoints_roots, start=1):
|
||||
if not os.path.exists(root):
|
||||
logger.warning(f"Checkpoint root path does not exist: {root}")
|
||||
continue
|
||||
|
||||
preview_path = f'/checkpoints_static/root{idx}/preview'
|
||||
|
||||
# Check if this root is a link path in the mappings
|
||||
real_root = root
|
||||
for target, link in config._path_mappings.items():
|
||||
if os.path.normpath(link) == os.path.normpath(root):
|
||||
# If so, route should point to the target (real path)
|
||||
real_root = target
|
||||
break
|
||||
|
||||
# Normalize and standardize path display for consistency
|
||||
display_root = real_root.replace('\\', '/')
|
||||
|
||||
# Add static route for original path
|
||||
app.router.add_static(preview_path, real_root)
|
||||
logger.info(f"Added static route {preview_path} -> {display_root}")
|
||||
|
||||
# Record route mapping
|
||||
config.add_route_mapping(real_root, preview_path)
|
||||
added_targets.add(os.path.normpath(real_root))
|
||||
|
||||
# Add static routes for symlink target paths that aren't already covered
|
||||
link_idx = {
|
||||
'lora': 1,
|
||||
'checkpoint': 1
|
||||
}
|
||||
|
||||
for target_path, link_path in config._path_mappings.items():
|
||||
norm_target = os.path.normpath(target_path)
|
||||
if norm_target not in added_targets:
|
||||
# Determine if this is a checkpoint or lora link based on path
|
||||
is_checkpoint = any(os.path.normpath(cp_root) in os.path.normpath(link_path) for cp_root in config.checkpoints_roots)
|
||||
is_checkpoint = is_checkpoint or any(os.path.normpath(cp_root) in norm_target for cp_root in config.checkpoints_roots)
|
||||
|
||||
if is_checkpoint:
|
||||
route_path = f'/checkpoints_static/link_{link_idx["checkpoint"]}/preview'
|
||||
link_idx["checkpoint"] += 1
|
||||
else:
|
||||
route_path = f'/loras_static/link_{link_idx["lora"]}/preview'
|
||||
link_idx["lora"] += 1
|
||||
|
||||
# Display path with forward slashes for consistency
|
||||
display_target = target_path.replace('\\', '/')
|
||||
|
||||
app.router.add_static(route_path, target_path)
|
||||
logger.info(f"Added static route for link target {route_path} -> {display_target}")
|
||||
config.add_route_mapping(target_path, route_path)
|
||||
added_targets.add(norm_target)
|
||||
|
||||
# Add static route for plugin assets
|
||||
app.router.add_static('/loras_static', config.static_path)
|
||||
|
||||
# Setup feature routes
|
||||
from py.routes.lora_routes import LoraRoutes
|
||||
from py.routes.api_routes import ApiRoutes
|
||||
from py.routes.recipe_routes import RecipeRoutes
|
||||
from py.routes.checkpoints_routes import CheckpointsRoutes
|
||||
from py.routes.update_routes import UpdateRoutes
|
||||
from py.routes.misc_routes import MiscRoutes
|
||||
from py.routes.example_images_routes import ExampleImagesRoutes
|
||||
|
||||
lora_routes = LoraRoutes()
|
||||
checkpoints_routes = CheckpointsRoutes()
|
||||
|
||||
# Initialize routes
|
||||
lora_routes.setup_routes(app)
|
||||
checkpoints_routes.setup_routes(app)
|
||||
ApiRoutes.setup_routes(app)
|
||||
RecipeRoutes.setup_routes(app)
|
||||
UpdateRoutes.setup_routes(app)
|
||||
MiscRoutes.setup_routes(app)
|
||||
ExampleImagesRoutes.setup_routes(app)
|
||||
|
||||
# Schedule service initialization
|
||||
app.on_startup.append(lambda app: cls._initialize_services())
|
||||
|
||||
# Add cleanup
|
||||
app.on_shutdown.append(cls._cleanup)
|
||||
app.on_shutdown.append(ApiRoutes.cleanup)
|
||||
|
||||
def parse_args():
|
||||
"""Parse command line arguments"""
|
||||
parser = argparse.ArgumentParser(description="LoRA Manager Standalone Server")
|
||||
parser.add_argument("--host", type=str, default="0.0.0.0",
|
||||
help="Host address to bind the server to (default: 0.0.0.0)")
|
||||
parser.add_argument("--port", type=int, default=8188,
|
||||
help="Port to bind the server to (default: 8188, access via http://localhost:8188/loras)")
|
||||
# parser.add_argument("--loras", type=str, nargs="+",
|
||||
# help="Additional paths to LoRA model directories (optional if settings.json has paths)")
|
||||
# parser.add_argument("--checkpoints", type=str, nargs="+",
|
||||
# help="Additional paths to checkpoint model directories (optional if settings.json has paths)")
|
||||
parser.add_argument("--log-level", type=str, default="INFO",
|
||||
choices=["DEBUG", "INFO", "WARNING", "ERROR", "CRITICAL"],
|
||||
help="Logging level")
|
||||
return parser.parse_args()
|
||||
|
||||
async def main():
|
||||
"""Main entry point for standalone mode"""
|
||||
args = parse_args()
|
||||
|
||||
# Set log level
|
||||
logging.getLogger().setLevel(getattr(logging, args.log_level))
|
||||
|
||||
# Explicitly configure aiohttp access logger regardless of selected log level
|
||||
logging.getLogger('aiohttp.access').setLevel(logging.WARNING)
|
||||
|
||||
# Create the server instance
|
||||
server = StandaloneServer()
|
||||
|
||||
# Initialize routes via the standalone lora manager
|
||||
StandaloneLoraManager.add_routes(server)
|
||||
|
||||
# Set up and start the server
|
||||
await server.setup()
|
||||
await server.start(host=args.host, port=args.port)
|
||||
|
||||
if __name__ == "__main__":
|
||||
try:
|
||||
# Run the main function
|
||||
asyncio.run(main())
|
||||
except KeyboardInterrupt:
|
||||
logger.info("Server stopped by user")
|
||||
@@ -32,13 +32,21 @@ html, body {
|
||||
--card-bg: #ffffff;
|
||||
--border-color: #e0e0e0;
|
||||
|
||||
/* Color System */
|
||||
--lora-accent: oklch(68% 0.28 256);
|
||||
/* Color Components */
|
||||
--lora-accent-l: 68%;
|
||||
--lora-accent-c: 0.28;
|
||||
--lora-accent-h: 256;
|
||||
--lora-warning-l: 75%;
|
||||
--lora-warning-c: 0.25;
|
||||
--lora-warning-h: 80;
|
||||
|
||||
/* Composed Colors */
|
||||
--lora-accent: oklch(var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h));
|
||||
--lora-surface: oklch(100% 0 0 / 0.98);
|
||||
--lora-border: oklch(90% 0.02 256 / 0.15);
|
||||
--lora-text: oklch(95% 0.02 256);
|
||||
--lora-error: oklch(75% 0.32 29);
|
||||
--lora-warning: oklch(75% 0.25 80); /* Add warning color for deleted LoRAs */
|
||||
--lora-warning: oklch(var(--lora-warning-l) var(--lora-warning-c) var(--lora-warning-h)); /* Modified to be used with oklch() */
|
||||
|
||||
/* Spacing Scale */
|
||||
--space-1: calc(8px * 1);
|
||||
@@ -59,6 +67,16 @@ html, body {
|
||||
--scrollbar-width: 8px; /* 添加滚动条宽度变量 */
|
||||
}
|
||||
|
||||
html[data-theme="dark"] {
|
||||
background-color: #1a1a1a !important;
|
||||
color-scheme: dark;
|
||||
}
|
||||
|
||||
html[data-theme="light"] {
|
||||
background-color: #ffffff !important;
|
||||
color-scheme: light;
|
||||
}
|
||||
|
||||
[data-theme="dark"] {
|
||||
--bg-color: #1a1a1a;
|
||||
--text-color: #e0e0e0;
|
||||
@@ -69,7 +87,7 @@ html, body {
|
||||
--lora-surface: oklch(25% 0.02 256 / 0.98);
|
||||
--lora-border: oklch(90% 0.02 256 / 0.15);
|
||||
--lora-text: oklch(98% 0.02 256);
|
||||
--lora-warning: oklch(75% 0.25 80); /* Add warning color for dark theme too */
|
||||
--lora-warning: oklch(75% 0.25 80); /* Modified to be used with oklch() */
|
||||
}
|
||||
|
||||
body {
|
||||
|
||||
165
static/css/components/alphabet-bar.css
Normal file
165
static/css/components/alphabet-bar.css
Normal file
@@ -0,0 +1,165 @@
|
||||
/* Alphabet Bar Component */
|
||||
.alphabet-bar-container {
|
||||
position: fixed;
|
||||
left: 0;
|
||||
top: 50%;
|
||||
transform: translateY(-50%);
|
||||
z-index: 100;
|
||||
display: flex;
|
||||
transition: transform 0.3s ease;
|
||||
}
|
||||
|
||||
.alphabet-bar-container.collapsed {
|
||||
transform: translateY(-50%) translateX(-90%);
|
||||
}
|
||||
|
||||
/* New visual indicator for when a letter is active and bar is collapsed */
|
||||
.alphabet-bar-container.collapsed .toggle-alphabet-bar.has-active-letter {
|
||||
border-color: var(--lora-accent);
|
||||
background: oklch(var(--lora-accent) / 0.15);
|
||||
}
|
||||
|
||||
.alphabet-bar-container.collapsed .toggle-alphabet-bar.has-active-letter::after {
|
||||
content: '';
|
||||
position: absolute;
|
||||
top: 7px;
|
||||
right: 7px;
|
||||
width: 8px;
|
||||
height: 8px;
|
||||
background-color: var(--lora-accent);
|
||||
border-radius: 50%;
|
||||
animation: pulse-active 2s infinite;
|
||||
}
|
||||
|
||||
@keyframes pulse-active {
|
||||
0% { transform: scale(0.8); opacity: 0.7; }
|
||||
50% { transform: scale(1.1); opacity: 1; }
|
||||
100% { transform: scale(0.8); opacity: 0.7; }
|
||||
}
|
||||
|
||||
.alphabet-bar {
|
||||
background: var(--card-bg);
|
||||
border: 1px solid var(--border-color);
|
||||
border-radius: 0 var(--border-radius-xs) var(--border-radius-xs) 0;
|
||||
padding: 8px 4px;
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
gap: 6px;
|
||||
align-items: center;
|
||||
box-shadow: 2px 0 8px rgba(0, 0, 0, 0.1);
|
||||
max-height: 80vh;
|
||||
overflow-y: auto;
|
||||
scrollbar-width: thin;
|
||||
}
|
||||
|
||||
.alphabet-bar::-webkit-scrollbar {
|
||||
width: 4px;
|
||||
}
|
||||
|
||||
.alphabet-bar::-webkit-scrollbar-thumb {
|
||||
background: var(--border-color);
|
||||
border-radius: 4px;
|
||||
}
|
||||
|
||||
.toggle-alphabet-bar {
|
||||
background: var(--card-bg);
|
||||
border: 1px solid var(--border-color);
|
||||
border-left: none;
|
||||
border-radius: 0 var(--border-radius-xs) var(--border-radius-xs) 0;
|
||||
padding: 8px 4px;
|
||||
cursor: pointer;
|
||||
display: flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
color: var(--text-color);
|
||||
width: 20px;
|
||||
height: 40px;
|
||||
align-self: center;
|
||||
box-shadow: 2px 0 8px rgba(0, 0, 0, 0.1);
|
||||
}
|
||||
|
||||
.toggle-alphabet-bar:hover {
|
||||
background: var(--bg-hover);
|
||||
}
|
||||
|
||||
.toggle-alphabet-bar i {
|
||||
transition: transform 0.3s ease;
|
||||
}
|
||||
|
||||
.alphabet-bar-container.collapsed .toggle-alphabet-bar i {
|
||||
transform: rotate(180deg);
|
||||
}
|
||||
|
||||
.letter-chip {
|
||||
padding: 4px 2px;
|
||||
border-radius: var(--border-radius-xs);
|
||||
background: var(--bg-color);
|
||||
color: var(--text-color);
|
||||
cursor: pointer;
|
||||
min-width: 24px;
|
||||
text-align: center;
|
||||
font-size: 0.85em;
|
||||
transition: all 0.2s ease;
|
||||
border: 1px solid var(--border-color);
|
||||
}
|
||||
|
||||
.letter-chip:hover {
|
||||
background: var(--lora-accent);
|
||||
color: white;
|
||||
transform: scale(1.1);
|
||||
box-shadow: 0 2px 4px rgba(0, 0, 0, 0.1);
|
||||
}
|
||||
|
||||
.letter-chip.active {
|
||||
background: var(--lora-accent);
|
||||
color: white;
|
||||
border-color: var(--lora-accent);
|
||||
}
|
||||
|
||||
.letter-chip.disabled {
|
||||
opacity: 0.5;
|
||||
pointer-events: none;
|
||||
cursor: default;
|
||||
}
|
||||
|
||||
/* Hide the count by default, only show in tooltip */
|
||||
.letter-chip .count {
|
||||
display: none;
|
||||
}
|
||||
|
||||
.alphabet-bar-title {
|
||||
font-size: 0.75em;
|
||||
color: var(--text-color);
|
||||
opacity: 0.7;
|
||||
margin-bottom: 6px;
|
||||
writing-mode: vertical-lr;
|
||||
transform: rotate(180deg);
|
||||
white-space: nowrap;
|
||||
}
|
||||
|
||||
@media (max-width: 768px) {
|
||||
.alphabet-bar-container {
|
||||
transform: translateY(-50%) translateX(-90%);
|
||||
}
|
||||
|
||||
.alphabet-bar-container.active {
|
||||
transform: translateY(-50%) translateX(0);
|
||||
}
|
||||
|
||||
.letter-chip {
|
||||
padding: 3px 1px;
|
||||
min-width: 20px;
|
||||
font-size: 0.75em;
|
||||
}
|
||||
}
|
||||
|
||||
/* Keyframe animations for the active letter */
|
||||
@keyframes pulse {
|
||||
0% { transform: scale(1); }
|
||||
50% { transform: scale(1.1); }
|
||||
100% { transform: scale(1); }
|
||||
}
|
||||
|
||||
.letter-chip.active {
|
||||
animation: pulse 1s ease-in-out 1;
|
||||
}
|
||||
@@ -60,6 +60,18 @@
|
||||
border-color: var(--lora-accent);
|
||||
}
|
||||
|
||||
/* Danger button style - updated to use proper theme variables */
|
||||
.bulk-operations-actions button.danger-btn {
|
||||
background: oklch(70% 0.2 29); /* Light red background that works in both themes */
|
||||
color: oklch(98% 0.01 0); /* Almost white text for good contrast */
|
||||
border-color: var(--lora-error);
|
||||
}
|
||||
|
||||
.bulk-operations-actions button.danger-btn:hover {
|
||||
background: var(--lora-error);
|
||||
color: oklch(100% 0 0); /* Pure white text on hover for maximum contrast */
|
||||
}
|
||||
|
||||
/* Style for selected cards */
|
||||
.lora-card.selected {
|
||||
box-shadow: 0 0 0 2px var(--lora-accent);
|
||||
@@ -262,83 +274,6 @@
|
||||
background: var(--lora-accent);
|
||||
}
|
||||
|
||||
/* NSFW Level Selector */
|
||||
.nsfw-level-selector {
|
||||
position: fixed;
|
||||
top: 50%;
|
||||
left: 50%;
|
||||
transform: translate(-50%, -50%);
|
||||
background: var(--card-bg);
|
||||
border: 1px solid var(--border-color);
|
||||
border-radius: var(--border-radius-base);
|
||||
padding: 16px;
|
||||
box-shadow: 0 4px 20px rgba(0, 0, 0, 0.2);
|
||||
z-index: var(--z-modal);
|
||||
width: 300px;
|
||||
display: none;
|
||||
}
|
||||
|
||||
.nsfw-level-header {
|
||||
display: flex;
|
||||
justify-content: space-between;
|
||||
align-items: center;
|
||||
margin-bottom: 16px;
|
||||
}
|
||||
|
||||
.nsfw-level-header h3 {
|
||||
margin: 0;
|
||||
font-size: 16px;
|
||||
font-weight: 500;
|
||||
}
|
||||
|
||||
.close-nsfw-selector {
|
||||
background: transparent;
|
||||
border: none;
|
||||
color: var(--text-color);
|
||||
cursor: pointer;
|
||||
padding: 4px;
|
||||
border-radius: var(--border-radius-xs);
|
||||
}
|
||||
|
||||
.close-nsfw-selector:hover {
|
||||
background: var(--border-color);
|
||||
}
|
||||
|
||||
.current-level {
|
||||
margin-bottom: 12px;
|
||||
padding: 8px;
|
||||
background: var(--bg-color);
|
||||
border-radius: var(--border-radius-xs);
|
||||
border: 1px solid var(--border-color);
|
||||
}
|
||||
|
||||
.nsfw-level-options {
|
||||
display: flex;
|
||||
flex-wrap: wrap;
|
||||
gap: 8px;
|
||||
}
|
||||
|
||||
.nsfw-level-btn {
|
||||
flex: 1 0 calc(33% - 8px);
|
||||
padding: 8px;
|
||||
border-radius: var(--border-radius-xs);
|
||||
background: var(--bg-color);
|
||||
border: 1px solid var(--border-color);
|
||||
color: var(--text-color);
|
||||
cursor: pointer;
|
||||
transition: all 0.2s ease;
|
||||
}
|
||||
|
||||
.nsfw-level-btn:hover {
|
||||
background: var(--lora-border);
|
||||
}
|
||||
|
||||
.nsfw-level-btn.active {
|
||||
background: var(--lora-accent);
|
||||
color: white;
|
||||
border-color: var(--lora-accent);
|
||||
}
|
||||
|
||||
/* Mobile optimizations */
|
||||
@media (max-width: 768px) {
|
||||
.selected-thumbnails-strip {
|
||||
|
||||
@@ -1,14 +1,17 @@
|
||||
/* 卡片网格布局 */
|
||||
.card-grid {
|
||||
display: grid;
|
||||
grid-template-columns: repeat(auto-fill, minmax(260px, 1fr)); /* Adjusted from 320px */
|
||||
gap: 12px; /* Reduced from var(--space-2) for tighter horizontal spacing */
|
||||
grid-template-columns: repeat(auto-fill, minmax(260px, 1fr)); /* Base size */
|
||||
gap: 12px; /* Consistent gap for both row and column spacing */
|
||||
row-gap: 20px; /* Increase vertical spacing between rows */
|
||||
margin-top: var(--space-2);
|
||||
padding-top: 4px; /* 添加顶部内边距,为悬停动画提供空间 */
|
||||
padding-bottom: 4px; /* 添加底部内边距,为悬停动画提供空间 */
|
||||
max-width: 1400px; /* Container width control */
|
||||
width: 100%; /* Ensure it takes full width of container */
|
||||
max-width: 1400px; /* Base container width */
|
||||
margin-left: auto;
|
||||
margin-right: auto;
|
||||
box-sizing: border-box; /* Include padding in width calculation */
|
||||
}
|
||||
|
||||
.lora-card {
|
||||
@@ -17,13 +20,14 @@
|
||||
border-radius: var(--border-radius-base);
|
||||
backdrop-filter: blur(16px);
|
||||
transition: transform 160ms ease-out;
|
||||
aspect-ratio: 896/1152;
|
||||
max-width: 260px; /* Adjusted from 320px to fit 5 cards */
|
||||
aspect-ratio: 896/1152; /* Preserve aspect ratio */
|
||||
max-width: 260px; /* Base size */
|
||||
width: 100%;
|
||||
margin: 0 auto;
|
||||
cursor: pointer; /* Added from recipe-card */
|
||||
display: flex; /* Added from recipe-card */
|
||||
flex-direction: column; /* Added from recipe-card */
|
||||
overflow: hidden; /* Add overflow hidden to contain children */
|
||||
cursor: pointer;
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
overflow: hidden;
|
||||
}
|
||||
|
||||
.lora-card:hover {
|
||||
@@ -36,6 +40,30 @@
|
||||
outline-offset: 2px;
|
||||
}
|
||||
|
||||
/* Responsive adjustments for 1440p screens (2K) */
|
||||
@media (min-width: 2000px) {
|
||||
.card-grid {
|
||||
max-width: 1800px; /* Increased for 2K screens */
|
||||
grid-template-columns: repeat(auto-fill, minmax(270px, 1fr));
|
||||
}
|
||||
|
||||
.lora-card {
|
||||
max-width: 270px;
|
||||
}
|
||||
}
|
||||
|
||||
/* Responsive adjustments for 4K screens */
|
||||
@media (min-width: 3000px) {
|
||||
.card-grid {
|
||||
max-width: 2400px; /* Increased for 4K screens */
|
||||
grid-template-columns: repeat(auto-fill, minmax(280px, 1fr));
|
||||
}
|
||||
|
||||
.lora-card {
|
||||
max-width: 280px;
|
||||
}
|
||||
}
|
||||
|
||||
/* Responsive adjustments */
|
||||
@media (max-width: 1400px) {
|
||||
.card-grid {
|
||||
@@ -58,6 +86,42 @@
|
||||
min-height: 0; /* Fix for potential flexbox sizing issue in Firefox */
|
||||
}
|
||||
|
||||
/* Smaller text for medium density */
|
||||
.medium-density .model-name {
|
||||
font-size: 0.95em;
|
||||
max-height: 2.6em;
|
||||
}
|
||||
|
||||
.medium-density .base-model-label {
|
||||
font-size: 0.85em;
|
||||
max-width: 120px;
|
||||
}
|
||||
|
||||
.medium-density .card-actions i {
|
||||
font-size: 0.98em;
|
||||
padding: 4px;
|
||||
}
|
||||
|
||||
/* Smaller text for compact mode */
|
||||
.compact-density .model-name {
|
||||
font-size: 0.9em;
|
||||
max-height: 2.4em;
|
||||
}
|
||||
|
||||
.compact-density .base-model-label {
|
||||
font-size: 0.8em;
|
||||
max-width: 110px;
|
||||
}
|
||||
|
||||
.compact-density .card-actions i {
|
||||
font-size: 0.95em;
|
||||
padding: 3px;
|
||||
}
|
||||
|
||||
.compact-density .model-info {
|
||||
padding-bottom: 2px;
|
||||
}
|
||||
|
||||
.card-preview img,
|
||||
.card-preview video {
|
||||
width: 100%;
|
||||
@@ -192,12 +256,43 @@
|
||||
margin-left: var(--space-1);
|
||||
cursor: pointer;
|
||||
color: white;
|
||||
transition: opacity 0.2s;
|
||||
font-size: 0.9em;
|
||||
transition: opacity 0.2s, transform 0.15s ease;
|
||||
font-size: 1.0em; /* Increased from 0.9em for better visibility */
|
||||
width: 16px; /* Fixed width for consistent spacing */
|
||||
height: 16px; /* Fixed height for larger touch target */
|
||||
display: flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
border-radius: 50%;
|
||||
padding: 4px; /* Add padding to increase clickable area */
|
||||
box-sizing: content-box; /* Ensure padding adds to dimensions */
|
||||
position: relative; /* For proper positioning */
|
||||
margin: 0; /* Reset margin */
|
||||
}
|
||||
|
||||
.card-actions i::before {
|
||||
position: absolute; /* Position the icon glyph */
|
||||
top: 50%;
|
||||
left: 50%;
|
||||
transform: translate(-50%, -50%); /* Center the icon */
|
||||
}
|
||||
|
||||
.card-actions {
|
||||
display: flex;
|
||||
gap: var(--space-1); /* Use gap instead of margin for spacing between icons */
|
||||
align-items: center;
|
||||
}
|
||||
|
||||
.card-actions i:hover {
|
||||
opacity: 0.8;
|
||||
opacity: 0.9;
|
||||
transform: scale(1.1);
|
||||
background-color: rgba(255, 255, 255, 0.1);
|
||||
}
|
||||
|
||||
/* Style for active favorites */
|
||||
.favorite-active {
|
||||
color: #ffc107 !important; /* Gold color for favorites */
|
||||
text-shadow: 0 0 5px rgba(255, 193, 7, 0.5);
|
||||
}
|
||||
|
||||
/* 响应式设计 */
|
||||
@@ -282,6 +377,25 @@
|
||||
font-size: 0.85em;
|
||||
}
|
||||
|
||||
/* Prevent text selection on cards and interactive elements */
|
||||
.lora-card,
|
||||
.lora-card *,
|
||||
.card-actions,
|
||||
.card-actions i,
|
||||
.toggle-blur-btn,
|
||||
.show-content-btn,
|
||||
.card-preview img,
|
||||
.card-preview video,
|
||||
.card-footer,
|
||||
.card-header,
|
||||
.model-name,
|
||||
.base-model-label {
|
||||
-webkit-user-select: none;
|
||||
-moz-user-select: none;
|
||||
-ms-user-select: none;
|
||||
user-select: none;
|
||||
}
|
||||
|
||||
/* Recipe specific elements - migrated from recipe-card.css */
|
||||
.recipe-indicator {
|
||||
position: absolute;
|
||||
@@ -331,4 +445,44 @@
|
||||
padding: 2rem;
|
||||
background: var(--lora-surface-alt);
|
||||
border-radius: var(--border-radius-base);
|
||||
}
|
||||
|
||||
/* Virtual scrolling specific styles - updated */
|
||||
.virtual-scroll-item {
|
||||
position: absolute;
|
||||
box-sizing: border-box;
|
||||
transition: transform 160ms ease-out;
|
||||
margin: 0; /* Remove margins, positioning is handled by VirtualScroller */
|
||||
width: 100%; /* Allow width to be set by the VirtualScroller */
|
||||
}
|
||||
|
||||
.virtual-scroll-item:hover {
|
||||
transform: translateY(-2px); /* Keep hover effect */
|
||||
z-index: 1; /* Ensure hovered items appear above others */
|
||||
}
|
||||
|
||||
/* When using virtual scroll, adjust container */
|
||||
.card-grid.virtual-scroll {
|
||||
display: block;
|
||||
position: relative;
|
||||
margin: 0 auto;
|
||||
padding: 4px 0; /* Add top/bottom padding equivalent to card padding */
|
||||
height: auto;
|
||||
width: 100%;
|
||||
max-width: 1400px; /* Keep the max-width from original grid */
|
||||
box-sizing: border-box; /* Include padding in width calculation */
|
||||
overflow-x: hidden; /* Prevent horizontal overflow */
|
||||
}
|
||||
|
||||
/* For larger screens, allow more space for the cards */
|
||||
@media (min-width: 2000px) {
|
||||
.card-grid.virtual-scroll {
|
||||
max-width: 1800px;
|
||||
}
|
||||
}
|
||||
|
||||
@media (min-width: 3000px) {
|
||||
.card-grid.virtual-scroll {
|
||||
max-width: 2400px;
|
||||
}
|
||||
}
|
||||
@@ -190,14 +190,6 @@
|
||||
border-color: var(--lora-border);
|
||||
}
|
||||
|
||||
/* Add disabled button styles */
|
||||
.primary-btn.disabled {
|
||||
background-color: var(--border-color);
|
||||
color: var(--text-color);
|
||||
opacity: 0.7;
|
||||
cursor: not-allowed;
|
||||
}
|
||||
|
||||
/* Enhance the local badge to make it more noticeable */
|
||||
.version-item.exists-locally {
|
||||
background: oklch(var(--lora-accent) / 0.05);
|
||||
|
||||
485
static/css/components/duplicates.css
Normal file
485
static/css/components/duplicates.css
Normal file
@@ -0,0 +1,485 @@
|
||||
/* Duplicates Management Styles */
|
||||
|
||||
/* Duplicates banner */
|
||||
.duplicates-banner {
|
||||
position: sticky; /* Keep the sticky position */
|
||||
top: var(--space-1);
|
||||
width: 100%;
|
||||
background-color: oklch(var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h) / 0.1); /* Use accent color with low opacity */
|
||||
color: var(--text-color);
|
||||
border-top: 1px solid oklch(var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h) / 0.3); /* Add top border with accent color */
|
||||
border-bottom: 1px solid oklch(var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h) / 0.4); /* Make bottom border stronger */
|
||||
z-index: var(--z-overlay);
|
||||
padding: 12px 0;
|
||||
box-shadow: 0 3px 10px rgba(0, 0, 0, 0.2); /* Stronger shadow */
|
||||
transition: all 0.3s ease;
|
||||
margin-bottom: 20px;
|
||||
}
|
||||
|
||||
.duplicates-banner .banner-content {
|
||||
position: relative;
|
||||
max-width: 1400px;
|
||||
margin: 0 auto;
|
||||
display: flex;
|
||||
align-items: center;
|
||||
gap: 12px;
|
||||
padding: 0 16px;
|
||||
}
|
||||
|
||||
/* Responsive container for larger screens - match container in layout.css */
|
||||
@media (min-width: 2000px) {
|
||||
.duplicates-banner .banner-content {
|
||||
max-width: 1800px;
|
||||
}
|
||||
}
|
||||
|
||||
@media (min-width: 3000px) {
|
||||
.duplicates-banner .banner-content {
|
||||
max-width: 2400px;
|
||||
}
|
||||
}
|
||||
|
||||
.duplicates-banner i.fa-exclamation-triangle {
|
||||
font-size: 18px;
|
||||
color: oklch(var(--lora-warning-l) var(--lora-warning-c) var(--lora-warning-h));
|
||||
}
|
||||
|
||||
.duplicates-banner .banner-actions {
|
||||
margin-left: auto;
|
||||
display: flex;
|
||||
gap: 8px;
|
||||
align-items: center;
|
||||
}
|
||||
|
||||
/* Improved exit button in banner */
|
||||
.duplicates-banner button.btn-exit-mode {
|
||||
min-width: 120px;
|
||||
background-color: var(--card-bg);
|
||||
color: var(--text-color);
|
||||
border: 1px solid var(--border-color);
|
||||
padding: 6px 12px;
|
||||
border-radius: var(--border-radius-xs);
|
||||
font-size: 0.85em;
|
||||
cursor: pointer;
|
||||
display: flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
gap: 6px;
|
||||
transition: all 0.2s ease;
|
||||
}
|
||||
|
||||
.duplicates-banner button.btn-exit-mode:hover {
|
||||
background-color: var(--bg-color);
|
||||
border-color: var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h);
|
||||
transform: translateY(-1px);
|
||||
}
|
||||
|
||||
.duplicates-banner button {
|
||||
min-width: 100px;
|
||||
display: flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
gap: 4px;
|
||||
border-radius: var(--border-radius-xs);
|
||||
padding: 4px 10px;
|
||||
border: 1px solid var(--border-color);
|
||||
background: var(--card-bg);
|
||||
color: var(--text-color);
|
||||
font-size: 0.85em;
|
||||
transition: all 0.2s ease;
|
||||
cursor: pointer;
|
||||
box-shadow: 0 1px 2px rgba(0, 0, 0, 0.05);
|
||||
}
|
||||
|
||||
.duplicates-banner button:hover {
|
||||
border-color: var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h);
|
||||
background: var(--bg-color);
|
||||
transform: translateY(-1px);
|
||||
box-shadow: 0 3px 5px rgba(0, 0, 0, 0.08);
|
||||
}
|
||||
|
||||
.duplicates-banner button.btn-exit {
|
||||
min-width: unset;
|
||||
width: 28px;
|
||||
height: 28px;
|
||||
padding: 0;
|
||||
display: flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
border-radius: 50%;
|
||||
}
|
||||
|
||||
.duplicates-banner button.disabled {
|
||||
opacity: 0.5;
|
||||
cursor: not-allowed;
|
||||
}
|
||||
|
||||
/* Duplicate groups */
|
||||
.duplicate-group {
|
||||
position: relative;
|
||||
border: 2px solid oklch(var(--lora-warning-l) var(--lora-warning-c) var(--lora-warning-h));
|
||||
border-radius: var(--border-radius-base);
|
||||
padding: 16px;
|
||||
margin-bottom: 24px;
|
||||
background: var(--card-bg);
|
||||
box-shadow: 0 2px 6px rgba(0, 0, 0, 0.12); /* Add subtle shadow to groups */
|
||||
/* Add responsive width settings to match banner */
|
||||
max-width: 1400px;
|
||||
margin-left: auto;
|
||||
margin-right: auto;
|
||||
}
|
||||
|
||||
/* Add responsive container adjustments for duplicate groups - match container in banner */
|
||||
@media (min-width: 2000px) {
|
||||
.duplicate-group {
|
||||
max-width: 1800px;
|
||||
}
|
||||
}
|
||||
|
||||
@media (min-width: 3000px) {
|
||||
.duplicate-group {
|
||||
max-width: 2400px;
|
||||
}
|
||||
}
|
||||
|
||||
.duplicate-group-header {
|
||||
background-color: var(--bg-color);
|
||||
color: var(--text-color);
|
||||
border: 1px solid var(--border-color);
|
||||
padding: 10px 16px; /* Slightly increased padding */
|
||||
border-radius: var(--border-radius-xs);
|
||||
margin-bottom: 16px;
|
||||
display: flex;
|
||||
justify-content: space-between;
|
||||
align-items: center;
|
||||
border-left: 4px solid oklch(var(--lora-warning-l) var(--lora-warning-c) var(--lora-warning-h)); /* Add accent border on the left */
|
||||
}
|
||||
|
||||
.duplicate-group-header span:last-child {
|
||||
display: flex;
|
||||
gap: 8px;
|
||||
align-items: center;
|
||||
}
|
||||
|
||||
.duplicate-group-header button {
|
||||
min-width: 80px;
|
||||
display: flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
gap: 4px;
|
||||
border-radius: var(--border-radius-xs);
|
||||
padding: 4px 8px;
|
||||
border: 1px solid var(--border-color);
|
||||
background: var(--card-bg);
|
||||
color: var(--text-color);
|
||||
font-size: 0.85em;
|
||||
transition: all 0.2s ease;
|
||||
cursor: pointer;
|
||||
box-shadow: 0 1px 2px rgba(0, 0, 0, 0.05);
|
||||
margin-left: 8px;
|
||||
}
|
||||
|
||||
.duplicate-group-header button:hover {
|
||||
border-color: var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h);
|
||||
background: var(--bg-color);
|
||||
transform: translateY(-1px);
|
||||
box-shadow: 0 3px 5px rgba(0, 0, 0, 0.08);
|
||||
}
|
||||
|
||||
.card-group-container {
|
||||
display: flex;
|
||||
flex-wrap: wrap;
|
||||
gap: 16px;
|
||||
justify-content: flex-start;
|
||||
align-items: flex-start;
|
||||
}
|
||||
|
||||
/* Make cards in duplicate groups have consistent width */
|
||||
.card-group-container .lora-card {
|
||||
flex: 0 0 auto;
|
||||
width: 240px;
|
||||
margin: 0;
|
||||
cursor: pointer; /* Indicate the card is clickable */
|
||||
}
|
||||
|
||||
/* Ensure the grid layout is only applied to the main recipe grid, not duplicate groups */
|
||||
.duplicate-mode .card-grid {
|
||||
display: block;
|
||||
}
|
||||
|
||||
/* Scrollable container for large duplicate groups */
|
||||
.card-group-container.scrollable {
|
||||
max-height: 450px;
|
||||
overflow-y: auto;
|
||||
padding-right: 8px;
|
||||
}
|
||||
|
||||
/* Add a toggle button to expand/collapse large duplicate groups */
|
||||
.group-toggle-btn {
|
||||
position: absolute;
|
||||
right: 16px;
|
||||
bottom: -12px;
|
||||
background: var(--card-bg);
|
||||
color: var(--text-color);
|
||||
border: 1px solid var(--border-color);
|
||||
border-radius: 50%;
|
||||
width: 24px;
|
||||
height: 24px;
|
||||
display: flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
cursor: pointer;
|
||||
z-index: 1;
|
||||
box-shadow: 0 1px 3px rgba(0, 0, 0, 0.1);
|
||||
transition: all 0.2s ease;
|
||||
}
|
||||
|
||||
.group-toggle-btn:hover {
|
||||
border-color: var(--lora-accent-l) var(--lora-accent-c) var (--lora-accent-h);
|
||||
transform: translateY(-1px);
|
||||
box-shadow: 0 3px 5px rgba(0, 0, 0, 0.08);
|
||||
}
|
||||
|
||||
/* Duplicate card styling */
|
||||
.lora-card.duplicate {
|
||||
position: relative;
|
||||
transition: all 0.2s ease;
|
||||
}
|
||||
|
||||
.lora-card.duplicate:hover {
|
||||
border-color: var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h);
|
||||
}
|
||||
|
||||
.lora-card.duplicate.latest {
|
||||
border-style: solid;
|
||||
border-color: oklch(var(--lora-warning-l) var(--lora-warning-c) var(--lora-warning-h));
|
||||
}
|
||||
|
||||
.lora-card.duplicate-selected {
|
||||
border: 2px solid oklch(var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h));
|
||||
box-shadow: 0 0 8px rgba(0, 0, 0, 0.2);
|
||||
}
|
||||
|
||||
.lora-card .selector-checkbox {
|
||||
position: absolute;
|
||||
top: 10px;
|
||||
right: 10px;
|
||||
z-index: 10;
|
||||
width: 20px;
|
||||
height: 20px;
|
||||
cursor: pointer;
|
||||
}
|
||||
|
||||
/* Latest indicator */
|
||||
.lora-card.duplicate.latest::after {
|
||||
content: "Latest";
|
||||
position: absolute;
|
||||
top: 10px;
|
||||
left: 10px;
|
||||
background: oklch(var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h));
|
||||
color: white;
|
||||
font-size: 12px;
|
||||
padding: 2px 6px;
|
||||
border-radius: var(--border-radius-xs);
|
||||
z-index: 5;
|
||||
}
|
||||
|
||||
/* Model tooltip for duplicates mode */
|
||||
.model-tooltip {
|
||||
position: absolute;
|
||||
background-color: var(--card-bg);
|
||||
border: 1px solid var(--border-color);
|
||||
border-radius: var(--border-radius-sm);
|
||||
box-shadow: 0 2px 10px rgba(0,0,0,0.2);
|
||||
padding: 10px;
|
||||
z-index: 1000;
|
||||
max-width: 350px;
|
||||
min-width: 250px;
|
||||
color: var(--text-color);
|
||||
font-size: 0.9em;
|
||||
pointer-events: none; /* Don't block mouse events */
|
||||
}
|
||||
|
||||
.model-tooltip .tooltip-header {
|
||||
font-weight: bold;
|
||||
font-size: 1.1em;
|
||||
margin-bottom: 8px;
|
||||
padding-bottom: 5px;
|
||||
border-bottom: 1px solid var(--border-color);
|
||||
white-space: nowrap;
|
||||
overflow: hidden;
|
||||
text-overflow: ellipsis;
|
||||
}
|
||||
|
||||
.model-tooltip .tooltip-info div {
|
||||
margin-bottom: 4px;
|
||||
display: flex;
|
||||
flex-wrap: wrap;
|
||||
}
|
||||
|
||||
.model-tooltip .tooltip-info div strong {
|
||||
margin-right: 5px;
|
||||
min-width: 70px;
|
||||
}
|
||||
|
||||
/* Badge Styles */
|
||||
.badge {
|
||||
display: inline-flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
min-width: 16px; /* Reduced from 20px */
|
||||
height: 16px; /* Reduced from 20px */
|
||||
border-radius: 8px; /* Adjusted for smaller size */
|
||||
background-color: var(--lora-error);
|
||||
color: white;
|
||||
font-size: 10px; /* Smaller font size */
|
||||
font-weight: bold;
|
||||
padding: 0 4px; /* Reduced padding */
|
||||
position: absolute;
|
||||
top: -8px; /* Moved closer to button */
|
||||
right: -8px; /* Moved closer to button */
|
||||
box-shadow: 0 1px 3px rgba(0, 0, 0, 0.15); /* Softer shadow */
|
||||
transition: transform 0.2s ease, opacity 0.2s ease;
|
||||
}
|
||||
|
||||
.badge:empty {
|
||||
display: none;
|
||||
}
|
||||
|
||||
/* Make the pulse animation more subtle */
|
||||
.badge.pulse {
|
||||
animation: badge-pulse 2s infinite; /* Slower animation */
|
||||
}
|
||||
|
||||
@keyframes badge-pulse {
|
||||
0% {
|
||||
transform: scale(1);
|
||||
}
|
||||
50% {
|
||||
transform: scale(1.1); /* Less expansion */
|
||||
}
|
||||
100% {
|
||||
transform: scale(1);
|
||||
}
|
||||
}
|
||||
|
||||
/* Help icon styling */
|
||||
.help-icon {
|
||||
color: var(--text-color);
|
||||
opacity: 0.7;
|
||||
cursor: help;
|
||||
font-size: 16px;
|
||||
margin-left: 8px;
|
||||
transition: all 0.2s ease;
|
||||
}
|
||||
|
||||
.help-icon:hover {
|
||||
opacity: 1;
|
||||
color: oklch(var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h));
|
||||
}
|
||||
|
||||
/* Help tooltip */
|
||||
.help-tooltip {
|
||||
display: none;
|
||||
position: absolute;
|
||||
max-width: 400px;
|
||||
background: var(--card-bg);
|
||||
color: var(--text-color);
|
||||
border: 1px solid var(--border-color);
|
||||
border-radius: var(--border-radius-sm);
|
||||
padding: 12px 16px;
|
||||
box-shadow: 0 4px 12px rgba(0, 0, 0, 0.15);
|
||||
z-index: var(--z-overlay);
|
||||
font-size: 0.9em;
|
||||
margin-top: 10px;
|
||||
text-align: left;
|
||||
pointer-events: none;
|
||||
}
|
||||
|
||||
.help-tooltip:after {
|
||||
content: "";
|
||||
position: absolute;
|
||||
top: -8px;
|
||||
left: 10px; /* Position the arrow near the left instead of center */
|
||||
border-width: 0 8px 8px 8px;
|
||||
border-style: solid;
|
||||
border-color: transparent transparent var(--card-bg) transparent;
|
||||
}
|
||||
|
||||
/* Responsive adjustments */
|
||||
@media (max-width: 768px) {
|
||||
.duplicates-banner .banner-content {
|
||||
flex-direction: column;
|
||||
align-items: flex-start;
|
||||
gap: 8px;
|
||||
}
|
||||
|
||||
.duplicates-banner .banner-actions {
|
||||
width: 100%;
|
||||
margin-left: 0;
|
||||
justify-content: space-between;
|
||||
}
|
||||
|
||||
.duplicate-group-header {
|
||||
flex-direction: column;
|
||||
gap: 8px;
|
||||
align-items: flex-start;
|
||||
}
|
||||
|
||||
.duplicate-group-header span:last-child {
|
||||
display: flex;
|
||||
gap: 8px;
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
.duplicate-group-header button {
|
||||
margin-left: 0;
|
||||
flex: 1;
|
||||
}
|
||||
|
||||
.help-tooltip {
|
||||
max-width: calc(100% - 40px);
|
||||
}
|
||||
|
||||
/* Remove the fixed positioning adjustments for mobile since we're now using dynamic positioning */
|
||||
.help-tooltip:after {
|
||||
left: 10px;
|
||||
}
|
||||
}
|
||||
|
||||
/* In dark mode, add additional distinction */
|
||||
html[data-theme="dark"] .duplicates-banner {
|
||||
box-shadow: 0 3px 12px rgba(0, 0, 0, 0.4); /* Stronger shadow in dark mode */
|
||||
background-color: oklch(var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h) / 0.15); /* Slightly stronger background in dark mode */
|
||||
}
|
||||
|
||||
html[data-theme="dark"] .duplicate-group {
|
||||
box-shadow: 0 2px 8px rgba(0, 0, 0, 0.25); /* Stronger shadow in dark mode */
|
||||
}
|
||||
|
||||
html[data-theme="dark"] .help-tooltip {
|
||||
box-shadow: 0 4px 12px rgba(0, 0, 0, 0.3);
|
||||
}
|
||||
|
||||
/* Styles for disabled controls during duplicates mode */
|
||||
.disabled-during-duplicates {
|
||||
opacity: 0.5 !important;
|
||||
pointer-events: none !important;
|
||||
cursor: not-allowed !important;
|
||||
user-select: none !important;
|
||||
filter: grayscale(50%) !important;
|
||||
}
|
||||
|
||||
/* Make the active duplicates button more prominent */
|
||||
#findDuplicatesBtn.active {
|
||||
background: var(--lora-accent);
|
||||
color: white;
|
||||
border-color: var(--lora-accent);
|
||||
box-shadow: 0 0 0 2px oklch(var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h) / 0.25);
|
||||
position: relative;
|
||||
z-index: 5;
|
||||
}
|
||||
|
||||
#findDuplicatesBtn.active:hover {
|
||||
background: oklch(calc(var(--lora-accent-l) - 5%) var(--lora-accent-c) var(--lora-accent-h));
|
||||
}
|
||||
@@ -136,6 +136,30 @@
|
||||
opacity: 0;
|
||||
}
|
||||
|
||||
/* Badge styling */
|
||||
.update-badge {
|
||||
position: absolute;
|
||||
top: -3px;
|
||||
right: -3px;
|
||||
width: 8px;
|
||||
height: 8px;
|
||||
background-color: var(--lora-error);
|
||||
border-radius: 50%;
|
||||
border: 2px solid var(--card-bg);
|
||||
transition: all 0.2s ease;
|
||||
pointer-events: none;
|
||||
opacity: 0;
|
||||
}
|
||||
|
||||
.update-badge.visible {
|
||||
opacity: 1;
|
||||
}
|
||||
|
||||
.update-badge.hidden,
|
||||
.update-badge:not(.visible) {
|
||||
opacity: 0;
|
||||
}
|
||||
|
||||
/* Mobile adjustments */
|
||||
@media (max-width: 768px) {
|
||||
.app-title {
|
||||
|
||||
@@ -291,7 +291,7 @@
|
||||
gap: 8px;
|
||||
padding: var(--space-1);
|
||||
border: 1px solid var(--border-color);
|
||||
border-radius: var(--border-radius-sm);
|
||||
border-radius: var (--border-radius-sm);
|
||||
background: var(--lora-surface);
|
||||
}
|
||||
|
||||
@@ -733,3 +733,150 @@
|
||||
font-size: 0.9em;
|
||||
line-height: 1.4;
|
||||
}
|
||||
|
||||
/* Duplicate Recipes Styles */
|
||||
.duplicate-recipes-container {
|
||||
margin-bottom: var(--space-3);
|
||||
border-radius: var(--border-radius-sm);
|
||||
overflow: hidden;
|
||||
animation: fadeIn 0.3s ease-in-out;
|
||||
}
|
||||
|
||||
@keyframes fadeIn {
|
||||
from { opacity: 0; transform: translateY(-10px); }
|
||||
to { opacity: 1; transform: translateY(0); }
|
||||
}
|
||||
|
||||
.duplicate-warning {
|
||||
display: flex;
|
||||
align-items: flex-start;
|
||||
gap: 12px;
|
||||
padding: 12px 16px;
|
||||
background: oklch(var(--lora-warning) / 0.1);
|
||||
border: 1px solid var(--lora-warning);
|
||||
border-radius: var(--border-radius-sm) var(--border-radius-sm) 0 0;
|
||||
color: var(--text-color);
|
||||
}
|
||||
|
||||
.duplicate-warning .warning-icon {
|
||||
color: var(--lora-warning);
|
||||
font-size: 1.2em;
|
||||
padding-top: 2px;
|
||||
}
|
||||
|
||||
.duplicate-warning .warning-content {
|
||||
flex: 1;
|
||||
}
|
||||
|
||||
.duplicate-warning .warning-title {
|
||||
font-weight: 600;
|
||||
margin-bottom: 4px;
|
||||
}
|
||||
|
||||
.duplicate-warning .warning-text {
|
||||
font-size: 0.9em;
|
||||
line-height: 1.4;
|
||||
display: flex;
|
||||
justify-content: space-between;
|
||||
align-items: center;
|
||||
flex-wrap: wrap;
|
||||
gap: 8px;
|
||||
}
|
||||
|
||||
.toggle-duplicates-btn {
|
||||
background: none;
|
||||
border: none;
|
||||
color: var(--lora-warning);
|
||||
cursor: pointer;
|
||||
font-size: 0.9em;
|
||||
display: flex;
|
||||
align-items: center;
|
||||
gap: 6px;
|
||||
padding: 4px 8px;
|
||||
border-radius: var(--border-radius-xs);
|
||||
}
|
||||
|
||||
.toggle-duplicates-btn:hover {
|
||||
background: oklch(var(--lora-warning) / 0.1);
|
||||
}
|
||||
|
||||
.duplicate-recipes-list {
|
||||
display: grid;
|
||||
grid-template-columns: repeat(auto-fill, minmax(150px, 1fr));
|
||||
gap: 12px;
|
||||
padding: 16px;
|
||||
border: 1px solid var(--border-color);
|
||||
border-top: none;
|
||||
border-radius: 0 0 var(--border-radius-sm) var(--border-radius-sm);
|
||||
background: var(--bg-color);
|
||||
max-height: 300px;
|
||||
overflow-y: auto;
|
||||
transition: max-height 0.3s ease, padding 0.3s ease;
|
||||
}
|
||||
|
||||
.duplicate-recipes-list.collapsed {
|
||||
max-height: 0;
|
||||
padding: 0 16px;
|
||||
overflow: hidden;
|
||||
}
|
||||
|
||||
.duplicate-recipe-card {
|
||||
position: relative;
|
||||
border-radius: var(--border-radius-sm);
|
||||
overflow: hidden;
|
||||
box-shadow: 0 2px 4px rgba(0, 0, 0, 0.1);
|
||||
transition: transform 0.2s ease;
|
||||
}
|
||||
|
||||
.duplicate-recipe-card:hover {
|
||||
transform: translateY(-2px);
|
||||
}
|
||||
|
||||
.duplicate-recipe-preview {
|
||||
width: 100%;
|
||||
position: relative;
|
||||
aspect-ratio: 2/3;
|
||||
background: var(--bg-color);
|
||||
}
|
||||
|
||||
.duplicate-recipe-preview img {
|
||||
width: 100%;
|
||||
height: 100%;
|
||||
object-fit: cover;
|
||||
}
|
||||
|
||||
.duplicate-recipe-title {
|
||||
position: absolute;
|
||||
bottom: 0;
|
||||
left: 0;
|
||||
right: 0;
|
||||
padding: 8px;
|
||||
background: rgba(0, 0, 0, 0.7);
|
||||
color: white;
|
||||
font-size: 0.85em;
|
||||
line-height: 1.3;
|
||||
max-height: 50%;
|
||||
overflow: hidden;
|
||||
text-overflow: ellipsis;
|
||||
display: -webkit-box;
|
||||
-webkit-line-clamp: 2;
|
||||
-webkit-box-orient: vertical;
|
||||
}
|
||||
|
||||
.duplicate-recipe-details {
|
||||
padding: 8px;
|
||||
background: var(--bg-color);
|
||||
font-size: 0.75em;
|
||||
display: flex;
|
||||
justify-content: space-between;
|
||||
align-items: center;
|
||||
color: var(--text-color);
|
||||
opacity: 0.8;
|
||||
}
|
||||
|
||||
.duplicate-recipe-date,
|
||||
.duplicate-recipe-lora-count {
|
||||
display: flex;
|
||||
align-items: center;
|
||||
gap: 4px;
|
||||
}
|
||||
|
||||
96
static/css/components/keyboard-nav.css
Normal file
96
static/css/components/keyboard-nav.css
Normal file
@@ -0,0 +1,96 @@
|
||||
/* Keyboard navigation indicator and help */
|
||||
.keyboard-nav-hint {
|
||||
display: inline-flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
position: relative;
|
||||
width: 32px;
|
||||
height: 32px;
|
||||
border-radius: 50%;
|
||||
background: var(--card-bg);
|
||||
border: 1px solid var(--border-color);
|
||||
color: var(--text-color);
|
||||
cursor: help;
|
||||
transition: all 0.2s ease;
|
||||
margin-left: 8px;
|
||||
}
|
||||
|
||||
.keyboard-nav-hint:hover {
|
||||
background: var(--lora-accent);
|
||||
color: white;
|
||||
transform: translateY(-2px);
|
||||
box-shadow: 0 3px 5px rgba(0, 0, 0, 0.08);
|
||||
}
|
||||
|
||||
.keyboard-nav-hint i {
|
||||
font-size: 14px;
|
||||
}
|
||||
|
||||
/* Tooltip styling */
|
||||
.tooltip {
|
||||
position: relative;
|
||||
}
|
||||
|
||||
.tooltip .tooltiptext {
|
||||
visibility: hidden;
|
||||
width: 240px;
|
||||
background-color: var(--lora-surface);
|
||||
color: var(--text-color);
|
||||
text-align: center;
|
||||
border-radius: var(--border-radius-xs);
|
||||
padding: 8px;
|
||||
position: absolute;
|
||||
z-index: 9999; /* 确保在卡片上方显示 */
|
||||
left: 120%; /* 将tooltip显示在图标右侧 */
|
||||
top: 50%; /* 垂直居中 */
|
||||
transform: translateY(-50%); /* 垂直居中 */
|
||||
opacity: 0;
|
||||
transition: opacity 0.3s;
|
||||
box-shadow: 0 3px 8px rgba(0, 0, 0, 0.15);
|
||||
border: 1px solid var(--lora-border);
|
||||
font-size: 0.85em;
|
||||
line-height: 1.4;
|
||||
}
|
||||
|
||||
.tooltip .tooltiptext::after {
|
||||
content: "";
|
||||
position: absolute;
|
||||
top: 50%; /* 箭头垂直居中 */
|
||||
right: 100%; /* 箭头在左侧 */
|
||||
margin-top: -5px;
|
||||
border-width: 5px;
|
||||
border-style: solid;
|
||||
border-color: transparent var(--lora-border) transparent transparent; /* 箭头指向左侧 */
|
||||
}
|
||||
|
||||
.tooltip:hover .tooltiptext {
|
||||
visibility: visible;
|
||||
opacity: 1;
|
||||
}
|
||||
|
||||
/* Keyboard shortcuts table */
|
||||
.keyboard-shortcuts {
|
||||
width: 100%;
|
||||
border-collapse: collapse;
|
||||
margin-top: 5px;
|
||||
}
|
||||
|
||||
.keyboard-shortcuts td {
|
||||
padding: 4px;
|
||||
text-align: left;
|
||||
}
|
||||
|
||||
.keyboard-shortcuts td:first-child {
|
||||
font-weight: bold;
|
||||
width: 40%;
|
||||
}
|
||||
|
||||
.key {
|
||||
display: inline-block;
|
||||
background: var(--bg-color);
|
||||
border: 1px solid var(--border-color);
|
||||
border-radius: 3px;
|
||||
padding: 1px 5px;
|
||||
font-size: 0.8em;
|
||||
box-shadow: 0 1px 2px rgba(0, 0, 0, 0.08);
|
||||
}
|
||||
@@ -132,7 +132,7 @@
|
||||
}
|
||||
|
||||
.scroll-indicator:hover {
|
||||
background: oklch(var(--lora-accent) / 0.1);
|
||||
background: oklch(var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h) / 0.1);
|
||||
transform: translateY(-1px);
|
||||
}
|
||||
|
||||
@@ -241,7 +241,7 @@
|
||||
|
||||
/* Keep the hover effect using accent color */
|
||||
.trigger-word-tag:hover {
|
||||
background: oklch(var(--lora-accent) / 0.1);
|
||||
background: oklch(var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h) / 0.1);
|
||||
border-color: var(--lora-accent);
|
||||
}
|
||||
|
||||
@@ -301,7 +301,7 @@
|
||||
}
|
||||
|
||||
.trigger-words-edit-controls button:hover {
|
||||
background: oklch(var(--lora-accent) / 0.1);
|
||||
background: oklch(var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h) / 0.1);
|
||||
border-color: var(--lora-accent);
|
||||
}
|
||||
|
||||
@@ -324,6 +324,7 @@
|
||||
margin-top: var(--space-2);
|
||||
display: flex;
|
||||
gap: var(--space-1);
|
||||
position: relative; /* Added for dropdown positioning */
|
||||
}
|
||||
|
||||
.new-trigger-word-input {
|
||||
@@ -346,7 +347,7 @@
|
||||
padding: 4px 8px;
|
||||
border-radius: var(--border-radius-xs);
|
||||
border: 1px solid var(--border-color);
|
||||
background: var(--bg-color);
|
||||
background: var (--bg-color);
|
||||
color: var(--text-color);
|
||||
font-size: 0.85em;
|
||||
cursor: pointer;
|
||||
@@ -371,6 +372,146 @@
|
||||
background: rgba(255, 255, 255, 0.05);
|
||||
}
|
||||
|
||||
/* Trained Words Loading Indicator */
|
||||
.trained-words-loading {
|
||||
display: flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
margin: var(--space-1) 0;
|
||||
color: var(--text-color);
|
||||
opacity: 0.7;
|
||||
font-size: 0.9em;
|
||||
gap: 8px;
|
||||
}
|
||||
|
||||
.trained-words-loading i {
|
||||
color: var(--lora-accent);
|
||||
}
|
||||
|
||||
/* Trained Words Dropdown Styles */
|
||||
.trained-words-dropdown {
|
||||
position: absolute;
|
||||
top: 100%;
|
||||
left: 0;
|
||||
right: 0;
|
||||
background: var(--bg-color);
|
||||
border: 1px solid var(--border-color);
|
||||
border-radius: var(--border-radius-sm);
|
||||
margin-top: 4px;
|
||||
z-index: 100;
|
||||
box-shadow: 0 4px 12px rgba(0, 0, 0, 0.15);
|
||||
overflow: hidden;
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
}
|
||||
|
||||
.trained-words-header {
|
||||
display: flex;
|
||||
justify-content: space-between;
|
||||
align-items: center;
|
||||
padding: 8px 12px;
|
||||
background: var(--card-bg);
|
||||
border-bottom: 1px solid var(--border-color);
|
||||
}
|
||||
|
||||
.trained-words-header span {
|
||||
font-size: 0.9em;
|
||||
font-weight: 500;
|
||||
color: var(--text-color);
|
||||
}
|
||||
|
||||
.trained-words-header small {
|
||||
font-size: 0.8em;
|
||||
opacity: 0.7;
|
||||
}
|
||||
|
||||
.trained-words-container {
|
||||
max-height: 200px;
|
||||
overflow-y: auto;
|
||||
padding: 10px;
|
||||
display: flex;
|
||||
flex-wrap: wrap;
|
||||
gap: 8px;
|
||||
align-content: flex-start;
|
||||
}
|
||||
|
||||
.trained-word-item {
|
||||
display: inline-flex;
|
||||
align-items: center;
|
||||
justify-content: space-between;
|
||||
padding: 5px 10px;
|
||||
cursor: pointer;
|
||||
transition: all 0.2s ease;
|
||||
border-radius: var(--border-radius-xs);
|
||||
background: var(--lora-surface);
|
||||
border: 1px solid var(--lora-border);
|
||||
max-width: 150px;
|
||||
}
|
||||
|
||||
.trained-word-item:hover {
|
||||
background: oklch(var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h) / 0.1);
|
||||
border-color: var(--lora-accent);
|
||||
}
|
||||
|
||||
.trained-word-item.already-added {
|
||||
opacity: 0.7;
|
||||
cursor: default;
|
||||
}
|
||||
|
||||
.trained-word-item.already-added:hover {
|
||||
background: var(--lora-surface);
|
||||
border-color: var(--lora-border);
|
||||
}
|
||||
|
||||
.trained-word-text {
|
||||
color: var(--lora-accent);
|
||||
font-size: 0.9em;
|
||||
white-space: nowrap;
|
||||
overflow: hidden;
|
||||
text-overflow: ellipsis;
|
||||
margin-right: 4px;
|
||||
max-width: 100px;
|
||||
}
|
||||
|
||||
.trained-word-meta {
|
||||
display: flex;
|
||||
align-items: center;
|
||||
gap: 4px;
|
||||
flex-shrink: 0;
|
||||
}
|
||||
|
||||
.trained-word-freq {
|
||||
color: var (--text-color);
|
||||
font-size: 0.75em;
|
||||
background: rgba(0, 0, 0, 0.05);
|
||||
border-radius: 10px;
|
||||
min-width: 20px;
|
||||
padding: 1px 5px;
|
||||
text-align: center;
|
||||
line-height: 1.2;
|
||||
}
|
||||
|
||||
[data-theme="dark"] .trained-word-freq {
|
||||
background: rgba(255, 255, 255, 0.05);
|
||||
}
|
||||
|
||||
.added-indicator {
|
||||
color: var(--lora-accent);
|
||||
display: flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
font-size: 0.75em;
|
||||
}
|
||||
|
||||
.no-trained-words {
|
||||
padding: 16px 12px;
|
||||
text-align: center;
|
||||
color: var(--text-color);
|
||||
opacity: 0.7;
|
||||
font-style: italic;
|
||||
font-size: 0.9em;
|
||||
}
|
||||
|
||||
/* Editable Fields */
|
||||
.editable-field {
|
||||
position: relative;
|
||||
@@ -515,7 +656,7 @@
|
||||
}
|
||||
|
||||
.preset-tag:hover {
|
||||
background: oklch(var(--lora-accent) / 0.1);
|
||||
background: oklch(var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h) / 0.1);
|
||||
border-color: var(--lora-accent);
|
||||
}
|
||||
|
||||
@@ -549,10 +690,6 @@
|
||||
position: relative;
|
||||
}
|
||||
|
||||
.file-name-wrapper:hover {
|
||||
background: oklch(var(--lora-accent) / 0.1);
|
||||
}
|
||||
|
||||
.file-name-content {
|
||||
padding: 2px 4px;
|
||||
border-radius: var(--border-radius-xs);
|
||||
@@ -673,11 +810,6 @@
|
||||
opacity: 0.9;
|
||||
}
|
||||
|
||||
/* Model name field styles - complete replacement */
|
||||
.model-name-field {
|
||||
display: none;
|
||||
}
|
||||
|
||||
/* New Model Name Header Styles */
|
||||
.model-name-header {
|
||||
display: flex;
|
||||
@@ -754,7 +886,7 @@
|
||||
|
||||
.tab-btn:hover {
|
||||
opacity: 1;
|
||||
background: oklch(var(--lora-accent) / 0.05);
|
||||
background: oklch(var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h) / 0.05);
|
||||
}
|
||||
|
||||
.tab-btn.active {
|
||||
@@ -936,7 +1068,7 @@
|
||||
.model-description-content pre {
|
||||
background: rgba(0, 0, 0, 0.05);
|
||||
border-radius: var(--border-radius-xs);
|
||||
padding: var(--space-1);
|
||||
padding: var (--space-1);
|
||||
white-space: pre-wrap;
|
||||
margin: 1em 0;
|
||||
overflow-x: auto;
|
||||
@@ -1133,8 +1265,8 @@
|
||||
pointer-events: none;
|
||||
}
|
||||
|
||||
/* Show metadata panel only on hover */
|
||||
.media-wrapper:hover .image-metadata-panel {
|
||||
/* Show metadata panel only when the 'visible' class is added */
|
||||
.media-wrapper .image-metadata-panel.visible {
|
||||
transform: translateY(0);
|
||||
opacity: 0.98;
|
||||
pointer-events: auto;
|
||||
@@ -1323,4 +1455,89 @@
|
||||
|
||||
.recipes-error i {
|
||||
color: var(--lora-error);
|
||||
}
|
||||
|
||||
/* Creator Information Styles */
|
||||
.creator-info {
|
||||
display: flex;
|
||||
align-items: center;
|
||||
gap: 10px;
|
||||
margin-bottom: var(--space-1);
|
||||
padding: 6px 10px;
|
||||
background: rgba(0, 0, 0, 0.03);
|
||||
border: 1px solid rgba(0, 0, 0, 0.1);
|
||||
border-radius: var(--border-radius-sm);
|
||||
max-width: fit-content;
|
||||
}
|
||||
|
||||
[data-theme="dark"] .creator-info {
|
||||
background: rgba(255, 255, 255, 0.03);
|
||||
border: 1px solid var(--lora-border);
|
||||
}
|
||||
|
||||
.creator-avatar {
|
||||
width: 28px;
|
||||
height: 28px;
|
||||
border-radius: 50%;
|
||||
overflow: hidden;
|
||||
flex-shrink: 0;
|
||||
display: flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
background: var(--lora-surface);
|
||||
border: 1px solid var(--lora-border);
|
||||
}
|
||||
|
||||
.creator-avatar img {
|
||||
width: 100%;
|
||||
height: 100%;
|
||||
object-fit: cover;
|
||||
}
|
||||
|
||||
.creator-placeholder {
|
||||
background: var(--lora-accent);
|
||||
color: white;
|
||||
display: flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
}
|
||||
|
||||
.creator-username {
|
||||
font-size: 0.9em;
|
||||
font-weight: 500;
|
||||
color: var(--text-color);
|
||||
}
|
||||
|
||||
/* Optional: add hover effect for creator info */
|
||||
.creator-info:hover {
|
||||
background: oklch(var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h) / 0.1);
|
||||
border-color: var(--lora-accent);
|
||||
}
|
||||
|
||||
/* Class tokens styling */
|
||||
.class-tokens-container {
|
||||
padding: 10px;
|
||||
display: flex;
|
||||
flex-wrap: wrap;
|
||||
gap: 8px;
|
||||
}
|
||||
|
||||
.class-token-item {
|
||||
background: oklch(var(--lora-accent-l) var(--lora-accent-c) var(--lora-accent-h) / 0.1) !important;
|
||||
border: 1px solid var(--lora-accent) !important;
|
||||
}
|
||||
|
||||
.token-badge {
|
||||
background: var(--lora-accent);
|
||||
color: white;
|
||||
font-size: 0.7em;
|
||||
padding: 2px 5px;
|
||||
border-radius: 8px;
|
||||
white-space: nowrap;
|
||||
}
|
||||
|
||||
.dropdown-separator {
|
||||
height: 1px;
|
||||
background: var(--lora-border);
|
||||
margin: 5px 10px;
|
||||
}
|
||||
@@ -39,4 +39,81 @@
|
||||
.context-menu-item i {
|
||||
width: 16px;
|
||||
text-align: center;
|
||||
}
|
||||
|
||||
/* NSFW Level Selector */
|
||||
.nsfw-level-selector {
|
||||
position: fixed;
|
||||
top: 50%;
|
||||
left: 50%;
|
||||
transform: translate(-50%, -50%);
|
||||
background: var(--card-bg);
|
||||
border: 1px solid var(--border-color);
|
||||
border-radius: var(--border-radius-base);
|
||||
padding: 16px;
|
||||
box-shadow: 0 4px 20px rgba(0, 0, 0, 0.2);
|
||||
z-index: var(--z-modal);
|
||||
width: 300px;
|
||||
display: none;
|
||||
}
|
||||
|
||||
.nsfw-level-header {
|
||||
display: flex;
|
||||
justify-content: space-between;
|
||||
align-items: center;
|
||||
margin-bottom: 16px;
|
||||
}
|
||||
|
||||
.nsfw-level-header h3 {
|
||||
margin: 0;
|
||||
font-size: 16px;
|
||||
font-weight: 500;
|
||||
}
|
||||
|
||||
.close-nsfw-selector {
|
||||
background: transparent;
|
||||
border: none;
|
||||
color: var(--text-color);
|
||||
cursor: pointer;
|
||||
padding: 4px;
|
||||
border-radius: var(--border-radius-xs);
|
||||
}
|
||||
|
||||
.close-nsfw-selector:hover {
|
||||
background: var(--border-color);
|
||||
}
|
||||
|
||||
.current-level {
|
||||
margin-bottom: 12px;
|
||||
padding: 8px;
|
||||
background: var(--bg-color);
|
||||
border-radius: var(--border-radius-xs);
|
||||
border: 1px solid var(--border-color);
|
||||
}
|
||||
|
||||
.nsfw-level-options {
|
||||
display: flex;
|
||||
flex-wrap: wrap;
|
||||
gap: 8px;
|
||||
}
|
||||
|
||||
.nsfw-level-btn {
|
||||
flex: 1 0 calc(33% - 8px);
|
||||
padding: 8px;
|
||||
border-radius: var(--border-radius-xs);
|
||||
background: var(--bg-color);
|
||||
border: 1px solid var(--border-color);
|
||||
color: var(--text-color);
|
||||
cursor: pointer;
|
||||
transition: all 0.2s ease;
|
||||
}
|
||||
|
||||
.nsfw-level-btn:hover {
|
||||
background: var(--lora-border);
|
||||
}
|
||||
|
||||
.nsfw-level-btn.active {
|
||||
background: var(--lora-accent);
|
||||
color: white;
|
||||
border-color: var(--lora-accent);
|
||||
}
|
||||
@@ -44,26 +44,12 @@ body.modal-open {
|
||||
}
|
||||
|
||||
/* Delete Modal specific styles */
|
||||
.delete-modal-content {
|
||||
max-width: 500px;
|
||||
text-align: center;
|
||||
}
|
||||
|
||||
.delete-message {
|
||||
color: var(--text-color);
|
||||
margin: var(--space-2) 0;
|
||||
}
|
||||
|
||||
.delete-model-info {
|
||||
background: var(--lora-surface);
|
||||
border: 1px solid var(--lora-border);
|
||||
border-radius: var(--border-radius-sm);
|
||||
padding: var(--space-2);
|
||||
margin: var(--space-2) 0;
|
||||
color: var(--text-color);
|
||||
word-break: break-all;
|
||||
}
|
||||
|
||||
/* Update delete modal styles */
|
||||
.delete-modal {
|
||||
display: none; /* Set initial display to none */
|
||||
@@ -92,7 +78,8 @@ body.modal-open {
|
||||
animation: modalFadeIn 0.2s ease-out;
|
||||
}
|
||||
|
||||
.delete-model-info {
|
||||
.delete-model-info,
|
||||
.exclude-model-info {
|
||||
/* Update info display styling */
|
||||
background: var(--lora-surface);
|
||||
border: 1px solid var(--lora-border);
|
||||
@@ -123,7 +110,7 @@ body.modal-open {
|
||||
margin-top: var(--space-3);
|
||||
}
|
||||
|
||||
.cancel-btn, .delete-btn {
|
||||
.cancel-btn, .delete-btn, .exclude-btn, .confirm-btn {
|
||||
padding: 8px var(--space-2);
|
||||
border-radius: 6px;
|
||||
border: none;
|
||||
@@ -143,6 +130,12 @@ body.modal-open {
|
||||
color: white;
|
||||
}
|
||||
|
||||
/* Style for exclude button - different from delete button */
|
||||
.exclude-btn, .confirm-btn {
|
||||
background: var(--lora-accent, #4f46e5);
|
||||
color: white;
|
||||
}
|
||||
|
||||
.cancel-btn:hover {
|
||||
background: var(--lora-border);
|
||||
}
|
||||
@@ -151,9 +144,14 @@ body.modal-open {
|
||||
opacity: 0.9;
|
||||
}
|
||||
|
||||
.exclude-btn:hover, .confirm-btn:hover {
|
||||
opacity: 0.9;
|
||||
background: oklch(from var(--lora-accent, #4f46e5) l c h / 85%);
|
||||
}
|
||||
|
||||
.modal-content h2 {
|
||||
color: var(--text-color);
|
||||
margin-bottom: var(--space-2);
|
||||
margin-bottom: var(--space-1);
|
||||
font-size: 1.5em;
|
||||
}
|
||||
|
||||
@@ -308,6 +306,18 @@ body.modal-open {
|
||||
width: 100%; /* Full width */
|
||||
}
|
||||
|
||||
/* Migrate control styling */
|
||||
.migrate-control {
|
||||
display: flex;
|
||||
align-items: center;
|
||||
gap: 8px;
|
||||
}
|
||||
|
||||
.migrate-control input {
|
||||
flex: 1;
|
||||
min-width: 0;
|
||||
}
|
||||
|
||||
/* 统一各个 section 的样式 */
|
||||
.support-section,
|
||||
.changelog-section,
|
||||
@@ -365,6 +375,12 @@ body.modal-open {
|
||||
background: rgba(255, 255, 255, 0.05);
|
||||
}
|
||||
|
||||
/* Add disabled style for setting items */
|
||||
.setting-item[data-requires-centralized="true"].disabled {
|
||||
opacity: 0.6;
|
||||
pointer-events: none;
|
||||
}
|
||||
|
||||
/* Control row with label and input together */
|
||||
.setting-row {
|
||||
display: flex;
|
||||
@@ -496,6 +512,114 @@ input:checked + .toggle-slider:before {
|
||||
filter: blur(8px);
|
||||
}
|
||||
|
||||
/* Example Images Settings Styles */
|
||||
.download-buttons {
|
||||
justify-content: flex-start;
|
||||
gap: var(--space-2);
|
||||
}
|
||||
|
||||
.primary-btn {
|
||||
display: flex;
|
||||
align-items: center;
|
||||
gap: 8px;
|
||||
padding: 8px 16px;
|
||||
background-color: var(--lora-accent);
|
||||
color: var(--lora-text);
|
||||
border: none;
|
||||
border-radius: var(--border-radius-sm);
|
||||
cursor: pointer;
|
||||
transition: background-color 0.2s;
|
||||
font-size: 0.95em;
|
||||
}
|
||||
|
||||
.primary-btn:hover {
|
||||
background-color: oklch(from var(--lora-accent) l c h / 85%);
|
||||
color: var(--lora-text);
|
||||
}
|
||||
|
||||
/* Secondary button styles */
|
||||
.secondary-btn {
|
||||
display: flex;
|
||||
align-items: center;
|
||||
gap: 8px;
|
||||
padding: 8px 16px;
|
||||
background-color: var(--card-bg);
|
||||
color: var (--text-color);
|
||||
border: 1px solid var(--border-color);
|
||||
border-radius: var(--border-radius-sm);
|
||||
cursor: pointer;
|
||||
transition: all 0.2s;
|
||||
font-size: 0.95em;
|
||||
}
|
||||
|
||||
.secondary-btn:hover {
|
||||
background-color: var(--border-color);
|
||||
color: var(--text-color);
|
||||
}
|
||||
|
||||
/* Disabled button styles */
|
||||
.primary-btn.disabled {
|
||||
opacity: 0.5;
|
||||
cursor: not-allowed;
|
||||
background-color: var(--lora-accent);
|
||||
color: var(--lora-text);
|
||||
pointer-events: none;
|
||||
}
|
||||
|
||||
.secondary-btn.disabled {
|
||||
opacity: 0.5;
|
||||
cursor: not-allowed;
|
||||
pointer-events: none;
|
||||
}
|
||||
|
||||
.restart-required-icon {
|
||||
color: var(--lora-warning);
|
||||
margin-left: 5px;
|
||||
font-size: 0.85em;
|
||||
vertical-align: text-bottom;
|
||||
}
|
||||
|
||||
/* Dark theme specific button adjustments */
|
||||
[data-theme="dark"] .primary-btn:hover {
|
||||
background-color: oklch(from var(--lora-accent) l c h / 75%);
|
||||
}
|
||||
|
||||
[data-theme="dark"] .secondary-btn {
|
||||
background-color: var(--lora-surface);
|
||||
}
|
||||
|
||||
[data-theme="dark"] .secondary-btn:hover {
|
||||
background-color: oklch(35% 0.02 256 / 0.98);
|
||||
}
|
||||
|
||||
.primary-btn.disabled {
|
||||
opacity: 0.5;
|
||||
cursor: not-allowed;
|
||||
}
|
||||
|
||||
.path-control {
|
||||
display: flex;
|
||||
gap: 8px;
|
||||
align-items: center;
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
.path-control input[type="text"] {
|
||||
flex: 1;
|
||||
padding: 6px 10px;
|
||||
border-radius: var(--border-radius-xs);
|
||||
border: 1px solid var(--border-color);
|
||||
background-color: var(--lora-surface);
|
||||
color: var (--text-color);
|
||||
font-size: 0.95em;
|
||||
height: 32px;
|
||||
}
|
||||
|
||||
.primary-btn.disabled {
|
||||
opacity: 0.5;
|
||||
cursor: not-allowed;
|
||||
}
|
||||
|
||||
/* Add styles for delete preview image */
|
||||
.delete-preview {
|
||||
max-width: 150px;
|
||||
@@ -573,4 +697,279 @@ input:checked + .toggle-slider:before {
|
||||
|
||||
.changelog-item a:hover {
|
||||
text-decoration: underline;
|
||||
}
|
||||
|
||||
/* Add warning text style for settings */
|
||||
.warning-text {
|
||||
color: var(--lora-warning, #e67e22);
|
||||
font-weight: 500;
|
||||
}
|
||||
|
||||
[data-theme="dark"] .warning-text {
|
||||
color: var(--lora-warning, #f39c12);
|
||||
}
|
||||
|
||||
/* Add styles for density description list */
|
||||
.density-description {
|
||||
margin: 8px 0;
|
||||
padding-left: 20px;
|
||||
font-size: 0.9em;
|
||||
}
|
||||
|
||||
.density-description li {
|
||||
margin-bottom: 4px;
|
||||
}
|
||||
|
||||
/* Help Modal styles */
|
||||
.help-modal {
|
||||
max-width: 850px;
|
||||
}
|
||||
|
||||
.help-header {
|
||||
display: flex;
|
||||
align-items: center;
|
||||
margin-bottom: var(--space-2);
|
||||
}
|
||||
|
||||
.modal-help-icon {
|
||||
font-size: 24px;
|
||||
color: var(--lora-accent);
|
||||
margin-right: var(--space-2);
|
||||
vertical-align: text-bottom;
|
||||
}
|
||||
|
||||
/* Tab navigation styles */
|
||||
.help-tabs {
|
||||
display: flex;
|
||||
border-bottom: 1px solid var(--lora-border);
|
||||
margin-bottom: var(--space-2);
|
||||
gap: 8px;
|
||||
}
|
||||
|
||||
.tab-btn {
|
||||
padding: 8px 16px;
|
||||
background: transparent;
|
||||
border: none;
|
||||
border-bottom: 2px solid transparent;
|
||||
color: var(--text-color);
|
||||
cursor: pointer;
|
||||
font-weight: 500;
|
||||
transition: all 0.2s;
|
||||
opacity: 0.7;
|
||||
}
|
||||
|
||||
.tab-btn:hover {
|
||||
background-color: rgba(0, 0, 0, 0.05);
|
||||
opacity: 0.9;
|
||||
}
|
||||
|
||||
.tab-btn.active {
|
||||
color: var(--lora-accent);
|
||||
border-bottom: 2px solid var(--lora-accent);
|
||||
opacity: 1;
|
||||
}
|
||||
|
||||
/* Tab content styles */
|
||||
.help-content {
|
||||
padding: var(--space-1) 0;
|
||||
overflow-y: auto;
|
||||
}
|
||||
|
||||
.tab-pane {
|
||||
display: none;
|
||||
}
|
||||
|
||||
.tab-pane.active {
|
||||
display: block;
|
||||
}
|
||||
|
||||
/* Video embed styles */
|
||||
.video-embed {
|
||||
position: relative;
|
||||
padding-bottom: 56.25%; /* 16:9 aspect ratio */
|
||||
height: 0;
|
||||
overflow: hidden;
|
||||
max-width: 100%;
|
||||
margin-bottom: var(--space-2);
|
||||
border-radius: var(--border-radius-sm);
|
||||
}
|
||||
|
||||
.video-embed iframe {
|
||||
position: absolute;
|
||||
top: 0;
|
||||
left: 0;
|
||||
width: 100%;
|
||||
height: 100%;
|
||||
}
|
||||
|
||||
.video-embed.small {
|
||||
max-width: 100%;
|
||||
margin-bottom: var(--space-1);
|
||||
}
|
||||
|
||||
.help-text {
|
||||
margin: var(--space-2) 0;
|
||||
}
|
||||
|
||||
.help-text ul {
|
||||
padding-left: 20px;
|
||||
margin-top: 8px;
|
||||
}
|
||||
|
||||
.help-text li {
|
||||
margin-bottom: 8px;
|
||||
}
|
||||
|
||||
/* Documentation link styles */
|
||||
.docs-section {
|
||||
margin-bottom: var(--space-3);
|
||||
}
|
||||
|
||||
.docs-section h4 {
|
||||
display: flex;
|
||||
align-items: center;
|
||||
gap: 8px;
|
||||
margin-bottom: var(--space-1);
|
||||
}
|
||||
|
||||
.docs-links {
|
||||
list-style-type: none;
|
||||
padding-left: var(--space-3);
|
||||
}
|
||||
|
||||
.docs-links li {
|
||||
margin-bottom: var(--space-1);
|
||||
position: relative;
|
||||
}
|
||||
|
||||
.docs-links li:before {
|
||||
content: "•";
|
||||
position: absolute;
|
||||
left: -15px;
|
||||
color: var(--lora-accent);
|
||||
}
|
||||
|
||||
.docs-links a {
|
||||
color: var(--lora-accent);
|
||||
text-decoration: none;
|
||||
transition: color 0.2s;
|
||||
}
|
||||
|
||||
.docs-links a:hover {
|
||||
text-decoration: underline;
|
||||
}
|
||||
|
||||
/* Update video list styles */
|
||||
.video-list {
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
gap: var(--space-3);
|
||||
}
|
||||
|
||||
.video-item {
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
}
|
||||
|
||||
.video-info {
|
||||
padding: var(--space-1);
|
||||
}
|
||||
|
||||
.video-info h4 {
|
||||
margin-bottom: var(--space-1);
|
||||
}
|
||||
|
||||
.video-info p {
|
||||
font-size: 0.9em;
|
||||
opacity: 0.8;
|
||||
}
|
||||
|
||||
/* Dark theme adjustments */
|
||||
[data-theme="dark"] .tab-btn:hover {
|
||||
background-color: rgba(255, 255, 255, 0.05);
|
||||
}
|
||||
|
||||
/* Update date badge styles */
|
||||
.update-date-badge {
|
||||
display: inline-flex;
|
||||
align-items: center;
|
||||
font-size: 0.75em;
|
||||
font-weight: 500;
|
||||
background-color: var(--lora-accent);
|
||||
color: var(--lora-text);
|
||||
padding: 4px 8px;
|
||||
border-radius: 12px;
|
||||
margin-left: 10px;
|
||||
vertical-align: middle;
|
||||
animation: fadeIn 0.5s ease-in-out;
|
||||
box-shadow: 0 2px 4px rgba(0, 0, 0, 0.1);
|
||||
}
|
||||
|
||||
.update-date-badge i {
|
||||
margin-right: 5px;
|
||||
font-size: 0.9em;
|
||||
}
|
||||
|
||||
@keyframes fadeIn {
|
||||
from { opacity: 0; transform: translateY(-5px); }
|
||||
to { opacity: 1; transform: translateY(0); }
|
||||
}
|
||||
|
||||
/* Dark theme adjustments */
|
||||
[data-theme="dark"] .update-date-badge {
|
||||
box-shadow: 0 2px 4px rgba(0, 0, 0, 0.3);
|
||||
}
|
||||
|
||||
/* Re-link to Civitai Modal styles */
|
||||
.warning-box {
|
||||
background-color: rgba(255, 193, 7, 0.1);
|
||||
border: 1px solid rgba(255, 193, 7, 0.5);
|
||||
border-radius: var(--border-radius-sm);
|
||||
padding: var(--space-2);
|
||||
margin-bottom: var(--space-3);
|
||||
}
|
||||
|
||||
.warning-box i {
|
||||
color: var(--lora-warning);
|
||||
margin-right: var(--space-1);
|
||||
}
|
||||
|
||||
.warning-box ul {
|
||||
padding-left: 20px;
|
||||
margin: var(--space-1) 0;
|
||||
}
|
||||
|
||||
.warning-box li {
|
||||
margin-bottom: 4px;
|
||||
}
|
||||
|
||||
.input-group {
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
margin-bottom: var(--space-2);
|
||||
}
|
||||
|
||||
.input-group label {
|
||||
margin-bottom: var(--space-1);
|
||||
font-weight: 500;
|
||||
}
|
||||
|
||||
.input-group input {
|
||||
padding: 8px 12px;
|
||||
border-radius: var(--border-radius-xs);
|
||||
border: 1px solid var(--border-color);
|
||||
background-color: var(--lora-surface);
|
||||
color: var(--text-color);
|
||||
}
|
||||
|
||||
.input-error {
|
||||
color: var(--lora-error);
|
||||
font-size: 0.9em;
|
||||
min-height: 20px;
|
||||
margin-top: 4px;
|
||||
}
|
||||
|
||||
[data-theme="dark"] .warning-box {
|
||||
background-color: rgba(255, 193, 7, 0.05);
|
||||
border-color: rgba(255, 193, 7, 0.3);
|
||||
}
|
||||
217
static/css/components/progress-panel.css
Normal file
217
static/css/components/progress-panel.css
Normal file
@@ -0,0 +1,217 @@
|
||||
/* Progress Panel Styles */
|
||||
.progress-panel {
|
||||
position: fixed;
|
||||
bottom: 20px;
|
||||
right: 20px;
|
||||
width: 350px;
|
||||
background: var(--lora-surface);
|
||||
border: 1px solid var(--lora-border);
|
||||
border-radius: var(--border-radius-sm);
|
||||
box-shadow: 0 4px 12px rgba(0, 0, 0, 0.1);
|
||||
z-index: calc(var(--z-modal) - 1);
|
||||
transition: transform 0.3s ease, opacity 0.3s ease;
|
||||
opacity: 0;
|
||||
transform: translateY(20px);
|
||||
pointer-events: none; /* Ignore mouse events when invisible */
|
||||
}
|
||||
|
||||
.progress-panel.visible {
|
||||
opacity: 1;
|
||||
transform: translateY(0);
|
||||
pointer-events: auto; /* Capture mouse events when visible */
|
||||
}
|
||||
|
||||
.progress-panel.collapsed .progress-panel-content {
|
||||
display: none;
|
||||
}
|
||||
|
||||
.progress-panel.collapsed .progress-panel-header {
|
||||
border-bottom: none;
|
||||
padding-bottom: calc(var(--space-2) + 12px);
|
||||
}
|
||||
|
||||
.progress-panel-header {
|
||||
padding: var(--space-2);
|
||||
display: flex;
|
||||
justify-content: space-between;
|
||||
align-items: center;
|
||||
border-bottom: 1px solid var(--lora-border);
|
||||
}
|
||||
|
||||
.progress-panel-title {
|
||||
font-weight: 500;
|
||||
color: var(--text-color);
|
||||
display: flex;
|
||||
align-items: center;
|
||||
gap: 8px;
|
||||
}
|
||||
|
||||
.progress-panel-actions {
|
||||
display: flex;
|
||||
gap: 6px;
|
||||
}
|
||||
|
||||
.icon-button {
|
||||
background: none;
|
||||
border: none;
|
||||
color: var(--text-color);
|
||||
width: 24px;
|
||||
height: 24px;
|
||||
border-radius: 50%;
|
||||
cursor: pointer;
|
||||
display: flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
opacity: 0.6;
|
||||
transition: all 0.2s;
|
||||
position: relative;
|
||||
}
|
||||
|
||||
.icon-button:hover {
|
||||
opacity: 1;
|
||||
background: rgba(0, 0, 0, 0.05);
|
||||
}
|
||||
|
||||
[data-theme="dark"] .icon-button:hover {
|
||||
background: rgba(255, 255, 255, 0.1);
|
||||
}
|
||||
|
||||
.progress-panel-content {
|
||||
padding: var(--space-2);
|
||||
}
|
||||
|
||||
.download-progress-info {
|
||||
margin-bottom: var(--space-2);
|
||||
}
|
||||
|
||||
.progress-status {
|
||||
display: flex;
|
||||
justify-content: space-between;
|
||||
margin-bottom: 8px;
|
||||
font-size: 0.9em;
|
||||
color: var(--text-color);
|
||||
}
|
||||
|
||||
/* Use specific selectors to avoid conflicts with loading.css */
|
||||
.progress-panel .progress-container {
|
||||
width: 100%;
|
||||
background-color: var(--lora-border);
|
||||
border-radius: 4px;
|
||||
overflow: hidden;
|
||||
height: var(--space-1);
|
||||
}
|
||||
|
||||
.progress-panel .progress-bar {
|
||||
width: 0%;
|
||||
height: 100%;
|
||||
background-color: var(--lora-accent);
|
||||
transition: width 0.5s ease;
|
||||
}
|
||||
|
||||
.current-model-info {
|
||||
background: var(--bg-color);
|
||||
border-radius: var(--border-radius-xs);
|
||||
padding: 8px;
|
||||
margin-bottom: var(--space-2);
|
||||
font-size: 0.95em;
|
||||
}
|
||||
|
||||
.current-label {
|
||||
font-size: 0.85em;
|
||||
color: var(--text-color);
|
||||
opacity: 0.7;
|
||||
margin-bottom: 4px;
|
||||
}
|
||||
|
||||
.current-model-name {
|
||||
white-space: nowrap;
|
||||
overflow: hidden;
|
||||
text-overflow: ellipsis;
|
||||
color: var(--text-color);
|
||||
}
|
||||
|
||||
.download-stats {
|
||||
display: flex;
|
||||
justify-content: space-between;
|
||||
margin-bottom: var(--space-2);
|
||||
}
|
||||
|
||||
.stat-item {
|
||||
font-size: 0.9em;
|
||||
color: var(--text-color);
|
||||
}
|
||||
|
||||
.stat-label {
|
||||
opacity: 0.7;
|
||||
margin-right: 4px;
|
||||
}
|
||||
|
||||
.download-errors {
|
||||
background: oklch(var(--lora-warning) / 0.1);
|
||||
border: 1px solid var(--lora-warning);
|
||||
border-radius: var(--border-radius-xs);
|
||||
padding: var(--space-1);
|
||||
max-height: 100px;
|
||||
overflow-y: auto;
|
||||
font-size: 0.85em;
|
||||
}
|
||||
|
||||
.error-header {
|
||||
color: var(--lora-warning);
|
||||
font-weight: 500;
|
||||
margin-bottom: 4px;
|
||||
}
|
||||
|
||||
.error-list {
|
||||
color: var(--text-color);
|
||||
opacity: 0.85;
|
||||
}
|
||||
|
||||
.hidden {
|
||||
display: none !important;
|
||||
}
|
||||
|
||||
/* Mini progress indicator on pause button when panel collapsed */
|
||||
.mini-progress-container {
|
||||
position: absolute;
|
||||
top: 0;
|
||||
left: 0;
|
||||
width: 100%;
|
||||
height: 100%;
|
||||
border-radius: 50%;
|
||||
pointer-events: none;
|
||||
opacity: 0; /* Hide by default */
|
||||
transition: opacity 0.2s ease;
|
||||
}
|
||||
|
||||
/* Show mini progress when panel is collapsed */
|
||||
.progress-panel.collapsed .mini-progress-container {
|
||||
opacity: 1;
|
||||
}
|
||||
|
||||
.mini-progress-circle {
|
||||
stroke: var(--lora-accent);
|
||||
fill: none;
|
||||
stroke-width: 2.5;
|
||||
stroke-linecap: round;
|
||||
transform: rotate(-90deg);
|
||||
transform-origin: center;
|
||||
transition: stroke-dashoffset 0.3s ease;
|
||||
}
|
||||
|
||||
.mini-progress-background {
|
||||
stroke: var(--lora-border);
|
||||
fill: none;
|
||||
stroke-width: 2;
|
||||
}
|
||||
|
||||
.progress-percent {
|
||||
position: absolute;
|
||||
top: 100%;
|
||||
left: 50%;
|
||||
transform: translateX(-50%);
|
||||
font-size: 0.65em;
|
||||
color: var(--text-color);
|
||||
opacity: 0.8;
|
||||
white-space: nowrap;
|
||||
}
|
||||
@@ -229,8 +229,10 @@
|
||||
background: var(--lora-surface);
|
||||
border: 1px solid var(--border-color);
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
position: relative;
|
||||
}
|
||||
|
||||
.recipe-preview-container img,
|
||||
@@ -246,6 +248,133 @@
|
||||
object-fit: contain;
|
||||
}
|
||||
|
||||
/* Source URL container */
|
||||
.source-url-container {
|
||||
position: absolute;
|
||||
bottom: 0;
|
||||
left: 0;
|
||||
right: 0;
|
||||
background: rgba(0, 0, 0, 0.5);
|
||||
padding: 8px 12px;
|
||||
display: flex;
|
||||
justify-content: space-between;
|
||||
align-items: center;
|
||||
transition: transform 0.3s ease;
|
||||
transform: translateY(100%);
|
||||
}
|
||||
|
||||
.recipe-preview-container:hover .source-url-container {
|
||||
transform: translateY(0);
|
||||
}
|
||||
|
||||
.source-url-container.active {
|
||||
transform: translateY(0);
|
||||
}
|
||||
|
||||
.source-url-content {
|
||||
display: flex;
|
||||
align-items: center;
|
||||
color: #fff;
|
||||
flex: 1;
|
||||
overflow: hidden;
|
||||
font-size: 0.85em;
|
||||
}
|
||||
|
||||
.source-url-icon {
|
||||
margin-right: 8px;
|
||||
flex-shrink: 0;
|
||||
}
|
||||
|
||||
.source-url-text {
|
||||
white-space: nowrap;
|
||||
overflow: hidden;
|
||||
text-overflow: ellipsis;
|
||||
cursor: pointer;
|
||||
flex: 1;
|
||||
}
|
||||
|
||||
.source-url-edit-btn {
|
||||
background: none;
|
||||
border: none;
|
||||
color: #fff;
|
||||
cursor: pointer;
|
||||
padding: 4px;
|
||||
margin-left: 8px;
|
||||
border-radius: var(--border-radius-xs);
|
||||
opacity: 0.7;
|
||||
transition: opacity 0.2s ease;
|
||||
flex-shrink: 0;
|
||||
}
|
||||
|
||||
.source-url-edit-btn:hover {
|
||||
opacity: 1;
|
||||
background: rgba(255, 255, 255, 0.1);
|
||||
}
|
||||
|
||||
/* Source URL editor */
|
||||
.source-url-editor {
|
||||
display: none;
|
||||
position: absolute;
|
||||
bottom: 0;
|
||||
left: 0;
|
||||
right: 0;
|
||||
background: var(--bg-color);
|
||||
border-top: 1px solid var(--border-color);
|
||||
padding: 12px;
|
||||
flex-direction: column;
|
||||
gap: 10px;
|
||||
z-index: 5;
|
||||
}
|
||||
|
||||
.source-url-editor.active {
|
||||
display: flex;
|
||||
}
|
||||
|
||||
.source-url-input {
|
||||
width: 100%;
|
||||
padding: 8px 10px;
|
||||
border: 1px solid var(--border-color);
|
||||
border-radius: var(--border-radius-xs);
|
||||
background: var(--bg-color);
|
||||
color: var(--text-color);
|
||||
font-size: 0.9em;
|
||||
}
|
||||
|
||||
.source-url-actions {
|
||||
display: flex;
|
||||
justify-content: flex-end;
|
||||
gap: 8px;
|
||||
}
|
||||
|
||||
.source-url-cancel-btn,
|
||||
.source-url-save-btn {
|
||||
padding: 6px 12px;
|
||||
border-radius: var(--border-radius-xs);
|
||||
font-size: 0.85em;
|
||||
cursor: pointer;
|
||||
border: none;
|
||||
transition: all 0.2s;
|
||||
}
|
||||
|
||||
.source-url-cancel-btn {
|
||||
background: var(--bg-color);
|
||||
color: var(--text-color);
|
||||
border: 1px solid var(--border-color);
|
||||
}
|
||||
|
||||
.source-url-save-btn {
|
||||
background: var(--lora-accent);
|
||||
color: white;
|
||||
}
|
||||
|
||||
.source-url-cancel-btn:hover {
|
||||
background: var(--lora-surface);
|
||||
}
|
||||
|
||||
.source-url-save-btn:hover {
|
||||
background: color-mix(in oklch, var(--lora-accent), black 10%);
|
||||
}
|
||||
|
||||
/* Generation Parameters */
|
||||
.recipe-gen-params {
|
||||
height: 360px;
|
||||
|
||||
@@ -117,9 +117,50 @@
|
||||
box-shadow: 0 4px 8px rgba(0, 0, 0, 0.1);
|
||||
}
|
||||
|
||||
/* QR Code section styles */
|
||||
.qrcode-toggle {
|
||||
width: 100%;
|
||||
margin-top: var(--space-2);
|
||||
justify-content: center;
|
||||
position: relative;
|
||||
}
|
||||
|
||||
.qrcode-toggle .toggle-icon {
|
||||
margin-left: 8px;
|
||||
transition: transform 0.3s ease;
|
||||
}
|
||||
|
||||
.qrcode-toggle.active .toggle-icon {
|
||||
transform: rotate(180deg);
|
||||
}
|
||||
|
||||
.qrcode-container {
|
||||
max-height: 0;
|
||||
overflow: hidden;
|
||||
transition: max-height 0.4s ease, opacity 0.3s ease;
|
||||
opacity: 0;
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
align-items: center;
|
||||
}
|
||||
|
||||
.qrcode-container.show {
|
||||
max-height: 500px;
|
||||
opacity: 1;
|
||||
margin-top: var(--space-3);
|
||||
}
|
||||
|
||||
.qrcode-image {
|
||||
max-width: 80%;
|
||||
height: auto;
|
||||
border-radius: var(--border-radius-sm);
|
||||
box-shadow: 0 2px 8px rgba(0, 0, 0, 0.1);
|
||||
border: 1px solid var(--lora-border);
|
||||
aspect-ratio: 1/1; /* Ensure proper aspect ratio for the square QR code */
|
||||
}
|
||||
|
||||
.support-footer {
|
||||
text-align: center;
|
||||
margin-top: var(--space-1);
|
||||
font-style: italic;
|
||||
color: var(--text-color);
|
||||
}
|
||||
|
||||
@@ -1,10 +1,10 @@
|
||||
.page-content {
|
||||
height: calc(100vh - 48px); /* Full height minus header */
|
||||
margin-top: 48px; /* Push down below header */
|
||||
overflow-y: auto; /* Enable scrolling here */
|
||||
width: 100%;
|
||||
position: relative;
|
||||
overflow-y: scroll;
|
||||
overflow-x: hidden; /* Prevent horizontal scrolling */
|
||||
overflow-y: auto; /* Enable vertical scrolling */
|
||||
}
|
||||
|
||||
.container {
|
||||
@@ -15,6 +15,19 @@
|
||||
z-index: var(--z-base);
|
||||
}
|
||||
|
||||
/* Responsive container for larger screens */
|
||||
@media (min-width: 2000px) {
|
||||
.container {
|
||||
max-width: 1800px;
|
||||
}
|
||||
}
|
||||
|
||||
@media (min-width: 3000px) {
|
||||
.container {
|
||||
max-width: 2400px;
|
||||
}
|
||||
}
|
||||
|
||||
.controls {
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
@@ -22,6 +35,13 @@
|
||||
margin-bottom: var(--space-2);
|
||||
}
|
||||
|
||||
.controls-right {
|
||||
display: flex;
|
||||
align-items: center;
|
||||
gap: 8px;
|
||||
margin-left: auto; /* Push to the right */
|
||||
}
|
||||
|
||||
.actions {
|
||||
display: flex;
|
||||
align-items: center;
|
||||
@@ -81,6 +101,22 @@
|
||||
opacity: 1;
|
||||
}
|
||||
|
||||
/* Controls */
|
||||
.control-group button.favorite-filter {
|
||||
position: relative;
|
||||
overflow: hidden;
|
||||
}
|
||||
|
||||
.control-group button.favorite-filter.active {
|
||||
background: var(--lora-accent);
|
||||
color: white;
|
||||
}
|
||||
|
||||
.control-group button.favorite-filter i {
|
||||
margin-right: 4px;
|
||||
color: #ffc107;
|
||||
}
|
||||
|
||||
/* Active state for buttons that can be toggled */
|
||||
.control-group button.active {
|
||||
background: var(--lora-accent);
|
||||
@@ -244,8 +280,8 @@
|
||||
/* Back to Top Button */
|
||||
.back-to-top {
|
||||
position: fixed;
|
||||
bottom: 20px;
|
||||
right: 20px;
|
||||
bottom: 85px;
|
||||
right: 30px;
|
||||
width: 36px;
|
||||
height: 36px;
|
||||
border-radius: 50%;
|
||||
@@ -277,6 +313,86 @@
|
||||
box-shadow: 0 4px 8px rgba(0, 0, 0, 0.15);
|
||||
}
|
||||
|
||||
/* Prevent text selection in control and header areas */
|
||||
.tag,
|
||||
.control-group button,
|
||||
.control-group select,
|
||||
.toggle-folders-btn,
|
||||
.bulk-operations-panel,
|
||||
.app-header,
|
||||
.header-branding,
|
||||
.app-title,
|
||||
.main-nav,
|
||||
.nav-item,
|
||||
.header-actions button,
|
||||
.header-controls,
|
||||
.toggle-folders-container button {
|
||||
-webkit-user-select: none;
|
||||
-moz-user-select: none;
|
||||
-ms-user-select: none;
|
||||
user-select: none;
|
||||
}
|
||||
|
||||
/* Dropdown Button Styling */
|
||||
.dropdown-group {
|
||||
position: relative;
|
||||
display: flex;
|
||||
}
|
||||
|
||||
.dropdown-main {
|
||||
border-top-right-radius: 0;
|
||||
border-bottom-right-radius: 0;
|
||||
border-right: 1px solid rgba(0, 0, 0, 0.1);
|
||||
}
|
||||
|
||||
.dropdown-toggle {
|
||||
width: 24px !important;
|
||||
min-width: unset !important;
|
||||
border-top-left-radius: 0;
|
||||
border-bottom-left-radius: 0;
|
||||
padding: 0 !important;
|
||||
}
|
||||
|
||||
.dropdown-menu {
|
||||
position: absolute;
|
||||
top: 100%;
|
||||
left: 0;
|
||||
z-index: 1000;
|
||||
display: none;
|
||||
min-width: 230px;
|
||||
padding: 5px 0;
|
||||
margin: 2px 0 0;
|
||||
font-size: 0.85em;
|
||||
background-color: var(--card-bg);
|
||||
border: 1px solid var(--border-color);
|
||||
border-radius: var(--border-radius-xs);
|
||||
box-shadow: 0 6px 12px rgba(0, 0, 0, 0.175);
|
||||
}
|
||||
|
||||
.dropdown-group.active .dropdown-menu {
|
||||
display: block;
|
||||
}
|
||||
|
||||
.dropdown-item {
|
||||
display: block;
|
||||
padding: 6px 15px;
|
||||
clear: both;
|
||||
font-weight: 400;
|
||||
color: var(--text-color);
|
||||
cursor: pointer;
|
||||
transition: background-color 0.2s ease;
|
||||
}
|
||||
|
||||
.dropdown-item:hover {
|
||||
background-color: oklch(var(--lora-accent) / 0.1);
|
||||
}
|
||||
|
||||
.dropdown-item i {
|
||||
margin-right: 8px;
|
||||
width: 16px;
|
||||
text-align: center;
|
||||
}
|
||||
|
||||
@media (max-width: 768px) {
|
||||
.actions {
|
||||
flex-wrap: wrap;
|
||||
@@ -289,11 +405,14 @@
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
.controls-right {
|
||||
width: 100%;
|
||||
justify-content: flex-end;
|
||||
margin-top: 8px;
|
||||
}
|
||||
|
||||
.toggle-folders-container {
|
||||
margin-left: 0;
|
||||
width: 100%;
|
||||
display: flex;
|
||||
justify-content: flex-end;
|
||||
}
|
||||
|
||||
.folder-tags-container {
|
||||
@@ -319,4 +438,9 @@
|
||||
.back-to-top {
|
||||
bottom: 60px; /* Give some extra space from bottom on mobile */
|
||||
}
|
||||
|
||||
.dropdown-menu {
|
||||
left: auto;
|
||||
right: 0; /* Align to right on mobile */
|
||||
}
|
||||
}
|
||||
|
||||
@@ -20,6 +20,10 @@
|
||||
@import 'components/shared.css';
|
||||
@import 'components/filter-indicator.css';
|
||||
@import 'components/initialization.css';
|
||||
@import 'components/progress-panel.css';
|
||||
@import 'components/alphabet-bar.css'; /* Add alphabet bar component */
|
||||
@import 'components/duplicates.css'; /* Add duplicates component */
|
||||
@import 'components/keyboard-nav.css'; /* Add keyboard navigation component */
|
||||
|
||||
.initialization-notice {
|
||||
display: flex;
|
||||
|
||||
BIN
static/images/one-click-send.jpg
Normal file
BIN
static/images/one-click-send.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 181 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 1.6 MiB After Width: | Height: | Size: 1.9 MiB |
BIN
static/images/wechat-qr.webp
Normal file
BIN
static/images/wechat-qr.webp
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 98 KiB |
@@ -1,8 +1,7 @@
|
||||
// filepath: d:\Workspace\ComfyUI\custom_nodes\ComfyUI-Lora-Manager\static\js\api\baseModelApi.js
|
||||
import { state, getCurrentPageState } from '../state/index.js';
|
||||
import { showToast } from '../utils/uiHelpers.js';
|
||||
import { showDeleteModal, confirmDelete } from '../utils/modalUtils.js';
|
||||
import { getSessionItem } from '../utils/storageHelpers.js';
|
||||
import { getSessionItem, saveMapToStorage } from '../utils/storageHelpers.js';
|
||||
|
||||
/**
|
||||
* Shared functionality for handling models (loras and checkpoints)
|
||||
@@ -45,6 +44,16 @@ export async function loadMoreModels(options = {}) {
|
||||
params.append('folder', pageState.activeFolder);
|
||||
}
|
||||
|
||||
// Add favorites filter parameter if enabled
|
||||
if (pageState.showFavoritesOnly) {
|
||||
params.append('favorites_only', 'true');
|
||||
}
|
||||
|
||||
// Add active letter filter if set
|
||||
if (pageState.activeLetterFilter) {
|
||||
params.append('first_letter', pageState.activeLetterFilter);
|
||||
}
|
||||
|
||||
// Add search parameters if there's a search term
|
||||
if (pageState.filters?.search) {
|
||||
params.append('search', pageState.filters.search);
|
||||
@@ -150,6 +159,231 @@ export async function loadMoreModels(options = {}) {
|
||||
}
|
||||
}
|
||||
|
||||
// New method for virtual scrolling fetch
|
||||
export async function fetchModelsPage(options = {}) {
|
||||
const {
|
||||
modelType = 'lora',
|
||||
page = 1,
|
||||
pageSize = 100,
|
||||
endpoint = '/api/loras'
|
||||
} = options;
|
||||
|
||||
const pageState = getCurrentPageState();
|
||||
|
||||
try {
|
||||
const params = new URLSearchParams({
|
||||
page: page,
|
||||
page_size: pageSize || pageState.pageSize || 20,
|
||||
sort_by: pageState.sortBy
|
||||
});
|
||||
|
||||
if (pageState.activeFolder !== null) {
|
||||
params.append('folder', pageState.activeFolder);
|
||||
}
|
||||
|
||||
// Add favorites filter parameter if enabled
|
||||
if (pageState.showFavoritesOnly) {
|
||||
params.append('favorites_only', 'true');
|
||||
}
|
||||
|
||||
// Add active letter filter if set
|
||||
if (pageState.activeLetterFilter) {
|
||||
params.append('first_letter', pageState.activeLetterFilter);
|
||||
}
|
||||
|
||||
// Add search parameters if there's a search term
|
||||
if (pageState.filters?.search) {
|
||||
params.append('search', pageState.filters.search);
|
||||
params.append('fuzzy', 'true');
|
||||
|
||||
// Add search option parameters if available
|
||||
if (pageState.searchOptions) {
|
||||
params.append('search_filename', pageState.searchOptions.filename.toString());
|
||||
params.append('search_modelname', pageState.searchOptions.modelname.toString());
|
||||
if (pageState.searchOptions.tags !== undefined) {
|
||||
params.append('search_tags', pageState.searchOptions.tags.toString());
|
||||
}
|
||||
params.append('recursive', (pageState.searchOptions?.recursive ?? false).toString());
|
||||
}
|
||||
}
|
||||
|
||||
// Add filter parameters if active
|
||||
if (pageState.filters) {
|
||||
// Handle tags filters
|
||||
if (pageState.filters.tags && pageState.filters.tags.length > 0) {
|
||||
// Checkpoints API expects individual 'tag' parameters, Loras API expects comma-separated 'tags'
|
||||
if (modelType === 'checkpoint') {
|
||||
pageState.filters.tags.forEach(tag => {
|
||||
params.append('tag', tag);
|
||||
});
|
||||
} else {
|
||||
params.append('tags', pageState.filters.tags.join(','));
|
||||
}
|
||||
}
|
||||
|
||||
// Handle base model filters
|
||||
if (pageState.filters.baseModel && pageState.filters.baseModel.length > 0) {
|
||||
if (modelType === 'checkpoint') {
|
||||
pageState.filters.baseModel.forEach(model => {
|
||||
params.append('base_model', model);
|
||||
});
|
||||
} else {
|
||||
params.append('base_models', pageState.filters.baseModel.join(','));
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Add model-specific parameters
|
||||
if (modelType === 'lora') {
|
||||
// Check for recipe-based filtering parameters from session storage
|
||||
const filterLoraHash = getSessionItem('recipe_to_lora_filterLoraHash');
|
||||
const filterLoraHashes = getSessionItem('recipe_to_lora_filterLoraHashes');
|
||||
|
||||
// Add hash filter parameter if present
|
||||
if (filterLoraHash) {
|
||||
params.append('lora_hash', filterLoraHash);
|
||||
}
|
||||
// Add multiple hashes filter if present
|
||||
else if (filterLoraHashes) {
|
||||
try {
|
||||
if (Array.isArray(filterLoraHashes) && filterLoraHashes.length > 0) {
|
||||
params.append('lora_hashes', filterLoraHashes.join(','));
|
||||
}
|
||||
} catch (error) {
|
||||
console.error('Error parsing lora hashes from session storage:', error);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
const response = await fetch(`${endpoint}?${params}`);
|
||||
if (!response.ok) {
|
||||
throw new Error(`Failed to fetch models: ${response.statusText}`);
|
||||
}
|
||||
|
||||
const data = await response.json();
|
||||
|
||||
return {
|
||||
items: data.items,
|
||||
totalItems: data.total,
|
||||
totalPages: data.total_pages,
|
||||
currentPage: page,
|
||||
hasMore: page < data.total_pages,
|
||||
folders: data.folders
|
||||
};
|
||||
|
||||
} catch (error) {
|
||||
console.error(`Error fetching ${modelType}s:`, error);
|
||||
showToast(`Failed to fetch ${modelType}s: ${error.message}`, 'error');
|
||||
throw error;
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Reset and reload models using virtual scrolling
|
||||
* @param {Object} options - Operation options
|
||||
* @returns {Promise<Object>} The fetch result
|
||||
*/
|
||||
export async function resetAndReloadWithVirtualScroll(options = {}) {
|
||||
const {
|
||||
modelType = 'lora',
|
||||
updateFolders = false,
|
||||
fetchPageFunction
|
||||
} = options;
|
||||
|
||||
const pageState = getCurrentPageState();
|
||||
|
||||
try {
|
||||
pageState.isLoading = true;
|
||||
document.body.classList.add('loading');
|
||||
|
||||
// Reset page counter
|
||||
pageState.currentPage = 1;
|
||||
|
||||
// Fetch the first page
|
||||
const result = await fetchPageFunction(1, pageState.pageSize || 50);
|
||||
|
||||
// Update the virtual scroller
|
||||
state.virtualScroller.refreshWithData(
|
||||
result.items,
|
||||
result.totalItems,
|
||||
result.hasMore
|
||||
);
|
||||
|
||||
// Update state
|
||||
pageState.hasMore = result.hasMore;
|
||||
pageState.currentPage = 2; // Next page will be 2
|
||||
|
||||
// Update folders if needed
|
||||
if (updateFolders && result.folders) {
|
||||
updateFolderTags(result.folders);
|
||||
}
|
||||
|
||||
return result;
|
||||
} catch (error) {
|
||||
console.error(`Error reloading ${modelType}s:`, error);
|
||||
showToast(`Failed to reload ${modelType}s: ${error.message}`, 'error');
|
||||
throw error;
|
||||
} finally {
|
||||
pageState.isLoading = false;
|
||||
document.body.classList.remove('loading');
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Load more models using virtual scrolling
|
||||
* @param {Object} options - Operation options
|
||||
* @returns {Promise<Object>} The fetch result
|
||||
*/
|
||||
export async function loadMoreWithVirtualScroll(options = {}) {
|
||||
const {
|
||||
modelType = 'lora',
|
||||
resetPage = false,
|
||||
updateFolders = false,
|
||||
fetchPageFunction
|
||||
} = options;
|
||||
|
||||
const pageState = getCurrentPageState();
|
||||
|
||||
try {
|
||||
// Start loading state
|
||||
pageState.isLoading = true;
|
||||
document.body.classList.add('loading');
|
||||
|
||||
// Reset to first page if requested
|
||||
if (resetPage) {
|
||||
pageState.currentPage = 1;
|
||||
}
|
||||
|
||||
// Fetch the first page of data
|
||||
const result = await fetchPageFunction(pageState.currentPage, pageState.pageSize || 50);
|
||||
|
||||
// Update virtual scroller with the new data
|
||||
state.virtualScroller.refreshWithData(
|
||||
result.items,
|
||||
result.totalItems,
|
||||
result.hasMore
|
||||
);
|
||||
|
||||
// Update state
|
||||
pageState.hasMore = result.hasMore;
|
||||
pageState.currentPage = 2; // Next page to load would be 2
|
||||
|
||||
// Update folders if needed
|
||||
if (updateFolders && result.folders) {
|
||||
updateFolderTags(result.folders);
|
||||
}
|
||||
|
||||
return result;
|
||||
} catch (error) {
|
||||
console.error(`Error loading ${modelType}s:`, error);
|
||||
showToast(`Failed to load ${modelType}s: ${error.message}`, 'error');
|
||||
throw error;
|
||||
} finally {
|
||||
pageState.isLoading = false;
|
||||
document.body.classList.remove('loading');
|
||||
}
|
||||
}
|
||||
|
||||
// Update folder tags in the UI
|
||||
export function updateFolderTags(folders) {
|
||||
const folderTagsContainer = document.querySelector('.folder-tags');
|
||||
@@ -198,13 +432,53 @@ export function replaceModelPreview(filePath, modelType = 'lora') {
|
||||
}
|
||||
|
||||
// Delete a model (generic)
|
||||
export function deleteModel(filePath, modelType = 'lora') {
|
||||
if (modelType === 'checkpoint') {
|
||||
confirmDelete('Are you sure you want to delete this checkpoint?', () => {
|
||||
performDelete(filePath, modelType);
|
||||
export async function deleteModel(filePath, modelType = 'lora') {
|
||||
try {
|
||||
state.loadingManager.showSimpleLoading(`Deleting ${modelType}...`);
|
||||
|
||||
const endpoint = modelType === 'checkpoint'
|
||||
? '/api/checkpoints/delete'
|
||||
: '/api/delete_model';
|
||||
|
||||
const response = await fetch(endpoint, {
|
||||
method: 'POST',
|
||||
headers: {
|
||||
'Content-Type': 'application/json',
|
||||
},
|
||||
body: JSON.stringify({
|
||||
file_path: filePath
|
||||
})
|
||||
});
|
||||
} else {
|
||||
showDeleteModal(filePath);
|
||||
|
||||
if (!response.ok) {
|
||||
throw new Error(`Failed to delete ${modelType}: ${response.statusText}`);
|
||||
}
|
||||
|
||||
const data = await response.json();
|
||||
|
||||
if (data.success) {
|
||||
// If virtual scroller exists, update its data
|
||||
if (state.virtualScroller) {
|
||||
state.virtualScroller.removeItemByFilePath(filePath);
|
||||
} else {
|
||||
// Legacy approach: remove the card from UI directly
|
||||
const card = document.querySelector(`.lora-card[data-filepath="${filePath}"]`);
|
||||
if (card) {
|
||||
card.remove();
|
||||
}
|
||||
}
|
||||
|
||||
showToast(`${modelType} deleted successfully`, 'success');
|
||||
return true;
|
||||
} else {
|
||||
throw new Error(data.error || `Failed to delete ${modelType}`);
|
||||
}
|
||||
} catch (error) {
|
||||
console.error(`Error deleting ${modelType}:`, error);
|
||||
showToast(`Failed to delete ${modelType}: ${error.message}`, 'error');
|
||||
return false;
|
||||
} finally {
|
||||
state.loadingManager.hide();
|
||||
}
|
||||
}
|
||||
|
||||
@@ -229,26 +503,31 @@ export async function refreshModels(options = {}) {
|
||||
const {
|
||||
modelType = 'lora',
|
||||
scanEndpoint = '/api/loras/scan',
|
||||
resetAndReloadFunction
|
||||
resetAndReloadFunction,
|
||||
fullRebuild = false // New parameter with default value false
|
||||
} = options;
|
||||
|
||||
try {
|
||||
state.loadingManager.showSimpleLoading(`Refreshing ${modelType}s...`);
|
||||
state.loadingManager.showSimpleLoading(`${fullRebuild ? 'Full rebuild' : 'Refreshing'} ${modelType}s...`);
|
||||
|
||||
const response = await fetch(scanEndpoint);
|
||||
// Add fullRebuild parameter to the request
|
||||
const url = new URL(scanEndpoint, window.location.origin);
|
||||
url.searchParams.append('full_rebuild', fullRebuild);
|
||||
|
||||
const response = await fetch(url);
|
||||
|
||||
if (!response.ok) {
|
||||
throw new Error(`Failed to refresh ${modelType}s: ${response.status} ${response.statusText}`);
|
||||
}
|
||||
|
||||
if (typeof resetAndReloadFunction === 'function') {
|
||||
await resetAndReloadFunction();
|
||||
await resetAndReloadFunction(true); // update folders
|
||||
}
|
||||
|
||||
showToast(`Refresh complete`, 'success');
|
||||
showToast(`${fullRebuild ? 'Full rebuild' : 'Refresh'} complete`, 'success');
|
||||
} catch (error) {
|
||||
console.error(`Refresh failed:`, error);
|
||||
showToast(`Failed to refresh ${modelType}s`, 'error');
|
||||
showToast(`Failed to ${fullRebuild ? 'rebuild' : 'refresh'} ${modelType}s`, 'error');
|
||||
} finally {
|
||||
state.loadingManager.hide();
|
||||
state.loadingManager.restoreProgressBar();
|
||||
@@ -384,6 +663,57 @@ export async function refreshSingleModelMetadata(filePath, modelType = 'lora') {
|
||||
}
|
||||
}
|
||||
|
||||
// Generic function to exclude a model
|
||||
export async function excludeModel(filePath, modelType = 'lora') {
|
||||
try {
|
||||
state.loadingManager.showSimpleLoading(`Excluding ${modelType}...`);
|
||||
|
||||
const endpoint = modelType === 'checkpoint'
|
||||
? '/api/checkpoints/exclude'
|
||||
: '/api/loras/exclude';
|
||||
|
||||
const response = await fetch(endpoint, {
|
||||
method: 'POST',
|
||||
headers: {
|
||||
'Content-Type': 'application/json',
|
||||
},
|
||||
body: JSON.stringify({
|
||||
file_path: filePath
|
||||
})
|
||||
});
|
||||
|
||||
if (!response.ok) {
|
||||
throw new Error(`Failed to exclude ${modelType}: ${response.statusText}`);
|
||||
}
|
||||
|
||||
const data = await response.json();
|
||||
|
||||
if (data.success) {
|
||||
// If virtual scroller exists, update its data
|
||||
if (state.virtualScroller) {
|
||||
state.virtualScroller.removeItemByFilePath(filePath);
|
||||
} else {
|
||||
// Legacy approach: remove the card from UI directly
|
||||
const card = document.querySelector(`.lora-card[data-filepath="${filePath}"]`);
|
||||
if (card) {
|
||||
card.remove();
|
||||
}
|
||||
}
|
||||
|
||||
showToast(`${modelType} excluded successfully`, 'success');
|
||||
return true;
|
||||
} else {
|
||||
throw new Error(data.error || `Failed to exclude ${modelType}`);
|
||||
}
|
||||
} catch (error) {
|
||||
console.error(`Error excluding ${modelType}:`, error);
|
||||
showToast(`Failed to exclude ${modelType}: ${error.message}`, 'error');
|
||||
return false;
|
||||
} finally {
|
||||
state.loadingManager.hide();
|
||||
}
|
||||
}
|
||||
|
||||
// Private methods
|
||||
|
||||
// Upload a preview image
|
||||
@@ -424,12 +754,20 @@ async function uploadPreview(filePath, file, modelType = 'lora') {
|
||||
const previewContainer = card.querySelector('.card-preview');
|
||||
const oldPreview = previewContainer.querySelector('img, video');
|
||||
|
||||
// For LoRA models, use timestamp to prevent caching
|
||||
if (modelType === 'lora') {
|
||||
state.previewVersions?.set(filePath, Date.now());
|
||||
// Get the current page's previewVersions Map based on model type
|
||||
const pageType = modelType === 'checkpoint' ? 'checkpoints' : 'loras';
|
||||
const previewVersions = state.pages[pageType].previewVersions;
|
||||
|
||||
// Update the version timestamp
|
||||
const timestamp = Date.now();
|
||||
if (previewVersions) {
|
||||
previewVersions.set(filePath, timestamp);
|
||||
|
||||
// Save the updated Map to localStorage
|
||||
const storageKey = modelType === 'checkpoint' ? 'checkpoint_preview_versions' : 'lora_preview_versions';
|
||||
saveMapToStorage(storageKey, previewVersions);
|
||||
}
|
||||
|
||||
const timestamp = Date.now();
|
||||
const previewUrl = data.preview_url ?
|
||||
`${data.preview_url}?t=${timestamp}` :
|
||||
`/api/model/preview_image?path=${encodeURIComponent(filePath)}&t=${timestamp}`;
|
||||
|
||||
@@ -1,39 +1,87 @@
|
||||
import { createCheckpointCard } from '../components/CheckpointCard.js';
|
||||
import {
|
||||
loadMoreModels,
|
||||
fetchModelsPage,
|
||||
resetAndReload as baseResetAndReload,
|
||||
resetAndReloadWithVirtualScroll,
|
||||
loadMoreWithVirtualScroll,
|
||||
refreshModels as baseRefreshModels,
|
||||
deleteModel as baseDeleteModel,
|
||||
replaceModelPreview,
|
||||
fetchCivitaiMetadata
|
||||
fetchCivitaiMetadata,
|
||||
refreshSingleModelMetadata,
|
||||
excludeModel as baseExcludeModel
|
||||
} from './baseModelApi.js';
|
||||
import { state } from '../state/index.js';
|
||||
|
||||
// Load more checkpoints with pagination
|
||||
export async function loadMoreCheckpoints(resetPagination = true) {
|
||||
return loadMoreModels({
|
||||
resetPage: resetPagination,
|
||||
updateFolders: true,
|
||||
/**
|
||||
* Fetch checkpoints with pagination for virtual scrolling
|
||||
* @param {number} page - Page number to fetch
|
||||
* @param {number} pageSize - Number of items per page
|
||||
* @returns {Promise<Object>} Object containing items, total count, and pagination info
|
||||
*/
|
||||
export async function fetchCheckpointsPage(page = 1, pageSize = 100) {
|
||||
return fetchModelsPage({
|
||||
modelType: 'checkpoint',
|
||||
createCardFunction: createCheckpointCard,
|
||||
page,
|
||||
pageSize,
|
||||
endpoint: '/api/checkpoints'
|
||||
});
|
||||
}
|
||||
|
||||
/**
|
||||
* Load more checkpoints with pagination - updated to work with VirtualScroller
|
||||
* @param {boolean} resetPage - Whether to reset to the first page
|
||||
* @param {boolean} updateFolders - Whether to update folder tags
|
||||
* @returns {Promise<void>}
|
||||
*/
|
||||
export async function loadMoreCheckpoints(resetPage = false, updateFolders = false) {
|
||||
// Check if virtual scroller is available
|
||||
if (state.virtualScroller) {
|
||||
return loadMoreWithVirtualScroll({
|
||||
modelType: 'checkpoint',
|
||||
resetPage,
|
||||
updateFolders,
|
||||
fetchPageFunction: fetchCheckpointsPage
|
||||
});
|
||||
} else {
|
||||
// Fall back to the original implementation if virtual scroller isn't available
|
||||
return loadMoreModels({
|
||||
resetPage,
|
||||
updateFolders,
|
||||
modelType: 'checkpoint',
|
||||
createCardFunction: createCheckpointCard,
|
||||
endpoint: '/api/checkpoints'
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
// Reset and reload checkpoints
|
||||
export async function resetAndReload() {
|
||||
return baseResetAndReload({
|
||||
updateFolders: true,
|
||||
modelType: 'checkpoint',
|
||||
loadMoreFunction: loadMoreCheckpoints
|
||||
});
|
||||
export async function resetAndReload(updateFolders = false) {
|
||||
// Check if virtual scroller is available
|
||||
if (state.virtualScroller) {
|
||||
return resetAndReloadWithVirtualScroll({
|
||||
modelType: 'checkpoint',
|
||||
updateFolders,
|
||||
fetchPageFunction: fetchCheckpointsPage
|
||||
});
|
||||
} else {
|
||||
// Fall back to original implementation
|
||||
return baseResetAndReload({
|
||||
updateFolders,
|
||||
modelType: 'checkpoint',
|
||||
loadMoreFunction: loadMoreCheckpoints
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
// Refresh checkpoints
|
||||
export async function refreshCheckpoints() {
|
||||
export async function refreshCheckpoints(fullRebuild = false) {
|
||||
return baseRefreshModels({
|
||||
modelType: 'checkpoint',
|
||||
scanEndpoint: '/api/checkpoints/scan',
|
||||
resetAndReloadFunction: resetAndReload
|
||||
resetAndReloadFunction: resetAndReload,
|
||||
fullRebuild: fullRebuild
|
||||
});
|
||||
}
|
||||
|
||||
@@ -54,4 +102,91 @@ export async function fetchCivitai() {
|
||||
fetchEndpoint: '/api/checkpoints/fetch-all-civitai',
|
||||
resetAndReloadFunction: resetAndReload
|
||||
});
|
||||
}
|
||||
|
||||
// Refresh single checkpoint metadata
|
||||
export async function refreshSingleCheckpointMetadata(filePath) {
|
||||
const success = await refreshSingleModelMetadata(filePath, 'checkpoint');
|
||||
if (success) {
|
||||
// Reload the current view to show updated data
|
||||
await resetAndReload();
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Save model metadata to the server
|
||||
* @param {string} filePath - Path to the model file
|
||||
* @param {Object} data - Metadata to save
|
||||
* @returns {Promise} - Promise that resolves with the server response
|
||||
*/
|
||||
export async function saveModelMetadata(filePath, data) {
|
||||
try {
|
||||
// Show loading indicator
|
||||
state.loadingManager.showSimpleLoading('Saving metadata...');
|
||||
|
||||
const response = await fetch('/api/checkpoints/save-metadata', {
|
||||
method: 'POST',
|
||||
headers: {
|
||||
'Content-Type': 'application/json',
|
||||
},
|
||||
body: JSON.stringify({
|
||||
file_path: filePath,
|
||||
...data
|
||||
})
|
||||
});
|
||||
|
||||
if (!response.ok) {
|
||||
throw new Error('Failed to save metadata');
|
||||
}
|
||||
|
||||
return response.json();
|
||||
} finally {
|
||||
// Always hide the loading indicator when done
|
||||
state.loadingManager.hide();
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Exclude a checkpoint model from being shown in the UI
|
||||
* @param {string} filePath - File path of the checkpoint to exclude
|
||||
* @returns {Promise<boolean>} Promise resolving to success status
|
||||
*/
|
||||
export function excludeCheckpoint(filePath) {
|
||||
return baseExcludeModel(filePath, 'checkpoint');
|
||||
}
|
||||
|
||||
/**
|
||||
* Rename a checkpoint file
|
||||
* @param {string} filePath - Current file path
|
||||
* @param {string} newFileName - New file name (without path)
|
||||
* @returns {Promise<Object>} - Promise that resolves with the server response
|
||||
*/
|
||||
export async function renameCheckpointFile(filePath, newFileName) {
|
||||
try {
|
||||
// Show loading indicator
|
||||
state.loadingManager.showSimpleLoading('Renaming checkpoint file...');
|
||||
|
||||
const response = await fetch('/api/rename_checkpoint', {
|
||||
method: 'POST',
|
||||
headers: {
|
||||
'Content-Type': 'application/json',
|
||||
},
|
||||
body: JSON.stringify({
|
||||
file_path: filePath,
|
||||
new_file_name: newFileName
|
||||
})
|
||||
});
|
||||
|
||||
if (!response.ok) {
|
||||
throw new Error(`Server returned ${response.status}: ${response.statusText}`);
|
||||
}
|
||||
|
||||
return await response.json();
|
||||
} catch (error) {
|
||||
console.error('Error renaming checkpoint file:', error);
|
||||
throw error;
|
||||
} finally {
|
||||
// Hide loading indicator
|
||||
state.loadingManager.hide();
|
||||
}
|
||||
}
|
||||
@@ -1,20 +1,101 @@
|
||||
import { createLoraCard } from '../components/LoraCard.js';
|
||||
import {
|
||||
loadMoreModels,
|
||||
fetchModelsPage,
|
||||
resetAndReload as baseResetAndReload,
|
||||
resetAndReloadWithVirtualScroll,
|
||||
loadMoreWithVirtualScroll,
|
||||
refreshModels as baseRefreshModels,
|
||||
deleteModel as baseDeleteModel,
|
||||
replaceModelPreview,
|
||||
fetchCivitaiMetadata,
|
||||
refreshSingleModelMetadata
|
||||
refreshSingleModelMetadata,
|
||||
excludeModel as baseExcludeModel
|
||||
} from './baseModelApi.js';
|
||||
import { state, getCurrentPageState } from '../state/index.js';
|
||||
|
||||
/**
|
||||
* Save model metadata to the server
|
||||
* @param {string} filePath - File path
|
||||
* @param {Object} data - Data to save
|
||||
* @returns {Promise} Promise of the save operation
|
||||
*/
|
||||
export async function saveModelMetadata(filePath, data) {
|
||||
try {
|
||||
// Show loading indicator
|
||||
state.loadingManager.showSimpleLoading('Saving metadata...');
|
||||
|
||||
const response = await fetch('/api/loras/save-metadata', {
|
||||
method: 'POST',
|
||||
headers: {
|
||||
'Content-Type': 'application/json',
|
||||
},
|
||||
body: JSON.stringify({
|
||||
file_path: filePath,
|
||||
...data
|
||||
})
|
||||
});
|
||||
|
||||
if (!response.ok) {
|
||||
throw new Error('Failed to save metadata');
|
||||
}
|
||||
|
||||
return response.json();
|
||||
} finally {
|
||||
// Always hide the loading indicator when done
|
||||
state.loadingManager.hide();
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Exclude a lora model from being shown in the UI
|
||||
* @param {string} filePath - File path of the model to exclude
|
||||
* @returns {Promise<boolean>} Promise resolving to success status
|
||||
*/
|
||||
export async function excludeLora(filePath) {
|
||||
return baseExcludeModel(filePath, 'lora');
|
||||
}
|
||||
|
||||
/**
|
||||
* Load more loras with pagination - updated to work with VirtualScroller
|
||||
* @param {boolean} resetPage - Whether to reset to the first page
|
||||
* @param {boolean} updateFolders - Whether to update folder tags
|
||||
* @returns {Promise<void>}
|
||||
*/
|
||||
export async function loadMoreLoras(resetPage = false, updateFolders = false) {
|
||||
return loadMoreModels({
|
||||
resetPage,
|
||||
updateFolders,
|
||||
const pageState = getCurrentPageState();
|
||||
|
||||
// Check if virtual scroller is available
|
||||
if (state.virtualScroller) {
|
||||
return loadMoreWithVirtualScroll({
|
||||
modelType: 'lora',
|
||||
resetPage,
|
||||
updateFolders,
|
||||
fetchPageFunction: fetchLorasPage
|
||||
});
|
||||
} else {
|
||||
// Fall back to the original implementation if virtual scroller isn't available
|
||||
return loadMoreModels({
|
||||
resetPage,
|
||||
updateFolders,
|
||||
modelType: 'lora',
|
||||
createCardFunction: createLoraCard,
|
||||
endpoint: '/api/loras'
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Fetch loras with pagination for virtual scrolling
|
||||
* @param {number} page - Page number to fetch
|
||||
* @param {number} pageSize - Number of items per page
|
||||
* @returns {Promise<Object>} Object containing items, total count, and pagination info
|
||||
*/
|
||||
export async function fetchLorasPage(page = 1, pageSize = 100) {
|
||||
return fetchModelsPage({
|
||||
modelType: 'lora',
|
||||
createCardFunction: createLoraCard,
|
||||
page,
|
||||
pageSize,
|
||||
endpoint: '/api/loras'
|
||||
});
|
||||
}
|
||||
@@ -36,28 +117,46 @@ export async function replacePreview(filePath) {
|
||||
}
|
||||
|
||||
export function appendLoraCards(loras) {
|
||||
const grid = document.getElementById('loraGrid');
|
||||
const sentinel = document.getElementById('scroll-sentinel');
|
||||
|
||||
loras.forEach(lora => {
|
||||
const card = createLoraCard(lora);
|
||||
grid.appendChild(card);
|
||||
});
|
||||
// This function is no longer needed with virtual scrolling
|
||||
// but kept for compatibility
|
||||
if (state.virtualScroller) {
|
||||
console.warn('appendLoraCards is deprecated when using virtual scrolling');
|
||||
} else {
|
||||
const grid = document.getElementById('loraGrid');
|
||||
|
||||
loras.forEach(lora => {
|
||||
const card = createLoraCard(lora);
|
||||
grid.appendChild(card);
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
export async function resetAndReload(updateFolders = false) {
|
||||
return baseResetAndReload({
|
||||
updateFolders,
|
||||
modelType: 'lora',
|
||||
loadMoreFunction: loadMoreLoras
|
||||
});
|
||||
const pageState = getCurrentPageState();
|
||||
|
||||
// Check if virtual scroller is available
|
||||
if (state.virtualScroller) {
|
||||
return resetAndReloadWithVirtualScroll({
|
||||
modelType: 'lora',
|
||||
updateFolders,
|
||||
fetchPageFunction: fetchLorasPage
|
||||
});
|
||||
} else {
|
||||
// Fall back to original implementation
|
||||
return baseResetAndReload({
|
||||
updateFolders,
|
||||
modelType: 'lora',
|
||||
loadMoreFunction: loadMoreLoras
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
export async function refreshLoras() {
|
||||
export async function refreshLoras(fullRebuild = false) {
|
||||
return baseRefreshModels({
|
||||
modelType: 'lora',
|
||||
scanEndpoint: '/api/loras/scan',
|
||||
resetAndReloadFunction: resetAndReload
|
||||
resetAndReloadFunction: resetAndReload,
|
||||
fullRebuild: fullRebuild
|
||||
});
|
||||
}
|
||||
|
||||
@@ -82,4 +181,40 @@ export async function fetchModelDescription(modelId, filePath) {
|
||||
console.error('Error fetching model description:', error);
|
||||
throw error;
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Rename a LoRA file
|
||||
* @param {string} filePath - Current file path
|
||||
* @param {string} newFileName - New file name (without path)
|
||||
* @returns {Promise<Object>} - Promise that resolves with the server response
|
||||
*/
|
||||
export async function renameLoraFile(filePath, newFileName) {
|
||||
try {
|
||||
// Show loading indicator
|
||||
state.loadingManager.showSimpleLoading('Renaming LoRA file...');
|
||||
|
||||
const response = await fetch('/api/rename_lora', {
|
||||
method: 'POST',
|
||||
headers: {
|
||||
'Content-Type': 'application/json',
|
||||
},
|
||||
body: JSON.stringify({
|
||||
file_path: filePath,
|
||||
new_file_name: newFileName
|
||||
})
|
||||
});
|
||||
|
||||
if (!response.ok) {
|
||||
throw new Error(`Server returned ${response.status}: ${response.statusText}`);
|
||||
}
|
||||
|
||||
return await response.json();
|
||||
} catch (error) {
|
||||
console.error('Error renaming LoRA file:', error);
|
||||
throw error;
|
||||
} finally {
|
||||
// Hide loading indicator
|
||||
state.loadingManager.hide();
|
||||
}
|
||||
}
|
||||
174
static/js/api/recipeApi.js
Normal file
174
static/js/api/recipeApi.js
Normal file
@@ -0,0 +1,174 @@
|
||||
import { RecipeCard } from '../components/RecipeCard.js';
|
||||
import {
|
||||
fetchModelsPage,
|
||||
resetAndReloadWithVirtualScroll,
|
||||
loadMoreWithVirtualScroll
|
||||
} from './baseModelApi.js';
|
||||
import { state, getCurrentPageState } from '../state/index.js';
|
||||
import { showToast } from '../utils/uiHelpers.js';
|
||||
|
||||
/**
|
||||
* Fetch recipes with pagination for virtual scrolling
|
||||
* @param {number} page - Page number to fetch
|
||||
* @param {number} pageSize - Number of items per page
|
||||
* @returns {Promise<Object>} Object containing items, total count, and pagination info
|
||||
*/
|
||||
export async function fetchRecipesPage(page = 1, pageSize = 100) {
|
||||
const pageState = getCurrentPageState();
|
||||
|
||||
try {
|
||||
const params = new URLSearchParams({
|
||||
page: page,
|
||||
page_size: pageSize || pageState.pageSize || 20,
|
||||
sort_by: pageState.sortBy
|
||||
});
|
||||
|
||||
// If we have a specific recipe ID to load
|
||||
if (pageState.customFilter?.active && pageState.customFilter?.recipeId) {
|
||||
// Special case: load specific recipe
|
||||
const response = await fetch(`/api/recipe/${pageState.customFilter.recipeId}`);
|
||||
|
||||
if (!response.ok) {
|
||||
throw new Error(`Failed to load recipe: ${response.statusText}`);
|
||||
}
|
||||
|
||||
const recipe = await response.json();
|
||||
|
||||
// Return in expected format
|
||||
return {
|
||||
items: [recipe],
|
||||
totalItems: 1,
|
||||
totalPages: 1,
|
||||
currentPage: 1,
|
||||
hasMore: false
|
||||
};
|
||||
}
|
||||
|
||||
// Add custom filter for Lora if present
|
||||
if (pageState.customFilter?.active && pageState.customFilter?.loraHash) {
|
||||
params.append('lora_hash', pageState.customFilter.loraHash);
|
||||
params.append('bypass_filters', 'true');
|
||||
} else {
|
||||
// Normal filtering logic
|
||||
|
||||
// Add search filter if present
|
||||
if (pageState.filters?.search) {
|
||||
params.append('search', pageState.filters.search);
|
||||
|
||||
// Add search option parameters
|
||||
if (pageState.searchOptions) {
|
||||
params.append('search_title', pageState.searchOptions.title.toString());
|
||||
params.append('search_tags', pageState.searchOptions.tags.toString());
|
||||
params.append('search_lora_name', pageState.searchOptions.loraName.toString());
|
||||
params.append('search_lora_model', pageState.searchOptions.loraModel.toString());
|
||||
params.append('fuzzy', 'true');
|
||||
}
|
||||
}
|
||||
|
||||
// Add base model filters
|
||||
if (pageState.filters?.baseModel && pageState.filters.baseModel.length) {
|
||||
params.append('base_models', pageState.filters.baseModel.join(','));
|
||||
}
|
||||
|
||||
// Add tag filters
|
||||
if (pageState.filters?.tags && pageState.filters.tags.length) {
|
||||
params.append('tags', pageState.filters.tags.join(','));
|
||||
}
|
||||
}
|
||||
|
||||
// Fetch recipes
|
||||
const response = await fetch(`/api/recipes?${params.toString()}`);
|
||||
|
||||
if (!response.ok) {
|
||||
throw new Error(`Failed to load recipes: ${response.statusText}`);
|
||||
}
|
||||
|
||||
const data = await response.json();
|
||||
|
||||
return {
|
||||
items: data.items,
|
||||
totalItems: data.total,
|
||||
totalPages: data.total_pages,
|
||||
currentPage: page,
|
||||
hasMore: page < data.total_pages
|
||||
};
|
||||
} catch (error) {
|
||||
console.error('Error fetching recipes:', error);
|
||||
showToast(`Failed to fetch recipes: ${error.message}`, 'error');
|
||||
throw error;
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Reset and reload recipes using virtual scrolling
|
||||
* @param {boolean} updateFolders - Whether to update folder tags
|
||||
* @returns {Promise<Object>} The fetch result
|
||||
*/
|
||||
export async function resetAndReload(updateFolders = false) {
|
||||
return resetAndReloadWithVirtualScroll({
|
||||
modelType: 'recipe',
|
||||
updateFolders,
|
||||
fetchPageFunction: fetchRecipesPage
|
||||
});
|
||||
}
|
||||
|
||||
/**
|
||||
* Refreshes the recipe list by first rebuilding the cache and then loading recipes
|
||||
*/
|
||||
export async function refreshRecipes() {
|
||||
try {
|
||||
state.loadingManager.showSimpleLoading('Refreshing recipes...');
|
||||
|
||||
// Call the API endpoint to rebuild the recipe cache
|
||||
const response = await fetch('/api/recipes/scan');
|
||||
|
||||
if (!response.ok) {
|
||||
const data = await response.json();
|
||||
throw new Error(data.error || 'Failed to refresh recipe cache');
|
||||
}
|
||||
|
||||
// After successful cache rebuild, reload the recipes
|
||||
await resetAndReload();
|
||||
|
||||
showToast('Refresh complete', 'success');
|
||||
} catch (error) {
|
||||
console.error('Error refreshing recipes:', error);
|
||||
showToast(error.message || 'Failed to refresh recipes', 'error');
|
||||
} finally {
|
||||
state.loadingManager.hide();
|
||||
state.loadingManager.restoreProgressBar();
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Load more recipes with pagination - updated to work with VirtualScroller
|
||||
* @param {boolean} resetPage - Whether to reset to the first page
|
||||
* @returns {Promise<void>}
|
||||
*/
|
||||
export async function loadMoreRecipes(resetPage = false) {
|
||||
const pageState = getCurrentPageState();
|
||||
|
||||
// Use virtual scroller if available
|
||||
if (state.virtualScroller) {
|
||||
return loadMoreWithVirtualScroll({
|
||||
modelType: 'recipe',
|
||||
resetPage,
|
||||
updateFolders: false,
|
||||
fetchPageFunction: fetchRecipesPage
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Create a recipe card instance from recipe data
|
||||
* @param {Object} recipe - Recipe data
|
||||
* @returns {HTMLElement} Recipe card DOM element
|
||||
*/
|
||||
export function createRecipeCard(recipe) {
|
||||
const recipeCard = new RecipeCard(recipe, (recipe) => {
|
||||
if (window.recipeManager) {
|
||||
window.recipeManager.showRecipeDetails(recipe);
|
||||
}
|
||||
});
|
||||
return recipeCard.element;
|
||||
}
|
||||
@@ -1,9 +1,10 @@
|
||||
import { appCore } from './core.js';
|
||||
import { initializeInfiniteScroll } from './utils/infiniteScroll.js';
|
||||
import { confirmDelete, closeDeleteModal } from './utils/modalUtils.js';
|
||||
import { confirmDelete, closeDeleteModal, confirmExclude, closeExcludeModal } from './utils/modalUtils.js';
|
||||
import { createPageControls } from './components/controls/index.js';
|
||||
import { loadMoreCheckpoints } from './api/checkpointApi.js';
|
||||
import { CheckpointDownloadManager } from './managers/CheckpointDownloadManager.js';
|
||||
import { CheckpointContextMenu } from './components/ContextMenu/index.js';
|
||||
import { ModelDuplicatesManager } from './components/ModelDuplicatesManager.js';
|
||||
|
||||
// Initialize the Checkpoints page
|
||||
class CheckpointsPageManager {
|
||||
@@ -14,6 +15,9 @@ class CheckpointsPageManager {
|
||||
// Initialize checkpoint download manager
|
||||
window.checkpointDownloadManager = new CheckpointDownloadManager();
|
||||
|
||||
// Initialize the ModelDuplicatesManager
|
||||
this.duplicatesManager = new ModelDuplicatesManager(this, 'checkpoints');
|
||||
|
||||
// Expose only necessary functions to global scope
|
||||
this._exposeRequiredGlobalFunctions();
|
||||
}
|
||||
@@ -22,11 +26,16 @@ class CheckpointsPageManager {
|
||||
// Minimal set of functions that need to remain global
|
||||
window.confirmDelete = confirmDelete;
|
||||
window.closeDeleteModal = closeDeleteModal;
|
||||
window.confirmExclude = confirmExclude;
|
||||
window.closeExcludeModal = closeExcludeModal;
|
||||
|
||||
// Add loadCheckpoints function to window for FilterManager compatibility
|
||||
window.checkpointManager = {
|
||||
loadCheckpoints: (reset) => loadMoreCheckpoints(reset)
|
||||
};
|
||||
|
||||
// Expose duplicates manager
|
||||
window.modelDuplicatesManager = this.duplicatesManager;
|
||||
}
|
||||
|
||||
async initialize() {
|
||||
@@ -34,8 +43,8 @@ class CheckpointsPageManager {
|
||||
this.pageControls.restoreFolderFilter();
|
||||
this.pageControls.initFolderTagsVisibility();
|
||||
|
||||
// Initialize infinite scroll
|
||||
initializeInfiniteScroll('checkpoints');
|
||||
// Initialize context menu
|
||||
new CheckpointContextMenu();
|
||||
|
||||
// Initialize common page features
|
||||
appCore.initializePageFeatures();
|
||||
|
||||
@@ -1,8 +1,9 @@
|
||||
import { showToast } from '../utils/uiHelpers.js';
|
||||
import { showToast, copyToClipboard, openExampleImagesFolder } from '../utils/uiHelpers.js';
|
||||
import { state } from '../state/index.js';
|
||||
import { showCheckpointModal } from './checkpointModal/index.js';
|
||||
import { NSFW_LEVELS } from '../utils/constants.js';
|
||||
import { replaceCheckpointPreview as apiReplaceCheckpointPreview } from '../api/checkpointApi.js';
|
||||
import { replaceCheckpointPreview as apiReplaceCheckpointPreview, saveModelMetadata } from '../api/checkpointApi.js';
|
||||
import { showDeleteModal } from '../utils/modalUtils.js';
|
||||
|
||||
export function createCheckpointCard(checkpoint) {
|
||||
const card = document.createElement('div');
|
||||
@@ -17,6 +18,7 @@ export function createCheckpointCard(checkpoint) {
|
||||
card.dataset.from_civitai = checkpoint.from_civitai;
|
||||
card.dataset.notes = checkpoint.notes || '';
|
||||
card.dataset.base_model = checkpoint.base_model || 'Unknown';
|
||||
card.dataset.favorite = checkpoint.favorite ? 'true' : 'false';
|
||||
|
||||
// Store metadata if available
|
||||
if (checkpoint.civitai) {
|
||||
@@ -44,7 +46,10 @@ export function createCheckpointCard(checkpoint) {
|
||||
|
||||
// Determine preview URL
|
||||
const previewUrl = checkpoint.preview_url || '/loras_static/images/no-preview.png';
|
||||
const version = state.previewVersions ? state.previewVersions.get(checkpoint.file_path) : null;
|
||||
|
||||
// Get the page-specific previewVersions map
|
||||
const previewVersions = state.pages.checkpoints.previewVersions || new Map();
|
||||
const version = previewVersions.get(checkpoint.file_path);
|
||||
const versionedPreviewUrl = version ? `${previewUrl}?t=${version}` : previewUrl;
|
||||
|
||||
// Determine NSFW warning text based on level
|
||||
@@ -62,6 +67,9 @@ export function createCheckpointCard(checkpoint) {
|
||||
const isVideo = previewUrl.endsWith('.mp4');
|
||||
const videoAttrs = autoplayOnHover ? 'controls muted loop' : 'controls autoplay muted loop';
|
||||
|
||||
// Get favorite status from checkpoint data
|
||||
const isFavorite = checkpoint.favorite === true;
|
||||
|
||||
card.innerHTML = `
|
||||
<div class="card-preview ${shouldBlur ? 'blurred' : ''}">
|
||||
${isVideo ?
|
||||
@@ -79,6 +87,9 @@ export function createCheckpointCard(checkpoint) {
|
||||
${checkpoint.base_model}
|
||||
</span>
|
||||
<div class="card-actions">
|
||||
<i class="${isFavorite ? 'fas fa-star favorite-active' : 'far fa-star'}"
|
||||
title="${isFavorite ? 'Remove from favorites' : 'Add to favorites'}">
|
||||
</i>
|
||||
<i class="fas fa-globe"
|
||||
title="${checkpoint.from_civitai ? 'View on Civitai' : 'Not available from Civitai'}"
|
||||
${!checkpoint.from_civitai ? 'style="opacity: 0.5; cursor: not-allowed"' : ''}>
|
||||
@@ -104,8 +115,8 @@ export function createCheckpointCard(checkpoint) {
|
||||
<span class="model-name">${checkpoint.model_name}</span>
|
||||
</div>
|
||||
<div class="card-actions">
|
||||
<i class="fas fa-image"
|
||||
title="Replace Preview Image">
|
||||
<i class="fas fa-folder-open"
|
||||
title="Open Example Images Folder">
|
||||
</i>
|
||||
</div>
|
||||
</div>
|
||||
@@ -195,27 +206,46 @@ export function createCheckpointCard(checkpoint) {
|
||||
});
|
||||
}
|
||||
|
||||
// Favorite button click event
|
||||
card.querySelector('.fa-star')?.addEventListener('click', async e => {
|
||||
e.stopPropagation();
|
||||
const starIcon = e.currentTarget;
|
||||
const isFavorite = starIcon.classList.contains('fas');
|
||||
const newFavoriteState = !isFavorite;
|
||||
|
||||
try {
|
||||
// Save the new favorite state to the server
|
||||
await saveModelMetadata(card.dataset.filepath, {
|
||||
favorite: newFavoriteState
|
||||
});
|
||||
|
||||
// Update the UI
|
||||
if (newFavoriteState) {
|
||||
starIcon.classList.remove('far');
|
||||
starIcon.classList.add('fas', 'favorite-active');
|
||||
starIcon.title = 'Remove from favorites';
|
||||
card.dataset.favorite = 'true';
|
||||
showToast('Added to favorites', 'success');
|
||||
} else {
|
||||
starIcon.classList.remove('fas', 'favorite-active');
|
||||
starIcon.classList.add('far');
|
||||
starIcon.title = 'Add to favorites';
|
||||
card.dataset.favorite = 'false';
|
||||
showToast('Removed from favorites', 'success');
|
||||
}
|
||||
} catch (error) {
|
||||
console.error('Failed to update favorite status:', error);
|
||||
showToast('Failed to update favorite status', 'error');
|
||||
}
|
||||
});
|
||||
|
||||
// Copy button click event
|
||||
card.querySelector('.fa-copy')?.addEventListener('click', async e => {
|
||||
e.stopPropagation();
|
||||
const checkpointName = card.dataset.file_name;
|
||||
|
||||
try {
|
||||
// Modern clipboard API
|
||||
if (navigator.clipboard && window.isSecureContext) {
|
||||
await navigator.clipboard.writeText(checkpointName);
|
||||
} else {
|
||||
// Fallback for older browsers
|
||||
const textarea = document.createElement('textarea');
|
||||
textarea.value = checkpointName;
|
||||
textarea.style.position = 'absolute';
|
||||
textarea.style.left = '-99999px';
|
||||
document.body.appendChild(textarea);
|
||||
textarea.select();
|
||||
document.execCommand('copy');
|
||||
document.body.removeChild(textarea);
|
||||
}
|
||||
showToast('Checkpoint name copied', 'success');
|
||||
await copyToClipboard(checkpointName, 'Checkpoint name copied');
|
||||
} catch (err) {
|
||||
console.error('Copy failed:', err);
|
||||
showToast('Copy failed', 'error');
|
||||
@@ -233,7 +263,7 @@ export function createCheckpointCard(checkpoint) {
|
||||
// Delete button click event
|
||||
card.querySelector('.fa-trash')?.addEventListener('click', e => {
|
||||
e.stopPropagation();
|
||||
deleteCheckpoint(checkpoint.file_path);
|
||||
showDeleteModal(checkpoint.file_path);
|
||||
});
|
||||
|
||||
// Replace preview button click event
|
||||
@@ -242,6 +272,12 @@ export function createCheckpointCard(checkpoint) {
|
||||
replaceCheckpointPreview(checkpoint.file_path);
|
||||
});
|
||||
|
||||
// Open example images folder button click event
|
||||
card.querySelector('.fa-folder-open')?.addEventListener('click', e => {
|
||||
e.stopPropagation();
|
||||
openExampleImagesFolder(checkpoint.sha256);
|
||||
});
|
||||
|
||||
// Add autoplayOnHover handlers for video elements if needed
|
||||
const videoElement = card.querySelector('video');
|
||||
if (videoElement && autoplayOnHover) {
|
||||
@@ -293,17 +329,6 @@ function openCivitai(modelName) {
|
||||
}
|
||||
}
|
||||
|
||||
function deleteCheckpoint(filePath) {
|
||||
if (window.deleteCheckpoint) {
|
||||
window.deleteCheckpoint(filePath);
|
||||
} else {
|
||||
// Use the modal delete functionality
|
||||
import('../utils/modalUtils.js').then(({ showDeleteModal }) => {
|
||||
showDeleteModal(filePath, 'checkpoint');
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
function replaceCheckpointPreview(filePath) {
|
||||
if (window.replaceCheckpointPreview) {
|
||||
window.replaceCheckpointPreview(filePath);
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user