mirror of
https://github.com/willmiao/ComfyUI-Lora-Manager.git
synced 2026-03-21 21:22:11 -03:00
Compare commits
595 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
adf7b6d4b2 | ||
|
|
0566d50346 | ||
|
|
4275dc3003 | ||
|
|
30956aeefc | ||
|
|
64e1dd3dd6 | ||
|
|
0dc4b6f728 | ||
|
|
86074c87d7 | ||
|
|
6f9245df01 | ||
|
|
4540e47055 | ||
|
|
4bb8981e78 | ||
|
|
c49be91aa0 | ||
|
|
2b847039d4 | ||
|
|
1147725fd7 | ||
|
|
26891e12a4 | ||
|
|
2f7e44a76f | ||
|
|
9366d3d2d0 | ||
|
|
6b606a5cc8 | ||
|
|
e5339c178a | ||
|
|
1a76f74482 | ||
|
|
13f13eb095 | ||
|
|
125fdecd61 | ||
|
|
d05076d258 | ||
|
|
00b77581fc | ||
|
|
897787d17c | ||
|
|
d5a280cf2b | ||
|
|
a0c2d9b5ad | ||
|
|
e713bd1ca2 | ||
|
|
beb8ff1dd1 | ||
|
|
6a8f0867d9 | ||
|
|
51ad1c9a33 | ||
|
|
34872eb612 | ||
|
|
8b4e3128ff | ||
|
|
c66cbc800b | ||
|
|
21941521a0 | ||
|
|
0d33884052 | ||
|
|
415df49377 | ||
|
|
f5f45002c7 | ||
|
|
1edf7126bb | ||
|
|
a1a55a1002 | ||
|
|
45f5cb46bd | ||
|
|
1b5e608a27 | ||
|
|
a7df8ae15c | ||
|
|
47ce0d0fe2 | ||
|
|
b220e288d0 | ||
|
|
1fc8b45b68 | ||
|
|
62f06302f0 | ||
|
|
3e5cb223f3 | ||
|
|
4ee5b7481c | ||
|
|
e104b78c01 | ||
|
|
ba1ac58721 | ||
|
|
a4fbeb6295 | ||
|
|
68f8871403 | ||
|
|
6fd74952b7 | ||
|
|
1ea468cfc4 | ||
|
|
14721c265f | ||
|
|
821827a375 | ||
|
|
9ba3e2c204 | ||
|
|
d287883671 | ||
|
|
ead34818db | ||
|
|
a060010b96 | ||
|
|
76a92ac847 | ||
|
|
74bc490383 | ||
|
|
510d476323 | ||
|
|
1e7257fd53 | ||
|
|
4ff1f51b1c | ||
|
|
74507cef05 | ||
|
|
c23ab04d90 | ||
|
|
d50dde6cf6 | ||
|
|
fcb1fb39be | ||
|
|
b0ef74f802 | ||
|
|
f332aef41d | ||
|
|
1f91a3da8e | ||
|
|
16840c321d | ||
|
|
c109e392ad | ||
|
|
5e69671366 | ||
|
|
52d23d9b75 | ||
|
|
4c4e6d7a7b | ||
|
|
03b6e78705 | ||
|
|
24c01141d7 | ||
|
|
6dc2811af4 | ||
|
|
e6425dce32 | ||
|
|
95e2ff5f1e | ||
|
|
92ac487128 | ||
|
|
3250fa89cb | ||
|
|
7475de366b | ||
|
|
affb507b37 | ||
|
|
3320b80150 | ||
|
|
fb2b69b787 | ||
|
|
29a05f6533 | ||
|
|
9fa3fac973 | ||
|
|
904b0d104a | ||
|
|
1d31dae110 | ||
|
|
476ecb7423 | ||
|
|
4eb67cf6da | ||
|
|
a5a9f7ed83 | ||
|
|
c0b029e228 | ||
|
|
9bebcc9a4b | ||
|
|
ac7d23011c | ||
|
|
491e09b7b5 | ||
|
|
192bc237bf | ||
|
|
f041f4a114 | ||
|
|
2546580377 | ||
|
|
8fbf2ab56d | ||
|
|
ea727aad2e | ||
|
|
5520aecbba | ||
|
|
6b738a4769 | ||
|
|
903a8050b3 | ||
|
|
31b032429d | ||
|
|
2bcf341f04 | ||
|
|
ca6f45b359 | ||
|
|
2a67cec16b | ||
|
|
1800afe31b | ||
|
|
8c6311355d | ||
|
|
91801dff85 | ||
|
|
be594133f0 | ||
|
|
8a538d117e | ||
|
|
8d9118cbee | ||
|
|
b67464ea13 | ||
|
|
33334da0bb | ||
|
|
40ce2baa7b | ||
|
|
1134466cc0 | ||
|
|
92341111ad | ||
|
|
4956d6781f | ||
|
|
63562240c4 | ||
|
|
84d801cf14 | ||
|
|
b56fe4ca68 | ||
|
|
6c83c65e02 | ||
|
|
a83f020fcc | ||
|
|
7f9a3bf272 | ||
|
|
f80e266d02 | ||
|
|
7bef562541 | ||
|
|
b2428f607c | ||
|
|
8303196b57 | ||
|
|
987b8c8742 | ||
|
|
e60a579b85 | ||
|
|
be8edafed0 | ||
|
|
a258a18fa4 | ||
|
|
59010ca431 | ||
|
|
75f3764e6c | ||
|
|
867ffd1163 | ||
|
|
6acccbbb94 | ||
|
|
b2c4efab45 | ||
|
|
408a435b71 | ||
|
|
36d3cd93d5 | ||
|
|
b36fea002e | ||
|
|
52acbd954a | ||
|
|
f6709a55c3 | ||
|
|
7b374d747b | ||
|
|
fd480a9360 | ||
|
|
ec8b228867 | ||
|
|
401200050b | ||
|
|
29160bd6e5 | ||
|
|
3c9e402bc0 | ||
|
|
ff4d0f0208 | ||
|
|
f82908221c | ||
|
|
4246908f2e | ||
|
|
f64597afd2 | ||
|
|
975ff2672d | ||
|
|
e90ba31784 | ||
|
|
a4074c93bc | ||
|
|
7a8b7598c7 | ||
|
|
cd0d832f14 | ||
|
|
5b0becaaf2 | ||
|
|
9817bac2fe | ||
|
|
f6bd48cfcd | ||
|
|
01843b8f2b | ||
|
|
94ed81de5e | ||
|
|
0700b8f399 | ||
|
|
d62cff9841 | ||
|
|
083f4805b2 | ||
|
|
8e5bfd379e | ||
|
|
2366f143d8 | ||
|
|
e997f5bc1b | ||
|
|
842beec7cc | ||
|
|
d2268fc9e0 | ||
|
|
a98e26139f | ||
|
|
522a3ea88b | ||
|
|
d7949fbc30 | ||
|
|
6df083a1d5 | ||
|
|
4dc80e7f6e | ||
|
|
c2a8508513 | ||
|
|
159193ef43 | ||
|
|
1f37ffb105 | ||
|
|
919fed05c5 | ||
|
|
1814f83bee | ||
|
|
1823840456 | ||
|
|
623c28bfc3 | ||
|
|
3079131337 | ||
|
|
a34ade0120 | ||
|
|
e9ada70088 | ||
|
|
597cc48248 | ||
|
|
ec3f857ef1 | ||
|
|
383b4de539 | ||
|
|
1bf9326604 | ||
|
|
d9f5459d46 | ||
|
|
e45a1b1e19 | ||
|
|
331ad8f644 | ||
|
|
52fa88b04c | ||
|
|
8895a64d24 | ||
|
|
fdec535559 | ||
|
|
6c5559ae2d | ||
|
|
9f54622b17 | ||
|
|
03b6f4b378 | ||
|
|
af4cbe2332 | ||
|
|
141f72963a | ||
|
|
3d3c66e12f | ||
|
|
ee84571bdb | ||
|
|
6500936aad | ||
|
|
32d2b6c013 | ||
|
|
05df40977d | ||
|
|
5d7a1dcde5 | ||
|
|
9c45d9db6c | ||
|
|
ca692ed0f2 | ||
|
|
af499565d3 | ||
|
|
fe2d7e3a9e | ||
|
|
9f69822221 | ||
|
|
bb43f047c2 | ||
|
|
2356662492 | ||
|
|
1624a45093 | ||
|
|
dcb9983786 | ||
|
|
83d1828905 | ||
|
|
6a281cf3ee | ||
|
|
ed1cd39a6c | ||
|
|
dda19b3920 | ||
|
|
25139ca922 | ||
|
|
3cd57a582c | ||
|
|
d3903ac655 | ||
|
|
199e374318 | ||
|
|
8375c1413d | ||
|
|
9e268cf016 | ||
|
|
112b3abc26 | ||
|
|
a8331a2357 | ||
|
|
52e3ad08c1 | ||
|
|
8d01d04ef0 | ||
|
|
a141384907 | ||
|
|
b8aa7184bd | ||
|
|
e4195f874d | ||
|
|
d04deff5ca | ||
|
|
20ce0778a0 | ||
|
|
5a0b3470f1 | ||
|
|
a920921570 | ||
|
|
286f4ff384 | ||
|
|
71ddfafa98 | ||
|
|
b7e3e53697 | ||
|
|
16df548b77 | ||
|
|
425c33ae00 | ||
|
|
c9289ed2dc | ||
|
|
96517cbdef | ||
|
|
b03420faac | ||
|
|
65a1aa7ca2 | ||
|
|
3a92e8eaf9 | ||
|
|
a8dc50d64a | ||
|
|
3397cc7d8d | ||
|
|
c3e8131b24 | ||
|
|
f8ca8584ae | ||
|
|
3050bbe260 | ||
|
|
e1dda2795a | ||
|
|
6d8408e626 | ||
|
|
0906271aa9 | ||
|
|
4c33c9d256 | ||
|
|
fa9c78209f | ||
|
|
6678ec8a60 | ||
|
|
854e467c12 | ||
|
|
e6b94c7b21 | ||
|
|
2c6f9d8602 | ||
|
|
c74033b9c0 | ||
|
|
d2b21d27bb | ||
|
|
215272469f | ||
|
|
f7d05ab0f1 | ||
|
|
6f2ad2be77 | ||
|
|
66575c719a | ||
|
|
677a239d53 | ||
|
|
3b96bfe5af | ||
|
|
83be5cfa64 | ||
|
|
6b834c2362 | ||
|
|
7abfc49e08 | ||
|
|
65d5f50088 | ||
|
|
4f1f4ffe3d | ||
|
|
b0c2027a1c | ||
|
|
33c83358b0 | ||
|
|
31223f0526 | ||
|
|
92daadb92c | ||
|
|
fae2e274fd | ||
|
|
342a722991 | ||
|
|
65ec6aacb7 | ||
|
|
9387470c69 | ||
|
|
31f6edf8f0 | ||
|
|
487b062175 | ||
|
|
d8e13de096 | ||
|
|
e8a30088ef | ||
|
|
bf7b07ba74 | ||
|
|
28fe3e7b7a | ||
|
|
c0eff2bb5e | ||
|
|
848c1741fe | ||
|
|
1370b8e8c1 | ||
|
|
82a068e610 | ||
|
|
32f42bafaa | ||
|
|
4081b7f022 | ||
|
|
a5808193a6 | ||
|
|
854ca322c1 | ||
|
|
c1d9b5137a | ||
|
|
f33d5745b3 | ||
|
|
d89c2ca128 | ||
|
|
835584cc85 | ||
|
|
b2ffbe3a68 | ||
|
|
defcc79e6c | ||
|
|
c06d9f84f0 | ||
|
|
fe57a8e156 | ||
|
|
b77105795a | ||
|
|
e2df5fcf27 | ||
|
|
836a64e728 | ||
|
|
08ba0c9f42 | ||
|
|
6fcc6a5299 | ||
|
|
6dd58248c6 | ||
|
|
2786801b71 | ||
|
|
ea29cbeb7a | ||
|
|
3cf9121a8c | ||
|
|
381bd3938a | ||
|
|
e4ce384023 | ||
|
|
12d1857b13 | ||
|
|
0d9003dea4 | ||
|
|
1a3751acfa | ||
|
|
c5a3af2399 | ||
|
|
ea8a64fafc | ||
|
|
981e367bf1 | ||
|
|
a3d6e62035 | ||
|
|
7f205cdcc8 | ||
|
|
e587189880 | ||
|
|
206c1bd69f | ||
|
|
a7d9255c2c | ||
|
|
08265a85ec | ||
|
|
1ed5630464 | ||
|
|
c784615f11 | ||
|
|
26d51b1190 | ||
|
|
d83fad6abc | ||
|
|
692796db46 | ||
|
|
f15c6f33f9 | ||
|
|
dda9eb4d7c | ||
|
|
6f3aeb61e7 | ||
|
|
d6145e633f | ||
|
|
07014d98ce | ||
|
|
e8ccdabe6c | ||
|
|
cf9fd2d5c2 | ||
|
|
bf9aa9356b | ||
|
|
68d00ce289 | ||
|
|
5288021e4f | ||
|
|
4d38add291 | ||
|
|
804808da4a | ||
|
|
298a95432d | ||
|
|
a834fc4b30 | ||
|
|
2c6c9542dd | ||
|
|
a9a7f4c8ec | ||
|
|
ea9370443d | ||
|
|
c2e00b240e | ||
|
|
a2b81ea099 | ||
|
|
ee609e8eac | ||
|
|
e04ef671e9 | ||
|
|
0184dfd7eb | ||
|
|
eccfa0ca54 | ||
|
|
6d3feb4bef | ||
|
|
29d2b5ee4b | ||
|
|
c82fabb67f | ||
|
|
fcfc868e57 | ||
|
|
67b403f8ca | ||
|
|
de06c6b2f6 | ||
|
|
fa444dfb8a | ||
|
|
124002a472 | ||
|
|
0c883433c1 | ||
|
|
bcf3b2cf55 | ||
|
|
357c4e9c08 | ||
|
|
9edfc68e91 | ||
|
|
8c06cb3e80 | ||
|
|
144fa0a6d4 | ||
|
|
25d5a1541e | ||
|
|
a579d36389 | ||
|
|
d766dac341 | ||
|
|
b15ef1bbc6 | ||
|
|
3e52e00597 | ||
|
|
f749dd0d52 | ||
|
|
48a8a42108 | ||
|
|
db7f57a5a4 | ||
|
|
556381b983 | ||
|
|
158d7d5898 | ||
|
|
18844da95d | ||
|
|
7e0df4d718 | ||
|
|
0dbb76e8c8 | ||
|
|
f73b3422a6 | ||
|
|
bd95e802ec | ||
|
|
5de16a78c5 | ||
|
|
6f8e09fcde | ||
|
|
f54d480f03 | ||
|
|
e68b213fb3 | ||
|
|
132334d500 | ||
|
|
a6f04c6d7e | ||
|
|
854e8bf356 | ||
|
|
6ff883d2d3 | ||
|
|
849b97afba | ||
|
|
1bd2635864 | ||
|
|
79ab0f7b6c | ||
|
|
79011bd257 | ||
|
|
c692713ffb | ||
|
|
df9b554ce1 | ||
|
|
277a8e4682 | ||
|
|
acb52dba09 | ||
|
|
8f10765254 | ||
|
|
0653f59473 | ||
|
|
7a4b5a4667 | ||
|
|
49c4a4068b | ||
|
|
40ad590046 | ||
|
|
30374ae3e6 | ||
|
|
ab22d16bad | ||
|
|
971cd56a4a | ||
|
|
d7cb546c5f | ||
|
|
9d8b7344cd | ||
|
|
2d4f6ae7ce | ||
|
|
d9126807b0 | ||
|
|
cad5fb3fba | ||
|
|
afe23ad6b7 | ||
|
|
fc4327087b | ||
|
|
71762d788f | ||
|
|
6472e00fb0 | ||
|
|
4043846767 | ||
|
|
d3b2bc962c | ||
|
|
54f7b64821 | ||
|
|
82a2a6e669 | ||
|
|
6376d60af5 | ||
|
|
b1e2e3831f | ||
|
|
5de1c8aa82 | ||
|
|
63dc5c2bdb | ||
|
|
7f2d1670a0 | ||
|
|
53c8c337fc | ||
|
|
5b4ec1b2a2 | ||
|
|
64dd2ed141 | ||
|
|
eb57e04e95 | ||
|
|
ae905c8630 | ||
|
|
c157e794f0 | ||
|
|
ed9bae6f6a | ||
|
|
9fe1ce19ad | ||
|
|
6148236cbd | ||
|
|
2471eb518a | ||
|
|
8931b41c76 | ||
|
|
7f523f167d | ||
|
|
446b6d6158 | ||
|
|
2ee057e19b | ||
|
|
afc810f21f | ||
|
|
357052a903 | ||
|
|
39d6d8d04a | ||
|
|
888896c0c0 | ||
|
|
ceee482ecc | ||
|
|
d0ed1213d8 | ||
|
|
f6ef428008 | ||
|
|
e726c4f442 | ||
|
|
402318e586 | ||
|
|
b198cc2a6e | ||
|
|
c3dd4da11b | ||
|
|
ba2e42b06e | ||
|
|
fa0902dc74 | ||
|
|
8fcb6083dc | ||
|
|
1ef88140e3 | ||
|
|
aa34c4c84c | ||
|
|
32d12bb334 | ||
|
|
1b2a02cb1a | ||
|
|
2ff11a16c4 | ||
|
|
441af82dbd | ||
|
|
e09c09af6f | ||
|
|
3721fe226f | ||
|
|
8ace0e11cf | ||
|
|
5e249b0b59 | ||
|
|
4889955ecf | ||
|
|
d840fd53da | ||
|
|
a61819cdb3 | ||
|
|
e986fbb5fb | ||
|
|
8f4d575ec8 | ||
|
|
605a06317b | ||
|
|
a7304ccf47 | ||
|
|
374e2bd4b9 | ||
|
|
09a3246ddb | ||
|
|
a615603866 | ||
|
|
1ca05808e1 | ||
|
|
5febc2a805 | ||
|
|
3c047bee58 | ||
|
|
022c6c157a | ||
|
|
fa587d5678 | ||
|
|
afa5a42f5a | ||
|
|
71df8ba3e2 | ||
|
|
8764998e8c | ||
|
|
2cb4f3aac8 | ||
|
|
1ccaf33aac | ||
|
|
cb0a8e0413 | ||
|
|
8674168df4 | ||
|
|
2221653801 | ||
|
|
78bcdcef5d | ||
|
|
672fbe2ac0 | ||
|
|
56a5970b44 | ||
|
|
a66cef7cfe | ||
|
|
c0b1c2e099 | ||
|
|
9e553bb87b | ||
|
|
f966514bc7 | ||
|
|
dc0a49f96d | ||
|
|
65c783c024 | ||
|
|
6395836fbb | ||
|
|
a7207084ef | ||
|
|
27ef1f1e71 | ||
|
|
68fdb14cd6 | ||
|
|
c2af282a85 | ||
|
|
92d48335cb | ||
|
|
78cac2edc2 | ||
|
|
26d105c439 | ||
|
|
7fec107b98 | ||
|
|
eb01ad3af9 | ||
|
|
e0d9880b32 | ||
|
|
e81e96f0ab | ||
|
|
06d5bd259c | ||
|
|
14238b8d62 | ||
|
|
3b51886927 | ||
|
|
a295ff2e06 | ||
|
|
18cdaabf5e | ||
|
|
787e37b7c6 | ||
|
|
4e5c8b2dd0 | ||
|
|
d8ddacde38 | ||
|
|
bb1e42f0d3 | ||
|
|
923669c495 | ||
|
|
7a4139544c | ||
|
|
4d6ea0236b | ||
|
|
e872a06f22 | ||
|
|
647bda2160 | ||
|
|
c1e93d23f3 | ||
|
|
c96550cc68 | ||
|
|
b1015ecdc5 | ||
|
|
f1b928a037 | ||
|
|
16c312c90b | ||
|
|
110ffd0118 | ||
|
|
35ad872419 | ||
|
|
9b943cf2b8 | ||
|
|
9d1b357e64 | ||
|
|
9fc2fb4d17 | ||
|
|
641fa8a3d9 | ||
|
|
add9269706 | ||
|
|
1a01c4a344 | ||
|
|
b4e7feed06 | ||
|
|
4b96c650eb | ||
|
|
107aef3785 | ||
|
|
b49807824f | ||
|
|
e5ef2ef8b5 | ||
|
|
88779ed56c | ||
|
|
8b59fb6adc | ||
|
|
7945647b0b | ||
|
|
2d39b84806 | ||
|
|
e151a19fcf | ||
|
|
99d2ba26b9 | ||
|
|
396924f4cc | ||
|
|
7545312229 | ||
|
|
26f9779fbf | ||
|
|
0bd62eef3a | ||
|
|
e06d15f508 | ||
|
|
aa1ee96bc9 | ||
|
|
355c73512d | ||
|
|
0daf9d92ff | ||
|
|
37de26ce25 | ||
|
|
0eaef7e7a0 | ||
|
|
8063cee3cd | ||
|
|
cbb25b4ac0 | ||
|
|
c62206a157 | ||
|
|
09832141d0 | ||
|
|
bf8e121a10 | ||
|
|
68568073ec | ||
|
|
ec36524c35 | ||
|
|
67acd9fd2c | ||
|
|
f7be5c8d25 | ||
|
|
ceacac75e0 | ||
|
|
bae66f94e8 | ||
|
|
ddf132bd78 | ||
|
|
afb012029f | ||
|
|
651e14c8c3 | ||
|
|
e7c626eb5f | ||
|
|
a0b0d40a19 | ||
|
|
42e3ab9e27 | ||
|
|
6e5f333364 | ||
|
|
f33a9abe60 | ||
|
|
7f1bbdd615 | ||
|
|
d3bf8eaceb | ||
|
|
b9c9d602de | ||
|
|
b25fbd6e24 | ||
|
|
6052608a4e | ||
|
|
a073b82751 | ||
|
|
8250acdfb5 | ||
|
|
8e1f73a34e | ||
|
|
50704bc882 | ||
|
|
35d34e3513 | ||
|
|
ea834f3de6 | ||
|
|
11aedde72f | ||
|
|
488654abc8 | ||
|
|
da1be0dc65 | ||
|
|
d0c728a339 | ||
|
|
66c66c4d9b |
1
.github/FUNDING.yml
vendored
1
.github/FUNDING.yml
vendored
@@ -1,4 +1,5 @@
|
||||
# These are supported funding model platforms
|
||||
|
||||
patreon: PixelPawsAI
|
||||
ko_fi: pixelpawsai
|
||||
custom: ['paypal.me/pixelpawsai']
|
||||
|
||||
1
.github/copilot-instructions.md
vendored
Normal file
1
.github/copilot-instructions.md
vendored
Normal file
@@ -0,0 +1 @@
|
||||
Always use English for comments.
|
||||
3
.gitignore
vendored
3
.gitignore
vendored
@@ -1,5 +1,8 @@
|
||||
__pycache__/
|
||||
settings.json
|
||||
path_mappings.yaml
|
||||
output/*
|
||||
py/run_test.py
|
||||
.vscode/
|
||||
cache/
|
||||
civitai/
|
||||
|
||||
164
README.md
164
README.md
@@ -9,117 +9,78 @@
|
||||
A comprehensive toolset that streamlines organizing, downloading, and applying LoRA models in ComfyUI. With powerful features like recipe management, checkpoint organization, and one-click workflow integration, working with models becomes faster, smoother, and significantly easier. Access the interface at: `http://localhost:8188/loras`
|
||||
|
||||

|
||||

|
||||
|
||||
## 📺 Tutorial: One-Click LoRA Integration
|
||||
Watch this quick tutorial to learn how to use the new one-click LoRA integration feature:
|
||||
|
||||
[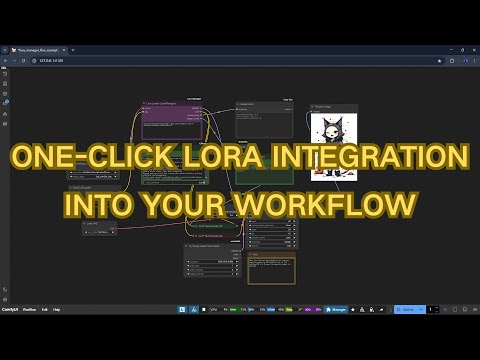](https://youtu.be/qS95OjX3e70)
|
||||
[](https://youtu.be/VKvTlCB78h4)
|
||||
[](https://youtu.be/hvKw31YpE-U)
|
||||
|
||||
## 🌐 Browser Extension
|
||||
Enhance your Civitai browsing experience with our companion browser extension! See which models you already have, download new ones with a single click, and manage your downloads efficiently.
|
||||
|
||||

|
||||
|
||||
<div>
|
||||
<a href="https://chromewebstore.google.com/detail/lm-civitai-extension/capigligggeijgmocnaflanlbghnamgm?utm_source=item-share-cb" style="display: inline-block; background-color: #4285F4; color: white; padding: 8px 16px; text-decoration: none; border-radius: 4px; font-weight: bold; margin: 10px 0;">
|
||||
<img src="https://www.google.com/chrome/static/images/chrome-logo.svg" width="20" style="vertical-align: middle; margin-right: 8px;"> Get Extension from Chrome Web Store
|
||||
</a>
|
||||
</div>
|
||||
|
||||
<div id="firefox-install" class="install-ok"><a href="https://github.com/willmiao/lm-civitai-extension-firefox/releases/latest/download/extension.xpi">📦 Install Firefox Extension (reviewed and verified by Mozilla)</a></div>
|
||||
|
||||
📚 [Learn More: Complete Tutorial](https://github.com/willmiao/ComfyUI-Lora-Manager/wiki/LoRA-Manager-Civitai-Extension-(Chrome-Extension))
|
||||
|
||||
---
|
||||
|
||||
## Release Notes
|
||||
|
||||
### v0.8.15
|
||||
* **Enhanced One-Click Integration** - Replaced copy button with direct send button allowing LoRAs/recipes to be sent directly to your current ComfyUI workflow without needing to paste
|
||||
* **Flexible Workflow Integration** - Click to append LoRAs/recipes to existing loader nodes or Shift+click to replace content, with additional right-click menu options for "Send to Workflow (Append)" or "Send to Workflow (Replace)"
|
||||
* **Improved LoRA Loader Controls** - Added header drag functionality for proportional strength adjustment of all LoRAs simultaneously (including CLIP strengths when expanded)
|
||||
* **Keyboard Navigation Support** - Implemented Page Up/Down for page scrolling, Home key to jump to top, and End key to jump to bottom for faster browsing through large collections
|
||||
### v0.9.3
|
||||
* **Metadata Archive Database Support** - Added the ability to download and utilize a metadata archive database, enabling access to metadata for models that have been deleted from CivitAI.
|
||||
* **App-Level Proxy Settings** - Introduced support for configuring a global proxy within the application, making it easier to use the manager behind network restrictions.
|
||||
* **Bug Fixes** - Various bug fixes for improved stability and reliability.
|
||||
|
||||
### v0.8.14
|
||||
* **Virtualized Scrolling** - Completely rebuilt rendering mechanism for smooth browsing with no lag or freezing, now supporting virtually unlimited model collections with optimized layouts for large displays, improving space utilization and user experience
|
||||
* **Compact Display Mode** - Added space-efficient view option that displays more cards per row (7 on 1080p, 8 on 2K, 10 on 4K)
|
||||
* **Enhanced LoRA Node Functionality** - Comprehensive improvements to LoRA loader/stacker nodes including real-time trigger word updates (reflecting any change anywhere in the LoRA chain for precise updates) and expanded context menu with "Copy Notes" and "Copy Trigger Words" options for faster workflow
|
||||
### v0.9.2
|
||||
* **Bulk Auto-Organization Action** - Added a new bulk auto-organization feature. You can now select multiple models and automatically organize them according to your current path template settings for streamlined management.
|
||||
* **Bug Fixes** - Addressed several bugs to improve stability and reliability.
|
||||
|
||||
### v0.8.13
|
||||
* **Enhanced Recipe Management** - Added "Find duplicates" feature to identify and batch delete duplicate recipes with duplicate detection notifications during imports
|
||||
* **Improved Source Tracking** - Source URLs are now saved with recipes imported via URL, allowing users to view original content with one click or manually edit links
|
||||
* **Advanced LoRA Control** - Double-click LoRAs in Loader/Stacker nodes to access expanded CLIP strength controls for more precise adjustments of model and CLIP strength separately
|
||||
* **Lycoris Model Support** - Added compatibility with Lycoris models for expanded creative options
|
||||
* **Bug Fixes & UX Improvements** - Resolved various issues and enhanced overall user experience with numerous optimizations
|
||||
### v0.9.1
|
||||
* **Enhanced Bulk Operations** - Improved bulk operations with Marquee Selection and a bulk operation context menu, providing a more intuitive, desktop-application-like user experience.
|
||||
* **New Bulk Actions** - Added bulk operations for adding tags and setting base models to multiple models simultaneously.
|
||||
|
||||
### v0.8.12
|
||||
* **Enhanced Model Discovery** - Added alphabetical navigation bar to LoRAs page for faster browsing through large collections
|
||||
* **Optimized Example Images** - Improved download logic to automatically refresh stale metadata before fetching example images
|
||||
* **Model Exclusion System** - New right-click option to exclude specific LoRAs or checkpoints from management
|
||||
* **Improved Showcase Experience** - Enhanced interaction in LoRA and checkpoint showcase areas for better usability
|
||||
### v0.9.0
|
||||
* **UI Overhaul for Enhanced Navigation** - Replaced the top flat folder tags with a new folder sidebar and breadcrumb navigation system for a more intuitive folder browsing and selection experience.
|
||||
* **Dual-Mode Folder Sidebar** - The new folder sidebar offers two display modes: 'List Mode,' which mirrors the classic folder view, and 'Tree Mode,' which presents a hierarchical folder structure for effortless navigation through nested directories.
|
||||
* **Internationalization Support** - Introduced multi-language support, now available in English, Simplified Chinese, Traditional Chinese, Spanish, Japanese, Korean, French, Russian, and German. Feedback from native speakers is welcome to improve the translations.
|
||||
* **Automatic Filename Conflict Resolution** - Implemented automatic file renaming (`original name + short hash`) to prevent conflicts when downloading or moving models.
|
||||
* **Performance Optimizations & Bug Fixes** - Various performance improvements and bug fixes for a more stable and responsive experience.
|
||||
|
||||
### v0.8.11
|
||||
* **Offline Image Support** - Added functionality to download and save all model example images locally, ensuring access even when offline or if images are removed from CivitAI or the site is down
|
||||
* **Resilient Download System** - Implemented pause/resume capability with checkpoint recovery that persists through restarts or unexpected exits
|
||||
* **Bug Fixes & Stability** - Resolved various issues to enhance overall reliability and performance
|
||||
### v0.8.30
|
||||
* **Automatic Model Path Correction** - Added auto-correction for model paths in built-in nodes such as Load Checkpoint, Load Diffusion Model, Load LoRA, and other custom nodes with similar functionality. Workflows containing outdated or incorrect model paths will now be automatically updated to reflect the current location of your models.
|
||||
* **Node UI Enhancements** - Improved node interface for a smoother and more intuitive user experience.
|
||||
* **Bug Fixes** - Addressed various bugs to enhance stability and reliability.
|
||||
|
||||
### v0.8.10
|
||||
* **Standalone Mode** - Run LoRA Manager independently from ComfyUI for a lightweight experience that works even with other stable diffusion interfaces
|
||||
* **Portable Edition** - New one-click portable version for easy startup and updates in standalone mode
|
||||
* **Enhanced Metadata Collection** - Added support for SamplerCustomAdvanced node in the metadata collector module
|
||||
* **Improved UI Organization** - Optimized Lora Loader node height to display up to 5 LoRAs at once with scrolling capability for larger collections
|
||||
### v0.8.29
|
||||
* **Enhanced Recipe Imports** - Improved recipe importing with new target folder selection, featuring path input autocomplete and interactive folder tree navigation. Added a "Use Default Path" option when downloading missing LoRAs.
|
||||
* **WanVideo Lora Select Node Update** - Updated the WanVideo Lora Select node with a 'merge_loras' option to match the counterpart node in the WanVideoWrapper node package.
|
||||
* **Autocomplete Conflict Resolution** - Resolved an autocomplete feature conflict in LoRA nodes with pysssss autocomplete.
|
||||
* **Improved Download Functionality** - Enhanced download functionality with resumable downloads and improved error handling.
|
||||
* **Bug Fixes** - Addressed several bugs for improved stability and performance.
|
||||
|
||||
### v0.8.9
|
||||
* **Favorites System** - New functionality to bookmark your favorite LoRAs and checkpoints for quick access and better organization
|
||||
* **Enhanced UI Controls** - Increased model card button sizes for improved usability and easier interaction
|
||||
* **Smoother Page Transitions** - Optimized interface switching between pages, eliminating flash issues particularly noticeable in dark theme
|
||||
* **Bug Fixes & Stability** - Resolved various issues to enhance overall reliability and performance
|
||||
### v0.8.28
|
||||
* **Autocomplete for Node Inputs** - Instantly find and add LoRAs by filename directly in Lora Loader, Lora Stacker, and WanVideo Lora Select nodes. Autocomplete suggestions include preview tooltips and preset weights, allowing you to quickly select LoRAs without opening the LoRA Manager UI.
|
||||
* **Duplicate Notification Control** - Added a switch to duplicates mode, enabling users to turn off duplicate model notifications for a more streamlined experience.
|
||||
* **Download Example Images from Context Menu** - Introduced a new context menu option to download example images for individual models.
|
||||
|
||||
### v0.8.8
|
||||
* **Real-time TriggerWord Updates** - Enhanced TriggerWord Toggle node to instantly update when connected Lora Loader or Lora Stacker nodes change, without requiring workflow execution
|
||||
* **Optimized Metadata Recovery** - Improved utilization of existing .civitai.info files for faster initialization and preservation of metadata from models deleted from CivitAI
|
||||
* **Migration Acceleration** - Further speed improvements for users transitioning from A1111/Forge environments
|
||||
* **Bug Fixes & Stability** - Resolved various issues to enhance overall reliability and performance
|
||||
### v0.8.27
|
||||
* **User Experience Enhancements** - Improved the model download target folder selection with path input autocomplete and interactive folder tree navigation, making it easier and faster to choose where models are saved.
|
||||
* **Default Path Option for Downloads** - Added a "Use Default Path" option when downloading models. When enabled, models are automatically organized and stored according to your configured path template settings.
|
||||
* **Advanced Download Path Templates** - Expanded path template settings, allowing users to set individual templates for LoRA, checkpoint, and embedding models for greater flexibility. Introduced the `{author}` placeholder, enabling automatic organization of model files by creator name.
|
||||
* **Bug Fixes & Stability Improvements** - Addressed various bugs and improved overall stability for a smoother experience.
|
||||
|
||||
### v0.8.7
|
||||
* **Enhanced Context Menu** - Added comprehensive context menu functionality to Recipes and Checkpoints pages for improved workflow
|
||||
* **Interactive LoRA Strength Control** - Implemented drag functionality in LoRA Loader for intuitive strength adjustment
|
||||
* **Metadata Collector Overhaul** - Rebuilt metadata collection system with optimized architecture for better performance
|
||||
* **Improved Save Image Node** - Enhanced metadata capture and image saving performance with the new metadata collector
|
||||
* **Streamlined Recipe Saving** - Optimized Save Recipe functionality to work independently without requiring Preview Image nodes
|
||||
* **Bug Fixes & Stability** - Resolved various issues to enhance overall reliability and performance
|
||||
|
||||
### v0.8.6 Major Update
|
||||
* **Checkpoint Management** - Added comprehensive management for model checkpoints including scanning, searching, filtering, and deletion
|
||||
* **Enhanced Metadata Support** - New capabilities for retrieving and managing checkpoint metadata with improved operations
|
||||
* **Improved Initial Loading** - Optimized cache initialization with visual progress indicators for better user experience
|
||||
|
||||
### v0.8.5
|
||||
* **Enhanced LoRA & Recipe Connectivity** - Added Recipes tab in LoRA details to see all recipes using a specific LoRA
|
||||
* **Improved Navigation** - New shortcuts to jump between related LoRAs and Recipes with one-click navigation
|
||||
* **Video Preview Controls** - Added "Autoplay Videos on Hover" setting to optimize performance and reduce resource usage
|
||||
* **UI Experience Refinements** - Smoother transitions between related content pages
|
||||
|
||||
### v0.8.4
|
||||
* **Node Layout Improvements** - Fixed layout issues with LoRA Loader and Trigger Words Toggle nodes in newer ComfyUI frontend versions
|
||||
* **Recipe LoRA Reconnection** - Added ability to reconnect deleted LoRAs in recipes by clicking the "deleted" badge in recipe details
|
||||
* **Bug Fixes & Stability** - Resolved various issues for improved reliability
|
||||
|
||||
### v0.8.3
|
||||
* **Enhanced Workflow Parser** - Rebuilt workflow analysis engine with improved support for ComfyUI core nodes and easier extensibility
|
||||
* **Improved Recipe System** - Refined the experimental Save Recipe functionality with better workflow integration
|
||||
* **New Save Image Node** - Added experimental node with metadata support for perfect CivitAI compatibility
|
||||
* Supports dynamic filename prefixes with variables [1](https://github.com/nkchocoai/ComfyUI-SaveImageWithMetaData?tab=readme-ov-file#filename_prefix)
|
||||
* **Default LoRA Root Setting** - Added configuration option for setting your preferred LoRA directory
|
||||
|
||||
### v0.8.2
|
||||
* **Faster Initialization for Forge Users** - Improved first-run efficiency by utilizing existing `.json` and `.civitai.info` files from Forge’s CivitAI helper extension, making migration smoother.
|
||||
* **LoRA Filename Editing** - Added support for renaming LoRA files directly within LoRA Manager.
|
||||
* **Recipe Editing** - Users can now edit recipe names and tags.
|
||||
* **Retain Deleted LoRAs in Recipes** - Deleted LoRAs will remain listed in recipes, allowing future functionality to reconnect them once re-obtained.
|
||||
* **Download Missing LoRAs from Recipes** - Easily fetch missing LoRAs associated with a recipe.
|
||||
|
||||
### v0.8.1
|
||||
* **Base Model Correction** - Added support for modifying base model associations to fix incorrect metadata for non-CivitAI LoRAs
|
||||
* **LoRA Loader Flexibility** - Made CLIP input optional for model-only workflows like Hunyuan video generation
|
||||
* **Expanded Recipe Support** - Added compatibility with 3 additional recipe metadata formats
|
||||
* **Enhanced Showcase Images** - Generation parameters now displayed alongside LoRA preview images
|
||||
* **UI Improvements & Bug Fixes** - Various interface refinements and stability enhancements
|
||||
|
||||
### v0.8.0
|
||||
* **Introduced LoRA Recipes** - Create, import, save, and share your favorite LoRA combinations
|
||||
* **Recipe Management System** - Easily browse, search, and organize your LoRA recipes
|
||||
* **Workflow Integration** - Save recipes directly from your workflow with generation parameters preserved
|
||||
* **Simplified Workflow Application** - Quickly apply saved recipes to new projects
|
||||
* **Enhanced UI & UX** - Improved interface design and user experience
|
||||
* **Bug Fixes & Stability** - Resolved various issues and enhanced overall performance
|
||||
### v0.8.26
|
||||
* **Creator Search Option** - Added ability to search models by creator name, making it easier to find models from specific authors.
|
||||
* **Enhanced Node Usability** - Improved user experience for Lora Loader, Lora Stacker, and WanVideo Lora Select nodes by fixing the maximum height of the text input area. Users can now freely and conveniently adjust the LoRA region within these nodes.
|
||||
* **Compatibility Fixes** - Resolved compatibility issues with ComfyUI and certain custom nodes, including ComfyUI-Custom-Scripts, ensuring smoother integration and operation.
|
||||
|
||||
[View Update History](./update_logs.md)
|
||||
|
||||
@@ -138,13 +99,6 @@ Watch this quick tutorial to learn how to use the new one-click LoRA integration
|
||||
- 🚀 **High Performance**
|
||||
- Fast model loading and browsing
|
||||
- Smooth scrolling through large collections
|
||||
- Real-time updates when files change
|
||||
|
||||
- 📂 **Advanced Organization**
|
||||
- Quick search with fuzzy matching
|
||||
- Folder-based categorization
|
||||
- Move LoRAs between folders
|
||||
- Sort by name or date
|
||||
|
||||
- 🌐 **Rich Model Integration**
|
||||
- Direct download from CivitAI
|
||||
@@ -185,10 +139,11 @@ Watch this quick tutorial to learn how to use the new one-click LoRA integration
|
||||
|
||||
### Option 2: **Portable Standalone Edition** (No ComfyUI required)
|
||||
|
||||
1. Download the [Portable Package](https://github.com/willmiao/ComfyUI-Lora-Manager/releases/download/v0.8.10/lora_manager_portable.7z)
|
||||
1. Download the [Portable Package](https://github.com/willmiao/ComfyUI-Lora-Manager/releases/download/v0.9.2/lora_manager_portable.7z)
|
||||
2. Copy the provided `settings.json.example` file to create a new file named `settings.json` in `comfyui-lora-manager` folder
|
||||
3. Edit `settings.json` to include your correct model folder paths and CivitAI API key
|
||||
4. Run run.bat
|
||||
- To change the startup port, edit `run.bat` and modify the parameter (e.g. `--port 9001`)
|
||||
|
||||
### Option 3: **Manual Installation**
|
||||
|
||||
@@ -308,6 +263,8 @@ If you find this project helpful, consider supporting its development:
|
||||
|
||||
[](https://ko-fi.com/pixelpawsai)
|
||||
|
||||
[](https://patreon.com/PixelPawsAI)
|
||||
|
||||
WeChat: [Click to view QR code](https://raw.githubusercontent.com/willmiao/ComfyUI-Lora-Manager/main/static/images/wechat-qr.webp)
|
||||
|
||||
## 💬 Community
|
||||
@@ -316,3 +273,6 @@ Join our Discord community for support, discussions, and updates:
|
||||
[Discord Server](https://discord.gg/vcqNrWVFvM)
|
||||
|
||||
---
|
||||
## Star History
|
||||
|
||||
[](https://star-history.com/#willmiao/ComfyUI-Lora-Manager&Date)
|
||||
|
||||
@@ -1,18 +1,23 @@
|
||||
from .py.lora_manager import LoraManager
|
||||
from .py.nodes.lora_loader import LoraManagerLoader
|
||||
from .py.nodes.lora_loader import LoraManagerLoader, LoraManagerTextLoader
|
||||
from .py.nodes.trigger_word_toggle import TriggerWordToggle
|
||||
from .py.nodes.lora_stacker import LoraStacker
|
||||
from .py.nodes.save_image import SaveImage
|
||||
from .py.nodes.debug_metadata import DebugMetadata
|
||||
from .py.nodes.wanvideo_lora_select import WanVideoLoraSelect
|
||||
from .py.nodes.wanvideo_lora_select_from_text import WanVideoLoraSelectFromText
|
||||
# Import metadata collector to install hooks on startup
|
||||
from .py.metadata_collector import init as init_metadata_collector
|
||||
|
||||
NODE_CLASS_MAPPINGS = {
|
||||
LoraManagerLoader.NAME: LoraManagerLoader,
|
||||
LoraManagerTextLoader.NAME: LoraManagerTextLoader,
|
||||
TriggerWordToggle.NAME: TriggerWordToggle,
|
||||
LoraStacker.NAME: LoraStacker,
|
||||
SaveImage.NAME: SaveImage,
|
||||
DebugMetadata.NAME: DebugMetadata
|
||||
DebugMetadata.NAME: DebugMetadata,
|
||||
WanVideoLoraSelect.NAME: WanVideoLoraSelect,
|
||||
WanVideoLoraSelectFromText.NAME: WanVideoLoraSelectFromText
|
||||
}
|
||||
|
||||
WEB_DIRECTORY = "./web/comfyui"
|
||||
|
||||
182
docs/EventManagementImplementation.md
Normal file
182
docs/EventManagementImplementation.md
Normal file
@@ -0,0 +1,182 @@
|
||||
# Event Management Implementation Summary
|
||||
|
||||
## What Has Been Implemented
|
||||
|
||||
### 1. Enhanced EventManager Class
|
||||
- **Location**: `static/js/utils/EventManager.js`
|
||||
- **Features**:
|
||||
- Priority-based event handling
|
||||
- Conditional execution based on application state
|
||||
- Element filtering (target/exclude selectors)
|
||||
- Mouse button filtering
|
||||
- Automatic cleanup with cleanup functions
|
||||
- State tracking for app modes
|
||||
- Error handling for event handlers
|
||||
|
||||
### 2. BulkManager Integration
|
||||
- **Location**: `static/js/managers/BulkManager.js`
|
||||
- **Migrated Events**:
|
||||
- Global keyboard shortcuts (Ctrl+A, Escape, B key)
|
||||
- Marquee selection events (mousedown, mousemove, mouseup, contextmenu)
|
||||
- State synchronization with EventManager
|
||||
- **Benefits**:
|
||||
- Centralized priority handling
|
||||
- Conditional execution based on modal state
|
||||
- Better coordination with other components
|
||||
|
||||
### 3. UIHelpers Integration
|
||||
- **Location**: `static/js/utils/uiHelpers.js`
|
||||
- **Migrated Events**:
|
||||
- Mouse position tracking for node selector positioning
|
||||
- Node selector click events (outside clicks and selection)
|
||||
- State management for node selector
|
||||
- **Benefits**:
|
||||
- Reduced direct DOM listeners
|
||||
- Coordinated state tracking
|
||||
- Better cleanup
|
||||
|
||||
### 4. ModelCard Integration
|
||||
- **Location**: `static/js/components/shared/ModelCard.js`
|
||||
- **Migrated Events**:
|
||||
- Model card click delegation
|
||||
- Action button handling (star, globe, copy, etc.)
|
||||
- Better return value handling for event propagation
|
||||
- **Benefits**:
|
||||
- Single event listener for all model cards
|
||||
- Priority-based execution
|
||||
- Better event flow control
|
||||
|
||||
### 5. Documentation and Initialization
|
||||
- **EventManagerDocs.md**: Comprehensive documentation
|
||||
- **eventManagementInit.js**: Initialization and global handlers
|
||||
- **Features**:
|
||||
- Global escape key handling
|
||||
- Modal state synchronization
|
||||
- Error handling
|
||||
- Analytics integration points
|
||||
- Cleanup on page unload
|
||||
|
||||
## Application States Tracked
|
||||
|
||||
1. **bulkMode**: When bulk selection mode is active
|
||||
2. **marqueeActive**: When marquee selection is in progress
|
||||
3. **modalOpen**: When any modal dialog is open
|
||||
4. **nodeSelectorActive**: When node selector popup is visible
|
||||
|
||||
## Priority Levels Used
|
||||
|
||||
- **250+**: Critical system events (escape keys)
|
||||
- **200+**: High priority system events (modal close)
|
||||
- **100-199**: Application-level shortcuts (bulk operations)
|
||||
- **80-99**: UI interactions (marquee selection)
|
||||
- **60-79**: Component interactions (model cards)
|
||||
- **10-49**: Tracking and monitoring
|
||||
- **1-9**: Analytics and low-priority tasks
|
||||
|
||||
## Event Flow Examples
|
||||
|
||||
### Bulk Mode Toggle (B key)
|
||||
1. **Priority 100**: BulkManager keyboard handler catches 'b' key
|
||||
2. Toggles bulk mode state
|
||||
3. Updates EventManager state
|
||||
4. Updates UI accordingly
|
||||
5. Stops propagation (returns true)
|
||||
|
||||
### Marquee Selection
|
||||
1. **Priority 80**: BulkManager mousedown handler (only in .models-container, excluding cards/buttons)
|
||||
2. Starts marquee selection
|
||||
3. **Priority 90**: BulkManager mousemove handler (only when marquee active)
|
||||
4. Updates selection rectangle
|
||||
5. **Priority 90**: BulkManager mouseup handler ends selection
|
||||
|
||||
### Model Card Click
|
||||
1. **Priority 60**: ModelCard delegation handler checks for specific elements
|
||||
2. If action button: handles action and stops propagation
|
||||
3. If general card click: continues to other handlers
|
||||
4. Bulk selection may also handle the event if in bulk mode
|
||||
|
||||
## Remaining Event Listeners (Not Yet Migrated)
|
||||
|
||||
### High Priority for Migration
|
||||
1. **SearchManager keyboard events** - Global search shortcuts
|
||||
2. **ModalManager escape handling** - Already integrated with initialization
|
||||
3. **Scroll-based events** - Back to top, virtual scrolling
|
||||
4. **Resize events** - Panel positioning, responsive layouts
|
||||
|
||||
### Medium Priority
|
||||
1. **Form input events** - Tag inputs, settings forms
|
||||
2. **Component-specific events** - Recipe modal, showcase view
|
||||
3. **Sidebar events** - Resize handling, toggle events
|
||||
|
||||
### Low Priority (Can Remain As-Is)
|
||||
1. **VirtualScroller events** - Performance-critical, specialized
|
||||
2. **Component lifecycle events** - Modal open/close callbacks
|
||||
3. **One-time setup events** - Theme initialization, etc.
|
||||
|
||||
## Benefits Achieved
|
||||
|
||||
### Performance Improvements
|
||||
- **Reduced DOM listeners**: From ~15+ individual listeners to ~5 coordinated handlers
|
||||
- **Conditional execution**: Handlers only run when conditions are met
|
||||
- **Priority ordering**: Important events handled first
|
||||
- **Better memory management**: Automatic cleanup prevents leaks
|
||||
|
||||
### Coordination Improvements
|
||||
- **State synchronization**: All components aware of app state
|
||||
- **Event flow control**: Proper propagation stopping
|
||||
- **Conflict resolution**: Priority system prevents conflicts
|
||||
- **Debugging**: Centralized event handling for easier debugging
|
||||
|
||||
### Code Quality Improvements
|
||||
- **Consistent patterns**: All event handling follows same patterns
|
||||
- **Better separation of concerns**: Event logic separated from business logic
|
||||
- **Error handling**: Centralized error catching and reporting
|
||||
- **Documentation**: Clear patterns for future development
|
||||
|
||||
## Next Steps (Recommendations)
|
||||
|
||||
### 1. Migrate Search Events
|
||||
```javascript
|
||||
// In SearchManager.js
|
||||
eventManager.addHandler('keydown', 'search-shortcuts', (e) => {
|
||||
if ((e.ctrlKey || e.metaKey) && e.key === 'f') {
|
||||
this.focusSearchInput();
|
||||
return true;
|
||||
}
|
||||
}, { priority: 120 });
|
||||
```
|
||||
|
||||
### 2. Integrate Resize Events
|
||||
```javascript
|
||||
// Create ResizeManager
|
||||
eventManager.addHandler('resize', 'layout-resize', debounce((e) => {
|
||||
this.updateLayoutDimensions();
|
||||
}, 250), { priority: 50 });
|
||||
```
|
||||
|
||||
### 3. Add Debug Mode
|
||||
```javascript
|
||||
// In EventManager.js
|
||||
if (window.DEBUG_EVENTS) {
|
||||
console.log(`Event ${eventType} handled by ${source} (priority: ${priority})`);
|
||||
}
|
||||
```
|
||||
|
||||
### 4. Create Event Analytics
|
||||
```javascript
|
||||
// Track event patterns for optimization
|
||||
eventManager.addHandler('*', 'analytics', (e) => {
|
||||
this.trackEventUsage(e.type, performance.now());
|
||||
}, { priority: 1 });
|
||||
```
|
||||
|
||||
## Testing Recommendations
|
||||
|
||||
1. **Verify bulk mode interactions** work correctly
|
||||
2. **Test marquee selection** in various scenarios
|
||||
3. **Check modal state synchronization**
|
||||
4. **Verify node selector** positioning and cleanup
|
||||
5. **Test keyboard shortcuts** don't conflict
|
||||
6. **Verify proper cleanup** when components are destroyed
|
||||
|
||||
The centralized event management system provides a solid foundation for coordinated, efficient event handling across the application while maintaining good performance and code organization.
|
||||
301
docs/EventManagerDocs.md
Normal file
301
docs/EventManagerDocs.md
Normal file
@@ -0,0 +1,301 @@
|
||||
# Centralized Event Management System
|
||||
|
||||
This document describes the centralized event management system that coordinates event handling across the ComfyUI LoRA Manager application.
|
||||
|
||||
## Overview
|
||||
|
||||
The `EventManager` class provides a centralized way to handle DOM events with priority-based execution, conditional execution based on application state, and proper cleanup mechanisms.
|
||||
|
||||
## Features
|
||||
|
||||
- **Priority-based execution**: Handlers with higher priority run first
|
||||
- **Conditional execution**: Handlers can be executed based on application state
|
||||
- **Element filtering**: Handlers can target specific elements or exclude others
|
||||
- **Automatic cleanup**: Cleanup functions are called when handlers are removed
|
||||
- **State tracking**: Tracks application states like bulk mode, modal open, etc.
|
||||
|
||||
## Basic Usage
|
||||
|
||||
### Importing
|
||||
|
||||
```javascript
|
||||
import { eventManager } from './EventManager.js';
|
||||
```
|
||||
|
||||
### Adding Event Handlers
|
||||
|
||||
```javascript
|
||||
eventManager.addHandler('click', 'myComponent', (event) => {
|
||||
console.log('Button clicked!');
|
||||
return true; // Stop propagation to other handlers
|
||||
}, {
|
||||
priority: 100,
|
||||
targetSelector: '.my-button',
|
||||
skipWhenModalOpen: true
|
||||
});
|
||||
```
|
||||
|
||||
### Removing Event Handlers
|
||||
|
||||
```javascript
|
||||
// Remove specific handler
|
||||
eventManager.removeHandler('click', 'myComponent');
|
||||
|
||||
// Remove all handlers for a component
|
||||
eventManager.removeAllHandlersForSource('myComponent');
|
||||
```
|
||||
|
||||
### Updating Application State
|
||||
|
||||
```javascript
|
||||
// Set state
|
||||
eventManager.setState('bulkMode', true);
|
||||
eventManager.setState('modalOpen', true);
|
||||
|
||||
// Get state
|
||||
const isBulkMode = eventManager.getState('bulkMode');
|
||||
```
|
||||
|
||||
## Available States
|
||||
|
||||
- `bulkMode`: Whether bulk selection mode is active
|
||||
- `marqueeActive`: Whether marquee selection is in progress
|
||||
- `modalOpen`: Whether any modal is currently open
|
||||
- `nodeSelectorActive`: Whether the node selector popup is active
|
||||
|
||||
## Handler Options
|
||||
|
||||
### Priority
|
||||
Higher numbers = higher priority. Handlers run in descending priority order.
|
||||
|
||||
```javascript
|
||||
{
|
||||
priority: 100 // High priority
|
||||
}
|
||||
```
|
||||
|
||||
### Conditional Execution
|
||||
|
||||
```javascript
|
||||
{
|
||||
onlyInBulkMode: true, // Only run when bulk mode is active
|
||||
onlyWhenMarqueeActive: true, // Only run when marquee selection is active
|
||||
skipWhenModalOpen: true, // Skip when any modal is open
|
||||
skipWhenNodeSelectorActive: true, // Skip when node selector is active
|
||||
onlyWhenNodeSelectorActive: true // Only run when node selector is active
|
||||
}
|
||||
```
|
||||
|
||||
### Element Filtering
|
||||
|
||||
```javascript
|
||||
{
|
||||
targetSelector: '.model-card', // Only handle events on matching elements
|
||||
excludeSelector: 'button, input', // Exclude events from these elements
|
||||
button: 0 // Only handle specific mouse button (0=left, 1=middle, 2=right)
|
||||
}
|
||||
```
|
||||
|
||||
### Cleanup Functions
|
||||
|
||||
```javascript
|
||||
{
|
||||
cleanup: () => {
|
||||
// Custom cleanup logic
|
||||
console.log('Handler cleaned up');
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Integration Examples
|
||||
|
||||
### BulkManager Integration
|
||||
|
||||
```javascript
|
||||
class BulkManager {
|
||||
registerEventHandlers() {
|
||||
// High priority keyboard shortcuts
|
||||
eventManager.addHandler('keydown', 'bulkManager-keyboard', (e) => {
|
||||
return this.handleGlobalKeyboard(e);
|
||||
}, {
|
||||
priority: 100,
|
||||
skipWhenModalOpen: true
|
||||
});
|
||||
|
||||
// Marquee selection
|
||||
eventManager.addHandler('mousedown', 'bulkManager-marquee-start', (e) => {
|
||||
return this.handleMarqueeStart(e);
|
||||
}, {
|
||||
priority: 80,
|
||||
skipWhenModalOpen: true,
|
||||
targetSelector: '.models-container',
|
||||
excludeSelector: '.model-card, button, input',
|
||||
button: 0
|
||||
});
|
||||
}
|
||||
|
||||
cleanup() {
|
||||
eventManager.removeAllHandlersForSource('bulkManager-keyboard');
|
||||
eventManager.removeAllHandlersForSource('bulkManager-marquee-start');
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Modal Integration
|
||||
|
||||
```javascript
|
||||
class ModalManager {
|
||||
showModal(modalId) {
|
||||
// Update state when modal opens
|
||||
eventManager.setState('modalOpen', true);
|
||||
this.displayModal(modalId);
|
||||
}
|
||||
|
||||
closeModal(modalId) {
|
||||
// Update state when modal closes
|
||||
eventManager.setState('modalOpen', false);
|
||||
this.hideModal(modalId);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Component Event Delegation
|
||||
|
||||
```javascript
|
||||
export function setupComponentEvents() {
|
||||
eventManager.addHandler('click', 'myComponent-actions', (event) => {
|
||||
const button = event.target.closest('.action-button');
|
||||
if (!button) return false;
|
||||
|
||||
this.handleAction(button.dataset.action);
|
||||
return true; // Stop propagation
|
||||
}, {
|
||||
priority: 60,
|
||||
targetSelector: '.component-container'
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
## Best Practices
|
||||
|
||||
### 1. Use Descriptive Source Names
|
||||
Use the format `componentName-purposeDescription`:
|
||||
```javascript
|
||||
// Good
|
||||
'bulkManager-marqueeSelection'
|
||||
'nodeSelector-clickOutside'
|
||||
'modelCard-delegation'
|
||||
|
||||
// Avoid
|
||||
'bulk'
|
||||
'click'
|
||||
'handler1'
|
||||
```
|
||||
|
||||
### 2. Set Appropriate Priorities
|
||||
- 200+: Critical system events (escape keys, critical modals)
|
||||
- 100-199: High priority application events (keyboard shortcuts)
|
||||
- 50-99: Normal UI interactions (buttons, cards)
|
||||
- 1-49: Low priority events (tracking, analytics)
|
||||
|
||||
### 3. Use Conditional Execution
|
||||
Instead of checking state inside handlers, use options:
|
||||
```javascript
|
||||
// Good
|
||||
eventManager.addHandler('click', 'bulk-action', handler, {
|
||||
onlyInBulkMode: true
|
||||
});
|
||||
|
||||
// Avoid
|
||||
eventManager.addHandler('click', 'bulk-action', (e) => {
|
||||
if (!state.bulkMode) return;
|
||||
// handler logic
|
||||
});
|
||||
```
|
||||
|
||||
### 4. Clean Up Properly
|
||||
Always clean up handlers when components are destroyed:
|
||||
```javascript
|
||||
class MyComponent {
|
||||
constructor() {
|
||||
this.registerEvents();
|
||||
}
|
||||
|
||||
destroy() {
|
||||
eventManager.removeAllHandlersForSource('myComponent');
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 5. Return Values Matter
|
||||
- Return `true` to stop event propagation to other handlers
|
||||
- Return `false` or `undefined` to continue with other handlers
|
||||
|
||||
## Migration Guide
|
||||
|
||||
### From Direct Event Listeners
|
||||
|
||||
**Before:**
|
||||
```javascript
|
||||
document.addEventListener('click', (e) => {
|
||||
if (e.target.closest('.my-button')) {
|
||||
this.handleClick(e);
|
||||
}
|
||||
});
|
||||
```
|
||||
|
||||
**After:**
|
||||
```javascript
|
||||
eventManager.addHandler('click', 'myComponent-button', (e) => {
|
||||
this.handleClick(e);
|
||||
}, {
|
||||
targetSelector: '.my-button'
|
||||
});
|
||||
```
|
||||
|
||||
### From Event Delegation
|
||||
|
||||
**Before:**
|
||||
```javascript
|
||||
container.addEventListener('click', (e) => {
|
||||
const card = e.target.closest('.model-card');
|
||||
if (!card) return;
|
||||
|
||||
if (e.target.closest('.action-btn')) {
|
||||
this.handleAction(e);
|
||||
}
|
||||
});
|
||||
```
|
||||
|
||||
**After:**
|
||||
```javascript
|
||||
eventManager.addHandler('click', 'container-actions', (e) => {
|
||||
const card = e.target.closest('.model-card');
|
||||
if (!card) return false;
|
||||
|
||||
if (e.target.closest('.action-btn')) {
|
||||
this.handleAction(e);
|
||||
return true;
|
||||
}
|
||||
}, {
|
||||
targetSelector: '.container'
|
||||
});
|
||||
```
|
||||
|
||||
## Performance Benefits
|
||||
|
||||
1. **Reduced DOM listeners**: Single listener per event type instead of multiple
|
||||
2. **Conditional execution**: Handlers only run when conditions are met
|
||||
3. **Priority ordering**: Important handlers run first, avoiding unnecessary work
|
||||
4. **Automatic cleanup**: Prevents memory leaks from orphaned listeners
|
||||
5. **Centralized debugging**: All event handling flows through one system
|
||||
|
||||
## Debugging
|
||||
|
||||
Enable debug logging to trace event handling:
|
||||
```javascript
|
||||
// Add to EventManager.js for debugging
|
||||
console.log(`Handling ${eventType} event with ${handlers.length} handlers`);
|
||||
```
|
||||
|
||||
The event manager provides a foundation for coordinated, efficient event handling across the entire application.
|
||||
BIN
example_workflows/nunchaku-flux.1-dev.jpg
Normal file
BIN
example_workflows/nunchaku-flux.1-dev.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 68 KiB |
1
example_workflows/nunchaku-flux.1-dev.json
Normal file
1
example_workflows/nunchaku-flux.1-dev.json
Normal file
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
1227
locales/de.json
Normal file
1227
locales/de.json
Normal file
File diff suppressed because it is too large
Load Diff
1227
locales/en.json
Normal file
1227
locales/en.json
Normal file
File diff suppressed because it is too large
Load Diff
1227
locales/es.json
Normal file
1227
locales/es.json
Normal file
File diff suppressed because it is too large
Load Diff
1227
locales/fr.json
Normal file
1227
locales/fr.json
Normal file
File diff suppressed because it is too large
Load Diff
1227
locales/ja.json
Normal file
1227
locales/ja.json
Normal file
File diff suppressed because it is too large
Load Diff
1227
locales/ko.json
Normal file
1227
locales/ko.json
Normal file
File diff suppressed because it is too large
Load Diff
1227
locales/ru.json
Normal file
1227
locales/ru.json
Normal file
File diff suppressed because it is too large
Load Diff
1227
locales/zh-CN.json
Normal file
1227
locales/zh-CN.json
Normal file
File diff suppressed because it is too large
Load Diff
1227
locales/zh-TW.json
Normal file
1227
locales/zh-TW.json
Normal file
File diff suppressed because it is too large
Load Diff
209
py/config.py
209
py/config.py
@@ -5,6 +5,7 @@ from typing import List
|
||||
import logging
|
||||
import sys
|
||||
import json
|
||||
import urllib.parse
|
||||
|
||||
# Check if running in standalone mode
|
||||
standalone_mode = 'nodes' not in sys.modules
|
||||
@@ -17,13 +18,18 @@ class Config:
|
||||
def __init__(self):
|
||||
self.templates_path = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'templates')
|
||||
self.static_path = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'static')
|
||||
# 路径映射字典, target to link mapping
|
||||
self.i18n_path = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'locales')
|
||||
# Path mapping dictionary, target to link mapping
|
||||
self._path_mappings = {}
|
||||
# 静态路由映射字典, target to route mapping
|
||||
# Static route mapping dictionary, target to route mapping
|
||||
self._route_mappings = {}
|
||||
self.loras_roots = self._init_lora_paths()
|
||||
self.checkpoints_roots = self._init_checkpoint_paths()
|
||||
# 在初始化时扫描符号链接
|
||||
self.checkpoints_roots = None
|
||||
self.unet_roots = None
|
||||
self.embeddings_roots = None
|
||||
self.base_models_roots = self._init_checkpoint_paths()
|
||||
self.embeddings_roots = self._init_embedding_paths()
|
||||
# Scan symbolic links during initialization
|
||||
self._scan_symbolic_links()
|
||||
|
||||
if not standalone_mode:
|
||||
@@ -33,34 +39,37 @@ class Config:
|
||||
def save_folder_paths_to_settings(self):
|
||||
"""Save folder paths to settings.json for standalone mode to use later"""
|
||||
try:
|
||||
# Check if we're running in ComfyUI mode (not standalone)
|
||||
if hasattr(folder_paths, "get_folder_paths") and not isinstance(folder_paths, type):
|
||||
# Get all relevant paths
|
||||
lora_paths = folder_paths.get_folder_paths("loras")
|
||||
checkpoint_paths = folder_paths.get_folder_paths("checkpoints")
|
||||
diffuser_paths = folder_paths.get_folder_paths("diffusers")
|
||||
unet_paths = folder_paths.get_folder_paths("unet")
|
||||
|
||||
# Load existing settings
|
||||
settings_path = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'settings.json')
|
||||
settings = {}
|
||||
if os.path.exists(settings_path):
|
||||
with open(settings_path, 'r', encoding='utf-8') as f:
|
||||
settings = json.load(f)
|
||||
|
||||
# Update settings with paths
|
||||
settings['folder_paths'] = {
|
||||
'loras': lora_paths,
|
||||
'checkpoints': checkpoint_paths,
|
||||
'diffusers': diffuser_paths,
|
||||
'unet': unet_paths
|
||||
}
|
||||
|
||||
# Save settings
|
||||
with open(settings_path, 'w', encoding='utf-8') as f:
|
||||
json.dump(settings, f, indent=2)
|
||||
|
||||
logger.info("Saved folder paths to settings.json")
|
||||
# Check if we're running in ComfyUI mode (not standalone)
|
||||
# Load existing settings
|
||||
settings_path = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'settings.json')
|
||||
settings = {}
|
||||
if os.path.exists(settings_path):
|
||||
with open(settings_path, 'r', encoding='utf-8') as f:
|
||||
settings = json.load(f)
|
||||
|
||||
# Update settings with paths
|
||||
settings['folder_paths'] = {
|
||||
'loras': self.loras_roots,
|
||||
'checkpoints': self.checkpoints_roots,
|
||||
'unet': self.unet_roots,
|
||||
'embeddings': self.embeddings_roots,
|
||||
}
|
||||
|
||||
# Add default roots if there's only one item and key doesn't exist
|
||||
if len(self.loras_roots) == 1 and "default_lora_root" not in settings:
|
||||
settings["default_lora_root"] = self.loras_roots[0]
|
||||
|
||||
if self.checkpoints_roots and len(self.checkpoints_roots) == 1 and "default_checkpoint_root" not in settings:
|
||||
settings["default_checkpoint_root"] = self.checkpoints_roots[0]
|
||||
|
||||
if self.embeddings_roots and len(self.embeddings_roots) == 1 and "default_embedding_root" not in settings:
|
||||
settings["default_embedding_root"] = self.embeddings_roots[0]
|
||||
|
||||
# Save settings
|
||||
with open(settings_path, 'w', encoding='utf-8') as f:
|
||||
json.dump(settings, f, indent=2)
|
||||
|
||||
logger.info("Saved folder paths to settings.json")
|
||||
except Exception as e:
|
||||
logger.warning(f"Failed to save folder paths: {e}")
|
||||
|
||||
@@ -82,15 +91,18 @@ class Config:
|
||||
return False
|
||||
|
||||
def _scan_symbolic_links(self):
|
||||
"""扫描所有 LoRA 和 Checkpoint 根目录中的符号链接"""
|
||||
"""Scan all symbolic links in LoRA, Checkpoint, and Embedding root directories"""
|
||||
for root in self.loras_roots:
|
||||
self._scan_directory_links(root)
|
||||
|
||||
for root in self.checkpoints_roots:
|
||||
for root in self.base_models_roots:
|
||||
self._scan_directory_links(root)
|
||||
|
||||
for root in self.embeddings_roots:
|
||||
self._scan_directory_links(root)
|
||||
|
||||
def _scan_directory_links(self, root: str):
|
||||
"""递归扫描目录中的符号链接"""
|
||||
"""Recursively scan symbolic links in a directory"""
|
||||
try:
|
||||
with os.scandir(root) as it:
|
||||
for entry in it:
|
||||
@@ -105,40 +117,40 @@ class Config:
|
||||
logger.error(f"Error scanning links in {root}: {e}")
|
||||
|
||||
def add_path_mapping(self, link_path: str, target_path: str):
|
||||
"""添加符号链接路径映射
|
||||
target_path: 实际目标路径
|
||||
link_path: 符号链接路径
|
||||
"""Add a symbolic link path mapping
|
||||
target_path: actual target path
|
||||
link_path: symbolic link path
|
||||
"""
|
||||
normalized_link = os.path.normpath(link_path).replace(os.sep, '/')
|
||||
normalized_target = os.path.normpath(target_path).replace(os.sep, '/')
|
||||
# 保持原有的映射关系:目标路径 -> 链接路径
|
||||
# Keep the original mapping: target path -> link path
|
||||
self._path_mappings[normalized_target] = normalized_link
|
||||
logger.info(f"Added path mapping: {normalized_target} -> {normalized_link}")
|
||||
|
||||
def add_route_mapping(self, path: str, route: str):
|
||||
"""添加静态路由映射"""
|
||||
"""Add a static route mapping"""
|
||||
normalized_path = os.path.normpath(path).replace(os.sep, '/')
|
||||
self._route_mappings[normalized_path] = route
|
||||
# logger.info(f"Added route mapping: {normalized_path} -> {route}")
|
||||
|
||||
def map_path_to_link(self, path: str) -> str:
|
||||
"""将目标路径映射回符号链接路径"""
|
||||
"""Map a target path back to its symbolic link path"""
|
||||
normalized_path = os.path.normpath(path).replace(os.sep, '/')
|
||||
# 检查路径是否包含在任何映射的目标路径中
|
||||
# Check if the path is contained in any mapped target path
|
||||
for target_path, link_path in self._path_mappings.items():
|
||||
if normalized_path.startswith(target_path):
|
||||
# 如果路径以目标路径开头,则替换为链接路径
|
||||
# If the path starts with the target path, replace with link path
|
||||
mapped_path = normalized_path.replace(target_path, link_path, 1)
|
||||
return mapped_path
|
||||
return path
|
||||
|
||||
def map_link_to_path(self, link_path: str) -> str:
|
||||
"""将符号链接路径映射回实际路径"""
|
||||
"""Map a symbolic link path back to the actual path"""
|
||||
normalized_link = os.path.normpath(link_path).replace(os.sep, '/')
|
||||
# 检查路径是否包含在任何映射的目标路径中
|
||||
# Check if the path is contained in any mapped target path
|
||||
for target_path, link_path in self._path_mappings.items():
|
||||
if normalized_link.startswith(target_path):
|
||||
# 如果路径以目标路径开头,则替换为实际路径
|
||||
# If the path starts with the target path, replace with actual path
|
||||
mapped_path = normalized_link.replace(target_path, link_path, 1)
|
||||
return mapped_path
|
||||
return link_path
|
||||
@@ -177,47 +189,106 @@ class Config:
|
||||
"""Initialize and validate checkpoint paths from ComfyUI settings"""
|
||||
try:
|
||||
# Get checkpoint paths from folder_paths
|
||||
checkpoint_paths = folder_paths.get_folder_paths("checkpoints")
|
||||
diffusion_paths = folder_paths.get_folder_paths("diffusers")
|
||||
unet_paths = folder_paths.get_folder_paths("unet")
|
||||
raw_checkpoint_paths = folder_paths.get_folder_paths("checkpoints")
|
||||
raw_unet_paths = folder_paths.get_folder_paths("unet")
|
||||
|
||||
# Combine all checkpoint-related paths
|
||||
all_paths = checkpoint_paths + diffusion_paths + unet_paths
|
||||
# Normalize and resolve symlinks for checkpoints, store mapping from resolved -> original
|
||||
checkpoint_map = {}
|
||||
for path in raw_checkpoint_paths:
|
||||
if os.path.exists(path):
|
||||
real_path = os.path.normpath(os.path.realpath(path)).replace(os.sep, '/')
|
||||
checkpoint_map[real_path] = checkpoint_map.get(real_path, path.replace(os.sep, "/")) # preserve first seen
|
||||
|
||||
# Filter and normalize paths
|
||||
paths = sorted(set(path.replace(os.sep, "/")
|
||||
for path in all_paths
|
||||
if os.path.exists(path)), key=lambda p: p.lower())
|
||||
# Normalize and resolve symlinks for unet, store mapping from resolved -> original
|
||||
unet_map = {}
|
||||
for path in raw_unet_paths:
|
||||
if os.path.exists(path):
|
||||
real_path = os.path.normpath(os.path.realpath(path)).replace(os.sep, '/')
|
||||
unet_map[real_path] = unet_map.get(real_path, path.replace(os.sep, "/")) # preserve first seen
|
||||
|
||||
logger.info("Found checkpoint roots:" + ("\n - " + "\n - ".join(paths) if paths else "[]"))
|
||||
# Merge both maps and deduplicate by real path
|
||||
merged_map = {}
|
||||
for real_path, orig_path in {**checkpoint_map, **unet_map}.items():
|
||||
if real_path not in merged_map:
|
||||
merged_map[real_path] = orig_path
|
||||
|
||||
# Now sort and use only the deduplicated real paths
|
||||
unique_paths = sorted(merged_map.values(), key=lambda p: p.lower())
|
||||
|
||||
if not paths:
|
||||
# Split back into checkpoints and unet roots for class properties
|
||||
self.checkpoints_roots = [p for p in unique_paths if p in checkpoint_map.values()]
|
||||
self.unet_roots = [p for p in unique_paths if p in unet_map.values()]
|
||||
|
||||
all_paths = unique_paths
|
||||
|
||||
logger.info("Found checkpoint roots:" + ("\n - " + "\n - ".join(all_paths) if all_paths else "[]"))
|
||||
|
||||
if not all_paths:
|
||||
logger.warning("No valid checkpoint folders found in ComfyUI configuration")
|
||||
return []
|
||||
|
||||
# 初始化路径映射,与 LoRA 路径处理方式相同
|
||||
for path in paths:
|
||||
real_path = os.path.normpath(os.path.realpath(path)).replace(os.sep, '/')
|
||||
if real_path != path:
|
||||
self.add_path_mapping(path, real_path)
|
||||
# Initialize path mappings
|
||||
for original_path in all_paths:
|
||||
real_path = os.path.normpath(os.path.realpath(original_path)).replace(os.sep, '/')
|
||||
if real_path != original_path:
|
||||
self.add_path_mapping(original_path, real_path)
|
||||
|
||||
return paths
|
||||
return all_paths
|
||||
except Exception as e:
|
||||
logger.warning(f"Error initializing checkpoint paths: {e}")
|
||||
return []
|
||||
|
||||
def _init_embedding_paths(self) -> List[str]:
|
||||
"""Initialize and validate embedding paths from ComfyUI settings"""
|
||||
try:
|
||||
raw_paths = folder_paths.get_folder_paths("embeddings")
|
||||
|
||||
# Normalize and resolve symlinks, store mapping from resolved -> original
|
||||
path_map = {}
|
||||
for path in raw_paths:
|
||||
if os.path.exists(path):
|
||||
real_path = os.path.normpath(os.path.realpath(path)).replace(os.sep, '/')
|
||||
path_map[real_path] = path_map.get(real_path, path.replace(os.sep, "/")) # preserve first seen
|
||||
|
||||
# Now sort and use only the deduplicated real paths
|
||||
unique_paths = sorted(path_map.values(), key=lambda p: p.lower())
|
||||
logger.info("Found embedding roots:" + ("\n - " + "\n - ".join(unique_paths) if unique_paths else "[]"))
|
||||
|
||||
if not unique_paths:
|
||||
logger.warning("No valid embeddings folders found in ComfyUI configuration")
|
||||
return []
|
||||
|
||||
for original_path in unique_paths:
|
||||
real_path = os.path.normpath(os.path.realpath(original_path)).replace(os.sep, '/')
|
||||
if real_path != original_path:
|
||||
self.add_path_mapping(original_path, real_path)
|
||||
|
||||
return unique_paths
|
||||
except Exception as e:
|
||||
logger.warning(f"Error initializing embedding paths: {e}")
|
||||
return []
|
||||
|
||||
def get_preview_static_url(self, preview_path: str) -> str:
|
||||
"""Convert local preview path to static URL"""
|
||||
if not preview_path:
|
||||
return ""
|
||||
|
||||
real_path = os.path.realpath(preview_path).replace(os.sep, '/')
|
||||
|
||||
|
||||
# Find longest matching path (most specific match)
|
||||
best_match = ""
|
||||
best_route = ""
|
||||
|
||||
for path, route in self._route_mappings.items():
|
||||
if real_path.startswith(path):
|
||||
relative_path = os.path.relpath(real_path, path)
|
||||
return f'{route}/{relative_path.replace(os.sep, "/")}'
|
||||
|
||||
if real_path.startswith(path) and len(path) > len(best_match):
|
||||
best_match = path
|
||||
best_route = route
|
||||
|
||||
if best_match:
|
||||
relative_path = os.path.relpath(real_path, best_match).replace(os.sep, '/')
|
||||
safe_parts = [urllib.parse.quote(part) for part in relative_path.split('/')]
|
||||
safe_path = '/'.join(safe_parts)
|
||||
return f'{best_route}/{safe_path}'
|
||||
|
||||
return ""
|
||||
|
||||
# Global config instance
|
||||
|
||||
@@ -1,17 +1,21 @@
|
||||
import asyncio
|
||||
from server import PromptServer # type: ignore
|
||||
from .config import config
|
||||
from .routes.lora_routes import LoraRoutes
|
||||
from .routes.api_routes import ApiRoutes
|
||||
from .routes.recipe_routes import RecipeRoutes
|
||||
from .routes.checkpoints_routes import CheckpointsRoutes
|
||||
from .routes.update_routes import UpdateRoutes
|
||||
from .routes.misc_routes import MiscRoutes
|
||||
from .services.service_registry import ServiceRegistry
|
||||
from .services.settings_manager import settings
|
||||
import logging
|
||||
import sys
|
||||
import os
|
||||
import logging
|
||||
from pathlib import Path
|
||||
from server import PromptServer # type: ignore
|
||||
|
||||
from .config import config
|
||||
from .services.model_service_factory import ModelServiceFactory, register_default_model_types
|
||||
from .routes.recipe_routes import RecipeRoutes
|
||||
from .routes.stats_routes import StatsRoutes
|
||||
from .routes.update_routes import UpdateRoutes
|
||||
from .routes.misc_routes import MiscRoutes
|
||||
from .routes.example_images_routes import ExampleImagesRoutes
|
||||
from .services.service_registry import ServiceRegistry
|
||||
from .services.settings_manager import settings
|
||||
from .utils.example_images_migration import ExampleImagesMigration
|
||||
from .services.websocket_manager import ws_manager
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@@ -23,12 +27,28 @@ class LoraManager:
|
||||
|
||||
@classmethod
|
||||
def add_routes(cls):
|
||||
"""Initialize and register all routes"""
|
||||
"""Initialize and register all routes using the new refactored architecture"""
|
||||
app = PromptServer.instance.app
|
||||
|
||||
# Configure aiohttp access logger to be less verbose
|
||||
logging.getLogger('aiohttp.access').setLevel(logging.WARNING)
|
||||
|
||||
# Add specific suppression for connection reset errors
|
||||
class ConnectionResetFilter(logging.Filter):
|
||||
def filter(self, record):
|
||||
# Filter out connection reset errors that are not critical
|
||||
if "ConnectionResetError" in str(record.getMessage()):
|
||||
return False
|
||||
if "_call_connection_lost" in str(record.getMessage()):
|
||||
return False
|
||||
if "WinError 10054" in str(record.getMessage()):
|
||||
return False
|
||||
return True
|
||||
|
||||
# Apply the filter to asyncio logger
|
||||
asyncio_logger = logging.getLogger("asyncio")
|
||||
asyncio_logger.addFilter(ConnectionResetFilter())
|
||||
|
||||
added_targets = set() # Track already added target paths
|
||||
|
||||
# Add static route for example images if the path exists in settings
|
||||
@@ -57,7 +77,7 @@ class LoraManager:
|
||||
added_targets.add(real_root)
|
||||
|
||||
# Add static routes for each checkpoint root
|
||||
for idx, root in enumerate(config.checkpoints_roots, start=1):
|
||||
for idx, root in enumerate(config.base_models_roots, start=1):
|
||||
preview_path = f'/checkpoints_static/root{idx}/preview'
|
||||
|
||||
real_root = root
|
||||
@@ -74,120 +94,381 @@ class LoraManager:
|
||||
config.add_route_mapping(real_root, preview_path)
|
||||
added_targets.add(real_root)
|
||||
|
||||
# Add static routes for each embedding root
|
||||
for idx, root in enumerate(config.embeddings_roots, start=1):
|
||||
preview_path = f'/embeddings_static/root{idx}/preview'
|
||||
|
||||
real_root = root
|
||||
if root in config._path_mappings.values():
|
||||
for target, link in config._path_mappings.items():
|
||||
if link == root:
|
||||
real_root = target
|
||||
break
|
||||
# Add static route for original path
|
||||
app.router.add_static(preview_path, real_root)
|
||||
logger.info(f"Added static route {preview_path} -> {real_root}")
|
||||
|
||||
# Record route mapping
|
||||
config.add_route_mapping(real_root, preview_path)
|
||||
added_targets.add(real_root)
|
||||
|
||||
# Add static routes for symlink target paths
|
||||
link_idx = {
|
||||
'lora': 1,
|
||||
'checkpoint': 1
|
||||
'checkpoint': 1,
|
||||
'embedding': 1
|
||||
}
|
||||
|
||||
for target_path, link_path in config._path_mappings.items():
|
||||
if target_path not in added_targets:
|
||||
# Determine if this is a checkpoint or lora link based on path
|
||||
is_checkpoint = any(cp_root in link_path for cp_root in config.checkpoints_roots)
|
||||
is_checkpoint = is_checkpoint or any(cp_root in target_path for cp_root in config.checkpoints_roots)
|
||||
# Determine if this is a checkpoint, lora, or embedding link based on path
|
||||
is_checkpoint = any(cp_root in link_path for cp_root in config.base_models_roots)
|
||||
is_checkpoint = is_checkpoint or any(cp_root in target_path for cp_root in config.base_models_roots)
|
||||
is_embedding = any(emb_root in link_path for emb_root in config.embeddings_roots)
|
||||
is_embedding = is_embedding or any(emb_root in target_path for emb_root in config.embeddings_roots)
|
||||
|
||||
if is_checkpoint:
|
||||
route_path = f'/checkpoints_static/link_{link_idx["checkpoint"]}/preview'
|
||||
link_idx["checkpoint"] += 1
|
||||
elif is_embedding:
|
||||
route_path = f'/embeddings_static/link_{link_idx["embedding"]}/preview'
|
||||
link_idx["embedding"] += 1
|
||||
else:
|
||||
route_path = f'/loras_static/link_{link_idx["lora"]}/preview'
|
||||
link_idx["lora"] += 1
|
||||
|
||||
app.router.add_static(route_path, target_path)
|
||||
logger.info(f"Added static route for link target {route_path} -> {target_path}")
|
||||
config.add_route_mapping(target_path, route_path)
|
||||
added_targets.add(target_path)
|
||||
|
||||
try:
|
||||
app.router.add_static(route_path, Path(target_path).resolve(strict=False))
|
||||
logger.info(f"Added static route for link target {route_path} -> {target_path}")
|
||||
config.add_route_mapping(target_path, route_path)
|
||||
added_targets.add(target_path)
|
||||
except Exception as e:
|
||||
logger.warning(f"Failed to add static route on initialization for {target_path}: {e}")
|
||||
continue
|
||||
|
||||
# Add static route for locales JSON files
|
||||
if os.path.exists(config.i18n_path):
|
||||
app.router.add_static('/locales', config.i18n_path)
|
||||
logger.info(f"Added static route for locales: /locales -> {config.i18n_path}")
|
||||
|
||||
# Add static route for plugin assets
|
||||
app.router.add_static('/loras_static', config.static_path)
|
||||
|
||||
# Setup feature routes
|
||||
lora_routes = LoraRoutes()
|
||||
checkpoints_routes = CheckpointsRoutes()
|
||||
# Register default model types with the factory
|
||||
register_default_model_types()
|
||||
|
||||
# Initialize routes
|
||||
lora_routes.setup_routes(app)
|
||||
checkpoints_routes.setup_routes(app)
|
||||
ApiRoutes.setup_routes(app)
|
||||
# Setup all model routes using the factory
|
||||
ModelServiceFactory.setup_all_routes(app)
|
||||
|
||||
# Setup non-model-specific routes
|
||||
stats_routes = StatsRoutes()
|
||||
stats_routes.setup_routes(app)
|
||||
RecipeRoutes.setup_routes(app)
|
||||
UpdateRoutes.setup_routes(app)
|
||||
MiscRoutes.setup_routes(app) # Register miscellaneous routes
|
||||
MiscRoutes.setup_routes(app)
|
||||
ExampleImagesRoutes.setup_routes(app)
|
||||
|
||||
# Setup WebSocket routes that are shared across all model types
|
||||
app.router.add_get('/ws/fetch-progress', ws_manager.handle_connection)
|
||||
app.router.add_get('/ws/download-progress', ws_manager.handle_download_connection)
|
||||
app.router.add_get('/ws/init-progress', ws_manager.handle_init_connection)
|
||||
|
||||
# Schedule service initialization
|
||||
app.on_startup.append(lambda app: cls._initialize_services())
|
||||
|
||||
# Add cleanup
|
||||
app.on_shutdown.append(cls._cleanup)
|
||||
app.on_shutdown.append(ApiRoutes.cleanup)
|
||||
|
||||
logger.info(f"LoRA Manager: Set up routes for {len(ModelServiceFactory.get_registered_types())} model types: {', '.join(ModelServiceFactory.get_registered_types())}")
|
||||
|
||||
@classmethod
|
||||
async def _initialize_services(cls):
|
||||
"""Initialize all services using the ServiceRegistry"""
|
||||
try:
|
||||
# Ensure aiohttp access logger is configured with reduced verbosity
|
||||
logging.getLogger('aiohttp.access').setLevel(logging.WARNING)
|
||||
|
||||
# Initialize CivitaiClient first to ensure it's ready for other services
|
||||
civitai_client = await ServiceRegistry.get_civitai_client()
|
||||
|
||||
# Get file monitors through ServiceRegistry
|
||||
lora_monitor = await ServiceRegistry.get_lora_monitor()
|
||||
checkpoint_monitor = await ServiceRegistry.get_checkpoint_monitor()
|
||||
|
||||
# Start monitors
|
||||
lora_monitor.start()
|
||||
logger.debug("Lora monitor started")
|
||||
|
||||
# Make sure checkpoint monitor has paths before starting
|
||||
await checkpoint_monitor.initialize_paths()
|
||||
checkpoint_monitor.start()
|
||||
logger.debug("Checkpoint monitor started")
|
||||
await ServiceRegistry.get_civitai_client()
|
||||
|
||||
# Register DownloadManager with ServiceRegistry
|
||||
download_manager = await ServiceRegistry.get_download_manager()
|
||||
await ServiceRegistry.get_download_manager()
|
||||
|
||||
from .services.metadata_service import initialize_metadata_providers
|
||||
await initialize_metadata_providers()
|
||||
|
||||
# Initialize WebSocket manager
|
||||
ws_manager = await ServiceRegistry.get_websocket_manager()
|
||||
await ServiceRegistry.get_websocket_manager()
|
||||
|
||||
# Initialize scanners in background
|
||||
lora_scanner = await ServiceRegistry.get_lora_scanner()
|
||||
checkpoint_scanner = await ServiceRegistry.get_checkpoint_scanner()
|
||||
embedding_scanner = await ServiceRegistry.get_embedding_scanner()
|
||||
|
||||
# Initialize recipe scanner if needed
|
||||
recipe_scanner = await ServiceRegistry.get_recipe_scanner()
|
||||
|
||||
# Initialize metadata collector if not in standalone mode
|
||||
if not STANDALONE_MODE:
|
||||
from .metadata_collector import init as init_metadata
|
||||
init_metadata()
|
||||
logger.debug("Metadata collector initialized")
|
||||
|
||||
# Create low-priority initialization tasks
|
||||
asyncio.create_task(lora_scanner.initialize_in_background(), name='lora_cache_init')
|
||||
asyncio.create_task(checkpoint_scanner.initialize_in_background(), name='checkpoint_cache_init')
|
||||
asyncio.create_task(recipe_scanner.initialize_in_background(), name='recipe_cache_init')
|
||||
init_tasks = [
|
||||
asyncio.create_task(lora_scanner.initialize_in_background(), name='lora_cache_init'),
|
||||
asyncio.create_task(checkpoint_scanner.initialize_in_background(), name='checkpoint_cache_init'),
|
||||
asyncio.create_task(embedding_scanner.initialize_in_background(), name='embedding_cache_init'),
|
||||
asyncio.create_task(recipe_scanner.initialize_in_background(), name='recipe_cache_init')
|
||||
]
|
||||
|
||||
await ExampleImagesMigration.check_and_run_migrations()
|
||||
|
||||
logger.info("LoRA Manager: All services initialized and background tasks scheduled")
|
||||
# Schedule post-initialization tasks to run after scanners complete
|
||||
asyncio.create_task(
|
||||
cls._run_post_initialization_tasks(init_tasks),
|
||||
name='post_init_tasks'
|
||||
)
|
||||
|
||||
logger.debug("LoRA Manager: All services initialized and background tasks scheduled")
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"LoRA Manager: Error initializing services: {e}", exc_info=True)
|
||||
|
||||
@classmethod
|
||||
async def _run_post_initialization_tasks(cls, init_tasks):
|
||||
"""Run post-initialization tasks after all scanners complete"""
|
||||
try:
|
||||
logger.debug("LoRA Manager: Waiting for scanner initialization to complete...")
|
||||
|
||||
# Wait for all scanner initialization tasks to complete
|
||||
await asyncio.gather(*init_tasks, return_exceptions=True)
|
||||
|
||||
logger.debug("LoRA Manager: Scanner initialization completed, starting post-initialization tasks...")
|
||||
|
||||
# Run post-initialization tasks
|
||||
post_tasks = [
|
||||
asyncio.create_task(cls._cleanup_backup_files(), name='cleanup_bak_files'),
|
||||
asyncio.create_task(cls._cleanup_example_images_folders(), name='cleanup_example_images'),
|
||||
# Add more post-initialization tasks here as needed
|
||||
# asyncio.create_task(cls._another_post_task(), name='another_task'),
|
||||
]
|
||||
|
||||
# Run all post-initialization tasks
|
||||
results = await asyncio.gather(*post_tasks, return_exceptions=True)
|
||||
|
||||
# Log results
|
||||
for i, result in enumerate(results):
|
||||
task_name = post_tasks[i].get_name()
|
||||
if isinstance(result, Exception):
|
||||
logger.error(f"Post-initialization task '{task_name}' failed: {result}")
|
||||
else:
|
||||
logger.debug(f"Post-initialization task '{task_name}' completed successfully")
|
||||
|
||||
logger.debug("LoRA Manager: All post-initialization tasks completed")
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"LoRA Manager: Error in post-initialization tasks: {e}", exc_info=True)
|
||||
|
||||
@classmethod
|
||||
async def _cleanup_backup_files(cls):
|
||||
"""Clean up .bak files in all model roots"""
|
||||
try:
|
||||
logger.debug("Starting cleanup of .bak files in model directories...")
|
||||
|
||||
# Collect all model roots
|
||||
all_roots = set()
|
||||
all_roots.update(config.loras_roots)
|
||||
all_roots.update(config.base_models_roots)
|
||||
all_roots.update(config.embeddings_roots)
|
||||
|
||||
total_deleted = 0
|
||||
total_size_freed = 0
|
||||
|
||||
for root_path in all_roots:
|
||||
if not os.path.exists(root_path):
|
||||
continue
|
||||
|
||||
try:
|
||||
deleted_count, size_freed = await cls._cleanup_backup_files_in_directory(root_path)
|
||||
total_deleted += deleted_count
|
||||
total_size_freed += size_freed
|
||||
|
||||
if deleted_count > 0:
|
||||
logger.debug(f"Cleaned up {deleted_count} .bak files in {root_path} (freed {size_freed / (1024*1024):.2f} MB)")
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error cleaning up .bak files in {root_path}: {e}")
|
||||
|
||||
# Yield control periodically
|
||||
await asyncio.sleep(0.01)
|
||||
|
||||
if total_deleted > 0:
|
||||
logger.debug(f"Backup cleanup completed: removed {total_deleted} .bak files, freed {total_size_freed / (1024*1024):.2f} MB total")
|
||||
else:
|
||||
logger.debug("Backup cleanup completed: no .bak files found")
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error during backup file cleanup: {e}", exc_info=True)
|
||||
|
||||
@classmethod
|
||||
async def _cleanup_backup_files_in_directory(cls, directory_path: str):
|
||||
"""Clean up .bak files in a specific directory recursively
|
||||
|
||||
Args:
|
||||
directory_path: Path to the directory to clean
|
||||
|
||||
Returns:
|
||||
Tuple[int, int]: (number of files deleted, total size freed in bytes)
|
||||
"""
|
||||
deleted_count = 0
|
||||
size_freed = 0
|
||||
visited_paths = set()
|
||||
|
||||
def cleanup_recursive(path):
|
||||
nonlocal deleted_count, size_freed
|
||||
|
||||
try:
|
||||
real_path = os.path.realpath(path)
|
||||
if real_path in visited_paths:
|
||||
return
|
||||
visited_paths.add(real_path)
|
||||
|
||||
with os.scandir(path) as it:
|
||||
for entry in it:
|
||||
try:
|
||||
if entry.is_file(follow_symlinks=True) and entry.name.endswith('.bak'):
|
||||
file_size = entry.stat().st_size
|
||||
os.remove(entry.path)
|
||||
deleted_count += 1
|
||||
size_freed += file_size
|
||||
logger.debug(f"Deleted .bak file: {entry.path}")
|
||||
|
||||
elif entry.is_dir(follow_symlinks=True):
|
||||
cleanup_recursive(entry.path)
|
||||
|
||||
except Exception as e:
|
||||
logger.warning(f"Could not delete .bak file {entry.path}: {e}")
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error scanning directory {path} for .bak files: {e}")
|
||||
|
||||
# Run the recursive cleanup in a thread pool to avoid blocking
|
||||
loop = asyncio.get_event_loop()
|
||||
await loop.run_in_executor(None, cleanup_recursive, directory_path)
|
||||
|
||||
return deleted_count, size_freed
|
||||
|
||||
@classmethod
|
||||
async def _cleanup_example_images_folders(cls):
|
||||
"""Clean up invalid or empty folders in example images directory"""
|
||||
try:
|
||||
example_images_path = settings.get('example_images_path')
|
||||
if not example_images_path or not os.path.exists(example_images_path):
|
||||
logger.debug("Example images path not configured or doesn't exist, skipping cleanup")
|
||||
return
|
||||
|
||||
logger.debug(f"Starting cleanup of example images folders in: {example_images_path}")
|
||||
|
||||
# Get all scanner instances to check hash validity
|
||||
lora_scanner = await ServiceRegistry.get_lora_scanner()
|
||||
checkpoint_scanner = await ServiceRegistry.get_checkpoint_scanner()
|
||||
embedding_scanner = await ServiceRegistry.get_embedding_scanner()
|
||||
|
||||
total_folders_checked = 0
|
||||
empty_folders_removed = 0
|
||||
invalid_hash_folders_removed = 0
|
||||
|
||||
# Scan the example images directory
|
||||
try:
|
||||
with os.scandir(example_images_path) as it:
|
||||
for entry in it:
|
||||
if not entry.is_dir(follow_symlinks=False):
|
||||
continue
|
||||
|
||||
folder_name = entry.name
|
||||
folder_path = entry.path
|
||||
total_folders_checked += 1
|
||||
|
||||
try:
|
||||
# Check if folder is empty
|
||||
is_empty = cls._is_folder_empty(folder_path)
|
||||
if is_empty:
|
||||
logger.debug(f"Removing empty example images folder: {folder_name}")
|
||||
await cls._remove_folder_safely(folder_path)
|
||||
empty_folders_removed += 1
|
||||
continue
|
||||
|
||||
# Check if folder name is a valid SHA256 hash (64 hex characters)
|
||||
if len(folder_name) != 64 or not all(c in '0123456789abcdefABCDEF' for c in folder_name):
|
||||
logger.debug(f"Removing invalid hash folder: {folder_name}")
|
||||
await cls._remove_folder_safely(folder_path)
|
||||
invalid_hash_folders_removed += 1
|
||||
continue
|
||||
|
||||
# Check if hash exists in any of the scanners
|
||||
hash_exists = (
|
||||
lora_scanner.has_hash(folder_name) or
|
||||
checkpoint_scanner.has_hash(folder_name) or
|
||||
embedding_scanner.has_hash(folder_name)
|
||||
)
|
||||
|
||||
if not hash_exists:
|
||||
logger.debug(f"Removing example images folder for deleted model: {folder_name}")
|
||||
await cls._remove_folder_safely(folder_path)
|
||||
invalid_hash_folders_removed += 1
|
||||
continue
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing example images folder {folder_name}: {e}")
|
||||
|
||||
# Yield control periodically
|
||||
await asyncio.sleep(0.01)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error scanning example images directory: {e}")
|
||||
return
|
||||
|
||||
# Log final cleanup report
|
||||
total_removed = empty_folders_removed + invalid_hash_folders_removed
|
||||
if total_removed > 0:
|
||||
logger.info(f"Example images cleanup completed: checked {total_folders_checked} folders, "
|
||||
f"removed {empty_folders_removed} empty folders and {invalid_hash_folders_removed} "
|
||||
f"folders for deleted/invalid models (total: {total_removed} removed)")
|
||||
else:
|
||||
logger.debug(f"Example images cleanup completed: checked {total_folders_checked} folders, "
|
||||
f"no cleanup needed")
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error during example images cleanup: {e}", exc_info=True)
|
||||
|
||||
@classmethod
|
||||
def _is_folder_empty(cls, folder_path: str) -> bool:
|
||||
"""Check if a folder is empty
|
||||
|
||||
Args:
|
||||
folder_path: Path to the folder to check
|
||||
|
||||
Returns:
|
||||
bool: True if folder is empty, False otherwise
|
||||
"""
|
||||
try:
|
||||
with os.scandir(folder_path) as it:
|
||||
return not any(it)
|
||||
except Exception as e:
|
||||
logger.debug(f"Error checking if folder is empty {folder_path}: {e}")
|
||||
return False
|
||||
|
||||
@classmethod
|
||||
async def _remove_folder_safely(cls, folder_path: str):
|
||||
"""Safely remove a folder and all its contents
|
||||
|
||||
Args:
|
||||
folder_path: Path to the folder to remove
|
||||
"""
|
||||
try:
|
||||
import shutil
|
||||
loop = asyncio.get_event_loop()
|
||||
await loop.run_in_executor(None, shutil.rmtree, folder_path)
|
||||
except Exception as e:
|
||||
logger.warning(f"Failed to remove folder {folder_path}: {e}")
|
||||
|
||||
@classmethod
|
||||
async def _cleanup(cls, app):
|
||||
"""Cleanup resources using ServiceRegistry"""
|
||||
try:
|
||||
logger.info("LoRA Manager: Cleaning up services")
|
||||
|
||||
# Get monitors from ServiceRegistry
|
||||
lora_monitor = await ServiceRegistry.get_service("lora_monitor")
|
||||
if lora_monitor:
|
||||
lora_monitor.stop()
|
||||
logger.info("Stopped LoRA monitor")
|
||||
|
||||
checkpoint_monitor = await ServiceRegistry.get_service("checkpoint_monitor")
|
||||
if checkpoint_monitor:
|
||||
checkpoint_monitor.stop()
|
||||
logger.info("Stopped checkpoint monitor")
|
||||
|
||||
# Close CivitaiClient gracefully
|
||||
civitai_client = await ServiceRegistry.get_service("civitai_client")
|
||||
|
||||
@@ -1,7 +1,5 @@
|
||||
"""Constants used by the metadata collector"""
|
||||
|
||||
# Metadata collection constants
|
||||
|
||||
# Metadata categories
|
||||
MODELS = "models"
|
||||
PROMPTS = "prompts"
|
||||
@@ -9,6 +7,7 @@ SAMPLING = "sampling"
|
||||
LORAS = "loras"
|
||||
SIZE = "size"
|
||||
IMAGES = "images"
|
||||
IS_SAMPLER = "is_sampler" # New constant to mark sampler nodes
|
||||
|
||||
# Complete list of categories to track
|
||||
METADATA_CATEGORIES = [MODELS, PROMPTS, SAMPLING, LORAS, SIZE, IMAGES]
|
||||
|
||||
@@ -26,98 +26,179 @@ class MetadataHook:
|
||||
print("Could not locate ComfyUI execution module, metadata collection disabled")
|
||||
return
|
||||
|
||||
# Store the original _map_node_over_list function
|
||||
original_map_node_over_list = execution._map_node_over_list
|
||||
# Detect whether we're using the new async version of ComfyUI
|
||||
is_async = False
|
||||
map_node_func_name = '_map_node_over_list'
|
||||
|
||||
# Define the wrapped _map_node_over_list function
|
||||
def map_node_over_list_with_metadata(obj, input_data_all, func, allow_interrupt=False, execution_block_cb=None, pre_execute_cb=None):
|
||||
# Only collect metadata when calling the main function of nodes
|
||||
if func == obj.FUNCTION and hasattr(obj, '__class__'):
|
||||
try:
|
||||
# Get the current prompt_id from the registry
|
||||
registry = MetadataRegistry()
|
||||
prompt_id = registry.current_prompt_id
|
||||
|
||||
if prompt_id is not None:
|
||||
# Get node class type
|
||||
class_type = obj.__class__.__name__
|
||||
|
||||
# Unique ID might be available through the obj if it has a unique_id field
|
||||
node_id = getattr(obj, 'unique_id', None)
|
||||
if node_id is None and pre_execute_cb:
|
||||
# Try to extract node_id through reflection on GraphBuilder.set_default_prefix
|
||||
frame = inspect.currentframe()
|
||||
while frame:
|
||||
if 'unique_id' in frame.f_locals:
|
||||
node_id = frame.f_locals['unique_id']
|
||||
break
|
||||
frame = frame.f_back
|
||||
|
||||
# Record inputs before execution
|
||||
if node_id is not None:
|
||||
registry.record_node_execution(node_id, class_type, input_data_all, None)
|
||||
except Exception as e:
|
||||
print(f"Error collecting metadata (pre-execution): {str(e)}")
|
||||
|
||||
# Execute the original function
|
||||
results = original_map_node_over_list(obj, input_data_all, func, allow_interrupt, execution_block_cb, pre_execute_cb)
|
||||
|
||||
# After execution, collect outputs for relevant nodes
|
||||
if func == obj.FUNCTION and hasattr(obj, '__class__'):
|
||||
try:
|
||||
# Get the current prompt_id from the registry
|
||||
registry = MetadataRegistry()
|
||||
prompt_id = registry.current_prompt_id
|
||||
|
||||
if prompt_id is not None:
|
||||
# Get node class type
|
||||
class_type = obj.__class__.__name__
|
||||
|
||||
# Unique ID might be available through the obj if it has a unique_id field
|
||||
node_id = getattr(obj, 'unique_id', None)
|
||||
if node_id is None and pre_execute_cb:
|
||||
# Try to extract node_id through reflection
|
||||
frame = inspect.currentframe()
|
||||
while frame:
|
||||
if 'unique_id' in frame.f_locals:
|
||||
node_id = frame.f_locals['unique_id']
|
||||
break
|
||||
frame = frame.f_back
|
||||
|
||||
# Record outputs after execution
|
||||
if node_id is not None:
|
||||
registry.update_node_execution(node_id, class_type, results)
|
||||
except Exception as e:
|
||||
print(f"Error collecting metadata (post-execution): {str(e)}")
|
||||
|
||||
return results
|
||||
|
||||
# Also hook the execute function to track the current prompt_id
|
||||
original_execute = execution.execute
|
||||
if hasattr(execution, '_async_map_node_over_list'):
|
||||
is_async = inspect.iscoroutinefunction(execution._async_map_node_over_list)
|
||||
map_node_func_name = '_async_map_node_over_list'
|
||||
elif hasattr(execution, '_map_node_over_list'):
|
||||
is_async = inspect.iscoroutinefunction(execution._map_node_over_list)
|
||||
|
||||
def execute_with_prompt_tracking(*args, **kwargs):
|
||||
if len(args) >= 7: # Check if we have enough arguments
|
||||
server, prompt, caches, node_id, extra_data, executed, prompt_id = args[:7]
|
||||
registry = MetadataRegistry()
|
||||
|
||||
# Start collection if this is a new prompt
|
||||
if not registry.current_prompt_id or registry.current_prompt_id != prompt_id:
|
||||
registry.start_collection(prompt_id)
|
||||
|
||||
# Store the dynprompt reference for node lookups
|
||||
if hasattr(prompt, 'original_prompt'):
|
||||
registry.set_current_prompt(prompt)
|
||||
|
||||
# Execute the original function
|
||||
return original_execute(*args, **kwargs)
|
||||
|
||||
# Replace the functions
|
||||
execution._map_node_over_list = map_node_over_list_with_metadata
|
||||
execution.execute = execute_with_prompt_tracking
|
||||
# Make map_node_over_list public to avoid it being hidden by hooks
|
||||
execution.map_node_over_list = original_map_node_over_list
|
||||
if is_async:
|
||||
print("Detected async ComfyUI execution, installing async metadata hooks")
|
||||
MetadataHook._install_async_hooks(execution, map_node_func_name)
|
||||
else:
|
||||
print("Detected sync ComfyUI execution, installing sync metadata hooks")
|
||||
MetadataHook._install_sync_hooks(execution)
|
||||
|
||||
print("Metadata collection hooks installed for runtime values")
|
||||
|
||||
except Exception as e:
|
||||
print(f"Error installing metadata hooks: {str(e)}")
|
||||
|
||||
@staticmethod
|
||||
def _install_sync_hooks(execution):
|
||||
"""Install hooks for synchronous execution model"""
|
||||
# Store the original _map_node_over_list function
|
||||
original_map_node_over_list = execution._map_node_over_list
|
||||
|
||||
# Define the wrapped _map_node_over_list function
|
||||
def map_node_over_list_with_metadata(obj, input_data_all, func, allow_interrupt=False, execution_block_cb=None, pre_execute_cb=None):
|
||||
# Only collect metadata when calling the main function of nodes
|
||||
if func == obj.FUNCTION and hasattr(obj, '__class__'):
|
||||
try:
|
||||
# Get the current prompt_id from the registry
|
||||
registry = MetadataRegistry()
|
||||
prompt_id = registry.current_prompt_id
|
||||
|
||||
if prompt_id is not None:
|
||||
# Get node class type
|
||||
class_type = obj.__class__.__name__
|
||||
|
||||
# Unique ID might be available through the obj if it has a unique_id field
|
||||
node_id = getattr(obj, 'unique_id', None)
|
||||
if node_id is None and pre_execute_cb:
|
||||
# Try to extract node_id through reflection on GraphBuilder.set_default_prefix
|
||||
frame = inspect.currentframe()
|
||||
while frame:
|
||||
if 'unique_id' in frame.f_locals:
|
||||
node_id = frame.f_locals['unique_id']
|
||||
break
|
||||
frame = frame.f_back
|
||||
|
||||
# Record inputs before execution
|
||||
if node_id is not None:
|
||||
registry.record_node_execution(node_id, class_type, input_data_all, None)
|
||||
except Exception as e:
|
||||
print(f"Error collecting metadata (pre-execution): {str(e)}")
|
||||
|
||||
# Execute the original function
|
||||
results = original_map_node_over_list(obj, input_data_all, func, allow_interrupt, execution_block_cb, pre_execute_cb)
|
||||
|
||||
# After execution, collect outputs for relevant nodes
|
||||
if func == obj.FUNCTION and hasattr(obj, '__class__'):
|
||||
try:
|
||||
# Get the current prompt_id from the registry
|
||||
registry = MetadataRegistry()
|
||||
prompt_id = registry.current_prompt_id
|
||||
|
||||
if prompt_id is not None:
|
||||
# Get node class type
|
||||
class_type = obj.__class__.__name__
|
||||
|
||||
# Unique ID might be available through the obj if it has a unique_id field
|
||||
node_id = getattr(obj, 'unique_id', None)
|
||||
if node_id is None and pre_execute_cb:
|
||||
# Try to extract node_id through reflection
|
||||
frame = inspect.currentframe()
|
||||
while frame:
|
||||
if 'unique_id' in frame.f_locals:
|
||||
node_id = frame.f_locals['unique_id']
|
||||
break
|
||||
frame = frame.f_back
|
||||
|
||||
# Record outputs after execution
|
||||
if node_id is not None:
|
||||
registry.update_node_execution(node_id, class_type, results)
|
||||
except Exception as e:
|
||||
print(f"Error collecting metadata (post-execution): {str(e)}")
|
||||
|
||||
return results
|
||||
|
||||
# Also hook the execute function to track the current prompt_id
|
||||
original_execute = execution.execute
|
||||
|
||||
def execute_with_prompt_tracking(*args, **kwargs):
|
||||
if len(args) >= 7: # Check if we have enough arguments
|
||||
server, prompt, caches, node_id, extra_data, executed, prompt_id = args[:7]
|
||||
registry = MetadataRegistry()
|
||||
|
||||
# Start collection if this is a new prompt
|
||||
if not registry.current_prompt_id or registry.current_prompt_id != prompt_id:
|
||||
registry.start_collection(prompt_id)
|
||||
|
||||
# Store the dynprompt reference for node lookups
|
||||
if hasattr(prompt, 'original_prompt'):
|
||||
registry.set_current_prompt(prompt)
|
||||
|
||||
# Execute the original function
|
||||
return original_execute(*args, **kwargs)
|
||||
|
||||
# Replace the functions
|
||||
execution._map_node_over_list = map_node_over_list_with_metadata
|
||||
execution.execute = execute_with_prompt_tracking
|
||||
|
||||
@staticmethod
|
||||
def _install_async_hooks(execution, map_node_func_name='_async_map_node_over_list'):
|
||||
"""Install hooks for asynchronous execution model"""
|
||||
# Store the original _async_map_node_over_list function
|
||||
original_map_node_over_list = getattr(execution, map_node_func_name)
|
||||
|
||||
# Wrapped async function, compatible with both stable and nightly
|
||||
async def async_map_node_over_list_with_metadata(prompt_id, unique_id, obj, input_data_all, func, allow_interrupt=False, execution_block_cb=None, pre_execute_cb=None, *args, **kwargs):
|
||||
hidden_inputs = kwargs.get('hidden_inputs', None)
|
||||
# Only collect metadata when calling the main function of nodes
|
||||
if func == obj.FUNCTION and hasattr(obj, '__class__'):
|
||||
try:
|
||||
registry = MetadataRegistry()
|
||||
if prompt_id is not None:
|
||||
class_type = obj.__class__.__name__
|
||||
node_id = unique_id
|
||||
if node_id is not None:
|
||||
registry.record_node_execution(node_id, class_type, input_data_all, None)
|
||||
except Exception as e:
|
||||
print(f"Error collecting metadata (pre-execution): {str(e)}")
|
||||
|
||||
# Call original function with all args/kwargs
|
||||
results = await original_map_node_over_list(
|
||||
prompt_id, unique_id, obj, input_data_all, func,
|
||||
allow_interrupt, execution_block_cb, pre_execute_cb, *args, **kwargs
|
||||
)
|
||||
|
||||
if func == obj.FUNCTION and hasattr(obj, '__class__'):
|
||||
try:
|
||||
registry = MetadataRegistry()
|
||||
if prompt_id is not None:
|
||||
class_type = obj.__class__.__name__
|
||||
node_id = unique_id
|
||||
if node_id is not None:
|
||||
registry.update_node_execution(node_id, class_type, results)
|
||||
except Exception as e:
|
||||
print(f"Error collecting metadata (post-execution): {str(e)}")
|
||||
|
||||
return results
|
||||
|
||||
# Also hook the execute function to track the current prompt_id
|
||||
original_execute = execution.execute
|
||||
|
||||
async def async_execute_with_prompt_tracking(*args, **kwargs):
|
||||
if len(args) >= 7: # Check if we have enough arguments
|
||||
server, prompt, caches, node_id, extra_data, executed, prompt_id = args[:7]
|
||||
registry = MetadataRegistry()
|
||||
|
||||
# Start collection if this is a new prompt
|
||||
if not registry.current_prompt_id or registry.current_prompt_id != prompt_id:
|
||||
registry.start_collection(prompt_id)
|
||||
|
||||
# Store the dynprompt reference for node lookups
|
||||
if hasattr(prompt, 'original_prompt'):
|
||||
registry.set_current_prompt(prompt)
|
||||
|
||||
# Execute the original function
|
||||
return await original_execute(*args, **kwargs)
|
||||
|
||||
# Replace the functions with async versions
|
||||
setattr(execution, map_node_func_name, async_map_node_over_list_with_metadata)
|
||||
execution.execute = async_execute_with_prompt_tracking
|
||||
|
||||
@@ -1,36 +1,117 @@
|
||||
import json
|
||||
import sys
|
||||
from .constants import IMAGES
|
||||
|
||||
# Check if running in standalone mode
|
||||
standalone_mode = 'nodes' not in sys.modules
|
||||
|
||||
from .constants import MODELS, PROMPTS, SAMPLING, LORAS, SIZE
|
||||
from .constants import MODELS, PROMPTS, SAMPLING, LORAS, SIZE, IS_SAMPLER
|
||||
|
||||
class MetadataProcessor:
|
||||
"""Process and format collected metadata"""
|
||||
|
||||
@staticmethod
|
||||
def find_primary_sampler(metadata):
|
||||
"""Find the primary KSampler node (with highest denoise value)"""
|
||||
def find_primary_sampler(metadata, downstream_id=None):
|
||||
"""
|
||||
Find the primary KSampler node that executed before the given downstream node
|
||||
|
||||
Parameters:
|
||||
- metadata: The workflow metadata
|
||||
- downstream_id: Optional ID of a downstream node to help identify the specific primary sampler
|
||||
"""
|
||||
if downstream_id is None:
|
||||
if IMAGES in metadata and "first_decode" in metadata[IMAGES]:
|
||||
downstream_id = metadata[IMAGES]["first_decode"]["node_id"]
|
||||
|
||||
# If we have a downstream_id and execution_order, use it to narrow down potential samplers
|
||||
if downstream_id and "execution_order" in metadata:
|
||||
execution_order = metadata["execution_order"]
|
||||
|
||||
# Find the index of the downstream node in the execution order
|
||||
if downstream_id in execution_order:
|
||||
downstream_index = execution_order.index(downstream_id)
|
||||
|
||||
# Extract all sampler nodes that executed before the downstream node
|
||||
candidate_samplers = {}
|
||||
for i in range(downstream_index):
|
||||
node_id = execution_order[i]
|
||||
# Use IS_SAMPLER flag to identify true sampler nodes
|
||||
if node_id in metadata.get(SAMPLING, {}) and metadata[SAMPLING][node_id].get(IS_SAMPLER, False):
|
||||
candidate_samplers[node_id] = metadata[SAMPLING][node_id]
|
||||
|
||||
# If we found candidate samplers, apply primary sampler logic to these candidates only
|
||||
if candidate_samplers:
|
||||
# Collect potential primary samplers based on different criteria
|
||||
custom_advanced_samplers = []
|
||||
advanced_add_noise_samplers = []
|
||||
high_denoise_samplers = []
|
||||
max_denoise = -1
|
||||
high_denoise_id = None
|
||||
|
||||
# First, check for SamplerCustomAdvanced among candidates
|
||||
prompt = metadata.get("current_prompt")
|
||||
if prompt and prompt.original_prompt:
|
||||
for node_id in candidate_samplers:
|
||||
node_info = prompt.original_prompt.get(node_id, {})
|
||||
if node_info.get("class_type") == "SamplerCustomAdvanced":
|
||||
custom_advanced_samplers.append(node_id)
|
||||
|
||||
# Next, check for KSamplerAdvanced with add_noise="enable" among candidates
|
||||
for node_id, sampler_info in candidate_samplers.items():
|
||||
parameters = sampler_info.get("parameters", {})
|
||||
add_noise = parameters.get("add_noise")
|
||||
if add_noise == "enable":
|
||||
advanced_add_noise_samplers.append(node_id)
|
||||
|
||||
# Find the sampler with highest denoise value among candidates
|
||||
for node_id, sampler_info in candidate_samplers.items():
|
||||
parameters = sampler_info.get("parameters", {})
|
||||
denoise = parameters.get("denoise")
|
||||
if denoise is not None and denoise > max_denoise:
|
||||
max_denoise = denoise
|
||||
high_denoise_id = node_id
|
||||
|
||||
if high_denoise_id:
|
||||
high_denoise_samplers.append(high_denoise_id)
|
||||
|
||||
# Combine all potential primary samplers
|
||||
potential_samplers = custom_advanced_samplers + advanced_add_noise_samplers + high_denoise_samplers
|
||||
|
||||
# Find the most recent potential primary sampler (closest to downstream node)
|
||||
for i in range(downstream_index - 1, -1, -1):
|
||||
node_id = execution_order[i]
|
||||
if node_id in potential_samplers:
|
||||
return node_id, candidate_samplers[node_id]
|
||||
|
||||
# If no potential sampler found from our criteria, return the most recent sampler
|
||||
if candidate_samplers:
|
||||
for i in range(downstream_index - 1, -1, -1):
|
||||
node_id = execution_order[i]
|
||||
if node_id in candidate_samplers:
|
||||
return node_id, candidate_samplers[node_id]
|
||||
|
||||
# If no downstream_id provided or no suitable sampler found, fall back to original logic
|
||||
primary_sampler = None
|
||||
primary_sampler_id = None
|
||||
max_denoise = -1 # Track the highest denoise value
|
||||
max_denoise = -1
|
||||
|
||||
# First, check for SamplerCustomAdvanced
|
||||
prompt = metadata.get("current_prompt")
|
||||
if prompt and prompt.original_prompt:
|
||||
for node_id, node_info in prompt.original_prompt.items():
|
||||
if node_info.get("class_type") == "SamplerCustomAdvanced":
|
||||
# Found a SamplerCustomAdvanced node
|
||||
if node_id in metadata.get(SAMPLING, {}):
|
||||
# Check if the node is in SAMPLING and has IS_SAMPLER flag
|
||||
if node_id in metadata.get(SAMPLING, {}) and metadata[SAMPLING][node_id].get(IS_SAMPLER, False):
|
||||
return node_id, metadata[SAMPLING][node_id]
|
||||
|
||||
# Next, check for KSamplerAdvanced with add_noise="enable"
|
||||
# Next, check for KSamplerAdvanced with add_noise="enable" using IS_SAMPLER flag
|
||||
for node_id, sampler_info in metadata.get(SAMPLING, {}).items():
|
||||
# Skip if not marked as a sampler
|
||||
if not sampler_info.get(IS_SAMPLER, False):
|
||||
continue
|
||||
|
||||
parameters = sampler_info.get("parameters", {})
|
||||
add_noise = parameters.get("add_noise")
|
||||
|
||||
# If add_noise is "enable", this is likely the primary sampler for KSamplerAdvanced
|
||||
if add_noise == "enable":
|
||||
primary_sampler = sampler_info
|
||||
primary_sampler_id = node_id
|
||||
@@ -39,10 +120,12 @@ class MetadataProcessor:
|
||||
# If no specialized sampler found, find the sampler with highest denoise value
|
||||
if primary_sampler is None:
|
||||
for node_id, sampler_info in metadata.get(SAMPLING, {}).items():
|
||||
# Skip if not marked as a sampler
|
||||
if not sampler_info.get(IS_SAMPLER, False):
|
||||
continue
|
||||
|
||||
parameters = sampler_info.get("parameters", {})
|
||||
denoise = parameters.get("denoise")
|
||||
|
||||
# If denoise exists and is higher than current max, use this sampler
|
||||
if denoise is not None and denoise > max_denoise:
|
||||
max_denoise = denoise
|
||||
primary_sampler = sampler_info
|
||||
@@ -74,13 +157,18 @@ class MetadataProcessor:
|
||||
current_node_id = node_id
|
||||
current_input = input_name
|
||||
|
||||
# If we're just tracing to origin (no target_class), keep track of the last valid node
|
||||
last_valid_node = None
|
||||
|
||||
while current_depth < max_depth:
|
||||
if current_node_id not in prompt.original_prompt:
|
||||
return None
|
||||
return last_valid_node if not target_class else None
|
||||
|
||||
node_inputs = prompt.original_prompt[current_node_id].get("inputs", {})
|
||||
if current_input not in node_inputs:
|
||||
return None
|
||||
# We've reached a node without the specified input - this is our origin node
|
||||
# if we're not looking for a specific target_class
|
||||
return current_node_id if not target_class else None
|
||||
|
||||
input_value = node_inputs[current_input]
|
||||
# Input connections are formatted as [node_id, output_index]
|
||||
@@ -91,9 +179,9 @@ class MetadataProcessor:
|
||||
if target_class and prompt.original_prompt[found_node_id].get("class_type") == target_class:
|
||||
return found_node_id
|
||||
|
||||
# If we're not looking for a specific class or haven't found it yet
|
||||
# If we're not looking for a specific class, update the last valid node
|
||||
if not target_class:
|
||||
return found_node_id
|
||||
last_valid_node = found_node_id
|
||||
|
||||
# Continue tracing through intermediate nodes
|
||||
current_node_id = found_node_id
|
||||
@@ -101,16 +189,17 @@ class MetadataProcessor:
|
||||
if "conditioning" in prompt.original_prompt[current_node_id].get("inputs", {}):
|
||||
current_input = "conditioning"
|
||||
else:
|
||||
# If there's no "conditioning" input, we can't trace further
|
||||
# If there's no "conditioning" input, return the current node
|
||||
# if we're not looking for a specific target_class
|
||||
return found_node_id if not target_class else None
|
||||
else:
|
||||
# We've reached a node with no further connections
|
||||
return None
|
||||
return last_valid_node if not target_class else None
|
||||
|
||||
current_depth += 1
|
||||
|
||||
# If we've reached max depth without finding target_class
|
||||
return None
|
||||
return last_valid_node if not target_class else None
|
||||
|
||||
@staticmethod
|
||||
def find_primary_checkpoint(metadata):
|
||||
@@ -126,15 +215,87 @@ class MetadataProcessor:
|
||||
return None
|
||||
|
||||
@staticmethod
|
||||
def extract_generation_params(metadata):
|
||||
"""Extract generation parameters from metadata using node relationships"""
|
||||
def match_conditioning_to_prompts(metadata, sampler_id):
|
||||
"""
|
||||
Match conditioning objects from a sampler to prompts in metadata
|
||||
|
||||
Parameters:
|
||||
- metadata: The workflow metadata
|
||||
- sampler_id: ID of the sampler node to match
|
||||
|
||||
Returns:
|
||||
- Dictionary with 'prompt' and 'negative_prompt' if found
|
||||
"""
|
||||
result = {
|
||||
"prompt": "",
|
||||
"negative_prompt": ""
|
||||
}
|
||||
|
||||
# Check if we have stored conditioning objects for this sampler
|
||||
if sampler_id in metadata.get(PROMPTS, {}) and (
|
||||
"pos_conditioning" in metadata[PROMPTS][sampler_id] or
|
||||
"neg_conditioning" in metadata[PROMPTS][sampler_id]):
|
||||
|
||||
pos_conditioning = metadata[PROMPTS][sampler_id].get("pos_conditioning")
|
||||
neg_conditioning = metadata[PROMPTS][sampler_id].get("neg_conditioning")
|
||||
|
||||
# Helper function to recursively find prompt text for a conditioning object
|
||||
def find_prompt_text_for_conditioning(conditioning_obj, is_positive=True):
|
||||
if conditioning_obj is None:
|
||||
return ""
|
||||
|
||||
# Try to match conditioning objects with those stored by extractors
|
||||
for prompt_node_id, prompt_data in metadata[PROMPTS].items():
|
||||
# For nodes with single conditioning output
|
||||
if "conditioning" in prompt_data:
|
||||
if id(prompt_data["conditioning"]) == id(conditioning_obj):
|
||||
return prompt_data.get("text", "")
|
||||
|
||||
# For nodes with separate pos_conditioning and neg_conditioning outputs (like TSC_EfficientLoader)
|
||||
if is_positive and "positive_encoded" in prompt_data:
|
||||
if id(prompt_data["positive_encoded"]) == id(conditioning_obj):
|
||||
if "positive_text" in prompt_data:
|
||||
return prompt_data["positive_text"]
|
||||
else:
|
||||
orig_conditioning = prompt_data.get("orig_pos_cond", None)
|
||||
if orig_conditioning is not None:
|
||||
# Recursively find the prompt text for the original conditioning
|
||||
return find_prompt_text_for_conditioning(orig_conditioning, is_positive=True)
|
||||
|
||||
if not is_positive and "negative_encoded" in prompt_data:
|
||||
if id(prompt_data["negative_encoded"]) == id(conditioning_obj):
|
||||
if "negative_text" in prompt_data:
|
||||
return prompt_data["negative_text"]
|
||||
else:
|
||||
orig_conditioning = prompt_data.get("orig_neg_cond", None)
|
||||
if orig_conditioning is not None:
|
||||
# Recursively find the prompt text for the original conditioning
|
||||
return find_prompt_text_for_conditioning(orig_conditioning, is_positive=False)
|
||||
|
||||
return ""
|
||||
|
||||
# Find prompt texts using the helper function
|
||||
result["prompt"] = find_prompt_text_for_conditioning(pos_conditioning, is_positive=True)
|
||||
result["negative_prompt"] = find_prompt_text_for_conditioning(neg_conditioning, is_positive=False)
|
||||
|
||||
return result
|
||||
|
||||
@staticmethod
|
||||
def extract_generation_params(metadata, id=None):
|
||||
"""
|
||||
Extract generation parameters from metadata using node relationships
|
||||
|
||||
Parameters:
|
||||
- metadata: The workflow metadata
|
||||
- id: Optional ID of a downstream node to help identify the specific primary sampler
|
||||
"""
|
||||
params = {
|
||||
"prompt": "",
|
||||
"negative_prompt": "",
|
||||
"seed": None,
|
||||
"steps": None,
|
||||
"cfg_scale": None,
|
||||
"guidance": None, # Add guidance parameter
|
||||
# "guidance": None, # Add guidance parameter
|
||||
"sampler": None,
|
||||
"scheduler": None,
|
||||
"checkpoint": None,
|
||||
@@ -147,13 +308,20 @@ class MetadataProcessor:
|
||||
prompt = metadata.get("current_prompt")
|
||||
|
||||
# Find the primary KSampler node
|
||||
primary_sampler_id, primary_sampler = MetadataProcessor.find_primary_sampler(metadata)
|
||||
primary_sampler_id, primary_sampler = MetadataProcessor.find_primary_sampler(metadata, id)
|
||||
|
||||
# Directly get checkpoint from metadata instead of tracing
|
||||
checkpoint = MetadataProcessor.find_primary_checkpoint(metadata)
|
||||
if checkpoint:
|
||||
params["checkpoint"] = checkpoint
|
||||
|
||||
# Check if guidance parameter exists in any sampling node
|
||||
for node_id, sampler_info in metadata.get(SAMPLING, {}).items():
|
||||
parameters = sampler_info.get("parameters", {})
|
||||
if "guidance" in parameters and parameters["guidance"] is not None:
|
||||
params["guidance"] = parameters["guidance"]
|
||||
break
|
||||
|
||||
if primary_sampler:
|
||||
# Extract sampling parameters
|
||||
sampling_params = primary_sampler.get("parameters", {})
|
||||
@@ -164,7 +332,6 @@ class MetadataProcessor:
|
||||
params["sampler"] = sampling_params.get("sampler_name")
|
||||
params["scheduler"] = sampling_params.get("scheduler")
|
||||
|
||||
# Trace connections from the primary sampler
|
||||
if prompt and primary_sampler_id:
|
||||
# Check if this is a SamplerCustomAdvanced node
|
||||
is_custom_advanced = False
|
||||
@@ -172,88 +339,43 @@ class MetadataProcessor:
|
||||
is_custom_advanced = prompt.original_prompt[primary_sampler_id].get("class_type") == "SamplerCustomAdvanced"
|
||||
|
||||
if is_custom_advanced:
|
||||
# For SamplerCustomAdvanced, trace specific inputs
|
||||
|
||||
# 1. Trace sigmas input to find BasicScheduler
|
||||
scheduler_node_id = MetadataProcessor.trace_node_input(prompt, primary_sampler_id, "sigmas", "BasicScheduler", max_depth=5)
|
||||
if scheduler_node_id and scheduler_node_id in metadata.get(SAMPLING, {}):
|
||||
scheduler_params = metadata[SAMPLING][scheduler_node_id].get("parameters", {})
|
||||
params["steps"] = scheduler_params.get("steps")
|
||||
params["scheduler"] = scheduler_params.get("scheduler")
|
||||
|
||||
# 2. Trace sampler input to find KSamplerSelect
|
||||
sampler_node_id = MetadataProcessor.trace_node_input(prompt, primary_sampler_id, "sampler", "KSamplerSelect", max_depth=5)
|
||||
if sampler_node_id and sampler_node_id in metadata.get(SAMPLING, {}):
|
||||
sampler_params = metadata[SAMPLING][sampler_node_id].get("parameters", {})
|
||||
params["sampler"] = sampler_params.get("sampler_name")
|
||||
|
||||
# 3. Trace guider input for CFGGuider, FluxGuidance and CLIPTextEncode
|
||||
guider_node_id = MetadataProcessor.trace_node_input(prompt, primary_sampler_id, "guider", max_depth=5)
|
||||
if guider_node_id and guider_node_id in prompt.original_prompt:
|
||||
# Check if the guider node is a CFGGuider
|
||||
if prompt.original_prompt[guider_node_id].get("class_type") == "CFGGuider":
|
||||
# Extract cfg value from the CFGGuider
|
||||
if guider_node_id in metadata.get(SAMPLING, {}):
|
||||
cfg_params = metadata[SAMPLING][guider_node_id].get("parameters", {})
|
||||
params["cfg_scale"] = cfg_params.get("cfg")
|
||||
|
||||
# Find CLIPTextEncode for positive prompt
|
||||
positive_node_id = MetadataProcessor.trace_node_input(prompt, guider_node_id, "positive", "CLIPTextEncode", max_depth=10)
|
||||
if positive_node_id and positive_node_id in metadata.get(PROMPTS, {}):
|
||||
params["prompt"] = metadata[PROMPTS][positive_node_id].get("text", "")
|
||||
|
||||
# Find CLIPTextEncode for negative prompt
|
||||
negative_node_id = MetadataProcessor.trace_node_input(prompt, guider_node_id, "negative", "CLIPTextEncode", max_depth=10)
|
||||
if negative_node_id and negative_node_id in metadata.get(PROMPTS, {}):
|
||||
params["negative_prompt"] = metadata[PROMPTS][negative_node_id].get("text", "")
|
||||
else:
|
||||
# Look for FluxGuidance along the guider path
|
||||
flux_node_id = MetadataProcessor.trace_node_input(prompt, guider_node_id, "conditioning", "FluxGuidance", max_depth=5)
|
||||
if flux_node_id and flux_node_id in metadata.get(SAMPLING, {}):
|
||||
flux_params = metadata[SAMPLING][flux_node_id].get("parameters", {})
|
||||
params["guidance"] = flux_params.get("guidance")
|
||||
|
||||
# Find CLIPTextEncode for positive prompt (through conditioning)
|
||||
positive_node_id = MetadataProcessor.trace_node_input(prompt, guider_node_id, "conditioning", "CLIPTextEncode", max_depth=10)
|
||||
if positive_node_id and positive_node_id in metadata.get(PROMPTS, {}):
|
||||
params["prompt"] = metadata[PROMPTS][positive_node_id].get("text", "")
|
||||
# For SamplerCustomAdvanced, use the new handler method
|
||||
MetadataProcessor.handle_custom_advanced_sampler(metadata, prompt, primary_sampler_id, params)
|
||||
|
||||
else:
|
||||
# Original tracing for standard samplers
|
||||
# Trace positive prompt - look specifically for CLIPTextEncode
|
||||
positive_node_id = MetadataProcessor.trace_node_input(prompt, primary_sampler_id, "positive", "CLIPTextEncode", max_depth=10)
|
||||
if positive_node_id and positive_node_id in metadata.get(PROMPTS, {}):
|
||||
params["prompt"] = metadata[PROMPTS][positive_node_id].get("text", "")
|
||||
else:
|
||||
# If CLIPTextEncode is not found, try to find CLIPTextEncodeFlux
|
||||
positive_flux_node_id = MetadataProcessor.trace_node_input(prompt, primary_sampler_id, "positive", "CLIPTextEncodeFlux", max_depth=10)
|
||||
if positive_flux_node_id and positive_flux_node_id in metadata.get(PROMPTS, {}):
|
||||
params["prompt"] = metadata[PROMPTS][positive_flux_node_id].get("text", "")
|
||||
|
||||
# Also extract guidance value if present in the sampling data
|
||||
if positive_flux_node_id in metadata.get(SAMPLING, {}):
|
||||
flux_params = metadata[SAMPLING][positive_flux_node_id].get("parameters", {})
|
||||
if "guidance" in flux_params:
|
||||
params["guidance"] = flux_params.get("guidance")
|
||||
# For standard samplers, match conditioning objects to prompts
|
||||
prompt_results = MetadataProcessor.match_conditioning_to_prompts(metadata, primary_sampler_id)
|
||||
params["prompt"] = prompt_results["prompt"]
|
||||
params["negative_prompt"] = prompt_results["negative_prompt"]
|
||||
|
||||
# If prompts were still not found, fall back to tracing connections
|
||||
if not params["prompt"]:
|
||||
# Original tracing for standard samplers
|
||||
# Trace positive prompt - look specifically for CLIPTextEncode
|
||||
positive_node_id = MetadataProcessor.trace_node_input(prompt, primary_sampler_id, "positive", max_depth=10)
|
||||
if positive_node_id and positive_node_id in metadata.get(PROMPTS, {}):
|
||||
params["prompt"] = metadata[PROMPTS][positive_node_id].get("text", "")
|
||||
else:
|
||||
# If CLIPTextEncode is not found, try to find CLIPTextEncodeFlux
|
||||
positive_flux_node_id = MetadataProcessor.trace_node_input(prompt, primary_sampler_id, "positive", "CLIPTextEncodeFlux", max_depth=10)
|
||||
if positive_flux_node_id and positive_flux_node_id in metadata.get(PROMPTS, {}):
|
||||
params["prompt"] = metadata[PROMPTS][positive_flux_node_id].get("text", "")
|
||||
|
||||
# Trace negative prompt - look specifically for CLIPTextEncode
|
||||
negative_node_id = MetadataProcessor.trace_node_input(prompt, primary_sampler_id, "negative", max_depth=10)
|
||||
if negative_node_id and negative_node_id in metadata.get(PROMPTS, {}):
|
||||
params["negative_prompt"] = metadata[PROMPTS][negative_node_id].get("text", "")
|
||||
|
||||
# Find any FluxGuidance nodes in the positive conditioning path
|
||||
flux_node_id = MetadataProcessor.trace_node_input(prompt, primary_sampler_id, "positive", "FluxGuidance", max_depth=5)
|
||||
if flux_node_id and flux_node_id in metadata.get(SAMPLING, {}):
|
||||
flux_params = metadata[SAMPLING][flux_node_id].get("parameters", {})
|
||||
params["guidance"] = flux_params.get("guidance")
|
||||
|
||||
# Trace negative prompt - look specifically for CLIPTextEncode
|
||||
negative_node_id = MetadataProcessor.trace_node_input(prompt, primary_sampler_id, "negative", "CLIPTextEncode", max_depth=10)
|
||||
if negative_node_id and negative_node_id in metadata.get(PROMPTS, {}):
|
||||
params["negative_prompt"] = metadata[PROMPTS][negative_node_id].get("text", "")
|
||||
# For SamplerCustom, handle any additional parameters
|
||||
MetadataProcessor.handle_custom_advanced_sampler(metadata, prompt, primary_sampler_id, params)
|
||||
|
||||
# Size extraction is same for all sampler types
|
||||
# Check if the sampler itself has size information (from latent_image)
|
||||
if primary_sampler_id in metadata.get(SIZE, {}):
|
||||
width = metadata[SIZE][primary_sampler_id].get("width")
|
||||
height = metadata[SIZE][primary_sampler_id].get("height")
|
||||
if width and height:
|
||||
params["size"] = f"{width}x{height}"
|
||||
# Size extraction is same for all sampler types
|
||||
# Check if the sampler itself has size information (from latent_image)
|
||||
if primary_sampler_id in metadata.get(SIZE, {}):
|
||||
width = metadata[SIZE][primary_sampler_id].get("width")
|
||||
height = metadata[SIZE][primary_sampler_id].get("height")
|
||||
if width and height:
|
||||
params["size"] = f"{width}x{height}"
|
||||
|
||||
# Extract LoRAs using the standardized format
|
||||
lora_parts = []
|
||||
@@ -273,13 +395,19 @@ class MetadataProcessor:
|
||||
return params
|
||||
|
||||
@staticmethod
|
||||
def to_dict(metadata):
|
||||
"""Convert extracted metadata to the ComfyUI output.json format"""
|
||||
def to_dict(metadata, id=None):
|
||||
"""
|
||||
Convert extracted metadata to the ComfyUI output.json format
|
||||
|
||||
Parameters:
|
||||
- metadata: The workflow metadata
|
||||
- id: Optional ID of a downstream node to help identify the specific primary sampler
|
||||
"""
|
||||
if standalone_mode:
|
||||
# Return empty dictionary in standalone mode
|
||||
return {}
|
||||
|
||||
params = MetadataProcessor.extract_generation_params(metadata)
|
||||
params = MetadataProcessor.extract_generation_params(metadata, id)
|
||||
|
||||
# Convert all values to strings to match output.json format
|
||||
for key in params:
|
||||
@@ -289,7 +417,63 @@ class MetadataProcessor:
|
||||
return params
|
||||
|
||||
@staticmethod
|
||||
def to_json(metadata):
|
||||
def to_json(metadata, id=None):
|
||||
"""Convert metadata to JSON string"""
|
||||
params = MetadataProcessor.to_dict(metadata)
|
||||
params = MetadataProcessor.to_dict(metadata, id)
|
||||
return json.dumps(params, indent=4)
|
||||
|
||||
@staticmethod
|
||||
def handle_custom_advanced_sampler(metadata, prompt, primary_sampler_id, params):
|
||||
"""
|
||||
Handle parameter extraction for SamplerCustomAdvanced nodes
|
||||
|
||||
Parameters:
|
||||
- metadata: The workflow metadata
|
||||
- prompt: The prompt object containing node connections
|
||||
- primary_sampler_id: ID of the SamplerCustomAdvanced node
|
||||
- params: Parameters dictionary to update
|
||||
"""
|
||||
if not prompt.original_prompt or primary_sampler_id not in prompt.original_prompt:
|
||||
return
|
||||
|
||||
sampler_inputs = prompt.original_prompt[primary_sampler_id].get("inputs", {})
|
||||
|
||||
# 1. Trace sigmas input to find BasicScheduler (only if sigmas input exists)
|
||||
if "sigmas" in sampler_inputs:
|
||||
scheduler_node_id = MetadataProcessor.trace_node_input(prompt, primary_sampler_id, "sigmas", None, max_depth=5)
|
||||
if scheduler_node_id and scheduler_node_id in metadata.get(SAMPLING, {}):
|
||||
scheduler_params = metadata[SAMPLING][scheduler_node_id].get("parameters", {})
|
||||
params["steps"] = scheduler_params.get("steps")
|
||||
params["scheduler"] = scheduler_params.get("scheduler")
|
||||
|
||||
# 2. Trace sampler input to find KSamplerSelect (only if sampler input exists)
|
||||
if "sampler" in sampler_inputs:
|
||||
sampler_node_id = MetadataProcessor.trace_node_input(prompt, primary_sampler_id, "sampler", "KSamplerSelect", max_depth=5)
|
||||
if sampler_node_id and sampler_node_id in metadata.get(SAMPLING, {}):
|
||||
sampler_params = metadata[SAMPLING][sampler_node_id].get("parameters", {})
|
||||
params["sampler"] = sampler_params.get("sampler_name")
|
||||
|
||||
# 3. Trace guider input for CFGGuider and CLIPTextEncode
|
||||
if "guider" in sampler_inputs:
|
||||
guider_node_id = MetadataProcessor.trace_node_input(prompt, primary_sampler_id, "guider", max_depth=5)
|
||||
if guider_node_id and guider_node_id in prompt.original_prompt:
|
||||
# Check if the guider node is a CFGGuider
|
||||
if prompt.original_prompt[guider_node_id].get("class_type") == "CFGGuider":
|
||||
# Extract cfg value from the CFGGuider
|
||||
if guider_node_id in metadata.get(SAMPLING, {}):
|
||||
cfg_params = metadata[SAMPLING][guider_node_id].get("parameters", {})
|
||||
params["cfg_scale"] = cfg_params.get("cfg")
|
||||
|
||||
# Find CLIPTextEncode for positive prompt
|
||||
positive_node_id = MetadataProcessor.trace_node_input(prompt, guider_node_id, "positive", "CLIPTextEncode", max_depth=10)
|
||||
if positive_node_id and positive_node_id in metadata.get(PROMPTS, {}):
|
||||
params["prompt"] = metadata[PROMPTS][positive_node_id].get("text", "")
|
||||
|
||||
# Find CLIPTextEncode for negative prompt
|
||||
negative_node_id = MetadataProcessor.trace_node_input(prompt, guider_node_id, "negative", "CLIPTextEncode", max_depth=10)
|
||||
if negative_node_id and negative_node_id in metadata.get(PROMPTS, {}):
|
||||
params["negative_prompt"] = metadata[PROMPTS][negative_node_id].get("text", "")
|
||||
else:
|
||||
positive_node_id = MetadataProcessor.trace_node_input(prompt, guider_node_id, "conditioning", max_depth=10)
|
||||
if positive_node_id and positive_node_id in metadata.get(PROMPTS, {}):
|
||||
params["prompt"] = metadata[PROMPTS][positive_node_id].get("text", "")
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
import os
|
||||
|
||||
from .constants import MODELS, PROMPTS, SAMPLING, LORAS, SIZE, IMAGES
|
||||
from .constants import MODELS, PROMPTS, SAMPLING, LORAS, SIZE, IMAGES, IS_SAMPLER
|
||||
|
||||
|
||||
class NodeMetadataExtractor:
|
||||
@@ -35,7 +35,70 @@ class CheckpointLoaderExtractor(NodeMetadataExtractor):
|
||||
"type": "checkpoint",
|
||||
"node_id": node_id
|
||||
}
|
||||
|
||||
class TSCCheckpointLoaderExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs or "ckpt_name" not in inputs:
|
||||
return
|
||||
|
||||
model_name = inputs.get("ckpt_name")
|
||||
if model_name:
|
||||
metadata[MODELS][node_id] = {
|
||||
"name": model_name,
|
||||
"type": "checkpoint",
|
||||
"node_id": node_id
|
||||
}
|
||||
|
||||
# For loader node has lora_stack input, like Efficient Loader from Efficient Nodes
|
||||
active_loras = []
|
||||
|
||||
# Process lora_stack if available
|
||||
if "lora_stack" in inputs:
|
||||
lora_stack = inputs.get("lora_stack", [])
|
||||
for lora_path, model_strength, clip_strength in lora_stack:
|
||||
# Extract lora name from path (following the format in lora_loader.py)
|
||||
lora_name = os.path.splitext(os.path.basename(lora_path))[0]
|
||||
active_loras.append({
|
||||
"name": lora_name,
|
||||
"strength": model_strength
|
||||
})
|
||||
|
||||
if active_loras:
|
||||
metadata[LORAS][node_id] = {
|
||||
"lora_list": active_loras,
|
||||
"node_id": node_id
|
||||
}
|
||||
|
||||
# Extract positive and negative prompt text if available
|
||||
positive_text = inputs.get("positive", "")
|
||||
negative_text = inputs.get("negative", "")
|
||||
|
||||
if positive_text or negative_text:
|
||||
if node_id not in metadata[PROMPTS]:
|
||||
metadata[PROMPTS][node_id] = {"node_id": node_id}
|
||||
|
||||
# Store both positive and negative text
|
||||
metadata[PROMPTS][node_id]["positive_text"] = positive_text
|
||||
metadata[PROMPTS][node_id]["negative_text"] = negative_text
|
||||
|
||||
@staticmethod
|
||||
def update(node_id, outputs, metadata):
|
||||
# Handle conditioning outputs from TSC_EfficientLoader
|
||||
# outputs is a list with [(model, positive_encoded, negative_encoded, {"samples":latent}, vae, clip, dependencies,)]
|
||||
if outputs and isinstance(outputs, list) and len(outputs) > 0:
|
||||
first_output = outputs[0]
|
||||
if isinstance(first_output, tuple) and len(first_output) >= 3:
|
||||
positive_conditioning = first_output[1]
|
||||
negative_conditioning = first_output[2]
|
||||
|
||||
# Save both conditioning objects in metadata
|
||||
if node_id not in metadata[PROMPTS]:
|
||||
metadata[PROMPTS][node_id] = {"node_id": node_id}
|
||||
|
||||
metadata[PROMPTS][node_id]["positive_encoded"] = positive_conditioning
|
||||
metadata[PROMPTS][node_id]["negative_encoded"] = negative_conditioning
|
||||
|
||||
class CLIPTextEncodeExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
@@ -47,60 +110,49 @@ class CLIPTextEncodeExtractor(NodeMetadataExtractor):
|
||||
"text": text,
|
||||
"node_id": node_id
|
||||
}
|
||||
|
||||
class SamplerExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs:
|
||||
return
|
||||
|
||||
sampling_params = {}
|
||||
for key in ["seed", "steps", "cfg", "sampler_name", "scheduler", "denoise"]:
|
||||
if key in inputs:
|
||||
sampling_params[key] = inputs[key]
|
||||
|
||||
metadata[SAMPLING][node_id] = {
|
||||
"parameters": sampling_params,
|
||||
"node_id": node_id
|
||||
}
|
||||
|
||||
# Extract latent image dimensions if available
|
||||
if "latent_image" in inputs and inputs["latent_image"] is not None:
|
||||
latent = inputs["latent_image"]
|
||||
if isinstance(latent, dict) and "samples" in latent:
|
||||
# Extract dimensions from latent tensor
|
||||
samples = latent["samples"]
|
||||
if hasattr(samples, "shape") and len(samples.shape) >= 3:
|
||||
# Correct shape interpretation: [batch_size, channels, height/8, width/8]
|
||||
# Multiply by 8 to get actual pixel dimensions
|
||||
height = int(samples.shape[2] * 8)
|
||||
width = int(samples.shape[3] * 8)
|
||||
|
||||
if SIZE not in metadata:
|
||||
metadata[SIZE] = {}
|
||||
|
||||
metadata[SIZE][node_id] = {
|
||||
"width": width,
|
||||
"height": height,
|
||||
"node_id": node_id
|
||||
}
|
||||
|
||||
class KSamplerAdvancedExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs:
|
||||
return
|
||||
|
||||
def update(node_id, outputs, metadata):
|
||||
if outputs and isinstance(outputs, list) and len(outputs) > 0:
|
||||
if isinstance(outputs[0], tuple) and len(outputs[0]) > 0:
|
||||
conditioning = outputs[0][0]
|
||||
metadata[PROMPTS][node_id]["conditioning"] = conditioning
|
||||
|
||||
# Base Sampler Extractor to reduce code redundancy
|
||||
class BaseSamplerExtractor(NodeMetadataExtractor):
|
||||
"""Base extractor for sampler nodes with common functionality"""
|
||||
@staticmethod
|
||||
def extract_sampling_params(node_id, inputs, metadata, param_keys):
|
||||
"""Extract sampling parameters from inputs"""
|
||||
sampling_params = {}
|
||||
for key in ["noise_seed", "steps", "cfg", "sampler_name", "scheduler", "add_noise"]:
|
||||
for key in param_keys:
|
||||
if key in inputs:
|
||||
sampling_params[key] = inputs[key]
|
||||
|
||||
metadata[SAMPLING][node_id] = {
|
||||
"parameters": sampling_params,
|
||||
"node_id": node_id
|
||||
"node_id": node_id,
|
||||
IS_SAMPLER: True # Add sampler flag
|
||||
}
|
||||
|
||||
|
||||
@staticmethod
|
||||
def extract_conditioning(node_id, inputs, metadata):
|
||||
"""Extract conditioning objects from inputs"""
|
||||
# Store the conditioning objects directly in metadata for later matching
|
||||
pos_conditioning = inputs.get("positive", None)
|
||||
neg_conditioning = inputs.get("negative", None)
|
||||
|
||||
# Save conditioning objects in metadata for later matching
|
||||
if pos_conditioning is not None or neg_conditioning is not None:
|
||||
if node_id not in metadata[PROMPTS]:
|
||||
metadata[PROMPTS][node_id] = {"node_id": node_id}
|
||||
|
||||
metadata[PROMPTS][node_id]["pos_conditioning"] = pos_conditioning
|
||||
metadata[PROMPTS][node_id]["neg_conditioning"] = neg_conditioning
|
||||
|
||||
@staticmethod
|
||||
def extract_latent_dimensions(node_id, inputs, metadata):
|
||||
"""Extract dimensions from latent image"""
|
||||
# Extract latent image dimensions if available
|
||||
if "latent_image" in inputs and inputs["latent_image"] is not None:
|
||||
latent = inputs["latent_image"]
|
||||
@@ -121,6 +173,176 @@ class KSamplerAdvancedExtractor(NodeMetadataExtractor):
|
||||
"height": height,
|
||||
"node_id": node_id
|
||||
}
|
||||
|
||||
class SamplerExtractor(BaseSamplerExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs:
|
||||
return
|
||||
|
||||
# Extract common sampling parameters
|
||||
BaseSamplerExtractor.extract_sampling_params(
|
||||
node_id, inputs, metadata,
|
||||
["seed", "steps", "cfg", "sampler_name", "scheduler", "denoise"]
|
||||
)
|
||||
|
||||
# Extract conditioning objects
|
||||
BaseSamplerExtractor.extract_conditioning(node_id, inputs, metadata)
|
||||
|
||||
# Extract latent dimensions
|
||||
BaseSamplerExtractor.extract_latent_dimensions(node_id, inputs, metadata)
|
||||
|
||||
class KSamplerAdvancedExtractor(BaseSamplerExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs:
|
||||
return
|
||||
|
||||
# Extract common sampling parameters
|
||||
BaseSamplerExtractor.extract_sampling_params(
|
||||
node_id, inputs, metadata,
|
||||
["noise_seed", "steps", "cfg", "sampler_name", "scheduler", "add_noise"]
|
||||
)
|
||||
|
||||
# Extract conditioning objects
|
||||
BaseSamplerExtractor.extract_conditioning(node_id, inputs, metadata)
|
||||
|
||||
# Extract latent dimensions
|
||||
BaseSamplerExtractor.extract_latent_dimensions(node_id, inputs, metadata)
|
||||
|
||||
class KSamplerBasicPipeExtractor(BaseSamplerExtractor):
|
||||
"""Extractor for KSamplerBasicPipe and KSampler_inspire_pipe nodes"""
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs:
|
||||
return
|
||||
|
||||
# Extract common sampling parameters
|
||||
BaseSamplerExtractor.extract_sampling_params(
|
||||
node_id, inputs, metadata,
|
||||
["seed", "steps", "cfg", "sampler_name", "scheduler", "denoise"]
|
||||
)
|
||||
|
||||
# Extract conditioning objects from basic_pipe
|
||||
if "basic_pipe" in inputs and inputs["basic_pipe"] is not None:
|
||||
basic_pipe = inputs["basic_pipe"]
|
||||
# Typically, basic_pipe structure is (model, clip, vae, positive, negative)
|
||||
if isinstance(basic_pipe, tuple) and len(basic_pipe) >= 5:
|
||||
pos_conditioning = basic_pipe[3] # positive is at index 3
|
||||
neg_conditioning = basic_pipe[4] # negative is at index 4
|
||||
|
||||
# Save conditioning objects in metadata
|
||||
if node_id not in metadata[PROMPTS]:
|
||||
metadata[PROMPTS][node_id] = {"node_id": node_id}
|
||||
|
||||
metadata[PROMPTS][node_id]["pos_conditioning"] = pos_conditioning
|
||||
metadata[PROMPTS][node_id]["neg_conditioning"] = neg_conditioning
|
||||
|
||||
# Extract latent dimensions
|
||||
BaseSamplerExtractor.extract_latent_dimensions(node_id, inputs, metadata)
|
||||
|
||||
class KSamplerAdvancedBasicPipeExtractor(BaseSamplerExtractor):
|
||||
"""Extractor for KSamplerAdvancedBasicPipe nodes"""
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs:
|
||||
return
|
||||
|
||||
# Extract common sampling parameters
|
||||
BaseSamplerExtractor.extract_sampling_params(
|
||||
node_id, inputs, metadata,
|
||||
["noise_seed", "steps", "cfg", "sampler_name", "scheduler", "add_noise"]
|
||||
)
|
||||
|
||||
# Extract conditioning objects from basic_pipe
|
||||
if "basic_pipe" in inputs and inputs["basic_pipe"] is not None:
|
||||
basic_pipe = inputs["basic_pipe"]
|
||||
# Typically, basic_pipe structure is (model, clip, vae, positive, negative)
|
||||
if isinstance(basic_pipe, tuple) and len(basic_pipe) >= 5:
|
||||
pos_conditioning = basic_pipe[3] # positive is at index 3
|
||||
neg_conditioning = basic_pipe[4] # negative is at index 4
|
||||
|
||||
# Save conditioning objects in metadata
|
||||
if node_id not in metadata[PROMPTS]:
|
||||
metadata[PROMPTS][node_id] = {"node_id": node_id}
|
||||
|
||||
metadata[PROMPTS][node_id]["pos_conditioning"] = pos_conditioning
|
||||
metadata[PROMPTS][node_id]["neg_conditioning"] = neg_conditioning
|
||||
|
||||
# Extract latent dimensions
|
||||
BaseSamplerExtractor.extract_latent_dimensions(node_id, inputs, metadata)
|
||||
|
||||
class TSCSamplerBaseExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
# Store vae_decode setting for later use in update
|
||||
if inputs and "vae_decode" in inputs:
|
||||
if SAMPLING not in metadata:
|
||||
metadata[SAMPLING] = {}
|
||||
|
||||
if node_id not in metadata[SAMPLING]:
|
||||
metadata[SAMPLING][node_id] = {"parameters": {}, "node_id": node_id}
|
||||
|
||||
# Store the vae_decode setting
|
||||
metadata[SAMPLING][node_id]["vae_decode"] = inputs["vae_decode"]
|
||||
|
||||
@staticmethod
|
||||
def update(node_id, outputs, metadata):
|
||||
# Check if vae_decode was set to "true"
|
||||
should_save_image = True
|
||||
if SAMPLING in metadata and node_id in metadata[SAMPLING]:
|
||||
vae_decode = metadata[SAMPLING][node_id].get("vae_decode")
|
||||
if vae_decode is not None:
|
||||
should_save_image = (vae_decode == "true")
|
||||
|
||||
# Skip image saving if vae_decode isn't "true"
|
||||
if not should_save_image:
|
||||
return
|
||||
|
||||
# Ensure IMAGES category exists
|
||||
if IMAGES not in metadata:
|
||||
metadata[IMAGES] = {}
|
||||
|
||||
# Extract output_images from the TSC sampler format
|
||||
# outputs = [{"ui": {"images": preview_images}, "result": result}]
|
||||
# where result = (original_model, original_positive, original_negative, latent_list, optional_vae, output_images,)
|
||||
if outputs and isinstance(outputs, list) and len(outputs) > 0:
|
||||
# Get the first item in the list
|
||||
output_item = outputs[0]
|
||||
if isinstance(output_item, dict) and "result" in output_item:
|
||||
result = output_item["result"]
|
||||
if isinstance(result, tuple) and len(result) >= 6:
|
||||
# The output_images is the last element in the result tuple
|
||||
output_images = (result[5],)
|
||||
|
||||
# Save image data under node ID index to be captured by caching mechanism
|
||||
metadata[IMAGES][node_id] = {
|
||||
"node_id": node_id,
|
||||
"image": output_images
|
||||
}
|
||||
|
||||
# Only set first_decode if it hasn't been recorded yet
|
||||
if "first_decode" not in metadata[IMAGES]:
|
||||
metadata[IMAGES]["first_decode"] = metadata[IMAGES][node_id]
|
||||
|
||||
class TSCKSamplerExtractor(SamplerExtractor, TSCSamplerBaseExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
# Call parent extract methods
|
||||
SamplerExtractor.extract(node_id, inputs, outputs, metadata)
|
||||
TSCSamplerBaseExtractor.extract(node_id, inputs, outputs, metadata)
|
||||
|
||||
# Update method is inherited from TSCSamplerBaseExtractor
|
||||
|
||||
|
||||
class TSCKSamplerAdvancedExtractor(KSamplerAdvancedExtractor, TSCSamplerBaseExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
# Call parent extract methods
|
||||
KSamplerAdvancedExtractor.extract(node_id, inputs, outputs, metadata)
|
||||
TSCSamplerBaseExtractor.extract(node_id, inputs, outputs, metadata)
|
||||
|
||||
# Update method is inherited from TSCSamplerBaseExtractor
|
||||
|
||||
class LoraLoaderExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
@@ -269,7 +491,8 @@ class KSamplerSelectExtractor(NodeMetadataExtractor):
|
||||
|
||||
metadata[SAMPLING][node_id] = {
|
||||
"parameters": sampling_params,
|
||||
"node_id": node_id
|
||||
"node_id": node_id,
|
||||
IS_SAMPLER: False # Mark as non-primary sampler
|
||||
}
|
||||
|
||||
class BasicSchedulerExtractor(NodeMetadataExtractor):
|
||||
@@ -285,10 +508,11 @@ class BasicSchedulerExtractor(NodeMetadataExtractor):
|
||||
|
||||
metadata[SAMPLING][node_id] = {
|
||||
"parameters": sampling_params,
|
||||
"node_id": node_id
|
||||
"node_id": node_id,
|
||||
IS_SAMPLER: False # Mark as non-primary sampler
|
||||
}
|
||||
|
||||
class SamplerCustomAdvancedExtractor(NodeMetadataExtractor):
|
||||
class SamplerCustomAdvancedExtractor(BaseSamplerExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs:
|
||||
@@ -303,29 +527,12 @@ class SamplerCustomAdvancedExtractor(NodeMetadataExtractor):
|
||||
|
||||
metadata[SAMPLING][node_id] = {
|
||||
"parameters": sampling_params,
|
||||
"node_id": node_id
|
||||
"node_id": node_id,
|
||||
IS_SAMPLER: True # Add sampler flag
|
||||
}
|
||||
|
||||
# Extract latent image dimensions if available
|
||||
if "latent_image" in inputs and inputs["latent_image"] is not None:
|
||||
latent = inputs["latent_image"]
|
||||
if isinstance(latent, dict) and "samples" in latent:
|
||||
# Extract dimensions from latent tensor
|
||||
samples = latent["samples"]
|
||||
if hasattr(samples, "shape") and len(samples.shape) >= 3:
|
||||
# Correct shape interpretation: [batch_size, channels, height/8, width/8]
|
||||
# Multiply by 8 to get actual pixel dimensions
|
||||
height = int(samples.shape[2] * 8)
|
||||
width = int(samples.shape[3] * 8)
|
||||
|
||||
if SIZE not in metadata:
|
||||
metadata[SIZE] = {}
|
||||
|
||||
metadata[SIZE][node_id] = {
|
||||
"width": width,
|
||||
"height": height,
|
||||
"node_id": node_id
|
||||
}
|
||||
# Extract latent dimensions
|
||||
BaseSamplerExtractor.extract_latent_dimensions(node_id, inputs, metadata)
|
||||
|
||||
import json
|
||||
|
||||
@@ -338,11 +545,20 @@ class CLIPTextEncodeFluxExtractor(NodeMetadataExtractor):
|
||||
clip_l_text = inputs.get("clip_l", "")
|
||||
t5xxl_text = inputs.get("t5xxl", "")
|
||||
|
||||
# Create JSON string with T5 content first, then CLIP-L
|
||||
combined_text = json.dumps({
|
||||
"T5": t5xxl_text,
|
||||
"CLIP-L": clip_l_text
|
||||
})
|
||||
# If both are empty, use empty string
|
||||
if not clip_l_text and not t5xxl_text:
|
||||
combined_text = ""
|
||||
# If one is empty, use the non-empty one
|
||||
elif not clip_l_text:
|
||||
combined_text = t5xxl_text
|
||||
elif not t5xxl_text:
|
||||
combined_text = clip_l_text
|
||||
# If both have content, use JSON format
|
||||
else:
|
||||
combined_text = json.dumps({
|
||||
"T5": t5xxl_text,
|
||||
"CLIP-L": clip_l_text
|
||||
})
|
||||
|
||||
metadata[PROMPTS][node_id] = {
|
||||
"text": combined_text,
|
||||
@@ -362,6 +578,13 @@ class CLIPTextEncodeFluxExtractor(NodeMetadataExtractor):
|
||||
|
||||
metadata[SAMPLING][node_id]["parameters"]["guidance"] = guidance_value
|
||||
|
||||
@staticmethod
|
||||
def update(node_id, outputs, metadata):
|
||||
if outputs and isinstance(outputs, list) and len(outputs) > 0:
|
||||
if isinstance(outputs[0], tuple) and len(outputs[0]) > 0:
|
||||
conditioning = outputs[0][0]
|
||||
metadata[PROMPTS][node_id]["conditioning"] = conditioning
|
||||
|
||||
class CFGGuiderExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
@@ -379,23 +602,76 @@ class CFGGuiderExtractor(NodeMetadataExtractor):
|
||||
|
||||
metadata[SAMPLING][node_id]["parameters"]["cfg"] = cfg_value
|
||||
|
||||
class CR_ApplyControlNetStackExtractor(NodeMetadataExtractor):
|
||||
@staticmethod
|
||||
def extract(node_id, inputs, outputs, metadata):
|
||||
if not inputs:
|
||||
return
|
||||
|
||||
# Save the original conditioning inputs
|
||||
base_positive = inputs.get("base_positive")
|
||||
base_negative = inputs.get("base_negative")
|
||||
|
||||
if base_positive is not None or base_negative is not None:
|
||||
if node_id not in metadata[PROMPTS]:
|
||||
metadata[PROMPTS][node_id] = {"node_id": node_id}
|
||||
|
||||
metadata[PROMPTS][node_id]["orig_pos_cond"] = base_positive
|
||||
metadata[PROMPTS][node_id]["orig_neg_cond"] = base_negative
|
||||
|
||||
@staticmethod
|
||||
def update(node_id, outputs, metadata):
|
||||
# Extract transformed conditionings from outputs
|
||||
# outputs structure: [(base_positive, base_negative, show_help, )]
|
||||
if outputs and isinstance(outputs, list) and len(outputs) > 0:
|
||||
first_output = outputs[0]
|
||||
if isinstance(first_output, tuple) and len(first_output) >= 2:
|
||||
transformed_positive = first_output[0]
|
||||
transformed_negative = first_output[1]
|
||||
|
||||
# Save transformed conditioning objects in metadata
|
||||
if node_id not in metadata[PROMPTS]:
|
||||
metadata[PROMPTS][node_id] = {"node_id": node_id}
|
||||
|
||||
metadata[PROMPTS][node_id]["positive_encoded"] = transformed_positive
|
||||
metadata[PROMPTS][node_id]["negative_encoded"] = transformed_negative
|
||||
|
||||
# Registry of node-specific extractors
|
||||
# Keys are node class names
|
||||
NODE_EXTRACTORS = {
|
||||
# Sampling
|
||||
"KSampler": SamplerExtractor,
|
||||
"KSamplerAdvanced": KSamplerAdvancedExtractor,
|
||||
"SamplerCustomAdvanced": SamplerCustomAdvancedExtractor, # Updated to use dedicated extractor
|
||||
"SamplerCustom": KSamplerAdvancedExtractor,
|
||||
"SamplerCustomAdvanced": SamplerCustomAdvancedExtractor,
|
||||
"ClownsharKSampler_Beta": SamplerExtractor,
|
||||
"TSC_KSampler": TSCKSamplerExtractor, # Efficient Nodes
|
||||
"TSC_KSamplerAdvanced": TSCKSamplerAdvancedExtractor, # Efficient Nodes
|
||||
"KSamplerBasicPipe": KSamplerBasicPipeExtractor, # comfyui-impact-pack
|
||||
"KSamplerAdvancedBasicPipe": KSamplerAdvancedBasicPipeExtractor, # comfyui-impact-pack
|
||||
"KSampler_inspire_pipe": KSamplerBasicPipeExtractor, # comfyui-inspire-pack
|
||||
"KSamplerAdvanced_inspire_pipe": KSamplerAdvancedBasicPipeExtractor, # comfyui-inspire-pack
|
||||
# Sampling Selectors
|
||||
"KSamplerSelect": KSamplerSelectExtractor, # Add KSamplerSelect
|
||||
"BasicScheduler": BasicSchedulerExtractor, # Add BasicScheduler
|
||||
"AlignYourStepsScheduler": BasicSchedulerExtractor, # Add AlignYourStepsScheduler
|
||||
# Loaders
|
||||
"CheckpointLoaderSimple": CheckpointLoaderExtractor,
|
||||
"comfyLoader": CheckpointLoaderExtractor, # easy comfyLoader
|
||||
"CheckpointLoaderSimpleWithImages": CheckpointLoaderExtractor, # CheckpointLoader|pysssss
|
||||
"TSC_EfficientLoader": TSCCheckpointLoaderExtractor, # Efficient Nodes
|
||||
"UNETLoader": UNETLoaderExtractor, # Updated to use dedicated extractor
|
||||
"UnetLoaderGGUF": UNETLoaderExtractor, # Updated to use dedicated extractor
|
||||
"LoraLoader": LoraLoaderExtractor,
|
||||
"LoraManagerLoader": LoraLoaderManagerExtractor,
|
||||
# Conditioning
|
||||
"CLIPTextEncode": CLIPTextEncodeExtractor,
|
||||
"CLIPTextEncodeFlux": CLIPTextEncodeFluxExtractor, # Add CLIPTextEncodeFlux
|
||||
"WAS_Text_to_Conditioning": CLIPTextEncodeExtractor,
|
||||
"AdvancedCLIPTextEncode": CLIPTextEncodeExtractor, # From https://github.com/BlenderNeko/ComfyUI_ADV_CLIP_emb
|
||||
"smZ_CLIPTextEncode": CLIPTextEncodeExtractor, # From https://github.com/shiimizu/ComfyUI_smZNodes
|
||||
"CR_ApplyControlNetStack": CR_ApplyControlNetStackExtractor, # Add CR_ApplyControlNetStack
|
||||
"PCTextEncode": CLIPTextEncodeExtractor, # From https://github.com/asagi4/comfyui-prompt-control
|
||||
# Latent
|
||||
"EmptyLatentImage": ImageSizeExtractor,
|
||||
# Flux
|
||||
|
||||
1
py/middleware/__init__.py
Normal file
1
py/middleware/__init__.py
Normal file
@@ -0,0 +1 @@
|
||||
"""Server middleware modules"""
|
||||
53
py/middleware/cache_middleware.py
Normal file
53
py/middleware/cache_middleware.py
Normal file
@@ -0,0 +1,53 @@
|
||||
"""Cache control middleware for ComfyUI server"""
|
||||
|
||||
from aiohttp import web
|
||||
from typing import Callable, Awaitable
|
||||
|
||||
# Time in seconds
|
||||
ONE_HOUR: int = 3600
|
||||
ONE_DAY: int = 86400
|
||||
IMG_EXTENSIONS = (
|
||||
".jpg",
|
||||
".jpeg",
|
||||
".png",
|
||||
".ppm",
|
||||
".bmp",
|
||||
".pgm",
|
||||
".tif",
|
||||
".tiff",
|
||||
".webp",
|
||||
".mp4"
|
||||
)
|
||||
|
||||
|
||||
@web.middleware
|
||||
async def cache_control(
|
||||
request: web.Request, handler: Callable[[web.Request], Awaitable[web.Response]]
|
||||
) -> web.Response:
|
||||
"""Cache control middleware that sets appropriate cache headers based on file type and response status"""
|
||||
response: web.Response = await handler(request)
|
||||
|
||||
if (
|
||||
request.path.endswith(".js")
|
||||
or request.path.endswith(".css")
|
||||
or request.path.endswith("index.json")
|
||||
):
|
||||
response.headers.setdefault("Cache-Control", "no-cache")
|
||||
return response
|
||||
|
||||
# Early return for non-image files - no cache headers needed
|
||||
if not request.path.lower().endswith(IMG_EXTENSIONS):
|
||||
return response
|
||||
|
||||
# Handle image files
|
||||
if response.status == 404:
|
||||
response.headers.setdefault("Cache-Control", f"public, max-age={ONE_HOUR}")
|
||||
elif response.status in (200, 201, 202, 203, 204, 205, 206, 301, 308):
|
||||
# Success responses and permanent redirects - cache for 1 day
|
||||
response.headers.setdefault("Cache-Control", f"public, max-age={ONE_DAY}")
|
||||
elif response.status in (302, 303, 307):
|
||||
# Temporary redirects - no cache
|
||||
response.headers.setdefault("Cache-Control", "no-cache")
|
||||
# Note: 304 Not Modified falls through - no cache headers set
|
||||
|
||||
return response
|
||||
@@ -1,4 +1,5 @@
|
||||
import logging
|
||||
from server import PromptServer # type: ignore
|
||||
from ..metadata_collector.metadata_processor import MetadataProcessor
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
@@ -7,6 +8,7 @@ class DebugMetadata:
|
||||
NAME = "Debug Metadata (LoraManager)"
|
||||
CATEGORY = "Lora Manager/utils"
|
||||
DESCRIPTION = "Debug node to verify metadata_processor functionality"
|
||||
OUTPUT_NODE = True
|
||||
|
||||
@classmethod
|
||||
def INPUT_TYPES(cls):
|
||||
@@ -14,22 +16,30 @@ class DebugMetadata:
|
||||
"required": {
|
||||
"images": ("IMAGE",),
|
||||
},
|
||||
"hidden": {
|
||||
"id": "UNIQUE_ID",
|
||||
},
|
||||
}
|
||||
|
||||
RETURN_TYPES = ("STRING",)
|
||||
RETURN_NAMES = ("metadata_json",)
|
||||
RETURN_TYPES = ()
|
||||
FUNCTION = "process_metadata"
|
||||
|
||||
def process_metadata(self, images):
|
||||
def process_metadata(self, images, id):
|
||||
try:
|
||||
# Get the current execution context's metadata
|
||||
from ..metadata_collector import get_metadata
|
||||
metadata = get_metadata()
|
||||
|
||||
# Use the MetadataProcessor to convert it to JSON string
|
||||
metadata_json = MetadataProcessor.to_json(metadata)
|
||||
metadata_json = MetadataProcessor.to_json(metadata, id)
|
||||
|
||||
# Send metadata to frontend for display
|
||||
PromptServer.instance.send_sync("metadata_update", {
|
||||
"id": id,
|
||||
"metadata": metadata_json
|
||||
})
|
||||
|
||||
return (metadata_json,)
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing metadata: {e}")
|
||||
return ("{}",) # Return empty JSON object in case of error
|
||||
|
||||
return ()
|
||||
|
||||
@@ -1,15 +1,16 @@
|
||||
import logging
|
||||
import re
|
||||
from nodes import LoraLoader
|
||||
from comfy.comfy_types import IO # type: ignore
|
||||
import asyncio
|
||||
from .utils import FlexibleOptionalInputType, any_type, get_lora_info, extract_lora_name, get_loras_list
|
||||
from ..utils.utils import get_lora_info
|
||||
from .utils import FlexibleOptionalInputType, any_type, extract_lora_name, get_loras_list, nunchaku_load_lora
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class LoraManagerLoader:
|
||||
NAME = "Lora Loader (LoraManager)"
|
||||
CATEGORY = "Lora Manager/loaders"
|
||||
|
||||
|
||||
@classmethod
|
||||
def INPUT_TYPES(cls):
|
||||
return {
|
||||
@@ -17,7 +18,8 @@ class LoraManagerLoader:
|
||||
"model": ("MODEL",),
|
||||
# "clip": ("CLIP",),
|
||||
"text": (IO.STRING, {
|
||||
"multiline": True,
|
||||
"multiline": True,
|
||||
"pysssss.autocomplete": False,
|
||||
"dynamicPrompts": True,
|
||||
"tooltip": "Format: <lora:lora_name:strength> separated by spaces or punctuation",
|
||||
"placeholder": "LoRA syntax input: <lora:name:strength>"
|
||||
@@ -37,19 +39,39 @@ class LoraManagerLoader:
|
||||
|
||||
clip = kwargs.get('clip', None)
|
||||
lora_stack = kwargs.get('lora_stack', None)
|
||||
|
||||
# Check if model is a Nunchaku Flux model - simplified approach
|
||||
is_nunchaku_model = False
|
||||
|
||||
try:
|
||||
model_wrapper = model.model.diffusion_model
|
||||
# Check if model is a Nunchaku Flux model using only class name
|
||||
if model_wrapper.__class__.__name__ == "ComfyFluxWrapper":
|
||||
is_nunchaku_model = True
|
||||
logger.info("Detected Nunchaku Flux model")
|
||||
except (AttributeError, TypeError):
|
||||
# Not a model with the expected structure
|
||||
pass
|
||||
|
||||
# First process lora_stack if available
|
||||
if lora_stack:
|
||||
for lora_path, model_strength, clip_strength in lora_stack:
|
||||
# Apply the LoRA using the provided path and strengths
|
||||
model, clip = LoraLoader().load_lora(model, clip, lora_path, model_strength, clip_strength)
|
||||
# Apply the LoRA using the appropriate loader
|
||||
if is_nunchaku_model:
|
||||
# Use our custom function for Flux models
|
||||
model = nunchaku_load_lora(model, lora_path, model_strength)
|
||||
# clip remains unchanged for Nunchaku models
|
||||
else:
|
||||
# Use default loader for standard models
|
||||
model, clip = LoraLoader().load_lora(model, clip, lora_path, model_strength, clip_strength)
|
||||
|
||||
# Extract lora name for trigger words lookup
|
||||
lora_name = extract_lora_name(lora_path)
|
||||
_, trigger_words = asyncio.run(get_lora_info(lora_name))
|
||||
_, trigger_words = get_lora_info(lora_name)
|
||||
|
||||
all_trigger_words.extend(trigger_words)
|
||||
# Add clip strength to output if different from model strength
|
||||
if abs(model_strength - clip_strength) > 0.001:
|
||||
# Add clip strength to output if different from model strength (except for Nunchaku models)
|
||||
if not is_nunchaku_model and abs(model_strength - clip_strength) > 0.001:
|
||||
loaded_loras.append(f"{lora_name}: {model_strength},{clip_strength}")
|
||||
else:
|
||||
loaded_loras.append(f"{lora_name}: {model_strength}")
|
||||
@@ -66,13 +88,19 @@ class LoraManagerLoader:
|
||||
clip_strength = float(lora.get('clipStrength', model_strength))
|
||||
|
||||
# Get lora path and trigger words
|
||||
lora_path, trigger_words = asyncio.run(get_lora_info(lora_name))
|
||||
lora_path, trigger_words = get_lora_info(lora_name)
|
||||
|
||||
# Apply the LoRA using the resolved path with separate strengths
|
||||
model, clip = LoraLoader().load_lora(model, clip, lora_path, model_strength, clip_strength)
|
||||
# Apply the LoRA using the appropriate loader
|
||||
if is_nunchaku_model:
|
||||
# For Nunchaku models, use our custom function
|
||||
model = nunchaku_load_lora(model, lora_path, model_strength)
|
||||
# clip remains unchanged
|
||||
else:
|
||||
# Use default loader for standard models
|
||||
model, clip = LoraLoader().load_lora(model, clip, lora_path, model_strength, clip_strength)
|
||||
|
||||
# Include clip strength in output if different from model strength
|
||||
if abs(model_strength - clip_strength) > 0.001:
|
||||
# Include clip strength in output if different from model strength and not a Nunchaku model
|
||||
if not is_nunchaku_model and abs(model_strength - clip_strength) > 0.001:
|
||||
loaded_loras.append(f"{lora_name}: {model_strength},{clip_strength}")
|
||||
else:
|
||||
loaded_loras.append(f"{lora_name}: {model_strength}")
|
||||
@@ -102,4 +130,142 @@ class LoraManagerLoader:
|
||||
|
||||
formatted_loras_text = " ".join(formatted_loras)
|
||||
|
||||
return (model, clip, trigger_words_text, formatted_loras_text)
|
||||
|
||||
class LoraManagerTextLoader:
|
||||
NAME = "LoRA Text Loader (LoraManager)"
|
||||
CATEGORY = "Lora Manager/loaders"
|
||||
|
||||
@classmethod
|
||||
def INPUT_TYPES(cls):
|
||||
return {
|
||||
"required": {
|
||||
"model": ("MODEL",),
|
||||
"lora_syntax": (IO.STRING, {
|
||||
"defaultInput": True,
|
||||
"forceInput": True,
|
||||
"tooltip": "Format: <lora:lora_name:strength> separated by spaces or punctuation"
|
||||
}),
|
||||
},
|
||||
"optional": {
|
||||
"clip": ("CLIP",),
|
||||
"lora_stack": ("LORA_STACK",),
|
||||
}
|
||||
}
|
||||
|
||||
RETURN_TYPES = ("MODEL", "CLIP", IO.STRING, IO.STRING)
|
||||
RETURN_NAMES = ("MODEL", "CLIP", "trigger_words", "loaded_loras")
|
||||
FUNCTION = "load_loras_from_text"
|
||||
|
||||
def parse_lora_syntax(self, text):
|
||||
"""Parse LoRA syntax from text input."""
|
||||
# Pattern to match <lora:name:strength> or <lora:name:model_strength:clip_strength>
|
||||
pattern = r'<lora:([^:>]+):([^:>]+)(?::([^:>]+))?>'
|
||||
matches = re.findall(pattern, text, re.IGNORECASE)
|
||||
|
||||
loras = []
|
||||
for match in matches:
|
||||
lora_name = match[0].strip()
|
||||
model_strength = float(match[1])
|
||||
clip_strength = float(match[2]) if match[2] else model_strength
|
||||
|
||||
loras.append({
|
||||
'name': lora_name,
|
||||
'model_strength': model_strength,
|
||||
'clip_strength': clip_strength
|
||||
})
|
||||
|
||||
return loras
|
||||
|
||||
def load_loras_from_text(self, model, lora_syntax, clip=None, lora_stack=None):
|
||||
"""Load LoRAs based on text syntax input."""
|
||||
loaded_loras = []
|
||||
all_trigger_words = []
|
||||
|
||||
# Check if model is a Nunchaku Flux model - simplified approach
|
||||
is_nunchaku_model = False
|
||||
|
||||
try:
|
||||
model_wrapper = model.model.diffusion_model
|
||||
# Check if model is a Nunchaku Flux model using only class name
|
||||
if model_wrapper.__class__.__name__ == "ComfyFluxWrapper":
|
||||
is_nunchaku_model = True
|
||||
logger.info("Detected Nunchaku Flux model")
|
||||
except (AttributeError, TypeError):
|
||||
# Not a model with the expected structure
|
||||
pass
|
||||
|
||||
# First process lora_stack if available
|
||||
if lora_stack:
|
||||
for lora_path, model_strength, clip_strength in lora_stack:
|
||||
# Apply the LoRA using the appropriate loader
|
||||
if is_nunchaku_model:
|
||||
# Use our custom function for Flux models
|
||||
model = nunchaku_load_lora(model, lora_path, model_strength)
|
||||
# clip remains unchanged for Nunchaku models
|
||||
else:
|
||||
# Use default loader for standard models
|
||||
model, clip = LoraLoader().load_lora(model, clip, lora_path, model_strength, clip_strength)
|
||||
|
||||
# Extract lora name for trigger words lookup
|
||||
lora_name = extract_lora_name(lora_path)
|
||||
_, trigger_words = get_lora_info(lora_name)
|
||||
|
||||
all_trigger_words.extend(trigger_words)
|
||||
# Add clip strength to output if different from model strength (except for Nunchaku models)
|
||||
if not is_nunchaku_model and abs(model_strength - clip_strength) > 0.001:
|
||||
loaded_loras.append(f"{lora_name}: {model_strength},{clip_strength}")
|
||||
else:
|
||||
loaded_loras.append(f"{lora_name}: {model_strength}")
|
||||
|
||||
# Parse and process LoRAs from text syntax
|
||||
parsed_loras = self.parse_lora_syntax(lora_syntax)
|
||||
for lora in parsed_loras:
|
||||
lora_name = lora['name']
|
||||
model_strength = lora['model_strength']
|
||||
clip_strength = lora['clip_strength']
|
||||
|
||||
# Get lora path and trigger words
|
||||
lora_path, trigger_words = get_lora_info(lora_name)
|
||||
|
||||
# Apply the LoRA using the appropriate loader
|
||||
if is_nunchaku_model:
|
||||
# For Nunchaku models, use our custom function
|
||||
model = nunchaku_load_lora(model, lora_path, model_strength)
|
||||
# clip remains unchanged
|
||||
else:
|
||||
# Use default loader for standard models
|
||||
model, clip = LoraLoader().load_lora(model, clip, lora_path, model_strength, clip_strength)
|
||||
|
||||
# Include clip strength in output if different from model strength and not a Nunchaku model
|
||||
if not is_nunchaku_model and abs(model_strength - clip_strength) > 0.001:
|
||||
loaded_loras.append(f"{lora_name}: {model_strength},{clip_strength}")
|
||||
else:
|
||||
loaded_loras.append(f"{lora_name}: {model_strength}")
|
||||
|
||||
# Add trigger words to collection
|
||||
all_trigger_words.extend(trigger_words)
|
||||
|
||||
# use ',, ' to separate trigger words for group mode
|
||||
trigger_words_text = ",, ".join(all_trigger_words) if all_trigger_words else ""
|
||||
|
||||
# Format loaded_loras with support for both formats
|
||||
formatted_loras = []
|
||||
for item in loaded_loras:
|
||||
parts = item.split(":")
|
||||
lora_name = parts[0].strip()
|
||||
strength_parts = parts[1].strip().split(",")
|
||||
|
||||
if len(strength_parts) > 1:
|
||||
# Different model and clip strengths
|
||||
model_str = strength_parts[0].strip()
|
||||
clip_str = strength_parts[1].strip()
|
||||
formatted_loras.append(f"<lora:{lora_name}:{model_str}:{clip_str}>")
|
||||
else:
|
||||
# Same strength for both
|
||||
model_str = strength_parts[0].strip()
|
||||
formatted_loras.append(f"<lora:{lora_name}:{model_str}>")
|
||||
|
||||
formatted_loras_text = " ".join(formatted_loras)
|
||||
|
||||
return (model, clip, trigger_words_text, formatted_loras_text)
|
||||
@@ -1,9 +1,8 @@
|
||||
from comfy.comfy_types import IO # type: ignore
|
||||
from ..services.lora_scanner import LoraScanner
|
||||
from ..config import config
|
||||
import asyncio
|
||||
import os
|
||||
from .utils import FlexibleOptionalInputType, any_type, get_lora_info, extract_lora_name, get_loras_list
|
||||
from ..utils.utils import get_lora_info
|
||||
from .utils import FlexibleOptionalInputType, any_type, extract_lora_name, get_loras_list
|
||||
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
@@ -18,6 +17,7 @@ class LoraStacker:
|
||||
"required": {
|
||||
"text": (IO.STRING, {
|
||||
"multiline": True,
|
||||
"pysssss.autocomplete": False,
|
||||
"dynamicPrompts": True,
|
||||
"tooltip": "Format: <lora:lora_name:strength> separated by spaces or punctuation",
|
||||
"placeholder": "LoRA syntax input: <lora:name:strength>"
|
||||
@@ -43,7 +43,7 @@ class LoraStacker:
|
||||
# Get trigger words from existing stack entries
|
||||
for lora_path, _, _ in lora_stack:
|
||||
lora_name = extract_lora_name(lora_path)
|
||||
_, trigger_words = asyncio.run(get_lora_info(lora_name))
|
||||
_, trigger_words = get_lora_info(lora_name)
|
||||
all_trigger_words.extend(trigger_words)
|
||||
|
||||
# Process loras from kwargs with support for both old and new formats
|
||||
@@ -58,7 +58,7 @@ class LoraStacker:
|
||||
clip_strength = float(lora.get('clipStrength', model_strength))
|
||||
|
||||
# Get lora path and trigger words
|
||||
lora_path, trigger_words = asyncio.run(get_lora_info(lora_name))
|
||||
lora_path, trigger_words = get_lora_info(lora_name)
|
||||
|
||||
# Add to stack without loading
|
||||
# replace '/' with os.sep to avoid different OS path format
|
||||
|
||||
@@ -1,11 +1,9 @@
|
||||
import json
|
||||
import os
|
||||
import asyncio
|
||||
import re
|
||||
import numpy as np
|
||||
import folder_paths # type: ignore
|
||||
from ..services.lora_scanner import LoraScanner
|
||||
from ..services.checkpoint_scanner import CheckpointScanner
|
||||
from ..services.service_registry import ServiceRegistry
|
||||
from ..metadata_collector.metadata_processor import MetadataProcessor
|
||||
from ..metadata_collector import get_metadata
|
||||
from PIL import Image, PngImagePlugin
|
||||
@@ -31,16 +29,36 @@ class SaveImage:
|
||||
return {
|
||||
"required": {
|
||||
"images": ("IMAGE",),
|
||||
"filename_prefix": ("STRING", {"default": "ComfyUI"}),
|
||||
"file_format": (["png", "jpeg", "webp"],),
|
||||
"filename_prefix": ("STRING", {
|
||||
"default": "ComfyUI",
|
||||
"tooltip": "Base filename for saved images. Supports format patterns like %seed%, %width%, %height%, %model%, etc."
|
||||
}),
|
||||
"file_format": (["png", "jpeg", "webp"], {
|
||||
"tooltip": "Image format to save as. PNG preserves quality, JPEG is smaller, WebP balances size and quality."
|
||||
}),
|
||||
},
|
||||
"optional": {
|
||||
"lossless_webp": ("BOOLEAN", {"default": False}),
|
||||
"quality": ("INT", {"default": 100, "min": 1, "max": 100}),
|
||||
"embed_workflow": ("BOOLEAN", {"default": False}),
|
||||
"add_counter_to_filename": ("BOOLEAN", {"default": True}),
|
||||
"lossless_webp": ("BOOLEAN", {
|
||||
"default": False,
|
||||
"tooltip": "When enabled, saves WebP images with lossless compression. Results in larger files but no quality loss."
|
||||
}),
|
||||
"quality": ("INT", {
|
||||
"default": 100,
|
||||
"min": 1,
|
||||
"max": 100,
|
||||
"tooltip": "Compression quality for JPEG and lossy WebP formats (1-100). Higher values mean better quality but larger files."
|
||||
}),
|
||||
"embed_workflow": ("BOOLEAN", {
|
||||
"default": False,
|
||||
"tooltip": "Embeds the complete workflow data into the image metadata. Only works with PNG and WebP formats."
|
||||
}),
|
||||
"add_counter_to_filename": ("BOOLEAN", {
|
||||
"default": True,
|
||||
"tooltip": "Adds an incremental counter to filenames to prevent overwriting previous images."
|
||||
}),
|
||||
},
|
||||
"hidden": {
|
||||
"id": "UNIQUE_ID",
|
||||
"prompt": "PROMPT",
|
||||
"extra_pnginfo": "EXTRA_PNGINFO",
|
||||
},
|
||||
@@ -51,25 +69,20 @@ class SaveImage:
|
||||
FUNCTION = "process_image"
|
||||
OUTPUT_NODE = True
|
||||
|
||||
async def get_lora_hash(self, lora_name):
|
||||
def get_lora_hash(self, lora_name):
|
||||
"""Get the lora hash from cache"""
|
||||
scanner = await LoraScanner.get_instance()
|
||||
scanner = ServiceRegistry.get_service_sync("lora_scanner")
|
||||
|
||||
# Use the new direct filename lookup method
|
||||
hash_value = scanner.get_hash_by_filename(lora_name)
|
||||
if hash_value:
|
||||
return hash_value
|
||||
|
||||
# Fallback to old method for compatibility
|
||||
cache = await scanner.get_cached_data()
|
||||
for item in cache.raw_data:
|
||||
if item.get('file_name') == lora_name:
|
||||
return item.get('sha256')
|
||||
return None
|
||||
|
||||
async def get_checkpoint_hash(self, checkpoint_path):
|
||||
def get_checkpoint_hash(self, checkpoint_path):
|
||||
"""Get the checkpoint hash from cache"""
|
||||
scanner = await CheckpointScanner.get_instance()
|
||||
scanner = ServiceRegistry.get_service_sync("checkpoint_scanner")
|
||||
|
||||
if not checkpoint_path:
|
||||
return None
|
||||
@@ -82,18 +95,10 @@ class SaveImage:
|
||||
hash_value = scanner.get_hash_by_filename(checkpoint_name)
|
||||
if hash_value:
|
||||
return hash_value
|
||||
|
||||
# Fallback to old method for compatibility
|
||||
cache = await scanner.get_cached_data()
|
||||
normalized_path = checkpoint_path.replace('\\', '/')
|
||||
|
||||
for item in cache.raw_data:
|
||||
if item.get('file_name') == checkpoint_name and item.get('file_path').endswith(normalized_path):
|
||||
return item.get('sha256')
|
||||
|
||||
return None
|
||||
|
||||
async def format_metadata(self, metadata_dict):
|
||||
def format_metadata(self, metadata_dict):
|
||||
"""Format metadata in the requested format similar to userComment example"""
|
||||
if not metadata_dict:
|
||||
return ""
|
||||
@@ -120,7 +125,7 @@ class SaveImage:
|
||||
|
||||
# Get hash for each lora
|
||||
for lora_name, strength in lora_matches:
|
||||
hash_value = await self.get_lora_hash(lora_name)
|
||||
hash_value = self.get_lora_hash(lora_name)
|
||||
if hash_value:
|
||||
lora_hashes[lora_name] = hash_value
|
||||
else:
|
||||
@@ -206,7 +211,7 @@ class SaveImage:
|
||||
checkpoint = metadata_dict.get('checkpoint')
|
||||
if checkpoint is not None:
|
||||
# Get model hash
|
||||
model_hash = await self.get_checkpoint_hash(checkpoint)
|
||||
model_hash = self.get_checkpoint_hash(checkpoint)
|
||||
|
||||
# Extract basename without path
|
||||
checkpoint_name = os.path.basename(checkpoint)
|
||||
@@ -223,7 +228,7 @@ class SaveImage:
|
||||
if lora_hashes:
|
||||
lora_hash_parts = []
|
||||
for lora_name, hash_value in lora_hashes.items():
|
||||
lora_hash_parts.append(f"{lora_name}: {hash_value}")
|
||||
lora_hash_parts.append(f"{lora_name}: {hash_value[:10]}")
|
||||
|
||||
if lora_hash_parts:
|
||||
params.append(f"Lora hashes: \"{', '.join(lora_hash_parts)}\"")
|
||||
@@ -300,17 +305,16 @@ class SaveImage:
|
||||
|
||||
return filename
|
||||
|
||||
def save_images(self, images, filename_prefix, file_format, prompt=None, extra_pnginfo=None,
|
||||
def save_images(self, images, filename_prefix, file_format, id, prompt=None, extra_pnginfo=None,
|
||||
lossless_webp=True, quality=100, embed_workflow=False, add_counter_to_filename=True):
|
||||
"""Save images with metadata"""
|
||||
results = []
|
||||
|
||||
|
||||
# Get metadata using the metadata collector
|
||||
raw_metadata = get_metadata()
|
||||
metadata_dict = MetadataProcessor.to_dict(raw_metadata)
|
||||
metadata_dict = MetadataProcessor.to_dict(raw_metadata, id)
|
||||
|
||||
# Get or create metadata asynchronously
|
||||
metadata = asyncio.run(self.format_metadata(metadata_dict))
|
||||
metadata = self.format_metadata(metadata_dict)
|
||||
|
||||
# Process filename_prefix with pattern substitution
|
||||
filename_prefix = self.format_filename(filename_prefix, metadata_dict)
|
||||
@@ -378,14 +382,23 @@ class SaveImage:
|
||||
print(f"Error adding EXIF data: {e}")
|
||||
img.save(file_path, format="JPEG", **save_kwargs)
|
||||
elif file_format == "webp":
|
||||
# For WebP, also use piexif for metadata
|
||||
if metadata:
|
||||
try:
|
||||
exif_dict = {'Exif': {piexif.ExifIFD.UserComment: b'UNICODE\0' + metadata.encode('utf-16be')}}
|
||||
exif_bytes = piexif.dump(exif_dict)
|
||||
save_kwargs["exif"] = exif_bytes
|
||||
except Exception as e:
|
||||
print(f"Error adding EXIF data: {e}")
|
||||
try:
|
||||
# For WebP, use piexif for metadata
|
||||
exif_dict = {}
|
||||
|
||||
if metadata:
|
||||
exif_dict['Exif'] = {piexif.ExifIFD.UserComment: b'UNICODE\0' + metadata.encode('utf-16be')}
|
||||
|
||||
# Add workflow if needed
|
||||
if embed_workflow and extra_pnginfo is not None:
|
||||
workflow_json = json.dumps(extra_pnginfo["workflow"])
|
||||
exif_dict['0th'] = {piexif.ImageIFD.ImageDescription: "Workflow:" + workflow_json}
|
||||
|
||||
exif_bytes = piexif.dump(exif_dict)
|
||||
save_kwargs["exif"] = exif_bytes
|
||||
except Exception as e:
|
||||
print(f"Error adding EXIF data: {e}")
|
||||
|
||||
img.save(file_path, format="WEBP", **save_kwargs)
|
||||
|
||||
results.append({
|
||||
@@ -399,23 +412,28 @@ class SaveImage:
|
||||
|
||||
return results
|
||||
|
||||
def process_image(self, images, filename_prefix="ComfyUI", file_format="png", prompt=None, extra_pnginfo=None,
|
||||
def process_image(self, images, id, filename_prefix="ComfyUI", file_format="png", prompt=None, extra_pnginfo=None,
|
||||
lossless_webp=True, quality=100, embed_workflow=False, add_counter_to_filename=True):
|
||||
"""Process and save image with metadata"""
|
||||
# Make sure the output directory exists
|
||||
os.makedirs(self.output_dir, exist_ok=True)
|
||||
|
||||
# Ensure images is always a list of images
|
||||
if len(images.shape) == 3: # Single image (height, width, channels)
|
||||
images = [images]
|
||||
else: # Multiple images (batch, height, width, channels)
|
||||
images = [img for img in images]
|
||||
# If images is already a list or array of images, do nothing; otherwise, convert to list
|
||||
if isinstance(images, (list, np.ndarray)):
|
||||
pass
|
||||
else:
|
||||
# Ensure images is always a list of images
|
||||
if len(images.shape) == 3: # Single image (height, width, channels)
|
||||
images = [images]
|
||||
else: # Multiple images (batch, height, width, channels)
|
||||
images = [img for img in images]
|
||||
|
||||
# Save all images
|
||||
results = self.save_images(
|
||||
images,
|
||||
filename_prefix,
|
||||
file_format,
|
||||
id,
|
||||
prompt,
|
||||
extra_pnginfo,
|
||||
lossless_webp,
|
||||
|
||||
@@ -16,11 +16,18 @@ class TriggerWordToggle:
|
||||
def INPUT_TYPES(cls):
|
||||
return {
|
||||
"required": {
|
||||
"group_mode": ("BOOLEAN", {"default": True}),
|
||||
"group_mode": ("BOOLEAN", {
|
||||
"default": True,
|
||||
"tooltip": "When enabled, treats each group of trigger words as a single toggleable unit."
|
||||
}),
|
||||
"default_active": ("BOOLEAN", {
|
||||
"default": True,
|
||||
"tooltip": "Sets the default initial state (active or inactive) when trigger words are added."
|
||||
}),
|
||||
},
|
||||
"optional": FlexibleOptionalInputType(any_type),
|
||||
"hidden": {
|
||||
"id": "UNIQUE_ID", # 会被 ComfyUI 自动替换为唯一ID
|
||||
"id": "UNIQUE_ID",
|
||||
},
|
||||
}
|
||||
|
||||
@@ -41,17 +48,11 @@ class TriggerWordToggle:
|
||||
else:
|
||||
return data
|
||||
|
||||
def process_trigger_words(self, id, group_mode, **kwargs):
|
||||
def process_trigger_words(self, id, group_mode, default_active, **kwargs):
|
||||
# Handle both old and new formats for trigger_words
|
||||
trigger_words_data = self._get_toggle_data(kwargs, 'trigger_words')
|
||||
trigger_words_data = self._get_toggle_data(kwargs, 'orinalMessage')
|
||||
trigger_words = trigger_words_data if isinstance(trigger_words_data, str) else ""
|
||||
|
||||
# Send trigger words to frontend
|
||||
# PromptServer.instance.send_sync("trigger_word_update", {
|
||||
# "id": id,
|
||||
# "message": trigger_words
|
||||
# })
|
||||
|
||||
filtered_triggers = trigger_words
|
||||
|
||||
# Get toggle data with support for both formats
|
||||
|
||||
@@ -35,31 +35,11 @@ any_type = AnyType("*")
|
||||
# Common methods extracted from lora_loader.py and lora_stacker.py
|
||||
import os
|
||||
import logging
|
||||
import asyncio
|
||||
from ..services.lora_scanner import LoraScanner
|
||||
from ..config import config
|
||||
import copy
|
||||
import folder_paths
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
async def get_lora_info(lora_name):
|
||||
"""Get the lora path and trigger words from cache"""
|
||||
scanner = await LoraScanner.get_instance()
|
||||
cache = await scanner.get_cached_data()
|
||||
|
||||
for item in cache.raw_data:
|
||||
if item.get('file_name') == lora_name:
|
||||
file_path = item.get('file_path')
|
||||
if file_path:
|
||||
for root in config.loras_roots:
|
||||
root = root.replace(os.sep, '/')
|
||||
if file_path.startswith(root):
|
||||
relative_path = os.path.relpath(file_path, root).replace(os.sep, '/')
|
||||
# Get trigger words from civitai metadata
|
||||
civitai = item.get('civitai', {})
|
||||
trigger_words = civitai.get('trainedWords', []) if civitai else []
|
||||
return relative_path, trigger_words
|
||||
return lora_name, [] # Fallback if not found
|
||||
|
||||
def extract_lora_name(lora_path):
|
||||
"""Extract the lora name from a lora path (e.g., 'IL\\aorunIllstrious.safetensors' -> 'aorunIllstrious')"""
|
||||
# Get the basename without extension
|
||||
@@ -81,4 +61,70 @@ def get_loras_list(kwargs):
|
||||
# Unexpected format
|
||||
else:
|
||||
logger.warning(f"Unexpected loras format: {type(loras_data)}")
|
||||
return []
|
||||
return []
|
||||
|
||||
def load_state_dict_in_safetensors(path, device="cpu", filter_prefix=""):
|
||||
"""Simplified version of load_state_dict_in_safetensors that just loads from a local path"""
|
||||
import safetensors.torch
|
||||
|
||||
state_dict = {}
|
||||
with safetensors.torch.safe_open(path, framework="pt", device=device) as f:
|
||||
for k in f.keys():
|
||||
if filter_prefix and not k.startswith(filter_prefix):
|
||||
continue
|
||||
state_dict[k.removeprefix(filter_prefix)] = f.get_tensor(k)
|
||||
return state_dict
|
||||
|
||||
def to_diffusers(input_lora):
|
||||
"""Simplified version of to_diffusers for Flux LoRA conversion"""
|
||||
import torch
|
||||
from diffusers.utils.state_dict_utils import convert_unet_state_dict_to_peft
|
||||
from diffusers.loaders import FluxLoraLoaderMixin
|
||||
|
||||
if isinstance(input_lora, str):
|
||||
tensors = load_state_dict_in_safetensors(input_lora, device="cpu")
|
||||
else:
|
||||
tensors = {k: v for k, v in input_lora.items()}
|
||||
|
||||
# Convert FP8 tensors to BF16
|
||||
for k, v in tensors.items():
|
||||
if v.dtype not in [torch.float64, torch.float32, torch.bfloat16, torch.float16]:
|
||||
tensors[k] = v.to(torch.bfloat16)
|
||||
|
||||
new_tensors = FluxLoraLoaderMixin.lora_state_dict(tensors)
|
||||
new_tensors = convert_unet_state_dict_to_peft(new_tensors)
|
||||
|
||||
return new_tensors
|
||||
|
||||
def nunchaku_load_lora(model, lora_name, lora_strength):
|
||||
"""Load a Flux LoRA for Nunchaku model"""
|
||||
model_wrapper = model.model.diffusion_model
|
||||
transformer = model_wrapper.model
|
||||
|
||||
# Save the transformer temporarily
|
||||
model_wrapper.model = None
|
||||
ret_model = copy.deepcopy(model) # copy everything except the model
|
||||
ret_model_wrapper = ret_model.model.diffusion_model
|
||||
|
||||
# Restore the model and set it for the copy
|
||||
model_wrapper.model = transformer
|
||||
ret_model_wrapper.model = transformer
|
||||
|
||||
# Get full path to the LoRA file
|
||||
lora_path = folder_paths.get_full_path("loras", lora_name)
|
||||
ret_model_wrapper.loras.append((lora_path, lora_strength))
|
||||
|
||||
# Convert the LoRA to diffusers format
|
||||
sd = to_diffusers(lora_path)
|
||||
|
||||
# Handle embedding adjustment if needed
|
||||
if "transformer.x_embedder.lora_A.weight" in sd:
|
||||
new_in_channels = sd["transformer.x_embedder.lora_A.weight"].shape[1]
|
||||
assert new_in_channels % 4 == 0
|
||||
new_in_channels = new_in_channels // 4
|
||||
|
||||
old_in_channels = ret_model.model.model_config.unet_config["in_channels"]
|
||||
if old_in_channels < new_in_channels:
|
||||
ret_model.model.model_config.unet_config["in_channels"] = new_in_channels
|
||||
|
||||
return ret_model
|
||||
98
py/nodes/wanvideo_lora_select.py
Normal file
98
py/nodes/wanvideo_lora_select.py
Normal file
@@ -0,0 +1,98 @@
|
||||
from comfy.comfy_types import IO # type: ignore
|
||||
import folder_paths # type: ignore
|
||||
from ..utils.utils import get_lora_info
|
||||
from .utils import FlexibleOptionalInputType, any_type, get_loras_list
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class WanVideoLoraSelect:
|
||||
NAME = "WanVideo Lora Select (LoraManager)"
|
||||
CATEGORY = "Lora Manager/stackers"
|
||||
|
||||
@classmethod
|
||||
def INPUT_TYPES(cls):
|
||||
return {
|
||||
"required": {
|
||||
"low_mem_load": ("BOOLEAN", {"default": False, "tooltip": "Load LORA models with less VRAM usage, slower loading. This affects ALL LoRAs, not just the current ones. No effect if merge_loras is False"}),
|
||||
"merge_loras": ("BOOLEAN", {"default": True, "tooltip": "Merge LoRAs into the model, otherwise they are loaded on the fly. Always disabled for GGUF and scaled fp8 models. This affects ALL LoRAs, not just the current one"}),
|
||||
"text": (IO.STRING, {
|
||||
"multiline": True,
|
||||
"pysssss.autocomplete": False,
|
||||
"dynamicPrompts": True,
|
||||
"tooltip": "Format: <lora:lora_name:strength> separated by spaces or punctuation",
|
||||
"placeholder": "LoRA syntax input: <lora:name:strength>"
|
||||
}),
|
||||
},
|
||||
"optional": FlexibleOptionalInputType(any_type),
|
||||
}
|
||||
|
||||
RETURN_TYPES = ("WANVIDLORA", IO.STRING, IO.STRING)
|
||||
RETURN_NAMES = ("lora", "trigger_words", "active_loras")
|
||||
FUNCTION = "process_loras"
|
||||
|
||||
def process_loras(self, text, low_mem_load=False, merge_loras=True, **kwargs):
|
||||
loras_list = []
|
||||
all_trigger_words = []
|
||||
active_loras = []
|
||||
|
||||
# Process existing prev_lora if available
|
||||
prev_lora = kwargs.get('prev_lora', None)
|
||||
if prev_lora is not None:
|
||||
loras_list.extend(prev_lora)
|
||||
|
||||
if not merge_loras:
|
||||
low_mem_load = False # Unmerged LoRAs don't need low_mem_load
|
||||
|
||||
# Get blocks if available
|
||||
blocks = kwargs.get('blocks', {})
|
||||
selected_blocks = blocks.get("selected_blocks", {})
|
||||
layer_filter = blocks.get("layer_filter", "")
|
||||
|
||||
# Process loras from kwargs with support for both old and new formats
|
||||
loras_from_widget = get_loras_list(kwargs)
|
||||
for lora in loras_from_widget:
|
||||
if not lora.get('active', False):
|
||||
continue
|
||||
|
||||
lora_name = lora['name']
|
||||
model_strength = float(lora['strength'])
|
||||
clip_strength = float(lora.get('clipStrength', model_strength))
|
||||
|
||||
# Get lora path and trigger words
|
||||
lora_path, trigger_words = get_lora_info(lora_name)
|
||||
|
||||
# Create lora item for WanVideo format
|
||||
lora_item = {
|
||||
"path": folder_paths.get_full_path("loras", lora_path),
|
||||
"strength": model_strength,
|
||||
"name": lora_path.split(".")[0],
|
||||
"blocks": selected_blocks,
|
||||
"layer_filter": layer_filter,
|
||||
"low_mem_load": low_mem_load,
|
||||
"merge_loras": merge_loras,
|
||||
}
|
||||
|
||||
# Add to list and collect active loras
|
||||
loras_list.append(lora_item)
|
||||
active_loras.append((lora_name, model_strength, clip_strength))
|
||||
|
||||
# Add trigger words to collection
|
||||
all_trigger_words.extend(trigger_words)
|
||||
|
||||
# Format trigger_words for output
|
||||
trigger_words_text = ",, ".join(all_trigger_words) if all_trigger_words else ""
|
||||
|
||||
# Format active_loras for output
|
||||
formatted_loras = []
|
||||
for name, model_strength, clip_strength in active_loras:
|
||||
if abs(model_strength - clip_strength) > 0.001:
|
||||
# Different model and clip strengths
|
||||
formatted_loras.append(f"<lora:{name}:{str(model_strength).strip()}:{str(clip_strength).strip()}>")
|
||||
else:
|
||||
# Same strength for both
|
||||
formatted_loras.append(f"<lora:{name}:{str(model_strength).strip()}>")
|
||||
|
||||
active_loras_text = " ".join(formatted_loras)
|
||||
|
||||
return (loras_list, trigger_words_text, active_loras_text)
|
||||
127
py/nodes/wanvideo_lora_select_from_text.py
Normal file
127
py/nodes/wanvideo_lora_select_from_text.py
Normal file
@@ -0,0 +1,127 @@
|
||||
from comfy.comfy_types import IO
|
||||
import folder_paths
|
||||
from ..utils.utils import get_lora_info
|
||||
from .utils import any_type
|
||||
import logging
|
||||
|
||||
# 初始化日志记录器
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# 定义新节点的类
|
||||
class WanVideoLoraSelectFromText:
|
||||
# 节点在UI中显示的名称
|
||||
NAME = "WanVideo Lora Select From Text (LoraManager)"
|
||||
# 节点所属的分类
|
||||
CATEGORY = "Lora Manager/stackers"
|
||||
|
||||
@classmethod
|
||||
def INPUT_TYPES(cls):
|
||||
return {
|
||||
"required": {
|
||||
"low_mem_load": ("BOOLEAN", {"default": False, "tooltip": "Load LORA models with less VRAM usage, slower loading. This affects ALL LoRAs, not just the current ones. No effect if merge_loras is False"}),
|
||||
"merge_lora": ("BOOLEAN", {"default": True, "tooltip": "Merge LoRAs into the model, otherwise they are loaded on the fly. Always disabled for GGUF and scaled fp8 models. This affects ALL LoRAs, not just the current one"}),
|
||||
"lora_syntax": (IO.STRING, {
|
||||
"multiline": True,
|
||||
"defaultInput": True,
|
||||
"forceInput": True,
|
||||
"tooltip": "Connect a TEXT output for LoRA syntax: <lora:name:strength>"
|
||||
}),
|
||||
},
|
||||
|
||||
"optional": {
|
||||
"prev_lora": ("WANVIDLORA",),
|
||||
"blocks": ("BLOCKS",)
|
||||
}
|
||||
}
|
||||
|
||||
RETURN_TYPES = ("WANVIDLORA", IO.STRING, IO.STRING)
|
||||
RETURN_NAMES = ("lora", "trigger_words", "active_loras")
|
||||
|
||||
FUNCTION = "process_loras_from_syntax"
|
||||
|
||||
def process_loras_from_syntax(self, lora_syntax, low_mem_load=False, merge_lora=True, **kwargs):
|
||||
text_to_process = lora_syntax
|
||||
|
||||
blocks = kwargs.get('blocks', {})
|
||||
selected_blocks = blocks.get("selected_blocks", {})
|
||||
layer_filter = blocks.get("layer_filter", "")
|
||||
|
||||
loras_list = []
|
||||
all_trigger_words = []
|
||||
active_loras = []
|
||||
|
||||
prev_lora = kwargs.get('prev_lora', None)
|
||||
if prev_lora is not None:
|
||||
loras_list.extend(prev_lora)
|
||||
|
||||
if not merge_lora:
|
||||
low_mem_load = False
|
||||
|
||||
parts = text_to_process.split('<lora:')
|
||||
for part in parts[1:]:
|
||||
end_index = part.find('>')
|
||||
if end_index == -1:
|
||||
continue
|
||||
|
||||
content = part[:end_index]
|
||||
lora_parts = content.split(':')
|
||||
|
||||
lora_name_raw = ""
|
||||
model_strength = 1.0
|
||||
clip_strength = 1.0
|
||||
|
||||
if len(lora_parts) == 2:
|
||||
lora_name_raw = lora_parts[0].strip()
|
||||
try:
|
||||
model_strength = float(lora_parts[1])
|
||||
clip_strength = model_strength
|
||||
except (ValueError, IndexError):
|
||||
logger.warning(f"Invalid strength for LoRA '{lora_name_raw}'. Skipping.")
|
||||
continue
|
||||
elif len(lora_parts) >= 3:
|
||||
lora_name_raw = lora_parts[0].strip()
|
||||
try:
|
||||
model_strength = float(lora_parts[1])
|
||||
clip_strength = float(lora_parts[2])
|
||||
except (ValueError, IndexError):
|
||||
logger.warning(f"Invalid strengths for LoRA '{lora_name_raw}'. Skipping.")
|
||||
continue
|
||||
else:
|
||||
continue
|
||||
|
||||
lora_path, trigger_words = get_lora_info(lora_name_raw)
|
||||
|
||||
lora_item = {
|
||||
"path": folder_paths.get_full_path("loras", lora_path),
|
||||
"strength": model_strength,
|
||||
"name": lora_path.split(".")[0],
|
||||
"blocks": selected_blocks,
|
||||
"layer_filter": layer_filter,
|
||||
"low_mem_load": low_mem_load,
|
||||
"merge_loras": merge_lora,
|
||||
}
|
||||
|
||||
loras_list.append(lora_item)
|
||||
active_loras.append((lora_name_raw, model_strength, clip_strength))
|
||||
all_trigger_words.extend(trigger_words)
|
||||
|
||||
trigger_words_text = ",, ".join(all_trigger_words) if all_trigger_words else ""
|
||||
|
||||
formatted_loras = []
|
||||
for name, model_strength, clip_strength in active_loras:
|
||||
if abs(model_strength - clip_strength) > 0.001:
|
||||
formatted_loras.append(f"<lora:{name}:{str(model_strength).strip()}:{str(clip_strength).strip()}>")
|
||||
else:
|
||||
formatted_loras.append(f"<lora:{name}:{str(model_strength).strip()}>")
|
||||
|
||||
active_loras_text = " ".join(formatted_loras)
|
||||
|
||||
return (loras_list, trigger_words_text, active_loras_text)
|
||||
|
||||
NODE_CLASS_MAPPINGS = {
|
||||
"WanVideoLoraSelectFromText": WanVideoLoraSelectFromText
|
||||
}
|
||||
|
||||
NODE_DISPLAY_NAME_MAPPINGS = {
|
||||
"WanVideoLoraSelectFromText": "WanVideo Lora Select From Text (LoraManager)"
|
||||
}
|
||||
@@ -7,7 +7,8 @@ from .parsers import (
|
||||
RecipeFormatParser,
|
||||
ComfyMetadataParser,
|
||||
MetaFormatParser,
|
||||
AutomaticMetadataParser
|
||||
AutomaticMetadataParser,
|
||||
CivitaiApiMetadataParser
|
||||
)
|
||||
|
||||
__all__ = [
|
||||
@@ -18,5 +19,6 @@ __all__ = [
|
||||
'RecipeFormatParser',
|
||||
'ComfyMetadataParser',
|
||||
'MetaFormatParser',
|
||||
'AutomaticMetadataParser'
|
||||
'AutomaticMetadataParser',
|
||||
'CivitaiApiMetadataParser'
|
||||
]
|
||||
|
||||
@@ -7,7 +7,7 @@ import re
|
||||
from typing import Dict, List, Any, Optional, Tuple
|
||||
from abc import ABC, abstractmethod
|
||||
from ..config import config
|
||||
from .constants import VALID_LORA_TYPES
|
||||
from ..utils.constants import VALID_LORA_TYPES
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@@ -79,6 +79,9 @@ class RecipeMetadataParser(ABC):
|
||||
if 'model' in civitai_info and 'name' in civitai_info['model']:
|
||||
lora_entry['name'] = civitai_info['model']['name']
|
||||
|
||||
lora_entry['id'] = civitai_info.get('id')
|
||||
lora_entry['modelId'] = civitai_info.get('modelId')
|
||||
|
||||
# Update version if available
|
||||
if 'name' in civitai_info:
|
||||
lora_entry['version'] = civitai_info.get('name', '')
|
||||
@@ -116,10 +119,10 @@ class RecipeMetadataParser(ABC):
|
||||
# Check if exists locally
|
||||
if recipe_scanner and lora_entry['hash']:
|
||||
lora_scanner = recipe_scanner._lora_scanner
|
||||
exists_locally = lora_scanner.has_lora_hash(lora_entry['hash'])
|
||||
exists_locally = lora_scanner.has_hash(lora_entry['hash'])
|
||||
if exists_locally:
|
||||
try:
|
||||
local_path = lora_scanner.get_lora_path_by_hash(lora_entry['hash'])
|
||||
local_path = lora_scanner.get_path_by_hash(lora_entry['hash'])
|
||||
lora_entry['existsLocally'] = True
|
||||
lora_entry['localPath'] = local_path
|
||||
lora_entry['file_name'] = os.path.splitext(os.path.basename(local_path))[0]
|
||||
|
||||
@@ -1,5 +1,8 @@
|
||||
"""Constants used across recipe parsers."""
|
||||
|
||||
# Import VALID_LORA_TYPES from utils.constants
|
||||
from ..utils.constants import VALID_LORA_TYPES
|
||||
|
||||
# Constants for generation parameters
|
||||
GEN_PARAM_KEYS = [
|
||||
'prompt',
|
||||
@@ -11,6 +14,3 @@ GEN_PARAM_KEYS = [
|
||||
'size',
|
||||
'clip_skip',
|
||||
]
|
||||
|
||||
# Valid Lora types
|
||||
VALID_LORA_TYPES = ['lora', 'locon']
|
||||
|
||||
@@ -5,7 +5,8 @@ from .parsers import (
|
||||
RecipeFormatParser,
|
||||
ComfyMetadataParser,
|
||||
MetaFormatParser,
|
||||
AutomaticMetadataParser
|
||||
AutomaticMetadataParser,
|
||||
CivitaiApiMetadataParser
|
||||
)
|
||||
from .base import RecipeMetadataParser
|
||||
|
||||
@@ -15,29 +16,49 @@ class RecipeParserFactory:
|
||||
"""Factory for creating recipe metadata parsers"""
|
||||
|
||||
@staticmethod
|
||||
def create_parser(user_comment: str) -> RecipeMetadataParser:
|
||||
def create_parser(metadata) -> RecipeMetadataParser:
|
||||
"""
|
||||
Create appropriate parser based on the user comment content
|
||||
Create appropriate parser based on the metadata content
|
||||
|
||||
Args:
|
||||
user_comment: The EXIF UserComment string from the image
|
||||
metadata: The metadata from the image (dict or str)
|
||||
|
||||
Returns:
|
||||
Appropriate RecipeMetadataParser implementation
|
||||
"""
|
||||
# Try ComfyMetadataParser first since it requires valid JSON
|
||||
# First, try CivitaiApiMetadataParser for dict input
|
||||
if isinstance(metadata, dict):
|
||||
try:
|
||||
if CivitaiApiMetadataParser().is_metadata_matching(metadata):
|
||||
return CivitaiApiMetadataParser()
|
||||
except Exception as e:
|
||||
logger.debug(f"CivitaiApiMetadataParser check failed: {e}")
|
||||
pass
|
||||
|
||||
# Convert dict to string for other parsers that expect string input
|
||||
try:
|
||||
import json
|
||||
metadata_str = json.dumps(metadata)
|
||||
except Exception as e:
|
||||
logger.debug(f"Failed to convert dict to JSON string: {e}")
|
||||
return None
|
||||
else:
|
||||
metadata_str = metadata
|
||||
|
||||
# Try ComfyMetadataParser which requires valid JSON
|
||||
try:
|
||||
if ComfyMetadataParser().is_metadata_matching(user_comment):
|
||||
if ComfyMetadataParser().is_metadata_matching(metadata_str):
|
||||
return ComfyMetadataParser()
|
||||
except Exception:
|
||||
# If JSON parsing fails, move on to other parsers
|
||||
pass
|
||||
|
||||
if RecipeFormatParser().is_metadata_matching(user_comment):
|
||||
|
||||
# Check other parsers that expect string input
|
||||
if RecipeFormatParser().is_metadata_matching(metadata_str):
|
||||
return RecipeFormatParser()
|
||||
elif AutomaticMetadataParser().is_metadata_matching(user_comment):
|
||||
elif AutomaticMetadataParser().is_metadata_matching(metadata_str):
|
||||
return AutomaticMetadataParser()
|
||||
elif MetaFormatParser().is_metadata_matching(user_comment):
|
||||
elif MetaFormatParser().is_metadata_matching(metadata_str):
|
||||
return MetaFormatParser()
|
||||
else:
|
||||
return None
|
||||
|
||||
@@ -4,10 +4,12 @@ from .recipe_format import RecipeFormatParser
|
||||
from .comfy import ComfyMetadataParser
|
||||
from .meta_format import MetaFormatParser
|
||||
from .automatic import AutomaticMetadataParser
|
||||
from .civitai_image import CivitaiApiMetadataParser
|
||||
|
||||
__all__ = [
|
||||
'RecipeFormatParser',
|
||||
'ComfyMetadataParser',
|
||||
'MetaFormatParser',
|
||||
'AutomaticMetadataParser',
|
||||
'CivitaiApiMetadataParser',
|
||||
]
|
||||
|
||||
@@ -6,6 +6,7 @@ import logging
|
||||
from typing import Dict, Any
|
||||
from ..base import RecipeMetadataParser
|
||||
from ..constants import GEN_PARAM_KEYS
|
||||
from ...services.metadata_service import get_default_metadata_provider
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@@ -19,7 +20,7 @@ class AutomaticMetadataParser(RecipeMetadataParser):
|
||||
LORA_HASHES_REGEX = r', Lora hashes:\s*"([^"]+)"'
|
||||
CIVITAI_RESOURCES_REGEX = r', Civitai resources:\s*(\[\{.*?\}\])'
|
||||
CIVITAI_METADATA_REGEX = r', Civitai metadata:\s*(\{.*?\})'
|
||||
EXTRANETS_REGEX = r'<(lora|hypernet):([a-zA-Z0-9_\.\-]+):([0-9.]+)>'
|
||||
EXTRANETS_REGEX = r'<(lora|hypernet):([^:]+):(-?[0-9.]+)>'
|
||||
MODEL_HASH_PATTERN = r'Model hash: ([a-zA-Z0-9]+)'
|
||||
VAE_HASH_PATTERN = r'VAE hash: ([a-zA-Z0-9]+)'
|
||||
|
||||
@@ -30,6 +31,9 @@ class AutomaticMetadataParser(RecipeMetadataParser):
|
||||
async def parse_metadata(self, user_comment: str, recipe_scanner=None, civitai_client=None) -> Dict[str, Any]:
|
||||
"""Parse metadata from Automatic1111 format"""
|
||||
try:
|
||||
# Get metadata provider instead of using civitai_client directly
|
||||
metadata_provider = await get_default_metadata_provider()
|
||||
|
||||
# Split on Negative prompt if it exists
|
||||
if "Negative prompt:" in user_comment:
|
||||
parts = user_comment.split('Negative prompt:', 1)
|
||||
@@ -181,13 +185,30 @@ class AutomaticMetadataParser(RecipeMetadataParser):
|
||||
# First use Civitai resources if available (more reliable source)
|
||||
if metadata.get("civitai_resources"):
|
||||
for resource in metadata.get("civitai_resources", []):
|
||||
# --- Added: Parse 'air' field if present ---
|
||||
air = resource.get("air")
|
||||
if air:
|
||||
# Format: urn:air:sdxl:lora:civitai:1221007@1375651
|
||||
# Or: urn:air:sdxl:checkpoint:civitai:623891@2019115
|
||||
air_pattern = r"urn:air:[^:]+:(?P<type>[^:]+):civitai:(?P<modelId>\d+)@(?P<modelVersionId>\d+)"
|
||||
air_match = re.match(air_pattern, air)
|
||||
if air_match:
|
||||
air_type = air_match.group("type")
|
||||
air_modelId = int(air_match.group("modelId"))
|
||||
air_modelVersionId = int(air_match.group("modelVersionId"))
|
||||
# checkpoint/lycoris/lora/hypernet
|
||||
resource["type"] = air_type
|
||||
resource["modelId"] = air_modelId
|
||||
resource["modelVersionId"] = air_modelVersionId
|
||||
# --- End added ---
|
||||
|
||||
if resource.get("type") in ["lora", "lycoris", "hypernet"] and resource.get("modelVersionId"):
|
||||
# Initialize lora entry
|
||||
lora_entry = {
|
||||
'id': str(resource.get("modelVersionId")),
|
||||
'modelId': str(resource.get("modelId")) if resource.get("modelId") else None,
|
||||
'id': resource.get("modelVersionId", 0),
|
||||
'modelId': resource.get("modelId", 0),
|
||||
'name': resource.get("modelName", "Unknown LoRA"),
|
||||
'version': resource.get("modelVersionName", ""),
|
||||
'version': resource.get("modelVersionName", resource.get("versionName", "")),
|
||||
'type': resource.get("type", "lora"),
|
||||
'weight': round(float(resource.get("weight", 1.0)), 2),
|
||||
'existsLocally': False,
|
||||
@@ -199,9 +220,9 @@ class AutomaticMetadataParser(RecipeMetadataParser):
|
||||
}
|
||||
|
||||
# Get additional info from Civitai
|
||||
if civitai_client:
|
||||
if metadata_provider:
|
||||
try:
|
||||
civitai_info = await civitai_client.get_model_version_info(resource.get("modelVersionId"))
|
||||
civitai_info = await metadata_provider.get_model_version_info(resource.get("modelVersionId"))
|
||||
populated_entry = await self.populate_lora_from_civitai(
|
||||
lora_entry,
|
||||
civitai_info,
|
||||
@@ -254,11 +275,11 @@ class AutomaticMetadataParser(RecipeMetadataParser):
|
||||
}
|
||||
|
||||
# Try to get info from Civitai
|
||||
if civitai_client:
|
||||
if metadata_provider:
|
||||
try:
|
||||
if lora_hash:
|
||||
# If we have hash, use it for lookup
|
||||
civitai_info = await civitai_client.get_model_by_hash(lora_hash)
|
||||
civitai_info = await metadata_provider.get_model_by_hash(lora_hash)
|
||||
else:
|
||||
civitai_info = None
|
||||
|
||||
|
||||
363
py/recipes/parsers/civitai_image.py
Normal file
363
py/recipes/parsers/civitai_image.py
Normal file
@@ -0,0 +1,363 @@
|
||||
"""Parser for Civitai image metadata format."""
|
||||
|
||||
import json
|
||||
import logging
|
||||
from typing import Dict, Any, Union
|
||||
from ..base import RecipeMetadataParser
|
||||
from ..constants import GEN_PARAM_KEYS
|
||||
from ...services.metadata_service import get_default_metadata_provider
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class CivitaiApiMetadataParser(RecipeMetadataParser):
|
||||
"""Parser for Civitai image metadata format"""
|
||||
|
||||
def is_metadata_matching(self, metadata) -> bool:
|
||||
"""Check if the metadata matches the Civitai image metadata format
|
||||
|
||||
Args:
|
||||
metadata: The metadata from the image (dict)
|
||||
|
||||
Returns:
|
||||
bool: True if this parser can handle the metadata
|
||||
"""
|
||||
if not metadata or not isinstance(metadata, dict):
|
||||
return False
|
||||
|
||||
# Check for key markers specific to Civitai image metadata
|
||||
return any([
|
||||
"resources" in metadata,
|
||||
"civitaiResources" in metadata,
|
||||
"additionalResources" in metadata
|
||||
])
|
||||
|
||||
async def parse_metadata(self, metadata, recipe_scanner=None, civitai_client=None) -> Dict[str, Any]:
|
||||
"""Parse metadata from Civitai image format
|
||||
|
||||
Args:
|
||||
metadata: The metadata from the image (dict)
|
||||
recipe_scanner: Optional recipe scanner service
|
||||
civitai_client: Optional Civitai API client (deprecated, use metadata_provider instead)
|
||||
|
||||
Returns:
|
||||
Dict containing parsed recipe data
|
||||
"""
|
||||
try:
|
||||
# Get metadata provider instead of using civitai_client directly
|
||||
metadata_provider = await get_default_metadata_provider()
|
||||
|
||||
# Initialize result structure
|
||||
result = {
|
||||
'base_model': None,
|
||||
'loras': [],
|
||||
'gen_params': {},
|
||||
'from_civitai_image': True
|
||||
}
|
||||
|
||||
# Track already added LoRAs to prevent duplicates
|
||||
added_loras = {} # key: model_version_id or hash, value: index in result["loras"]
|
||||
|
||||
# Extract hash information from hashes field for LoRA matching
|
||||
lora_hashes = {}
|
||||
if "hashes" in metadata and isinstance(metadata["hashes"], dict):
|
||||
for key, hash_value in metadata["hashes"].items():
|
||||
if key.startswith("LORA:"):
|
||||
lora_name = key.replace("LORA:", "")
|
||||
lora_hashes[lora_name] = hash_value
|
||||
|
||||
# Extract prompt and negative prompt
|
||||
if "prompt" in metadata:
|
||||
result["gen_params"]["prompt"] = metadata["prompt"]
|
||||
|
||||
if "negativePrompt" in metadata:
|
||||
result["gen_params"]["negative_prompt"] = metadata["negativePrompt"]
|
||||
|
||||
# Extract other generation parameters
|
||||
param_mapping = {
|
||||
"steps": "steps",
|
||||
"sampler": "sampler",
|
||||
"cfgScale": "cfg_scale",
|
||||
"seed": "seed",
|
||||
"Size": "size",
|
||||
"clipSkip": "clip_skip",
|
||||
}
|
||||
|
||||
for civitai_key, our_key in param_mapping.items():
|
||||
if civitai_key in metadata and our_key in GEN_PARAM_KEYS:
|
||||
result["gen_params"][our_key] = metadata[civitai_key]
|
||||
|
||||
# Extract base model information - directly if available
|
||||
if "baseModel" in metadata:
|
||||
result["base_model"] = metadata["baseModel"]
|
||||
elif "Model hash" in metadata and metadata_provider:
|
||||
model_hash = metadata["Model hash"]
|
||||
model_info = await metadata_provider.get_model_by_hash(model_hash)
|
||||
if model_info:
|
||||
result["base_model"] = model_info.get("baseModel", "")
|
||||
elif "Model" in metadata and isinstance(metadata.get("resources"), list):
|
||||
# Try to find base model in resources
|
||||
for resource in metadata.get("resources", []):
|
||||
if resource.get("type") == "model" and resource.get("name") == metadata.get("Model"):
|
||||
# This is likely the checkpoint model
|
||||
if metadata_provider and resource.get("hash"):
|
||||
model_info = await metadata_provider.get_model_by_hash(resource.get("hash"))
|
||||
if model_info:
|
||||
result["base_model"] = model_info.get("baseModel", "")
|
||||
|
||||
base_model_counts = {}
|
||||
|
||||
# Process standard resources array
|
||||
if "resources" in metadata and isinstance(metadata["resources"], list):
|
||||
for resource in metadata["resources"]:
|
||||
# Modified to process resources without a type field as potential LoRAs
|
||||
if resource.get("type", "lora") == "lora":
|
||||
lora_hash = resource.get("hash", "")
|
||||
|
||||
# Try to get hash from the hashes field if not present in resource
|
||||
if not lora_hash and resource.get("name"):
|
||||
lora_hash = lora_hashes.get(resource["name"], "")
|
||||
|
||||
# Skip LoRAs without proper identification (hash or modelVersionId)
|
||||
if not lora_hash and not resource.get("modelVersionId"):
|
||||
logger.debug(f"Skipping LoRA resource '{resource.get('name', 'Unknown')}' - no hash or modelVersionId")
|
||||
continue
|
||||
|
||||
# Skip if we've already added this LoRA by hash
|
||||
if lora_hash and lora_hash in added_loras:
|
||||
continue
|
||||
|
||||
lora_entry = {
|
||||
'name': resource.get("name", "Unknown LoRA"),
|
||||
'type': "lora",
|
||||
'weight': float(resource.get("weight", 1.0)),
|
||||
'hash': lora_hash,
|
||||
'existsLocally': False,
|
||||
'localPath': None,
|
||||
'file_name': resource.get("name", "Unknown"),
|
||||
'thumbnailUrl': '/loras_static/images/no-preview.png',
|
||||
'baseModel': '',
|
||||
'size': 0,
|
||||
'downloadUrl': '',
|
||||
'isDeleted': False
|
||||
}
|
||||
|
||||
# Try to get info from Civitai if hash is available
|
||||
if lora_entry['hash'] and metadata_provider:
|
||||
try:
|
||||
civitai_info = await metadata_provider.get_model_by_hash(lora_hash)
|
||||
|
||||
populated_entry = await self.populate_lora_from_civitai(
|
||||
lora_entry,
|
||||
civitai_info,
|
||||
recipe_scanner,
|
||||
base_model_counts,
|
||||
lora_hash
|
||||
)
|
||||
|
||||
if populated_entry is None:
|
||||
continue # Skip invalid LoRA types
|
||||
|
||||
lora_entry = populated_entry
|
||||
|
||||
# If we have a version ID from Civitai, track it for deduplication
|
||||
if 'id' in lora_entry and lora_entry['id']:
|
||||
added_loras[str(lora_entry['id'])] = len(result["loras"])
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching Civitai info for LoRA hash {lora_entry['hash']}: {e}")
|
||||
|
||||
# Track by hash if we have it
|
||||
if lora_hash:
|
||||
added_loras[lora_hash] = len(result["loras"])
|
||||
|
||||
result["loras"].append(lora_entry)
|
||||
|
||||
# Process civitaiResources array
|
||||
if "civitaiResources" in metadata and isinstance(metadata["civitaiResources"], list):
|
||||
for resource in metadata["civitaiResources"]:
|
||||
# Get unique identifier for deduplication
|
||||
version_id = str(resource.get("modelVersionId", ""))
|
||||
|
||||
# Skip if we've already added this LoRA
|
||||
if version_id and version_id in added_loras:
|
||||
continue
|
||||
|
||||
# Initialize lora entry
|
||||
lora_entry = {
|
||||
'id': resource.get("modelVersionId", 0),
|
||||
'modelId': resource.get("modelId", 0),
|
||||
'name': resource.get("modelName", "Unknown LoRA"),
|
||||
'version': resource.get("modelVersionName", ""),
|
||||
'type': resource.get("type", "lora"),
|
||||
'weight': round(float(resource.get("weight", 1.0)), 2),
|
||||
'existsLocally': False,
|
||||
'thumbnailUrl': '/loras_static/images/no-preview.png',
|
||||
'baseModel': '',
|
||||
'size': 0,
|
||||
'downloadUrl': '',
|
||||
'isDeleted': False
|
||||
}
|
||||
|
||||
# Try to get info from Civitai if modelVersionId is available
|
||||
if version_id and metadata_provider:
|
||||
try:
|
||||
# Use get_model_version_info instead of get_model_version
|
||||
civitai_info, error = await metadata_provider.get_model_version_info(version_id)
|
||||
|
||||
if error:
|
||||
logger.warning(f"Error getting model version info: {error}")
|
||||
continue
|
||||
|
||||
populated_entry = await self.populate_lora_from_civitai(
|
||||
lora_entry,
|
||||
civitai_info,
|
||||
recipe_scanner,
|
||||
base_model_counts
|
||||
)
|
||||
|
||||
if populated_entry is None:
|
||||
continue # Skip invalid LoRA types
|
||||
|
||||
lora_entry = populated_entry
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching Civitai info for model version {version_id}: {e}")
|
||||
|
||||
# Track this LoRA in our deduplication dict
|
||||
if version_id:
|
||||
added_loras[version_id] = len(result["loras"])
|
||||
|
||||
result["loras"].append(lora_entry)
|
||||
|
||||
# Process additionalResources array
|
||||
if "additionalResources" in metadata and isinstance(metadata["additionalResources"], list):
|
||||
for resource in metadata["additionalResources"]:
|
||||
# Skip resources that aren't LoRAs or LyCORIS
|
||||
if resource.get("type") not in ["lora", "lycoris"] and "type" not in resource:
|
||||
continue
|
||||
|
||||
lora_type = resource.get("type", "lora")
|
||||
name = resource.get("name", "")
|
||||
|
||||
# Extract ID from URN format if available
|
||||
version_id = None
|
||||
if name and "civitai:" in name:
|
||||
parts = name.split("@")
|
||||
if len(parts) > 1:
|
||||
version_id = parts[1]
|
||||
|
||||
# Skip if we've already added this LoRA
|
||||
if version_id in added_loras:
|
||||
continue
|
||||
|
||||
lora_entry = {
|
||||
'name': name,
|
||||
'type': lora_type,
|
||||
'weight': float(resource.get("strength", 1.0)),
|
||||
'hash': "",
|
||||
'existsLocally': False,
|
||||
'localPath': None,
|
||||
'file_name': name,
|
||||
'thumbnailUrl': '/loras_static/images/no-preview.png',
|
||||
'baseModel': '',
|
||||
'size': 0,
|
||||
'downloadUrl': '',
|
||||
'isDeleted': False
|
||||
}
|
||||
|
||||
# If we have a version ID and metadata provider, try to get more info
|
||||
if version_id and metadata_provider:
|
||||
try:
|
||||
# Use get_model_version_info with the version ID
|
||||
civitai_info, error = await metadata_provider.get_model_version_info(version_id)
|
||||
|
||||
if error:
|
||||
logger.warning(f"Error getting model version info: {error}")
|
||||
else:
|
||||
populated_entry = await self.populate_lora_from_civitai(
|
||||
lora_entry,
|
||||
civitai_info,
|
||||
recipe_scanner,
|
||||
base_model_counts
|
||||
)
|
||||
|
||||
if populated_entry is None:
|
||||
continue # Skip invalid LoRA types
|
||||
|
||||
lora_entry = populated_entry
|
||||
|
||||
# Track this LoRA for deduplication
|
||||
if version_id:
|
||||
added_loras[version_id] = len(result["loras"])
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching Civitai info for model ID {version_id}: {e}")
|
||||
|
||||
result["loras"].append(lora_entry)
|
||||
|
||||
# Check for LoRA info in the format "Lora_0 Model hash", "Lora_0 Model name", etc.
|
||||
lora_index = 0
|
||||
while f"Lora_{lora_index} Model hash" in metadata and f"Lora_{lora_index} Model name" in metadata:
|
||||
lora_hash = metadata[f"Lora_{lora_index} Model hash"]
|
||||
lora_name = metadata[f"Lora_{lora_index} Model name"]
|
||||
lora_strength_model = float(metadata.get(f"Lora_{lora_index} Strength model", 1.0))
|
||||
|
||||
# Skip if we've already added this LoRA by hash
|
||||
if lora_hash and lora_hash in added_loras:
|
||||
lora_index += 1
|
||||
continue
|
||||
|
||||
lora_entry = {
|
||||
'name': lora_name,
|
||||
'type': "lora",
|
||||
'weight': lora_strength_model,
|
||||
'hash': lora_hash,
|
||||
'existsLocally': False,
|
||||
'localPath': None,
|
||||
'file_name': lora_name,
|
||||
'thumbnailUrl': '/loras_static/images/no-preview.png',
|
||||
'baseModel': '',
|
||||
'size': 0,
|
||||
'downloadUrl': '',
|
||||
'isDeleted': False
|
||||
}
|
||||
|
||||
# Try to get info from Civitai if hash is available
|
||||
if lora_entry['hash'] and metadata_provider:
|
||||
try:
|
||||
civitai_info = await metadata_provider.get_model_by_hash(lora_hash)
|
||||
|
||||
populated_entry = await self.populate_lora_from_civitai(
|
||||
lora_entry,
|
||||
civitai_info,
|
||||
recipe_scanner,
|
||||
base_model_counts,
|
||||
lora_hash
|
||||
)
|
||||
|
||||
if populated_entry is None:
|
||||
lora_index += 1
|
||||
continue # Skip invalid LoRA types
|
||||
|
||||
lora_entry = populated_entry
|
||||
|
||||
# If we have a version ID from Civitai, track it for deduplication
|
||||
if 'id' in lora_entry and lora_entry['id']:
|
||||
added_loras[str(lora_entry['id'])] = len(result["loras"])
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching Civitai info for LoRA hash {lora_entry['hash']}: {e}")
|
||||
|
||||
# Track by hash if we have it
|
||||
if lora_hash:
|
||||
added_loras[lora_hash] = len(result["loras"])
|
||||
|
||||
result["loras"].append(lora_entry)
|
||||
|
||||
lora_index += 1
|
||||
|
||||
# If base model wasn't found earlier, use the most common one from LoRAs
|
||||
if not result["base_model"] and base_model_counts:
|
||||
result["base_model"] = max(base_model_counts.items(), key=lambda x: x[1])[0]
|
||||
|
||||
return result
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error parsing Civitai image metadata: {e}", exc_info=True)
|
||||
return {"error": str(e), "loras": []}
|
||||
@@ -6,6 +6,7 @@ import logging
|
||||
from typing import Dict, Any
|
||||
from ..base import RecipeMetadataParser
|
||||
from ..constants import GEN_PARAM_KEYS
|
||||
from ...services.metadata_service import get_default_metadata_provider
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@@ -26,6 +27,9 @@ class ComfyMetadataParser(RecipeMetadataParser):
|
||||
async def parse_metadata(self, user_comment: str, recipe_scanner=None, civitai_client=None) -> Dict[str, Any]:
|
||||
"""Parse metadata from Civitai ComfyUI metadata format"""
|
||||
try:
|
||||
# Get metadata provider instead of using civitai_client directly
|
||||
metadata_provider = await get_default_metadata_provider()
|
||||
|
||||
data = json.loads(user_comment)
|
||||
loras = []
|
||||
|
||||
@@ -73,10 +77,10 @@ class ComfyMetadataParser(RecipeMetadataParser):
|
||||
'isDeleted': False
|
||||
}
|
||||
|
||||
# Get additional info from Civitai if client is available
|
||||
if civitai_client:
|
||||
# Get additional info from Civitai if metadata provider is available
|
||||
if metadata_provider:
|
||||
try:
|
||||
civitai_info_tuple = await civitai_client.get_model_version_info(model_version_id)
|
||||
civitai_info_tuple = await metadata_provider.get_model_version_info(model_version_id)
|
||||
# Populate lora entry with Civitai info
|
||||
populated_entry = await self.populate_lora_from_civitai(
|
||||
lora_entry,
|
||||
@@ -116,9 +120,9 @@ class ComfyMetadataParser(RecipeMetadataParser):
|
||||
}
|
||||
|
||||
# Get additional checkpoint info from Civitai
|
||||
if civitai_client:
|
||||
if metadata_provider:
|
||||
try:
|
||||
civitai_info_tuple = await civitai_client.get_model_version_info(checkpoint_version_id)
|
||||
civitai_info_tuple = await metadata_provider.get_model_version_info(checkpoint_version_id)
|
||||
civitai_info, _ = civitai_info_tuple if isinstance(civitai_info_tuple, tuple) else (civitai_info_tuple, None)
|
||||
# Populate checkpoint with Civitai info
|
||||
checkpoint = await self.populate_checkpoint_from_civitai(checkpoint, civitai_info)
|
||||
|
||||
@@ -5,6 +5,7 @@ import logging
|
||||
from typing import Dict, Any
|
||||
from ..base import RecipeMetadataParser
|
||||
from ..constants import GEN_PARAM_KEYS
|
||||
from ...services.metadata_service import get_default_metadata_provider
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@@ -18,8 +19,11 @@ class MetaFormatParser(RecipeMetadataParser):
|
||||
return re.search(self.METADATA_MARKER, user_comment, re.IGNORECASE | re.DOTALL) is not None
|
||||
|
||||
async def parse_metadata(self, user_comment: str, recipe_scanner=None, civitai_client=None) -> Dict[str, Any]:
|
||||
"""Parse metadata from images with meta format metadata"""
|
||||
"""Parse metadata from images with meta format metadata (Lora_N Model hash format)"""
|
||||
try:
|
||||
# Get metadata provider instead of using civitai_client directly
|
||||
metadata_provider = await get_default_metadata_provider()
|
||||
|
||||
# Extract prompt and negative prompt
|
||||
parts = user_comment.split('Negative prompt:', 1)
|
||||
prompt = parts[0].strip()
|
||||
@@ -122,9 +126,9 @@ class MetaFormatParser(RecipeMetadataParser):
|
||||
}
|
||||
|
||||
# Get info from Civitai by hash if available
|
||||
if civitai_client and hash_value:
|
||||
if metadata_provider and hash_value:
|
||||
try:
|
||||
civitai_info = await civitai_client.get_model_by_hash(hash_value)
|
||||
civitai_info = await metadata_provider.get_model_by_hash(hash_value)
|
||||
# Populate lora entry with Civitai info
|
||||
populated_entry = await self.populate_lora_from_civitai(
|
||||
lora_entry,
|
||||
|
||||
@@ -7,6 +7,7 @@ from typing import Dict, Any
|
||||
from ...config import config
|
||||
from ..base import RecipeMetadataParser
|
||||
from ..constants import GEN_PARAM_KEYS
|
||||
from ...services.metadata_service import get_default_metadata_provider
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@@ -23,6 +24,9 @@ class RecipeFormatParser(RecipeMetadataParser):
|
||||
async def parse_metadata(self, user_comment: str, recipe_scanner=None, civitai_client=None) -> Dict[str, Any]:
|
||||
"""Parse metadata from images with dedicated recipe metadata format"""
|
||||
try:
|
||||
# Get metadata provider instead of using civitai_client directly
|
||||
metadata_provider = await get_default_metadata_provider()
|
||||
|
||||
# Extract recipe metadata from user comment
|
||||
try:
|
||||
# Look for recipe metadata section
|
||||
@@ -43,7 +47,7 @@ class RecipeFormatParser(RecipeMetadataParser):
|
||||
for lora in recipe_metadata.get('loras', []):
|
||||
# Convert recipe lora format to frontend format
|
||||
lora_entry = {
|
||||
'id': lora.get('modelVersionId', ''),
|
||||
'id': int(lora.get('modelVersionId', 0)),
|
||||
'name': lora.get('modelName', ''),
|
||||
'version': lora.get('modelVersionName', ''),
|
||||
'type': 'lora',
|
||||
@@ -55,7 +59,7 @@ class RecipeFormatParser(RecipeMetadataParser):
|
||||
# Check if this LoRA exists locally by SHA256 hash
|
||||
if lora.get('hash') and recipe_scanner:
|
||||
lora_scanner = recipe_scanner._lora_scanner
|
||||
exists_locally = lora_scanner.has_lora_hash(lora['hash'])
|
||||
exists_locally = lora_scanner.has_hash(lora['hash'])
|
||||
if exists_locally:
|
||||
lora_cache = await lora_scanner.get_cached_data()
|
||||
lora_item = next((item for item in lora_cache.raw_data if item['sha256'].lower() == lora['hash'].lower()), None)
|
||||
@@ -71,9 +75,9 @@ class RecipeFormatParser(RecipeMetadataParser):
|
||||
lora_entry['localPath'] = None
|
||||
|
||||
# Try to get additional info from Civitai if we have a model version ID
|
||||
if lora.get('modelVersionId') and civitai_client:
|
||||
if lora.get('modelVersionId') and metadata_provider:
|
||||
try:
|
||||
civitai_info_tuple = await civitai_client.get_model_version_info(lora['modelVersionId'])
|
||||
civitai_info_tuple = await metadata_provider.get_model_version_info(lora['modelVersionId'])
|
||||
# Populate lora entry with Civitai info
|
||||
populated_entry = await self.populate_lora_from_civitai(
|
||||
lora_entry,
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
973
py/routes/base_model_routes.py
Normal file
973
py/routes/base_model_routes.py
Normal file
@@ -0,0 +1,973 @@
|
||||
from abc import ABC, abstractmethod
|
||||
import asyncio
|
||||
import os
|
||||
import json
|
||||
import logging
|
||||
from aiohttp import web
|
||||
from typing import Dict
|
||||
|
||||
import jinja2
|
||||
|
||||
from ..utils.routes_common import ModelRouteUtils
|
||||
from ..services.websocket_manager import ws_manager
|
||||
from ..services.settings_manager import settings
|
||||
from ..services.server_i18n import server_i18n
|
||||
from ..services.model_file_service import ModelFileService, ModelMoveService
|
||||
from ..services.websocket_progress_callback import WebSocketProgressCallback
|
||||
from ..config import config
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class BaseModelRoutes(ABC):
|
||||
"""Base route controller for all model types"""
|
||||
|
||||
def __init__(self, service):
|
||||
"""Initialize the route controller
|
||||
|
||||
Args:
|
||||
service: Model service instance (LoraService, CheckpointService, etc.)
|
||||
"""
|
||||
self.service = service
|
||||
self.model_type = service.model_type
|
||||
self.template_env = jinja2.Environment(
|
||||
loader=jinja2.FileSystemLoader(config.templates_path),
|
||||
autoescape=True
|
||||
)
|
||||
|
||||
# Initialize file services with dependency injection
|
||||
self.model_file_service = ModelFileService(service.scanner, service.model_type)
|
||||
self.model_move_service = ModelMoveService(service.scanner)
|
||||
self.websocket_progress_callback = WebSocketProgressCallback()
|
||||
|
||||
def setup_routes(self, app: web.Application, prefix: str):
|
||||
"""Setup common routes for the model type
|
||||
|
||||
Args:
|
||||
app: aiohttp application
|
||||
prefix: URL prefix (e.g., 'loras', 'checkpoints')
|
||||
"""
|
||||
# Common model management routes
|
||||
app.router.add_get(f'/api/{prefix}/list', self.get_models)
|
||||
app.router.add_post(f'/api/{prefix}/delete', self.delete_model)
|
||||
app.router.add_post(f'/api/{prefix}/exclude', self.exclude_model)
|
||||
app.router.add_post(f'/api/{prefix}/fetch-civitai', self.fetch_civitai)
|
||||
app.router.add_post(f'/api/{prefix}/fetch-all-civitai', self.fetch_all_civitai)
|
||||
app.router.add_post(f'/api/{prefix}/relink-civitai', self.relink_civitai)
|
||||
app.router.add_post(f'/api/{prefix}/replace-preview', self.replace_preview)
|
||||
app.router.add_post(f'/api/{prefix}/save-metadata', self.save_metadata)
|
||||
app.router.add_post(f'/api/{prefix}/add-tags', self.add_tags)
|
||||
app.router.add_post(f'/api/{prefix}/rename', self.rename_model)
|
||||
app.router.add_post(f'/api/{prefix}/bulk-delete', self.bulk_delete_models)
|
||||
app.router.add_post(f'/api/{prefix}/verify-duplicates', self.verify_duplicates)
|
||||
app.router.add_post(f'/api/{prefix}/move_model', self.move_model)
|
||||
app.router.add_post(f'/api/{prefix}/move_models_bulk', self.move_models_bulk)
|
||||
app.router.add_get(f'/api/{prefix}/auto-organize', self.auto_organize_models)
|
||||
app.router.add_post(f'/api/{prefix}/auto-organize', self.auto_organize_models)
|
||||
app.router.add_get(f'/api/{prefix}/auto-organize-progress', self.get_auto_organize_progress)
|
||||
|
||||
# Common query routes
|
||||
app.router.add_get(f'/api/{prefix}/top-tags', self.get_top_tags)
|
||||
app.router.add_get(f'/api/{prefix}/base-models', self.get_base_models)
|
||||
app.router.add_get(f'/api/{prefix}/scan', self.scan_models)
|
||||
app.router.add_get(f'/api/{prefix}/roots', self.get_model_roots)
|
||||
app.router.add_get(f'/api/{prefix}/folders', self.get_folders)
|
||||
app.router.add_get(f'/api/{prefix}/folder-tree', self.get_folder_tree)
|
||||
app.router.add_get(f'/api/{prefix}/unified-folder-tree', self.get_unified_folder_tree)
|
||||
app.router.add_get(f'/api/{prefix}/find-duplicates', self.find_duplicate_models)
|
||||
app.router.add_get(f'/api/{prefix}/find-filename-conflicts', self.find_filename_conflicts)
|
||||
app.router.add_get(f'/api/{prefix}/get-notes', self.get_model_notes)
|
||||
app.router.add_get(f'/api/{prefix}/preview-url', self.get_model_preview_url)
|
||||
app.router.add_get(f'/api/{prefix}/civitai-url', self.get_model_civitai_url)
|
||||
app.router.add_get(f'/api/{prefix}/metadata', self.get_model_metadata)
|
||||
app.router.add_get(f'/api/{prefix}/model-description', self.get_model_description)
|
||||
|
||||
# Autocomplete route
|
||||
app.router.add_get(f'/api/{prefix}/relative-paths', self.get_relative_paths)
|
||||
|
||||
# Common Download management
|
||||
app.router.add_post(f'/api/download-model', self.download_model)
|
||||
app.router.add_get(f'/api/download-model-get', self.download_model_get)
|
||||
app.router.add_get(f'/api/cancel-download-get', self.cancel_download_get)
|
||||
app.router.add_get(f'/api/download-progress/{{download_id}}', self.get_download_progress)
|
||||
|
||||
# app.router.add_get(f'/api/civitai/versions/{{model_id}}', self.get_civitai_versions)
|
||||
|
||||
# Add generic page route
|
||||
app.router.add_get(f'/{prefix}', self.handle_models_page)
|
||||
|
||||
# Setup model-specific routes
|
||||
self.setup_specific_routes(app, prefix)
|
||||
|
||||
@abstractmethod
|
||||
def setup_specific_routes(self, app: web.Application, prefix: str):
|
||||
"""Setup model-specific routes - to be implemented by subclasses"""
|
||||
pass
|
||||
|
||||
async def handle_models_page(self, request: web.Request) -> web.Response:
|
||||
"""
|
||||
Generic handler for model pages (e.g., /loras, /checkpoints).
|
||||
Subclasses should set self.template_env and template_name.
|
||||
"""
|
||||
try:
|
||||
# Check if the scanner is initializing
|
||||
is_initializing = (
|
||||
self.service.scanner._cache is None or
|
||||
(hasattr(self.service.scanner, 'is_initializing') and callable(self.service.scanner.is_initializing) and self.service.scanner.is_initializing()) or
|
||||
(hasattr(self.service.scanner, '_is_initializing') and self.service.scanner._is_initializing)
|
||||
)
|
||||
|
||||
template_name = getattr(self, "template_name", None)
|
||||
if not self.template_env or not template_name:
|
||||
return web.Response(text="Template environment or template name not set", status=500)
|
||||
|
||||
# Get user's language setting
|
||||
user_language = settings.get('language', 'en')
|
||||
|
||||
# Set server-side i18n locale
|
||||
server_i18n.set_locale(user_language)
|
||||
|
||||
# Add i18n filter to the template environment if not already added
|
||||
if not hasattr(self.template_env, '_i18n_filter_added'):
|
||||
self.template_env.filters['t'] = server_i18n.create_template_filter()
|
||||
self.template_env._i18n_filter_added = True
|
||||
|
||||
# Prepare template context
|
||||
template_context = {
|
||||
'is_initializing': is_initializing,
|
||||
'settings': settings,
|
||||
'request': request,
|
||||
'folders': [],
|
||||
't': server_i18n.get_translation,
|
||||
}
|
||||
|
||||
if not is_initializing:
|
||||
try:
|
||||
cache = await self.service.scanner.get_cached_data(force_refresh=False)
|
||||
template_context['folders'] = getattr(cache, "folders", [])
|
||||
except Exception as cache_error:
|
||||
logger.error(f"Error loading cache data: {cache_error}")
|
||||
template_context['is_initializing'] = True
|
||||
|
||||
rendered = self.template_env.get_template(template_name).render(**template_context)
|
||||
|
||||
return web.Response(
|
||||
text=rendered,
|
||||
content_type='text/html'
|
||||
)
|
||||
except Exception as e:
|
||||
logger.error(f"Error handling models page: {e}", exc_info=True)
|
||||
return web.Response(
|
||||
text="Error loading models page",
|
||||
status=500
|
||||
)
|
||||
|
||||
async def get_models(self, request: web.Request) -> web.Response:
|
||||
"""Get paginated model data"""
|
||||
try:
|
||||
# Parse common query parameters
|
||||
params = self._parse_common_params(request)
|
||||
|
||||
# Get data from service
|
||||
result = await self.service.get_paginated_data(**params)
|
||||
|
||||
# Format response items
|
||||
formatted_result = {
|
||||
'items': [await self.service.format_response(item) for item in result['items']],
|
||||
'total': result['total'],
|
||||
'page': result['page'],
|
||||
'page_size': result['page_size'],
|
||||
'total_pages': result['total_pages']
|
||||
}
|
||||
|
||||
return web.json_response(formatted_result)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error in get_{self.model_type}s: {e}", exc_info=True)
|
||||
return web.json_response({"error": str(e)}, status=500)
|
||||
|
||||
def _parse_common_params(self, request: web.Request) -> Dict:
|
||||
"""Parse common query parameters"""
|
||||
# Parse basic pagination and sorting
|
||||
page = int(request.query.get('page', '1'))
|
||||
page_size = min(int(request.query.get('page_size', '20')), 100)
|
||||
sort_by = request.query.get('sort_by', 'name')
|
||||
folder = request.query.get('folder', None)
|
||||
search = request.query.get('search', None)
|
||||
fuzzy_search = request.query.get('fuzzy_search', 'false').lower() == 'true'
|
||||
|
||||
# Parse filter arrays
|
||||
base_models = request.query.getall('base_model', [])
|
||||
tags = request.query.getall('tag', [])
|
||||
favorites_only = request.query.get('favorites_only', 'false').lower() == 'true'
|
||||
|
||||
# Parse search options
|
||||
search_options = {
|
||||
'filename': request.query.get('search_filename', 'true').lower() == 'true',
|
||||
'modelname': request.query.get('search_modelname', 'true').lower() == 'true',
|
||||
'tags': request.query.get('search_tags', 'false').lower() == 'true',
|
||||
'creator': request.query.get('search_creator', 'false').lower() == 'true',
|
||||
'recursive': request.query.get('recursive', 'true').lower() == 'true',
|
||||
}
|
||||
|
||||
# Parse hash filters if provided
|
||||
hash_filters = {}
|
||||
if 'hash' in request.query:
|
||||
hash_filters['single_hash'] = request.query['hash']
|
||||
elif 'hashes' in request.query:
|
||||
try:
|
||||
hash_list = json.loads(request.query['hashes'])
|
||||
if isinstance(hash_list, list):
|
||||
hash_filters['multiple_hashes'] = hash_list
|
||||
except (json.JSONDecodeError, TypeError):
|
||||
pass
|
||||
|
||||
return {
|
||||
'page': page,
|
||||
'page_size': page_size,
|
||||
'sort_by': sort_by,
|
||||
'folder': folder,
|
||||
'search': search,
|
||||
'fuzzy_search': fuzzy_search,
|
||||
'base_models': base_models,
|
||||
'tags': tags,
|
||||
'search_options': search_options,
|
||||
'hash_filters': hash_filters,
|
||||
'favorites_only': favorites_only,
|
||||
# Add model-specific parameters
|
||||
**self._parse_specific_params(request)
|
||||
}
|
||||
|
||||
def _parse_specific_params(self, request: web.Request) -> Dict:
|
||||
"""Parse model-specific parameters - to be overridden by subclasses"""
|
||||
return {}
|
||||
|
||||
# Common route handlers
|
||||
async def delete_model(self, request: web.Request) -> web.Response:
|
||||
"""Handle model deletion request"""
|
||||
return await ModelRouteUtils.handle_delete_model(request, self.service.scanner)
|
||||
|
||||
async def exclude_model(self, request: web.Request) -> web.Response:
|
||||
"""Handle model exclusion request"""
|
||||
return await ModelRouteUtils.handle_exclude_model(request, self.service.scanner)
|
||||
|
||||
async def fetch_civitai(self, request: web.Request) -> web.Response:
|
||||
"""Handle CivitAI metadata fetch request"""
|
||||
response = await ModelRouteUtils.handle_fetch_civitai(request, self.service.scanner)
|
||||
|
||||
# If successful, format the metadata before returning
|
||||
if response.status == 200:
|
||||
data = json.loads(response.body.decode('utf-8'))
|
||||
if data.get("success") and data.get("metadata"):
|
||||
formatted_metadata = await self.service.format_response(data["metadata"])
|
||||
return web.json_response({
|
||||
"success": True,
|
||||
"metadata": formatted_metadata
|
||||
})
|
||||
|
||||
return response
|
||||
|
||||
async def relink_civitai(self, request: web.Request) -> web.Response:
|
||||
"""Handle CivitAI metadata re-linking request"""
|
||||
return await ModelRouteUtils.handle_relink_civitai(request, self.service.scanner)
|
||||
|
||||
async def replace_preview(self, request: web.Request) -> web.Response:
|
||||
"""Handle preview image replacement"""
|
||||
return await ModelRouteUtils.handle_replace_preview(request, self.service.scanner)
|
||||
|
||||
async def save_metadata(self, request: web.Request) -> web.Response:
|
||||
"""Handle saving metadata updates"""
|
||||
return await ModelRouteUtils.handle_save_metadata(request, self.service.scanner)
|
||||
|
||||
async def add_tags(self, request: web.Request) -> web.Response:
|
||||
"""Handle adding tags to model metadata"""
|
||||
return await ModelRouteUtils.handle_add_tags(request, self.service.scanner)
|
||||
|
||||
async def rename_model(self, request: web.Request) -> web.Response:
|
||||
"""Handle renaming a model file and its associated files"""
|
||||
return await ModelRouteUtils.handle_rename_model(request, self.service.scanner)
|
||||
|
||||
async def bulk_delete_models(self, request: web.Request) -> web.Response:
|
||||
"""Handle bulk deletion of models"""
|
||||
return await ModelRouteUtils.handle_bulk_delete_models(request, self.service.scanner)
|
||||
|
||||
async def verify_duplicates(self, request: web.Request) -> web.Response:
|
||||
"""Handle verification of duplicate model hashes"""
|
||||
return await ModelRouteUtils.handle_verify_duplicates(request, self.service.scanner)
|
||||
|
||||
async def get_top_tags(self, request: web.Request) -> web.Response:
|
||||
"""Handle request for top tags sorted by frequency"""
|
||||
try:
|
||||
limit = int(request.query.get('limit', '20'))
|
||||
if limit < 1 or limit > 100:
|
||||
limit = 20
|
||||
|
||||
top_tags = await self.service.get_top_tags(limit)
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'tags': top_tags
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting top tags: {str(e)}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Internal server error'
|
||||
}, status=500)
|
||||
|
||||
async def get_base_models(self, request: web.Request) -> web.Response:
|
||||
"""Get base models used in models"""
|
||||
try:
|
||||
limit = int(request.query.get('limit', '20'))
|
||||
if limit < 1 or limit > 100:
|
||||
limit = 20
|
||||
|
||||
base_models = await self.service.get_base_models(limit)
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'base_models': base_models
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error retrieving base models: {e}")
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def scan_models(self, request: web.Request) -> web.Response:
|
||||
"""Force a rescan of model files"""
|
||||
try:
|
||||
full_rebuild = request.query.get('full_rebuild', 'false').lower() == 'true'
|
||||
|
||||
await self.service.scan_models(force_refresh=True, rebuild_cache=full_rebuild)
|
||||
return web.json_response({
|
||||
"status": "success",
|
||||
"message": f"{self.model_type.capitalize()} scan completed"
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error in scan_{self.model_type}s: {e}", exc_info=True)
|
||||
return web.json_response({"error": str(e)}, status=500)
|
||||
|
||||
async def get_model_roots(self, request: web.Request) -> web.Response:
|
||||
"""Return the model root directories"""
|
||||
try:
|
||||
roots = self.service.get_model_roots()
|
||||
return web.json_response({
|
||||
"success": True,
|
||||
"roots": roots
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting {self.model_type} roots: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
"success": False,
|
||||
"error": str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_folders(self, request: web.Request) -> web.Response:
|
||||
"""Get all folders in the cache"""
|
||||
try:
|
||||
cache = await self.service.scanner.get_cached_data()
|
||||
return web.json_response({
|
||||
'folders': cache.folders
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting folders: {e}")
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_folder_tree(self, request: web.Request) -> web.Response:
|
||||
"""Get hierarchical folder tree structure for download modal"""
|
||||
try:
|
||||
model_root = request.query.get('model_root')
|
||||
if not model_root:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'model_root parameter is required'
|
||||
}, status=400)
|
||||
|
||||
folder_tree = await self.service.get_folder_tree(model_root)
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'tree': folder_tree
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting folder tree: {e}")
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_unified_folder_tree(self, request: web.Request) -> web.Response:
|
||||
"""Get unified folder tree across all model roots"""
|
||||
try:
|
||||
unified_tree = await self.service.get_unified_folder_tree()
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'tree': unified_tree
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting unified folder tree: {e}")
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def find_duplicate_models(self, request: web.Request) -> web.Response:
|
||||
"""Find models with duplicate SHA256 hashes"""
|
||||
try:
|
||||
# Get duplicate hashes from service
|
||||
duplicates = self.service.find_duplicate_hashes()
|
||||
|
||||
# Format the response
|
||||
result = []
|
||||
cache = await self.service.scanner.get_cached_data()
|
||||
|
||||
for sha256, paths in duplicates.items():
|
||||
group = {
|
||||
"hash": sha256,
|
||||
"models": []
|
||||
}
|
||||
# Find matching models for each path
|
||||
for path in paths:
|
||||
model = next((m for m in cache.raw_data if m['file_path'] == path), None)
|
||||
if model:
|
||||
group["models"].append(await self.service.format_response(model))
|
||||
|
||||
# Add the primary model too
|
||||
primary_path = self.service.get_path_by_hash(sha256)
|
||||
if primary_path and primary_path not in paths:
|
||||
primary_model = next((m for m in cache.raw_data if m['file_path'] == primary_path), None)
|
||||
if primary_model:
|
||||
group["models"].insert(0, await self.service.format_response(primary_model))
|
||||
|
||||
if len(group["models"]) > 1: # Only include if we found multiple models
|
||||
result.append(group)
|
||||
|
||||
return web.json_response({
|
||||
"success": True,
|
||||
"duplicates": result,
|
||||
"count": len(result)
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error finding duplicate {self.model_type}s: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
"success": False,
|
||||
"error": str(e)
|
||||
}, status=500)
|
||||
|
||||
async def find_filename_conflicts(self, request: web.Request) -> web.Response:
|
||||
"""Find models with conflicting filenames"""
|
||||
try:
|
||||
# Get duplicate filenames from service
|
||||
duplicates = self.service.find_duplicate_filenames()
|
||||
|
||||
# Format the response
|
||||
result = []
|
||||
cache = await self.service.scanner.get_cached_data()
|
||||
|
||||
for filename, paths in duplicates.items():
|
||||
group = {
|
||||
"filename": filename,
|
||||
"models": []
|
||||
}
|
||||
# Find matching models for each path
|
||||
for path in paths:
|
||||
model = next((m for m in cache.raw_data if m['file_path'] == path), None)
|
||||
if model:
|
||||
group["models"].append(await self.service.format_response(model))
|
||||
|
||||
# Find the model from the main index too
|
||||
hash_val = self.service.scanner.get_hash_by_filename(filename)
|
||||
if hash_val:
|
||||
main_path = self.service.get_path_by_hash(hash_val)
|
||||
if main_path and main_path not in paths:
|
||||
main_model = next((m for m in cache.raw_data if m['file_path'] == main_path), None)
|
||||
if main_model:
|
||||
group["models"].insert(0, await self.service.format_response(main_model))
|
||||
|
||||
if group["models"]:
|
||||
result.append(group)
|
||||
|
||||
return web.json_response({
|
||||
"success": True,
|
||||
"conflicts": result,
|
||||
"count": len(result)
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error finding filename conflicts for {self.model_type}s: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
"success": False,
|
||||
"error": str(e)
|
||||
}, status=500)
|
||||
|
||||
# Download management methods
|
||||
async def download_model(self, request: web.Request) -> web.Response:
|
||||
"""Handle model download request"""
|
||||
return await ModelRouteUtils.handle_download_model(request)
|
||||
|
||||
async def download_model_get(self, request: web.Request) -> web.Response:
|
||||
"""Handle model download request via GET method"""
|
||||
try:
|
||||
# Extract query parameters
|
||||
model_id = request.query.get('model_id')
|
||||
if not model_id:
|
||||
return web.Response(
|
||||
status=400,
|
||||
text="Missing required parameter: Please provide 'model_id'"
|
||||
)
|
||||
|
||||
# Get optional parameters
|
||||
model_version_id = request.query.get('model_version_id')
|
||||
download_id = request.query.get('download_id')
|
||||
use_default_paths = request.query.get('use_default_paths', 'false').lower() == 'true'
|
||||
source = request.query.get('source') # Optional source parameter
|
||||
|
||||
# Create a data dictionary that mimics what would be received from a POST request
|
||||
data = {
|
||||
'model_id': model_id
|
||||
}
|
||||
|
||||
# Add optional parameters only if they are provided
|
||||
if model_version_id:
|
||||
data['model_version_id'] = model_version_id
|
||||
|
||||
if download_id:
|
||||
data['download_id'] = download_id
|
||||
|
||||
data['use_default_paths'] = use_default_paths
|
||||
|
||||
# Add source parameter if provided
|
||||
if source:
|
||||
data['source'] = source
|
||||
|
||||
# Create a mock request object with the data
|
||||
future = asyncio.get_event_loop().create_future()
|
||||
future.set_result(data)
|
||||
|
||||
mock_request = type('MockRequest', (), {
|
||||
'json': lambda self=None: future
|
||||
})()
|
||||
|
||||
# Call the existing download handler
|
||||
return await ModelRouteUtils.handle_download_model(mock_request)
|
||||
|
||||
except Exception as e:
|
||||
error_message = str(e)
|
||||
logger.error(f"Error downloading model via GET: {error_message}", exc_info=True)
|
||||
return web.Response(status=500, text=error_message)
|
||||
|
||||
async def cancel_download_get(self, request: web.Request) -> web.Response:
|
||||
"""Handle GET request for cancelling a download by download_id"""
|
||||
try:
|
||||
download_id = request.query.get('download_id')
|
||||
if not download_id:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Download ID is required'
|
||||
}, status=400)
|
||||
|
||||
# Create a mock request with match_info for compatibility
|
||||
mock_request = type('MockRequest', (), {
|
||||
'match_info': {'download_id': download_id}
|
||||
})()
|
||||
return await ModelRouteUtils.handle_cancel_download(mock_request)
|
||||
except Exception as e:
|
||||
logger.error(f"Error cancelling download via GET: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_download_progress(self, request: web.Request) -> web.Response:
|
||||
"""Handle request for download progress by download_id"""
|
||||
try:
|
||||
# Get download_id from URL path
|
||||
download_id = request.match_info.get('download_id')
|
||||
if not download_id:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Download ID is required'
|
||||
}, status=400)
|
||||
|
||||
progress_data = ws_manager.get_download_progress(download_id)
|
||||
|
||||
if progress_data is None:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Download ID not found'
|
||||
}, status=404)
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'progress': progress_data.get('progress', 0)
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting download progress: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def fetch_all_civitai(self, request: web.Request) -> web.Response:
|
||||
"""Fetch CivitAI metadata for all models in the background"""
|
||||
try:
|
||||
cache = await self.service.scanner.get_cached_data()
|
||||
total = len(cache.raw_data)
|
||||
processed = 0
|
||||
success = 0
|
||||
needs_resort = False
|
||||
|
||||
# Prepare models to process, only those without CivitAI data or missing tags, description, or creator
|
||||
enable_metadata_archive_db = settings.get('enable_metadata_archive_db', False)
|
||||
to_process = [
|
||||
model for model in cache.raw_data
|
||||
if (
|
||||
model.get('sha256')
|
||||
and (
|
||||
not model.get('civitai')
|
||||
or not model['civitai'].get('id')
|
||||
# or not model.get('tags') # Skipping tag cause it could be empty legitimately
|
||||
# or not model.get('modelDescription')
|
||||
# or not (model.get('civitai') and model['civitai'].get('creator'))
|
||||
)
|
||||
and (
|
||||
(enable_metadata_archive_db)
|
||||
or (not enable_metadata_archive_db and model.get('from_civitai') is True)
|
||||
)
|
||||
)
|
||||
]
|
||||
total_to_process = len(to_process)
|
||||
|
||||
# Send initial progress
|
||||
await ws_manager.broadcast({
|
||||
'status': 'started',
|
||||
'total': total_to_process,
|
||||
'processed': 0,
|
||||
'success': 0
|
||||
})
|
||||
|
||||
# Process each model
|
||||
for model in to_process:
|
||||
try:
|
||||
original_name = model.get('model_name')
|
||||
if await ModelRouteUtils.fetch_and_update_model(
|
||||
sha256=model['sha256'],
|
||||
file_path=model['file_path'],
|
||||
model_data=model,
|
||||
update_cache_func=self.service.scanner.update_single_model_cache
|
||||
):
|
||||
success += 1
|
||||
if original_name != model.get('model_name'):
|
||||
needs_resort = True
|
||||
|
||||
processed += 1
|
||||
|
||||
# Send progress update
|
||||
await ws_manager.broadcast({
|
||||
'status': 'processing',
|
||||
'total': total_to_process,
|
||||
'processed': processed,
|
||||
'success': success,
|
||||
'current_name': model.get('model_name', 'Unknown')
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching CivitAI data for {model['file_path']}: {e}")
|
||||
|
||||
if needs_resort:
|
||||
await cache.resort()
|
||||
|
||||
# Send completion message
|
||||
await ws_manager.broadcast({
|
||||
'status': 'completed',
|
||||
'total': total_to_process,
|
||||
'processed': processed,
|
||||
'success': success
|
||||
})
|
||||
|
||||
return web.json_response({
|
||||
"success": True,
|
||||
"message": f"Successfully updated {success} of {processed} processed {self.model_type}s (total: {total})"
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
# Send error message
|
||||
await ws_manager.broadcast({
|
||||
'status': 'error',
|
||||
'error': str(e)
|
||||
})
|
||||
logger.error(f"Error in fetch_all_civitai for {self.model_type}s: {e}")
|
||||
return web.Response(text=str(e), status=500)
|
||||
|
||||
async def get_civitai_versions(self, request: web.Request) -> web.Response:
|
||||
"""Get available versions for a Civitai model with local availability info"""
|
||||
# This will be implemented by subclasses as they need CivitAI client access
|
||||
return web.json_response({
|
||||
"error": "Not implemented in base class"
|
||||
}, status=501)
|
||||
|
||||
# Common model move handlers
|
||||
async def move_model(self, request: web.Request) -> web.Response:
|
||||
"""Handle model move request"""
|
||||
try:
|
||||
data = await request.json()
|
||||
file_path = data.get('file_path')
|
||||
target_path = data.get('target_path')
|
||||
|
||||
if not file_path or not target_path:
|
||||
return web.Response(text='File path and target path are required', status=400)
|
||||
|
||||
result = await self.model_move_service.move_model(file_path, target_path)
|
||||
|
||||
if result['success']:
|
||||
return web.json_response(result)
|
||||
else:
|
||||
return web.json_response(result, status=500)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error moving model: {e}", exc_info=True)
|
||||
return web.Response(text=str(e), status=500)
|
||||
|
||||
async def move_models_bulk(self, request: web.Request) -> web.Response:
|
||||
"""Handle bulk model move request"""
|
||||
try:
|
||||
data = await request.json()
|
||||
file_paths = data.get('file_paths', [])
|
||||
target_path = data.get('target_path')
|
||||
|
||||
if not file_paths or not target_path:
|
||||
return web.Response(text='File paths and target path are required', status=400)
|
||||
|
||||
result = await self.model_move_service.move_models_bulk(file_paths, target_path)
|
||||
return web.json_response(result)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error moving models in bulk: {e}", exc_info=True)
|
||||
return web.Response(text=str(e), status=500)
|
||||
|
||||
async def auto_organize_models(self, request: web.Request) -> web.Response:
|
||||
"""Auto-organize all models or a specific set of models based on current settings"""
|
||||
try:
|
||||
# Check if auto-organize is already running
|
||||
if ws_manager.is_auto_organize_running():
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Auto-organize is already running. Please wait for it to complete.'
|
||||
}, status=409)
|
||||
|
||||
# Acquire lock to prevent concurrent auto-organize operations
|
||||
auto_organize_lock = await ws_manager.get_auto_organize_lock()
|
||||
|
||||
if auto_organize_lock.locked():
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Auto-organize is already running. Please wait for it to complete.'
|
||||
}, status=409)
|
||||
|
||||
# Get specific file paths from request if this is a POST with selected models
|
||||
file_paths = None
|
||||
if request.method == 'POST':
|
||||
try:
|
||||
data = await request.json()
|
||||
file_paths = data.get('file_paths')
|
||||
except Exception:
|
||||
pass # Continue with all models if no valid JSON
|
||||
|
||||
async with auto_organize_lock:
|
||||
# Use the service layer for business logic
|
||||
result = await self.model_file_service.auto_organize_models(
|
||||
file_paths=file_paths,
|
||||
progress_callback=self.websocket_progress_callback
|
||||
)
|
||||
|
||||
return web.json_response(result.to_dict())
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error in auto_organize_models: {e}", exc_info=True)
|
||||
|
||||
# Send error message via WebSocket
|
||||
await ws_manager.broadcast_auto_organize_progress({
|
||||
'type': 'auto_organize_progress',
|
||||
'status': 'error',
|
||||
'error': str(e)
|
||||
})
|
||||
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_auto_organize_progress(self, request: web.Request) -> web.Response:
|
||||
"""Get current auto-organize progress for polling"""
|
||||
try:
|
||||
progress_data = ws_manager.get_auto_organize_progress()
|
||||
|
||||
if progress_data is None:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'No auto-organize operation in progress'
|
||||
}, status=404)
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'progress': progress_data
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting auto-organize progress: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_model_notes(self, request: web.Request) -> web.Response:
|
||||
"""Get notes for a specific model file"""
|
||||
try:
|
||||
model_name = request.query.get('name')
|
||||
if not model_name:
|
||||
return web.Response(text=f'{self.model_type.capitalize()} file name is required', status=400)
|
||||
|
||||
notes = await self.service.get_model_notes(model_name)
|
||||
if notes is not None:
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'notes': notes
|
||||
})
|
||||
else:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': f'{self.model_type.capitalize()} not found in cache'
|
||||
}, status=404)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting {self.model_type} notes: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_model_preview_url(self, request: web.Request) -> web.Response:
|
||||
"""Get the static preview URL for a model file"""
|
||||
try:
|
||||
model_name = request.query.get('name')
|
||||
if not model_name:
|
||||
return web.Response(text=f'{self.model_type.capitalize()} file name is required', status=400)
|
||||
|
||||
preview_url = await self.service.get_model_preview_url(model_name)
|
||||
if preview_url:
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'preview_url': preview_url
|
||||
})
|
||||
else:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': f'No preview URL found for the specified {self.model_type}'
|
||||
}, status=404)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting {self.model_type} preview URL: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_model_civitai_url(self, request: web.Request) -> web.Response:
|
||||
"""Get the Civitai URL for a model file"""
|
||||
try:
|
||||
model_name = request.query.get('name')
|
||||
if not model_name:
|
||||
return web.Response(text=f'{self.model_type.capitalize()} file name is required', status=400)
|
||||
|
||||
result = await self.service.get_model_civitai_url(model_name)
|
||||
if result['civitai_url']:
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
**result
|
||||
})
|
||||
else:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': f'No Civitai data found for the specified {self.model_type}'
|
||||
}, status=404)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting {self.model_type} Civitai URL: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_model_metadata(self, request: web.Request) -> web.Response:
|
||||
"""Get filtered CivitAI metadata for a model by file path"""
|
||||
try:
|
||||
file_path = request.query.get('file_path')
|
||||
if not file_path:
|
||||
return web.Response(text='File path is required', status=400)
|
||||
|
||||
metadata = await self.service.get_model_metadata(file_path)
|
||||
if metadata is not None:
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'metadata': metadata
|
||||
})
|
||||
else:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': f'{self.model_type.capitalize()} not found or no CivitAI metadata available'
|
||||
}, status=404)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting {self.model_type} metadata: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_model_description(self, request: web.Request) -> web.Response:
|
||||
"""Get model description by file path"""
|
||||
try:
|
||||
file_path = request.query.get('file_path')
|
||||
if not file_path:
|
||||
return web.Response(text='File path is required', status=400)
|
||||
|
||||
description = await self.service.get_model_description(file_path)
|
||||
if description is not None:
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'description': description
|
||||
})
|
||||
else:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': f'{self.model_type.capitalize()} not found or no description available'
|
||||
}, status=404)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting {self.model_type} description: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_relative_paths(self, request: web.Request) -> web.Response:
|
||||
"""Get model relative file paths for autocomplete functionality"""
|
||||
try:
|
||||
search = request.query.get('search', '').strip()
|
||||
limit = min(int(request.query.get('limit', '15')), 50) # Max 50 items
|
||||
|
||||
matching_paths = await self.service.search_relative_paths(search, limit)
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'relative_paths': matching_paths
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting relative paths for autocomplete: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
140
py/routes/checkpoint_routes.py
Normal file
140
py/routes/checkpoint_routes.py
Normal file
@@ -0,0 +1,140 @@
|
||||
import logging
|
||||
from aiohttp import web
|
||||
|
||||
from .base_model_routes import BaseModelRoutes
|
||||
from ..services.checkpoint_service import CheckpointService
|
||||
from ..services.service_registry import ServiceRegistry
|
||||
from ..services.metadata_service import get_default_metadata_provider
|
||||
from ..config import config
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class CheckpointRoutes(BaseModelRoutes):
|
||||
"""Checkpoint-specific route controller"""
|
||||
|
||||
def __init__(self):
|
||||
"""Initialize Checkpoint routes with Checkpoint service"""
|
||||
# Service will be initialized later via setup_routes
|
||||
self.service = None
|
||||
self.template_name = "checkpoints.html"
|
||||
|
||||
async def initialize_services(self):
|
||||
"""Initialize services from ServiceRegistry"""
|
||||
checkpoint_scanner = await ServiceRegistry.get_checkpoint_scanner()
|
||||
self.service = CheckpointService(checkpoint_scanner)
|
||||
|
||||
# Initialize parent with the service
|
||||
super().__init__(self.service)
|
||||
|
||||
def setup_routes(self, app: web.Application):
|
||||
"""Setup Checkpoint routes"""
|
||||
# Schedule service initialization on app startup
|
||||
app.on_startup.append(lambda _: self.initialize_services())
|
||||
|
||||
# Setup common routes with 'checkpoints' prefix (includes page route)
|
||||
super().setup_routes(app, 'checkpoints')
|
||||
|
||||
def setup_specific_routes(self, app: web.Application, prefix: str):
|
||||
"""Setup Checkpoint-specific routes"""
|
||||
# Checkpoint-specific CivitAI integration
|
||||
app.router.add_get(f'/api/{prefix}/civitai/versions/{{model_id}}', self.get_civitai_versions_checkpoint)
|
||||
|
||||
# Checkpoint info by name
|
||||
app.router.add_get(f'/api/{prefix}/info/{{name}}', self.get_checkpoint_info)
|
||||
|
||||
# Checkpoint roots and Unet roots
|
||||
app.router.add_get(f'/api/{prefix}/checkpoints_roots', self.get_checkpoints_roots)
|
||||
app.router.add_get(f'/api/{prefix}/unet_roots', self.get_unet_roots)
|
||||
|
||||
async def get_checkpoint_info(self, request: web.Request) -> web.Response:
|
||||
"""Get detailed information for a specific checkpoint by name"""
|
||||
try:
|
||||
name = request.match_info.get('name', '')
|
||||
checkpoint_info = await self.service.get_model_info_by_name(name)
|
||||
|
||||
if checkpoint_info:
|
||||
return web.json_response(checkpoint_info)
|
||||
else:
|
||||
return web.json_response({"error": "Checkpoint not found"}, status=404)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error in get_checkpoint_info: {e}", exc_info=True)
|
||||
return web.json_response({"error": str(e)}, status=500)
|
||||
|
||||
async def get_civitai_versions_checkpoint(self, request: web.Request) -> web.Response:
|
||||
"""Get available versions for a Civitai checkpoint model with local availability info"""
|
||||
try:
|
||||
model_id = request.match_info['model_id']
|
||||
metadata_provider = await get_default_metadata_provider()
|
||||
response = await metadata_provider.get_model_versions(model_id)
|
||||
if not response or not response.get('modelVersions'):
|
||||
return web.Response(status=404, text="Model not found")
|
||||
|
||||
versions = response.get('modelVersions', [])
|
||||
model_type = response.get('type', '')
|
||||
|
||||
# Check model type - should be Checkpoint
|
||||
if model_type.lower() != 'checkpoint':
|
||||
return web.json_response({
|
||||
'error': f"Model type mismatch. Expected Checkpoint, got {model_type}"
|
||||
}, status=400)
|
||||
|
||||
# Check local availability for each version
|
||||
for version in versions:
|
||||
# Find the primary model file (type="Model" and primary=true) in the files list
|
||||
model_file = next((file for file in version.get('files', [])
|
||||
if file.get('type') == 'Model' and file.get('primary') == True), None)
|
||||
|
||||
# If no primary file found, try to find any model file
|
||||
if not model_file:
|
||||
model_file = next((file for file in version.get('files', [])
|
||||
if file.get('type') == 'Model'), None)
|
||||
|
||||
if model_file:
|
||||
sha256 = model_file.get('hashes', {}).get('SHA256')
|
||||
if sha256:
|
||||
# Set existsLocally and localPath at the version level
|
||||
version['existsLocally'] = self.service.has_hash(sha256)
|
||||
if version['existsLocally']:
|
||||
version['localPath'] = self.service.get_path_by_hash(sha256)
|
||||
|
||||
# Also set the model file size at the version level for easier access
|
||||
version['modelSizeKB'] = model_file.get('sizeKB')
|
||||
else:
|
||||
# No model file found in this version
|
||||
version['existsLocally'] = False
|
||||
|
||||
return web.json_response(versions)
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching checkpoint model versions: {e}")
|
||||
return web.Response(status=500, text=str(e))
|
||||
|
||||
async def get_checkpoints_roots(self, request: web.Request) -> web.Response:
|
||||
"""Return the list of checkpoint roots from config"""
|
||||
try:
|
||||
roots = config.checkpoints_roots
|
||||
return web.json_response({
|
||||
"success": True,
|
||||
"roots": roots
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting checkpoint roots: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
"success": False,
|
||||
"error": str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_unet_roots(self, request: web.Request) -> web.Response:
|
||||
"""Return the list of unet roots from config"""
|
||||
try:
|
||||
roots = config.unet_roots
|
||||
return web.json_response({
|
||||
"success": True,
|
||||
"roots": roots
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting unet roots: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
"success": False,
|
||||
"error": str(e)
|
||||
}, status=500)
|
||||
@@ -1,694 +0,0 @@
|
||||
import os
|
||||
import json
|
||||
import jinja2
|
||||
from aiohttp import web
|
||||
import logging
|
||||
import asyncio
|
||||
|
||||
from ..utils.routes_common import ModelRouteUtils
|
||||
from ..utils.constants import NSFW_LEVELS
|
||||
from ..services.websocket_manager import ws_manager
|
||||
from ..services.service_registry import ServiceRegistry
|
||||
from ..config import config
|
||||
from ..services.settings_manager import settings
|
||||
from ..utils.utils import fuzzy_match
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class CheckpointsRoutes:
|
||||
"""API routes for checkpoint management"""
|
||||
|
||||
def __init__(self):
|
||||
self.scanner = None # Will be initialized in setup_routes
|
||||
self.template_env = jinja2.Environment(
|
||||
loader=jinja2.FileSystemLoader(config.templates_path),
|
||||
autoescape=True
|
||||
)
|
||||
self.download_manager = None # Will be initialized in setup_routes
|
||||
self._download_lock = asyncio.Lock()
|
||||
|
||||
async def initialize_services(self):
|
||||
"""Initialize services from ServiceRegistry"""
|
||||
self.scanner = await ServiceRegistry.get_checkpoint_scanner()
|
||||
self.download_manager = await ServiceRegistry.get_download_manager()
|
||||
|
||||
def setup_routes(self, app):
|
||||
"""Register routes with the aiohttp app"""
|
||||
# Schedule service initialization on app startup
|
||||
app.on_startup.append(lambda _: self.initialize_services())
|
||||
|
||||
app.router.add_get('/checkpoints', self.handle_checkpoints_page)
|
||||
app.router.add_get('/api/checkpoints', self.get_checkpoints)
|
||||
app.router.add_post('/api/checkpoints/fetch-all-civitai', self.fetch_all_civitai)
|
||||
app.router.add_get('/api/checkpoints/base-models', self.get_base_models)
|
||||
app.router.add_get('/api/checkpoints/top-tags', self.get_top_tags)
|
||||
app.router.add_get('/api/checkpoints/scan', self.scan_checkpoints)
|
||||
app.router.add_get('/api/checkpoints/info/{name}', self.get_checkpoint_info)
|
||||
app.router.add_get('/api/checkpoints/roots', self.get_checkpoint_roots)
|
||||
app.router.add_get('/api/checkpoints/civitai/versions/{model_id}', self.get_civitai_versions) # Add new route
|
||||
|
||||
# Add new routes for model management similar to LoRA routes
|
||||
app.router.add_post('/api/checkpoints/delete', self.delete_model)
|
||||
app.router.add_post('/api/checkpoints/exclude', self.exclude_model) # Add new exclude endpoint
|
||||
app.router.add_post('/api/checkpoints/fetch-civitai', self.fetch_civitai)
|
||||
app.router.add_post('/api/checkpoints/replace-preview', self.replace_preview)
|
||||
app.router.add_post('/api/checkpoints/download', self.download_checkpoint)
|
||||
app.router.add_post('/api/checkpoints/save-metadata', self.save_metadata) # Add new route
|
||||
|
||||
# Add new WebSocket endpoint for checkpoint progress
|
||||
app.router.add_get('/ws/checkpoint-progress', ws_manager.handle_checkpoint_connection)
|
||||
|
||||
async def get_checkpoints(self, request):
|
||||
"""Get paginated checkpoint data"""
|
||||
try:
|
||||
# Parse query parameters
|
||||
page = int(request.query.get('page', '1'))
|
||||
page_size = min(int(request.query.get('page_size', '20')), 100)
|
||||
sort_by = request.query.get('sort_by', 'name')
|
||||
folder = request.query.get('folder', None)
|
||||
search = request.query.get('search', None)
|
||||
fuzzy_search = request.query.get('fuzzy_search', 'false').lower() == 'true'
|
||||
base_models = request.query.getall('base_model', [])
|
||||
tags = request.query.getall('tag', [])
|
||||
favorites_only = request.query.get('favorites_only', 'false').lower() == 'true' # Add favorites_only parameter
|
||||
|
||||
# Process search options
|
||||
search_options = {
|
||||
'filename': request.query.get('search_filename', 'true').lower() == 'true',
|
||||
'modelname': request.query.get('search_modelname', 'true').lower() == 'true',
|
||||
'tags': request.query.get('search_tags', 'false').lower() == 'true',
|
||||
'recursive': request.query.get('recursive', 'false').lower() == 'true',
|
||||
}
|
||||
|
||||
# Process hash filters if provided
|
||||
hash_filters = {}
|
||||
if 'hash' in request.query:
|
||||
hash_filters['single_hash'] = request.query['hash']
|
||||
elif 'hashes' in request.query:
|
||||
try:
|
||||
hash_list = json.loads(request.query['hashes'])
|
||||
if isinstance(hash_list, list):
|
||||
hash_filters['multiple_hashes'] = hash_list
|
||||
except (json.JSONDecodeError, TypeError):
|
||||
pass
|
||||
|
||||
# Get data from scanner
|
||||
result = await self.get_paginated_data(
|
||||
page=page,
|
||||
page_size=page_size,
|
||||
sort_by=sort_by,
|
||||
folder=folder,
|
||||
search=search,
|
||||
fuzzy_search=fuzzy_search,
|
||||
base_models=base_models,
|
||||
tags=tags,
|
||||
search_options=search_options,
|
||||
hash_filters=hash_filters,
|
||||
favorites_only=favorites_only # Pass favorites_only parameter
|
||||
)
|
||||
|
||||
# Format response items
|
||||
formatted_result = {
|
||||
'items': [self._format_checkpoint_response(cp) for cp in result['items']],
|
||||
'total': result['total'],
|
||||
'page': result['page'],
|
||||
'page_size': result['page_size'],
|
||||
'total_pages': result['total_pages']
|
||||
}
|
||||
|
||||
# Return as JSON
|
||||
return web.json_response(formatted_result)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error in get_checkpoints: {e}", exc_info=True)
|
||||
return web.json_response({"error": str(e)}, status=500)
|
||||
|
||||
async def get_paginated_data(self, page, page_size, sort_by='name',
|
||||
folder=None, search=None, fuzzy_search=False,
|
||||
base_models=None, tags=None,
|
||||
search_options=None, hash_filters=None,
|
||||
favorites_only=False): # Add favorites_only parameter with default False
|
||||
"""Get paginated and filtered checkpoint data"""
|
||||
cache = await self.scanner.get_cached_data()
|
||||
|
||||
# Get default search options if not provided
|
||||
if search_options is None:
|
||||
search_options = {
|
||||
'filename': True,
|
||||
'modelname': True,
|
||||
'tags': False,
|
||||
'recursive': False,
|
||||
}
|
||||
|
||||
# Get the base data set
|
||||
filtered_data = cache.sorted_by_date if sort_by == 'date' else cache.sorted_by_name
|
||||
|
||||
# Apply hash filtering if provided (highest priority)
|
||||
if hash_filters:
|
||||
single_hash = hash_filters.get('single_hash')
|
||||
multiple_hashes = hash_filters.get('multiple_hashes')
|
||||
|
||||
if single_hash:
|
||||
# Filter by single hash
|
||||
single_hash = single_hash.lower() # Ensure lowercase for matching
|
||||
filtered_data = [
|
||||
cp for cp in filtered_data
|
||||
if cp.get('sha256', '').lower() == single_hash
|
||||
]
|
||||
elif multiple_hashes:
|
||||
# Filter by multiple hashes
|
||||
hash_set = set(hash.lower() for hash in multiple_hashes) # Convert to set for faster lookup
|
||||
filtered_data = [
|
||||
cp for cp in filtered_data
|
||||
if cp.get('sha256', '').lower() in hash_set
|
||||
]
|
||||
|
||||
# Jump to pagination
|
||||
total_items = len(filtered_data)
|
||||
start_idx = (page - 1) * page_size
|
||||
end_idx = min(start_idx + page_size, total_items)
|
||||
|
||||
result = {
|
||||
'items': filtered_data[start_idx:end_idx],
|
||||
'total': total_items,
|
||||
'page': page,
|
||||
'page_size': page_size,
|
||||
'total_pages': (total_items + page_size - 1) // page_size
|
||||
}
|
||||
|
||||
return result
|
||||
|
||||
# Apply SFW filtering if enabled in settings
|
||||
if settings.get('show_only_sfw', False):
|
||||
filtered_data = [
|
||||
cp for cp in filtered_data
|
||||
if not cp.get('preview_nsfw_level') or cp.get('preview_nsfw_level') < NSFW_LEVELS['R']
|
||||
]
|
||||
|
||||
# Apply favorites filtering if enabled
|
||||
if favorites_only:
|
||||
filtered_data = [
|
||||
cp for cp in filtered_data
|
||||
if cp.get('favorite', False) is True
|
||||
]
|
||||
|
||||
# Apply folder filtering
|
||||
if folder is not None:
|
||||
if search_options.get('recursive', False):
|
||||
# Recursive folder filtering - include all subfolders
|
||||
filtered_data = [
|
||||
cp for cp in filtered_data
|
||||
if cp['folder'].startswith(folder)
|
||||
]
|
||||
else:
|
||||
# Exact folder filtering
|
||||
filtered_data = [
|
||||
cp for cp in filtered_data
|
||||
if cp['folder'] == folder
|
||||
]
|
||||
|
||||
# Apply base model filtering
|
||||
if base_models and len(base_models) > 0:
|
||||
filtered_data = [
|
||||
cp for cp in filtered_data
|
||||
if cp.get('base_model') in base_models
|
||||
]
|
||||
|
||||
# Apply tag filtering
|
||||
if tags and len(tags) > 0:
|
||||
filtered_data = [
|
||||
cp for cp in filtered_data
|
||||
if any(tag in cp.get('tags', []) for tag in tags)
|
||||
]
|
||||
|
||||
# Apply search filtering
|
||||
if search:
|
||||
search_results = []
|
||||
|
||||
for cp in filtered_data:
|
||||
# Search by file name
|
||||
if search_options.get('filename', True):
|
||||
if fuzzy_search:
|
||||
if fuzzy_match(cp.get('file_name', ''), search):
|
||||
search_results.append(cp)
|
||||
continue
|
||||
elif search.lower() in cp.get('file_name', '').lower():
|
||||
search_results.append(cp)
|
||||
continue
|
||||
|
||||
# Search by model name
|
||||
if search_options.get('modelname', True):
|
||||
if fuzzy_search:
|
||||
if fuzzy_match(cp.get('model_name', ''), search):
|
||||
search_results.append(cp)
|
||||
continue
|
||||
elif search.lower() in cp.get('model_name', '').lower():
|
||||
search_results.append(cp)
|
||||
continue
|
||||
|
||||
# Search by tags
|
||||
if search_options.get('tags', False) and 'tags' in cp:
|
||||
if any((fuzzy_match(tag, search) if fuzzy_search else search.lower() in tag.lower()) for tag in cp['tags']):
|
||||
search_results.append(cp)
|
||||
continue
|
||||
|
||||
filtered_data = search_results
|
||||
|
||||
# Calculate pagination
|
||||
total_items = len(filtered_data)
|
||||
start_idx = (page - 1) * page_size
|
||||
end_idx = min(start_idx + page_size, total_items)
|
||||
|
||||
result = {
|
||||
'items': filtered_data[start_idx:end_idx],
|
||||
'total': total_items,
|
||||
'page': page,
|
||||
'page_size': page_size,
|
||||
'total_pages': (total_items + page_size - 1) // page_size
|
||||
}
|
||||
|
||||
return result
|
||||
|
||||
def _format_checkpoint_response(self, checkpoint):
|
||||
"""Format checkpoint data for API response"""
|
||||
return {
|
||||
"model_name": checkpoint["model_name"],
|
||||
"file_name": checkpoint["file_name"],
|
||||
"preview_url": config.get_preview_static_url(checkpoint.get("preview_url", "")),
|
||||
"preview_nsfw_level": checkpoint.get("preview_nsfw_level", 0),
|
||||
"base_model": checkpoint.get("base_model", ""),
|
||||
"folder": checkpoint["folder"],
|
||||
"sha256": checkpoint.get("sha256", ""),
|
||||
"file_path": checkpoint["file_path"].replace(os.sep, "/"),
|
||||
"file_size": checkpoint.get("size", 0),
|
||||
"modified": checkpoint.get("modified", ""),
|
||||
"tags": checkpoint.get("tags", []),
|
||||
"modelDescription": checkpoint.get("modelDescription", ""),
|
||||
"from_civitai": checkpoint.get("from_civitai", True),
|
||||
"notes": checkpoint.get("notes", ""),
|
||||
"model_type": checkpoint.get("model_type", "checkpoint"),
|
||||
"favorite": checkpoint.get("favorite", False),
|
||||
"civitai": ModelRouteUtils.filter_civitai_data(checkpoint.get("civitai", {}))
|
||||
}
|
||||
|
||||
async def fetch_all_civitai(self, request: web.Request) -> web.Response:
|
||||
"""Fetch CivitAI metadata for all checkpoints in the background"""
|
||||
try:
|
||||
cache = await self.scanner.get_cached_data()
|
||||
total = len(cache.raw_data)
|
||||
processed = 0
|
||||
success = 0
|
||||
needs_resort = False
|
||||
|
||||
# Prepare checkpoints to process
|
||||
to_process = [
|
||||
cp for cp in cache.raw_data
|
||||
if cp.get('sha256') and (not cp.get('civitai') or 'id' not in cp.get('civitai')) and cp.get('from_civitai', True)
|
||||
]
|
||||
total_to_process = len(to_process)
|
||||
|
||||
# Send initial progress
|
||||
await ws_manager.broadcast({
|
||||
'status': 'started',
|
||||
'total': total_to_process,
|
||||
'processed': 0,
|
||||
'success': 0
|
||||
})
|
||||
|
||||
# Process each checkpoint
|
||||
for cp in to_process:
|
||||
try:
|
||||
original_name = cp.get('model_name')
|
||||
if await ModelRouteUtils.fetch_and_update_model(
|
||||
sha256=cp['sha256'],
|
||||
file_path=cp['file_path'],
|
||||
model_data=cp,
|
||||
update_cache_func=self.scanner.update_single_model_cache
|
||||
):
|
||||
success += 1
|
||||
if original_name != cp.get('model_name'):
|
||||
needs_resort = True
|
||||
|
||||
processed += 1
|
||||
|
||||
# Send progress update
|
||||
await ws_manager.broadcast({
|
||||
'status': 'processing',
|
||||
'total': total_to_process,
|
||||
'processed': processed,
|
||||
'success': success,
|
||||
'current_name': cp.get('model_name', 'Unknown')
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching CivitAI data for {cp['file_path']}: {e}")
|
||||
|
||||
if needs_resort:
|
||||
await cache.resort(name_only=True)
|
||||
|
||||
# Send completion message
|
||||
await ws_manager.broadcast({
|
||||
'status': 'completed',
|
||||
'total': total_to_process,
|
||||
'processed': processed,
|
||||
'success': success
|
||||
})
|
||||
|
||||
return web.json_response({
|
||||
"success": True,
|
||||
"message": f"Successfully updated {success} of {processed} processed checkpoints (total: {total})"
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
# Send error message
|
||||
await ws_manager.broadcast({
|
||||
'status': 'error',
|
||||
'error': str(e)
|
||||
})
|
||||
logger.error(f"Error in fetch_all_civitai for checkpoints: {e}")
|
||||
return web.Response(text=str(e), status=500)
|
||||
|
||||
async def get_top_tags(self, request: web.Request) -> web.Response:
|
||||
"""Handle request for top tags sorted by frequency"""
|
||||
try:
|
||||
# Parse query parameters
|
||||
limit = int(request.query.get('limit', '20'))
|
||||
|
||||
# Validate limit
|
||||
if limit < 1 or limit > 100:
|
||||
limit = 20 # Default to a reasonable limit
|
||||
|
||||
# Get top tags
|
||||
top_tags = await self.scanner.get_top_tags(limit)
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'tags': top_tags
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting top tags: {str(e)}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Internal server error'
|
||||
}, status=500)
|
||||
|
||||
async def get_base_models(self, request: web.Request) -> web.Response:
|
||||
"""Get base models used in loras"""
|
||||
try:
|
||||
# Parse query parameters
|
||||
limit = int(request.query.get('limit', '20'))
|
||||
|
||||
# Validate limit
|
||||
if limit < 1 or limit > 100:
|
||||
limit = 20 # Default to a reasonable limit
|
||||
|
||||
# Get base models
|
||||
base_models = await self.scanner.get_base_models(limit)
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'base_models': base_models
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error retrieving base models: {e}")
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def scan_checkpoints(self, request):
|
||||
"""Force a rescan of checkpoint files"""
|
||||
try:
|
||||
await self.scanner.get_cached_data(force_refresh=True)
|
||||
return web.json_response({"status": "success", "message": "Checkpoint scan completed"})
|
||||
except Exception as e:
|
||||
logger.error(f"Error in scan_checkpoints: {e}", exc_info=True)
|
||||
return web.json_response({"error": str(e)}, status=500)
|
||||
|
||||
async def get_checkpoint_info(self, request):
|
||||
"""Get detailed information for a specific checkpoint by name"""
|
||||
try:
|
||||
name = request.match_info.get('name', '')
|
||||
checkpoint_info = await self.scanner.get_model_info_by_name(name)
|
||||
|
||||
if checkpoint_info:
|
||||
return web.json_response(checkpoint_info)
|
||||
else:
|
||||
return web.json_response({"error": "Checkpoint not found"}, status=404)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error in get_checkpoint_info: {e}", exc_info=True)
|
||||
return web.json_response({"error": str(e)}, status=500)
|
||||
|
||||
async def handle_checkpoints_page(self, request: web.Request) -> web.Response:
|
||||
"""Handle GET /checkpoints request"""
|
||||
try:
|
||||
# Check if the CheckpointScanner is initializing
|
||||
# It's initializing if the cache object doesn't exist yet,
|
||||
# OR if the scanner explicitly says it's initializing (background task running).
|
||||
is_initializing = (
|
||||
self.scanner._cache is None or
|
||||
(hasattr(self.scanner, '_is_initializing') and self.scanner._is_initializing)
|
||||
)
|
||||
|
||||
if is_initializing:
|
||||
# If still initializing, return loading page
|
||||
template = self.template_env.get_template('checkpoints.html')
|
||||
rendered = template.render(
|
||||
folders=[], # 空文件夹列表
|
||||
is_initializing=True, # 新增标志
|
||||
settings=settings, # Pass settings to template
|
||||
request=request # Pass the request object to the template
|
||||
)
|
||||
|
||||
logger.info("Checkpoints page is initializing, returning loading page")
|
||||
else:
|
||||
# 正常流程 - 获取已经初始化好的缓存数据
|
||||
try:
|
||||
cache = await self.scanner.get_cached_data(force_refresh=False)
|
||||
template = self.template_env.get_template('checkpoints.html')
|
||||
rendered = template.render(
|
||||
folders=cache.folders,
|
||||
is_initializing=False,
|
||||
settings=settings, # Pass settings to template
|
||||
request=request # Pass the request object to the template
|
||||
)
|
||||
except Exception as cache_error:
|
||||
logger.error(f"Error loading checkpoints cache data: {cache_error}")
|
||||
# 如果获取缓存失败,也显示初始化页面
|
||||
template = self.template_env.get_template('checkpoints.html')
|
||||
rendered = template.render(
|
||||
folders=[],
|
||||
is_initializing=True,
|
||||
settings=settings,
|
||||
request=request
|
||||
)
|
||||
logger.info("Checkpoints cache error, returning initialization page")
|
||||
|
||||
return web.Response(
|
||||
text=rendered,
|
||||
content_type='text/html'
|
||||
)
|
||||
except Exception as e:
|
||||
logger.error(f"Error handling checkpoints request: {e}", exc_info=True)
|
||||
return web.Response(
|
||||
text="Error loading checkpoints page",
|
||||
status=500
|
||||
)
|
||||
|
||||
async def delete_model(self, request: web.Request) -> web.Response:
|
||||
"""Handle checkpoint model deletion request"""
|
||||
return await ModelRouteUtils.handle_delete_model(request, self.scanner)
|
||||
|
||||
async def exclude_model(self, request: web.Request) -> web.Response:
|
||||
"""Handle checkpoint model exclusion request"""
|
||||
return await ModelRouteUtils.handle_exclude_model(request, self.scanner)
|
||||
|
||||
async def fetch_civitai(self, request: web.Request) -> web.Response:
|
||||
"""Handle CivitAI metadata fetch request for checkpoints"""
|
||||
return await ModelRouteUtils.handle_fetch_civitai(request, self.scanner)
|
||||
|
||||
async def replace_preview(self, request: web.Request) -> web.Response:
|
||||
"""Handle preview image replacement for checkpoints"""
|
||||
return await ModelRouteUtils.handle_replace_preview(request, self.scanner)
|
||||
|
||||
async def download_checkpoint(self, request: web.Request) -> web.Response:
|
||||
"""Handle checkpoint download request"""
|
||||
async with self._download_lock:
|
||||
# Get the download manager from service registry if not already initialized
|
||||
if self.download_manager is None:
|
||||
self.download_manager = await ServiceRegistry.get_download_manager()
|
||||
|
||||
try:
|
||||
data = await request.json()
|
||||
|
||||
# Create progress callback that uses checkpoint-specific WebSocket
|
||||
async def progress_callback(progress):
|
||||
await ws_manager.broadcast_checkpoint_progress({
|
||||
'status': 'progress',
|
||||
'progress': progress
|
||||
})
|
||||
|
||||
# Check which identifier is provided
|
||||
download_url = data.get('download_url')
|
||||
model_hash = data.get('model_hash')
|
||||
model_version_id = data.get('model_version_id')
|
||||
|
||||
# Validate that at least one identifier is provided
|
||||
if not any([download_url, model_hash, model_version_id]):
|
||||
return web.Response(
|
||||
status=400,
|
||||
text="Missing required parameter: Please provide either 'download_url', 'hash', or 'modelVersionId'"
|
||||
)
|
||||
|
||||
result = await self.download_manager.download_from_civitai(
|
||||
download_url=download_url,
|
||||
model_hash=model_hash,
|
||||
model_version_id=model_version_id,
|
||||
save_dir=data.get('checkpoint_root'),
|
||||
relative_path=data.get('relative_path', ''),
|
||||
progress_callback=progress_callback,
|
||||
model_type="checkpoint"
|
||||
)
|
||||
|
||||
if not result.get('success', False):
|
||||
error_message = result.get('error', 'Unknown error')
|
||||
|
||||
# Return 401 for early access errors
|
||||
if 'early access' in error_message.lower():
|
||||
logger.warning(f"Early access download failed: {error_message}")
|
||||
return web.Response(
|
||||
status=401,
|
||||
text=f"Early Access Restriction: {error_message}"
|
||||
)
|
||||
|
||||
return web.Response(status=500, text=error_message)
|
||||
|
||||
return web.json_response(result)
|
||||
|
||||
except Exception as e:
|
||||
error_message = str(e)
|
||||
|
||||
# Check if this might be an early access error
|
||||
if '401' in error_message:
|
||||
logger.warning(f"Early access error (401): {error_message}")
|
||||
return web.Response(
|
||||
status=401,
|
||||
text="Early Access Restriction: This model requires purchase. Please ensure you have purchased early access and are logged in to Civitai."
|
||||
)
|
||||
|
||||
logger.error(f"Error downloading checkpoint: {error_message}")
|
||||
return web.Response(status=500, text=error_message)
|
||||
|
||||
async def get_checkpoint_roots(self, request):
|
||||
"""Return the checkpoint root directories"""
|
||||
try:
|
||||
if self.scanner is None:
|
||||
self.scanner = await ServiceRegistry.get_checkpoint_scanner()
|
||||
|
||||
roots = self.scanner.get_model_roots()
|
||||
return web.json_response({
|
||||
"success": True,
|
||||
"roots": roots
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting checkpoint roots: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
"success": False,
|
||||
"error": str(e)
|
||||
}, status=500)
|
||||
|
||||
async def save_metadata(self, request: web.Request) -> web.Response:
|
||||
"""Handle saving metadata updates for checkpoints"""
|
||||
try:
|
||||
if self.scanner is None:
|
||||
self.scanner = await ServiceRegistry.get_checkpoint_scanner()
|
||||
|
||||
data = await request.json()
|
||||
file_path = data.get('file_path')
|
||||
if not file_path:
|
||||
return web.Response(text='File path is required', status=400)
|
||||
|
||||
# Remove file path from data to avoid saving it
|
||||
metadata_updates = {k: v for k, v in data.items() if k != 'file_path'}
|
||||
|
||||
# Get metadata file path
|
||||
metadata_path = os.path.splitext(file_path)[0] + '.metadata.json'
|
||||
|
||||
# Load existing metadata
|
||||
metadata = await ModelRouteUtils.load_local_metadata(metadata_path)
|
||||
|
||||
# Update metadata
|
||||
metadata.update(metadata_updates)
|
||||
|
||||
# Save updated metadata
|
||||
with open(metadata_path, 'w', encoding='utf-8') as f:
|
||||
json.dump(metadata, f, indent=2, ensure_ascii=False)
|
||||
|
||||
# Update cache
|
||||
await self.scanner.update_single_model_cache(file_path, file_path, metadata)
|
||||
|
||||
# If model_name was updated, resort the cache
|
||||
if 'model_name' in metadata_updates:
|
||||
cache = await self.scanner.get_cached_data()
|
||||
await cache.resort(name_only=True)
|
||||
|
||||
return web.json_response({'success': True})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error saving checkpoint metadata: {e}", exc_info=True)
|
||||
return web.Response(text=str(e), status=500)
|
||||
|
||||
async def get_civitai_versions(self, request: web.Request) -> web.Response:
|
||||
"""Get available versions for a Civitai checkpoint model with local availability info"""
|
||||
try:
|
||||
if self.scanner is None:
|
||||
self.scanner = await ServiceRegistry.get_checkpoint_scanner()
|
||||
|
||||
# Get the civitai client from service registry
|
||||
civitai_client = await ServiceRegistry.get_civitai_client()
|
||||
|
||||
model_id = request.match_info['model_id']
|
||||
response = await civitai_client.get_model_versions(model_id)
|
||||
if not response or not response.get('modelVersions'):
|
||||
return web.Response(status=404, text="Model not found")
|
||||
|
||||
versions = response.get('modelVersions', [])
|
||||
model_type = response.get('type', '')
|
||||
|
||||
# Check model type - should be Checkpoint
|
||||
if (model_type.lower() != 'checkpoint'):
|
||||
return web.json_response({
|
||||
'error': f"Model type mismatch. Expected Checkpoint, got {model_type}"
|
||||
}, status=400)
|
||||
|
||||
# Check local availability for each version
|
||||
for version in versions:
|
||||
# Find the primary model file (type="Model" and primary=true) in the files list
|
||||
model_file = next((file for file in version.get('files', [])
|
||||
if file.get('type') == 'Model' and file.get('primary') == True), None)
|
||||
|
||||
# If no primary file found, try to find any model file
|
||||
if not model_file:
|
||||
model_file = next((file for file in version.get('files', [])
|
||||
if file.get('type') == 'Model'), None)
|
||||
|
||||
if model_file:
|
||||
sha256 = model_file.get('hashes', {}).get('SHA256')
|
||||
if sha256:
|
||||
# Set existsLocally and localPath at the version level
|
||||
version['existsLocally'] = self.scanner.has_hash(sha256)
|
||||
if version['existsLocally']:
|
||||
version['localPath'] = self.scanner.get_path_by_hash(sha256)
|
||||
|
||||
# Also set the model file size at the version level for easier access
|
||||
version['modelSizeKB'] = model_file.get('sizeKB')
|
||||
else:
|
||||
# No model file found in this version
|
||||
version['existsLocally'] = False
|
||||
|
||||
return web.json_response(versions)
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching checkpoint model versions: {e}")
|
||||
return web.Response(status=500, text=str(e))
|
||||
105
py/routes/embedding_routes.py
Normal file
105
py/routes/embedding_routes.py
Normal file
@@ -0,0 +1,105 @@
|
||||
import logging
|
||||
from aiohttp import web
|
||||
|
||||
from .base_model_routes import BaseModelRoutes
|
||||
from ..services.embedding_service import EmbeddingService
|
||||
from ..services.service_registry import ServiceRegistry
|
||||
from ..services.metadata_service import get_default_metadata_provider
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class EmbeddingRoutes(BaseModelRoutes):
|
||||
"""Embedding-specific route controller"""
|
||||
|
||||
def __init__(self):
|
||||
"""Initialize Embedding routes with Embedding service"""
|
||||
# Service will be initialized later via setup_routes
|
||||
self.service = None
|
||||
self.template_name = "embeddings.html"
|
||||
|
||||
async def initialize_services(self):
|
||||
"""Initialize services from ServiceRegistry"""
|
||||
embedding_scanner = await ServiceRegistry.get_embedding_scanner()
|
||||
self.service = EmbeddingService(embedding_scanner)
|
||||
|
||||
# Initialize parent with the service
|
||||
super().__init__(self.service)
|
||||
|
||||
def setup_routes(self, app: web.Application):
|
||||
"""Setup Embedding routes"""
|
||||
# Schedule service initialization on app startup
|
||||
app.on_startup.append(lambda _: self.initialize_services())
|
||||
|
||||
# Setup common routes with 'embeddings' prefix (includes page route)
|
||||
super().setup_routes(app, 'embeddings')
|
||||
|
||||
def setup_specific_routes(self, app: web.Application, prefix: str):
|
||||
"""Setup Embedding-specific routes"""
|
||||
# Embedding-specific CivitAI integration
|
||||
app.router.add_get(f'/api/{prefix}/civitai/versions/{{model_id}}', self.get_civitai_versions_embedding)
|
||||
|
||||
# Embedding info by name
|
||||
app.router.add_get(f'/api/{prefix}/info/{{name}}', self.get_embedding_info)
|
||||
|
||||
async def get_embedding_info(self, request: web.Request) -> web.Response:
|
||||
"""Get detailed information for a specific embedding by name"""
|
||||
try:
|
||||
name = request.match_info.get('name', '')
|
||||
embedding_info = await self.service.get_model_info_by_name(name)
|
||||
|
||||
if embedding_info:
|
||||
return web.json_response(embedding_info)
|
||||
else:
|
||||
return web.json_response({"error": "Embedding not found"}, status=404)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error in get_embedding_info: {e}", exc_info=True)
|
||||
return web.json_response({"error": str(e)}, status=500)
|
||||
|
||||
async def get_civitai_versions_embedding(self, request: web.Request) -> web.Response:
|
||||
"""Get available versions for a Civitai embedding model with local availability info"""
|
||||
try:
|
||||
model_id = request.match_info['model_id']
|
||||
metadata_provider = await get_default_metadata_provider()
|
||||
response = await metadata_provider.get_model_versions(model_id)
|
||||
if not response or not response.get('modelVersions'):
|
||||
return web.Response(status=404, text="Model not found")
|
||||
|
||||
versions = response.get('modelVersions', [])
|
||||
model_type = response.get('type', '')
|
||||
|
||||
# Check model type - should be TextualInversion (Embedding)
|
||||
if model_type.lower() not in ['textualinversion', 'embedding']:
|
||||
return web.json_response({
|
||||
'error': f"Model type mismatch. Expected TextualInversion/Embedding, got {model_type}"
|
||||
}, status=400)
|
||||
|
||||
# Check local availability for each version
|
||||
for version in versions:
|
||||
# Find the primary model file (type="Model" and primary=true) in the files list
|
||||
model_file = next((file for file in version.get('files', [])
|
||||
if file.get('type') == 'Model' and file.get('primary') == True), None)
|
||||
|
||||
# If no primary file found, try to find any model file
|
||||
if not model_file:
|
||||
model_file = next((file for file in version.get('files', [])
|
||||
if file.get('type') == 'Model'), None)
|
||||
|
||||
if model_file:
|
||||
sha256 = model_file.get('hashes', {}).get('SHA256')
|
||||
if sha256:
|
||||
# Set existsLocally and localPath at the version level
|
||||
version['existsLocally'] = self.service.has_hash(sha256)
|
||||
if version['existsLocally']:
|
||||
version['localPath'] = self.service.get_path_by_hash(sha256)
|
||||
|
||||
# Also set the model file size at the version level for easier access
|
||||
version['modelSizeKB'] = model_file.get('sizeKB')
|
||||
else:
|
||||
# No model file found in this version
|
||||
version['existsLocally'] = False
|
||||
|
||||
return web.json_response(versions)
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching embedding model versions: {e}")
|
||||
return web.Response(status=500, text=str(e))
|
||||
74
py/routes/example_images_routes.py
Normal file
74
py/routes/example_images_routes.py
Normal file
@@ -0,0 +1,74 @@
|
||||
import logging
|
||||
from ..utils.example_images_download_manager import DownloadManager
|
||||
from ..utils.example_images_processor import ExampleImagesProcessor
|
||||
from ..utils.example_images_file_manager import ExampleImagesFileManager
|
||||
from ..services.websocket_manager import ws_manager
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class ExampleImagesRoutes:
|
||||
"""Routes for example images related functionality"""
|
||||
|
||||
@staticmethod
|
||||
def setup_routes(app):
|
||||
"""Register example images routes"""
|
||||
app.router.add_post('/api/download-example-images', ExampleImagesRoutes.download_example_images)
|
||||
app.router.add_post('/api/import-example-images', ExampleImagesRoutes.import_example_images)
|
||||
app.router.add_get('/api/example-images-status', ExampleImagesRoutes.get_example_images_status)
|
||||
app.router.add_post('/api/pause-example-images', ExampleImagesRoutes.pause_example_images)
|
||||
app.router.add_post('/api/resume-example-images', ExampleImagesRoutes.resume_example_images)
|
||||
app.router.add_post('/api/open-example-images-folder', ExampleImagesRoutes.open_example_images_folder)
|
||||
app.router.add_get('/api/example-image-files', ExampleImagesRoutes.get_example_image_files)
|
||||
app.router.add_get('/api/has-example-images', ExampleImagesRoutes.has_example_images)
|
||||
app.router.add_post('/api/delete-example-image', ExampleImagesRoutes.delete_example_image)
|
||||
app.router.add_post('/api/force-download-example-images', ExampleImagesRoutes.force_download_example_images)
|
||||
|
||||
@staticmethod
|
||||
async def download_example_images(request):
|
||||
"""Download example images for models from Civitai"""
|
||||
return await DownloadManager.start_download(request)
|
||||
|
||||
@staticmethod
|
||||
async def get_example_images_status(request):
|
||||
"""Get the current status of example images download"""
|
||||
return await DownloadManager.get_status(request)
|
||||
|
||||
@staticmethod
|
||||
async def pause_example_images(request):
|
||||
"""Pause the example images download"""
|
||||
return await DownloadManager.pause_download(request)
|
||||
|
||||
@staticmethod
|
||||
async def resume_example_images(request):
|
||||
"""Resume the example images download"""
|
||||
return await DownloadManager.resume_download(request)
|
||||
|
||||
@staticmethod
|
||||
async def open_example_images_folder(request):
|
||||
"""Open the example images folder for a specific model"""
|
||||
return await ExampleImagesFileManager.open_folder(request)
|
||||
|
||||
@staticmethod
|
||||
async def get_example_image_files(request):
|
||||
"""Get list of example image files for a specific model"""
|
||||
return await ExampleImagesFileManager.get_files(request)
|
||||
|
||||
@staticmethod
|
||||
async def import_example_images(request):
|
||||
"""Import local example images for a model"""
|
||||
return await ExampleImagesProcessor.import_images(request)
|
||||
|
||||
@staticmethod
|
||||
async def has_example_images(request):
|
||||
"""Check if example images folder exists and is not empty for a model"""
|
||||
return await ExampleImagesFileManager.has_images(request)
|
||||
|
||||
@staticmethod
|
||||
async def delete_example_image(request):
|
||||
"""Delete a custom example image for a model"""
|
||||
return await ExampleImagesProcessor.delete_custom_image(request)
|
||||
|
||||
@staticmethod
|
||||
async def force_download_example_images(request):
|
||||
"""Force download example images for specific models"""
|
||||
return await DownloadManager.start_force_download(request)
|
||||
@@ -1,189 +1,330 @@
|
||||
import os
|
||||
from aiohttp import web
|
||||
import jinja2
|
||||
from typing import Dict
|
||||
import asyncio
|
||||
import logging
|
||||
from ..config import config
|
||||
from ..services.settings_manager import settings
|
||||
from ..services.service_registry import ServiceRegistry # Add ServiceRegistry import
|
||||
from aiohttp import web
|
||||
from typing import Dict
|
||||
from server import PromptServer # type: ignore
|
||||
|
||||
from .base_model_routes import BaseModelRoutes
|
||||
from ..services.lora_service import LoraService
|
||||
from ..services.service_registry import ServiceRegistry
|
||||
from ..services.metadata_service import get_default_metadata_provider
|
||||
from ..utils.utils import get_lora_info
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
logging.getLogger('asyncio').setLevel(logging.CRITICAL)
|
||||
|
||||
class LoraRoutes:
|
||||
"""Route handlers for LoRA management endpoints"""
|
||||
class LoraRoutes(BaseModelRoutes):
|
||||
"""LoRA-specific route controller"""
|
||||
|
||||
def __init__(self):
|
||||
# Initialize service references as None, will be set during async init
|
||||
self.scanner = None
|
||||
self.recipe_scanner = None
|
||||
self.template_env = jinja2.Environment(
|
||||
loader=jinja2.FileSystemLoader(config.templates_path),
|
||||
autoescape=True
|
||||
)
|
||||
|
||||
async def init_services(self):
|
||||
"""Initialize services from ServiceRegistry"""
|
||||
self.scanner = await ServiceRegistry.get_lora_scanner()
|
||||
self.recipe_scanner = await ServiceRegistry.get_recipe_scanner()
|
||||
"""Initialize LoRA routes with LoRA service"""
|
||||
# Service will be initialized later via setup_routes
|
||||
self.service = None
|
||||
self.template_name = "loras.html"
|
||||
|
||||
async def initialize_services(self):
|
||||
"""Initialize services from ServiceRegistry"""
|
||||
lora_scanner = await ServiceRegistry.get_lora_scanner()
|
||||
self.service = LoraService(lora_scanner)
|
||||
|
||||
# Initialize parent with the service
|
||||
super().__init__(self.service)
|
||||
|
||||
def format_lora_data(self, lora: Dict) -> Dict:
|
||||
"""Format LoRA data for template rendering"""
|
||||
return {
|
||||
"model_name": lora["model_name"],
|
||||
"file_name": lora["file_name"],
|
||||
"preview_url": config.get_preview_static_url(lora["preview_url"]),
|
||||
"preview_nsfw_level": lora.get("preview_nsfw_level", 0),
|
||||
"base_model": lora["base_model"],
|
||||
"folder": lora["folder"],
|
||||
"sha256": lora["sha256"],
|
||||
"file_path": lora["file_path"].replace(os.sep, "/"),
|
||||
"size": lora["size"],
|
||||
"tags": lora["tags"],
|
||||
"modelDescription": lora["modelDescription"],
|
||||
"usage_tips": lora["usage_tips"],
|
||||
"notes": lora["notes"],
|
||||
"modified": lora["modified"],
|
||||
"from_civitai": lora.get("from_civitai", True),
|
||||
"civitai": self._filter_civitai_data(lora.get("civitai", {}))
|
||||
}
|
||||
|
||||
def _filter_civitai_data(self, data: Dict) -> Dict:
|
||||
"""Filter relevant fields from CivitAI data"""
|
||||
if not data:
|
||||
return {}
|
||||
|
||||
fields = [
|
||||
"id", "modelId", "name", "createdAt", "updatedAt",
|
||||
"publishedAt", "trainedWords", "baseModel", "description",
|
||||
"model", "images"
|
||||
]
|
||||
return {k: data[k] for k in fields if k in data}
|
||||
|
||||
async def handle_loras_page(self, request: web.Request) -> web.Response:
|
||||
"""Handle GET /loras request"""
|
||||
try:
|
||||
# Ensure services are initialized
|
||||
await self.init_services()
|
||||
|
||||
# Check if the LoraScanner is initializing
|
||||
# It's initializing if the cache object doesn't exist yet,
|
||||
# OR if the scanner explicitly says it's initializing (background task running).
|
||||
is_initializing = (
|
||||
self.scanner._cache is None or
|
||||
(hasattr(self.scanner, '_is_initializing') and self.scanner._is_initializing)
|
||||
)
|
||||
|
||||
if is_initializing:
|
||||
# If still initializing, return loading page
|
||||
template = self.template_env.get_template('loras.html')
|
||||
rendered = template.render(
|
||||
folders=[],
|
||||
is_initializing=True,
|
||||
settings=settings,
|
||||
request=request
|
||||
)
|
||||
|
||||
logger.info("Loras page is initializing, returning loading page")
|
||||
else:
|
||||
# Normal flow - get data from initialized cache
|
||||
try:
|
||||
cache = await self.scanner.get_cached_data(force_refresh=False)
|
||||
template = self.template_env.get_template('loras.html')
|
||||
rendered = template.render(
|
||||
folders=cache.folders,
|
||||
is_initializing=False,
|
||||
settings=settings,
|
||||
request=request
|
||||
)
|
||||
except Exception as cache_error:
|
||||
logger.error(f"Error loading cache data: {cache_error}")
|
||||
template = self.template_env.get_template('loras.html')
|
||||
rendered = template.render(
|
||||
folders=[],
|
||||
is_initializing=True,
|
||||
settings=settings,
|
||||
request=request
|
||||
)
|
||||
logger.info("Cache error, returning initialization page")
|
||||
|
||||
return web.Response(
|
||||
text=rendered,
|
||||
content_type='text/html'
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error handling loras request: {e}", exc_info=True)
|
||||
return web.Response(
|
||||
text="Error loading loras page",
|
||||
status=500
|
||||
)
|
||||
|
||||
async def handle_recipes_page(self, request: web.Request) -> web.Response:
|
||||
"""Handle GET /loras/recipes request"""
|
||||
try:
|
||||
# Ensure services are initialized
|
||||
await self.init_services()
|
||||
|
||||
# Skip initialization check and directly try to get cached data
|
||||
try:
|
||||
# Recipe scanner will initialize cache if needed
|
||||
await self.recipe_scanner.get_cached_data(force_refresh=False)
|
||||
template = self.template_env.get_template('recipes.html')
|
||||
rendered = template.render(
|
||||
recipes=[], # Frontend will load recipes via API
|
||||
is_initializing=False,
|
||||
settings=settings,
|
||||
request=request
|
||||
)
|
||||
except Exception as cache_error:
|
||||
logger.error(f"Error loading recipe cache data: {cache_error}")
|
||||
# Still keep error handling - show initializing page on error
|
||||
template = self.template_env.get_template('recipes.html')
|
||||
rendered = template.render(
|
||||
is_initializing=True,
|
||||
settings=settings,
|
||||
request=request
|
||||
)
|
||||
logger.info("Recipe cache error, returning initialization page")
|
||||
|
||||
return web.Response(
|
||||
text=rendered,
|
||||
content_type='text/html'
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error handling recipes request: {e}", exc_info=True)
|
||||
return web.Response(
|
||||
text="Error loading recipes page",
|
||||
status=500
|
||||
)
|
||||
|
||||
def _format_recipe_file_url(self, file_path: str) -> str:
|
||||
"""Format file path for recipe image as a URL - same as in recipe_routes"""
|
||||
try:
|
||||
# Return the file URL directly for the first lora root's preview
|
||||
recipes_dir = os.path.join(config.loras_roots[0], "recipes").replace(os.sep, '/')
|
||||
if file_path.replace(os.sep, '/').startswith(recipes_dir):
|
||||
relative_path = os.path.relpath(file_path, config.loras_roots[0]).replace(os.sep, '/')
|
||||
return f"/loras_static/root1/preview/{relative_path}"
|
||||
|
||||
# If not in recipes dir, try to create a valid URL from the file path
|
||||
file_name = os.path.basename(file_path)
|
||||
return f"/loras_static/root1/preview/recipes/{file_name}"
|
||||
except Exception as e:
|
||||
logger.error(f"Error formatting recipe file URL: {e}", exc_info=True)
|
||||
return '/loras_static/images/no-preview.png' # Return default image on error
|
||||
|
||||
def setup_routes(self, app: web.Application):
|
||||
"""Register routes with the application"""
|
||||
# Add an app startup handler to initialize services
|
||||
app.on_startup.append(self._on_startup)
|
||||
"""Setup LoRA routes"""
|
||||
# Schedule service initialization on app startup
|
||||
app.on_startup.append(lambda _: self.initialize_services())
|
||||
|
||||
# Register routes
|
||||
app.router.add_get('/loras', self.handle_loras_page)
|
||||
app.router.add_get('/loras/recipes', self.handle_recipes_page)
|
||||
# Setup common routes with 'loras' prefix (includes page route)
|
||||
super().setup_routes(app, 'loras')
|
||||
|
||||
def setup_specific_routes(self, app: web.Application, prefix: str):
|
||||
"""Setup LoRA-specific routes"""
|
||||
# LoRA-specific query routes
|
||||
app.router.add_get(f'/api/{prefix}/letter-counts', self.get_letter_counts)
|
||||
app.router.add_get(f'/api/{prefix}/get-trigger-words', self.get_lora_trigger_words)
|
||||
app.router.add_get(f'/api/{prefix}/usage-tips-by-path', self.get_lora_usage_tips_by_path)
|
||||
|
||||
async def _on_startup(self, app):
|
||||
"""Initialize services when the app starts"""
|
||||
await self.init_services()
|
||||
# CivitAI integration with LoRA-specific validation
|
||||
app.router.add_get(f'/api/{prefix}/civitai/versions/{{model_id}}', self.get_civitai_versions_lora)
|
||||
app.router.add_get(f'/api/{prefix}/civitai/model/version/{{modelVersionId}}', self.get_civitai_model_by_version)
|
||||
app.router.add_get(f'/api/{prefix}/civitai/model/hash/{{hash}}', self.get_civitai_model_by_hash)
|
||||
|
||||
# ComfyUI integration
|
||||
app.router.add_post(f'/api/{prefix}/get_trigger_words', self.get_trigger_words)
|
||||
|
||||
def _parse_specific_params(self, request: web.Request) -> Dict:
|
||||
"""Parse LoRA-specific parameters"""
|
||||
params = {}
|
||||
|
||||
# LoRA-specific parameters
|
||||
if 'first_letter' in request.query:
|
||||
params['first_letter'] = request.query.get('first_letter')
|
||||
|
||||
# Handle fuzzy search parameter name variation
|
||||
if request.query.get('fuzzy') == 'true':
|
||||
params['fuzzy_search'] = True
|
||||
|
||||
# Handle additional filter parameters for LoRAs
|
||||
if 'lora_hash' in request.query:
|
||||
if not params.get('hash_filters'):
|
||||
params['hash_filters'] = {}
|
||||
params['hash_filters']['single_hash'] = request.query['lora_hash'].lower()
|
||||
elif 'lora_hashes' in request.query:
|
||||
if not params.get('hash_filters'):
|
||||
params['hash_filters'] = {}
|
||||
params['hash_filters']['multiple_hashes'] = [h.lower() for h in request.query['lora_hashes'].split(',')]
|
||||
|
||||
return params
|
||||
|
||||
# LoRA-specific route handlers
|
||||
async def get_letter_counts(self, request: web.Request) -> web.Response:
|
||||
"""Get count of LoRAs for each letter of the alphabet"""
|
||||
try:
|
||||
letter_counts = await self.service.get_letter_counts()
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'letter_counts': letter_counts
|
||||
})
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting letter counts: {e}")
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_lora_notes(self, request: web.Request) -> web.Response:
|
||||
"""Get notes for a specific LoRA file"""
|
||||
try:
|
||||
lora_name = request.query.get('name')
|
||||
if not lora_name:
|
||||
return web.Response(text='Lora file name is required', status=400)
|
||||
|
||||
notes = await self.service.get_lora_notes(lora_name)
|
||||
if notes is not None:
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'notes': notes
|
||||
})
|
||||
else:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'LoRA not found in cache'
|
||||
}, status=404)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting lora notes: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_lora_trigger_words(self, request: web.Request) -> web.Response:
|
||||
"""Get trigger words for a specific LoRA file"""
|
||||
try:
|
||||
lora_name = request.query.get('name')
|
||||
if not lora_name:
|
||||
return web.Response(text='Lora file name is required', status=400)
|
||||
|
||||
trigger_words = await self.service.get_lora_trigger_words(lora_name)
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'trigger_words': trigger_words
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting lora trigger words: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_lora_usage_tips_by_path(self, request: web.Request) -> web.Response:
|
||||
"""Get usage tips for a LoRA by its relative path"""
|
||||
try:
|
||||
relative_path = request.query.get('relative_path')
|
||||
if not relative_path:
|
||||
return web.Response(text='Relative path is required', status=400)
|
||||
|
||||
usage_tips = await self.service.get_lora_usage_tips_by_relative_path(relative_path)
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'usage_tips': usage_tips or ''
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting lora usage tips by path: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_lora_preview_url(self, request: web.Request) -> web.Response:
|
||||
"""Get the static preview URL for a LoRA file"""
|
||||
try:
|
||||
lora_name = request.query.get('name')
|
||||
if not lora_name:
|
||||
return web.Response(text='Lora file name is required', status=400)
|
||||
|
||||
preview_url = await self.service.get_lora_preview_url(lora_name)
|
||||
if preview_url:
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'preview_url': preview_url
|
||||
})
|
||||
else:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'No preview URL found for the specified lora'
|
||||
}, status=404)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting lora preview URL: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_lora_civitai_url(self, request: web.Request) -> web.Response:
|
||||
"""Get the Civitai URL for a LoRA file"""
|
||||
try:
|
||||
lora_name = request.query.get('name')
|
||||
if not lora_name:
|
||||
return web.Response(text='Lora file name is required', status=400)
|
||||
|
||||
result = await self.service.get_lora_civitai_url(lora_name)
|
||||
if result['civitai_url']:
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
**result
|
||||
})
|
||||
else:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'No Civitai data found for the specified lora'
|
||||
}, status=404)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting lora Civitai URL: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
# CivitAI integration methods
|
||||
async def get_civitai_versions_lora(self, request: web.Request) -> web.Response:
|
||||
"""Get available versions for a Civitai LoRA model with local availability info"""
|
||||
try:
|
||||
model_id = request.match_info['model_id']
|
||||
metadata_provider = await get_default_metadata_provider()
|
||||
response = await metadata_provider.get_model_versions(model_id)
|
||||
if not response or not response.get('modelVersions'):
|
||||
return web.Response(status=404, text="Model not found")
|
||||
|
||||
versions = response.get('modelVersions', [])
|
||||
model_type = response.get('type', '')
|
||||
|
||||
# Check model type - should be LORA, LoCon, or DORA
|
||||
from ..utils.constants import VALID_LORA_TYPES
|
||||
if model_type.lower() not in VALID_LORA_TYPES:
|
||||
return web.json_response({
|
||||
'error': f"Model type mismatch. Expected LORA or LoCon, got {model_type}"
|
||||
}, status=400)
|
||||
|
||||
# Check local availability for each version
|
||||
for version in versions:
|
||||
# Find the model file (type="Model") in the files list
|
||||
model_file = next((file for file in version.get('files', [])
|
||||
if file.get('type') == 'Model'), None)
|
||||
|
||||
if model_file:
|
||||
sha256 = model_file.get('hashes', {}).get('SHA256')
|
||||
if sha256:
|
||||
# Set existsLocally and localPath at the version level
|
||||
version['existsLocally'] = self.service.has_hash(sha256)
|
||||
if version['existsLocally']:
|
||||
version['localPath'] = self.service.get_path_by_hash(sha256)
|
||||
|
||||
# Also set the model file size at the version level for easier access
|
||||
version['modelSizeKB'] = model_file.get('sizeKB')
|
||||
else:
|
||||
# No model file found in this version
|
||||
version['existsLocally'] = False
|
||||
|
||||
return web.json_response(versions)
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching LoRA model versions: {e}")
|
||||
return web.Response(status=500, text=str(e))
|
||||
|
||||
async def get_civitai_model_by_version(self, request: web.Request) -> web.Response:
|
||||
"""Get CivitAI model details by model version ID"""
|
||||
try:
|
||||
model_version_id = request.match_info.get('modelVersionId')
|
||||
|
||||
# Get model details from metadata provider
|
||||
metadata_provider = await get_default_metadata_provider()
|
||||
model, error_msg = await metadata_provider.get_model_version_info(model_version_id)
|
||||
|
||||
if not model:
|
||||
# Log warning for failed model retrieval
|
||||
logger.warning(f"Failed to fetch model version {model_version_id}: {error_msg}")
|
||||
|
||||
# Determine status code based on error message
|
||||
status_code = 404 if error_msg and "not found" in error_msg.lower() else 500
|
||||
|
||||
return web.json_response({
|
||||
"success": False,
|
||||
"error": error_msg or "Failed to fetch model information"
|
||||
}, status=status_code)
|
||||
|
||||
return web.json_response(model)
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching model details: {e}")
|
||||
return web.json_response({
|
||||
"success": False,
|
||||
"error": str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_civitai_model_by_hash(self, request: web.Request) -> web.Response:
|
||||
"""Get CivitAI model details by hash"""
|
||||
try:
|
||||
hash = request.match_info.get('hash')
|
||||
metadata_provider = await get_default_metadata_provider()
|
||||
model = await metadata_provider.get_model_by_hash(hash)
|
||||
return web.json_response(model)
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching model details by hash: {e}")
|
||||
return web.json_response({
|
||||
"success": False,
|
||||
"error": str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_trigger_words(self, request: web.Request) -> web.Response:
|
||||
"""Get trigger words for specified LoRA models"""
|
||||
try:
|
||||
json_data = await request.json()
|
||||
lora_names = json_data.get("lora_names", [])
|
||||
node_ids = json_data.get("node_ids", [])
|
||||
|
||||
all_trigger_words = []
|
||||
for lora_name in lora_names:
|
||||
_, trigger_words = get_lora_info(lora_name)
|
||||
all_trigger_words.extend(trigger_words)
|
||||
|
||||
# Format the trigger words
|
||||
trigger_words_text = ",, ".join(all_trigger_words) if all_trigger_words else ""
|
||||
|
||||
# Send update to all connected trigger word toggle nodes
|
||||
for node_id in node_ids:
|
||||
PromptServer.instance.send_sync("trigger_word_update", {
|
||||
"id": node_id,
|
||||
"message": trigger_words_text
|
||||
})
|
||||
|
||||
return web.json_response({"success": True})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting trigger words: {e}")
|
||||
return web.json_response({
|
||||
"success": False,
|
||||
"error": str(e)
|
||||
}, status=500)
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -1,9 +1,9 @@
|
||||
import os
|
||||
import time
|
||||
import base64
|
||||
import jinja2
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
import torch
|
||||
import io
|
||||
import logging
|
||||
from aiohttp import web
|
||||
@@ -16,13 +16,15 @@ from ..utils.exif_utils import ExifUtils
|
||||
from ..recipes import RecipeParserFactory
|
||||
from ..utils.constants import CARD_PREVIEW_WIDTH
|
||||
|
||||
from ..services.settings_manager import settings
|
||||
from ..services.server_i18n import server_i18n
|
||||
from ..config import config
|
||||
|
||||
# Check if running in standalone mode
|
||||
standalone_mode = 'nodes' not in sys.modules
|
||||
|
||||
from ..utils.utils import download_civitai_image
|
||||
from ..services.service_registry import ServiceRegistry # Add ServiceRegistry import
|
||||
from ..services.downloader import get_downloader
|
||||
|
||||
# Only import MetadataRegistry in non-standalone mode
|
||||
if not standalone_mode:
|
||||
@@ -40,7 +42,10 @@ class RecipeRoutes:
|
||||
# Initialize service references as None, will be set during async init
|
||||
self.recipe_scanner = None
|
||||
self.civitai_client = None
|
||||
# Remove WorkflowParser instance
|
||||
self.template_env = jinja2.Environment(
|
||||
loader=jinja2.FileSystemLoader(config.templates_path),
|
||||
autoescape=True
|
||||
)
|
||||
|
||||
# Pre-warm the cache
|
||||
self._init_cache_task = None
|
||||
@@ -54,6 +59,8 @@ class RecipeRoutes:
|
||||
def setup_routes(cls, app: web.Application):
|
||||
"""Register API routes"""
|
||||
routes = cls()
|
||||
app.router.add_get('/loras/recipes', routes.handle_recipes_page)
|
||||
|
||||
app.router.add_get('/api/recipes', routes.get_recipes)
|
||||
app.router.add_get('/api/recipe/{recipe_id}', routes.get_recipe_detail)
|
||||
app.router.add_post('/api/recipes/analyze-image', routes.analyze_recipe_image)
|
||||
@@ -115,6 +122,61 @@ class RecipeRoutes:
|
||||
await self.recipe_scanner.get_cached_data(force_refresh=True)
|
||||
except Exception as e:
|
||||
logger.error(f"Error pre-warming recipe cache: {e}", exc_info=True)
|
||||
|
||||
async def handle_recipes_page(self, request: web.Request) -> web.Response:
|
||||
"""Handle GET /loras/recipes request"""
|
||||
try:
|
||||
# Ensure services are initialized
|
||||
await self.init_services()
|
||||
|
||||
# 获取用户语言设置
|
||||
user_language = settings.get('language', 'en')
|
||||
|
||||
# 设置服务端i18n语言
|
||||
server_i18n.set_locale(user_language)
|
||||
|
||||
# 为模板环境添加i18n过滤器
|
||||
if not hasattr(self.template_env, '_i18n_filter_added'):
|
||||
self.template_env.filters['t'] = server_i18n.create_template_filter()
|
||||
self.template_env._i18n_filter_added = True
|
||||
|
||||
# Skip initialization check and directly try to get cached data
|
||||
try:
|
||||
# Recipe scanner will initialize cache if needed
|
||||
await self.recipe_scanner.get_cached_data(force_refresh=False)
|
||||
template = self.template_env.get_template('recipes.html')
|
||||
rendered = template.render(
|
||||
recipes=[], # Frontend will load recipes via API
|
||||
is_initializing=False,
|
||||
settings=settings,
|
||||
request=request,
|
||||
# 添加服务端翻译函数
|
||||
t=server_i18n.get_translation,
|
||||
)
|
||||
except Exception as cache_error:
|
||||
logger.error(f"Error loading recipe cache data: {cache_error}")
|
||||
# Still keep error handling - show initializing page on error
|
||||
template = self.template_env.get_template('recipes.html')
|
||||
rendered = template.render(
|
||||
is_initializing=True,
|
||||
settings=settings,
|
||||
request=request,
|
||||
# 添加服务端翻译函数
|
||||
t=server_i18n.get_translation,
|
||||
)
|
||||
logger.info("Recipe cache error, returning initialization page")
|
||||
|
||||
return web.Response(
|
||||
text=rendered,
|
||||
content_type='text/html'
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error handling recipes request: {e}", exc_info=True)
|
||||
return web.Response(
|
||||
text="Error loading recipes page",
|
||||
status=500
|
||||
)
|
||||
|
||||
async def get_recipes(self, request: web.Request) -> web.Response:
|
||||
"""API endpoint for getting paginated recipes"""
|
||||
@@ -254,6 +316,7 @@ class RecipeRoutes:
|
||||
content_type = request.headers.get('Content-Type', '')
|
||||
|
||||
is_url_mode = False
|
||||
metadata = None # Initialize metadata variable
|
||||
|
||||
if 'multipart/form-data' in content_type:
|
||||
# Handle image upload
|
||||
@@ -287,17 +350,55 @@ class RecipeRoutes:
|
||||
"loras": []
|
||||
}, status=400)
|
||||
|
||||
# Download image from URL
|
||||
temp_path = download_civitai_image(url)
|
||||
# Check if this is a Civitai image URL
|
||||
import re
|
||||
civitai_image_match = re.match(r'https://civitai\.com/images/(\d+)', url)
|
||||
|
||||
if not temp_path:
|
||||
return web.json_response({
|
||||
"error": "Failed to download image from URL",
|
||||
"loras": []
|
||||
}, status=400)
|
||||
if civitai_image_match:
|
||||
# Extract image ID and fetch image info using get_image_info
|
||||
image_id = civitai_image_match.group(1)
|
||||
image_info = await self.civitai_client.get_image_info(image_id)
|
||||
|
||||
if not image_info:
|
||||
return web.json_response({
|
||||
"error": "Failed to fetch image information from Civitai",
|
||||
"loras": []
|
||||
}, status=400)
|
||||
|
||||
# Get image URL from response
|
||||
image_url = image_info.get('url')
|
||||
if not image_url:
|
||||
return web.json_response({
|
||||
"error": "No image URL found in Civitai response",
|
||||
"loras": []
|
||||
}, status=400)
|
||||
|
||||
# Download image using unified downloader
|
||||
downloader = await get_downloader()
|
||||
# Create a temporary file to save the downloaded image
|
||||
with tempfile.NamedTemporaryFile(delete=False, suffix='.jpg') as temp_file:
|
||||
temp_path = temp_file.name
|
||||
|
||||
success, result = await downloader.download_file(
|
||||
image_url,
|
||||
temp_path,
|
||||
use_auth=False # Image downloads typically don't need auth
|
||||
)
|
||||
|
||||
if not success:
|
||||
return web.json_response({
|
||||
"error": f"Failed to download image from URL: {result}",
|
||||
"loras": []
|
||||
}, status=400)
|
||||
|
||||
# Use meta field from image_info as metadata
|
||||
if 'meta' in image_info:
|
||||
metadata = image_info['meta']
|
||||
|
||||
# Extract metadata from the image using ExifUtils
|
||||
metadata = ExifUtils.extract_image_metadata(temp_path)
|
||||
# If metadata wasn't obtained from Civitai API, extract it from the image
|
||||
if metadata is None:
|
||||
# Extract metadata from the image using ExifUtils
|
||||
metadata = ExifUtils.extract_image_metadata(temp_path)
|
||||
|
||||
# If no metadata found, return a more specific error
|
||||
if not metadata:
|
||||
@@ -332,8 +433,7 @@ class RecipeRoutes:
|
||||
# Parse the metadata
|
||||
result = await parser.parse_metadata(
|
||||
metadata,
|
||||
recipe_scanner=self.recipe_scanner,
|
||||
civitai_client=self.civitai_client
|
||||
recipe_scanner=self.recipe_scanner
|
||||
)
|
||||
|
||||
# For URL mode, include the image data as base64
|
||||
@@ -434,8 +534,7 @@ class RecipeRoutes:
|
||||
# Parse the metadata
|
||||
result = await parser.parse_metadata(
|
||||
metadata,
|
||||
recipe_scanner=self.recipe_scanner,
|
||||
civitai_client=self.civitai_client
|
||||
recipe_scanner=self.recipe_scanner
|
||||
)
|
||||
|
||||
# Add base64 image data to result
|
||||
@@ -545,21 +644,6 @@ class RecipeRoutes:
|
||||
image = base64.b64decode(image_base64)
|
||||
except Exception as e:
|
||||
return web.json_response({"error": f"Invalid base64 image data: {str(e)}"}, status=400)
|
||||
elif image_url:
|
||||
# Download image from URL
|
||||
temp_path = download_civitai_image(image_url)
|
||||
if not temp_path:
|
||||
return web.json_response({"error": "Failed to download image from URL"}, status=400)
|
||||
|
||||
# Read the downloaded image
|
||||
with open(temp_path, 'rb') as f:
|
||||
image = f.read()
|
||||
|
||||
# Clean up temp file
|
||||
try:
|
||||
os.unlink(temp_path)
|
||||
except:
|
||||
pass
|
||||
else:
|
||||
return web.json_response({"error": "No image data provided"}, status=400)
|
||||
|
||||
@@ -601,7 +685,7 @@ class RecipeRoutes:
|
||||
"file_name": lora.get("file_name", "") or os.path.splitext(os.path.basename(lora.get("localPath", "")))[0] if lora.get("localPath") else "",
|
||||
"hash": lora.get("hash", "").lower() if lora.get("hash") else "",
|
||||
"strength": float(lora.get("weight", 1.0)),
|
||||
"modelVersionId": lora.get("id", ""),
|
||||
"modelVersionId": lora.get("id", 0),
|
||||
"modelName": lora.get("name", ""),
|
||||
"modelVersionName": lora.get("version", ""),
|
||||
"isDeleted": lora.get("isDeleted", False), # Preserve deletion status in saved recipe
|
||||
@@ -949,7 +1033,7 @@ class RecipeRoutes:
|
||||
else:
|
||||
latest_image = None
|
||||
|
||||
if not latest_image:
|
||||
if latest_image is None:
|
||||
return web.json_response({"error": "No recent images found to use for recipe. Try generating an image first."}, status=400)
|
||||
|
||||
# Convert the image data to bytes - handle tuple and tensor cases
|
||||
@@ -971,6 +1055,8 @@ class RecipeRoutes:
|
||||
shape_info = tensor_image.shape
|
||||
logger.debug(f"Tensor shape: {shape_info}, dtype: {tensor_image.dtype}")
|
||||
|
||||
import torch
|
||||
|
||||
# Convert tensor to numpy array
|
||||
if isinstance(tensor_image, torch.Tensor):
|
||||
image_np = tensor_image.cpu().numpy()
|
||||
@@ -1053,14 +1139,14 @@ class RecipeRoutes:
|
||||
for lora_name, lora_strength in lora_matches:
|
||||
try:
|
||||
# Get lora info from scanner
|
||||
lora_info = await self.recipe_scanner._lora_scanner.get_lora_info_by_name(lora_name)
|
||||
lora_info = await self.recipe_scanner._lora_scanner.get_model_info_by_name(lora_name)
|
||||
|
||||
# Create lora entry
|
||||
lora_entry = {
|
||||
"file_name": lora_name,
|
||||
"hash": lora_info.get("sha256", "").lower() if lora_info else "",
|
||||
"strength": float(lora_strength),
|
||||
"modelVersionId": lora_info.get("civitai", {}).get("id", "") if lora_info else "",
|
||||
"modelVersionId": lora_info.get("civitai", {}).get("id", 0) if lora_info else 0,
|
||||
"modelName": lora_info.get("civitai", {}).get("model", {}).get("name", "") if lora_info else lora_name,
|
||||
"modelVersionName": lora_info.get("civitai", {}).get("name", "") if lora_info else "",
|
||||
"isDeleted": False
|
||||
@@ -1072,7 +1158,7 @@ class RecipeRoutes:
|
||||
# Get base model from lora scanner for the available loras
|
||||
base_model_counts = {}
|
||||
for lora in loras_data:
|
||||
lora_info = await self.recipe_scanner._lora_scanner.get_lora_info_by_name(lora.get("file_name", ""))
|
||||
lora_info = await self.recipe_scanner._lora_scanner.get_model_info_by_name(lora.get("file_name", ""))
|
||||
if lora_info and "base_model" in lora_info:
|
||||
base_model = lora_info["base_model"]
|
||||
base_model_counts[base_model] = base_model_counts.get(base_model, 0) + 1
|
||||
@@ -1162,7 +1248,7 @@ class RecipeRoutes:
|
||||
if lora.get("isDeleted", False):
|
||||
continue
|
||||
|
||||
if not self.recipe_scanner._lora_scanner.has_lora_hash(lora.get("hash", "")):
|
||||
if not self.recipe_scanner._lora_scanner.has_hash(lora.get("hash", "")):
|
||||
continue
|
||||
|
||||
# Get the strength
|
||||
@@ -1219,9 +1305,9 @@ class RecipeRoutes:
|
||||
data = await request.json()
|
||||
|
||||
# Validate required fields
|
||||
if 'title' not in data and 'tags' not in data and 'source_path' not in data:
|
||||
if 'title' not in data and 'tags' not in data and 'source_path' not in data and 'preview_nsfw_level' not in data:
|
||||
return web.json_response({
|
||||
"error": "At least one field to update must be provided (title or tags or source_path)"
|
||||
"error": "At least one field to update must be provided (title or tags or source_path or preview_nsfw_level)"
|
||||
}, status=400)
|
||||
|
||||
# Use the recipe scanner's update method
|
||||
@@ -1249,7 +1335,7 @@ class RecipeRoutes:
|
||||
data = await request.json()
|
||||
|
||||
# Validate required fields
|
||||
required_fields = ['recipe_id', 'lora_data', 'target_name']
|
||||
required_fields = ['recipe_id', 'lora_index', 'target_name']
|
||||
for field in required_fields:
|
||||
if field not in data:
|
||||
return web.json_response({
|
||||
@@ -1257,7 +1343,7 @@ class RecipeRoutes:
|
||||
}, status=400)
|
||||
|
||||
recipe_id = data['recipe_id']
|
||||
lora_data = data['lora_data']
|
||||
lora_index = int(data['lora_index'])
|
||||
target_name = data['target_name']
|
||||
|
||||
# Get recipe scanner
|
||||
@@ -1270,53 +1356,34 @@ class RecipeRoutes:
|
||||
return web.json_response({"error": "Recipe not found"}, status=404)
|
||||
|
||||
# Find target LoRA by name
|
||||
target_lora = await lora_scanner.get_lora_info_by_name(target_name)
|
||||
target_lora = await lora_scanner.get_model_info_by_name(target_name)
|
||||
if not target_lora:
|
||||
return web.json_response({"error": f"Local LoRA not found with name: {target_name}"}, status=404)
|
||||
|
||||
# Load recipe data
|
||||
with open(recipe_path, 'r', encoding='utf-8') as f:
|
||||
recipe_data = json.load(f)
|
||||
|
||||
# Find the deleted LoRA in the recipe
|
||||
found = False
|
||||
updated_lora = None
|
||||
|
||||
lora = recipe_data.get("loras", [])[lora_index] if lora_index < len(recipe_data.get('loras', [])) else None
|
||||
|
||||
if lora is None:
|
||||
return web.json_response({"error": "LoRA index out of range in recipe"}, status=404)
|
||||
|
||||
# Update LoRA data
|
||||
lora['isDeleted'] = False
|
||||
lora['exclude'] = False
|
||||
lora['file_name'] = target_name
|
||||
|
||||
# Identification can be by hash, modelVersionId, or modelName
|
||||
for i, lora in enumerate(recipe_data.get('loras', [])):
|
||||
match_found = False
|
||||
|
||||
# Try to match by available identifiers
|
||||
if 'hash' in lora and 'hash' in lora_data and lora['hash'] == lora_data['hash']:
|
||||
match_found = True
|
||||
elif 'modelVersionId' in lora and 'modelVersionId' in lora_data and lora['modelVersionId'] == lora_data['modelVersionId']:
|
||||
match_found = True
|
||||
elif 'modelName' in lora and 'modelName' in lora_data and lora['modelName'] == lora_data['modelName']:
|
||||
match_found = True
|
||||
|
||||
if match_found:
|
||||
# Update LoRA data
|
||||
lora['isDeleted'] = False
|
||||
lora['file_name'] = target_name
|
||||
|
||||
# Update with information from the target LoRA
|
||||
if 'sha256' in target_lora:
|
||||
lora['hash'] = target_lora['sha256'].lower()
|
||||
if target_lora.get("civitai"):
|
||||
lora['modelName'] = target_lora['civitai']['model']['name']
|
||||
lora['modelVersionName'] = target_lora['civitai']['name']
|
||||
lora['modelVersionId'] = target_lora['civitai']['id']
|
||||
|
||||
# Keep original fields for identification
|
||||
|
||||
# Mark as found and store updated lora
|
||||
found = True
|
||||
updated_lora = dict(lora) # Make a copy for response
|
||||
break
|
||||
|
||||
if not found:
|
||||
return web.json_response({"error": "Could not find matching deleted LoRA in recipe"}, status=404)
|
||||
# Update with information from the target LoRA
|
||||
if 'sha256' in target_lora:
|
||||
lora['hash'] = target_lora['sha256'].lower()
|
||||
if target_lora.get("civitai"):
|
||||
lora['modelName'] = target_lora['civitai']['model']['name']
|
||||
lora['modelVersionName'] = target_lora['civitai']['name']
|
||||
lora['modelVersionId'] = target_lora['civitai']['id']
|
||||
|
||||
updated_lora = dict(lora) # Make a copy for response
|
||||
|
||||
# Recalculate recipe fingerprint after updating LoRA
|
||||
from ..utils.utils import calculate_recipe_fingerprint
|
||||
recipe_data['fingerprint'] = calculate_recipe_fingerprint(recipe_data.get('loras', []))
|
||||
@@ -1326,7 +1393,7 @@ class RecipeRoutes:
|
||||
json.dump(recipe_data, f, indent=4, ensure_ascii=False)
|
||||
|
||||
updated_lora['inLibrary'] = True
|
||||
updated_lora['preview_url'] = target_lora['preview_url']
|
||||
updated_lora['preview_url'] = config.get_preview_static_url(target_lora['preview_url'])
|
||||
updated_lora['localPath'] = target_lora['file_path']
|
||||
|
||||
# Update in cache if it exists
|
||||
@@ -1401,9 +1468,9 @@ class RecipeRoutes:
|
||||
if 'loras' in recipe:
|
||||
for lora in recipe['loras']:
|
||||
if 'hash' in lora and lora['hash']:
|
||||
lora['inLibrary'] = self.recipe_scanner._lora_scanner.has_lora_hash(lora['hash'].lower())
|
||||
lora['inLibrary'] = self.recipe_scanner._lora_scanner.has_hash(lora['hash'].lower())
|
||||
lora['preview_url'] = self.recipe_scanner._lora_scanner.get_preview_url_by_hash(lora['hash'].lower())
|
||||
lora['localPath'] = self.recipe_scanner._lora_scanner.get_lora_path_by_hash(lora['hash'].lower())
|
||||
lora['localPath'] = self.recipe_scanner._lora_scanner.get_path_by_hash(lora['hash'].lower())
|
||||
|
||||
# Ensure file_url is set (needed by frontend)
|
||||
if 'file_path' in recipe:
|
||||
|
||||
519
py/routes/stats_routes.py
Normal file
519
py/routes/stats_routes.py
Normal file
@@ -0,0 +1,519 @@
|
||||
import os
|
||||
import json
|
||||
import jinja2
|
||||
from aiohttp import web
|
||||
import logging
|
||||
from datetime import datetime, timedelta
|
||||
from collections import defaultdict, Counter
|
||||
from typing import Dict, List, Any
|
||||
|
||||
from ..config import config
|
||||
from ..services.settings_manager import settings
|
||||
from ..services.server_i18n import server_i18n
|
||||
from ..services.service_registry import ServiceRegistry
|
||||
from ..utils.usage_stats import UsageStats
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class StatsRoutes:
|
||||
"""Route handlers for Statistics page and API endpoints"""
|
||||
|
||||
def __init__(self):
|
||||
self.lora_scanner = None
|
||||
self.checkpoint_scanner = None
|
||||
self.embedding_scanner = None
|
||||
self.usage_stats = None
|
||||
self.template_env = jinja2.Environment(
|
||||
loader=jinja2.FileSystemLoader(config.templates_path),
|
||||
autoescape=True
|
||||
)
|
||||
|
||||
async def init_services(self):
|
||||
"""Initialize services from ServiceRegistry"""
|
||||
self.lora_scanner = await ServiceRegistry.get_lora_scanner()
|
||||
self.checkpoint_scanner = await ServiceRegistry.get_checkpoint_scanner()
|
||||
self.embedding_scanner = await ServiceRegistry.get_embedding_scanner()
|
||||
|
||||
# Only initialize usage stats if we have valid paths configured
|
||||
try:
|
||||
self.usage_stats = UsageStats()
|
||||
except RuntimeError as e:
|
||||
logger.warning(f"Could not initialize usage statistics: {e}")
|
||||
self.usage_stats = None
|
||||
|
||||
async def handle_stats_page(self, request: web.Request) -> web.Response:
|
||||
"""Handle GET /statistics request"""
|
||||
try:
|
||||
# Ensure services are initialized
|
||||
await self.init_services()
|
||||
|
||||
# Check if scanners are initializing
|
||||
lora_initializing = (
|
||||
self.lora_scanner._cache is None or
|
||||
(hasattr(self.lora_scanner, 'is_initializing') and self.lora_scanner.is_initializing())
|
||||
)
|
||||
|
||||
checkpoint_initializing = (
|
||||
self.checkpoint_scanner._cache is None or
|
||||
(hasattr(self.checkpoint_scanner, '_is_initializing') and self.checkpoint_scanner._is_initializing)
|
||||
)
|
||||
|
||||
embedding_initializing = (
|
||||
self.embedding_scanner._cache is None or
|
||||
(hasattr(self.embedding_scanner, 'is_initializing') and self.embedding_scanner.is_initializing())
|
||||
)
|
||||
|
||||
is_initializing = lora_initializing or checkpoint_initializing or embedding_initializing
|
||||
|
||||
# 获取用户语言设置
|
||||
user_language = settings.get('language', 'en')
|
||||
|
||||
# 设置服务端i18n语言
|
||||
server_i18n.set_locale(user_language)
|
||||
|
||||
# 为模板环境添加i18n过滤器
|
||||
if not hasattr(self.template_env, '_i18n_filter_added'):
|
||||
self.template_env.filters['t'] = server_i18n.create_template_filter()
|
||||
self.template_env._i18n_filter_added = True
|
||||
|
||||
template = self.template_env.get_template('statistics.html')
|
||||
rendered = template.render(
|
||||
is_initializing=is_initializing,
|
||||
settings=settings,
|
||||
request=request,
|
||||
t=server_i18n.get_translation,
|
||||
)
|
||||
|
||||
return web.Response(
|
||||
text=rendered,
|
||||
content_type='text/html'
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error handling statistics request: {e}", exc_info=True)
|
||||
return web.Response(
|
||||
text="Error loading statistics page",
|
||||
status=500
|
||||
)
|
||||
|
||||
async def get_collection_overview(self, request: web.Request) -> web.Response:
|
||||
"""Get collection overview statistics"""
|
||||
try:
|
||||
await self.init_services()
|
||||
|
||||
# Get LoRA statistics
|
||||
lora_cache = await self.lora_scanner.get_cached_data()
|
||||
lora_count = len(lora_cache.raw_data)
|
||||
lora_size = sum(lora.get('size', 0) for lora in lora_cache.raw_data)
|
||||
|
||||
# Get Checkpoint statistics
|
||||
checkpoint_cache = await self.checkpoint_scanner.get_cached_data()
|
||||
checkpoint_count = len(checkpoint_cache.raw_data)
|
||||
checkpoint_size = sum(cp.get('size', 0) for cp in checkpoint_cache.raw_data)
|
||||
|
||||
# Get Embedding statistics
|
||||
embedding_cache = await self.embedding_scanner.get_cached_data()
|
||||
embedding_count = len(embedding_cache.raw_data)
|
||||
embedding_size = sum(emb.get('size', 0) for emb in embedding_cache.raw_data)
|
||||
|
||||
# Get usage statistics
|
||||
usage_data = await self.usage_stats.get_stats()
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'data': {
|
||||
'total_models': lora_count + checkpoint_count + embedding_count,
|
||||
'lora_count': lora_count,
|
||||
'checkpoint_count': checkpoint_count,
|
||||
'embedding_count': embedding_count,
|
||||
'total_size': lora_size + checkpoint_size + embedding_size,
|
||||
'lora_size': lora_size,
|
||||
'checkpoint_size': checkpoint_size,
|
||||
'embedding_size': embedding_size,
|
||||
'total_generations': usage_data.get('total_executions', 0),
|
||||
'unused_loras': self._count_unused_models(lora_cache.raw_data, usage_data.get('loras', {})),
|
||||
'unused_checkpoints': self._count_unused_models(checkpoint_cache.raw_data, usage_data.get('checkpoints', {})),
|
||||
'unused_embeddings': self._count_unused_models(embedding_cache.raw_data, usage_data.get('embeddings', {}))
|
||||
}
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting collection overview: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_usage_analytics(self, request: web.Request) -> web.Response:
|
||||
"""Get usage analytics data"""
|
||||
try:
|
||||
await self.init_services()
|
||||
|
||||
# Get usage statistics
|
||||
usage_data = await self.usage_stats.get_stats()
|
||||
|
||||
# Get model data for enrichment
|
||||
lora_cache = await self.lora_scanner.get_cached_data()
|
||||
checkpoint_cache = await self.checkpoint_scanner.get_cached_data()
|
||||
embedding_cache = await self.embedding_scanner.get_cached_data()
|
||||
|
||||
# Create hash to model mapping
|
||||
lora_map = {lora['sha256']: lora for lora in lora_cache.raw_data}
|
||||
checkpoint_map = {cp['sha256']: cp for cp in checkpoint_cache.raw_data}
|
||||
embedding_map = {emb['sha256']: emb for emb in embedding_cache.raw_data}
|
||||
|
||||
# Prepare top used models
|
||||
top_loras = self._get_top_used_models(usage_data.get('loras', {}), lora_map, 10)
|
||||
top_checkpoints = self._get_top_used_models(usage_data.get('checkpoints', {}), checkpoint_map, 10)
|
||||
top_embeddings = self._get_top_used_models(usage_data.get('embeddings', {}), embedding_map, 10)
|
||||
|
||||
# Prepare usage timeline (last 30 days)
|
||||
timeline = self._get_usage_timeline(usage_data, 30)
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'data': {
|
||||
'top_loras': top_loras,
|
||||
'top_checkpoints': top_checkpoints,
|
||||
'top_embeddings': top_embeddings,
|
||||
'usage_timeline': timeline,
|
||||
'total_executions': usage_data.get('total_executions', 0)
|
||||
}
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting usage analytics: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_base_model_distribution(self, request: web.Request) -> web.Response:
|
||||
"""Get base model distribution statistics"""
|
||||
try:
|
||||
await self.init_services()
|
||||
|
||||
# Get model data
|
||||
lora_cache = await self.lora_scanner.get_cached_data()
|
||||
checkpoint_cache = await self.checkpoint_scanner.get_cached_data()
|
||||
embedding_cache = await self.embedding_scanner.get_cached_data()
|
||||
|
||||
# Count by base model
|
||||
lora_base_models = Counter(lora.get('base_model', 'Unknown') for lora in lora_cache.raw_data)
|
||||
checkpoint_base_models = Counter(cp.get('base_model', 'Unknown') for cp in checkpoint_cache.raw_data)
|
||||
embedding_base_models = Counter(emb.get('base_model', 'Unknown') for emb in embedding_cache.raw_data)
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'data': {
|
||||
'loras': dict(lora_base_models),
|
||||
'checkpoints': dict(checkpoint_base_models),
|
||||
'embeddings': dict(embedding_base_models)
|
||||
}
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting base model distribution: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_tag_analytics(self, request: web.Request) -> web.Response:
|
||||
"""Get tag usage analytics"""
|
||||
try:
|
||||
await self.init_services()
|
||||
|
||||
# Get model data
|
||||
lora_cache = await self.lora_scanner.get_cached_data()
|
||||
checkpoint_cache = await self.checkpoint_scanner.get_cached_data()
|
||||
embedding_cache = await self.embedding_scanner.get_cached_data()
|
||||
|
||||
# Count tag frequencies
|
||||
all_tags = []
|
||||
for lora in lora_cache.raw_data:
|
||||
all_tags.extend(lora.get('tags', []))
|
||||
for cp in checkpoint_cache.raw_data:
|
||||
all_tags.extend(cp.get('tags', []))
|
||||
for emb in embedding_cache.raw_data:
|
||||
all_tags.extend(emb.get('tags', []))
|
||||
|
||||
tag_counts = Counter(all_tags)
|
||||
|
||||
# Get top 50 tags
|
||||
top_tags = [{'tag': tag, 'count': count} for tag, count in tag_counts.most_common(50)]
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'data': {
|
||||
'top_tags': top_tags,
|
||||
'total_unique_tags': len(tag_counts)
|
||||
}
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting tag analytics: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_storage_analytics(self, request: web.Request) -> web.Response:
|
||||
"""Get storage usage analytics"""
|
||||
try:
|
||||
await self.init_services()
|
||||
|
||||
# Get usage statistics
|
||||
usage_data = await self.usage_stats.get_stats()
|
||||
|
||||
# Get model data
|
||||
lora_cache = await self.lora_scanner.get_cached_data()
|
||||
checkpoint_cache = await self.checkpoint_scanner.get_cached_data()
|
||||
embedding_cache = await self.embedding_scanner.get_cached_data()
|
||||
|
||||
# Create models with usage data
|
||||
lora_storage = []
|
||||
for lora in lora_cache.raw_data:
|
||||
usage_count = 0
|
||||
if lora['sha256'] in usage_data.get('loras', {}):
|
||||
usage_count = usage_data['loras'][lora['sha256']].get('total', 0)
|
||||
|
||||
lora_storage.append({
|
||||
'name': lora['model_name'],
|
||||
'size': lora.get('size', 0),
|
||||
'usage_count': usage_count,
|
||||
'folder': lora.get('folder', ''),
|
||||
'base_model': lora.get('base_model', 'Unknown')
|
||||
})
|
||||
|
||||
checkpoint_storage = []
|
||||
for cp in checkpoint_cache.raw_data:
|
||||
usage_count = 0
|
||||
if cp['sha256'] in usage_data.get('checkpoints', {}):
|
||||
usage_count = usage_data['checkpoints'][cp['sha256']].get('total', 0)
|
||||
|
||||
checkpoint_storage.append({
|
||||
'name': cp['model_name'],
|
||||
'size': cp.get('size', 0),
|
||||
'usage_count': usage_count,
|
||||
'folder': cp.get('folder', ''),
|
||||
'base_model': cp.get('base_model', 'Unknown')
|
||||
})
|
||||
|
||||
embedding_storage = []
|
||||
for emb in embedding_cache.raw_data:
|
||||
usage_count = 0
|
||||
if emb['sha256'] in usage_data.get('embeddings', {}):
|
||||
usage_count = usage_data['embeddings'][emb['sha256']].get('total', 0)
|
||||
|
||||
embedding_storage.append({
|
||||
'name': emb['model_name'],
|
||||
'size': emb.get('size', 0),
|
||||
'usage_count': usage_count,
|
||||
'folder': emb.get('folder', ''),
|
||||
'base_model': emb.get('base_model', 'Unknown')
|
||||
})
|
||||
|
||||
# Sort by size
|
||||
lora_storage.sort(key=lambda x: x['size'], reverse=True)
|
||||
checkpoint_storage.sort(key=lambda x: x['size'], reverse=True)
|
||||
embedding_storage.sort(key=lambda x: x['size'], reverse=True)
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'data': {
|
||||
'loras': lora_storage[:20], # Top 20 by size
|
||||
'checkpoints': checkpoint_storage[:20],
|
||||
'embeddings': embedding_storage[:20]
|
||||
}
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting storage analytics: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
async def get_insights(self, request: web.Request) -> web.Response:
|
||||
"""Get smart insights about the collection"""
|
||||
try:
|
||||
await self.init_services()
|
||||
|
||||
# Get usage statistics
|
||||
usage_data = await self.usage_stats.get_stats()
|
||||
|
||||
# Get model data
|
||||
lora_cache = await self.lora_scanner.get_cached_data()
|
||||
checkpoint_cache = await self.checkpoint_scanner.get_cached_data()
|
||||
embedding_cache = await self.embedding_scanner.get_cached_data()
|
||||
|
||||
insights = []
|
||||
|
||||
# Calculate unused models
|
||||
unused_loras = self._count_unused_models(lora_cache.raw_data, usage_data.get('loras', {}))
|
||||
unused_checkpoints = self._count_unused_models(checkpoint_cache.raw_data, usage_data.get('checkpoints', {}))
|
||||
unused_embeddings = self._count_unused_models(embedding_cache.raw_data, usage_data.get('embeddings', {}))
|
||||
|
||||
total_loras = len(lora_cache.raw_data)
|
||||
total_checkpoints = len(checkpoint_cache.raw_data)
|
||||
total_embeddings = len(embedding_cache.raw_data)
|
||||
|
||||
if total_loras > 0:
|
||||
unused_lora_percent = (unused_loras / total_loras) * 100
|
||||
if unused_lora_percent > 50:
|
||||
insights.append({
|
||||
'type': 'warning',
|
||||
'title': 'High Number of Unused LoRAs',
|
||||
'description': f'{unused_lora_percent:.1f}% of your LoRAs ({unused_loras}/{total_loras}) have never been used.',
|
||||
'suggestion': 'Consider organizing or archiving unused models to free up storage space.'
|
||||
})
|
||||
|
||||
if total_checkpoints > 0:
|
||||
unused_checkpoint_percent = (unused_checkpoints / total_checkpoints) * 100
|
||||
if unused_checkpoint_percent > 30:
|
||||
insights.append({
|
||||
'type': 'warning',
|
||||
'title': 'Unused Checkpoints Detected',
|
||||
'description': f'{unused_checkpoint_percent:.1f}% of your checkpoints ({unused_checkpoints}/{total_checkpoints}) have never been used.',
|
||||
'suggestion': 'Review and consider removing checkpoints you no longer need.'
|
||||
})
|
||||
|
||||
if total_embeddings > 0:
|
||||
unused_embedding_percent = (unused_embeddings / total_embeddings) * 100
|
||||
if unused_embedding_percent > 50:
|
||||
insights.append({
|
||||
'type': 'warning',
|
||||
'title': 'High Number of Unused Embeddings',
|
||||
'description': f'{unused_embedding_percent:.1f}% of your embeddings ({unused_embeddings}/{total_embeddings}) have never been used.',
|
||||
'suggestion': 'Consider organizing or archiving unused embeddings to optimize your collection.'
|
||||
})
|
||||
|
||||
# Storage insights
|
||||
total_size = sum(lora.get('size', 0) for lora in lora_cache.raw_data) + \
|
||||
sum(cp.get('size', 0) for cp in checkpoint_cache.raw_data) + \
|
||||
sum(emb.get('size', 0) for emb in embedding_cache.raw_data)
|
||||
|
||||
if total_size > 100 * 1024 * 1024 * 1024: # 100GB
|
||||
insights.append({
|
||||
'type': 'info',
|
||||
'title': 'Large Collection Detected',
|
||||
'description': f'Your model collection is using {self._format_size(total_size)} of storage.',
|
||||
'suggestion': 'Consider using external storage or cloud solutions for better organization.'
|
||||
})
|
||||
|
||||
# Recent activity insight
|
||||
if usage_data.get('total_executions', 0) > 100:
|
||||
insights.append({
|
||||
'type': 'success',
|
||||
'title': 'Active User',
|
||||
'description': f'You\'ve completed {usage_data["total_executions"]} generations so far!',
|
||||
'suggestion': 'Keep exploring and creating amazing content with your models.'
|
||||
})
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'data': {
|
||||
'insights': insights
|
||||
}
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting insights: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
def _count_unused_models(self, models: List[Dict], usage_data: Dict) -> int:
|
||||
"""Count models that have never been used"""
|
||||
used_hashes = set(usage_data.keys())
|
||||
unused_count = 0
|
||||
|
||||
for model in models:
|
||||
if model.get('sha256') not in used_hashes:
|
||||
unused_count += 1
|
||||
|
||||
return unused_count
|
||||
|
||||
def _get_top_used_models(self, usage_data: Dict, model_map: Dict, limit: int) -> List[Dict]:
|
||||
"""Get top used models with their metadata"""
|
||||
sorted_usage = sorted(usage_data.items(), key=lambda x: x[1].get('total', 0), reverse=True)
|
||||
|
||||
top_models = []
|
||||
for sha256, usage_info in sorted_usage[:limit]:
|
||||
if sha256 in model_map:
|
||||
model = model_map[sha256]
|
||||
top_models.append({
|
||||
'name': model['model_name'],
|
||||
'usage_count': usage_info.get('total', 0),
|
||||
'base_model': model.get('base_model', 'Unknown'),
|
||||
'preview_url': config.get_preview_static_url(model.get('preview_url', '')),
|
||||
'folder': model.get('folder', '')
|
||||
})
|
||||
|
||||
return top_models
|
||||
|
||||
def _get_usage_timeline(self, usage_data: Dict, days: int) -> List[Dict]:
|
||||
"""Get usage timeline for the past N days"""
|
||||
timeline = []
|
||||
today = datetime.now()
|
||||
|
||||
for i in range(days):
|
||||
date = today - timedelta(days=i)
|
||||
date_str = date.strftime('%Y-%m-%d')
|
||||
|
||||
lora_usage = 0
|
||||
checkpoint_usage = 0
|
||||
embedding_usage = 0
|
||||
|
||||
# Count usage for this date
|
||||
for model_usage in usage_data.get('loras', {}).values():
|
||||
if isinstance(model_usage, dict) and 'history' in model_usage:
|
||||
lora_usage += model_usage['history'].get(date_str, 0)
|
||||
|
||||
for model_usage in usage_data.get('checkpoints', {}).values():
|
||||
if isinstance(model_usage, dict) and 'history' in model_usage:
|
||||
checkpoint_usage += model_usage['history'].get(date_str, 0)
|
||||
|
||||
for model_usage in usage_data.get('embeddings', {}).values():
|
||||
if isinstance(model_usage, dict) and 'history' in model_usage:
|
||||
embedding_usage += model_usage['history'].get(date_str, 0)
|
||||
|
||||
timeline.append({
|
||||
'date': date_str,
|
||||
'lora_usage': lora_usage,
|
||||
'checkpoint_usage': checkpoint_usage,
|
||||
'embedding_usage': embedding_usage,
|
||||
'total_usage': lora_usage + checkpoint_usage + embedding_usage
|
||||
})
|
||||
|
||||
return list(reversed(timeline)) # Oldest to newest
|
||||
|
||||
def _format_size(self, size_bytes: int) -> str:
|
||||
"""Format file size in human readable format"""
|
||||
for unit in ['B', 'KB', 'MB', 'GB', 'TB']:
|
||||
if size_bytes < 1024.0:
|
||||
return f"{size_bytes:.1f} {unit}"
|
||||
size_bytes /= 1024.0
|
||||
return f"{size_bytes:.1f} PB"
|
||||
|
||||
def setup_routes(self, app: web.Application):
|
||||
"""Register routes with the application"""
|
||||
# Add an app startup handler to initialize services
|
||||
app.on_startup.append(self._on_startup)
|
||||
|
||||
# Register page route
|
||||
app.router.add_get('/statistics', self.handle_stats_page)
|
||||
|
||||
# Register API routes
|
||||
app.router.add_get('/api/stats/collection-overview', self.get_collection_overview)
|
||||
app.router.add_get('/api/stats/usage-analytics', self.get_usage_analytics)
|
||||
app.router.add_get('/api/stats/base-model-distribution', self.get_base_model_distribution)
|
||||
app.router.add_get('/api/stats/tag-analytics', self.get_tag_analytics)
|
||||
app.router.add_get('/api/stats/storage-analytics', self.get_storage_analytics)
|
||||
app.router.add_get('/api/stats/insights', self.get_insights)
|
||||
|
||||
async def _on_startup(self, app):
|
||||
"""Initialize services when the app starts"""
|
||||
await self.init_services()
|
||||
@@ -1,9 +1,13 @@
|
||||
import os
|
||||
import aiohttp
|
||||
import logging
|
||||
import toml
|
||||
import git
|
||||
import zipfile
|
||||
import shutil
|
||||
import tempfile
|
||||
from aiohttp import web
|
||||
from typing import Dict, Any, List
|
||||
from typing import Dict, List
|
||||
from ..services.downloader import get_downloader, Downloader
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@@ -13,7 +17,9 @@ class UpdateRoutes:
|
||||
@staticmethod
|
||||
def setup_routes(app):
|
||||
"""Register update check routes"""
|
||||
app.router.add_get('/loras/api/check-updates', UpdateRoutes.check_updates)
|
||||
app.router.add_get('/api/check-updates', UpdateRoutes.check_updates)
|
||||
app.router.add_get('/api/version-info', UpdateRoutes.get_version_info)
|
||||
app.router.add_post('/api/perform-update', UpdateRoutes.perform_update)
|
||||
|
||||
@staticmethod
|
||||
async def check_updates(request):
|
||||
@@ -22,24 +28,39 @@ class UpdateRoutes:
|
||||
Returns update status and version information
|
||||
"""
|
||||
try:
|
||||
nightly = request.query.get('nightly', 'false').lower() == 'true'
|
||||
|
||||
# Read local version from pyproject.toml
|
||||
local_version = UpdateRoutes._get_local_version()
|
||||
|
||||
# Get git info (commit hash, branch)
|
||||
git_info = UpdateRoutes._get_git_info()
|
||||
|
||||
# Fetch remote version from GitHub
|
||||
remote_version, changelog = await UpdateRoutes._get_remote_version()
|
||||
if nightly:
|
||||
remote_version, changelog = await UpdateRoutes._get_nightly_version()
|
||||
else:
|
||||
remote_version, changelog = await UpdateRoutes._get_remote_version()
|
||||
|
||||
# Compare versions
|
||||
update_available = UpdateRoutes._compare_versions(
|
||||
local_version.replace('v', ''),
|
||||
remote_version.replace('v', '')
|
||||
)
|
||||
if nightly:
|
||||
# For nightly, compare commit hashes
|
||||
update_available = UpdateRoutes._compare_nightly_versions(git_info, remote_version)
|
||||
else:
|
||||
# For stable, compare semantic versions
|
||||
update_available = UpdateRoutes._compare_versions(
|
||||
local_version.replace('v', ''),
|
||||
remote_version.replace('v', '')
|
||||
)
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'current_version': local_version,
|
||||
'latest_version': remote_version,
|
||||
'update_available': update_available,
|
||||
'changelog': changelog
|
||||
'changelog': changelog,
|
||||
'git_info': git_info,
|
||||
'nightly': nightly
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
@@ -48,6 +69,301 @@ class UpdateRoutes:
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
})
|
||||
|
||||
@staticmethod
|
||||
async def get_version_info(request):
|
||||
"""
|
||||
Returns the current version in the format 'version-short_hash'
|
||||
"""
|
||||
try:
|
||||
# Read local version from pyproject.toml
|
||||
local_version = UpdateRoutes._get_local_version().replace('v', '')
|
||||
|
||||
# Get git info (commit hash, branch)
|
||||
git_info = UpdateRoutes._get_git_info()
|
||||
short_hash = git_info['short_hash']
|
||||
|
||||
# Format: version-short_hash
|
||||
version_string = f"{local_version}-{short_hash}"
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'version': version_string
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to get version info: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
})
|
||||
|
||||
@staticmethod
|
||||
async def perform_update(request):
|
||||
"""
|
||||
Perform Git-based update to latest release tag or main branch.
|
||||
If .git is missing, fallback to ZIP download.
|
||||
"""
|
||||
try:
|
||||
body = await request.json() if request.has_body else {}
|
||||
nightly = body.get('nightly', False)
|
||||
|
||||
current_dir = os.path.dirname(os.path.abspath(__file__))
|
||||
plugin_root = os.path.dirname(os.path.dirname(current_dir))
|
||||
|
||||
settings_path = os.path.join(plugin_root, 'settings.json')
|
||||
settings_backup = None
|
||||
if os.path.exists(settings_path):
|
||||
with open(settings_path, 'r', encoding='utf-8') as f:
|
||||
settings_backup = f.read()
|
||||
logger.info("Backed up settings.json")
|
||||
|
||||
git_folder = os.path.join(plugin_root, '.git')
|
||||
if os.path.exists(git_folder):
|
||||
# Git update
|
||||
success, new_version = await UpdateRoutes._perform_git_update(plugin_root, nightly)
|
||||
else:
|
||||
# Fallback: Download ZIP and replace files
|
||||
success, new_version = await UpdateRoutes._download_and_replace_zip(plugin_root)
|
||||
|
||||
if settings_backup and success:
|
||||
with open(settings_path, 'w', encoding='utf-8') as f:
|
||||
f.write(settings_backup)
|
||||
logger.info("Restored settings.json")
|
||||
|
||||
if success:
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'message': f'Successfully updated to {new_version}',
|
||||
'new_version': new_version
|
||||
})
|
||||
else:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Failed to complete update'
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to perform update: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
})
|
||||
|
||||
@staticmethod
|
||||
async def _download_and_replace_zip(plugin_root: str) -> tuple[bool, str]:
|
||||
"""
|
||||
Download latest release ZIP from GitHub and replace plugin files.
|
||||
Skips settings.json and civitai folder. Writes extracted file list to .tracking.
|
||||
"""
|
||||
repo_owner = "willmiao"
|
||||
repo_name = "ComfyUI-Lora-Manager"
|
||||
github_api = f"https://api.github.com/repos/{repo_owner}/{repo_name}/releases/latest"
|
||||
|
||||
try:
|
||||
downloader = await get_downloader()
|
||||
|
||||
# Get release info
|
||||
success, data = await downloader.make_request(
|
||||
'GET',
|
||||
github_api,
|
||||
use_auth=False
|
||||
)
|
||||
if not success:
|
||||
logger.error(f"Failed to fetch release info: {data}")
|
||||
return False, ""
|
||||
|
||||
zip_url = data.get("zipball_url")
|
||||
version = data.get("tag_name", "unknown")
|
||||
|
||||
# Download ZIP to temporary file
|
||||
with tempfile.NamedTemporaryFile(delete=False, suffix=".zip") as tmp_zip:
|
||||
tmp_zip_path = tmp_zip.name
|
||||
|
||||
success, result = await downloader.download_file(
|
||||
url=zip_url,
|
||||
save_path=tmp_zip_path,
|
||||
use_auth=False,
|
||||
allow_resume=False
|
||||
)
|
||||
|
||||
if not success:
|
||||
logger.error(f"Failed to download ZIP: {result}")
|
||||
return False, ""
|
||||
|
||||
zip_path = tmp_zip_path
|
||||
|
||||
# Skip both settings.json and civitai folder
|
||||
UpdateRoutes._clean_plugin_folder(plugin_root, skip_files=['settings.json', 'civitai'])
|
||||
|
||||
# Extract ZIP to temp dir
|
||||
with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
with zipfile.ZipFile(zip_path, 'r') as zip_ref:
|
||||
zip_ref.extractall(tmp_dir)
|
||||
# Find extracted folder (GitHub ZIP contains a root folder)
|
||||
extracted_root = next(os.scandir(tmp_dir)).path
|
||||
|
||||
# Copy files, skipping settings.json and civitai folder
|
||||
for item in os.listdir(extracted_root):
|
||||
if item == 'settings.json' or item == 'civitai':
|
||||
continue
|
||||
src = os.path.join(extracted_root, item)
|
||||
dst = os.path.join(plugin_root, item)
|
||||
if os.path.isdir(src):
|
||||
if os.path.exists(dst):
|
||||
shutil.rmtree(dst)
|
||||
shutil.copytree(src, dst, ignore=shutil.ignore_patterns('settings.json', 'civitai'))
|
||||
else:
|
||||
shutil.copy2(src, dst)
|
||||
|
||||
# Write .tracking file: list all files under extracted_root, relative to extracted_root
|
||||
# for ComfyUI Manager to work properly
|
||||
tracking_info_file = os.path.join(plugin_root, '.tracking')
|
||||
tracking_files = []
|
||||
for root, dirs, files in os.walk(extracted_root):
|
||||
# Skip civitai folder and its contents
|
||||
rel_root = os.path.relpath(root, extracted_root)
|
||||
if rel_root == 'civitai' or rel_root.startswith('civitai' + os.sep):
|
||||
continue
|
||||
for file in files:
|
||||
rel_path = os.path.relpath(os.path.join(root, file), extracted_root)
|
||||
# Skip settings.json and any file under civitai
|
||||
if rel_path == 'settings.json' or rel_path.startswith('civitai' + os.sep):
|
||||
continue
|
||||
tracking_files.append(rel_path.replace("\\", "/"))
|
||||
with open(tracking_info_file, "w", encoding='utf-8') as file:
|
||||
file.write('\n'.join(tracking_files))
|
||||
|
||||
os.remove(zip_path)
|
||||
logger.info(f"Updated plugin via ZIP to {version}")
|
||||
return True, version
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"ZIP update failed: {e}", exc_info=True)
|
||||
return False, ""
|
||||
|
||||
def _clean_plugin_folder(plugin_root, skip_files=None):
|
||||
skip_files = skip_files or []
|
||||
for item in os.listdir(plugin_root):
|
||||
if item in skip_files:
|
||||
continue
|
||||
path = os.path.join(plugin_root, item)
|
||||
if os.path.isdir(path):
|
||||
shutil.rmtree(path)
|
||||
else:
|
||||
os.remove(path)
|
||||
|
||||
@staticmethod
|
||||
async def _get_nightly_version() -> tuple[str, List[str]]:
|
||||
"""
|
||||
Fetch latest commit from main branch
|
||||
"""
|
||||
repo_owner = "willmiao"
|
||||
repo_name = "ComfyUI-Lora-Manager"
|
||||
|
||||
# Use GitHub API to fetch the latest commit from main branch
|
||||
github_url = f"https://api.github.com/repos/{repo_owner}/{repo_name}/commits/main"
|
||||
|
||||
try:
|
||||
downloader = await Downloader.get_instance()
|
||||
success, data = await downloader.make_request('GET', github_url, custom_headers={'Accept': 'application/vnd.github+json'})
|
||||
|
||||
if not success:
|
||||
logger.warning(f"Failed to fetch GitHub commit: {data}")
|
||||
return "main", []
|
||||
|
||||
commit_sha = data.get('sha', '')[:7] # Short hash
|
||||
commit_message = data.get('commit', {}).get('message', '')
|
||||
|
||||
# Format as "main-{short_hash}"
|
||||
version = f"main-{commit_sha}"
|
||||
|
||||
# Use commit message as changelog
|
||||
changelog = [commit_message] if commit_message else []
|
||||
|
||||
return version, changelog
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching nightly version: {e}", exc_info=True)
|
||||
return "main", []
|
||||
|
||||
@staticmethod
|
||||
def _compare_nightly_versions(local_git_info: Dict[str, str], remote_version: str) -> bool:
|
||||
"""
|
||||
Compare local commit hash with remote main branch
|
||||
"""
|
||||
try:
|
||||
local_hash = local_git_info.get('short_hash', 'unknown')
|
||||
if local_hash == 'unknown':
|
||||
return True # Assume update available if we can't get local hash
|
||||
|
||||
# Extract remote hash from version string (format: "main-{hash}")
|
||||
if '-' in remote_version:
|
||||
remote_hash = remote_version.split('-')[-1]
|
||||
return local_hash != remote_hash
|
||||
|
||||
return True # Default to update available
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error comparing nightly versions: {e}")
|
||||
return False
|
||||
|
||||
@staticmethod
|
||||
async def _perform_git_update(plugin_root: str, nightly: bool = False) -> tuple[bool, str]:
|
||||
"""
|
||||
Perform Git-based update using GitPython
|
||||
|
||||
Args:
|
||||
plugin_root: Path to the plugin root directory
|
||||
nightly: Whether to update to main branch or latest release
|
||||
|
||||
Returns:
|
||||
tuple: (success, new_version)
|
||||
"""
|
||||
try:
|
||||
# Open the Git repository
|
||||
repo = git.Repo(plugin_root)
|
||||
|
||||
# Fetch latest changes
|
||||
origin = repo.remotes.origin
|
||||
origin.fetch()
|
||||
|
||||
if nightly:
|
||||
# Switch to main branch and pull latest
|
||||
main_branch = 'main'
|
||||
if main_branch not in [branch.name for branch in repo.branches]:
|
||||
# Create local main branch if it doesn't exist
|
||||
repo.create_head(main_branch, origin.refs.main)
|
||||
|
||||
repo.heads[main_branch].checkout()
|
||||
origin.pull(main_branch)
|
||||
|
||||
# Get new commit hash
|
||||
new_version = f"main-{repo.head.commit.hexsha[:7]}"
|
||||
|
||||
else:
|
||||
# Get latest release tag
|
||||
tags = sorted(repo.tags, key=lambda t: t.commit.committed_datetime, reverse=True)
|
||||
if not tags:
|
||||
logger.error("No tags found in repository")
|
||||
return False, ""
|
||||
|
||||
latest_tag = tags[0]
|
||||
|
||||
# Checkout to latest tag
|
||||
repo.git.checkout(latest_tag.name)
|
||||
|
||||
new_version = latest_tag.name
|
||||
|
||||
logger.info(f"Successfully updated to {new_version}")
|
||||
return True, new_version
|
||||
|
||||
except git.exc.GitError as e:
|
||||
logger.error(f"Git error during update: {e}")
|
||||
return False, ""
|
||||
except Exception as e:
|
||||
logger.error(f"Error during Git update: {e}")
|
||||
return False, ""
|
||||
|
||||
@staticmethod
|
||||
def _get_local_version() -> str:
|
||||
@@ -72,6 +388,35 @@ class UpdateRoutes:
|
||||
logger.error(f"Failed to get local version: {e}", exc_info=True)
|
||||
return "v0.0.0"
|
||||
|
||||
@staticmethod
|
||||
def _get_git_info() -> Dict[str, str]:
|
||||
"""Get Git repository information"""
|
||||
current_dir = os.path.dirname(os.path.abspath(__file__))
|
||||
plugin_root = os.path.dirname(os.path.dirname(current_dir))
|
||||
|
||||
git_info = {
|
||||
'commit_hash': 'unknown',
|
||||
'short_hash': 'stable',
|
||||
'branch': 'unknown',
|
||||
'commit_date': 'unknown'
|
||||
}
|
||||
|
||||
try:
|
||||
# Check if we're in a git repository
|
||||
if not os.path.exists(os.path.join(plugin_root, '.git')):
|
||||
return git_info
|
||||
|
||||
repo = git.Repo(plugin_root)
|
||||
commit = repo.head.commit
|
||||
git_info['commit_hash'] = commit.hexsha
|
||||
git_info['short_hash'] = commit.hexsha[:7]
|
||||
git_info['branch'] = repo.active_branch.name if not repo.head.is_detached else 'detached'
|
||||
git_info['commit_date'] = commit.committed_datetime.strftime('%Y-%m-%d')
|
||||
except Exception as e:
|
||||
logger.warning(f"Error getting git info: {e}")
|
||||
|
||||
return git_info
|
||||
|
||||
@staticmethod
|
||||
async def _get_remote_version() -> tuple[str, List[str]]:
|
||||
"""
|
||||
@@ -86,22 +431,22 @@ class UpdateRoutes:
|
||||
github_url = f"https://api.github.com/repos/{repo_owner}/{repo_name}/releases/latest"
|
||||
|
||||
try:
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.get(github_url, headers={'Accept': 'application/vnd.github+json'}) as response:
|
||||
if response.status != 200:
|
||||
logger.warning(f"Failed to fetch GitHub release: {response.status}")
|
||||
return "v0.0.0", []
|
||||
|
||||
data = await response.json()
|
||||
version = data.get('tag_name', '')
|
||||
if not version.startswith('v'):
|
||||
version = f"v{version}"
|
||||
|
||||
# Extract changelog from release notes
|
||||
body = data.get('body', '')
|
||||
changelog = UpdateRoutes._parse_changelog(body)
|
||||
|
||||
return version, changelog
|
||||
downloader = await Downloader.get_instance()
|
||||
success, data = await downloader.make_request('GET', github_url, custom_headers={'Accept': 'application/vnd.github+json'})
|
||||
|
||||
if not success:
|
||||
logger.warning(f"Failed to fetch GitHub release: {data}")
|
||||
return "v0.0.0", []
|
||||
|
||||
version = data.get('tag_name', '')
|
||||
if not version.startswith('v'):
|
||||
version = f"v{version}"
|
||||
|
||||
# Extract changelog from release notes
|
||||
body = data.get('body', '')
|
||||
changelog = UpdateRoutes._parse_changelog(body)
|
||||
|
||||
return version, changelog
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching remote version: {e}", exc_info=True)
|
||||
|
||||
451
py/services/base_model_service.py
Normal file
451
py/services/base_model_service.py
Normal file
@@ -0,0 +1,451 @@
|
||||
from abc import ABC, abstractmethod
|
||||
from typing import Dict, List, Optional, Type
|
||||
import logging
|
||||
import os
|
||||
|
||||
from ..utils.models import BaseModelMetadata
|
||||
from ..utils.routes_common import ModelRouteUtils
|
||||
from ..utils.constants import NSFW_LEVELS
|
||||
from .settings_manager import settings
|
||||
from ..utils.utils import fuzzy_match
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class BaseModelService(ABC):
|
||||
"""Base service class for all model types"""
|
||||
|
||||
def __init__(self, model_type: str, scanner, metadata_class: Type[BaseModelMetadata]):
|
||||
"""Initialize the service
|
||||
|
||||
Args:
|
||||
model_type: Type of model (lora, checkpoint, etc.)
|
||||
scanner: Model scanner instance
|
||||
metadata_class: Metadata class for this model type
|
||||
"""
|
||||
self.model_type = model_type
|
||||
self.scanner = scanner
|
||||
self.metadata_class = metadata_class
|
||||
|
||||
async def get_paginated_data(self, page: int, page_size: int, sort_by: str = 'name',
|
||||
folder: str = None, search: str = None, fuzzy_search: bool = False,
|
||||
base_models: list = None, tags: list = None,
|
||||
search_options: dict = None, hash_filters: dict = None,
|
||||
favorites_only: bool = False, **kwargs) -> Dict:
|
||||
"""Get paginated and filtered model data
|
||||
|
||||
Args:
|
||||
page: Page number (1-based)
|
||||
page_size: Number of items per page
|
||||
sort_by: Sort criteria, e.g. 'name', 'name:asc', 'name:desc', 'date', 'date:asc', 'date:desc'
|
||||
folder: Folder filter
|
||||
search: Search term
|
||||
fuzzy_search: Whether to use fuzzy search
|
||||
base_models: List of base models to filter by
|
||||
tags: List of tags to filter by
|
||||
search_options: Search options dict
|
||||
hash_filters: Hash filtering options
|
||||
favorites_only: Filter for favorites only
|
||||
**kwargs: Additional model-specific filters
|
||||
|
||||
Returns:
|
||||
Dict containing paginated results
|
||||
"""
|
||||
cache = await self.scanner.get_cached_data()
|
||||
|
||||
# Parse sort_by into sort_key and order
|
||||
if ':' in sort_by:
|
||||
sort_key, order = sort_by.split(':', 1)
|
||||
sort_key = sort_key.strip()
|
||||
order = order.strip().lower()
|
||||
if order not in ('asc', 'desc'):
|
||||
order = 'asc'
|
||||
else:
|
||||
sort_key = sort_by.strip()
|
||||
order = 'asc'
|
||||
|
||||
# Get default search options if not provided
|
||||
if search_options is None:
|
||||
search_options = {
|
||||
'filename': True,
|
||||
'modelname': True,
|
||||
'tags': False,
|
||||
'recursive': True,
|
||||
}
|
||||
|
||||
# Get the base data set using new sort logic
|
||||
filtered_data = await cache.get_sorted_data(sort_key, order)
|
||||
|
||||
# Apply hash filtering if provided (highest priority)
|
||||
if hash_filters:
|
||||
filtered_data = await self._apply_hash_filters(filtered_data, hash_filters)
|
||||
|
||||
# Jump to pagination for hash filters
|
||||
return self._paginate(filtered_data, page, page_size)
|
||||
|
||||
# Apply common filters
|
||||
filtered_data = await self._apply_common_filters(
|
||||
filtered_data, folder, base_models, tags, favorites_only, search_options
|
||||
)
|
||||
|
||||
# Apply search filtering
|
||||
if search:
|
||||
filtered_data = await self._apply_search_filters(
|
||||
filtered_data, search, fuzzy_search, search_options
|
||||
)
|
||||
|
||||
# Apply model-specific filters
|
||||
filtered_data = await self._apply_specific_filters(filtered_data, **kwargs)
|
||||
|
||||
return self._paginate(filtered_data, page, page_size)
|
||||
|
||||
async def _apply_hash_filters(self, data: List[Dict], hash_filters: Dict) -> List[Dict]:
|
||||
"""Apply hash-based filtering"""
|
||||
single_hash = hash_filters.get('single_hash')
|
||||
multiple_hashes = hash_filters.get('multiple_hashes')
|
||||
|
||||
if single_hash:
|
||||
# Filter by single hash
|
||||
single_hash = single_hash.lower()
|
||||
return [
|
||||
item for item in data
|
||||
if item.get('sha256', '').lower() == single_hash
|
||||
]
|
||||
elif multiple_hashes:
|
||||
# Filter by multiple hashes
|
||||
hash_set = set(hash.lower() for hash in multiple_hashes)
|
||||
return [
|
||||
item for item in data
|
||||
if item.get('sha256', '').lower() in hash_set
|
||||
]
|
||||
|
||||
return data
|
||||
|
||||
async def _apply_common_filters(self, data: List[Dict], folder: str = None,
|
||||
base_models: list = None, tags: list = None,
|
||||
favorites_only: bool = False, search_options: dict = None) -> List[Dict]:
|
||||
"""Apply common filters that work across all model types"""
|
||||
# Apply SFW filtering if enabled in settings
|
||||
if settings.get('show_only_sfw', False):
|
||||
data = [
|
||||
item for item in data
|
||||
if not item.get('preview_nsfw_level') or item.get('preview_nsfw_level') < NSFW_LEVELS['R']
|
||||
]
|
||||
|
||||
# Apply favorites filtering if enabled
|
||||
if favorites_only:
|
||||
data = [
|
||||
item for item in data
|
||||
if item.get('favorite', False) is True
|
||||
]
|
||||
|
||||
# Apply folder filtering
|
||||
if folder is not None:
|
||||
if search_options and search_options.get('recursive', True):
|
||||
# Recursive folder filtering - include all subfolders
|
||||
# Ensure we match exact folder or its subfolders by checking path boundaries
|
||||
if folder == "":
|
||||
# Empty folder means root - include all items
|
||||
pass # Don't filter anything
|
||||
else:
|
||||
# Add trailing slash to ensure we match folder boundaries correctly
|
||||
folder_with_separator = folder + "/"
|
||||
data = [
|
||||
item for item in data
|
||||
if (item['folder'] == folder or
|
||||
item['folder'].startswith(folder_with_separator))
|
||||
]
|
||||
else:
|
||||
# Exact folder filtering
|
||||
data = [
|
||||
item for item in data
|
||||
if item['folder'] == folder
|
||||
]
|
||||
|
||||
# Apply base model filtering
|
||||
if base_models and len(base_models) > 0:
|
||||
data = [
|
||||
item for item in data
|
||||
if item.get('base_model') in base_models
|
||||
]
|
||||
|
||||
# Apply tag filtering
|
||||
if tags and len(tags) > 0:
|
||||
data = [
|
||||
item for item in data
|
||||
if any(tag in item.get('tags', []) for tag in tags)
|
||||
]
|
||||
|
||||
return data
|
||||
|
||||
async def _apply_search_filters(self, data: List[Dict], search: str,
|
||||
fuzzy_search: bool, search_options: dict) -> List[Dict]:
|
||||
"""Apply search filtering"""
|
||||
search_results = []
|
||||
|
||||
for item in data:
|
||||
# Search by file name
|
||||
if search_options.get('filename', True):
|
||||
if fuzzy_search:
|
||||
if fuzzy_match(item.get('file_name', ''), search):
|
||||
search_results.append(item)
|
||||
continue
|
||||
elif search.lower() in item.get('file_name', '').lower():
|
||||
search_results.append(item)
|
||||
continue
|
||||
|
||||
# Search by model name
|
||||
if search_options.get('modelname', True):
|
||||
if fuzzy_search:
|
||||
if fuzzy_match(item.get('model_name', ''), search):
|
||||
search_results.append(item)
|
||||
continue
|
||||
elif search.lower() in item.get('model_name', '').lower():
|
||||
search_results.append(item)
|
||||
continue
|
||||
|
||||
# Search by tags
|
||||
if search_options.get('tags', False) and 'tags' in item:
|
||||
if any((fuzzy_match(tag, search) if fuzzy_search else search.lower() in tag.lower())
|
||||
for tag in item['tags']):
|
||||
search_results.append(item)
|
||||
continue
|
||||
|
||||
# Search by creator
|
||||
civitai = item.get('civitai')
|
||||
creator_username = ''
|
||||
if civitai and isinstance(civitai, dict):
|
||||
creator = civitai.get('creator')
|
||||
if creator and isinstance(creator, dict):
|
||||
creator_username = creator.get('username', '')
|
||||
if search_options.get('creator', False) and creator_username:
|
||||
if fuzzy_search:
|
||||
if fuzzy_match(creator_username, search):
|
||||
search_results.append(item)
|
||||
continue
|
||||
elif search.lower() in creator_username.lower():
|
||||
search_results.append(item)
|
||||
continue
|
||||
|
||||
return search_results
|
||||
|
||||
async def _apply_specific_filters(self, data: List[Dict], **kwargs) -> List[Dict]:
|
||||
"""Apply model-specific filters - to be overridden by subclasses if needed"""
|
||||
return data
|
||||
|
||||
def _paginate(self, data: List[Dict], page: int, page_size: int) -> Dict:
|
||||
"""Apply pagination to filtered data"""
|
||||
total_items = len(data)
|
||||
start_idx = (page - 1) * page_size
|
||||
end_idx = min(start_idx + page_size, total_items)
|
||||
|
||||
return {
|
||||
'items': data[start_idx:end_idx],
|
||||
'total': total_items,
|
||||
'page': page,
|
||||
'page_size': page_size,
|
||||
'total_pages': (total_items + page_size - 1) // page_size
|
||||
}
|
||||
|
||||
@abstractmethod
|
||||
async def format_response(self, model_data: Dict) -> Dict:
|
||||
"""Format model data for API response - must be implemented by subclasses"""
|
||||
pass
|
||||
|
||||
# Common service methods that delegate to scanner
|
||||
async def get_top_tags(self, limit: int = 20) -> List[Dict]:
|
||||
"""Get top tags sorted by frequency"""
|
||||
return await self.scanner.get_top_tags(limit)
|
||||
|
||||
async def get_base_models(self, limit: int = 20) -> List[Dict]:
|
||||
"""Get base models sorted by frequency"""
|
||||
return await self.scanner.get_base_models(limit)
|
||||
|
||||
def has_hash(self, sha256: str) -> bool:
|
||||
"""Check if a model with given hash exists"""
|
||||
return self.scanner.has_hash(sha256)
|
||||
|
||||
def get_path_by_hash(self, sha256: str) -> Optional[str]:
|
||||
"""Get file path for a model by its hash"""
|
||||
return self.scanner.get_path_by_hash(sha256)
|
||||
|
||||
def get_hash_by_path(self, file_path: str) -> Optional[str]:
|
||||
"""Get hash for a model by its file path"""
|
||||
return self.scanner.get_hash_by_path(file_path)
|
||||
|
||||
async def scan_models(self, force_refresh: bool = False, rebuild_cache: bool = False):
|
||||
"""Trigger model scanning"""
|
||||
return await self.scanner.get_cached_data(force_refresh=force_refresh, rebuild_cache=rebuild_cache)
|
||||
|
||||
async def get_model_info_by_name(self, name: str):
|
||||
"""Get model information by name"""
|
||||
return await self.scanner.get_model_info_by_name(name)
|
||||
|
||||
def get_model_roots(self) -> List[str]:
|
||||
"""Get model root directories"""
|
||||
return self.scanner.get_model_roots()
|
||||
|
||||
async def get_folder_tree(self, model_root: str) -> Dict:
|
||||
"""Get hierarchical folder tree for a specific model root"""
|
||||
cache = await self.scanner.get_cached_data()
|
||||
|
||||
# Build tree structure from folders
|
||||
tree = {}
|
||||
|
||||
for folder in cache.folders:
|
||||
# Check if this folder belongs to the specified model root
|
||||
folder_belongs_to_root = False
|
||||
for root in self.scanner.get_model_roots():
|
||||
if root == model_root:
|
||||
folder_belongs_to_root = True
|
||||
break
|
||||
|
||||
if not folder_belongs_to_root:
|
||||
continue
|
||||
|
||||
# Split folder path into components
|
||||
parts = folder.split('/') if folder else []
|
||||
current_level = tree
|
||||
|
||||
for part in parts:
|
||||
if part not in current_level:
|
||||
current_level[part] = {}
|
||||
current_level = current_level[part]
|
||||
|
||||
return tree
|
||||
|
||||
async def get_unified_folder_tree(self) -> Dict:
|
||||
"""Get unified folder tree across all model roots"""
|
||||
cache = await self.scanner.get_cached_data()
|
||||
|
||||
# Build unified tree structure by analyzing all relative paths
|
||||
unified_tree = {}
|
||||
|
||||
# Get all model roots for path normalization
|
||||
model_roots = self.scanner.get_model_roots()
|
||||
|
||||
for folder in cache.folders:
|
||||
if not folder: # Skip empty folders
|
||||
continue
|
||||
|
||||
# Find which root this folder belongs to by checking the actual file paths
|
||||
# This is a simplified approach - we'll use the folder as-is since it should already be relative
|
||||
relative_path = folder
|
||||
|
||||
# Split folder path into components
|
||||
parts = relative_path.split('/')
|
||||
current_level = unified_tree
|
||||
|
||||
for part in parts:
|
||||
if part not in current_level:
|
||||
current_level[part] = {}
|
||||
current_level = current_level[part]
|
||||
|
||||
return unified_tree
|
||||
|
||||
async def get_model_notes(self, model_name: str) -> Optional[str]:
|
||||
"""Get notes for a specific model file"""
|
||||
cache = await self.scanner.get_cached_data()
|
||||
|
||||
for model in cache.raw_data:
|
||||
if model['file_name'] == model_name:
|
||||
return model.get('notes', '')
|
||||
|
||||
return None
|
||||
|
||||
async def get_model_preview_url(self, model_name: str) -> Optional[str]:
|
||||
"""Get the static preview URL for a model file"""
|
||||
cache = await self.scanner.get_cached_data()
|
||||
|
||||
for model in cache.raw_data:
|
||||
if model['file_name'] == model_name:
|
||||
preview_url = model.get('preview_url')
|
||||
if preview_url:
|
||||
from ..config import config
|
||||
return config.get_preview_static_url(preview_url)
|
||||
|
||||
return '/loras_static/images/no-preview.png'
|
||||
|
||||
async def get_model_civitai_url(self, model_name: str) -> Dict[str, Optional[str]]:
|
||||
"""Get the Civitai URL for a model file"""
|
||||
cache = await self.scanner.get_cached_data()
|
||||
|
||||
for model in cache.raw_data:
|
||||
if model['file_name'] == model_name:
|
||||
civitai_data = model.get('civitai', {})
|
||||
model_id = civitai_data.get('modelId')
|
||||
version_id = civitai_data.get('id')
|
||||
|
||||
if model_id:
|
||||
civitai_url = f"https://civitai.com/models/{model_id}"
|
||||
if version_id:
|
||||
civitai_url += f"?modelVersionId={version_id}"
|
||||
|
||||
return {
|
||||
'civitai_url': civitai_url,
|
||||
'model_id': str(model_id),
|
||||
'version_id': str(version_id) if version_id else None
|
||||
}
|
||||
|
||||
return {'civitai_url': None, 'model_id': None, 'version_id': None}
|
||||
|
||||
async def get_model_metadata(self, file_path: str) -> Optional[Dict]:
|
||||
"""Get filtered CivitAI metadata for a model by file path"""
|
||||
cache = await self.scanner.get_cached_data()
|
||||
|
||||
for model in cache.raw_data:
|
||||
if model.get('file_path') == file_path:
|
||||
return ModelRouteUtils.filter_civitai_data(model.get("civitai", {}))
|
||||
|
||||
return None
|
||||
|
||||
async def get_model_description(self, file_path: str) -> Optional[str]:
|
||||
"""Get model description by file path"""
|
||||
cache = await self.scanner.get_cached_data()
|
||||
|
||||
for model in cache.raw_data:
|
||||
if model.get('file_path') == file_path:
|
||||
return model.get('modelDescription', '')
|
||||
|
||||
return None
|
||||
|
||||
async def search_relative_paths(self, search_term: str, limit: int = 15) -> List[str]:
|
||||
"""Search model relative file paths for autocomplete functionality"""
|
||||
cache = await self.scanner.get_cached_data()
|
||||
|
||||
matching_paths = []
|
||||
search_lower = search_term.lower()
|
||||
|
||||
# Get model roots for path calculation
|
||||
model_roots = self.scanner.get_model_roots()
|
||||
|
||||
for model in cache.raw_data:
|
||||
file_path = model.get('file_path', '')
|
||||
if not file_path:
|
||||
continue
|
||||
|
||||
# Calculate relative path from model root
|
||||
relative_path = None
|
||||
for root in model_roots:
|
||||
# Normalize paths for comparison
|
||||
normalized_root = os.path.normpath(root)
|
||||
normalized_file = os.path.normpath(file_path)
|
||||
|
||||
if normalized_file.startswith(normalized_root):
|
||||
# Remove root and leading separator to get relative path
|
||||
relative_path = normalized_file[len(normalized_root):].lstrip(os.sep)
|
||||
break
|
||||
|
||||
if relative_path and search_lower in relative_path.lower():
|
||||
matching_paths.append(relative_path)
|
||||
|
||||
if len(matching_paths) >= limit * 2: # Get more for better sorting
|
||||
break
|
||||
|
||||
# Sort by relevance (exact matches first, then by length)
|
||||
matching_paths.sort(key=lambda x: (
|
||||
not x.lower().startswith(search_lower), # Exact prefix matches first
|
||||
len(x), # Then by length (shorter first)
|
||||
x.lower() # Then alphabetically
|
||||
))
|
||||
|
||||
return matching_paths[:limit]
|
||||
@@ -1,131 +1,34 @@
|
||||
import os
|
||||
import logging
|
||||
import asyncio
|
||||
from typing import List, Dict, Optional, Set
|
||||
import folder_paths # type: ignore
|
||||
from typing import List
|
||||
|
||||
from ..utils.models import CheckpointMetadata
|
||||
from ..config import config
|
||||
from .model_scanner import ModelScanner
|
||||
from .model_hash_index import ModelHashIndex
|
||||
from .service_registry import ServiceRegistry
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class CheckpointScanner(ModelScanner):
|
||||
"""Service for scanning and managing checkpoint files"""
|
||||
|
||||
_instance = None
|
||||
_lock = asyncio.Lock()
|
||||
|
||||
def __new__(cls):
|
||||
if cls._instance is None:
|
||||
cls._instance = super().__new__(cls)
|
||||
return cls._instance
|
||||
|
||||
def __init__(self):
|
||||
if not hasattr(self, '_initialized'):
|
||||
# Define supported file extensions
|
||||
file_extensions = {'.safetensors', '.ckpt', '.pt', '.pth', '.sft', '.gguf'}
|
||||
super().__init__(
|
||||
model_type="checkpoint",
|
||||
model_class=CheckpointMetadata,
|
||||
file_extensions=file_extensions,
|
||||
hash_index=ModelHashIndex()
|
||||
)
|
||||
self._checkpoint_roots = self._init_checkpoint_roots()
|
||||
self._initialized = True
|
||||
# Define supported file extensions
|
||||
file_extensions = {'.ckpt', '.pt', '.pt2', '.bin', '.pth', '.safetensors', '.pkl', '.sft', '.gguf'}
|
||||
super().__init__(
|
||||
model_type="checkpoint",
|
||||
model_class=CheckpointMetadata,
|
||||
file_extensions=file_extensions,
|
||||
hash_index=ModelHashIndex()
|
||||
)
|
||||
|
||||
def adjust_metadata(self, metadata, file_path, root_path):
|
||||
if hasattr(metadata, "model_type"):
|
||||
if root_path in config.checkpoints_roots:
|
||||
metadata.model_type = "checkpoint"
|
||||
elif root_path in config.unet_roots:
|
||||
metadata.model_type = "diffusion_model"
|
||||
return metadata
|
||||
|
||||
@classmethod
|
||||
async def get_instance(cls):
|
||||
"""Get singleton instance with async support"""
|
||||
async with cls._lock:
|
||||
if cls._instance is None:
|
||||
cls._instance = cls()
|
||||
return cls._instance
|
||||
|
||||
def _init_checkpoint_roots(self) -> List[str]:
|
||||
"""Initialize checkpoint roots from ComfyUI settings"""
|
||||
# Get both checkpoint and diffusion_models paths
|
||||
checkpoint_paths = folder_paths.get_folder_paths("checkpoints")
|
||||
diffusion_paths = folder_paths.get_folder_paths("diffusion_models")
|
||||
|
||||
# Combine, normalize and deduplicate paths
|
||||
all_paths = set()
|
||||
for path in checkpoint_paths + diffusion_paths:
|
||||
if os.path.exists(path):
|
||||
norm_path = path.replace(os.sep, "/")
|
||||
all_paths.add(norm_path)
|
||||
|
||||
# Sort for consistent order
|
||||
sorted_paths = sorted(all_paths, key=lambda p: p.lower())
|
||||
|
||||
return sorted_paths
|
||||
|
||||
def get_model_roots(self) -> List[str]:
|
||||
"""Get checkpoint root directories"""
|
||||
return self._checkpoint_roots
|
||||
|
||||
async def scan_all_models(self) -> List[Dict]:
|
||||
"""Scan all checkpoint directories and return metadata"""
|
||||
all_checkpoints = []
|
||||
|
||||
# Create scan tasks for each directory
|
||||
scan_tasks = []
|
||||
for root in self._checkpoint_roots:
|
||||
task = asyncio.create_task(self._scan_directory(root))
|
||||
scan_tasks.append(task)
|
||||
|
||||
# Wait for all tasks to complete
|
||||
for task in scan_tasks:
|
||||
try:
|
||||
checkpoints = await task
|
||||
all_checkpoints.extend(checkpoints)
|
||||
except Exception as e:
|
||||
logger.error(f"Error scanning checkpoint directory: {e}")
|
||||
|
||||
return all_checkpoints
|
||||
|
||||
async def _scan_directory(self, root_path: str) -> List[Dict]:
|
||||
"""Scan a directory for checkpoint files"""
|
||||
checkpoints = []
|
||||
original_root = root_path
|
||||
|
||||
async def scan_recursive(path: str, visited_paths: set):
|
||||
try:
|
||||
real_path = os.path.realpath(path)
|
||||
if real_path in visited_paths:
|
||||
logger.debug(f"Skipping already visited path: {path}")
|
||||
return
|
||||
visited_paths.add(real_path)
|
||||
|
||||
with os.scandir(path) as it:
|
||||
entries = list(it)
|
||||
for entry in entries:
|
||||
try:
|
||||
if entry.is_file(follow_symlinks=True):
|
||||
# Check if file has supported extension
|
||||
ext = os.path.splitext(entry.name)[1].lower()
|
||||
if ext in self.file_extensions:
|
||||
file_path = entry.path.replace(os.sep, "/")
|
||||
await self._process_single_file(file_path, original_root, checkpoints)
|
||||
await asyncio.sleep(0)
|
||||
elif entry.is_dir(follow_symlinks=True):
|
||||
# For directories, continue scanning with original path
|
||||
await scan_recursive(entry.path, visited_paths)
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing entry {entry.path}: {e}")
|
||||
except Exception as e:
|
||||
logger.error(f"Error scanning {path}: {e}")
|
||||
|
||||
await scan_recursive(root_path, set())
|
||||
return checkpoints
|
||||
|
||||
async def _process_single_file(self, file_path: str, root_path: str, checkpoints: list):
|
||||
"""Process a single checkpoint file and add to results"""
|
||||
try:
|
||||
result = await self._process_model_file(file_path, root_path)
|
||||
if result:
|
||||
checkpoints.append(result)
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing {file_path}: {e}")
|
||||
return config.base_models_roots
|
||||
50
py/services/checkpoint_service.py
Normal file
50
py/services/checkpoint_service.py
Normal file
@@ -0,0 +1,50 @@
|
||||
import os
|
||||
import logging
|
||||
from typing import Dict, List, Optional
|
||||
|
||||
from .base_model_service import BaseModelService
|
||||
from ..utils.models import CheckpointMetadata
|
||||
from ..config import config
|
||||
from ..utils.routes_common import ModelRouteUtils
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class CheckpointService(BaseModelService):
|
||||
"""Checkpoint-specific service implementation"""
|
||||
|
||||
def __init__(self, scanner):
|
||||
"""Initialize Checkpoint service
|
||||
|
||||
Args:
|
||||
scanner: Checkpoint scanner instance
|
||||
"""
|
||||
super().__init__("checkpoint", scanner, CheckpointMetadata)
|
||||
|
||||
async def format_response(self, checkpoint_data: Dict) -> Dict:
|
||||
"""Format Checkpoint data for API response"""
|
||||
return {
|
||||
"model_name": checkpoint_data["model_name"],
|
||||
"file_name": checkpoint_data["file_name"],
|
||||
"preview_url": config.get_preview_static_url(checkpoint_data.get("preview_url", "")),
|
||||
"preview_nsfw_level": checkpoint_data.get("preview_nsfw_level", 0),
|
||||
"base_model": checkpoint_data.get("base_model", ""),
|
||||
"folder": checkpoint_data["folder"],
|
||||
"sha256": checkpoint_data.get("sha256", ""),
|
||||
"file_path": checkpoint_data["file_path"].replace(os.sep, "/"),
|
||||
"file_size": checkpoint_data.get("size", 0),
|
||||
"modified": checkpoint_data.get("modified", ""),
|
||||
"tags": checkpoint_data.get("tags", []),
|
||||
"from_civitai": checkpoint_data.get("from_civitai", True),
|
||||
"notes": checkpoint_data.get("notes", ""),
|
||||
"model_type": checkpoint_data.get("model_type", "checkpoint"),
|
||||
"favorite": checkpoint_data.get("favorite", False),
|
||||
"civitai": ModelRouteUtils.filter_civitai_data(checkpoint_data.get("civitai", {}), minimal=True)
|
||||
}
|
||||
|
||||
def find_duplicate_hashes(self) -> Dict:
|
||||
"""Find Checkpoints with duplicate SHA256 hashes"""
|
||||
return self.scanner._hash_index.get_duplicate_hashes()
|
||||
|
||||
def find_duplicate_filenames(self) -> Dict:
|
||||
"""Find Checkpoints with conflicting filenames"""
|
||||
return self.scanner._hash_index.get_duplicate_filenames()
|
||||
@@ -1,13 +1,10 @@
|
||||
from datetime import datetime
|
||||
import aiohttp
|
||||
import os
|
||||
import json
|
||||
import logging
|
||||
import asyncio
|
||||
from email.parser import Parser
|
||||
from typing import Optional, Dict, Tuple, List
|
||||
from urllib.parse import unquote
|
||||
from ..utils.models import LoraMetadata
|
||||
from .model_metadata_provider import CivitaiModelMetadataProvider, ModelMetadataProviderManager
|
||||
from .downloader import get_downloader
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@@ -21,6 +18,11 @@ class CivitaiClient:
|
||||
async with cls._lock:
|
||||
if cls._instance is None:
|
||||
cls._instance = cls()
|
||||
|
||||
# Register this client as a metadata provider
|
||||
provider_manager = await ModelMetadataProviderManager.get_instance()
|
||||
provider_manager.register_provider('civitai', CivitaiModelMetadataProvider(cls._instance), True)
|
||||
|
||||
return cls._instance
|
||||
|
||||
def __init__(self):
|
||||
@@ -30,81 +32,9 @@ class CivitaiClient:
|
||||
self._initialized = True
|
||||
|
||||
self.base_url = "https://civitai.com/api/v1"
|
||||
self.headers = {
|
||||
'User-Agent': 'ComfyUI-LoRA-Manager/1.0'
|
||||
}
|
||||
self._session = None
|
||||
self._session_created_at = None
|
||||
# Set default buffer size to 1MB for higher throughput
|
||||
self.chunk_size = 1024 * 1024
|
||||
|
||||
@property
|
||||
async def session(self) -> aiohttp.ClientSession:
|
||||
"""Lazy initialize the session"""
|
||||
if self._session is None:
|
||||
# Optimize TCP connection parameters
|
||||
connector = aiohttp.TCPConnector(
|
||||
ssl=True,
|
||||
limit=3, # Further reduced from 5 to 3
|
||||
ttl_dns_cache=0, # Disabled DNS caching completely
|
||||
force_close=False, # Keep connections for reuse
|
||||
enable_cleanup_closed=True
|
||||
)
|
||||
trust_env = True # Allow using system environment proxy settings
|
||||
# Configure timeout parameters
|
||||
timeout = aiohttp.ClientTimeout(total=None, connect=60, sock_read=60)
|
||||
self._session = aiohttp.ClientSession(
|
||||
connector=connector,
|
||||
trust_env=trust_env,
|
||||
timeout=timeout
|
||||
)
|
||||
self._session_created_at = datetime.now()
|
||||
return self._session
|
||||
|
||||
async def _ensure_fresh_session(self):
|
||||
"""Refresh session if it's been open too long"""
|
||||
if self._session is not None:
|
||||
if not hasattr(self, '_session_created_at') or \
|
||||
(datetime.now() - self._session_created_at).total_seconds() > 300: # 5 minutes
|
||||
await self.close()
|
||||
self._session = None
|
||||
|
||||
return await self.session
|
||||
|
||||
def _parse_content_disposition(self, header: str) -> str:
|
||||
"""Parse filename from content-disposition header"""
|
||||
if not header:
|
||||
return None
|
||||
|
||||
# Handle quoted filenames
|
||||
if 'filename="' in header:
|
||||
start = header.index('filename="') + 10
|
||||
end = header.index('"', start)
|
||||
return unquote(header[start:end])
|
||||
|
||||
# Fallback to original parsing
|
||||
disposition = Parser().parsestr(f'Content-Disposition: {header}')
|
||||
filename = disposition.get_param('filename')
|
||||
if filename:
|
||||
return unquote(filename)
|
||||
return None
|
||||
|
||||
def _get_request_headers(self) -> dict:
|
||||
"""Get request headers with optional API key"""
|
||||
headers = {
|
||||
'User-Agent': 'ComfyUI-LoRA-Manager/1.0',
|
||||
'Content-Type': 'application/json'
|
||||
}
|
||||
|
||||
from .settings_manager import settings
|
||||
api_key = settings.get('civitai_api_key')
|
||||
if (api_key):
|
||||
headers['Authorization'] = f'Bearer {api_key}'
|
||||
|
||||
return headers
|
||||
|
||||
async def _download_file(self, url: str, save_dir: str, default_filename: str, progress_callback=None) -> Tuple[bool, str]:
|
||||
"""Download file with content-disposition support and progress tracking
|
||||
async def download_file(self, url: str, save_dir: str, default_filename: str, progress_callback=None) -> Tuple[bool, str]:
|
||||
"""Download file with resumable downloads and retry mechanism
|
||||
|
||||
Args:
|
||||
url: Download URL
|
||||
@@ -115,115 +45,178 @@ class CivitaiClient:
|
||||
Returns:
|
||||
Tuple[bool, str]: (success, save_path or error message)
|
||||
"""
|
||||
logger.debug(f"Resolving DNS for: {url}")
|
||||
session = await self._ensure_fresh_session()
|
||||
try:
|
||||
headers = self._get_request_headers()
|
||||
|
||||
# Add Range header to allow resumable downloads
|
||||
headers['Accept-Encoding'] = 'identity' # Disable compression for better chunked downloads
|
||||
|
||||
logger.debug(f"Starting download from: {url}")
|
||||
async with session.get(url, headers=headers, allow_redirects=True) as response:
|
||||
if response.status != 200:
|
||||
# Handle 401 unauthorized responses
|
||||
if response.status == 401:
|
||||
logger.warning(f"Unauthorized access to resource: {url} (Status 401)")
|
||||
|
||||
return False, "Invalid or missing CivitAI API key, or early access restriction."
|
||||
|
||||
# Handle other client errors that might be permission-related
|
||||
if response.status == 403:
|
||||
logger.warning(f"Forbidden access to resource: {url} (Status 403)")
|
||||
return False, "Access forbidden: You don't have permission to download this file."
|
||||
|
||||
# Generic error response for other status codes
|
||||
logger.error(f"Download failed for {url} with status {response.status}")
|
||||
return False, f"Download failed with status {response.status}"
|
||||
|
||||
# Get filename from content-disposition header
|
||||
content_disposition = response.headers.get('Content-Disposition')
|
||||
filename = self._parse_content_disposition(content_disposition)
|
||||
if not filename:
|
||||
filename = default_filename
|
||||
|
||||
save_path = os.path.join(save_dir, filename)
|
||||
|
||||
# Get total file size for progress calculation
|
||||
total_size = int(response.headers.get('content-length', 0))
|
||||
current_size = 0
|
||||
last_progress_report_time = datetime.now()
|
||||
|
||||
# Stream download to file with progress updates using larger buffer
|
||||
with open(save_path, 'wb') as f:
|
||||
async for chunk in response.content.iter_chunked(self.chunk_size):
|
||||
if chunk:
|
||||
f.write(chunk)
|
||||
current_size += len(chunk)
|
||||
|
||||
# Limit progress update frequency to reduce overhead
|
||||
now = datetime.now()
|
||||
time_diff = (now - last_progress_report_time).total_seconds()
|
||||
|
||||
if progress_callback and total_size and time_diff >= 0.5:
|
||||
progress = (current_size / total_size) * 100
|
||||
await progress_callback(progress)
|
||||
last_progress_report_time = now
|
||||
|
||||
# Ensure 100% progress is reported
|
||||
if progress_callback:
|
||||
await progress_callback(100)
|
||||
|
||||
return True, save_path
|
||||
|
||||
except aiohttp.ClientError as e:
|
||||
logger.error(f"Network error during download: {e}")
|
||||
return False, f"Network error: {str(e)}"
|
||||
except Exception as e:
|
||||
logger.error(f"Download error: {e}")
|
||||
return False, str(e)
|
||||
downloader = await get_downloader()
|
||||
save_path = os.path.join(save_dir, default_filename)
|
||||
|
||||
# Use unified downloader with CivitAI authentication
|
||||
success, result = await downloader.download_file(
|
||||
url=url,
|
||||
save_path=save_path,
|
||||
progress_callback=progress_callback,
|
||||
use_auth=True, # Enable CivitAI authentication
|
||||
allow_resume=True
|
||||
)
|
||||
|
||||
return success, result
|
||||
|
||||
async def get_model_by_hash(self, model_hash: str) -> Optional[Dict]:
|
||||
try:
|
||||
session = await self._ensure_fresh_session()
|
||||
async with session.get(f"{self.base_url}/model-versions/by-hash/{model_hash}") as response:
|
||||
if response.status == 200:
|
||||
return await response.json()
|
||||
return None
|
||||
downloader = await get_downloader()
|
||||
success, version = await downloader.make_request(
|
||||
'GET',
|
||||
f"{self.base_url}/model-versions/by-hash/{model_hash}",
|
||||
use_auth=True
|
||||
)
|
||||
if success:
|
||||
# Get model ID from version data
|
||||
model_id = version.get('modelId')
|
||||
if model_id:
|
||||
# Fetch additional model metadata
|
||||
success_model, data = await downloader.make_request(
|
||||
'GET',
|
||||
f"{self.base_url}/models/{model_id}",
|
||||
use_auth=True
|
||||
)
|
||||
if success_model:
|
||||
# Enrich version_info with model data
|
||||
version['model']['description'] = data.get("description")
|
||||
version['model']['tags'] = data.get("tags", [])
|
||||
|
||||
# Add creator from model data
|
||||
version['creator'] = data.get("creator")
|
||||
|
||||
return version
|
||||
return None
|
||||
except Exception as e:
|
||||
logger.error(f"API Error: {str(e)}")
|
||||
return None
|
||||
|
||||
async def download_preview_image(self, image_url: str, save_path: str):
|
||||
try:
|
||||
session = await self._ensure_fresh_session()
|
||||
async with session.get(image_url) as response:
|
||||
if response.status == 200:
|
||||
content = await response.read()
|
||||
with open(save_path, 'wb') as f:
|
||||
f.write(content)
|
||||
return True
|
||||
return False
|
||||
downloader = await get_downloader()
|
||||
success, content, headers = await downloader.download_to_memory(
|
||||
image_url,
|
||||
use_auth=False # Preview images don't need auth
|
||||
)
|
||||
if success:
|
||||
# Ensure directory exists
|
||||
os.makedirs(os.path.dirname(save_path), exist_ok=True)
|
||||
with open(save_path, 'wb') as f:
|
||||
f.write(content)
|
||||
return True
|
||||
return False
|
||||
except Exception as e:
|
||||
print(f"Download Error: {str(e)}")
|
||||
logger.error(f"Download Error: {str(e)}")
|
||||
return False
|
||||
|
||||
async def get_model_versions(self, model_id: str) -> List[Dict]:
|
||||
"""Get all versions of a model with local availability info"""
|
||||
try:
|
||||
session = await self._ensure_fresh_session() # Use fresh session
|
||||
async with session.get(f"{self.base_url}/models/{model_id}") as response:
|
||||
if response.status != 200:
|
||||
return None
|
||||
data = await response.json()
|
||||
downloader = await get_downloader()
|
||||
success, result = await downloader.make_request(
|
||||
'GET',
|
||||
f"{self.base_url}/models/{model_id}",
|
||||
use_auth=True
|
||||
)
|
||||
if success:
|
||||
# Also return model type along with versions
|
||||
return {
|
||||
'modelVersions': data.get('modelVersions', []),
|
||||
'type': data.get('type', '')
|
||||
'modelVersions': result.get('modelVersions', []),
|
||||
'type': result.get('type', '')
|
||||
}
|
||||
return None
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching model versions: {e}")
|
||||
return None
|
||||
|
||||
async def get_model_version(self, model_id: int = None, version_id: int = None) -> Optional[Dict]:
|
||||
"""Get specific model version with additional metadata
|
||||
|
||||
Args:
|
||||
model_id: The Civitai model ID (optional if version_id is provided)
|
||||
version_id: Optional specific version ID to retrieve
|
||||
|
||||
Returns:
|
||||
Optional[Dict]: The model version data with additional fields or None if not found
|
||||
"""
|
||||
try:
|
||||
downloader = await get_downloader()
|
||||
|
||||
# Case 1: Only version_id is provided
|
||||
if model_id is None and version_id is not None:
|
||||
# First get the version info to extract model_id
|
||||
success, version = await downloader.make_request(
|
||||
'GET',
|
||||
f"{self.base_url}/model-versions/{version_id}",
|
||||
use_auth=True
|
||||
)
|
||||
if not success:
|
||||
return None
|
||||
|
||||
model_id = version.get('modelId')
|
||||
if not model_id:
|
||||
logger.error(f"No modelId found in version {version_id}")
|
||||
return None
|
||||
|
||||
# Now get the model data for additional metadata
|
||||
success, model_data = await downloader.make_request(
|
||||
'GET',
|
||||
f"{self.base_url}/models/{model_id}",
|
||||
use_auth=True
|
||||
)
|
||||
if success:
|
||||
# Enrich version with model data
|
||||
version['model']['description'] = model_data.get("description")
|
||||
version['model']['tags'] = model_data.get("tags", [])
|
||||
version['creator'] = model_data.get("creator")
|
||||
|
||||
return version
|
||||
|
||||
# Case 2: model_id is provided (with or without version_id)
|
||||
elif model_id is not None:
|
||||
# Step 1: Get model data to find version_id if not provided and get additional metadata
|
||||
success, data = await downloader.make_request(
|
||||
'GET',
|
||||
f"{self.base_url}/models/{model_id}",
|
||||
use_auth=True
|
||||
)
|
||||
if not success:
|
||||
return None
|
||||
|
||||
model_versions = data.get('modelVersions', [])
|
||||
|
||||
# Step 2: Determine the version_id to use
|
||||
target_version_id = version_id
|
||||
if target_version_id is None:
|
||||
target_version_id = model_versions[0].get('id')
|
||||
|
||||
# Step 3: Get detailed version info using the version_id
|
||||
success, version = await downloader.make_request(
|
||||
'GET',
|
||||
f"{self.base_url}/model-versions/{target_version_id}",
|
||||
use_auth=True
|
||||
)
|
||||
if not success:
|
||||
return None
|
||||
|
||||
# Step 4: Enrich version_info with model data
|
||||
# Add description and tags from model data
|
||||
version['model']['description'] = data.get("description")
|
||||
version['model']['tags'] = data.get("tags", [])
|
||||
|
||||
# Add creator from model data
|
||||
version['creator'] = data.get("creator")
|
||||
|
||||
return version
|
||||
|
||||
# Case 3: Neither model_id nor version_id provided
|
||||
else:
|
||||
logger.error("Either model_id or version_id must be provided")
|
||||
return None
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching model version: {e}")
|
||||
return None
|
||||
|
||||
async def get_model_version_info(self, version_id: str) -> Tuple[Optional[Dict], Optional[str]]:
|
||||
"""Fetch model version metadata from Civitai
|
||||
@@ -237,30 +230,29 @@ class CivitaiClient:
|
||||
- An error message if there was an error, or None on success
|
||||
"""
|
||||
try:
|
||||
session = await self._ensure_fresh_session()
|
||||
downloader = await get_downloader()
|
||||
url = f"{self.base_url}/model-versions/{version_id}"
|
||||
headers = self._get_request_headers()
|
||||
|
||||
logger.debug(f"Resolving DNS for model version info: {url}")
|
||||
async with session.get(url, headers=headers) as response:
|
||||
if response.status == 200:
|
||||
logger.debug(f"Successfully fetched model version info for: {version_id}")
|
||||
return await response.json(), None
|
||||
|
||||
# Handle specific error cases
|
||||
if response.status == 404:
|
||||
# Try to parse the error message
|
||||
try:
|
||||
error_data = await response.json()
|
||||
error_msg = error_data.get('error', f"Model not found (status 404)")
|
||||
logger.warning(f"Model version not found: {version_id} - {error_msg}")
|
||||
return None, error_msg
|
||||
except:
|
||||
return None, "Model not found (status 404)"
|
||||
|
||||
# Other error cases
|
||||
logger.error(f"Failed to fetch model info for {version_id} (status {response.status})")
|
||||
return None, f"Failed to fetch model info (status {response.status})"
|
||||
success, result = await downloader.make_request(
|
||||
'GET',
|
||||
url,
|
||||
use_auth=True
|
||||
)
|
||||
|
||||
if success:
|
||||
logger.debug(f"Successfully fetched model version info for: {version_id}")
|
||||
return result, None
|
||||
|
||||
# Handle specific error cases
|
||||
if "404" in str(result):
|
||||
error_msg = f"Model not found (status 404)"
|
||||
logger.warning(f"Model version not found: {version_id} - {error_msg}")
|
||||
return None, error_msg
|
||||
|
||||
# Other error cases
|
||||
logger.error(f"Failed to fetch model info for {version_id}: {result}")
|
||||
return None, str(result)
|
||||
except Exception as e:
|
||||
error_msg = f"Error fetching model version info: {e}"
|
||||
logger.error(error_msg)
|
||||
@@ -275,74 +267,80 @@ class CivitaiClient:
|
||||
Returns:
|
||||
Tuple[Optional[Dict], int]: A tuple containing:
|
||||
- A dictionary with model metadata or None if not found
|
||||
- The HTTP status code from the request
|
||||
- The HTTP status code from the request (0 for exceptions)
|
||||
"""
|
||||
try:
|
||||
session = await self._ensure_fresh_session()
|
||||
headers = self._get_request_headers()
|
||||
downloader = await get_downloader()
|
||||
url = f"{self.base_url}/models/{model_id}"
|
||||
|
||||
async with session.get(url, headers=headers) as response:
|
||||
status_code = response.status
|
||||
|
||||
if status_code != 200:
|
||||
logger.warning(f"Failed to fetch model metadata: Status {status_code}")
|
||||
return None, status_code
|
||||
|
||||
data = await response.json()
|
||||
|
||||
# Extract relevant metadata
|
||||
metadata = {
|
||||
"description": data.get("description") or "No model description available",
|
||||
"tags": data.get("tags", []),
|
||||
"creator": {
|
||||
"username": data.get("creator", {}).get("username"),
|
||||
"image": data.get("creator", {}).get("image")
|
||||
}
|
||||
success, result = await downloader.make_request(
|
||||
'GET',
|
||||
url,
|
||||
use_auth=True
|
||||
)
|
||||
|
||||
if not success:
|
||||
# Try to extract status code from error message
|
||||
status_code = 0
|
||||
if "404" in str(result):
|
||||
status_code = 404
|
||||
elif "401" in str(result):
|
||||
status_code = 401
|
||||
elif "403" in str(result):
|
||||
status_code = 403
|
||||
logger.warning(f"Failed to fetch model metadata: {result}")
|
||||
return None, status_code
|
||||
|
||||
# Extract relevant metadata
|
||||
metadata = {
|
||||
"description": result.get("description") or "No model description available",
|
||||
"tags": result.get("tags", []),
|
||||
"creator": {
|
||||
"username": result.get("creator", {}).get("username"),
|
||||
"image": result.get("creator", {}).get("image")
|
||||
}
|
||||
|
||||
if metadata["description"] or metadata["tags"] or metadata["creator"]["username"]:
|
||||
return metadata, status_code
|
||||
else:
|
||||
logger.warning(f"No metadata found for model {model_id}")
|
||||
return None, status_code
|
||||
}
|
||||
|
||||
if metadata["description"] or metadata["tags"] or metadata["creator"]["username"]:
|
||||
return metadata, 200
|
||||
else:
|
||||
logger.warning(f"No metadata found for model {model_id}")
|
||||
return None, 200
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching model metadata: {e}", exc_info=True)
|
||||
return None, 0
|
||||
|
||||
# Keep old method for backward compatibility, delegating to the new one
|
||||
async def get_model_description(self, model_id: str) -> Optional[str]:
|
||||
"""Fetch the model description from Civitai API (Legacy method)"""
|
||||
metadata, _ = await self.get_model_metadata(model_id)
|
||||
return metadata.get("description") if metadata else None
|
||||
|
||||
async def close(self):
|
||||
"""Close the session if it exists"""
|
||||
if self._session is not None:
|
||||
await self._session.close()
|
||||
self._session = None
|
||||
|
||||
async def _get_hash_from_civitai(self, model_version_id: str) -> Optional[str]:
|
||||
"""Get hash from Civitai API"""
|
||||
async def get_image_info(self, image_id: str) -> Optional[Dict]:
|
||||
"""Fetch image information from Civitai API
|
||||
|
||||
Args:
|
||||
image_id: The Civitai image ID
|
||||
|
||||
Returns:
|
||||
Optional[Dict]: The image data or None if not found
|
||||
"""
|
||||
try:
|
||||
session = await self._ensure_fresh_session()
|
||||
if not session:
|
||||
downloader = await get_downloader()
|
||||
url = f"{self.base_url}/images?imageId={image_id}&nsfw=X"
|
||||
|
||||
logger.debug(f"Fetching image info for ID: {image_id}")
|
||||
success, result = await downloader.make_request(
|
||||
'GET',
|
||||
url,
|
||||
use_auth=True
|
||||
)
|
||||
|
||||
if success:
|
||||
if result and "items" in result and len(result["items"]) > 0:
|
||||
logger.debug(f"Successfully fetched image info for ID: {image_id}")
|
||||
return result["items"][0]
|
||||
logger.warning(f"No image found with ID: {image_id}")
|
||||
return None
|
||||
|
||||
version_info = await session.get(f"{self.base_url}/model-versions/{model_version_id}")
|
||||
|
||||
if not version_info or not version_info.json().get('files'):
|
||||
return None
|
||||
|
||||
# Get hash from the first file
|
||||
for file_info in version_info.json().get('files', []):
|
||||
if file_info.get('hashes', {}).get('SHA256'):
|
||||
# Convert hash to lowercase to standardize
|
||||
hash_value = file_info['hashes']['SHA256'].lower()
|
||||
return hash_value
|
||||
|
||||
logger.error(f"Failed to fetch image info for ID: {image_id}: {result}")
|
||||
return None
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting hash from Civitai: {e}")
|
||||
error_msg = f"Error fetching image info: {e}"
|
||||
logger.error(error_msg)
|
||||
return None
|
||||
|
||||
@@ -1,13 +1,17 @@
|
||||
import logging
|
||||
import os
|
||||
import json
|
||||
import asyncio
|
||||
from typing import Optional, Dict, Any
|
||||
from .civitai_client import CivitaiClient
|
||||
from ..utils.models import LoraMetadata, CheckpointMetadata
|
||||
from ..utils.constants import CARD_PREVIEW_WIDTH
|
||||
from collections import OrderedDict
|
||||
import uuid
|
||||
from typing import Dict
|
||||
from ..utils.models import LoraMetadata, CheckpointMetadata, EmbeddingMetadata
|
||||
from ..utils.constants import CARD_PREVIEW_WIDTH, VALID_LORA_TYPES, CIVITAI_MODEL_TAGS
|
||||
from ..utils.exif_utils import ExifUtils
|
||||
from ..utils.metadata_manager import MetadataManager
|
||||
from .service_registry import ServiceRegistry
|
||||
from .settings_manager import settings
|
||||
from .metadata_service import get_default_metadata_provider
|
||||
from .downloader import get_downloader
|
||||
|
||||
# Download to temporary file first
|
||||
import tempfile
|
||||
@@ -32,21 +36,10 @@ class DownloadManager:
|
||||
return
|
||||
self._initialized = True
|
||||
|
||||
self._civitai_client = None # Will be lazily initialized
|
||||
|
||||
async def _get_civitai_client(self):
|
||||
"""Lazily initialize CivitaiClient from registry"""
|
||||
if self._civitai_client is None:
|
||||
self._civitai_client = await ServiceRegistry.get_civitai_client()
|
||||
return self._civitai_client
|
||||
|
||||
async def _get_lora_monitor(self):
|
||||
"""Get the lora file monitor from registry"""
|
||||
return await ServiceRegistry.get_lora_monitor()
|
||||
|
||||
async def _get_checkpoint_monitor(self):
|
||||
"""Get the checkpoint file monitor from registry"""
|
||||
return await ServiceRegistry.get_checkpoint_monitor()
|
||||
# Add download management
|
||||
self._active_downloads = OrderedDict() # download_id -> download_info
|
||||
self._download_semaphore = asyncio.Semaphore(5) # Limit concurrent downloads
|
||||
self._download_tasks = {} # download_id -> asyncio.Task
|
||||
|
||||
async def _get_lora_scanner(self):
|
||||
"""Get the lora scanner from registry"""
|
||||
@@ -55,56 +48,225 @@ class DownloadManager:
|
||||
async def _get_checkpoint_scanner(self):
|
||||
"""Get the checkpoint scanner from registry"""
|
||||
return await ServiceRegistry.get_checkpoint_scanner()
|
||||
|
||||
async def download_from_civitai(self, download_url: str = None, model_hash: str = None,
|
||||
model_version_id: str = None, save_dir: str = None,
|
||||
relative_path: str = '', progress_callback=None,
|
||||
model_type: str = "lora") -> Dict:
|
||||
"""Download model from Civitai
|
||||
|
||||
async def download_from_civitai(self, model_id: int = None, model_version_id: int = None,
|
||||
save_dir: str = None, relative_path: str = '',
|
||||
progress_callback=None, use_default_paths: bool = False,
|
||||
download_id: str = None, source: str = None) -> Dict:
|
||||
"""Download model from Civitai with task tracking and concurrency control
|
||||
|
||||
Args:
|
||||
download_url: Direct download URL for the model
|
||||
model_hash: SHA256 hash of the model
|
||||
model_version_id: Civitai model version ID
|
||||
save_dir: Directory to save the model to
|
||||
model_id: Civitai model ID (optional if model_version_id is provided)
|
||||
model_version_id: Civitai model version ID (optional if model_id is provided)
|
||||
save_dir: Directory to save the model
|
||||
relative_path: Relative path within save_dir
|
||||
progress_callback: Callback function for progress updates
|
||||
model_type: Type of model ('lora' or 'checkpoint')
|
||||
use_default_paths: Flag to use default paths
|
||||
download_id: Unique identifier for this download task
|
||||
source: Optional source parameter to specify metadata provider
|
||||
|
||||
Returns:
|
||||
Dict with download result
|
||||
"""
|
||||
# Validate that at least one identifier is provided
|
||||
if not model_id and not model_version_id:
|
||||
return {'success': False, 'error': 'Either model_id or model_version_id must be provided'}
|
||||
|
||||
# Use provided download_id or generate new one
|
||||
task_id = download_id or str(uuid.uuid4())
|
||||
|
||||
# Register download task in tracking dict
|
||||
self._active_downloads[task_id] = {
|
||||
'model_id': model_id,
|
||||
'model_version_id': model_version_id,
|
||||
'progress': 0,
|
||||
'status': 'queued'
|
||||
}
|
||||
|
||||
# Create tracking task
|
||||
download_task = asyncio.create_task(
|
||||
self._download_with_semaphore(
|
||||
task_id, model_id, model_version_id, save_dir,
|
||||
relative_path, progress_callback, use_default_paths, source
|
||||
)
|
||||
)
|
||||
|
||||
# Store task for tracking and cancellation
|
||||
self._download_tasks[task_id] = download_task
|
||||
|
||||
try:
|
||||
# Wait for download to complete
|
||||
result = await download_task
|
||||
result['download_id'] = task_id # Include download_id in result
|
||||
return result
|
||||
except asyncio.CancelledError:
|
||||
return {'success': False, 'error': 'Download was cancelled', 'download_id': task_id}
|
||||
finally:
|
||||
# Clean up task reference
|
||||
if task_id in self._download_tasks:
|
||||
del self._download_tasks[task_id]
|
||||
|
||||
async def _download_with_semaphore(self, task_id: str, model_id: int, model_version_id: int,
|
||||
save_dir: str, relative_path: str,
|
||||
progress_callback=None, use_default_paths: bool = False,
|
||||
source: str = None):
|
||||
"""Execute download with semaphore to limit concurrency"""
|
||||
# Update status to waiting
|
||||
if task_id in self._active_downloads:
|
||||
self._active_downloads[task_id]['status'] = 'waiting'
|
||||
|
||||
# Wrap progress callback to track progress in active_downloads
|
||||
original_callback = progress_callback
|
||||
async def tracking_callback(progress):
|
||||
if task_id in self._active_downloads:
|
||||
self._active_downloads[task_id]['progress'] = progress
|
||||
if original_callback:
|
||||
await original_callback(progress)
|
||||
|
||||
# Acquire semaphore to limit concurrent downloads
|
||||
try:
|
||||
async with self._download_semaphore:
|
||||
# Update status to downloading
|
||||
if task_id in self._active_downloads:
|
||||
self._active_downloads[task_id]['status'] = 'downloading'
|
||||
|
||||
# Use original download implementation
|
||||
try:
|
||||
# Check for cancellation before starting
|
||||
if asyncio.current_task().cancelled():
|
||||
raise asyncio.CancelledError()
|
||||
|
||||
result = await self._execute_original_download(
|
||||
model_id, model_version_id, save_dir,
|
||||
relative_path, tracking_callback, use_default_paths,
|
||||
task_id, source
|
||||
)
|
||||
|
||||
# Update status based on result
|
||||
if task_id in self._active_downloads:
|
||||
self._active_downloads[task_id]['status'] = 'completed' if result['success'] else 'failed'
|
||||
if not result['success']:
|
||||
self._active_downloads[task_id]['error'] = result.get('error', 'Unknown error')
|
||||
|
||||
return result
|
||||
except asyncio.CancelledError:
|
||||
# Handle cancellation
|
||||
if task_id in self._active_downloads:
|
||||
self._active_downloads[task_id]['status'] = 'cancelled'
|
||||
logger.info(f"Download cancelled for task {task_id}")
|
||||
raise
|
||||
except Exception as e:
|
||||
# Handle other errors
|
||||
logger.error(f"Download error for task {task_id}: {str(e)}", exc_info=True)
|
||||
if task_id in self._active_downloads:
|
||||
self._active_downloads[task_id]['status'] = 'failed'
|
||||
self._active_downloads[task_id]['error'] = str(e)
|
||||
return {'success': False, 'error': str(e)}
|
||||
finally:
|
||||
# Schedule cleanup of download record after delay
|
||||
asyncio.create_task(self._cleanup_download_record(task_id))
|
||||
|
||||
async def _cleanup_download_record(self, task_id: str):
|
||||
"""Keep completed downloads in history for a short time"""
|
||||
await asyncio.sleep(600) # Keep for 10 minutes
|
||||
if task_id in self._active_downloads:
|
||||
del self._active_downloads[task_id]
|
||||
|
||||
async def _execute_original_download(self, model_id, model_version_id, save_dir,
|
||||
relative_path, progress_callback, use_default_paths,
|
||||
download_id=None, source=None):
|
||||
"""Wrapper for original download_from_civitai implementation"""
|
||||
try:
|
||||
# Check if model version already exists in library
|
||||
if model_version_id is not None:
|
||||
# Check both scanners
|
||||
lora_scanner = await self._get_lora_scanner()
|
||||
checkpoint_scanner = await self._get_checkpoint_scanner()
|
||||
embedding_scanner = await ServiceRegistry.get_embedding_scanner()
|
||||
|
||||
# Check lora scanner first
|
||||
if await lora_scanner.check_model_version_exists(model_version_id):
|
||||
return {'success': False, 'error': 'Model version already exists in lora library'}
|
||||
|
||||
# Check checkpoint scanner
|
||||
if await checkpoint_scanner.check_model_version_exists(model_version_id):
|
||||
return {'success': False, 'error': 'Model version already exists in checkpoint library'}
|
||||
|
||||
# Check embedding scanner
|
||||
if await embedding_scanner.check_model_version_exists(model_version_id):
|
||||
return {'success': False, 'error': 'Model version already exists in embedding library'}
|
||||
|
||||
# Get metadata provider based on source parameter
|
||||
if source == 'civarchive':
|
||||
from .metadata_service import get_metadata_provider
|
||||
metadata_provider = await get_metadata_provider('civarchive')
|
||||
else:
|
||||
metadata_provider = await get_default_metadata_provider()
|
||||
|
||||
# Get version info based on the provided identifier
|
||||
version_info = await metadata_provider.get_model_version(model_id, model_version_id)
|
||||
|
||||
if not version_info:
|
||||
return {'success': False, 'error': 'Failed to fetch model metadata'}
|
||||
|
||||
model_type_from_info = version_info.get('model', {}).get('type', '').lower()
|
||||
if model_type_from_info == 'checkpoint':
|
||||
model_type = 'checkpoint'
|
||||
elif model_type_from_info in VALID_LORA_TYPES:
|
||||
model_type = 'lora'
|
||||
elif model_type_from_info == 'textualinversion':
|
||||
model_type = 'embedding'
|
||||
else:
|
||||
return {'success': False, 'error': f'Model type "{model_type_from_info}" is not supported for download'}
|
||||
|
||||
# Case 2: model_version_id was None, check after getting version_info
|
||||
if model_version_id is None:
|
||||
version_id = version_info.get('id')
|
||||
|
||||
if model_type == 'lora':
|
||||
# Check lora scanner
|
||||
lora_scanner = await self._get_lora_scanner()
|
||||
if await lora_scanner.check_model_version_exists(version_id):
|
||||
return {'success': False, 'error': 'Model version already exists in lora library'}
|
||||
elif model_type == 'checkpoint':
|
||||
# Check checkpoint scanner
|
||||
checkpoint_scanner = await self._get_checkpoint_scanner()
|
||||
if await checkpoint_scanner.check_model_version_exists(version_id):
|
||||
return {'success': False, 'error': 'Model version already exists in checkpoint library'}
|
||||
elif model_type == 'embedding':
|
||||
# Embeddings are not checked in scanners, but we can still check if it exists
|
||||
embedding_scanner = await ServiceRegistry.get_embedding_scanner()
|
||||
if await embedding_scanner.check_model_version_exists(version_id):
|
||||
return {'success': False, 'error': 'Model version already exists in embedding library'}
|
||||
|
||||
# Handle use_default_paths
|
||||
if use_default_paths:
|
||||
# Set save_dir based on model type
|
||||
if model_type == 'checkpoint':
|
||||
default_path = settings.get('default_checkpoint_root')
|
||||
if not default_path:
|
||||
return {'success': False, 'error': 'Default checkpoint root path not set in settings'}
|
||||
save_dir = default_path
|
||||
elif model_type == 'lora':
|
||||
default_path = settings.get('default_lora_root')
|
||||
if not default_path:
|
||||
return {'success': False, 'error': 'Default lora root path not set in settings'}
|
||||
save_dir = default_path
|
||||
elif model_type == 'embedding':
|
||||
default_path = settings.get('default_embedding_root')
|
||||
if not default_path:
|
||||
return {'success': False, 'error': 'Default embedding root path not set in settings'}
|
||||
save_dir = default_path
|
||||
|
||||
# Calculate relative path using template
|
||||
relative_path = self._calculate_relative_path(version_info, model_type)
|
||||
|
||||
# Update save directory with relative path if provided
|
||||
if relative_path:
|
||||
save_dir = os.path.join(save_dir, relative_path)
|
||||
# Create directory if it doesn't exist
|
||||
os.makedirs(save_dir, exist_ok=True)
|
||||
|
||||
# Get civitai client
|
||||
civitai_client = await self._get_civitai_client()
|
||||
|
||||
# Get version info based on the provided identifier
|
||||
version_info = None
|
||||
error_msg = None
|
||||
|
||||
if model_hash:
|
||||
# Get model by hash
|
||||
version_info = await civitai_client.get_model_by_hash(model_hash)
|
||||
elif model_version_id:
|
||||
# Use model version ID directly
|
||||
version_info, error_msg = await civitai_client.get_model_version_info(model_version_id)
|
||||
elif download_url:
|
||||
# Extract version ID from download URL
|
||||
version_id = download_url.split('/')[-1]
|
||||
version_info, error_msg = await civitai_client.get_model_version_info(version_id)
|
||||
|
||||
|
||||
if not version_info:
|
||||
if error_msg and "model not found" in error_msg.lower():
|
||||
return {'success': False, 'error': f'Model not found on Civitai: {error_msg}'}
|
||||
return {'success': False, 'error': error_msg or 'Failed to fetch model metadata'}
|
||||
|
||||
# Check if this is an early access model
|
||||
if version_info.get('earlyAccessEndsAt'):
|
||||
early_access_date = version_info.get('earlyAccessEndsAt', '')
|
||||
@@ -113,9 +275,9 @@ class DownloadManager:
|
||||
from datetime import datetime
|
||||
date_obj = datetime.fromisoformat(early_access_date.replace('Z', '+00:00'))
|
||||
formatted_date = date_obj.strftime('%Y-%m-%d')
|
||||
early_access_msg = f"This model requires early access payment (until {formatted_date}). "
|
||||
early_access_msg = f"This model requires payment (until {formatted_date}). "
|
||||
except:
|
||||
early_access_msg = "This model requires early access payment. "
|
||||
early_access_msg = "This model requires payment. "
|
||||
|
||||
early_access_msg += "Please ensure you have purchased early access and are logged in to Civitai."
|
||||
logger.warning(f"Early access model detected: {version_info.get('name', 'Unknown')}")
|
||||
@@ -132,33 +294,23 @@ class DownloadManager:
|
||||
file_info = next((f for f in version_info.get('files', []) if f.get('primary')), None)
|
||||
if not file_info:
|
||||
return {'success': False, 'error': 'No primary file found in metadata'}
|
||||
if not file_info.get('downloadUrl'):
|
||||
return {'success': False, 'error': 'No download URL found for primary file'}
|
||||
|
||||
# 3. Prepare download
|
||||
file_name = file_info['name']
|
||||
save_path = os.path.join(save_dir, file_name)
|
||||
|
||||
# 4. Notify file monitor - use normalized path and file size
|
||||
# file monitor is despreted, so we don't need to use it
|
||||
|
||||
# 5. Prepare metadata based on model type
|
||||
if model_type == "checkpoint":
|
||||
metadata = CheckpointMetadata.from_civitai_info(version_info, file_info, save_path)
|
||||
logger.info(f"Creating CheckpointMetadata for {file_name}")
|
||||
else:
|
||||
elif model_type == "lora":
|
||||
metadata = LoraMetadata.from_civitai_info(version_info, file_info, save_path)
|
||||
logger.info(f"Creating LoraMetadata for {file_name}")
|
||||
|
||||
# 5.1 Get and update model tags, description and creator info
|
||||
model_id = version_info.get('modelId')
|
||||
if model_id:
|
||||
model_metadata, _ = await civitai_client.get_model_metadata(str(model_id))
|
||||
if model_metadata:
|
||||
if model_metadata.get("tags"):
|
||||
metadata.tags = model_metadata.get("tags", [])
|
||||
if model_metadata.get("description"):
|
||||
metadata.modelDescription = model_metadata.get("description", "")
|
||||
if model_metadata.get("creator"):
|
||||
metadata.civitai["creator"] = model_metadata.get("creator")
|
||||
elif model_type == "embedding":
|
||||
metadata = EmbeddingMetadata.from_civitai_info(version_info, file_info, save_path)
|
||||
logger.info(f"Creating EmbeddingMetadata for {file_name}")
|
||||
|
||||
# 6. Start download process
|
||||
result = await self._execute_download(
|
||||
@@ -168,9 +320,14 @@ class DownloadManager:
|
||||
version_info=version_info,
|
||||
relative_path=relative_path,
|
||||
progress_callback=progress_callback,
|
||||
model_type=model_type
|
||||
model_type=model_type,
|
||||
download_id=download_id
|
||||
)
|
||||
|
||||
# If early_access_msg exists and download failed, replace error message
|
||||
if 'early_access_msg' in locals() and not result.get('success', False):
|
||||
result['error'] = early_access_msg
|
||||
|
||||
return result
|
||||
|
||||
except Exception as e:
|
||||
@@ -181,15 +338,98 @@ class DownloadManager:
|
||||
return {'success': False, 'error': f"Early access restriction: {str(e)}. Please ensure you have purchased early access and are logged in to Civitai."}
|
||||
return {'success': False, 'error': str(e)}
|
||||
|
||||
def _calculate_relative_path(self, version_info: Dict, model_type: str = 'lora') -> str:
|
||||
"""Calculate relative path using template from settings
|
||||
|
||||
Args:
|
||||
version_info: Version info from Civitai API
|
||||
model_type: Type of model ('lora', 'checkpoint', 'embedding')
|
||||
|
||||
Returns:
|
||||
Relative path string
|
||||
"""
|
||||
# Get path template from settings for specific model type
|
||||
path_template = settings.get_download_path_template(model_type)
|
||||
|
||||
# If template is empty, return empty path (flat structure)
|
||||
if not path_template:
|
||||
return ''
|
||||
|
||||
# Get base model name
|
||||
base_model = version_info.get('baseModel', '')
|
||||
|
||||
# Get author from creator data
|
||||
creator_info = version_info.get('creator')
|
||||
if creator_info and isinstance(creator_info, dict):
|
||||
author = creator_info.get('username') or 'Anonymous'
|
||||
else:
|
||||
author = 'Anonymous'
|
||||
|
||||
# Apply mapping if available
|
||||
base_model_mappings = settings.get('base_model_path_mappings', {})
|
||||
mapped_base_model = base_model_mappings.get(base_model, base_model)
|
||||
|
||||
# Get model tags
|
||||
model_tags = version_info.get('model', {}).get('tags', [])
|
||||
|
||||
# Find the first Civitai model tag that exists in model_tags
|
||||
first_tag = ''
|
||||
for civitai_tag in CIVITAI_MODEL_TAGS:
|
||||
if civitai_tag in model_tags:
|
||||
first_tag = civitai_tag
|
||||
break
|
||||
|
||||
# If no Civitai model tag found, fallback to first tag
|
||||
if not first_tag and model_tags:
|
||||
first_tag = model_tags[0]
|
||||
|
||||
# Format the template with available data
|
||||
formatted_path = path_template
|
||||
formatted_path = formatted_path.replace('{base_model}', mapped_base_model)
|
||||
formatted_path = formatted_path.replace('{first_tag}', first_tag)
|
||||
formatted_path = formatted_path.replace('{author}', author)
|
||||
|
||||
return formatted_path
|
||||
|
||||
async def _execute_download(self, download_url: str, save_dir: str,
|
||||
metadata, version_info: Dict,
|
||||
relative_path: str, progress_callback=None,
|
||||
model_type: str = "lora") -> Dict:
|
||||
metadata, version_info: Dict,
|
||||
relative_path: str, progress_callback=None,
|
||||
model_type: str = "lora", download_id: str = None) -> Dict:
|
||||
"""Execute the actual download process including preview images and model files"""
|
||||
try:
|
||||
civitai_client = await self._get_civitai_client()
|
||||
save_path = metadata.file_path
|
||||
# Extract original filename details
|
||||
original_filename = os.path.basename(metadata.file_path)
|
||||
base_name, extension = os.path.splitext(original_filename)
|
||||
|
||||
# Check for filename conflicts and generate unique filename if needed
|
||||
# Use the hash from metadata for conflict resolution
|
||||
def hash_provider():
|
||||
return metadata.sha256
|
||||
|
||||
unique_filename = metadata.generate_unique_filename(
|
||||
save_dir,
|
||||
base_name,
|
||||
extension,
|
||||
hash_provider=hash_provider
|
||||
)
|
||||
|
||||
# Update paths if filename changed
|
||||
if unique_filename != original_filename:
|
||||
logger.info(f"Filename conflict detected. Changing '{original_filename}' to '{unique_filename}'")
|
||||
save_path = os.path.join(save_dir, unique_filename)
|
||||
# Update metadata with new file path and name
|
||||
metadata.file_path = save_path.replace(os.sep, '/')
|
||||
metadata.file_name = os.path.splitext(unique_filename)[0]
|
||||
else:
|
||||
save_path = metadata.file_path
|
||||
|
||||
part_path = save_path + '.part'
|
||||
metadata_path = os.path.splitext(save_path)[0] + '.metadata.json'
|
||||
|
||||
# Store file paths in active_downloads for potential cleanup
|
||||
if download_id and download_id in self._active_downloads:
|
||||
self._active_downloads[download_id]['file_path'] = save_path
|
||||
self._active_downloads[download_id]['part_path'] = part_path
|
||||
|
||||
# Download preview image if available
|
||||
images = version_info.get('images', [])
|
||||
@@ -206,19 +446,31 @@ class DownloadManager:
|
||||
preview_ext = '.mp4'
|
||||
preview_path = os.path.splitext(save_path)[0] + preview_ext
|
||||
|
||||
# Download video directly
|
||||
if await civitai_client.download_preview_image(images[0]['url'], preview_path):
|
||||
# Download video directly using downloader
|
||||
downloader = await get_downloader()
|
||||
success, result = await downloader.download_file(
|
||||
images[0]['url'],
|
||||
preview_path,
|
||||
use_auth=False # Preview images typically don't need auth
|
||||
)
|
||||
if success:
|
||||
metadata.preview_url = preview_path.replace(os.sep, '/')
|
||||
metadata.preview_nsfw_level = images[0].get('nsfwLevel', 0)
|
||||
with open(metadata_path, 'w', encoding='utf-8') as f:
|
||||
json.dump(metadata.to_dict(), f, indent=2, ensure_ascii=False)
|
||||
else:
|
||||
# For images, use WebP format for better performance
|
||||
with tempfile.NamedTemporaryFile(suffix='.png', delete=False) as temp_file:
|
||||
temp_path = temp_file.name
|
||||
|
||||
# Download the original image to temp path
|
||||
if await civitai_client.download_preview_image(images[0]['url'], temp_path):
|
||||
# Download the original image to temp path using downloader
|
||||
downloader = await get_downloader()
|
||||
success, content, headers = await downloader.download_to_memory(
|
||||
images[0]['url'],
|
||||
use_auth=False
|
||||
)
|
||||
if success:
|
||||
# Save to temp file
|
||||
with open(temp_path, 'wb') as f:
|
||||
f.write(content)
|
||||
# Optimize and convert to WebP
|
||||
preview_path = os.path.splitext(save_path)[0] + '.webp'
|
||||
|
||||
@@ -238,8 +490,6 @@ class DownloadManager:
|
||||
# Update metadata
|
||||
metadata.preview_url = preview_path.replace(os.sep, '/')
|
||||
metadata.preview_nsfw_level = images[0].get('nsfwLevel', 0)
|
||||
with open(metadata_path, 'w', encoding='utf-8') as f:
|
||||
json.dump(metadata.to_dict(), f, indent=2, ensure_ascii=False)
|
||||
|
||||
# Remove temporary file
|
||||
try:
|
||||
@@ -251,47 +501,58 @@ class DownloadManager:
|
||||
if progress_callback:
|
||||
await progress_callback(3) # 3% progress after preview download
|
||||
|
||||
# Download model file with progress tracking
|
||||
success, result = await civitai_client._download_file(
|
||||
# Download model file with progress tracking using downloader
|
||||
downloader = await get_downloader()
|
||||
# Determine if the download URL is from Civitai
|
||||
use_auth = download_url.startswith("https://civitai.com/api/download/")
|
||||
success, result = await downloader.download_file(
|
||||
download_url,
|
||||
save_dir,
|
||||
os.path.basename(save_path),
|
||||
progress_callback=lambda p: self._handle_download_progress(p, progress_callback)
|
||||
save_path, # Use full path instead of separate dir and filename
|
||||
progress_callback=lambda p: self._handle_download_progress(p, progress_callback),
|
||||
use_auth=use_auth # Only use authentication for Civitai downloads
|
||||
)
|
||||
|
||||
if not success:
|
||||
# Clean up files on failure
|
||||
for path in [save_path, metadata_path, metadata.preview_url]:
|
||||
# Clean up files on failure, but preserve .part file for resume
|
||||
cleanup_files = [metadata_path]
|
||||
if metadata.preview_url and os.path.exists(metadata.preview_url):
|
||||
cleanup_files.append(metadata.preview_url)
|
||||
|
||||
for path in cleanup_files:
|
||||
if path and os.path.exists(path):
|
||||
os.remove(path)
|
||||
try:
|
||||
os.remove(path)
|
||||
except Exception as e:
|
||||
logger.warning(f"Failed to cleanup file {path}: {e}")
|
||||
|
||||
# Log but don't remove .part file to allow resume
|
||||
if os.path.exists(part_path):
|
||||
logger.info(f"Preserving partial download for resume: {part_path}")
|
||||
|
||||
return {'success': False, 'error': result}
|
||||
|
||||
# 4. Update file information (size and modified time)
|
||||
metadata.update_file_info(save_path)
|
||||
|
||||
# 5. Final metadata update
|
||||
with open(metadata_path, 'w', encoding='utf-8') as f:
|
||||
json.dump(metadata.to_dict(), f, indent=2, ensure_ascii=False)
|
||||
await MetadataManager.save_metadata(save_path, metadata)
|
||||
|
||||
# 6. Update cache based on model type
|
||||
if model_type == "checkpoint":
|
||||
scanner = await self._get_checkpoint_scanner()
|
||||
logger.info(f"Updating checkpoint cache for {save_path}")
|
||||
else:
|
||||
elif model_type == "lora":
|
||||
scanner = await self._get_lora_scanner()
|
||||
logger.info(f"Updating lora cache for {save_path}")
|
||||
elif model_type == "embedding":
|
||||
scanner = await ServiceRegistry.get_embedding_scanner()
|
||||
logger.info(f"Updating embedding cache for {save_path}")
|
||||
|
||||
cache = await scanner.get_cached_data()
|
||||
# Convert metadata to dictionary
|
||||
metadata_dict = metadata.to_dict()
|
||||
metadata_dict['folder'] = relative_path
|
||||
cache.raw_data.append(metadata_dict)
|
||||
await cache.resort()
|
||||
all_folders = set(cache.folders)
|
||||
all_folders.add(relative_path)
|
||||
cache.folders = sorted(list(all_folders), key=lambda x: x.lower())
|
||||
|
||||
# Update the hash index with the new model entry
|
||||
scanner._hash_index.add_entry(metadata_dict['sha256'], metadata_dict['file_path'])
|
||||
|
||||
# Add model to cache and save to disk in a single operation
|
||||
await scanner.add_model_to_cache(metadata_dict, relative_path)
|
||||
|
||||
# Report 100% completion
|
||||
if progress_callback:
|
||||
@@ -303,10 +564,18 @@ class DownloadManager:
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error in _execute_download: {e}", exc_info=True)
|
||||
# Clean up partial downloads
|
||||
for path in [save_path, metadata_path]:
|
||||
# Clean up partial downloads except .part file
|
||||
cleanup_files = [metadata_path]
|
||||
if hasattr(metadata, 'preview_url') and metadata.preview_url and os.path.exists(metadata.preview_url):
|
||||
cleanup_files.append(metadata.preview_url)
|
||||
|
||||
for path in cleanup_files:
|
||||
if path and os.path.exists(path):
|
||||
os.remove(path)
|
||||
try:
|
||||
os.remove(path)
|
||||
except Exception as e:
|
||||
logger.warning(f"Failed to cleanup file {path}: {e}")
|
||||
|
||||
return {'success': False, 'error': str(e)}
|
||||
|
||||
async def _handle_download_progress(self, file_progress: float, progress_callback):
|
||||
@@ -319,4 +588,99 @@ class DownloadManager:
|
||||
if progress_callback:
|
||||
# Scale file progress to 3-100 range (after preview download)
|
||||
overall_progress = 3 + (file_progress * 0.97) # 97% of progress for file download
|
||||
await progress_callback(round(overall_progress))
|
||||
await progress_callback(round(overall_progress))
|
||||
|
||||
async def cancel_download(self, download_id: str) -> Dict:
|
||||
"""Cancel an active download by download_id
|
||||
|
||||
Args:
|
||||
download_id: The unique identifier of the download task
|
||||
|
||||
Returns:
|
||||
Dict: Status of the cancellation operation
|
||||
"""
|
||||
if download_id not in self._download_tasks:
|
||||
return {'success': False, 'error': 'Download task not found'}
|
||||
|
||||
try:
|
||||
# Get the task and cancel it
|
||||
task = self._download_tasks[download_id]
|
||||
task.cancel()
|
||||
|
||||
# Update status in active downloads
|
||||
if download_id in self._active_downloads:
|
||||
self._active_downloads[download_id]['status'] = 'cancelling'
|
||||
|
||||
# Wait briefly for the task to acknowledge cancellation
|
||||
try:
|
||||
await asyncio.wait_for(asyncio.shield(task), timeout=2.0)
|
||||
except (asyncio.CancelledError, asyncio.TimeoutError):
|
||||
pass
|
||||
|
||||
# Clean up ALL files including .part when user cancels
|
||||
download_info = self._active_downloads.get(download_id)
|
||||
if download_info:
|
||||
# Delete the main file
|
||||
if 'file_path' in download_info:
|
||||
file_path = download_info['file_path']
|
||||
if os.path.exists(file_path):
|
||||
try:
|
||||
os.unlink(file_path)
|
||||
logger.debug(f"Deleted cancelled download: {file_path}")
|
||||
except Exception as e:
|
||||
logger.error(f"Error deleting file: {e}")
|
||||
|
||||
# Delete the .part file (only on user cancellation)
|
||||
if 'part_path' in download_info:
|
||||
part_path = download_info['part_path']
|
||||
if os.path.exists(part_path):
|
||||
try:
|
||||
os.unlink(part_path)
|
||||
logger.debug(f"Deleted partial download: {part_path}")
|
||||
except Exception as e:
|
||||
logger.error(f"Error deleting part file: {e}")
|
||||
|
||||
# Delete metadata file if exists
|
||||
if 'file_path' in download_info:
|
||||
file_path = download_info['file_path']
|
||||
metadata_path = os.path.splitext(file_path)[0] + '.metadata.json'
|
||||
if os.path.exists(metadata_path):
|
||||
try:
|
||||
os.unlink(metadata_path)
|
||||
except Exception as e:
|
||||
logger.error(f"Error deleting metadata file: {e}")
|
||||
|
||||
# Delete preview file if exists (.webp or .mp4)
|
||||
for preview_ext in ['.webp', '.mp4']:
|
||||
preview_path = os.path.splitext(file_path)[0] + preview_ext
|
||||
if os.path.exists(preview_path):
|
||||
try:
|
||||
os.unlink(preview_path)
|
||||
logger.debug(f"Deleted preview file: {preview_path}")
|
||||
except Exception as e:
|
||||
logger.error(f"Error deleting preview file: {e}")
|
||||
|
||||
return {'success': True, 'message': 'Download cancelled successfully'}
|
||||
except Exception as e:
|
||||
logger.error(f"Error cancelling download: {e}", exc_info=True)
|
||||
return {'success': False, 'error': str(e)}
|
||||
|
||||
async def get_active_downloads(self) -> Dict:
|
||||
"""Get information about all active downloads
|
||||
|
||||
Returns:
|
||||
Dict: List of active downloads and their status
|
||||
"""
|
||||
return {
|
||||
'downloads': [
|
||||
{
|
||||
'download_id': task_id,
|
||||
'model_id': info.get('model_id'),
|
||||
'model_version_id': info.get('model_version_id'),
|
||||
'progress': info.get('progress', 0),
|
||||
'status': info.get('status', 'unknown'),
|
||||
'error': info.get('error', None)
|
||||
}
|
||||
for task_id, info in self._active_downloads.items()
|
||||
]
|
||||
}
|
||||
539
py/services/downloader.py
Normal file
539
py/services/downloader.py
Normal file
@@ -0,0 +1,539 @@
|
||||
"""
|
||||
Unified download manager for all HTTP/HTTPS downloads in the application.
|
||||
|
||||
This module provides a centralized download service with:
|
||||
- Singleton pattern for global session management
|
||||
- Support for authenticated downloads (e.g., CivitAI API key)
|
||||
- Resumable downloads with automatic retry
|
||||
- Progress tracking and callbacks
|
||||
- Optimized connection pooling and timeouts
|
||||
- Unified error handling and logging
|
||||
"""
|
||||
|
||||
import os
|
||||
import logging
|
||||
import asyncio
|
||||
import aiohttp
|
||||
from datetime import datetime
|
||||
from typing import Optional, Dict, Tuple, Callable, Union
|
||||
from ..services.settings_manager import settings
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class Downloader:
|
||||
"""Unified downloader for all HTTP/HTTPS downloads in the application."""
|
||||
|
||||
_instance = None
|
||||
_lock = asyncio.Lock()
|
||||
|
||||
@classmethod
|
||||
async def get_instance(cls):
|
||||
"""Get singleton instance of Downloader"""
|
||||
async with cls._lock:
|
||||
if cls._instance is None:
|
||||
cls._instance = cls()
|
||||
return cls._instance
|
||||
|
||||
def __init__(self):
|
||||
"""Initialize the downloader with optimal settings"""
|
||||
# Check if already initialized for singleton pattern
|
||||
if hasattr(self, '_initialized'):
|
||||
return
|
||||
self._initialized = True
|
||||
|
||||
# Session management
|
||||
self._session = None
|
||||
self._session_created_at = None
|
||||
self._proxy_url = None # Store proxy URL for current session
|
||||
|
||||
# Configuration
|
||||
self.chunk_size = 4 * 1024 * 1024 # 4MB chunks for better throughput
|
||||
self.max_retries = 5
|
||||
self.base_delay = 2.0 # Base delay for exponential backoff
|
||||
self.session_timeout = 300 # 5 minutes
|
||||
|
||||
# Default headers
|
||||
self.default_headers = {
|
||||
'User-Agent': 'ComfyUI-LoRA-Manager/1.0'
|
||||
}
|
||||
|
||||
@property
|
||||
async def session(self) -> aiohttp.ClientSession:
|
||||
"""Get or create the global aiohttp session with optimized settings"""
|
||||
if self._session is None or self._should_refresh_session():
|
||||
await self._create_session()
|
||||
return self._session
|
||||
|
||||
@property
|
||||
def proxy_url(self) -> Optional[str]:
|
||||
"""Get the current proxy URL (initialize if needed)"""
|
||||
if not hasattr(self, '_proxy_url'):
|
||||
self._proxy_url = None
|
||||
return self._proxy_url
|
||||
|
||||
def _should_refresh_session(self) -> bool:
|
||||
"""Check if session should be refreshed"""
|
||||
if self._session is None:
|
||||
return True
|
||||
|
||||
if not hasattr(self, '_session_created_at') or self._session_created_at is None:
|
||||
return True
|
||||
|
||||
# Refresh if session is older than timeout
|
||||
if (datetime.now() - self._session_created_at).total_seconds() > self.session_timeout:
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
async def _create_session(self):
|
||||
"""Create a new aiohttp session with optimized settings"""
|
||||
# Close existing session if any
|
||||
if self._session is not None:
|
||||
await self._session.close()
|
||||
|
||||
# Check for app-level proxy settings
|
||||
proxy_url = None
|
||||
if settings.get('proxy_enabled', False):
|
||||
proxy_host = settings.get('proxy_host', '').strip()
|
||||
proxy_port = settings.get('proxy_port', '').strip()
|
||||
proxy_type = settings.get('proxy_type', 'http').lower()
|
||||
proxy_username = settings.get('proxy_username', '').strip()
|
||||
proxy_password = settings.get('proxy_password', '').strip()
|
||||
|
||||
if proxy_host and proxy_port:
|
||||
# Build proxy URL
|
||||
if proxy_username and proxy_password:
|
||||
proxy_url = f"{proxy_type}://{proxy_username}:{proxy_password}@{proxy_host}:{proxy_port}"
|
||||
else:
|
||||
proxy_url = f"{proxy_type}://{proxy_host}:{proxy_port}"
|
||||
|
||||
logger.debug(f"Using app-level proxy: {proxy_type}://{proxy_host}:{proxy_port}")
|
||||
logger.debug("Proxy mode: app-level proxy is active.")
|
||||
else:
|
||||
logger.debug("Proxy mode: system-level proxy (trust_env) will be used if configured in environment.")
|
||||
# Optimize TCP connection parameters
|
||||
connector = aiohttp.TCPConnector(
|
||||
ssl=True,
|
||||
limit=8, # Concurrent connections
|
||||
ttl_dns_cache=300, # DNS cache timeout
|
||||
force_close=False, # Keep connections for reuse
|
||||
enable_cleanup_closed=True
|
||||
)
|
||||
|
||||
# Configure timeout parameters
|
||||
timeout = aiohttp.ClientTimeout(
|
||||
total=None, # No total timeout for large downloads
|
||||
connect=60, # Connection timeout
|
||||
sock_read=300 # 5 minute socket read timeout
|
||||
)
|
||||
|
||||
self._session = aiohttp.ClientSession(
|
||||
connector=connector,
|
||||
trust_env=proxy_url is None, # Only use system proxy if no app-level proxy is set
|
||||
timeout=timeout
|
||||
)
|
||||
|
||||
# Store proxy URL for use in requests
|
||||
self._proxy_url = proxy_url
|
||||
self._session_created_at = datetime.now()
|
||||
|
||||
logger.debug("Created new HTTP session with proxy settings. App-level proxy: %s, System-level proxy (trust_env): %s", bool(proxy_url), proxy_url is None)
|
||||
|
||||
def _get_auth_headers(self, use_auth: bool = False) -> Dict[str, str]:
|
||||
"""Get headers with optional authentication"""
|
||||
headers = self.default_headers.copy()
|
||||
|
||||
if use_auth:
|
||||
# Add CivitAI API key if available
|
||||
api_key = settings.get('civitai_api_key')
|
||||
if api_key:
|
||||
headers['Authorization'] = f'Bearer {api_key}'
|
||||
headers['Content-Type'] = 'application/json'
|
||||
|
||||
return headers
|
||||
|
||||
async def download_file(
|
||||
self,
|
||||
url: str,
|
||||
save_path: str,
|
||||
progress_callback: Optional[Callable[[float], None]] = None,
|
||||
use_auth: bool = False,
|
||||
custom_headers: Optional[Dict[str, str]] = None,
|
||||
allow_resume: bool = True
|
||||
) -> Tuple[bool, str]:
|
||||
"""
|
||||
Download a file with resumable downloads and retry mechanism
|
||||
|
||||
Args:
|
||||
url: Download URL
|
||||
save_path: Full path where the file should be saved
|
||||
progress_callback: Optional callback for progress updates (0-100)
|
||||
use_auth: Whether to include authentication headers (e.g., CivitAI API key)
|
||||
custom_headers: Additional headers to include in request
|
||||
allow_resume: Whether to support resumable downloads
|
||||
|
||||
Returns:
|
||||
Tuple[bool, str]: (success, save_path or error message)
|
||||
"""
|
||||
retry_count = 0
|
||||
part_path = save_path + '.part' if allow_resume else save_path
|
||||
|
||||
# Prepare headers
|
||||
headers = self._get_auth_headers(use_auth)
|
||||
if custom_headers:
|
||||
headers.update(custom_headers)
|
||||
|
||||
# Get existing file size for resume
|
||||
resume_offset = 0
|
||||
if allow_resume and os.path.exists(part_path):
|
||||
resume_offset = os.path.getsize(part_path)
|
||||
logger.info(f"Resuming download from offset {resume_offset} bytes")
|
||||
|
||||
total_size = 0
|
||||
|
||||
while retry_count <= self.max_retries:
|
||||
try:
|
||||
session = await self.session
|
||||
# Debug log for proxy mode at request time
|
||||
if self.proxy_url:
|
||||
logger.debug(f"[download_file] Using app-level proxy: {self.proxy_url}")
|
||||
else:
|
||||
logger.debug("[download_file] Using system-level proxy (trust_env) if configured.")
|
||||
|
||||
# Add Range header for resume if we have partial data
|
||||
request_headers = headers.copy()
|
||||
if allow_resume and resume_offset > 0:
|
||||
request_headers['Range'] = f'bytes={resume_offset}-'
|
||||
|
||||
# Disable compression for better chunked downloads
|
||||
request_headers['Accept-Encoding'] = 'identity'
|
||||
|
||||
logger.debug(f"Download attempt {retry_count + 1}/{self.max_retries + 1} from: {url}")
|
||||
if resume_offset > 0:
|
||||
logger.debug(f"Requesting range from byte {resume_offset}")
|
||||
|
||||
async with session.get(url, headers=request_headers, allow_redirects=True, proxy=self.proxy_url) as response:
|
||||
# Handle different response codes
|
||||
if response.status == 200:
|
||||
# Full content response
|
||||
if resume_offset > 0:
|
||||
# Server doesn't support ranges, restart from beginning
|
||||
logger.warning("Server doesn't support range requests, restarting download")
|
||||
resume_offset = 0
|
||||
if os.path.exists(part_path):
|
||||
os.remove(part_path)
|
||||
elif response.status == 206:
|
||||
# Partial content response (resume successful)
|
||||
content_range = response.headers.get('Content-Range')
|
||||
if content_range:
|
||||
# Parse total size from Content-Range header (e.g., "bytes 1024-2047/2048")
|
||||
range_parts = content_range.split('/')
|
||||
if len(range_parts) == 2:
|
||||
total_size = int(range_parts[1])
|
||||
logger.info(f"Successfully resumed download from byte {resume_offset}")
|
||||
elif response.status == 416:
|
||||
# Range not satisfiable - file might be complete or corrupted
|
||||
if allow_resume and os.path.exists(part_path):
|
||||
part_size = os.path.getsize(part_path)
|
||||
logger.warning(f"Range not satisfiable. Part file size: {part_size}")
|
||||
# Try to get actual file size
|
||||
head_response = await session.head(url, headers=headers, proxy=self.proxy_url)
|
||||
if head_response.status == 200:
|
||||
actual_size = int(head_response.headers.get('content-length', 0))
|
||||
if part_size == actual_size:
|
||||
# File is complete, just rename it
|
||||
if allow_resume:
|
||||
os.rename(part_path, save_path)
|
||||
if progress_callback:
|
||||
await progress_callback(100)
|
||||
return True, save_path
|
||||
# Remove corrupted part file and restart
|
||||
os.remove(part_path)
|
||||
resume_offset = 0
|
||||
continue
|
||||
elif response.status == 401:
|
||||
logger.warning(f"Unauthorized access to resource: {url} (Status 401)")
|
||||
return False, "Invalid or missing API key, or early access restriction."
|
||||
elif response.status == 403:
|
||||
logger.warning(f"Forbidden access to resource: {url} (Status 403)")
|
||||
return False, "Access forbidden: You don't have permission to download this file."
|
||||
elif response.status == 404:
|
||||
logger.warning(f"Resource not found: {url} (Status 404)")
|
||||
return False, "File not found - the download link may be invalid or expired."
|
||||
else:
|
||||
logger.error(f"Download failed for {url} with status {response.status}")
|
||||
return False, f"Download failed with status {response.status}"
|
||||
|
||||
# Get total file size for progress calculation (if not set from Content-Range)
|
||||
if total_size == 0:
|
||||
total_size = int(response.headers.get('content-length', 0))
|
||||
if response.status == 206:
|
||||
# For partial content, add the offset to get total file size
|
||||
total_size += resume_offset
|
||||
|
||||
current_size = resume_offset
|
||||
last_progress_report_time = datetime.now()
|
||||
|
||||
# Ensure directory exists
|
||||
os.makedirs(os.path.dirname(save_path), exist_ok=True)
|
||||
|
||||
# Stream download to file with progress updates
|
||||
loop = asyncio.get_running_loop()
|
||||
mode = 'ab' if (allow_resume and resume_offset > 0) else 'wb'
|
||||
with open(part_path, mode) as f:
|
||||
async for chunk in response.content.iter_chunked(self.chunk_size):
|
||||
if chunk:
|
||||
# Run blocking file write in executor
|
||||
await loop.run_in_executor(None, f.write, chunk)
|
||||
current_size += len(chunk)
|
||||
|
||||
# Limit progress update frequency to reduce overhead
|
||||
now = datetime.now()
|
||||
time_diff = (now - last_progress_report_time).total_seconds()
|
||||
|
||||
if progress_callback and total_size and time_diff >= 1.0:
|
||||
progress = (current_size / total_size) * 100
|
||||
await progress_callback(progress)
|
||||
last_progress_report_time = now
|
||||
|
||||
# Download completed successfully
|
||||
# Verify file size if total_size was provided
|
||||
final_size = os.path.getsize(part_path)
|
||||
if total_size > 0 and final_size != total_size:
|
||||
logger.warning(f"File size mismatch. Expected: {total_size}, Got: {final_size}")
|
||||
# Don't treat this as fatal error, continue anyway
|
||||
|
||||
# Atomically rename .part to final file (only if using resume)
|
||||
if allow_resume and part_path != save_path:
|
||||
max_rename_attempts = 5
|
||||
rename_attempt = 0
|
||||
rename_success = False
|
||||
|
||||
while rename_attempt < max_rename_attempts and not rename_success:
|
||||
try:
|
||||
# If the destination file exists, remove it first (Windows safe)
|
||||
if os.path.exists(save_path):
|
||||
os.remove(save_path)
|
||||
|
||||
os.rename(part_path, save_path)
|
||||
rename_success = True
|
||||
except PermissionError as e:
|
||||
rename_attempt += 1
|
||||
if rename_attempt < max_rename_attempts:
|
||||
logger.info(f"File still in use, retrying rename in 2 seconds (attempt {rename_attempt}/{max_rename_attempts})")
|
||||
await asyncio.sleep(2)
|
||||
else:
|
||||
logger.error(f"Failed to rename file after {max_rename_attempts} attempts: {e}")
|
||||
return False, f"Failed to finalize download: {str(e)}"
|
||||
|
||||
# Ensure 100% progress is reported
|
||||
if progress_callback:
|
||||
await progress_callback(100)
|
||||
|
||||
return True, save_path
|
||||
|
||||
except (aiohttp.ClientError, aiohttp.ClientPayloadError,
|
||||
aiohttp.ServerDisconnectedError, asyncio.TimeoutError) as e:
|
||||
retry_count += 1
|
||||
logger.warning(f"Network error during download (attempt {retry_count}/{self.max_retries + 1}): {e}")
|
||||
|
||||
if retry_count <= self.max_retries:
|
||||
# Calculate delay with exponential backoff
|
||||
delay = self.base_delay * (2 ** (retry_count - 1))
|
||||
logger.info(f"Retrying in {delay} seconds...")
|
||||
await asyncio.sleep(delay)
|
||||
|
||||
# Update resume offset for next attempt
|
||||
if allow_resume and os.path.exists(part_path):
|
||||
resume_offset = os.path.getsize(part_path)
|
||||
logger.info(f"Will resume from byte {resume_offset}")
|
||||
|
||||
# Refresh session to get new connection
|
||||
await self._create_session()
|
||||
continue
|
||||
else:
|
||||
logger.error(f"Max retries exceeded for download: {e}")
|
||||
return False, f"Network error after {self.max_retries + 1} attempts: {str(e)}"
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Unexpected download error: {e}")
|
||||
return False, str(e)
|
||||
|
||||
return False, f"Download failed after {self.max_retries + 1} attempts"
|
||||
|
||||
async def download_to_memory(
|
||||
self,
|
||||
url: str,
|
||||
use_auth: bool = False,
|
||||
custom_headers: Optional[Dict[str, str]] = None,
|
||||
return_headers: bool = False
|
||||
) -> Tuple[bool, Union[bytes, str], Optional[Dict]]:
|
||||
"""
|
||||
Download a file to memory (for small files like preview images)
|
||||
|
||||
Args:
|
||||
url: Download URL
|
||||
use_auth: Whether to include authentication headers
|
||||
custom_headers: Additional headers to include in request
|
||||
return_headers: Whether to return response headers along with content
|
||||
|
||||
Returns:
|
||||
Tuple[bool, Union[bytes, str], Optional[Dict]]: (success, content or error message, response headers if requested)
|
||||
"""
|
||||
try:
|
||||
session = await self.session
|
||||
# Debug log for proxy mode at request time
|
||||
if self.proxy_url:
|
||||
logger.debug(f"[download_to_memory] Using app-level proxy: {self.proxy_url}")
|
||||
else:
|
||||
logger.debug("[download_to_memory] Using system-level proxy (trust_env) if configured.")
|
||||
|
||||
# Prepare headers
|
||||
headers = self._get_auth_headers(use_auth)
|
||||
if custom_headers:
|
||||
headers.update(custom_headers)
|
||||
|
||||
async with session.get(url, headers=headers, proxy=self.proxy_url) as response:
|
||||
if response.status == 200:
|
||||
content = await response.read()
|
||||
if return_headers:
|
||||
return True, content, dict(response.headers)
|
||||
else:
|
||||
return True, content, None
|
||||
elif response.status == 401:
|
||||
error_msg = "Unauthorized access - invalid or missing API key"
|
||||
return False, error_msg, None
|
||||
elif response.status == 403:
|
||||
error_msg = "Access forbidden"
|
||||
return False, error_msg, None
|
||||
elif response.status == 404:
|
||||
error_msg = "File not found"
|
||||
return False, error_msg, None
|
||||
else:
|
||||
error_msg = f"Download failed with status {response.status}"
|
||||
return False, error_msg, None
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error downloading to memory from {url}: {e}")
|
||||
return False, str(e), None
|
||||
|
||||
async def get_response_headers(
|
||||
self,
|
||||
url: str,
|
||||
use_auth: bool = False,
|
||||
custom_headers: Optional[Dict[str, str]] = None
|
||||
) -> Tuple[bool, Union[Dict, str]]:
|
||||
"""
|
||||
Get response headers without downloading the full content
|
||||
|
||||
Args:
|
||||
url: URL to check
|
||||
use_auth: Whether to include authentication headers
|
||||
custom_headers: Additional headers to include in request
|
||||
|
||||
Returns:
|
||||
Tuple[bool, Union[Dict, str]]: (success, headers dict or error message)
|
||||
"""
|
||||
try:
|
||||
session = await self.session
|
||||
# Debug log for proxy mode at request time
|
||||
if self.proxy_url:
|
||||
logger.debug(f"[get_response_headers] Using app-level proxy: {self.proxy_url}")
|
||||
else:
|
||||
logger.debug("[get_response_headers] Using system-level proxy (trust_env) if configured.")
|
||||
|
||||
# Prepare headers
|
||||
headers = self._get_auth_headers(use_auth)
|
||||
if custom_headers:
|
||||
headers.update(custom_headers)
|
||||
|
||||
async with session.head(url, headers=headers, proxy=self.proxy_url) as response:
|
||||
if response.status == 200:
|
||||
return True, dict(response.headers)
|
||||
else:
|
||||
return False, f"Head request failed with status {response.status}"
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting headers from {url}: {e}")
|
||||
return False, str(e)
|
||||
|
||||
async def make_request(
|
||||
self,
|
||||
method: str,
|
||||
url: str,
|
||||
use_auth: bool = False,
|
||||
custom_headers: Optional[Dict[str, str]] = None,
|
||||
**kwargs
|
||||
) -> Tuple[bool, Union[Dict, str]]:
|
||||
"""
|
||||
Make a generic HTTP request and return JSON response
|
||||
|
||||
Args:
|
||||
method: HTTP method (GET, POST, etc.)
|
||||
url: Request URL
|
||||
use_auth: Whether to include authentication headers
|
||||
custom_headers: Additional headers to include in request
|
||||
**kwargs: Additional arguments for aiohttp request
|
||||
|
||||
Returns:
|
||||
Tuple[bool, Union[Dict, str]]: (success, response data or error message)
|
||||
"""
|
||||
try:
|
||||
session = await self.session
|
||||
# Debug log for proxy mode at request time
|
||||
if self.proxy_url:
|
||||
logger.debug(f"[make_request] Using app-level proxy: {self.proxy_url}")
|
||||
else:
|
||||
logger.debug("[make_request] Using system-level proxy (trust_env) if configured.")
|
||||
|
||||
# Prepare headers
|
||||
headers = self._get_auth_headers(use_auth)
|
||||
if custom_headers:
|
||||
headers.update(custom_headers)
|
||||
|
||||
# Add proxy to kwargs if not already present
|
||||
if 'proxy' not in kwargs:
|
||||
kwargs['proxy'] = self.proxy_url
|
||||
|
||||
async with session.request(method, url, headers=headers, **kwargs) as response:
|
||||
if response.status == 200:
|
||||
# Try to parse as JSON, fall back to text
|
||||
try:
|
||||
data = await response.json()
|
||||
return True, data
|
||||
except:
|
||||
text = await response.text()
|
||||
return True, text
|
||||
elif response.status == 401:
|
||||
return False, "Unauthorized access - invalid or missing API key"
|
||||
elif response.status == 403:
|
||||
return False, "Access forbidden"
|
||||
elif response.status == 404:
|
||||
return False, "Resource not found"
|
||||
else:
|
||||
return False, f"Request failed with status {response.status}"
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error making {method} request to {url}: {e}")
|
||||
return False, str(e)
|
||||
|
||||
async def close(self):
|
||||
"""Close the HTTP session"""
|
||||
if self._session is not None:
|
||||
await self._session.close()
|
||||
self._session = None
|
||||
self._session_created_at = None
|
||||
self._proxy_url = None
|
||||
logger.debug("Closed HTTP session")
|
||||
|
||||
async def refresh_session(self):
|
||||
"""Force refresh the HTTP session (useful when proxy settings change)"""
|
||||
await self._create_session()
|
||||
logger.info("HTTP session refreshed due to settings change")
|
||||
|
||||
|
||||
# Global instance accessor
|
||||
async def get_downloader() -> Downloader:
|
||||
"""Get the global downloader instance"""
|
||||
return await Downloader.get_instance()
|
||||
26
py/services/embedding_scanner.py
Normal file
26
py/services/embedding_scanner.py
Normal file
@@ -0,0 +1,26 @@
|
||||
import logging
|
||||
from typing import List
|
||||
|
||||
from ..utils.models import EmbeddingMetadata
|
||||
from ..config import config
|
||||
from .model_scanner import ModelScanner
|
||||
from .model_hash_index import ModelHashIndex
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class EmbeddingScanner(ModelScanner):
|
||||
"""Service for scanning and managing embedding files"""
|
||||
|
||||
def __init__(self):
|
||||
# Define supported file extensions
|
||||
file_extensions = {'.ckpt', '.pt', '.pt2', '.bin', '.pth', '.safetensors', '.pkl', '.sft'}
|
||||
super().__init__(
|
||||
model_type="embedding",
|
||||
model_class=EmbeddingMetadata,
|
||||
file_extensions=file_extensions,
|
||||
hash_index=ModelHashIndex()
|
||||
)
|
||||
|
||||
def get_model_roots(self) -> List[str]:
|
||||
"""Get embedding root directories"""
|
||||
return config.embeddings_roots
|
||||
50
py/services/embedding_service.py
Normal file
50
py/services/embedding_service.py
Normal file
@@ -0,0 +1,50 @@
|
||||
import os
|
||||
import logging
|
||||
from typing import Dict, List, Optional
|
||||
|
||||
from .base_model_service import BaseModelService
|
||||
from ..utils.models import EmbeddingMetadata
|
||||
from ..config import config
|
||||
from ..utils.routes_common import ModelRouteUtils
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class EmbeddingService(BaseModelService):
|
||||
"""Embedding-specific service implementation"""
|
||||
|
||||
def __init__(self, scanner):
|
||||
"""Initialize Embedding service
|
||||
|
||||
Args:
|
||||
scanner: Embedding scanner instance
|
||||
"""
|
||||
super().__init__("embedding", scanner, EmbeddingMetadata)
|
||||
|
||||
async def format_response(self, embedding_data: Dict) -> Dict:
|
||||
"""Format Embedding data for API response"""
|
||||
return {
|
||||
"model_name": embedding_data["model_name"],
|
||||
"file_name": embedding_data["file_name"],
|
||||
"preview_url": config.get_preview_static_url(embedding_data.get("preview_url", "")),
|
||||
"preview_nsfw_level": embedding_data.get("preview_nsfw_level", 0),
|
||||
"base_model": embedding_data.get("base_model", ""),
|
||||
"folder": embedding_data["folder"],
|
||||
"sha256": embedding_data.get("sha256", ""),
|
||||
"file_path": embedding_data["file_path"].replace(os.sep, "/"),
|
||||
"file_size": embedding_data.get("size", 0),
|
||||
"modified": embedding_data.get("modified", ""),
|
||||
"tags": embedding_data.get("tags", []),
|
||||
"from_civitai": embedding_data.get("from_civitai", True),
|
||||
"notes": embedding_data.get("notes", ""),
|
||||
"model_type": embedding_data.get("model_type", "embedding"),
|
||||
"favorite": embedding_data.get("favorite", False),
|
||||
"civitai": ModelRouteUtils.filter_civitai_data(embedding_data.get("civitai", {}), minimal=True)
|
||||
}
|
||||
|
||||
def find_duplicate_hashes(self) -> Dict:
|
||||
"""Find Embeddings with duplicate SHA256 hashes"""
|
||||
return self.scanner._hash_index.get_duplicate_hashes()
|
||||
|
||||
def find_duplicate_filenames(self) -> Dict:
|
||||
"""Find Embeddings with conflicting filenames"""
|
||||
return self.scanner._hash_index.get_duplicate_filenames()
|
||||
@@ -1,542 +0,0 @@
|
||||
import os
|
||||
import logging
|
||||
import asyncio
|
||||
import time
|
||||
from watchdog.observers import Observer
|
||||
from watchdog.events import FileSystemEventHandler
|
||||
from typing import List, Dict, Set, Optional
|
||||
from threading import Lock
|
||||
|
||||
from ..config import config
|
||||
from .service_registry import ServiceRegistry
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# Configuration constant to control file monitoring functionality
|
||||
ENABLE_FILE_MONITORING = False
|
||||
|
||||
class BaseFileHandler(FileSystemEventHandler):
|
||||
"""Base handler for file system events"""
|
||||
|
||||
def __init__(self, loop: asyncio.AbstractEventLoop):
|
||||
self.loop = loop # Store event loop reference
|
||||
self.pending_changes = set() # Pending changes
|
||||
self.lock = Lock() # Thread-safe lock
|
||||
self.update_task = None # Async update task
|
||||
self._ignore_paths = set() # Paths to ignore
|
||||
self._min_ignore_timeout = 5 # Minimum timeout in seconds
|
||||
self._download_speed = 1024 * 1024 # Assume 1MB/s as base speed
|
||||
|
||||
# Track modified files with timestamps for debouncing
|
||||
self.modified_files: Dict[str, float] = {}
|
||||
self.debounce_timer = None
|
||||
self.debounce_delay = 3.0 # Seconds to wait after last modification
|
||||
|
||||
# Track files already scheduled for processing
|
||||
self.scheduled_files: Set[str] = set()
|
||||
|
||||
# File extensions to monitor - should be overridden by subclasses
|
||||
self.file_extensions = set()
|
||||
|
||||
def _should_ignore(self, path: str) -> bool:
|
||||
"""Check if path should be ignored"""
|
||||
real_path = os.path.realpath(path) # Resolve any symbolic links
|
||||
return real_path.replace(os.sep, '/') in self._ignore_paths
|
||||
|
||||
def add_ignore_path(self, path: str, file_size: int = 0):
|
||||
"""Add path to ignore list with dynamic timeout based on file size"""
|
||||
real_path = os.path.realpath(path) # Resolve any symbolic links
|
||||
self._ignore_paths.add(real_path.replace(os.sep, '/'))
|
||||
|
||||
# Short timeout (e.g. 5 seconds) is sufficient to ignore the CREATE event
|
||||
timeout = 5
|
||||
|
||||
self.loop.call_later(
|
||||
timeout,
|
||||
self._ignore_paths.discard,
|
||||
real_path.replace(os.sep, '/')
|
||||
)
|
||||
|
||||
def on_created(self, event):
|
||||
if event.is_directory:
|
||||
return
|
||||
|
||||
# Handle appropriate files based on extensions
|
||||
file_ext = os.path.splitext(event.src_path)[1].lower()
|
||||
if file_ext in self.file_extensions:
|
||||
if self._should_ignore(event.src_path):
|
||||
return
|
||||
|
||||
# Process this file directly and ignore subsequent modifications
|
||||
normalized_path = os.path.realpath(event.src_path).replace(os.sep, '/')
|
||||
if normalized_path not in self.scheduled_files:
|
||||
logger.info(f"File created: {event.src_path}")
|
||||
self.scheduled_files.add(normalized_path)
|
||||
self._schedule_update('add', event.src_path)
|
||||
|
||||
# Ignore modifications for a short period after creation
|
||||
self.loop.call_later(
|
||||
self.debounce_delay * 2,
|
||||
self.scheduled_files.discard,
|
||||
normalized_path
|
||||
)
|
||||
|
||||
def on_modified(self, event):
|
||||
if event.is_directory:
|
||||
return
|
||||
|
||||
# Only process files with supported extensions
|
||||
file_ext = os.path.splitext(event.src_path)[1].lower()
|
||||
if file_ext in self.file_extensions:
|
||||
if self._should_ignore(event.src_path):
|
||||
return
|
||||
|
||||
normalized_path = os.path.realpath(event.src_path).replace(os.sep, '/')
|
||||
|
||||
# Skip if this file is already scheduled for processing
|
||||
if normalized_path in self.scheduled_files:
|
||||
return
|
||||
|
||||
# Update the timestamp for this file
|
||||
self.modified_files[normalized_path] = time.time()
|
||||
|
||||
# Cancel any existing timer
|
||||
if self.debounce_timer:
|
||||
self.debounce_timer.cancel()
|
||||
|
||||
# Set a new timer to process modified files after debounce period
|
||||
self.debounce_timer = self.loop.call_later(
|
||||
self.debounce_delay,
|
||||
self.loop.call_soon_threadsafe,
|
||||
self._process_modified_files
|
||||
)
|
||||
|
||||
def _process_modified_files(self):
|
||||
"""Process files that have been modified after debounce period"""
|
||||
current_time = time.time()
|
||||
files_to_process = []
|
||||
|
||||
# Find files that haven't been modified for debounce_delay seconds
|
||||
for file_path, last_modified in list(self.modified_files.items()):
|
||||
if current_time - last_modified >= self.debounce_delay:
|
||||
# Only process if not already scheduled
|
||||
if file_path not in self.scheduled_files:
|
||||
files_to_process.append(file_path)
|
||||
self.scheduled_files.add(file_path)
|
||||
|
||||
# Auto-remove from scheduled list after reasonable time
|
||||
self.loop.call_later(
|
||||
self.debounce_delay * 2,
|
||||
self.scheduled_files.discard,
|
||||
file_path
|
||||
)
|
||||
|
||||
del self.modified_files[file_path]
|
||||
|
||||
# Process stable files
|
||||
for file_path in files_to_process:
|
||||
logger.info(f"Processing modified file: {file_path}")
|
||||
self._schedule_update('add', file_path)
|
||||
|
||||
def on_deleted(self, event):
|
||||
if event.is_directory:
|
||||
return
|
||||
|
||||
file_ext = os.path.splitext(event.src_path)[1].lower()
|
||||
if file_ext not in self.file_extensions:
|
||||
return
|
||||
|
||||
if self._should_ignore(event.src_path):
|
||||
return
|
||||
|
||||
# Remove from scheduled files if present
|
||||
normalized_path = os.path.realpath(event.src_path).replace(os.sep, '/')
|
||||
self.scheduled_files.discard(normalized_path)
|
||||
|
||||
logger.info(f"File deleted: {event.src_path}")
|
||||
self._schedule_update('remove', event.src_path)
|
||||
|
||||
def on_moved(self, event):
|
||||
"""Handle file move/rename events"""
|
||||
|
||||
src_ext = os.path.splitext(event.src_path)[1].lower()
|
||||
dest_ext = os.path.splitext(event.dest_path)[1].lower()
|
||||
|
||||
# If destination has supported extension, treat as new file
|
||||
if dest_ext in self.file_extensions:
|
||||
if self._should_ignore(event.dest_path):
|
||||
return
|
||||
|
||||
normalized_path = os.path.realpath(event.dest_path).replace(os.sep, '/')
|
||||
|
||||
# Only process if not already scheduled
|
||||
if normalized_path not in self.scheduled_files:
|
||||
logger.info(f"File renamed/moved to: {event.dest_path}")
|
||||
self.scheduled_files.add(normalized_path)
|
||||
self._schedule_update('add', event.dest_path)
|
||||
|
||||
# Auto-remove from scheduled list after reasonable time
|
||||
self.loop.call_later(
|
||||
self.debounce_delay * 2,
|
||||
self.scheduled_files.discard,
|
||||
normalized_path
|
||||
)
|
||||
|
||||
# If source was a supported file, treat it as deleted
|
||||
if src_ext in self.file_extensions:
|
||||
if self._should_ignore(event.src_path):
|
||||
return
|
||||
|
||||
normalized_path = os.path.realpath(event.src_path).replace(os.sep, '/')
|
||||
self.scheduled_files.discard(normalized_path)
|
||||
|
||||
logger.info(f"File moved/renamed from: {event.src_path}")
|
||||
self._schedule_update('remove', event.src_path)
|
||||
|
||||
def _schedule_update(self, action: str, file_path: str):
|
||||
"""Schedule a cache update"""
|
||||
with self.lock:
|
||||
# Use config method to map path
|
||||
mapped_path = config.map_path_to_link(file_path)
|
||||
normalized_path = mapped_path.replace(os.sep, '/')
|
||||
self.pending_changes.add((action, normalized_path))
|
||||
|
||||
self.loop.call_soon_threadsafe(self._create_update_task)
|
||||
|
||||
def _create_update_task(self):
|
||||
"""Create update task in the event loop"""
|
||||
if self.update_task is None or self.update_task.done():
|
||||
self.update_task = asyncio.create_task(self._process_changes())
|
||||
|
||||
async def _process_changes(self, delay: float = 2.0):
|
||||
"""Process pending changes with debouncing - should be implemented by subclasses"""
|
||||
raise NotImplementedError("Subclasses must implement _process_changes")
|
||||
|
||||
|
||||
class LoraFileHandler(BaseFileHandler):
|
||||
"""Handler for LoRA file system events"""
|
||||
|
||||
def __init__(self, loop: asyncio.AbstractEventLoop):
|
||||
super().__init__(loop)
|
||||
# Set supported file extensions for LoRAs
|
||||
self.file_extensions = {'.safetensors'}
|
||||
|
||||
async def _process_changes(self, delay: float = 2.0):
|
||||
"""Process pending changes with debouncing"""
|
||||
await asyncio.sleep(delay)
|
||||
|
||||
try:
|
||||
with self.lock:
|
||||
changes = self.pending_changes.copy()
|
||||
self.pending_changes.clear()
|
||||
|
||||
if not changes:
|
||||
return
|
||||
|
||||
logger.info(f"Processing {len(changes)} LoRA file changes")
|
||||
|
||||
# Get scanner through ServiceRegistry
|
||||
scanner = await ServiceRegistry.get_lora_scanner()
|
||||
cache = await scanner.get_cached_data()
|
||||
needs_resort = False
|
||||
new_folders = set()
|
||||
|
||||
for action, file_path in changes:
|
||||
try:
|
||||
if action == 'add':
|
||||
# Check if file already exists in cache
|
||||
existing = next((item for item in cache.raw_data if item['file_path'] == file_path), None)
|
||||
if existing:
|
||||
logger.info(f"File {file_path} already in cache, skipping")
|
||||
continue
|
||||
|
||||
# Scan new file
|
||||
model_data = await scanner.scan_single_model(file_path)
|
||||
if model_data:
|
||||
# Update tags count
|
||||
for tag in model_data.get('tags', []):
|
||||
scanner._tags_count[tag] = scanner._tags_count.get(tag, 0) + 1
|
||||
|
||||
cache.raw_data.append(model_data)
|
||||
new_folders.add(model_data['folder'])
|
||||
# Update hash index
|
||||
if 'sha256' in model_data:
|
||||
scanner._hash_index.add_entry(
|
||||
model_data['sha256'],
|
||||
model_data['file_path']
|
||||
)
|
||||
needs_resort = True
|
||||
|
||||
elif action == 'remove':
|
||||
# Find the model to remove so we can update tags count
|
||||
model_to_remove = next((item for item in cache.raw_data if item['file_path'] == file_path), None)
|
||||
if model_to_remove:
|
||||
# Update tags count by reducing counts
|
||||
for tag in model_to_remove.get('tags', []):
|
||||
if tag in scanner._tags_count:
|
||||
scanner._tags_count[tag] = max(0, scanner._tags_count[tag] - 1)
|
||||
if scanner._tags_count[tag] == 0:
|
||||
del scanner._tags_count[tag]
|
||||
|
||||
# Remove from cache and hash index
|
||||
logger.info(f"Removing {file_path} from cache")
|
||||
scanner._hash_index.remove_by_path(file_path)
|
||||
cache.raw_data = [
|
||||
item for item in cache.raw_data
|
||||
if item['file_path'] != file_path
|
||||
]
|
||||
needs_resort = True
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing {action} for {file_path}: {e}")
|
||||
|
||||
if needs_resort:
|
||||
await cache.resort()
|
||||
|
||||
# Update folder list
|
||||
all_folders = set(cache.folders) | new_folders
|
||||
cache.folders = sorted(list(all_folders), key=lambda x: x.lower())
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error in process_changes for LoRA: {e}")
|
||||
|
||||
|
||||
class CheckpointFileHandler(BaseFileHandler):
|
||||
"""Handler for checkpoint file system events"""
|
||||
|
||||
def __init__(self, loop: asyncio.AbstractEventLoop):
|
||||
super().__init__(loop)
|
||||
# Set supported file extensions for checkpoints
|
||||
self.file_extensions = {'.safetensors', '.ckpt', '.pt', '.pth', '.sft', '.gguf'}
|
||||
|
||||
async def _process_changes(self, delay: float = 2.0):
|
||||
"""Process pending changes with debouncing for checkpoint files"""
|
||||
await asyncio.sleep(delay)
|
||||
|
||||
try:
|
||||
with self.lock:
|
||||
changes = self.pending_changes.copy()
|
||||
self.pending_changes.clear()
|
||||
|
||||
if not changes:
|
||||
return
|
||||
|
||||
logger.info(f"Processing {len(changes)} checkpoint file changes")
|
||||
|
||||
# Get scanner through ServiceRegistry
|
||||
scanner = await ServiceRegistry.get_checkpoint_scanner()
|
||||
cache = await scanner.get_cached_data()
|
||||
needs_resort = False
|
||||
new_folders = set()
|
||||
|
||||
for action, file_path in changes:
|
||||
try:
|
||||
if action == 'add':
|
||||
# Check if file already exists in cache
|
||||
existing = next((item for item in cache.raw_data if item['file_path'] == file_path), None)
|
||||
if existing:
|
||||
logger.info(f"File {file_path} already in cache, skipping")
|
||||
continue
|
||||
|
||||
# Scan new file
|
||||
model_data = await scanner.scan_single_model(file_path)
|
||||
if model_data:
|
||||
# Update tags count if applicable
|
||||
for tag in model_data.get('tags', []):
|
||||
scanner._tags_count[tag] = scanner._tags_count.get(tag, 0) + 1
|
||||
|
||||
cache.raw_data.append(model_data)
|
||||
new_folders.add(model_data['folder'])
|
||||
# Update hash index
|
||||
if 'sha256' in model_data:
|
||||
scanner._hash_index.add_entry(
|
||||
model_data['sha256'],
|
||||
model_data['file_path']
|
||||
)
|
||||
needs_resort = True
|
||||
|
||||
elif action == 'remove':
|
||||
# Find the model to remove so we can update tags count
|
||||
model_to_remove = next((item for item in cache.raw_data if item['file_path'] == file_path), None)
|
||||
if model_to_remove:
|
||||
# Update tags count by reducing counts
|
||||
for tag in model_to_remove.get('tags', []):
|
||||
if tag in scanner._tags_count:
|
||||
scanner._tags_count[tag] = max(0, scanner._tags_count[tag] - 1)
|
||||
if scanner._tags_count[tag] == 0:
|
||||
del scanner._tags_count[tag]
|
||||
|
||||
# Remove from cache and hash index
|
||||
logger.info(f"Removing {file_path} from checkpoint cache")
|
||||
scanner._hash_index.remove_by_path(file_path)
|
||||
cache.raw_data = [
|
||||
item for item in cache.raw_data
|
||||
if item['file_path'] != file_path
|
||||
]
|
||||
needs_resort = True
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing checkpoint {action} for {file_path}: {e}")
|
||||
|
||||
if needs_resort:
|
||||
await cache.resort()
|
||||
|
||||
# Update folder list
|
||||
all_folders = set(cache.folders) | new_folders
|
||||
cache.folders = sorted(list(all_folders), key=lambda x: x.lower())
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error in process_changes for checkpoint: {e}")
|
||||
|
||||
|
||||
class BaseFileMonitor:
|
||||
"""Base class for file monitoring"""
|
||||
|
||||
def __init__(self, monitor_paths: List[str]):
|
||||
self.observer = Observer()
|
||||
self.loop = asyncio.get_event_loop()
|
||||
self.monitor_paths = set()
|
||||
|
||||
# Process monitor paths
|
||||
for path in monitor_paths:
|
||||
self.monitor_paths.add(os.path.realpath(path).replace(os.sep, '/'))
|
||||
|
||||
# Add mapped paths from config
|
||||
for target_path in config._path_mappings.keys():
|
||||
self.monitor_paths.add(target_path)
|
||||
|
||||
def start(self):
|
||||
"""Start file monitoring"""
|
||||
if not ENABLE_FILE_MONITORING:
|
||||
logger.debug("File monitoring is disabled via ENABLE_FILE_MONITORING setting")
|
||||
return
|
||||
|
||||
for path in self.monitor_paths:
|
||||
try:
|
||||
self.observer.schedule(self.handler, path, recursive=True)
|
||||
logger.info(f"Started monitoring: {path}")
|
||||
except Exception as e:
|
||||
logger.error(f"Error monitoring {path}: {e}")
|
||||
|
||||
self.observer.start()
|
||||
|
||||
def stop(self):
|
||||
"""Stop file monitoring"""
|
||||
if not ENABLE_FILE_MONITORING:
|
||||
return
|
||||
|
||||
self.observer.stop()
|
||||
self.observer.join()
|
||||
|
||||
def rescan_links(self):
|
||||
"""Rescan links when new ones are added"""
|
||||
if not ENABLE_FILE_MONITORING:
|
||||
return
|
||||
|
||||
# Find new paths not yet being monitored
|
||||
new_paths = set()
|
||||
for path in config._path_mappings.keys():
|
||||
real_path = os.path.realpath(path).replace(os.sep, '/')
|
||||
if real_path not in self.monitor_paths:
|
||||
new_paths.add(real_path)
|
||||
self.monitor_paths.add(real_path)
|
||||
|
||||
# Add new paths to monitoring
|
||||
for path in new_paths:
|
||||
try:
|
||||
self.observer.schedule(self.handler, path, recursive=True)
|
||||
logger.info(f"Added new monitoring path: {path}")
|
||||
except Exception as e:
|
||||
logger.error(f"Error adding new monitor for {path}: {e}")
|
||||
|
||||
|
||||
class LoraFileMonitor(BaseFileMonitor):
|
||||
"""Monitor for LoRA file changes"""
|
||||
|
||||
_instance = None
|
||||
_lock = asyncio.Lock()
|
||||
|
||||
def __new__(cls, monitor_paths=None):
|
||||
if cls._instance is None:
|
||||
cls._instance = super().__new__(cls)
|
||||
return cls._instance
|
||||
|
||||
def __init__(self, monitor_paths=None):
|
||||
if not hasattr(self, '_initialized'):
|
||||
if monitor_paths is None:
|
||||
from ..config import config
|
||||
monitor_paths = config.loras_roots
|
||||
|
||||
super().__init__(monitor_paths)
|
||||
self.handler = LoraFileHandler(self.loop)
|
||||
self._initialized = True
|
||||
|
||||
@classmethod
|
||||
async def get_instance(cls):
|
||||
"""Get singleton instance with async support"""
|
||||
async with cls._lock:
|
||||
if cls._instance is None:
|
||||
from ..config import config
|
||||
cls._instance = cls(config.loras_roots)
|
||||
return cls._instance
|
||||
|
||||
|
||||
class CheckpointFileMonitor(BaseFileMonitor):
|
||||
"""Monitor for checkpoint file changes"""
|
||||
|
||||
_instance = None
|
||||
_lock = asyncio.Lock()
|
||||
|
||||
def __new__(cls, monitor_paths=None):
|
||||
if cls._instance is None:
|
||||
cls._instance = super().__new__(cls)
|
||||
return cls._instance
|
||||
|
||||
def __init__(self, monitor_paths=None):
|
||||
if not hasattr(self, '_initialized'):
|
||||
if monitor_paths is None:
|
||||
# Get checkpoint roots from scanner
|
||||
monitor_paths = []
|
||||
# We'll initialize monitor paths later when scanner is available
|
||||
|
||||
super().__init__(monitor_paths or [])
|
||||
self.handler = CheckpointFileHandler(self.loop)
|
||||
self._initialized = True
|
||||
|
||||
@classmethod
|
||||
async def get_instance(cls):
|
||||
"""Get singleton instance with async support"""
|
||||
async with cls._lock:
|
||||
if cls._instance is None:
|
||||
cls._instance = cls([])
|
||||
|
||||
# Now get checkpoint roots from scanner
|
||||
from .checkpoint_scanner import CheckpointScanner
|
||||
scanner = await CheckpointScanner.get_instance()
|
||||
monitor_paths = scanner.get_model_roots()
|
||||
|
||||
# Update monitor paths - but don't actually monitor them
|
||||
for path in monitor_paths:
|
||||
real_path = os.path.realpath(path).replace(os.sep, '/')
|
||||
cls._instance.monitor_paths.add(real_path)
|
||||
|
||||
return cls._instance
|
||||
|
||||
def start(self):
|
||||
"""Override start to check global enable flag"""
|
||||
if not ENABLE_FILE_MONITORING:
|
||||
logger.debug("Checkpoint file monitoring is disabled via ENABLE_FILE_MONITORING setting")
|
||||
return
|
||||
|
||||
logger.debug("Checkpoint file monitoring is temporarily disabled")
|
||||
# Skip the actual monitoring setup
|
||||
pass
|
||||
|
||||
async def initialize_paths(self):
|
||||
"""Initialize monitor paths from scanner - currently disabled"""
|
||||
if not ENABLE_FILE_MONITORING:
|
||||
logger.debug("Checkpoint path initialization skipped (monitoring disabled)")
|
||||
return
|
||||
|
||||
logger.debug("Checkpoint file path initialization skipped (monitoring disabled)")
|
||||
pass
|
||||
@@ -1,65 +0,0 @@
|
||||
import asyncio
|
||||
from typing import List, Dict
|
||||
from dataclasses import dataclass
|
||||
from operator import itemgetter
|
||||
from natsort import natsorted
|
||||
|
||||
@dataclass
|
||||
class LoraCache:
|
||||
"""Cache structure for LoRA data"""
|
||||
raw_data: List[Dict]
|
||||
sorted_by_name: List[Dict]
|
||||
sorted_by_date: List[Dict]
|
||||
folders: List[str]
|
||||
|
||||
def __post_init__(self):
|
||||
self._lock = asyncio.Lock()
|
||||
|
||||
async def resort(self, name_only: bool = False):
|
||||
"""Resort all cached data views"""
|
||||
async with self._lock:
|
||||
self.sorted_by_name = natsorted(
|
||||
self.raw_data,
|
||||
key=lambda x: x['model_name'].lower() # Case-insensitive sort
|
||||
)
|
||||
if not name_only:
|
||||
self.sorted_by_date = sorted(
|
||||
self.raw_data,
|
||||
key=itemgetter('modified'),
|
||||
reverse=True
|
||||
)
|
||||
# Update folder list
|
||||
all_folders = set(l['folder'] for l in self.raw_data)
|
||||
self.folders = sorted(list(all_folders), key=lambda x: x.lower())
|
||||
|
||||
async def update_preview_url(self, file_path: str, preview_url: str) -> bool:
|
||||
"""Update preview_url for a specific lora in all cached data
|
||||
|
||||
Args:
|
||||
file_path: The file path of the lora to update
|
||||
preview_url: The new preview URL
|
||||
|
||||
Returns:
|
||||
bool: True if the update was successful, False if the lora wasn't found
|
||||
"""
|
||||
async with self._lock:
|
||||
# Update in raw_data
|
||||
for item in self.raw_data:
|
||||
if item['file_path'] == file_path:
|
||||
item['preview_url'] = preview_url
|
||||
break
|
||||
else:
|
||||
return False # Lora not found
|
||||
|
||||
# Update in sorted lists (references to the same dict objects)
|
||||
for item in self.sorted_by_name:
|
||||
if item['file_path'] == file_path:
|
||||
item['preview_url'] = preview_url
|
||||
break
|
||||
|
||||
for item in self.sorted_by_date:
|
||||
if item['file_path'] == file_path:
|
||||
item['preview_url'] = preview_url
|
||||
break
|
||||
|
||||
return True
|
||||
@@ -1,54 +0,0 @@
|
||||
from typing import Dict, Optional
|
||||
import logging
|
||||
from dataclasses import dataclass
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@dataclass
|
||||
class LoraHashIndex:
|
||||
"""Index for mapping LoRA file hashes to their file paths"""
|
||||
|
||||
def __init__(self):
|
||||
self._hash_to_path: Dict[str, str] = {}
|
||||
|
||||
def add_entry(self, sha256: str, file_path: str) -> None:
|
||||
"""Add or update a hash -> path mapping"""
|
||||
if not sha256 or not file_path:
|
||||
return
|
||||
# Always store lowercase hashes for consistency
|
||||
self._hash_to_path[sha256.lower()] = file_path
|
||||
|
||||
def remove_entry(self, sha256: str) -> None:
|
||||
"""Remove a hash entry"""
|
||||
if sha256:
|
||||
self._hash_to_path.pop(sha256.lower(), None)
|
||||
|
||||
def remove_by_path(self, file_path: str) -> None:
|
||||
"""Remove entry by file path"""
|
||||
for sha256, path in list(self._hash_to_path.items()):
|
||||
if path == file_path:
|
||||
del self._hash_to_path[sha256]
|
||||
break
|
||||
|
||||
def get_path(self, sha256: str) -> Optional[str]:
|
||||
"""Get file path for a given hash"""
|
||||
if not sha256:
|
||||
return None
|
||||
return self._hash_to_path.get(sha256.lower())
|
||||
|
||||
def get_hash(self, file_path: str) -> Optional[str]:
|
||||
"""Get hash for a given file path"""
|
||||
for sha256, path in self._hash_to_path.items():
|
||||
if path == file_path:
|
||||
return sha256
|
||||
return None
|
||||
|
||||
def has_hash(self, sha256: str) -> bool:
|
||||
"""Check if hash exists in index"""
|
||||
if not sha256:
|
||||
return False
|
||||
return sha256.lower() in self._hash_to_path
|
||||
|
||||
def clear(self) -> None:
|
||||
"""Clear all entries"""
|
||||
self._hash_to_path.clear()
|
||||
@@ -1,20 +1,10 @@
|
||||
import json
|
||||
import os
|
||||
import logging
|
||||
import asyncio
|
||||
import shutil
|
||||
import time
|
||||
import re
|
||||
from typing import List, Dict, Optional, Set
|
||||
from typing import List
|
||||
|
||||
from ..utils.models import LoraMetadata
|
||||
from ..config import config
|
||||
from .model_scanner import ModelScanner
|
||||
from .model_hash_index import ModelHashIndex # Changed from LoraHashIndex to ModelHashIndex
|
||||
from .settings_manager import settings
|
||||
from ..utils.constants import NSFW_LEVELS
|
||||
from ..utils.utils import fuzzy_match
|
||||
from .service_registry import ServiceRegistry
|
||||
import sys
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
@@ -22,430 +12,21 @@ logger = logging.getLogger(__name__)
|
||||
class LoraScanner(ModelScanner):
|
||||
"""Service for scanning and managing LoRA files"""
|
||||
|
||||
_instance = None
|
||||
_lock = asyncio.Lock()
|
||||
|
||||
def __new__(cls):
|
||||
if cls._instance is None:
|
||||
cls._instance = super().__new__(cls)
|
||||
return cls._instance
|
||||
|
||||
def __init__(self):
|
||||
# Ensure initialization happens only once
|
||||
if not hasattr(self, '_initialized'):
|
||||
# Define supported file extensions
|
||||
file_extensions = {'.safetensors'}
|
||||
|
||||
# Initialize parent class with ModelHashIndex
|
||||
super().__init__(
|
||||
model_type="lora",
|
||||
model_class=LoraMetadata,
|
||||
file_extensions=file_extensions,
|
||||
hash_index=ModelHashIndex() # Changed from LoraHashIndex to ModelHashIndex
|
||||
)
|
||||
self._initialized = True
|
||||
|
||||
@classmethod
|
||||
async def get_instance(cls):
|
||||
"""Get singleton instance with async support"""
|
||||
async with cls._lock:
|
||||
if cls._instance is None:
|
||||
cls._instance = cls()
|
||||
return cls._instance
|
||||
# Define supported file extensions
|
||||
file_extensions = {'.safetensors'}
|
||||
|
||||
# Initialize parent class with ModelHashIndex
|
||||
super().__init__(
|
||||
model_type="lora",
|
||||
model_class=LoraMetadata,
|
||||
file_extensions=file_extensions,
|
||||
hash_index=ModelHashIndex() # Changed from LoraHashIndex to ModelHashIndex
|
||||
)
|
||||
|
||||
def get_model_roots(self) -> List[str]:
|
||||
"""Get lora root directories"""
|
||||
return config.loras_roots
|
||||
|
||||
async def scan_all_models(self) -> List[Dict]:
|
||||
"""Scan all LoRA directories and return metadata"""
|
||||
all_loras = []
|
||||
|
||||
# Create scan tasks for each directory
|
||||
scan_tasks = []
|
||||
for lora_root in self.get_model_roots():
|
||||
task = asyncio.create_task(self._scan_directory(lora_root))
|
||||
scan_tasks.append(task)
|
||||
|
||||
# Wait for all tasks to complete
|
||||
for task in scan_tasks:
|
||||
try:
|
||||
loras = await task
|
||||
all_loras.extend(loras)
|
||||
except Exception as e:
|
||||
logger.error(f"Error scanning directory: {e}")
|
||||
|
||||
return all_loras
|
||||
|
||||
async def _scan_directory(self, root_path: str) -> List[Dict]:
|
||||
"""Scan a single directory for LoRA files"""
|
||||
loras = []
|
||||
original_root = root_path # Save original root path
|
||||
|
||||
async def scan_recursive(path: str, visited_paths: set):
|
||||
"""Recursively scan directory, avoiding circular symlinks"""
|
||||
try:
|
||||
real_path = os.path.realpath(path)
|
||||
if real_path in visited_paths:
|
||||
logger.debug(f"Skipping already visited path: {path}")
|
||||
return
|
||||
visited_paths.add(real_path)
|
||||
|
||||
with os.scandir(path) as it:
|
||||
entries = list(it)
|
||||
for entry in entries:
|
||||
try:
|
||||
if entry.is_file(follow_symlinks=True) and any(entry.name.endswith(ext) for ext in self.file_extensions):
|
||||
# Use original path instead of real path
|
||||
file_path = entry.path.replace(os.sep, "/")
|
||||
await self._process_single_file(file_path, original_root, loras)
|
||||
await asyncio.sleep(0)
|
||||
elif entry.is_dir(follow_symlinks=True):
|
||||
# For directories, continue scanning with original path
|
||||
await scan_recursive(entry.path, visited_paths)
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing entry {entry.path}: {e}")
|
||||
except Exception as e:
|
||||
logger.error(f"Error scanning {path}: {e}")
|
||||
|
||||
await scan_recursive(root_path, set())
|
||||
return loras
|
||||
|
||||
async def _process_single_file(self, file_path: str, root_path: str, loras: list):
|
||||
"""Process a single file and add to results list"""
|
||||
try:
|
||||
result = await self._process_model_file(file_path, root_path)
|
||||
if result:
|
||||
loras.append(result)
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing {file_path}: {e}")
|
||||
|
||||
async def get_paginated_data(self, page: int, page_size: int, sort_by: str = 'name',
|
||||
folder: str = None, search: str = None, fuzzy_search: bool = False,
|
||||
base_models: list = None, tags: list = None,
|
||||
search_options: dict = None, hash_filters: dict = None,
|
||||
favorites_only: bool = False, first_letter: str = None) -> Dict:
|
||||
"""Get paginated and filtered lora data
|
||||
|
||||
Args:
|
||||
page: Current page number (1-based)
|
||||
page_size: Number of items per page
|
||||
sort_by: Sort method ('name' or 'date')
|
||||
folder: Filter by folder path
|
||||
search: Search term
|
||||
fuzzy_search: Use fuzzy matching for search
|
||||
base_models: List of base models to filter by
|
||||
tags: List of tags to filter by
|
||||
search_options: Dictionary with search options (filename, modelname, tags, recursive)
|
||||
hash_filters: Dictionary with hash filtering options (single_hash or multiple_hashes)
|
||||
favorites_only: Filter for favorite models only
|
||||
first_letter: Filter by first letter of model name
|
||||
"""
|
||||
cache = await self.get_cached_data()
|
||||
|
||||
# Get default search options if not provided
|
||||
if search_options is None:
|
||||
search_options = {
|
||||
'filename': True,
|
||||
'modelname': True,
|
||||
'tags': False,
|
||||
'recursive': False,
|
||||
}
|
||||
|
||||
# Get the base data set
|
||||
filtered_data = cache.sorted_by_date if sort_by == 'date' else cache.sorted_by_name
|
||||
|
||||
# Apply hash filtering if provided (highest priority)
|
||||
if hash_filters:
|
||||
single_hash = hash_filters.get('single_hash')
|
||||
multiple_hashes = hash_filters.get('multiple_hashes')
|
||||
|
||||
if single_hash:
|
||||
# Filter by single hash
|
||||
single_hash = single_hash.lower() # Ensure lowercase for matching
|
||||
filtered_data = [
|
||||
lora for lora in filtered_data
|
||||
if lora.get('sha256', '').lower() == single_hash
|
||||
]
|
||||
elif multiple_hashes:
|
||||
# Filter by multiple hashes
|
||||
hash_set = set(hash.lower() for hash in multiple_hashes) # Convert to set for faster lookup
|
||||
filtered_data = [
|
||||
lora for lora in filtered_data
|
||||
if lora.get('sha256', '').lower() in hash_set
|
||||
]
|
||||
|
||||
|
||||
# Jump to pagination
|
||||
total_items = len(filtered_data)
|
||||
start_idx = (page - 1) * page_size
|
||||
end_idx = min(start_idx + page_size, total_items)
|
||||
|
||||
result = {
|
||||
'items': filtered_data[start_idx:end_idx],
|
||||
'total': total_items,
|
||||
'page': page,
|
||||
'page_size': page_size,
|
||||
'total_pages': (total_items + page_size - 1) // page_size
|
||||
}
|
||||
|
||||
return result
|
||||
|
||||
# Apply SFW filtering if enabled
|
||||
if settings.get('show_only_sfw', False):
|
||||
filtered_data = [
|
||||
lora for lora in filtered_data
|
||||
if not lora.get('preview_nsfw_level') or lora.get('preview_nsfw_level') < NSFW_LEVELS['R']
|
||||
]
|
||||
|
||||
# Apply favorites filtering if enabled
|
||||
if favorites_only:
|
||||
filtered_data = [
|
||||
lora for lora in filtered_data
|
||||
if lora.get('favorite', False) is True
|
||||
]
|
||||
|
||||
# Apply first letter filtering
|
||||
if first_letter:
|
||||
filtered_data = self._filter_by_first_letter(filtered_data, first_letter)
|
||||
|
||||
# Apply folder filtering
|
||||
if folder is not None:
|
||||
if search_options.get('recursive', False):
|
||||
# Recursive folder filtering - include all subfolders
|
||||
filtered_data = [
|
||||
lora for lora in filtered_data
|
||||
if lora['folder'].startswith(folder)
|
||||
]
|
||||
else:
|
||||
# Exact folder filtering
|
||||
filtered_data = [
|
||||
lora for lora in filtered_data
|
||||
if lora['folder'] == folder
|
||||
]
|
||||
|
||||
# Apply base model filtering
|
||||
if base_models and len(base_models) > 0:
|
||||
filtered_data = [
|
||||
lora for lora in filtered_data
|
||||
if lora.get('base_model') in base_models
|
||||
]
|
||||
|
||||
# Apply tag filtering
|
||||
if tags and len(tags) > 0:
|
||||
filtered_data = [
|
||||
lora for lora in filtered_data
|
||||
if any(tag in lora.get('tags', []) for tag in tags)
|
||||
]
|
||||
|
||||
# Apply search filtering
|
||||
if search:
|
||||
search_results = []
|
||||
search_opts = search_options or {}
|
||||
|
||||
for lora in filtered_data:
|
||||
# Search by file name
|
||||
if search_opts.get('filename', True):
|
||||
if fuzzy_match(lora.get('file_name', ''), search):
|
||||
search_results.append(lora)
|
||||
continue
|
||||
|
||||
# Search by model name
|
||||
if search_opts.get('modelname', True):
|
||||
if fuzzy_match(lora.get('model_name', ''), search):
|
||||
search_results.append(lora)
|
||||
continue
|
||||
|
||||
# Search by tags
|
||||
if search_opts.get('tags', False) and 'tags' in lora:
|
||||
if any(fuzzy_match(tag, search) for tag in lora['tags']):
|
||||
search_results.append(lora)
|
||||
continue
|
||||
|
||||
filtered_data = search_results
|
||||
|
||||
# Calculate pagination
|
||||
total_items = len(filtered_data)
|
||||
start_idx = (page - 1) * page_size
|
||||
end_idx = min(start_idx + page_size, total_items)
|
||||
|
||||
result = {
|
||||
'items': filtered_data[start_idx:end_idx],
|
||||
'total': total_items,
|
||||
'page': page,
|
||||
'page_size': page_size,
|
||||
'total_pages': (total_items + page_size - 1) // page_size
|
||||
}
|
||||
|
||||
return result
|
||||
|
||||
def _filter_by_first_letter(self, data, letter):
|
||||
"""Filter data by first letter of model name
|
||||
|
||||
Special handling:
|
||||
- '#': Numbers (0-9)
|
||||
- '@': Special characters (not alphanumeric)
|
||||
- '漢': CJK characters
|
||||
"""
|
||||
filtered_data = []
|
||||
|
||||
for lora in data:
|
||||
model_name = lora.get('model_name', '')
|
||||
if not model_name:
|
||||
continue
|
||||
|
||||
first_char = model_name[0].upper()
|
||||
|
||||
if letter == '#' and first_char.isdigit():
|
||||
filtered_data.append(lora)
|
||||
elif letter == '@' and not first_char.isalnum():
|
||||
# Special characters (not alphanumeric)
|
||||
filtered_data.append(lora)
|
||||
elif letter == '漢' and self._is_cjk_character(first_char):
|
||||
# CJK characters
|
||||
filtered_data.append(lora)
|
||||
elif letter.upper() == first_char:
|
||||
# Regular alphabet matching
|
||||
filtered_data.append(lora)
|
||||
|
||||
return filtered_data
|
||||
|
||||
def _is_cjk_character(self, char):
|
||||
"""Check if character is a CJK character"""
|
||||
# Define Unicode ranges for CJK characters
|
||||
cjk_ranges = [
|
||||
(0x4E00, 0x9FFF), # CJK Unified Ideographs
|
||||
(0x3400, 0x4DBF), # CJK Unified Ideographs Extension A
|
||||
(0x20000, 0x2A6DF), # CJK Unified Ideographs Extension B
|
||||
(0x2A700, 0x2B73F), # CJK Unified Ideographs Extension C
|
||||
(0x2B740, 0x2B81F), # CJK Unified Ideographs Extension D
|
||||
(0x2B820, 0x2CEAF), # CJK Unified Ideographs Extension E
|
||||
(0x2CEB0, 0x2EBEF), # CJK Unified Ideographs Extension F
|
||||
(0x30000, 0x3134F), # CJK Unified Ideographs Extension G
|
||||
(0xF900, 0xFAFF), # CJK Compatibility Ideographs
|
||||
(0x3300, 0x33FF), # CJK Compatibility
|
||||
(0x3200, 0x32FF), # Enclosed CJK Letters and Months
|
||||
(0x3100, 0x312F), # Bopomofo
|
||||
(0x31A0, 0x31BF), # Bopomofo Extended
|
||||
(0x3040, 0x309F), # Hiragana
|
||||
(0x30A0, 0x30FF), # Katakana
|
||||
(0x31F0, 0x31FF), # Katakana Phonetic Extensions
|
||||
(0xAC00, 0xD7AF), # Hangul Syllables
|
||||
(0x1100, 0x11FF), # Hangul Jamo
|
||||
(0xA960, 0xA97F), # Hangul Jamo Extended-A
|
||||
(0xD7B0, 0xD7FF), # Hangul Jamo Extended-B
|
||||
]
|
||||
|
||||
code_point = ord(char)
|
||||
return any(start <= code_point <= end for start, end in cjk_ranges)
|
||||
|
||||
async def get_letter_counts(self):
|
||||
"""Get count of models for each letter of the alphabet"""
|
||||
cache = await self.get_cached_data()
|
||||
data = cache.sorted_by_name
|
||||
|
||||
# Define letter categories
|
||||
letters = {
|
||||
'#': 0, # Numbers
|
||||
'A': 0, 'B': 0, 'C': 0, 'D': 0, 'E': 0, 'F': 0, 'G': 0, 'H': 0,
|
||||
'I': 0, 'J': 0, 'K': 0, 'L': 0, 'M': 0, 'N': 0, 'O': 0, 'P': 0,
|
||||
'Q': 0, 'R': 0, 'S': 0, 'T': 0, 'U': 0, 'V': 0, 'W': 0, 'X': 0,
|
||||
'Y': 0, 'Z': 0,
|
||||
'@': 0, # Special characters
|
||||
'漢': 0 # CJK characters
|
||||
}
|
||||
|
||||
# Count models for each letter
|
||||
for lora in data:
|
||||
model_name = lora.get('model_name', '')
|
||||
if not model_name:
|
||||
continue
|
||||
|
||||
first_char = model_name[0].upper()
|
||||
|
||||
if first_char.isdigit():
|
||||
letters['#'] += 1
|
||||
elif first_char in letters:
|
||||
letters[first_char] += 1
|
||||
elif self._is_cjk_character(first_char):
|
||||
letters['漢'] += 1
|
||||
elif not first_char.isalnum():
|
||||
letters['@'] += 1
|
||||
|
||||
return letters
|
||||
|
||||
async def _update_metadata_paths(self, metadata_path: str, lora_path: str) -> Dict:
|
||||
"""Update file paths in metadata file"""
|
||||
try:
|
||||
with open(metadata_path, 'r', encoding='utf-8') as f:
|
||||
metadata = json.load(f)
|
||||
|
||||
# Update file_path
|
||||
metadata['file_path'] = lora_path.replace(os.sep, '/')
|
||||
|
||||
# Update preview_url if exists
|
||||
if 'preview_url' in metadata:
|
||||
preview_dir = os.path.dirname(lora_path)
|
||||
preview_name = os.path.splitext(os.path.basename(metadata['preview_url']))[0]
|
||||
preview_ext = os.path.splitext(metadata['preview_url'])[1]
|
||||
new_preview_path = os.path.join(preview_dir, f"{preview_name}{preview_ext}")
|
||||
metadata['preview_url'] = new_preview_path.replace(os.sep, '/')
|
||||
|
||||
# Save updated metadata
|
||||
with open(metadata_path, 'w', encoding='utf-8') as f:
|
||||
json.dump(metadata, f, indent=2, ensure_ascii=False)
|
||||
|
||||
return metadata
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error updating metadata paths: {e}", exc_info=True)
|
||||
|
||||
# Lora-specific hash index functionality
|
||||
def has_lora_hash(self, sha256: str) -> bool:
|
||||
"""Check if a LoRA with given hash exists"""
|
||||
return self.has_hash(sha256)
|
||||
|
||||
def get_lora_path_by_hash(self, sha256: str) -> Optional[str]:
|
||||
"""Get file path for a LoRA by its hash"""
|
||||
return self.get_path_by_hash(sha256)
|
||||
|
||||
def get_lora_hash_by_path(self, file_path: str) -> Optional[str]:
|
||||
"""Get hash for a LoRA by its file path"""
|
||||
return self.get_hash_by_path(file_path)
|
||||
|
||||
async def get_top_tags(self, limit: int = 20) -> List[Dict[str, any]]:
|
||||
"""Get top tags sorted by count"""
|
||||
# Make sure cache is initialized
|
||||
await self.get_cached_data()
|
||||
|
||||
# Sort tags by count in descending order
|
||||
sorted_tags = sorted(
|
||||
[{"tag": tag, "count": count} for tag, count in self._tags_count.items()],
|
||||
key=lambda x: x['count'],
|
||||
reverse=True
|
||||
)
|
||||
|
||||
# Return limited number
|
||||
return sorted_tags[:limit]
|
||||
|
||||
async def get_base_models(self, limit: int = 20) -> List[Dict[str, any]]:
|
||||
"""Get base models used in loras sorted by frequency"""
|
||||
# Make sure cache is initialized
|
||||
cache = await self.get_cached_data()
|
||||
|
||||
# Count base model occurrences
|
||||
base_model_counts = {}
|
||||
for lora in cache.raw_data:
|
||||
if 'base_model' in lora and lora['base_model']:
|
||||
base_model = lora['base_model']
|
||||
base_model_counts[base_model] = base_model_counts.get(base_model, 0) + 1
|
||||
|
||||
# Sort base models by count
|
||||
sorted_models = [{'name': model, 'count': count} for model, count in base_model_counts.items()]
|
||||
sorted_models.sort(key=lambda x: x['count'], reverse=True)
|
||||
|
||||
# Return limited number
|
||||
return sorted_models[:limit]
|
||||
|
||||
async def diagnose_hash_index(self):
|
||||
"""Diagnostic method to verify hash index functionality"""
|
||||
@@ -482,19 +63,3 @@ class LoraScanner(ModelScanner):
|
||||
test_hash_result = self._hash_index.get_hash(test_path)
|
||||
print(f"Test reverse lookup: {test_path} -> {test_hash_result[:8]}...\n\n", file=sys.stderr)
|
||||
|
||||
async def get_lora_info_by_name(self, name):
|
||||
"""Get LoRA information by name"""
|
||||
try:
|
||||
# Get cached data
|
||||
cache = await self.get_cached_data()
|
||||
|
||||
# Find the LoRA by name
|
||||
for lora in cache.raw_data:
|
||||
if lora.get("file_name") == name:
|
||||
return lora
|
||||
|
||||
return None
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting LoRA info by name: {e}", exc_info=True)
|
||||
return None
|
||||
|
||||
|
||||
182
py/services/lora_service.py
Normal file
182
py/services/lora_service.py
Normal file
@@ -0,0 +1,182 @@
|
||||
import os
|
||||
import logging
|
||||
from typing import Dict, List, Optional
|
||||
|
||||
from .base_model_service import BaseModelService
|
||||
from ..utils.models import LoraMetadata
|
||||
from ..config import config
|
||||
from ..utils.routes_common import ModelRouteUtils
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class LoraService(BaseModelService):
|
||||
"""LoRA-specific service implementation"""
|
||||
|
||||
def __init__(self, scanner):
|
||||
"""Initialize LoRA service
|
||||
|
||||
Args:
|
||||
scanner: LoRA scanner instance
|
||||
"""
|
||||
super().__init__("lora", scanner, LoraMetadata)
|
||||
|
||||
async def format_response(self, lora_data: Dict) -> Dict:
|
||||
"""Format LoRA data for API response"""
|
||||
return {
|
||||
"model_name": lora_data["model_name"],
|
||||
"file_name": lora_data["file_name"],
|
||||
"preview_url": config.get_preview_static_url(lora_data.get("preview_url", "")),
|
||||
"preview_nsfw_level": lora_data.get("preview_nsfw_level", 0),
|
||||
"base_model": lora_data.get("base_model", ""),
|
||||
"folder": lora_data["folder"],
|
||||
"sha256": lora_data.get("sha256", ""),
|
||||
"file_path": lora_data["file_path"].replace(os.sep, "/"),
|
||||
"file_size": lora_data.get("size", 0),
|
||||
"modified": lora_data.get("modified", ""),
|
||||
"tags": lora_data.get("tags", []),
|
||||
"from_civitai": lora_data.get("from_civitai", True),
|
||||
"usage_tips": lora_data.get("usage_tips", ""),
|
||||
"notes": lora_data.get("notes", ""),
|
||||
"favorite": lora_data.get("favorite", False),
|
||||
"civitai": ModelRouteUtils.filter_civitai_data(lora_data.get("civitai", {}), minimal=True)
|
||||
}
|
||||
|
||||
async def _apply_specific_filters(self, data: List[Dict], **kwargs) -> List[Dict]:
|
||||
"""Apply LoRA-specific filters"""
|
||||
# Handle first_letter filter for LoRAs
|
||||
first_letter = kwargs.get('first_letter')
|
||||
if first_letter:
|
||||
data = self._filter_by_first_letter(data, first_letter)
|
||||
|
||||
return data
|
||||
|
||||
def _filter_by_first_letter(self, data: List[Dict], letter: str) -> List[Dict]:
|
||||
"""Filter data by first letter of model name
|
||||
|
||||
Special handling:
|
||||
- '#': Numbers (0-9)
|
||||
- '@': Special characters (not alphanumeric)
|
||||
- '漢': CJK characters
|
||||
"""
|
||||
filtered_data = []
|
||||
|
||||
for lora in data:
|
||||
model_name = lora.get('model_name', '')
|
||||
if not model_name:
|
||||
continue
|
||||
|
||||
first_char = model_name[0].upper()
|
||||
|
||||
if letter == '#' and first_char.isdigit():
|
||||
filtered_data.append(lora)
|
||||
elif letter == '@' and not first_char.isalnum():
|
||||
# Special characters (not alphanumeric)
|
||||
filtered_data.append(lora)
|
||||
elif letter == '漢' and self._is_cjk_character(first_char):
|
||||
# CJK characters
|
||||
filtered_data.append(lora)
|
||||
elif letter.upper() == first_char:
|
||||
# Regular alphabet matching
|
||||
filtered_data.append(lora)
|
||||
|
||||
return filtered_data
|
||||
|
||||
def _is_cjk_character(self, char: str) -> bool:
|
||||
"""Check if character is a CJK character"""
|
||||
# Define Unicode ranges for CJK characters
|
||||
cjk_ranges = [
|
||||
(0x4E00, 0x9FFF), # CJK Unified Ideographs
|
||||
(0x3400, 0x4DBF), # CJK Unified Ideographs Extension A
|
||||
(0x20000, 0x2A6DF), # CJK Unified Ideographs Extension B
|
||||
(0x2A700, 0x2B73F), # CJK Unified Ideographs Extension C
|
||||
(0x2B740, 0x2B81F), # CJK Unified Ideographs Extension D
|
||||
(0x2B820, 0x2CEAF), # CJK Unified Ideographs Extension E
|
||||
(0x2CEB0, 0x2EBEF), # CJK Unified Ideographs Extension F
|
||||
(0x30000, 0x3134F), # CJK Unified Ideographs Extension G
|
||||
(0xF900, 0xFAFF), # CJK Compatibility Ideographs
|
||||
(0x3300, 0x33FF), # CJK Compatibility
|
||||
(0x3200, 0x32FF), # Enclosed CJK Letters and Months
|
||||
(0x3100, 0x312F), # Bopomofo
|
||||
(0x31A0, 0x31BF), # Bopomofo Extended
|
||||
(0x3040, 0x309F), # Hiragana
|
||||
(0x30A0, 0x30FF), # Katakana
|
||||
(0x31F0, 0x31FF), # Katakana Phonetic Extensions
|
||||
(0xAC00, 0xD7AF), # Hangul Syllables
|
||||
(0x1100, 0x11FF), # Hangul Jamo
|
||||
(0xA960, 0xA97F), # Hangul Jamo Extended-A
|
||||
(0xD7B0, 0xD7FF), # Hangul Jamo Extended-B
|
||||
]
|
||||
|
||||
code_point = ord(char)
|
||||
return any(start <= code_point <= end for start, end in cjk_ranges)
|
||||
|
||||
# LoRA-specific methods
|
||||
async def get_letter_counts(self) -> Dict[str, int]:
|
||||
"""Get count of LoRAs for each letter of the alphabet"""
|
||||
cache = await self.scanner.get_cached_data()
|
||||
data = cache.raw_data
|
||||
|
||||
# Define letter categories
|
||||
letters = {
|
||||
'#': 0, # Numbers
|
||||
'A': 0, 'B': 0, 'C': 0, 'D': 0, 'E': 0, 'F': 0, 'G': 0, 'H': 0,
|
||||
'I': 0, 'J': 0, 'K': 0, 'L': 0, 'M': 0, 'N': 0, 'O': 0, 'P': 0,
|
||||
'Q': 0, 'R': 0, 'S': 0, 'T': 0, 'U': 0, 'V': 0, 'W': 0, 'X': 0,
|
||||
'Y': 0, 'Z': 0,
|
||||
'@': 0, # Special characters
|
||||
'漢': 0 # CJK characters
|
||||
}
|
||||
|
||||
# Count models for each letter
|
||||
for lora in data:
|
||||
model_name = lora.get('model_name', '')
|
||||
if not model_name:
|
||||
continue
|
||||
|
||||
first_char = model_name[0].upper()
|
||||
|
||||
if first_char.isdigit():
|
||||
letters['#'] += 1
|
||||
elif first_char in letters:
|
||||
letters[first_char] += 1
|
||||
elif self._is_cjk_character(first_char):
|
||||
letters['漢'] += 1
|
||||
elif not first_char.isalnum():
|
||||
letters['@'] += 1
|
||||
|
||||
return letters
|
||||
|
||||
async def get_lora_trigger_words(self, lora_name: str) -> List[str]:
|
||||
"""Get trigger words for a specific LoRA file"""
|
||||
cache = await self.scanner.get_cached_data()
|
||||
|
||||
for lora in cache.raw_data:
|
||||
if lora['file_name'] == lora_name:
|
||||
civitai_data = lora.get('civitai', {})
|
||||
return civitai_data.get('trainedWords', [])
|
||||
|
||||
return []
|
||||
|
||||
async def get_lora_usage_tips_by_relative_path(self, relative_path: str) -> Optional[str]:
|
||||
"""Get usage tips for a LoRA by its relative path"""
|
||||
cache = await self.scanner.get_cached_data()
|
||||
|
||||
for lora in cache.raw_data:
|
||||
file_path = lora.get('file_path', '')
|
||||
if file_path:
|
||||
# Convert to forward slashes and extract relative path
|
||||
file_path_normalized = file_path.replace('\\', '/')
|
||||
relative_path = relative_path.replace('\\', '/')
|
||||
# Find the relative path part by looking for the relative_path in the full path
|
||||
if file_path_normalized.endswith(relative_path) or relative_path in file_path_normalized:
|
||||
return lora.get('usage_tips', '')
|
||||
|
||||
return None
|
||||
|
||||
def find_duplicate_hashes(self) -> Dict:
|
||||
"""Find LoRAs with duplicate SHA256 hashes"""
|
||||
return self.scanner._hash_index.get_duplicate_hashes()
|
||||
|
||||
def find_duplicate_filenames(self) -> Dict:
|
||||
"""Find LoRAs with conflicting filenames"""
|
||||
return self.scanner._hash_index.get_duplicate_filenames()
|
||||
151
py/services/metadata_archive_manager.py
Normal file
151
py/services/metadata_archive_manager.py
Normal file
@@ -0,0 +1,151 @@
|
||||
import zipfile
|
||||
import logging
|
||||
import asyncio
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
from .downloader import get_downloader
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class MetadataArchiveManager:
|
||||
"""Manages downloading and extracting Civitai metadata archive database"""
|
||||
|
||||
DOWNLOAD_URLS = [
|
||||
"https://github.com/willmiao/civitai-metadata-archive-db/releases/download/db-2025-08-08/civitai.zip",
|
||||
"https://huggingface.co/datasets/willmiao/civitai-metadata-archive-db/blob/main/civitai.zip"
|
||||
]
|
||||
|
||||
def __init__(self, base_path: str):
|
||||
"""Initialize with base path where files will be stored"""
|
||||
self.base_path = Path(base_path)
|
||||
self.civitai_folder = self.base_path / "civitai"
|
||||
self.archive_path = self.base_path / "civitai.zip"
|
||||
self.db_path = self.civitai_folder / "civitai.sqlite"
|
||||
|
||||
def is_database_available(self) -> bool:
|
||||
"""Check if the SQLite database is available and valid"""
|
||||
return self.db_path.exists() and self.db_path.stat().st_size > 0
|
||||
|
||||
def get_database_path(self) -> Optional[str]:
|
||||
"""Get the path to the SQLite database if available"""
|
||||
if self.is_database_available():
|
||||
return str(self.db_path)
|
||||
return None
|
||||
|
||||
async def download_and_extract_database(self, progress_callback=None) -> bool:
|
||||
"""Download and extract the metadata archive database
|
||||
|
||||
Args:
|
||||
progress_callback: Optional callback function to report progress
|
||||
|
||||
Returns:
|
||||
bool: True if successful, False otherwise
|
||||
"""
|
||||
try:
|
||||
# Create directories if they don't exist
|
||||
self.base_path.mkdir(parents=True, exist_ok=True)
|
||||
self.civitai_folder.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
# Download the archive
|
||||
if not await self._download_archive(progress_callback):
|
||||
return False
|
||||
|
||||
# Extract the archive
|
||||
if not await self._extract_archive(progress_callback):
|
||||
return False
|
||||
|
||||
# Clean up the archive file
|
||||
if self.archive_path.exists():
|
||||
self.archive_path.unlink()
|
||||
|
||||
logger.info(f"Successfully downloaded and extracted metadata database to {self.db_path}")
|
||||
return True
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error downloading and extracting metadata database: {e}", exc_info=True)
|
||||
return False
|
||||
|
||||
async def _download_archive(self, progress_callback=None) -> bool:
|
||||
"""Download the zip archive from one of the available URLs"""
|
||||
downloader = await get_downloader()
|
||||
|
||||
for url in self.DOWNLOAD_URLS:
|
||||
try:
|
||||
logger.info(f"Attempting to download from {url}")
|
||||
|
||||
if progress_callback:
|
||||
progress_callback("download", f"Downloading from {url}")
|
||||
|
||||
# Custom progress callback to report download progress
|
||||
async def download_progress(progress):
|
||||
if progress_callback:
|
||||
progress_callback("download", f"Downloading archive... {progress:.1f}%")
|
||||
|
||||
success, result = await downloader.download_file(
|
||||
url=url,
|
||||
save_path=str(self.archive_path),
|
||||
progress_callback=download_progress,
|
||||
use_auth=False, # Public download, no auth needed
|
||||
allow_resume=True
|
||||
)
|
||||
|
||||
if success:
|
||||
logger.info(f"Successfully downloaded archive from {url}")
|
||||
return True
|
||||
else:
|
||||
logger.warning(f"Failed to download from {url}: {result}")
|
||||
continue
|
||||
|
||||
except Exception as e:
|
||||
logger.warning(f"Error downloading from {url}: {e}")
|
||||
continue
|
||||
|
||||
logger.error("Failed to download archive from any URL")
|
||||
return False
|
||||
|
||||
async def _extract_archive(self, progress_callback=None) -> bool:
|
||||
"""Extract the zip archive to the civitai folder"""
|
||||
try:
|
||||
if progress_callback:
|
||||
progress_callback("extract", "Extracting archive...")
|
||||
|
||||
# Run extraction in thread pool to avoid blocking
|
||||
loop = asyncio.get_event_loop()
|
||||
await loop.run_in_executor(None, self._extract_zip_sync)
|
||||
|
||||
if progress_callback:
|
||||
progress_callback("extract", "Extraction completed")
|
||||
|
||||
return True
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error extracting archive: {e}", exc_info=True)
|
||||
return False
|
||||
|
||||
def _extract_zip_sync(self):
|
||||
"""Synchronous zip extraction (runs in thread pool)"""
|
||||
with zipfile.ZipFile(self.archive_path, 'r') as archive:
|
||||
archive.extractall(path=self.base_path)
|
||||
|
||||
async def remove_database(self) -> bool:
|
||||
"""Remove the metadata database and folder"""
|
||||
try:
|
||||
if self.civitai_folder.exists():
|
||||
# Remove all files in the civitai folder
|
||||
for file_path in self.civitai_folder.iterdir():
|
||||
if file_path.is_file():
|
||||
file_path.unlink()
|
||||
|
||||
# Remove the folder itself
|
||||
self.civitai_folder.rmdir()
|
||||
|
||||
# Also remove the archive file if it exists
|
||||
if self.archive_path.exists():
|
||||
self.archive_path.unlink()
|
||||
|
||||
logger.info("Successfully removed metadata database")
|
||||
return True
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error removing metadata database: {e}", exc_info=True)
|
||||
return False
|
||||
117
py/services/metadata_service.py
Normal file
117
py/services/metadata_service.py
Normal file
@@ -0,0 +1,117 @@
|
||||
import os
|
||||
import logging
|
||||
from .model_metadata_provider import (
|
||||
ModelMetadataProviderManager,
|
||||
SQLiteModelMetadataProvider,
|
||||
CivitaiModelMetadataProvider,
|
||||
FallbackMetadataProvider
|
||||
)
|
||||
from .settings_manager import settings
|
||||
from .metadata_archive_manager import MetadataArchiveManager
|
||||
from .service_registry import ServiceRegistry
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
async def initialize_metadata_providers():
|
||||
"""Initialize and configure all metadata providers based on settings"""
|
||||
provider_manager = await ModelMetadataProviderManager.get_instance()
|
||||
|
||||
# Clear existing providers to allow reinitialization
|
||||
provider_manager.providers.clear()
|
||||
provider_manager.default_provider = None
|
||||
|
||||
# Get settings
|
||||
enable_archive_db = settings.get('enable_metadata_archive_db', False)
|
||||
|
||||
providers = []
|
||||
|
||||
# Initialize archive database provider if enabled
|
||||
if enable_archive_db:
|
||||
try:
|
||||
# Initialize archive manager
|
||||
base_path = os.path.dirname(os.path.dirname(os.path.dirname(__file__)))
|
||||
archive_manager = MetadataArchiveManager(base_path)
|
||||
|
||||
db_path = archive_manager.get_database_path()
|
||||
if db_path and os.path.exists(db_path):
|
||||
sqlite_provider = SQLiteModelMetadataProvider(db_path)
|
||||
provider_manager.register_provider('sqlite', sqlite_provider)
|
||||
providers.append(('sqlite', sqlite_provider))
|
||||
logger.info(f"SQLite metadata provider registered with database: {db_path}")
|
||||
else:
|
||||
logger.warning("Metadata archive database is enabled but database file not found")
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to initialize SQLite metadata provider: {e}")
|
||||
|
||||
# Initialize Civitai API provider (always available as fallback)
|
||||
try:
|
||||
civitai_client = await ServiceRegistry.get_civitai_client()
|
||||
civitai_provider = CivitaiModelMetadataProvider(civitai_client)
|
||||
provider_manager.register_provider('civitai_api', civitai_provider)
|
||||
providers.append(('civitai_api', civitai_provider))
|
||||
logger.debug("Civitai API metadata provider registered")
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to initialize Civitai API metadata provider: {e}")
|
||||
|
||||
# Register CivArchive provider, but do NOT add to fallback providers
|
||||
try:
|
||||
from .model_metadata_provider import CivArchiveModelMetadataProvider
|
||||
civarchive_provider = CivArchiveModelMetadataProvider()
|
||||
provider_manager.register_provider('civarchive', civarchive_provider)
|
||||
logger.debug("CivArchive metadata provider registered (not included in fallback)")
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to initialize CivArchive metadata provider: {e}")
|
||||
|
||||
# Set up fallback provider based on available providers
|
||||
if len(providers) > 1:
|
||||
# Always use Civitai API first, then Archive DB
|
||||
ordered_providers = []
|
||||
ordered_providers.extend([p[1] for p in providers if p[0] == 'civitai_api'])
|
||||
ordered_providers.extend([p[1] for p in providers if p[0] == 'sqlite'])
|
||||
|
||||
if ordered_providers:
|
||||
fallback_provider = FallbackMetadataProvider(ordered_providers)
|
||||
provider_manager.register_provider('fallback', fallback_provider, is_default=True)
|
||||
logger.info(f"Fallback metadata provider registered with {len(ordered_providers)} providers, Civitai API first")
|
||||
elif len(providers) == 1:
|
||||
# Only one provider available, set it as default
|
||||
provider_name, provider = providers[0]
|
||||
provider_manager.register_provider(provider_name, provider, is_default=True)
|
||||
logger.debug(f"Single metadata provider registered as default: {provider_name}")
|
||||
else:
|
||||
logger.warning("No metadata providers available - this may cause metadata lookup failures")
|
||||
|
||||
return provider_manager
|
||||
|
||||
async def update_metadata_providers():
|
||||
"""Update metadata providers based on current settings"""
|
||||
try:
|
||||
# Get current settings
|
||||
enable_archive_db = settings.get('enable_metadata_archive_db', False)
|
||||
|
||||
# Reinitialize all providers with new settings
|
||||
provider_manager = await initialize_metadata_providers()
|
||||
|
||||
logger.info(f"Updated metadata providers, archive_db enabled: {enable_archive_db}")
|
||||
return provider_manager
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to update metadata providers: {e}")
|
||||
return await ModelMetadataProviderManager.get_instance()
|
||||
|
||||
async def get_metadata_archive_manager():
|
||||
"""Get metadata archive manager instance"""
|
||||
base_path = os.path.dirname(os.path.dirname(os.path.dirname(__file__)))
|
||||
return MetadataArchiveManager(base_path)
|
||||
|
||||
async def get_metadata_provider(provider_name: str = None):
|
||||
"""Get a specific metadata provider or default provider"""
|
||||
provider_manager = await ModelMetadataProviderManager.get_instance()
|
||||
|
||||
if provider_name:
|
||||
return provider_manager._get_provider(provider_name)
|
||||
|
||||
return provider_manager._get_provider()
|
||||
|
||||
async def get_default_metadata_provider():
|
||||
"""Get the default metadata provider (fallback or single provider)"""
|
||||
return await get_metadata_provider()
|
||||
@@ -1,43 +1,92 @@
|
||||
import asyncio
|
||||
from typing import List, Dict
|
||||
from typing import List, Dict, Tuple
|
||||
from dataclasses import dataclass
|
||||
from operator import itemgetter
|
||||
from natsort import natsorted
|
||||
|
||||
# Supported sort modes: (sort_key, order)
|
||||
# order: 'asc' for ascending, 'desc' for descending
|
||||
SUPPORTED_SORT_MODES = [
|
||||
('name', 'asc'),
|
||||
('name', 'desc'),
|
||||
('date', 'asc'),
|
||||
('date', 'desc'),
|
||||
('size', 'asc'),
|
||||
('size', 'desc'),
|
||||
]
|
||||
|
||||
@dataclass
|
||||
class ModelCache:
|
||||
"""Cache structure for model data"""
|
||||
"""Cache structure for model data with extensible sorting"""
|
||||
raw_data: List[Dict]
|
||||
sorted_by_name: List[Dict]
|
||||
sorted_by_date: List[Dict]
|
||||
folders: List[str]
|
||||
|
||||
def __post_init__(self):
|
||||
self._lock = asyncio.Lock()
|
||||
# Cache for last sort: (sort_key, order) -> sorted list
|
||||
self._last_sort: Tuple[str, str] = (None, None)
|
||||
self._last_sorted_data: List[Dict] = []
|
||||
# Default sort on init
|
||||
asyncio.create_task(self.resort())
|
||||
|
||||
async def resort(self, name_only: bool = False):
|
||||
"""Resort all cached data views"""
|
||||
async def resort(self):
|
||||
"""Resort cached data according to last sort mode if set"""
|
||||
async with self._lock:
|
||||
self.sorted_by_name = natsorted(
|
||||
self.raw_data,
|
||||
key=lambda x: x['model_name'].lower() # Case-insensitive sort
|
||||
)
|
||||
if not name_only:
|
||||
self.sorted_by_date = sorted(
|
||||
self.raw_data,
|
||||
key=itemgetter('modified'),
|
||||
reverse=True
|
||||
)
|
||||
# Update folder list
|
||||
if self._last_sort != (None, None):
|
||||
sort_key, order = self._last_sort
|
||||
sorted_data = self._sort_data(self.raw_data, sort_key, order)
|
||||
self._last_sorted_data = sorted_data
|
||||
# Update folder list
|
||||
# else: do nothing
|
||||
|
||||
all_folders = set(l['folder'] for l in self.raw_data)
|
||||
self.folders = sorted(list(all_folders), key=lambda x: x.lower())
|
||||
|
||||
async def update_preview_url(self, file_path: str, preview_url: str) -> bool:
|
||||
def _sort_data(self, data: List[Dict], sort_key: str, order: str) -> List[Dict]:
|
||||
"""Sort data by sort_key and order"""
|
||||
reverse = (order == 'desc')
|
||||
if sort_key == 'name':
|
||||
# Natural sort by model_name, case-insensitive
|
||||
return natsorted(
|
||||
data,
|
||||
key=lambda x: x['model_name'].lower(),
|
||||
reverse=reverse
|
||||
)
|
||||
elif sort_key == 'date':
|
||||
# Sort by modified timestamp
|
||||
return sorted(
|
||||
data,
|
||||
key=itemgetter('modified'),
|
||||
reverse=reverse
|
||||
)
|
||||
elif sort_key == 'size':
|
||||
# Sort by file size
|
||||
return sorted(
|
||||
data,
|
||||
key=itemgetter('size'),
|
||||
reverse=reverse
|
||||
)
|
||||
else:
|
||||
# Fallback: no sort
|
||||
return list(data)
|
||||
|
||||
async def get_sorted_data(self, sort_key: str = 'name', order: str = 'asc') -> List[Dict]:
|
||||
"""Get sorted data by sort_key and order, using cache if possible"""
|
||||
async with self._lock:
|
||||
if (sort_key, order) == self._last_sort:
|
||||
return self._last_sorted_data
|
||||
sorted_data = self._sort_data(self.raw_data, sort_key, order)
|
||||
self._last_sort = (sort_key, order)
|
||||
self._last_sorted_data = sorted_data
|
||||
return sorted_data
|
||||
|
||||
async def update_preview_url(self, file_path: str, preview_url: str, preview_nsfw_level: int) -> bool:
|
||||
"""Update preview_url for a specific model in all cached data
|
||||
|
||||
Args:
|
||||
file_path: The file path of the model to update
|
||||
preview_url: The new preview URL
|
||||
preview_nsfw_level: The NSFW level of the preview
|
||||
|
||||
Returns:
|
||||
bool: True if the update was successful, False if the model wasn't found
|
||||
@@ -47,19 +96,9 @@ class ModelCache:
|
||||
for item in self.raw_data:
|
||||
if item['file_path'] == file_path:
|
||||
item['preview_url'] = preview_url
|
||||
item['preview_nsfw_level'] = preview_nsfw_level
|
||||
break
|
||||
else:
|
||||
return False # Model not found
|
||||
|
||||
# Update in sorted lists (references to the same dict objects)
|
||||
for item in self.sorted_by_name:
|
||||
if item['file_path'] == file_path:
|
||||
item['preview_url'] = preview_url
|
||||
break
|
||||
|
||||
for item in self.sorted_by_date:
|
||||
if item['file_path'] == file_path:
|
||||
item['preview_url'] = preview_url
|
||||
break
|
||||
|
||||
return True
|
||||
463
py/services/model_file_service.py
Normal file
463
py/services/model_file_service.py
Normal file
@@ -0,0 +1,463 @@
|
||||
import asyncio
|
||||
import os
|
||||
import logging
|
||||
from typing import List, Dict, Optional, Any, Set
|
||||
from abc import ABC, abstractmethod
|
||||
|
||||
from ..utils.utils import calculate_relative_path_for_model, remove_empty_dirs
|
||||
from ..utils.constants import AUTO_ORGANIZE_BATCH_SIZE
|
||||
from ..services.settings_manager import settings
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class ProgressCallback(ABC):
|
||||
"""Abstract callback interface for progress reporting"""
|
||||
|
||||
@abstractmethod
|
||||
async def on_progress(self, progress_data: Dict[str, Any]) -> None:
|
||||
"""Called when progress is updated"""
|
||||
pass
|
||||
|
||||
|
||||
class AutoOrganizeResult:
|
||||
"""Result object for auto-organize operations"""
|
||||
|
||||
def __init__(self):
|
||||
self.total: int = 0
|
||||
self.processed: int = 0
|
||||
self.success_count: int = 0
|
||||
self.failure_count: int = 0
|
||||
self.skipped_count: int = 0
|
||||
self.operation_type: str = 'unknown'
|
||||
self.cleanup_counts: Dict[str, int] = {}
|
||||
self.results: List[Dict[str, Any]] = []
|
||||
self.results_truncated: bool = False
|
||||
self.sample_results: List[Dict[str, Any]] = []
|
||||
self.is_flat_structure: bool = False
|
||||
|
||||
def to_dict(self) -> Dict[str, Any]:
|
||||
"""Convert result to dictionary"""
|
||||
result = {
|
||||
'success': True,
|
||||
'message': f'Auto-organize {self.operation_type} completed: {self.success_count} moved, {self.skipped_count} skipped, {self.failure_count} failed out of {self.total} total',
|
||||
'summary': {
|
||||
'total': self.total,
|
||||
'success': self.success_count,
|
||||
'skipped': self.skipped_count,
|
||||
'failures': self.failure_count,
|
||||
'organization_type': 'flat' if self.is_flat_structure else 'structured',
|
||||
'cleaned_dirs': self.cleanup_counts,
|
||||
'operation_type': self.operation_type
|
||||
}
|
||||
}
|
||||
|
||||
if self.results_truncated:
|
||||
result['results_truncated'] = True
|
||||
result['sample_results'] = self.sample_results
|
||||
else:
|
||||
result['results'] = self.results
|
||||
|
||||
return result
|
||||
|
||||
|
||||
class ModelFileService:
|
||||
"""Service for handling model file operations and organization"""
|
||||
|
||||
def __init__(self, scanner, model_type: str):
|
||||
"""Initialize the service
|
||||
|
||||
Args:
|
||||
scanner: Model scanner instance
|
||||
model_type: Type of model (e.g., 'lora', 'checkpoint')
|
||||
"""
|
||||
self.scanner = scanner
|
||||
self.model_type = model_type
|
||||
|
||||
def get_model_roots(self) -> List[str]:
|
||||
"""Get model root directories"""
|
||||
return self.scanner.get_model_roots()
|
||||
|
||||
async def auto_organize_models(
|
||||
self,
|
||||
file_paths: Optional[List[str]] = None,
|
||||
progress_callback: Optional[ProgressCallback] = None
|
||||
) -> AutoOrganizeResult:
|
||||
"""Auto-organize models based on current settings
|
||||
|
||||
Args:
|
||||
file_paths: Optional list of specific file paths to organize.
|
||||
If None, organizes all models.
|
||||
progress_callback: Optional callback for progress updates
|
||||
|
||||
Returns:
|
||||
AutoOrganizeResult object with operation results
|
||||
"""
|
||||
result = AutoOrganizeResult()
|
||||
source_directories: Set[str] = set()
|
||||
|
||||
try:
|
||||
# Get all models from cache
|
||||
cache = await self.scanner.get_cached_data()
|
||||
all_models = cache.raw_data
|
||||
|
||||
# Filter models if specific file paths are provided
|
||||
if file_paths:
|
||||
all_models = [model for model in all_models if model.get('file_path') in file_paths]
|
||||
result.operation_type = 'bulk'
|
||||
else:
|
||||
result.operation_type = 'all'
|
||||
|
||||
# Get model roots for this scanner
|
||||
model_roots = self.get_model_roots()
|
||||
if not model_roots:
|
||||
raise ValueError('No model roots configured')
|
||||
|
||||
# Check if flat structure is configured for this model type
|
||||
path_template = settings.get_download_path_template(self.model_type)
|
||||
result.is_flat_structure = not path_template
|
||||
|
||||
# Initialize tracking
|
||||
result.total = len(all_models)
|
||||
|
||||
# Send initial progress
|
||||
if progress_callback:
|
||||
await progress_callback.on_progress({
|
||||
'type': 'auto_organize_progress',
|
||||
'status': 'started',
|
||||
'total': result.total,
|
||||
'processed': 0,
|
||||
'success': 0,
|
||||
'failures': 0,
|
||||
'skipped': 0,
|
||||
'operation_type': result.operation_type
|
||||
})
|
||||
|
||||
# Process models in batches
|
||||
await self._process_models_in_batches(
|
||||
all_models,
|
||||
model_roots,
|
||||
result,
|
||||
progress_callback,
|
||||
source_directories # Pass the set to track source directories
|
||||
)
|
||||
|
||||
# Send cleanup progress
|
||||
if progress_callback:
|
||||
await progress_callback.on_progress({
|
||||
'type': 'auto_organize_progress',
|
||||
'status': 'cleaning',
|
||||
'total': result.total,
|
||||
'processed': result.processed,
|
||||
'success': result.success_count,
|
||||
'failures': result.failure_count,
|
||||
'skipped': result.skipped_count,
|
||||
'message': 'Cleaning up empty directories...',
|
||||
'operation_type': result.operation_type
|
||||
})
|
||||
|
||||
# Clean up empty directories - only in affected directories for bulk operations
|
||||
cleanup_paths = list(source_directories) if result.operation_type == 'bulk' else model_roots
|
||||
result.cleanup_counts = await self._cleanup_empty_directories(cleanup_paths)
|
||||
|
||||
# Send completion message
|
||||
if progress_callback:
|
||||
await progress_callback.on_progress({
|
||||
'type': 'auto_organize_progress',
|
||||
'status': 'completed',
|
||||
'total': result.total,
|
||||
'processed': result.processed,
|
||||
'success': result.success_count,
|
||||
'failures': result.failure_count,
|
||||
'skipped': result.skipped_count,
|
||||
'cleanup': result.cleanup_counts,
|
||||
'operation_type': result.operation_type
|
||||
})
|
||||
|
||||
return result
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error in auto_organize_models: {e}", exc_info=True)
|
||||
|
||||
# Send error message
|
||||
if progress_callback:
|
||||
await progress_callback.on_progress({
|
||||
'type': 'auto_organize_progress',
|
||||
'status': 'error',
|
||||
'error': str(e),
|
||||
'operation_type': result.operation_type
|
||||
})
|
||||
|
||||
raise e
|
||||
|
||||
async def _process_models_in_batches(
|
||||
self,
|
||||
all_models: List[Dict[str, Any]],
|
||||
model_roots: List[str],
|
||||
result: AutoOrganizeResult,
|
||||
progress_callback: Optional[ProgressCallback],
|
||||
source_directories: Optional[Set[str]] = None
|
||||
) -> None:
|
||||
"""Process models in batches to avoid overwhelming the system"""
|
||||
|
||||
for i in range(0, result.total, AUTO_ORGANIZE_BATCH_SIZE):
|
||||
batch = all_models[i:i + AUTO_ORGANIZE_BATCH_SIZE]
|
||||
|
||||
for model in batch:
|
||||
await self._process_single_model(model, model_roots, result, source_directories)
|
||||
result.processed += 1
|
||||
|
||||
# Send progress update after each batch
|
||||
if progress_callback:
|
||||
await progress_callback.on_progress({
|
||||
'type': 'auto_organize_progress',
|
||||
'status': 'processing',
|
||||
'total': result.total,
|
||||
'processed': result.processed,
|
||||
'success': result.success_count,
|
||||
'failures': result.failure_count,
|
||||
'skipped': result.skipped_count,
|
||||
'operation_type': result.operation_type
|
||||
})
|
||||
|
||||
# Small delay between batches
|
||||
await asyncio.sleep(0.1)
|
||||
|
||||
async def _process_single_model(
|
||||
self,
|
||||
model: Dict[str, Any],
|
||||
model_roots: List[str],
|
||||
result: AutoOrganizeResult,
|
||||
source_directories: Optional[Set[str]] = None
|
||||
) -> None:
|
||||
"""Process a single model for organization"""
|
||||
try:
|
||||
file_path = model.get('file_path')
|
||||
model_name = model.get('model_name', 'Unknown')
|
||||
|
||||
if not file_path:
|
||||
self._add_result(result, model_name, False, "No file path found")
|
||||
result.failure_count += 1
|
||||
return
|
||||
|
||||
# Find which model root this file belongs to
|
||||
current_root = self._find_model_root(file_path, model_roots)
|
||||
if not current_root:
|
||||
self._add_result(result, model_name, False,
|
||||
"Model file not found in any configured root directory")
|
||||
result.failure_count += 1
|
||||
return
|
||||
|
||||
# Determine target directory
|
||||
target_dir = await self._calculate_target_directory(
|
||||
model, current_root, result.is_flat_structure
|
||||
)
|
||||
|
||||
if target_dir is None:
|
||||
self._add_result(result, model_name, False,
|
||||
"Skipped - insufficient metadata for organization")
|
||||
result.skipped_count += 1
|
||||
return
|
||||
|
||||
current_dir = os.path.dirname(file_path)
|
||||
|
||||
# Skip if already in correct location
|
||||
if current_dir.replace(os.sep, '/') == target_dir.replace(os.sep, '/'):
|
||||
result.skipped_count += 1
|
||||
return
|
||||
|
||||
# Check for conflicts
|
||||
file_name = os.path.basename(file_path)
|
||||
target_file_path = os.path.join(target_dir, file_name)
|
||||
|
||||
if os.path.exists(target_file_path):
|
||||
self._add_result(result, model_name, False,
|
||||
f"Target file already exists: {target_file_path}")
|
||||
result.failure_count += 1
|
||||
return
|
||||
|
||||
# Store the source directory for potential cleanup
|
||||
if source_directories is not None:
|
||||
source_directories.add(current_dir)
|
||||
|
||||
# Perform the move
|
||||
success = await self.scanner.move_model(file_path, target_dir)
|
||||
|
||||
if success:
|
||||
result.success_count += 1
|
||||
else:
|
||||
self._add_result(result, model_name, False, "Failed to move model")
|
||||
result.failure_count += 1
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing model {model.get('model_name', 'Unknown')}: {e}", exc_info=True)
|
||||
self._add_result(result, model.get('model_name', 'Unknown'), False, f"Error: {str(e)}")
|
||||
result.failure_count += 1
|
||||
|
||||
def _find_model_root(self, file_path: str, model_roots: List[str]) -> Optional[str]:
|
||||
"""Find which model root the file belongs to"""
|
||||
for root in model_roots:
|
||||
# Normalize paths for comparison
|
||||
normalized_root = os.path.normpath(root).replace(os.sep, '/')
|
||||
normalized_file = os.path.normpath(file_path).replace(os.sep, '/')
|
||||
|
||||
if normalized_file.startswith(normalized_root):
|
||||
return root
|
||||
return None
|
||||
|
||||
async def _calculate_target_directory(
|
||||
self,
|
||||
model: Dict[str, Any],
|
||||
current_root: str,
|
||||
is_flat_structure: bool
|
||||
) -> Optional[str]:
|
||||
"""Calculate the target directory for a model"""
|
||||
if is_flat_structure:
|
||||
file_path = model.get('file_path')
|
||||
current_dir = os.path.dirname(file_path)
|
||||
|
||||
# Check if already in root directory
|
||||
if os.path.normpath(current_dir) == os.path.normpath(current_root):
|
||||
return None # Signal to skip
|
||||
|
||||
return current_root
|
||||
else:
|
||||
# Calculate new relative path based on settings
|
||||
new_relative_path = calculate_relative_path_for_model(model, self.model_type)
|
||||
|
||||
if not new_relative_path:
|
||||
return None # Signal to skip
|
||||
|
||||
return os.path.join(current_root, new_relative_path).replace(os.sep, '/')
|
||||
|
||||
def _add_result(
|
||||
self,
|
||||
result: AutoOrganizeResult,
|
||||
model_name: str,
|
||||
success: bool,
|
||||
message: str
|
||||
) -> None:
|
||||
"""Add a result entry if under the limit"""
|
||||
if len(result.results) < 100: # Limit detailed results
|
||||
result.results.append({
|
||||
"model": model_name,
|
||||
"success": success,
|
||||
"message": message
|
||||
})
|
||||
elif len(result.results) == 100:
|
||||
# Mark as truncated and save sample
|
||||
result.results_truncated = True
|
||||
result.sample_results = result.results[:50]
|
||||
|
||||
async def _cleanup_empty_directories(self, paths: List[str]) -> Dict[str, int]:
|
||||
"""Clean up empty directories after organizing
|
||||
|
||||
Args:
|
||||
paths: List of paths to check for empty directories
|
||||
|
||||
Returns:
|
||||
Dictionary with counts of removed directories by root path
|
||||
"""
|
||||
cleanup_counts = {}
|
||||
for path in paths:
|
||||
removed = remove_empty_dirs(path)
|
||||
cleanup_counts[path] = removed
|
||||
return cleanup_counts
|
||||
|
||||
|
||||
class ModelMoveService:
|
||||
"""Service for handling individual model moves"""
|
||||
|
||||
def __init__(self, scanner):
|
||||
"""Initialize the service
|
||||
|
||||
Args:
|
||||
scanner: Model scanner instance
|
||||
"""
|
||||
self.scanner = scanner
|
||||
|
||||
async def move_model(self, file_path: str, target_path: str) -> Dict[str, Any]:
|
||||
"""Move a single model file
|
||||
|
||||
Args:
|
||||
file_path: Source file path
|
||||
target_path: Target directory path
|
||||
|
||||
Returns:
|
||||
Dictionary with move result
|
||||
"""
|
||||
try:
|
||||
source_dir = os.path.dirname(file_path)
|
||||
if os.path.normpath(source_dir) == os.path.normpath(target_path):
|
||||
logger.info(f"Source and target directories are the same: {source_dir}")
|
||||
return {
|
||||
'success': True,
|
||||
'message': 'Source and target directories are the same',
|
||||
'original_file_path': file_path,
|
||||
'new_file_path': file_path
|
||||
}
|
||||
|
||||
new_file_path = await self.scanner.move_model(file_path, target_path)
|
||||
if new_file_path:
|
||||
return {
|
||||
'success': True,
|
||||
'original_file_path': file_path,
|
||||
'new_file_path': new_file_path
|
||||
}
|
||||
else:
|
||||
return {
|
||||
'success': False,
|
||||
'error': 'Failed to move model',
|
||||
'original_file_path': file_path,
|
||||
'new_file_path': None
|
||||
}
|
||||
except Exception as e:
|
||||
logger.error(f"Error moving model: {e}", exc_info=True)
|
||||
return {
|
||||
'success': False,
|
||||
'error': str(e),
|
||||
'original_file_path': file_path,
|
||||
'new_file_path': None
|
||||
}
|
||||
|
||||
async def move_models_bulk(self, file_paths: List[str], target_path: str) -> Dict[str, Any]:
|
||||
"""Move multiple model files
|
||||
|
||||
Args:
|
||||
file_paths: List of source file paths
|
||||
target_path: Target directory path
|
||||
|
||||
Returns:
|
||||
Dictionary with bulk move results
|
||||
"""
|
||||
try:
|
||||
results = []
|
||||
|
||||
for file_path in file_paths:
|
||||
result = await self.move_model(file_path, target_path)
|
||||
results.append({
|
||||
"original_file_path": file_path,
|
||||
"new_file_path": result.get('new_file_path'),
|
||||
"success": result['success'],
|
||||
"message": result.get('message', result.get('error', 'Unknown'))
|
||||
})
|
||||
|
||||
success_count = sum(1 for r in results if r["success"])
|
||||
failure_count = len(results) - success_count
|
||||
|
||||
return {
|
||||
'success': True,
|
||||
'message': f'Moved {success_count} of {len(file_paths)} models',
|
||||
'results': results,
|
||||
'success_count': success_count,
|
||||
'failure_count': failure_count
|
||||
}
|
||||
except Exception as e:
|
||||
logger.error(f"Error moving models in bulk: {e}", exc_info=True)
|
||||
return {
|
||||
'success': False,
|
||||
'error': str(e),
|
||||
'results': [],
|
||||
'success_count': 0,
|
||||
'failure_count': len(file_paths)
|
||||
}
|
||||
@@ -1,12 +1,15 @@
|
||||
from typing import Dict, Optional, Set
|
||||
from typing import Dict, Optional, Set, List
|
||||
import os
|
||||
|
||||
class ModelHashIndex:
|
||||
"""Index for looking up models by hash or path"""
|
||||
"""Index for looking up models by hash or filename"""
|
||||
|
||||
def __init__(self):
|
||||
self._hash_to_path: Dict[str, str] = {}
|
||||
self._filename_to_hash: Dict[str, str] = {} # Changed from path_to_hash to filename_to_hash
|
||||
self._filename_to_hash: Dict[str, str] = {}
|
||||
# New data structures for tracking duplicates
|
||||
self._duplicate_hashes: Dict[str, List[str]] = {} # sha256 -> list of paths
|
||||
self._duplicate_filenames: Dict[str, List[str]] = {} # filename -> list of paths
|
||||
|
||||
def add_entry(self, sha256: str, file_path: str) -> None:
|
||||
"""Add or update hash index entry"""
|
||||
@@ -19,18 +22,43 @@ class ModelHashIndex:
|
||||
# Extract filename without extension
|
||||
filename = self._get_filename_from_path(file_path)
|
||||
|
||||
# Track duplicates by hash
|
||||
if sha256 in self._hash_to_path:
|
||||
old_path = self._hash_to_path[sha256]
|
||||
if old_path != file_path: # Only record if it's actually a different path
|
||||
if sha256 not in self._duplicate_hashes:
|
||||
self._duplicate_hashes[sha256] = [old_path]
|
||||
if file_path not in self._duplicate_hashes.get(sha256, []):
|
||||
self._duplicate_hashes.setdefault(sha256, []).append(file_path)
|
||||
|
||||
# Track duplicates by filename - FIXED LOGIC
|
||||
if filename in self._filename_to_hash:
|
||||
existing_hash = self._filename_to_hash[filename]
|
||||
existing_path = self._hash_to_path.get(existing_hash)
|
||||
|
||||
# If this is a different file with the same filename
|
||||
if existing_path and existing_path != file_path:
|
||||
# Initialize duplicates tracking if needed
|
||||
if filename not in self._duplicate_filenames:
|
||||
self._duplicate_filenames[filename] = [existing_path]
|
||||
|
||||
# Add current file to duplicates if not already present
|
||||
if file_path not in self._duplicate_filenames[filename]:
|
||||
self._duplicate_filenames[filename].append(file_path)
|
||||
|
||||
# Remove old path mapping if hash exists
|
||||
if sha256 in self._hash_to_path:
|
||||
old_path = self._hash_to_path[sha256]
|
||||
old_filename = self._get_filename_from_path(old_path)
|
||||
if old_filename in self._filename_to_hash:
|
||||
if old_filename in self._filename_to_hash and self._filename_to_hash[old_filename] == sha256:
|
||||
del self._filename_to_hash[old_filename]
|
||||
|
||||
# Remove old hash mapping if filename exists
|
||||
# Remove old hash mapping if filename exists and points to different hash
|
||||
if filename in self._filename_to_hash:
|
||||
old_hash = self._filename_to_hash[filename]
|
||||
if old_hash in self._hash_to_path:
|
||||
del self._hash_to_path[old_hash]
|
||||
if old_hash != sha256 and old_hash in self._hash_to_path:
|
||||
# Don't delete the old hash mapping, just update filename mapping
|
||||
pass
|
||||
|
||||
# Add new mappings
|
||||
self._hash_to_path[sha256] = file_path
|
||||
@@ -40,24 +68,126 @@ class ModelHashIndex:
|
||||
"""Extract filename without extension from path"""
|
||||
return os.path.splitext(os.path.basename(file_path))[0]
|
||||
|
||||
def remove_by_path(self, file_path: str) -> None:
|
||||
def remove_by_path(self, file_path: str, hash_val: str = None) -> None:
|
||||
"""Remove entry by file path"""
|
||||
filename = self._get_filename_from_path(file_path)
|
||||
if filename in self._filename_to_hash:
|
||||
hash_val = self._filename_to_hash[filename]
|
||||
if hash_val in self._hash_to_path:
|
||||
|
||||
# Find the hash for this file path
|
||||
if hash_val is None:
|
||||
for h, p in self._hash_to_path.items():
|
||||
if p == file_path:
|
||||
hash_val = h
|
||||
break
|
||||
|
||||
# If we didn't find a hash, nothing to do
|
||||
if not hash_val:
|
||||
return
|
||||
|
||||
# Update duplicates tracking for hash
|
||||
if hash_val in self._duplicate_hashes:
|
||||
# Remove the current path from duplicates
|
||||
self._duplicate_hashes[hash_val] = [p for p in self._duplicate_hashes[hash_val] if p != file_path]
|
||||
|
||||
# Update or remove hash mapping based on remaining duplicates
|
||||
if len(self._duplicate_hashes[hash_val]) > 0:
|
||||
# Replace with one of the remaining paths
|
||||
new_path = self._duplicate_hashes[hash_val][0]
|
||||
new_filename = self._get_filename_from_path(new_path)
|
||||
|
||||
# Update hash-to-path mapping
|
||||
self._hash_to_path[hash_val] = new_path
|
||||
|
||||
# IMPORTANT: Update filename-to-hash mapping for consistency
|
||||
# Remove old filename mapping if it points to this hash
|
||||
if filename in self._filename_to_hash and self._filename_to_hash[filename] == hash_val:
|
||||
del self._filename_to_hash[filename]
|
||||
|
||||
# Add new filename mapping
|
||||
self._filename_to_hash[new_filename] = hash_val
|
||||
|
||||
# If only one duplicate left, remove from duplicates tracking
|
||||
if len(self._duplicate_hashes[hash_val]) == 1:
|
||||
del self._duplicate_hashes[hash_val]
|
||||
else:
|
||||
# No duplicates left, remove hash entry completely
|
||||
del self._duplicate_hashes[hash_val]
|
||||
del self._hash_to_path[hash_val]
|
||||
del self._filename_to_hash[filename]
|
||||
|
||||
# Remove corresponding filename entry if it points to this hash
|
||||
if filename in self._filename_to_hash and self._filename_to_hash[filename] == hash_val:
|
||||
del self._filename_to_hash[filename]
|
||||
else:
|
||||
# No duplicates, simply remove the hash entry
|
||||
del self._hash_to_path[hash_val]
|
||||
|
||||
# Remove corresponding filename entry if it points to this hash
|
||||
if filename in self._filename_to_hash and self._filename_to_hash[filename] == hash_val:
|
||||
del self._filename_to_hash[filename]
|
||||
|
||||
# Update duplicates tracking for filename
|
||||
if filename in self._duplicate_filenames:
|
||||
# Remove the current path from duplicates
|
||||
self._duplicate_filenames[filename] = [p for p in self._duplicate_filenames[filename] if p != file_path]
|
||||
|
||||
# Update or remove filename mapping based on remaining duplicates
|
||||
if len(self._duplicate_filenames[filename]) > 0:
|
||||
# Get the hash for the first remaining duplicate path
|
||||
first_dup_path = self._duplicate_filenames[filename][0]
|
||||
first_dup_hash = None
|
||||
for h, p in self._hash_to_path.items():
|
||||
if p == first_dup_path:
|
||||
first_dup_hash = h
|
||||
break
|
||||
|
||||
# Update the filename to hash mapping if we found a hash
|
||||
if first_dup_hash:
|
||||
self._filename_to_hash[filename] = first_dup_hash
|
||||
|
||||
# If only one duplicate left, remove from duplicates tracking
|
||||
if len(self._duplicate_filenames[filename]) == 1:
|
||||
del self._duplicate_filenames[filename]
|
||||
else:
|
||||
# No duplicates left, remove filename entry completely
|
||||
del self._duplicate_filenames[filename]
|
||||
if filename in self._filename_to_hash:
|
||||
del self._filename_to_hash[filename]
|
||||
|
||||
def remove_by_hash(self, sha256: str) -> None:
|
||||
"""Remove entry by hash"""
|
||||
sha256 = sha256.lower()
|
||||
if sha256 in self._hash_to_path:
|
||||
path = self._hash_to_path[sha256]
|
||||
filename = self._get_filename_from_path(path)
|
||||
if filename in self._filename_to_hash:
|
||||
del self._filename_to_hash[filename]
|
||||
del self._hash_to_path[sha256]
|
||||
if sha256 not in self._hash_to_path:
|
||||
return
|
||||
|
||||
# Get the path and filename
|
||||
path = self._hash_to_path[sha256]
|
||||
filename = self._get_filename_from_path(path)
|
||||
|
||||
# Get all paths for this hash (including duplicates)
|
||||
paths_to_remove = [path]
|
||||
if sha256 in self._duplicate_hashes:
|
||||
paths_to_remove.extend(self._duplicate_hashes[sha256])
|
||||
del self._duplicate_hashes[sha256]
|
||||
|
||||
# Remove hash-to-path mapping
|
||||
del self._hash_to_path[sha256]
|
||||
|
||||
# Update filename-to-hash and duplicate filenames for all paths
|
||||
for path_to_remove in paths_to_remove:
|
||||
fname = self._get_filename_from_path(path_to_remove)
|
||||
|
||||
# If this filename maps to the hash we're removing, remove it
|
||||
if fname in self._filename_to_hash and self._filename_to_hash[fname] == sha256:
|
||||
del self._filename_to_hash[fname]
|
||||
|
||||
# Update duplicate filenames tracking
|
||||
if fname in self._duplicate_filenames:
|
||||
self._duplicate_filenames[fname] = [p for p in self._duplicate_filenames[fname] if p != path_to_remove]
|
||||
|
||||
if not self._duplicate_filenames[fname]:
|
||||
del self._duplicate_filenames[fname]
|
||||
elif len(self._duplicate_filenames[fname]) == 1:
|
||||
# If only one entry remains, it's no longer a duplicate
|
||||
del self._duplicate_filenames[fname]
|
||||
|
||||
def has_hash(self, sha256: str) -> bool:
|
||||
"""Check if hash exists in index"""
|
||||
@@ -74,14 +204,14 @@ class ModelHashIndex:
|
||||
|
||||
def get_hash_by_filename(self, filename: str) -> Optional[str]:
|
||||
"""Get hash for a filename without extension"""
|
||||
# Strip extension if present to make the function more flexible
|
||||
filename = os.path.splitext(filename)[0]
|
||||
return self._filename_to_hash.get(filename)
|
||||
|
||||
def clear(self) -> None:
|
||||
"""Clear all entries"""
|
||||
self._hash_to_path.clear()
|
||||
self._filename_to_hash.clear()
|
||||
self._duplicate_hashes.clear()
|
||||
self._duplicate_filenames.clear()
|
||||
|
||||
def get_all_hashes(self) -> Set[str]:
|
||||
"""Get all hashes in the index"""
|
||||
@@ -91,6 +221,14 @@ class ModelHashIndex:
|
||||
"""Get all filenames in the index"""
|
||||
return set(self._filename_to_hash.keys())
|
||||
|
||||
def get_duplicate_hashes(self) -> Dict[str, List[str]]:
|
||||
"""Get dictionary of duplicate hashes and their paths"""
|
||||
return self._duplicate_hashes
|
||||
|
||||
def get_duplicate_filenames(self) -> Dict[str, List[str]]:
|
||||
"""Get dictionary of duplicate filenames and their paths"""
|
||||
return self._duplicate_filenames
|
||||
|
||||
def __len__(self) -> int:
|
||||
"""Get number of entries"""
|
||||
return len(self._hash_to_path)
|
||||
519
py/services/model_metadata_provider.py
Normal file
519
py/services/model_metadata_provider.py
Normal file
@@ -0,0 +1,519 @@
|
||||
from abc import ABC, abstractmethod
|
||||
import json
|
||||
import aiosqlite
|
||||
import logging
|
||||
import aiohttp
|
||||
from bs4 import BeautifulSoup
|
||||
from typing import Optional, Dict, Tuple
|
||||
from .downloader import get_downloader
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class ModelMetadataProvider(ABC):
|
||||
"""Base abstract class for all model metadata providers"""
|
||||
|
||||
@abstractmethod
|
||||
async def get_model_by_hash(self, model_hash: str) -> Optional[Dict]:
|
||||
"""Find model by hash value"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
async def get_model_versions(self, model_id: str) -> Optional[Dict]:
|
||||
"""Get all versions of a model with their details"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
async def get_model_version(self, model_id: int = None, version_id: int = None) -> Optional[Dict]:
|
||||
"""Get specific model version with additional metadata"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
async def get_model_version_info(self, version_id: str) -> Tuple[Optional[Dict], Optional[str]]:
|
||||
"""Fetch model version metadata"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
async def get_model_metadata(self, model_id: str) -> Tuple[Optional[Dict], int]:
|
||||
"""Fetch model metadata (description, tags, and creator info)"""
|
||||
pass
|
||||
|
||||
class CivitaiModelMetadataProvider(ModelMetadataProvider):
|
||||
"""Provider that uses Civitai API for metadata"""
|
||||
|
||||
def __init__(self, civitai_client):
|
||||
self.client = civitai_client
|
||||
|
||||
async def get_model_by_hash(self, model_hash: str) -> Optional[Dict]:
|
||||
return await self.client.get_model_by_hash(model_hash)
|
||||
|
||||
async def get_model_versions(self, model_id: str) -> Optional[Dict]:
|
||||
return await self.client.get_model_versions(model_id)
|
||||
|
||||
async def get_model_version(self, model_id: int = None, version_id: int = None) -> Optional[Dict]:
|
||||
return await self.client.get_model_version(model_id, version_id)
|
||||
|
||||
async def get_model_version_info(self, version_id: str) -> Tuple[Optional[Dict], Optional[str]]:
|
||||
return await self.client.get_model_version_info(version_id)
|
||||
|
||||
async def get_model_metadata(self, model_id: str) -> Tuple[Optional[Dict], int]:
|
||||
return await self.client.get_model_metadata(model_id)
|
||||
|
||||
class CivArchiveModelMetadataProvider(ModelMetadataProvider):
|
||||
"""Provider that uses CivArchive HTML page parsing for metadata"""
|
||||
|
||||
async def get_model_by_hash(self, model_hash: str) -> Optional[Dict]:
|
||||
"""Not supported by CivArchive provider"""
|
||||
return None
|
||||
|
||||
async def get_model_versions(self, model_id: str) -> Optional[Dict]:
|
||||
"""Not supported by CivArchive provider"""
|
||||
return None
|
||||
|
||||
async def get_model_version(self, model_id: int = None, version_id: int = None) -> Optional[Dict]:
|
||||
"""Get specific model version by parsing CivArchive HTML page"""
|
||||
if model_id is None or version_id is None:
|
||||
return None
|
||||
|
||||
try:
|
||||
# Construct CivArchive URL
|
||||
url = f"https://civarchive.com/models/{model_id}?modelVersionId={version_id}"
|
||||
|
||||
downloader = await get_downloader()
|
||||
session = await downloader.session
|
||||
async with session.get(url) as response:
|
||||
if response.status != 200:
|
||||
return None
|
||||
|
||||
html_content = await response.text()
|
||||
|
||||
# Parse HTML to extract JSON data
|
||||
soup = BeautifulSoup(html_content, 'html.parser')
|
||||
script_tag = soup.find('script', {'id': '__NEXT_DATA__', 'type': 'application/json'})
|
||||
|
||||
if not script_tag:
|
||||
return None
|
||||
|
||||
# Parse JSON content
|
||||
json_data = json.loads(script_tag.string)
|
||||
model_data = json_data.get('props', {}).get('pageProps', {}).get('model')
|
||||
|
||||
if not model_data or 'version' not in model_data:
|
||||
return None
|
||||
|
||||
# Extract version data as base
|
||||
version = model_data['version'].copy()
|
||||
|
||||
# Restructure stats
|
||||
if 'downloadCount' in version and 'ratingCount' in version and 'rating' in version:
|
||||
version['stats'] = {
|
||||
'downloadCount': version.pop('downloadCount'),
|
||||
'ratingCount': version.pop('ratingCount'),
|
||||
'rating': version.pop('rating')
|
||||
}
|
||||
|
||||
# Rename trigger to trainedWords
|
||||
if 'trigger' in version:
|
||||
version['trainedWords'] = version.pop('trigger')
|
||||
|
||||
# Transform files data to expected format
|
||||
if 'files' in version:
|
||||
transformed_files = []
|
||||
for file_data in version['files']:
|
||||
# Find first available mirror (deletedAt is null)
|
||||
available_mirror = None
|
||||
for mirror in file_data.get('mirrors', []):
|
||||
if mirror.get('deletedAt') is None:
|
||||
available_mirror = mirror
|
||||
break
|
||||
|
||||
# Create transformed file entry
|
||||
transformed_file = {
|
||||
'id': file_data.get('id'),
|
||||
'sizeKB': file_data.get('sizeKB'),
|
||||
'name': available_mirror.get('filename', file_data.get('name')) if available_mirror else file_data.get('name'),
|
||||
'type': file_data.get('type'),
|
||||
'downloadUrl': available_mirror.get('url') if available_mirror else None,
|
||||
'primary': True,
|
||||
'mirrors': file_data.get('mirrors', [])
|
||||
}
|
||||
|
||||
# Transform hash format
|
||||
if 'sha256' in file_data:
|
||||
transformed_file['hashes'] = {
|
||||
'SHA256': file_data['sha256'].upper()
|
||||
}
|
||||
|
||||
transformed_files.append(transformed_file)
|
||||
|
||||
version['files'] = transformed_files
|
||||
|
||||
# Add model information
|
||||
version['model'] = {
|
||||
'name': model_data.get('name'),
|
||||
'type': model_data.get('type'),
|
||||
'nsfw': model_data.get('is_nsfw', False),
|
||||
'description': model_data.get('description'),
|
||||
'tags': model_data.get('tags', [])
|
||||
}
|
||||
|
||||
version['creator'] = {
|
||||
'username': model_data.get('username'),
|
||||
'image': ''
|
||||
}
|
||||
|
||||
# Add source identifier
|
||||
version['source'] = 'civarchive'
|
||||
version['is_deleted'] = json_data.get('query', {}).get('is_deleted', False)
|
||||
|
||||
return version
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error fetching CivArchive model version {model_id}/{version_id}: {e}")
|
||||
return None
|
||||
|
||||
async def get_model_version_info(self, version_id: str) -> Tuple[Optional[Dict], Optional[str]]:
|
||||
"""Not supported by CivArchive provider - requires both model_id and version_id"""
|
||||
return None, "CivArchive provider requires both model_id and version_id"
|
||||
|
||||
async def get_model_metadata(self, model_id: str) -> Tuple[Optional[Dict], int]:
|
||||
"""Not supported by CivArchive provider"""
|
||||
return None, 404
|
||||
|
||||
class SQLiteModelMetadataProvider(ModelMetadataProvider):
|
||||
"""Provider that uses SQLite database for metadata"""
|
||||
|
||||
def __init__(self, db_path: str):
|
||||
self.db_path = db_path
|
||||
|
||||
async def get_model_by_hash(self, model_hash: str) -> Optional[Dict]:
|
||||
"""Find model by hash value from SQLite database"""
|
||||
async with aiosqlite.connect(self.db_path) as db:
|
||||
# Look up in model_files table to get model_id and version_id
|
||||
query = """
|
||||
SELECT model_id, version_id
|
||||
FROM model_files
|
||||
WHERE sha256 = ?
|
||||
LIMIT 1
|
||||
"""
|
||||
db.row_factory = aiosqlite.Row
|
||||
cursor = await db.execute(query, (model_hash.upper(),))
|
||||
file_row = await cursor.fetchone()
|
||||
|
||||
if not file_row:
|
||||
return None
|
||||
|
||||
# Get version details
|
||||
model_id = file_row['model_id']
|
||||
version_id = file_row['version_id']
|
||||
|
||||
# Build response in the same format as Civitai API
|
||||
return await self._get_version_with_model_data(db, model_id, version_id)
|
||||
|
||||
async def get_model_versions(self, model_id: str) -> Optional[Dict]:
|
||||
"""Get all versions of a model from SQLite database"""
|
||||
async with aiosqlite.connect(self.db_path) as db:
|
||||
db.row_factory = aiosqlite.Row
|
||||
|
||||
# First check if model exists
|
||||
model_query = "SELECT * FROM models WHERE id = ?"
|
||||
cursor = await db.execute(model_query, (model_id,))
|
||||
model_row = await cursor.fetchone()
|
||||
|
||||
if not model_row:
|
||||
return None
|
||||
|
||||
model_data = json.loads(model_row['data'])
|
||||
model_type = model_row['type']
|
||||
|
||||
# Get all versions for this model
|
||||
versions_query = """
|
||||
SELECT id, name, base_model, data, position, published_at
|
||||
FROM model_versions
|
||||
WHERE model_id = ?
|
||||
ORDER BY position ASC
|
||||
"""
|
||||
cursor = await db.execute(versions_query, (model_id,))
|
||||
version_rows = await cursor.fetchall()
|
||||
|
||||
if not version_rows:
|
||||
return {'modelVersions': [], 'type': model_type}
|
||||
|
||||
# Format versions similar to Civitai API
|
||||
model_versions = []
|
||||
for row in version_rows:
|
||||
version_data = json.loads(row['data'])
|
||||
# Add fields from the row to ensure we have the basic fields
|
||||
version_entry = {
|
||||
'id': row['id'],
|
||||
'modelId': int(model_id),
|
||||
'name': row['name'],
|
||||
'baseModel': row['base_model'],
|
||||
'model': {
|
||||
'name': model_row['name'],
|
||||
'type': model_type,
|
||||
},
|
||||
'source': 'archive_db'
|
||||
}
|
||||
# Update with any additional data
|
||||
version_entry.update(version_data)
|
||||
model_versions.append(version_entry)
|
||||
|
||||
return {
|
||||
'modelVersions': model_versions,
|
||||
'type': model_type
|
||||
}
|
||||
|
||||
async def get_model_version(self, model_id: int = None, version_id: int = None) -> Optional[Dict]:
|
||||
"""Get specific model version with additional metadata from SQLite database"""
|
||||
if not model_id and not version_id:
|
||||
return None
|
||||
|
||||
async with aiosqlite.connect(self.db_path) as db:
|
||||
db.row_factory = aiosqlite.Row
|
||||
|
||||
# Case 1: Only version_id is provided
|
||||
if model_id is None and version_id is not None:
|
||||
# First get the version info to extract model_id
|
||||
version_query = "SELECT model_id FROM model_versions WHERE id = ?"
|
||||
cursor = await db.execute(version_query, (version_id,))
|
||||
version_row = await cursor.fetchone()
|
||||
|
||||
if not version_row:
|
||||
return None
|
||||
|
||||
model_id = version_row['model_id']
|
||||
|
||||
# Case 2: model_id is provided but version_id is not
|
||||
elif model_id is not None and version_id is None:
|
||||
# Find the latest version
|
||||
version_query = """
|
||||
SELECT id FROM model_versions
|
||||
WHERE model_id = ?
|
||||
ORDER BY position ASC
|
||||
LIMIT 1
|
||||
"""
|
||||
cursor = await db.execute(version_query, (model_id,))
|
||||
version_row = await cursor.fetchone()
|
||||
|
||||
if not version_row:
|
||||
return None
|
||||
|
||||
version_id = version_row['id']
|
||||
|
||||
# Now we have both model_id and version_id, get the full data
|
||||
return await self._get_version_with_model_data(db, model_id, version_id)
|
||||
|
||||
async def get_model_version_info(self, version_id: str) -> Tuple[Optional[Dict], Optional[str]]:
|
||||
"""Fetch model version metadata from SQLite database"""
|
||||
async with aiosqlite.connect(self.db_path) as db:
|
||||
db.row_factory = aiosqlite.Row
|
||||
|
||||
# Get version details
|
||||
version_query = "SELECT model_id FROM model_versions WHERE id = ?"
|
||||
cursor = await db.execute(version_query, (version_id,))
|
||||
version_row = await cursor.fetchone()
|
||||
|
||||
if not version_row:
|
||||
return None, "Model version not found"
|
||||
|
||||
model_id = version_row['model_id']
|
||||
|
||||
# Build complete version data with model info
|
||||
version_data = await self._get_version_with_model_data(db, model_id, version_id)
|
||||
return version_data, None
|
||||
|
||||
async def get_model_metadata(self, model_id: str) -> Tuple[Optional[Dict], int]:
|
||||
"""Fetch model metadata from SQLite database"""
|
||||
async with aiosqlite.connect(self.db_path) as db:
|
||||
db.row_factory = aiosqlite.Row
|
||||
|
||||
# Get model details
|
||||
model_query = "SELECT name, type, data, username FROM models WHERE id = ?"
|
||||
cursor = await db.execute(model_query, (model_id,))
|
||||
model_row = await cursor.fetchone()
|
||||
|
||||
if not model_row:
|
||||
return None, 404
|
||||
|
||||
# Parse data JSON
|
||||
try:
|
||||
model_data = json.loads(model_row['data'])
|
||||
|
||||
# Extract relevant metadata
|
||||
metadata = {
|
||||
"description": model_data.get("description", "No model description available"),
|
||||
"tags": model_data.get("tags", []),
|
||||
"creator": {
|
||||
"username": model_row['username'] or model_data.get("creator", {}).get("username"),
|
||||
"image": model_data.get("creator", {}).get("image")
|
||||
}
|
||||
}
|
||||
|
||||
return metadata, 200
|
||||
except json.JSONDecodeError:
|
||||
return None, 500
|
||||
|
||||
async def _get_version_with_model_data(self, db, model_id, version_id) -> Optional[Dict]:
|
||||
"""Helper to build version data with model information"""
|
||||
# Get version details
|
||||
version_query = "SELECT name, base_model, data FROM model_versions WHERE id = ? AND model_id = ?"
|
||||
cursor = await db.execute(version_query, (version_id, model_id))
|
||||
version_row = await cursor.fetchone()
|
||||
|
||||
if not version_row:
|
||||
return None
|
||||
|
||||
# Get model details
|
||||
model_query = "SELECT name, type, data, username FROM models WHERE id = ?"
|
||||
cursor = await db.execute(model_query, (model_id,))
|
||||
model_row = await cursor.fetchone()
|
||||
|
||||
if not model_row:
|
||||
return None
|
||||
|
||||
# Parse JSON data
|
||||
try:
|
||||
version_data = json.loads(version_row['data'])
|
||||
model_data = json.loads(model_row['data'])
|
||||
|
||||
# Build response
|
||||
result = {
|
||||
"id": int(version_id),
|
||||
"modelId": int(model_id),
|
||||
"name": version_row['name'],
|
||||
"baseModel": version_row['base_model'],
|
||||
"model": {
|
||||
"name": model_row['name'],
|
||||
"description": model_data.get("description"),
|
||||
"type": model_row['type'],
|
||||
"tags": model_data.get("tags", [])
|
||||
},
|
||||
"creator": {
|
||||
"username": model_row['username'] or model_data.get("creator", {}).get("username"),
|
||||
"image": model_data.get("creator", {}).get("image")
|
||||
},
|
||||
"source": "archive_db"
|
||||
}
|
||||
|
||||
# Add any additional fields from version data
|
||||
result.update(version_data)
|
||||
|
||||
return result
|
||||
except json.JSONDecodeError:
|
||||
return None
|
||||
|
||||
class FallbackMetadataProvider(ModelMetadataProvider):
|
||||
"""Try providers in order, return first successful result."""
|
||||
def __init__(self, providers: list):
|
||||
self.providers = providers
|
||||
|
||||
async def get_model_by_hash(self, model_hash: str) -> Optional[Dict]:
|
||||
for provider in self.providers:
|
||||
try:
|
||||
result = await provider.get_model_by_hash(model_hash)
|
||||
if result:
|
||||
return result
|
||||
except Exception:
|
||||
continue
|
||||
return None
|
||||
|
||||
async def get_model_versions(self, model_id: str) -> Optional[Dict]:
|
||||
for provider in self.providers:
|
||||
try:
|
||||
result = await provider.get_model_versions(model_id)
|
||||
if result:
|
||||
return result
|
||||
except Exception as e:
|
||||
logger.debug(f"Provider failed for get_model_versions: {e}")
|
||||
continue
|
||||
return None
|
||||
|
||||
async def get_model_version(self, model_id: int = None, version_id: int = None) -> Optional[Dict]:
|
||||
for provider in self.providers:
|
||||
try:
|
||||
result = await provider.get_model_version(model_id, version_id)
|
||||
if result:
|
||||
return result
|
||||
except Exception as e:
|
||||
logger.debug(f"Provider failed for get_model_version: {e}")
|
||||
continue
|
||||
return None
|
||||
|
||||
async def get_model_version_info(self, version_id: str) -> Tuple[Optional[Dict], Optional[str]]:
|
||||
for provider in self.providers:
|
||||
try:
|
||||
result, error = await provider.get_model_version_info(version_id)
|
||||
if result:
|
||||
return result, error
|
||||
except Exception as e:
|
||||
logger.debug(f"Provider failed for get_model_version_info: {e}")
|
||||
continue
|
||||
return None, "No provider could retrieve the data"
|
||||
|
||||
async def get_model_metadata(self, model_id: str) -> Tuple[Optional[Dict], int]:
|
||||
for provider in self.providers:
|
||||
try:
|
||||
result, status = await provider.get_model_metadata(model_id)
|
||||
if result:
|
||||
return result, status
|
||||
except Exception as e:
|
||||
logger.debug(f"Provider failed for get_model_metadata: {e}")
|
||||
continue
|
||||
return None, 404
|
||||
|
||||
class ModelMetadataProviderManager:
|
||||
"""Manager for selecting and using model metadata providers"""
|
||||
|
||||
_instance = None
|
||||
|
||||
@classmethod
|
||||
async def get_instance(cls):
|
||||
"""Get singleton instance of ModelMetadataProviderManager"""
|
||||
if cls._instance is None:
|
||||
cls._instance = cls()
|
||||
return cls._instance
|
||||
|
||||
def __init__(self):
|
||||
self.providers = {}
|
||||
self.default_provider = None
|
||||
|
||||
def register_provider(self, name: str, provider: ModelMetadataProvider, is_default: bool = False):
|
||||
"""Register a metadata provider"""
|
||||
self.providers[name] = provider
|
||||
if is_default or self.default_provider is None:
|
||||
self.default_provider = name
|
||||
|
||||
async def get_model_by_hash(self, model_hash: str, provider_name: str = None) -> Optional[Dict]:
|
||||
"""Find model by hash using specified or default provider"""
|
||||
provider = self._get_provider(provider_name)
|
||||
return await provider.get_model_by_hash(model_hash)
|
||||
|
||||
async def get_model_versions(self, model_id: str, provider_name: str = None) -> Optional[Dict]:
|
||||
"""Get model versions using specified or default provider"""
|
||||
provider = self._get_provider(provider_name)
|
||||
return await provider.get_model_versions(model_id)
|
||||
|
||||
async def get_model_version(self, model_id: int = None, version_id: int = None, provider_name: str = None) -> Optional[Dict]:
|
||||
"""Get specific model version using specified or default provider"""
|
||||
provider = self._get_provider(provider_name)
|
||||
return await provider.get_model_version(model_id, version_id)
|
||||
|
||||
async def get_model_version_info(self, version_id: str, provider_name: str = None) -> Tuple[Optional[Dict], Optional[str]]:
|
||||
"""Fetch model version info using specified or default provider"""
|
||||
provider = self._get_provider(provider_name)
|
||||
return await provider.get_model_version_info(version_id)
|
||||
|
||||
async def get_model_metadata(self, model_id: str, provider_name: str = None) -> Tuple[Optional[Dict], int]:
|
||||
"""Fetch model metadata using specified or default provider"""
|
||||
provider = self._get_provider(provider_name)
|
||||
return await provider.get_model_metadata(model_id)
|
||||
|
||||
def _get_provider(self, provider_name: str = None) -> ModelMetadataProvider:
|
||||
"""Get provider by name or default provider"""
|
||||
if provider_name and provider_name in self.providers:
|
||||
return self.providers[provider_name]
|
||||
|
||||
if self.default_provider is None:
|
||||
raise ValueError("No default provider set and no valid provider specified")
|
||||
|
||||
return self.providers[self.default_provider]
|
||||
File diff suppressed because it is too large
Load Diff
142
py/services/model_service_factory.py
Normal file
142
py/services/model_service_factory.py
Normal file
@@ -0,0 +1,142 @@
|
||||
from typing import Dict, Type, Any
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class ModelServiceFactory:
|
||||
"""Factory for managing model services and routes"""
|
||||
|
||||
_services: Dict[str, Type] = {}
|
||||
_routes: Dict[str, Type] = {}
|
||||
_initialized_services: Dict[str, Any] = {}
|
||||
_initialized_routes: Dict[str, Any] = {}
|
||||
|
||||
@classmethod
|
||||
def register_model_type(cls, model_type: str, service_class: Type, route_class: Type):
|
||||
"""Register a new model type with its service and route classes
|
||||
|
||||
Args:
|
||||
model_type: The model type identifier (e.g., 'lora', 'checkpoint')
|
||||
service_class: The service class for this model type
|
||||
route_class: The route class for this model type
|
||||
"""
|
||||
cls._services[model_type] = service_class
|
||||
cls._routes[model_type] = route_class
|
||||
logger.info(f"Registered model type '{model_type}' with service {service_class.__name__} and routes {route_class.__name__}")
|
||||
|
||||
@classmethod
|
||||
def get_service_class(cls, model_type: str) -> Type:
|
||||
"""Get service class for a model type
|
||||
|
||||
Args:
|
||||
model_type: The model type identifier
|
||||
|
||||
Returns:
|
||||
The service class for the model type
|
||||
|
||||
Raises:
|
||||
ValueError: If model type is not registered
|
||||
"""
|
||||
if model_type not in cls._services:
|
||||
raise ValueError(f"Unknown model type: {model_type}")
|
||||
return cls._services[model_type]
|
||||
|
||||
@classmethod
|
||||
def get_route_class(cls, model_type: str) -> Type:
|
||||
"""Get route class for a model type
|
||||
|
||||
Args:
|
||||
model_type: The model type identifier
|
||||
|
||||
Returns:
|
||||
The route class for the model type
|
||||
|
||||
Raises:
|
||||
ValueError: If model type is not registered
|
||||
"""
|
||||
if model_type not in cls._routes:
|
||||
raise ValueError(f"Unknown model type: {model_type}")
|
||||
return cls._routes[model_type]
|
||||
|
||||
@classmethod
|
||||
def get_route_instance(cls, model_type: str):
|
||||
"""Get or create route instance for a model type
|
||||
|
||||
Args:
|
||||
model_type: The model type identifier
|
||||
|
||||
Returns:
|
||||
The route instance for the model type
|
||||
"""
|
||||
if model_type not in cls._initialized_routes:
|
||||
route_class = cls.get_route_class(model_type)
|
||||
cls._initialized_routes[model_type] = route_class()
|
||||
return cls._initialized_routes[model_type]
|
||||
|
||||
@classmethod
|
||||
def setup_all_routes(cls, app):
|
||||
"""Setup routes for all registered model types
|
||||
|
||||
Args:
|
||||
app: The aiohttp application instance
|
||||
"""
|
||||
logger.info(f"Setting up routes for {len(cls._services)} registered model types")
|
||||
|
||||
for model_type in cls._services.keys():
|
||||
try:
|
||||
routes_instance = cls.get_route_instance(model_type)
|
||||
routes_instance.setup_routes(app)
|
||||
logger.info(f"Successfully set up routes for {model_type}")
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to setup routes for {model_type}: {e}", exc_info=True)
|
||||
|
||||
@classmethod
|
||||
def get_registered_types(cls) -> list:
|
||||
"""Get list of all registered model types
|
||||
|
||||
Returns:
|
||||
List of registered model type identifiers
|
||||
"""
|
||||
return list(cls._services.keys())
|
||||
|
||||
@classmethod
|
||||
def is_registered(cls, model_type: str) -> bool:
|
||||
"""Check if a model type is registered
|
||||
|
||||
Args:
|
||||
model_type: The model type identifier
|
||||
|
||||
Returns:
|
||||
True if the model type is registered, False otherwise
|
||||
"""
|
||||
return model_type in cls._services
|
||||
|
||||
@classmethod
|
||||
def clear_registrations(cls):
|
||||
"""Clear all registrations - mainly for testing purposes"""
|
||||
cls._services.clear()
|
||||
cls._routes.clear()
|
||||
cls._initialized_services.clear()
|
||||
cls._initialized_routes.clear()
|
||||
logger.info("Cleared all model type registrations")
|
||||
|
||||
|
||||
def register_default_model_types():
|
||||
"""Register the default model types (LoRA, Checkpoint, and Embedding)"""
|
||||
from ..services.lora_service import LoraService
|
||||
from ..services.checkpoint_service import CheckpointService
|
||||
from ..services.embedding_service import EmbeddingService
|
||||
from ..routes.lora_routes import LoraRoutes
|
||||
from ..routes.checkpoint_routes import CheckpointRoutes
|
||||
from ..routes.embedding_routes import EmbeddingRoutes
|
||||
|
||||
# Register LoRA model type
|
||||
ModelServiceFactory.register_model_type('lora', LoraService, LoraRoutes)
|
||||
|
||||
# Register Checkpoint model type
|
||||
ModelServiceFactory.register_model_type('checkpoint', CheckpointService, CheckpointRoutes)
|
||||
|
||||
# Register Embedding model type
|
||||
ModelServiceFactory.register_model_type('embedding', EmbeddingService, EmbeddingRoutes)
|
||||
|
||||
logger.info("Registered default model types: lora, checkpoint, embedding")
|
||||
@@ -8,6 +8,7 @@ from ..config import config
|
||||
from .recipe_cache import RecipeCache
|
||||
from .service_registry import ServiceRegistry
|
||||
from .lora_scanner import LoraScanner
|
||||
from .metadata_service import get_default_metadata_provider
|
||||
from ..utils.utils import fuzzy_match
|
||||
from natsort import natsorted
|
||||
import sys
|
||||
@@ -393,8 +394,8 @@ class RecipeScanner:
|
||||
if 'hash' in lora and (not lora.get('file_name') or not lora['file_name']):
|
||||
hash_value = lora['hash']
|
||||
|
||||
if self._lora_scanner.has_lora_hash(hash_value):
|
||||
lora_path = self._lora_scanner.get_lora_path_by_hash(hash_value)
|
||||
if self._lora_scanner.has_hash(hash_value):
|
||||
lora_path = self._lora_scanner.get_path_by_hash(hash_value)
|
||||
if lora_path:
|
||||
file_name = os.path.splitext(os.path.basename(lora_path))[0]
|
||||
lora['file_name'] = file_name
|
||||
@@ -431,13 +432,13 @@ class RecipeScanner:
|
||||
async def _get_hash_from_civitai(self, model_version_id: str) -> Optional[str]:
|
||||
"""Get hash from Civitai API"""
|
||||
try:
|
||||
# Get CivitaiClient from ServiceRegistry
|
||||
civitai_client = await self._get_civitai_client()
|
||||
if not civitai_client:
|
||||
logger.error("Failed to get CivitaiClient from ServiceRegistry")
|
||||
# Get metadata provider instead of civitai client directly
|
||||
metadata_provider = await get_default_metadata_provider()
|
||||
if not metadata_provider:
|
||||
logger.error("Failed to get metadata provider")
|
||||
return None
|
||||
|
||||
version_info, error_msg = await civitai_client.get_model_version_info(model_version_id)
|
||||
version_info, error_msg = await metadata_provider.get_model_version_info(model_version_id)
|
||||
|
||||
if not version_info:
|
||||
if error_msg and "model not found" in error_msg.lower():
|
||||
@@ -465,7 +466,7 @@ class RecipeScanner:
|
||||
# Count occurrences of each base model
|
||||
for lora in loras:
|
||||
if 'hash' in lora:
|
||||
lora_path = self._lora_scanner.get_lora_path_by_hash(lora['hash'])
|
||||
lora_path = self._lora_scanner.get_path_by_hash(lora['hash'])
|
||||
if lora_path:
|
||||
base_model = await self._get_base_model_for_lora(lora_path)
|
||||
if base_model:
|
||||
@@ -603,9 +604,9 @@ class RecipeScanner:
|
||||
if 'loras' in item:
|
||||
for lora in item['loras']:
|
||||
if 'hash' in lora and lora['hash']:
|
||||
lora['inLibrary'] = self._lora_scanner.has_lora_hash(lora['hash'].lower())
|
||||
lora['inLibrary'] = self._lora_scanner.has_hash(lora['hash'].lower())
|
||||
lora['preview_url'] = self._lora_scanner.get_preview_url_by_hash(lora['hash'].lower())
|
||||
lora['localPath'] = self._lora_scanner.get_lora_path_by_hash(lora['hash'].lower())
|
||||
lora['localPath'] = self._lora_scanner.get_path_by_hash(lora['hash'].lower())
|
||||
|
||||
result = {
|
||||
'items': paginated_items,
|
||||
@@ -655,9 +656,9 @@ class RecipeScanner:
|
||||
for lora in formatted_recipe['loras']:
|
||||
if 'hash' in lora and lora['hash']:
|
||||
lora_hash = lora['hash'].lower()
|
||||
lora['inLibrary'] = self._lora_scanner.has_lora_hash(lora_hash)
|
||||
lora['inLibrary'] = self._lora_scanner.has_hash(lora_hash)
|
||||
lora['preview_url'] = self._lora_scanner.get_preview_url_by_hash(lora_hash)
|
||||
lora['localPath'] = self._lora_scanner.get_lora_path_by_hash(lora_hash)
|
||||
lora['localPath'] = self._lora_scanner.get_path_by_hash(lora_hash)
|
||||
|
||||
return formatted_recipe
|
||||
|
||||
|
||||
114
py/services/server_i18n.py
Normal file
114
py/services/server_i18n.py
Normal file
@@ -0,0 +1,114 @@
|
||||
import os
|
||||
import json
|
||||
import logging
|
||||
from typing import Dict, Any, Optional
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class ServerI18nManager:
|
||||
"""Server-side internationalization manager for template rendering"""
|
||||
|
||||
def __init__(self):
|
||||
self.translations = {}
|
||||
self.current_locale = 'en'
|
||||
self._load_translations()
|
||||
|
||||
def _load_translations(self):
|
||||
"""Load all translation files from the locales directory"""
|
||||
i18n_path = os.path.join(
|
||||
os.path.dirname(os.path.dirname(os.path.dirname(__file__))),
|
||||
'locales'
|
||||
)
|
||||
|
||||
if not os.path.exists(i18n_path):
|
||||
logger.warning(f"I18n directory not found: {i18n_path}")
|
||||
return
|
||||
|
||||
# Load all available locale files
|
||||
for filename in os.listdir(i18n_path):
|
||||
if filename.endswith('.json'):
|
||||
locale_code = filename[:-5] # Remove .json extension
|
||||
try:
|
||||
self._load_locale_file(i18n_path, filename, locale_code)
|
||||
except Exception as e:
|
||||
logger.error(f"Error loading locale file {filename}: {e}")
|
||||
|
||||
def _load_locale_file(self, path: str, filename: str, locale_code: str):
|
||||
"""Load a single locale JSON file"""
|
||||
file_path = os.path.join(path, filename)
|
||||
|
||||
try:
|
||||
with open(file_path, 'r', encoding='utf-8') as f:
|
||||
translations = json.load(f)
|
||||
|
||||
self.translations[locale_code] = translations
|
||||
logger.debug(f"Loaded translations for {locale_code} from {filename}")
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error parsing locale file {filename}: {e}")
|
||||
|
||||
def set_locale(self, locale: str):
|
||||
"""Set the current locale"""
|
||||
if locale in self.translations:
|
||||
self.current_locale = locale
|
||||
else:
|
||||
logger.warning(f"Locale {locale} not found, using 'en'")
|
||||
self.current_locale = 'en'
|
||||
|
||||
def get_translation(self, key: str, params: Dict[str, Any] = None, **kwargs) -> str:
|
||||
"""Get translation for a key with optional parameters (supports both dict and keyword args)"""
|
||||
# Merge kwargs into params for convenience
|
||||
if params is None:
|
||||
params = {}
|
||||
if kwargs:
|
||||
params = {**params, **kwargs}
|
||||
|
||||
if self.current_locale not in self.translations:
|
||||
return key
|
||||
|
||||
# Navigate through nested object using dot notation
|
||||
keys = key.split('.')
|
||||
value = self.translations[self.current_locale]
|
||||
|
||||
for k in keys:
|
||||
if isinstance(value, dict) and k in value:
|
||||
value = value[k]
|
||||
else:
|
||||
# Fallback to English if current locale doesn't have the key
|
||||
if self.current_locale != 'en' and 'en' in self.translations:
|
||||
en_value = self.translations['en']
|
||||
for k in keys:
|
||||
if isinstance(en_value, dict) and k in en_value:
|
||||
en_value = en_value[k]
|
||||
else:
|
||||
return key
|
||||
value = en_value
|
||||
else:
|
||||
return key
|
||||
break
|
||||
|
||||
if not isinstance(value, str):
|
||||
return key
|
||||
|
||||
# Replace parameters if provided
|
||||
if params:
|
||||
for param_key, param_value in params.items():
|
||||
placeholder = f"{{{param_key}}}"
|
||||
double_placeholder = f"{{{{{param_key}}}}}"
|
||||
value = value.replace(placeholder, str(param_value))
|
||||
value = value.replace(double_placeholder, str(param_value))
|
||||
|
||||
return value
|
||||
|
||||
def get_available_locales(self) -> list:
|
||||
"""Get list of available locales"""
|
||||
return list(self.translations.keys())
|
||||
|
||||
def create_template_filter(self):
|
||||
"""Create a Jinja2 filter function for templates"""
|
||||
def t_filter(key: str, **params) -> str:
|
||||
return self.get_translation(key, params)
|
||||
return t_filter
|
||||
|
||||
# Create global instance
|
||||
server_i18n = ServerI18nManager()
|
||||
@@ -7,118 +7,209 @@ logger = logging.getLogger(__name__)
|
||||
T = TypeVar('T') # Define a type variable for service types
|
||||
|
||||
class ServiceRegistry:
|
||||
"""Centralized registry for service singletons"""
|
||||
"""Central registry for managing singleton services"""
|
||||
|
||||
_instance = None
|
||||
_services: Dict[str, Any] = {}
|
||||
_lock = asyncio.Lock()
|
||||
_locks: Dict[str, asyncio.Lock] = {}
|
||||
|
||||
@classmethod
|
||||
def get_instance(cls):
|
||||
"""Get singleton instance of the registry"""
|
||||
if cls._instance is None:
|
||||
cls._instance = cls()
|
||||
return cls._instance
|
||||
async def register_service(cls, name: str, service: Any) -> None:
|
||||
"""Register a service instance with the registry
|
||||
|
||||
Args:
|
||||
name: Service name identifier
|
||||
service: Service instance to register
|
||||
"""
|
||||
cls._services[name] = service
|
||||
logger.debug(f"Registered service: {name}")
|
||||
|
||||
@classmethod
|
||||
async def register_service(cls, service_name: str, service_instance: Any) -> None:
|
||||
"""Register a service instance with the registry"""
|
||||
registry = cls.get_instance()
|
||||
async with cls._lock:
|
||||
registry._services[service_name] = service_instance
|
||||
logger.debug(f"Registered service: {service_name}")
|
||||
async def get_service(cls, name: str) -> Optional[Any]:
|
||||
"""Get a service instance by name
|
||||
|
||||
Args:
|
||||
name: Service name identifier
|
||||
|
||||
Returns:
|
||||
Service instance or None if not found
|
||||
"""
|
||||
return cls._services.get(name)
|
||||
|
||||
@classmethod
|
||||
async def get_service(cls, service_name: str) -> Any:
|
||||
"""Get a service instance by name"""
|
||||
registry = cls.get_instance()
|
||||
async with cls._lock:
|
||||
if service_name not in registry._services:
|
||||
logger.debug(f"Service {service_name} not found in registry")
|
||||
return None
|
||||
return registry._services[service_name]
|
||||
def get_service_sync(cls, name: str) -> Optional[Any]:
|
||||
"""Synchronously get a service instance by name
|
||||
|
||||
Args:
|
||||
name: Service name identifier
|
||||
|
||||
Returns:
|
||||
Service instance or None if not found
|
||||
"""
|
||||
return cls._services.get(name)
|
||||
|
||||
@classmethod
|
||||
def _get_lock(cls, name: str) -> asyncio.Lock:
|
||||
"""Get or create a lock for a service
|
||||
|
||||
Args:
|
||||
name: Service name identifier
|
||||
|
||||
Returns:
|
||||
AsyncIO lock for the service
|
||||
"""
|
||||
if name not in cls._locks:
|
||||
cls._locks[name] = asyncio.Lock()
|
||||
return cls._locks[name]
|
||||
|
||||
# Convenience methods for common services
|
||||
@classmethod
|
||||
async def get_lora_scanner(cls):
|
||||
"""Get the LoraScanner instance"""
|
||||
from .lora_scanner import LoraScanner
|
||||
scanner = await cls.get_service("lora_scanner")
|
||||
if scanner is None:
|
||||
scanner = await LoraScanner.get_instance()
|
||||
await cls.register_service("lora_scanner", scanner)
|
||||
return scanner
|
||||
"""Get or create LoRA scanner instance"""
|
||||
service_name = "lora_scanner"
|
||||
|
||||
if service_name in cls._services:
|
||||
return cls._services[service_name]
|
||||
|
||||
async with cls._get_lock(service_name):
|
||||
# Double-check after acquiring lock
|
||||
if service_name in cls._services:
|
||||
return cls._services[service_name]
|
||||
|
||||
# Import here to avoid circular imports
|
||||
from .lora_scanner import LoraScanner
|
||||
|
||||
scanner = await LoraScanner.get_instance()
|
||||
cls._services[service_name] = scanner
|
||||
logger.debug(f"Created and registered {service_name}")
|
||||
return scanner
|
||||
|
||||
@classmethod
|
||||
async def get_checkpoint_scanner(cls):
|
||||
"""Get the CheckpointScanner instance"""
|
||||
from .checkpoint_scanner import CheckpointScanner
|
||||
scanner = await cls.get_service("checkpoint_scanner")
|
||||
if scanner is None:
|
||||
"""Get or create Checkpoint scanner instance"""
|
||||
service_name = "checkpoint_scanner"
|
||||
|
||||
if service_name in cls._services:
|
||||
return cls._services[service_name]
|
||||
|
||||
async with cls._get_lock(service_name):
|
||||
# Double-check after acquiring lock
|
||||
if service_name in cls._services:
|
||||
return cls._services[service_name]
|
||||
|
||||
# Import here to avoid circular imports
|
||||
from .checkpoint_scanner import CheckpointScanner
|
||||
|
||||
scanner = await CheckpointScanner.get_instance()
|
||||
await cls.register_service("checkpoint_scanner", scanner)
|
||||
return scanner
|
||||
cls._services[service_name] = scanner
|
||||
logger.debug(f"Created and registered {service_name}")
|
||||
return scanner
|
||||
|
||||
@classmethod
|
||||
async def get_lora_monitor(cls):
|
||||
"""Get the LoraFileMonitor instance"""
|
||||
from .file_monitor import LoraFileMonitor
|
||||
monitor = await cls.get_service("lora_monitor")
|
||||
if monitor is None:
|
||||
monitor = await LoraFileMonitor.get_instance()
|
||||
await cls.register_service("lora_monitor", monitor)
|
||||
return monitor
|
||||
|
||||
@classmethod
|
||||
async def get_checkpoint_monitor(cls):
|
||||
"""Get the CheckpointFileMonitor instance"""
|
||||
from .file_monitor import CheckpointFileMonitor
|
||||
monitor = await cls.get_service("checkpoint_monitor")
|
||||
if monitor is None:
|
||||
monitor = await CheckpointFileMonitor.get_instance()
|
||||
await cls.register_service("checkpoint_monitor", monitor)
|
||||
return monitor
|
||||
|
||||
@classmethod
|
||||
async def get_civitai_client(cls):
|
||||
"""Get the CivitaiClient instance"""
|
||||
from .civitai_client import CivitaiClient
|
||||
client = await cls.get_service("civitai_client")
|
||||
if client is None:
|
||||
client = await CivitaiClient.get_instance()
|
||||
await cls.register_service("civitai_client", client)
|
||||
return client
|
||||
|
||||
@classmethod
|
||||
async def get_download_manager(cls):
|
||||
"""Get the DownloadManager instance"""
|
||||
from .download_manager import DownloadManager
|
||||
manager = await cls.get_service("download_manager")
|
||||
if manager is None:
|
||||
# We'll let DownloadManager.get_instance handle file_monitor parameter
|
||||
manager = await DownloadManager.get_instance()
|
||||
await cls.register_service("download_manager", manager)
|
||||
return manager
|
||||
|
||||
@classmethod
|
||||
async def get_recipe_scanner(cls):
|
||||
"""Get the RecipeScanner instance"""
|
||||
from .recipe_scanner import RecipeScanner
|
||||
scanner = await cls.get_service("recipe_scanner")
|
||||
if scanner is None:
|
||||
lora_scanner = await cls.get_lora_scanner()
|
||||
scanner = RecipeScanner(lora_scanner)
|
||||
await cls.register_service("recipe_scanner", scanner)
|
||||
return scanner
|
||||
|
||||
"""Get or create Recipe scanner instance"""
|
||||
service_name = "recipe_scanner"
|
||||
|
||||
if service_name in cls._services:
|
||||
return cls._services[service_name]
|
||||
|
||||
async with cls._get_lock(service_name):
|
||||
# Double-check after acquiring lock
|
||||
if service_name in cls._services:
|
||||
return cls._services[service_name]
|
||||
|
||||
# Import here to avoid circular imports
|
||||
from .recipe_scanner import RecipeScanner
|
||||
|
||||
scanner = await RecipeScanner.get_instance()
|
||||
cls._services[service_name] = scanner
|
||||
logger.debug(f"Created and registered {service_name}")
|
||||
return scanner
|
||||
|
||||
@classmethod
|
||||
async def get_civitai_client(cls):
|
||||
"""Get or create CivitAI client instance"""
|
||||
service_name = "civitai_client"
|
||||
|
||||
if service_name in cls._services:
|
||||
return cls._services[service_name]
|
||||
|
||||
async with cls._get_lock(service_name):
|
||||
# Double-check after acquiring lock
|
||||
if service_name in cls._services:
|
||||
return cls._services[service_name]
|
||||
|
||||
# Import here to avoid circular imports
|
||||
from .civitai_client import CivitaiClient
|
||||
|
||||
client = await CivitaiClient.get_instance()
|
||||
cls._services[service_name] = client
|
||||
logger.debug(f"Created and registered {service_name}")
|
||||
return client
|
||||
|
||||
@classmethod
|
||||
async def get_download_manager(cls):
|
||||
"""Get or create Download manager instance"""
|
||||
service_name = "download_manager"
|
||||
|
||||
if service_name in cls._services:
|
||||
return cls._services[service_name]
|
||||
|
||||
async with cls._get_lock(service_name):
|
||||
# Double-check after acquiring lock
|
||||
if service_name in cls._services:
|
||||
return cls._services[service_name]
|
||||
|
||||
# Import here to avoid circular imports
|
||||
from .download_manager import DownloadManager
|
||||
|
||||
manager = DownloadManager()
|
||||
cls._services[service_name] = manager
|
||||
logger.debug(f"Created and registered {service_name}")
|
||||
return manager
|
||||
|
||||
@classmethod
|
||||
async def get_websocket_manager(cls):
|
||||
"""Get the WebSocketManager instance"""
|
||||
from .websocket_manager import ws_manager
|
||||
manager = await cls.get_service("websocket_manager")
|
||||
if manager is None:
|
||||
# ws_manager is already a global instance in websocket_manager.py
|
||||
"""Get or create WebSocket manager instance"""
|
||||
service_name = "websocket_manager"
|
||||
|
||||
if service_name in cls._services:
|
||||
return cls._services[service_name]
|
||||
|
||||
async with cls._get_lock(service_name):
|
||||
# Double-check after acquiring lock
|
||||
if service_name in cls._services:
|
||||
return cls._services[service_name]
|
||||
|
||||
# Import here to avoid circular imports
|
||||
from .websocket_manager import ws_manager
|
||||
await cls.register_service("websocket_manager", ws_manager)
|
||||
manager = ws_manager
|
||||
return manager
|
||||
|
||||
cls._services[service_name] = ws_manager
|
||||
logger.debug(f"Registered {service_name}")
|
||||
return ws_manager
|
||||
|
||||
@classmethod
|
||||
async def get_embedding_scanner(cls):
|
||||
"""Get or create Embedding scanner instance"""
|
||||
service_name = "embedding_scanner"
|
||||
|
||||
if service_name in cls._services:
|
||||
return cls._services[service_name]
|
||||
|
||||
async with cls._get_lock(service_name):
|
||||
# Double-check after acquiring lock
|
||||
if service_name in cls._services:
|
||||
return cls._services[service_name]
|
||||
|
||||
# Import here to avoid circular imports
|
||||
from .embedding_scanner import EmbeddingScanner
|
||||
|
||||
scanner = await EmbeddingScanner.get_instance()
|
||||
cls._services[service_name] = scanner
|
||||
logger.debug(f"Created and registered {service_name}")
|
||||
return scanner
|
||||
|
||||
@classmethod
|
||||
def clear_services(cls):
|
||||
"""Clear all registered services - mainly for testing"""
|
||||
cls._services.clear()
|
||||
cls._locks.clear()
|
||||
logger.info("Cleared all registered services")
|
||||
@@ -9,6 +9,8 @@ class SettingsManager:
|
||||
def __init__(self):
|
||||
self.settings_file = os.path.join(os.path.dirname(os.path.dirname(os.path.dirname(__file__))), 'settings.json')
|
||||
self.settings = self._load_settings()
|
||||
self._migrate_download_path_template()
|
||||
self._auto_set_default_roots()
|
||||
self._check_environment_variables()
|
||||
|
||||
def _load_settings(self) -> Dict[str, Any]:
|
||||
@@ -21,6 +23,46 @@ class SettingsManager:
|
||||
logger.error(f"Error loading settings: {e}")
|
||||
return self._get_default_settings()
|
||||
|
||||
def _migrate_download_path_template(self):
|
||||
"""Migrate old download_path_template to new download_path_templates"""
|
||||
old_template = self.settings.get('download_path_template')
|
||||
templates = self.settings.get('download_path_templates')
|
||||
|
||||
# If old template exists and new templates don't exist, migrate
|
||||
if old_template is not None and not templates:
|
||||
logger.info("Migrating download_path_template to download_path_templates")
|
||||
self.settings['download_path_templates'] = {
|
||||
'lora': old_template,
|
||||
'checkpoint': old_template,
|
||||
'embedding': old_template
|
||||
}
|
||||
# Remove old setting
|
||||
del self.settings['download_path_template']
|
||||
self._save_settings()
|
||||
logger.info("Migration completed")
|
||||
|
||||
def _auto_set_default_roots(self):
|
||||
"""Auto set default root paths if only one folder is present and default is empty."""
|
||||
folder_paths = self.settings.get('folder_paths', {})
|
||||
updated = False
|
||||
# loras
|
||||
loras = folder_paths.get('loras', [])
|
||||
if isinstance(loras, list) and len(loras) == 1 and not self.settings.get('default_lora_root'):
|
||||
self.settings['default_lora_root'] = loras[0]
|
||||
updated = True
|
||||
# checkpoints
|
||||
checkpoints = folder_paths.get('checkpoints', [])
|
||||
if isinstance(checkpoints, list) and len(checkpoints) == 1 and not self.settings.get('default_checkpoint_root'):
|
||||
self.settings['default_checkpoint_root'] = checkpoints[0]
|
||||
updated = True
|
||||
# embeddings
|
||||
embeddings = folder_paths.get('embeddings', [])
|
||||
if isinstance(embeddings, list) and len(embeddings) == 1 and not self.settings.get('default_embedding_root'):
|
||||
self.settings['default_embedding_root'] = embeddings[0]
|
||||
updated = True
|
||||
if updated:
|
||||
self._save_settings()
|
||||
|
||||
def _check_environment_variables(self) -> None:
|
||||
"""Check for environment variables and update settings if needed"""
|
||||
env_api_key = os.environ.get('CIVITAI_API_KEY')
|
||||
@@ -38,7 +80,14 @@ class SettingsManager:
|
||||
"""Return default settings"""
|
||||
return {
|
||||
"civitai_api_key": "",
|
||||
"show_only_sfw": False
|
||||
"language": "en",
|
||||
"enable_metadata_archive_db": False, # Enable metadata archive database
|
||||
"proxy_enabled": False, # Enable app-level proxy
|
||||
"proxy_host": "", # Proxy host
|
||||
"proxy_port": "", # Proxy port
|
||||
"proxy_username": "", # Proxy username (optional)
|
||||
"proxy_password": "", # Proxy password (optional)
|
||||
"proxy_type": "http" # Proxy type: http, https, socks4, socks5
|
||||
}
|
||||
|
||||
def get(self, key: str, default: Any = None) -> Any:
|
||||
@@ -50,6 +99,13 @@ class SettingsManager:
|
||||
self.settings[key] = value
|
||||
self._save_settings()
|
||||
|
||||
def delete(self, key: str) -> None:
|
||||
"""Delete setting key and save"""
|
||||
if key in self.settings:
|
||||
del self.settings[key]
|
||||
self._save_settings()
|
||||
logger.info(f"Deleted setting: {key}")
|
||||
|
||||
def _save_settings(self) -> None:
|
||||
"""Save settings to file"""
|
||||
try:
|
||||
@@ -58,4 +114,53 @@ class SettingsManager:
|
||||
except Exception as e:
|
||||
logger.error(f"Error saving settings: {e}")
|
||||
|
||||
def get_download_path_template(self, model_type: str) -> str:
|
||||
"""Get download path template for specific model type
|
||||
|
||||
Args:
|
||||
model_type: The type of model ('lora', 'checkpoint', 'embedding')
|
||||
|
||||
Returns:
|
||||
Template string for the model type, defaults to '{base_model}/{first_tag}'
|
||||
"""
|
||||
templates = self.settings.get('download_path_templates', {})
|
||||
|
||||
# Handle edge case where templates might be stored as JSON string
|
||||
if isinstance(templates, str):
|
||||
try:
|
||||
# Try to parse JSON string
|
||||
parsed_templates = json.loads(templates)
|
||||
if isinstance(parsed_templates, dict):
|
||||
# Update settings with parsed dictionary
|
||||
self.settings['download_path_templates'] = parsed_templates
|
||||
self._save_settings()
|
||||
templates = parsed_templates
|
||||
logger.info("Successfully parsed download_path_templates from JSON string")
|
||||
else:
|
||||
raise ValueError("Parsed JSON is not a dictionary")
|
||||
except (json.JSONDecodeError, ValueError) as e:
|
||||
# If parsing fails, set default values
|
||||
logger.warning(f"Failed to parse download_path_templates JSON string: {e}. Setting default values.")
|
||||
default_template = '{base_model}/{first_tag}'
|
||||
templates = {
|
||||
'lora': default_template,
|
||||
'checkpoint': default_template,
|
||||
'embedding': default_template
|
||||
}
|
||||
self.settings['download_path_templates'] = templates
|
||||
self._save_settings()
|
||||
|
||||
# Ensure templates is a dictionary
|
||||
if not isinstance(templates, dict):
|
||||
default_template = '{base_model}/{first_tag}'
|
||||
templates = {
|
||||
'lora': default_template,
|
||||
'checkpoint': default_template,
|
||||
'embedding': default_template
|
||||
}
|
||||
self.settings['download_path_templates'] = templates
|
||||
self._save_settings()
|
||||
|
||||
return templates.get(model_type, '{base_model}/{first_tag}')
|
||||
|
||||
settings = SettingsManager()
|
||||
|
||||
@@ -1,6 +1,9 @@
|
||||
import logging
|
||||
from aiohttp import web
|
||||
from typing import Set, Dict, Optional
|
||||
from uuid import uuid4
|
||||
import asyncio
|
||||
from datetime import datetime, timedelta
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@@ -10,7 +13,12 @@ class WebSocketManager:
|
||||
def __init__(self):
|
||||
self._websockets: Set[web.WebSocketResponse] = set()
|
||||
self._init_websockets: Set[web.WebSocketResponse] = set() # New set for initialization progress clients
|
||||
self._checkpoint_websockets: Set[web.WebSocketResponse] = set() # New set for checkpoint download progress
|
||||
self._download_websockets: Dict[str, web.WebSocketResponse] = {} # New dict for download-specific clients
|
||||
# Add progress tracking dictionary
|
||||
self._download_progress: Dict[str, Dict] = {}
|
||||
# Add auto-organize progress tracking
|
||||
self._auto_organize_progress: Optional[Dict] = None
|
||||
self._auto_organize_lock = asyncio.Lock()
|
||||
|
||||
async def handle_connection(self, request: web.Request) -> web.WebSocketResponse:
|
||||
"""Handle new WebSocket connection"""
|
||||
@@ -39,21 +47,48 @@ class WebSocketManager:
|
||||
finally:
|
||||
self._init_websockets.discard(ws)
|
||||
return ws
|
||||
|
||||
async def handle_checkpoint_connection(self, request: web.Request) -> web.WebSocketResponse:
|
||||
"""Handle new WebSocket connection for checkpoint download progress"""
|
||||
|
||||
async def handle_download_connection(self, request: web.Request) -> web.WebSocketResponse:
|
||||
"""Handle new WebSocket connection for download progress"""
|
||||
ws = web.WebSocketResponse()
|
||||
await ws.prepare(request)
|
||||
self._checkpoint_websockets.add(ws)
|
||||
|
||||
# Get download_id from query parameters
|
||||
download_id = request.query.get('id')
|
||||
|
||||
if not download_id:
|
||||
# Generate a new download ID if not provided
|
||||
download_id = str(uuid4())
|
||||
|
||||
# Store the websocket with its download ID
|
||||
self._download_websockets[download_id] = ws
|
||||
|
||||
try:
|
||||
# Send the download ID back to the client
|
||||
await ws.send_json({
|
||||
'type': 'download_id',
|
||||
'download_id': download_id
|
||||
})
|
||||
|
||||
async for msg in ws:
|
||||
if msg.type == web.WSMsgType.ERROR:
|
||||
logger.error(f'Checkpoint WebSocket error: {ws.exception()}')
|
||||
logger.error(f'Download WebSocket error: {ws.exception()}')
|
||||
finally:
|
||||
self._checkpoint_websockets.discard(ws)
|
||||
if download_id in self._download_websockets:
|
||||
del self._download_websockets[download_id]
|
||||
|
||||
# Schedule cleanup of completed downloads after WebSocket disconnection
|
||||
asyncio.create_task(self._delayed_cleanup(download_id))
|
||||
return ws
|
||||
|
||||
|
||||
async def _delayed_cleanup(self, download_id: str, delay_seconds: int = 300):
|
||||
"""Clean up download progress after a delay (5 minutes by default)"""
|
||||
await asyncio.sleep(delay_seconds)
|
||||
progress_data = self._download_progress.get(download_id)
|
||||
if progress_data and progress_data.get('progress', 0) >= 100:
|
||||
self.cleanup_download_progress(download_id)
|
||||
logger.debug(f"Delayed cleanup completed for download {download_id}")
|
||||
|
||||
async def broadcast(self, data: Dict):
|
||||
"""Broadcast message to all connected clients"""
|
||||
if not self._websockets:
|
||||
@@ -84,17 +119,72 @@ class WebSocketManager:
|
||||
except Exception as e:
|
||||
logger.error(f"Error sending initialization progress: {e}")
|
||||
|
||||
async def broadcast_checkpoint_progress(self, data: Dict):
|
||||
"""Broadcast checkpoint download progress to connected clients"""
|
||||
if not self._checkpoint_websockets:
|
||||
async def broadcast_download_progress(self, download_id: str, data: Dict):
|
||||
"""Send progress update to specific download client"""
|
||||
# Store simplified progress data in memory (only progress percentage)
|
||||
self._download_progress[download_id] = {
|
||||
'progress': data.get('progress', 0),
|
||||
'timestamp': datetime.now()
|
||||
}
|
||||
|
||||
if download_id not in self._download_websockets:
|
||||
logger.debug(f"No WebSocket found for download ID: {download_id}")
|
||||
return
|
||||
|
||||
for ws in self._checkpoint_websockets:
|
||||
try:
|
||||
await ws.send_json(data)
|
||||
except Exception as e:
|
||||
logger.error(f"Error sending checkpoint progress: {e}")
|
||||
|
||||
ws = self._download_websockets[download_id]
|
||||
try:
|
||||
await ws.send_json(data)
|
||||
except Exception as e:
|
||||
logger.error(f"Error sending download progress: {e}")
|
||||
|
||||
async def broadcast_auto_organize_progress(self, data: Dict):
|
||||
"""Broadcast auto-organize progress to connected clients"""
|
||||
# Store progress data in memory
|
||||
self._auto_organize_progress = data
|
||||
|
||||
# Broadcast via WebSocket
|
||||
await self.broadcast(data)
|
||||
|
||||
def get_auto_organize_progress(self) -> Optional[Dict]:
|
||||
"""Get current auto-organize progress"""
|
||||
return self._auto_organize_progress
|
||||
|
||||
def cleanup_auto_organize_progress(self):
|
||||
"""Clear auto-organize progress data"""
|
||||
self._auto_organize_progress = None
|
||||
|
||||
def is_auto_organize_running(self) -> bool:
|
||||
"""Check if auto-organize is currently running"""
|
||||
if not self._auto_organize_progress:
|
||||
return False
|
||||
status = self._auto_organize_progress.get('status')
|
||||
return status in ['started', 'processing', 'cleaning']
|
||||
|
||||
async def get_auto_organize_lock(self):
|
||||
"""Get the auto-organize lock"""
|
||||
return self._auto_organize_lock
|
||||
|
||||
def get_download_progress(self, download_id: str) -> Optional[Dict]:
|
||||
"""Get progress information for a specific download"""
|
||||
return self._download_progress.get(download_id)
|
||||
|
||||
def cleanup_download_progress(self, download_id: str):
|
||||
"""Remove progress info for a specific download"""
|
||||
self._download_progress.pop(download_id, None)
|
||||
|
||||
def cleanup_old_downloads(self, max_age_hours: int = 24):
|
||||
"""Clean up old download progress entries"""
|
||||
cutoff_time = datetime.now() - timedelta(hours=max_age_hours)
|
||||
to_remove = []
|
||||
|
||||
for download_id, progress_data in self._download_progress.items():
|
||||
if progress_data.get('timestamp', datetime.now()) < cutoff_time:
|
||||
to_remove.append(download_id)
|
||||
|
||||
for download_id in to_remove:
|
||||
self._download_progress.pop(download_id, None)
|
||||
logger.debug(f"Cleaned up old download progress for {download_id}")
|
||||
|
||||
def get_connected_clients_count(self) -> int:
|
||||
"""Get number of connected clients"""
|
||||
return len(self._websockets)
|
||||
@@ -102,10 +192,14 @@ class WebSocketManager:
|
||||
def get_init_clients_count(self) -> int:
|
||||
"""Get number of initialization progress clients"""
|
||||
return len(self._init_websockets)
|
||||
|
||||
def get_checkpoint_clients_count(self) -> int:
|
||||
"""Get number of checkpoint progress clients"""
|
||||
return len(self._checkpoint_websockets)
|
||||
|
||||
def get_download_clients_count(self) -> int:
|
||||
"""Get number of download progress clients"""
|
||||
return len(self._download_websockets)
|
||||
|
||||
def generate_download_id(self) -> str:
|
||||
"""Generate a unique download ID"""
|
||||
return str(uuid4())
|
||||
|
||||
# Global instance
|
||||
ws_manager = WebSocketManager()
|
||||
11
py/services/websocket_progress_callback.py
Normal file
11
py/services/websocket_progress_callback.py
Normal file
@@ -0,0 +1,11 @@
|
||||
from typing import Dict, Any
|
||||
from .model_file_service import ProgressCallback
|
||||
from .websocket_manager import ws_manager
|
||||
|
||||
|
||||
class WebSocketProgressCallback(ProgressCallback):
|
||||
"""WebSocket implementation of progress callback"""
|
||||
|
||||
async def on_progress(self, progress_data: Dict[str, Any]) -> None:
|
||||
"""Send progress data via WebSocket"""
|
||||
await ws_manager.broadcast_auto_organize_progress(progress_data)
|
||||
@@ -7,6 +7,16 @@ NSFW_LEVELS = {
|
||||
"Blocked": 32, # Probably not actually visible through the API without being logged in on model owner account?
|
||||
}
|
||||
|
||||
# Node type constants
|
||||
NODE_TYPES = {
|
||||
"Lora Loader (LoraManager)": 1,
|
||||
"Lora Stacker (LoraManager)": 2,
|
||||
"WanVideo Lora Select (LoraManager)": 3
|
||||
}
|
||||
|
||||
# Default ComfyUI node color when bgcolor is null
|
||||
DEFAULT_NODE_COLOR = "#353535"
|
||||
|
||||
# preview extensions
|
||||
PREVIEW_EXTENSIONS = [
|
||||
'.webp',
|
||||
@@ -18,7 +28,9 @@ PREVIEW_EXTENSIONS = [
|
||||
'.png',
|
||||
'.jpeg',
|
||||
'.jpg',
|
||||
'.mp4'
|
||||
'.mp4',
|
||||
'.gif',
|
||||
'.webm'
|
||||
]
|
||||
|
||||
# Card preview image width
|
||||
@@ -31,4 +43,18 @@ EXAMPLE_IMAGE_WIDTH = 832
|
||||
SUPPORTED_MEDIA_EXTENSIONS = {
|
||||
'images': ['.jpg', '.jpeg', '.png', '.webp', '.gif'],
|
||||
'videos': ['.mp4', '.webm']
|
||||
}
|
||||
}
|
||||
|
||||
# Valid Lora types
|
||||
VALID_LORA_TYPES = ['lora', 'locon', 'dora']
|
||||
|
||||
# Auto-organize settings
|
||||
AUTO_ORGANIZE_BATCH_SIZE = 50 # Process models in batches to avoid overwhelming the system
|
||||
|
||||
# Civitai model tags in priority order for subfolder organization
|
||||
CIVITAI_MODEL_TAGS = [
|
||||
'character', 'concept', 'clothing',
|
||||
'realistic', 'anime', 'toon', 'furry', 'style',
|
||||
'poses', 'background', 'tool', 'vehicle', 'buildings',
|
||||
'objects', 'assets', 'animal', 'action'
|
||||
]
|
||||
765
py/utils/example_images_download_manager.py
Normal file
765
py/utils/example_images_download_manager.py
Normal file
@@ -0,0 +1,765 @@
|
||||
import logging
|
||||
import os
|
||||
import asyncio
|
||||
import json
|
||||
import time
|
||||
from aiohttp import web
|
||||
from ..services.service_registry import ServiceRegistry
|
||||
from ..utils.metadata_manager import MetadataManager
|
||||
from .example_images_processor import ExampleImagesProcessor
|
||||
from .example_images_metadata import MetadataUpdater
|
||||
from ..services.websocket_manager import ws_manager # Add this import at the top
|
||||
from ..services.downloader import get_downloader
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# Download status tracking
|
||||
download_task = None
|
||||
is_downloading = False
|
||||
download_progress = {
|
||||
'total': 0,
|
||||
'completed': 0,
|
||||
'current_model': '',
|
||||
'status': 'idle', # idle, running, paused, completed, error
|
||||
'errors': [],
|
||||
'last_error': None,
|
||||
'start_time': None,
|
||||
'end_time': None,
|
||||
'processed_models': set(), # Track models that have been processed
|
||||
'refreshed_models': set(), # Track models that had metadata refreshed
|
||||
'failed_models': set() # Track models that failed to download after metadata refresh
|
||||
}
|
||||
|
||||
class DownloadManager:
|
||||
"""Manages downloading example images for models"""
|
||||
|
||||
@staticmethod
|
||||
async def start_download(request):
|
||||
"""
|
||||
Start downloading example images for models
|
||||
|
||||
Expects a JSON body with:
|
||||
{
|
||||
"output_dir": "path/to/output", # Base directory to save example images
|
||||
"optimize": true, # Whether to optimize images (default: true)
|
||||
"model_types": ["lora", "checkpoint"], # Model types to process (default: both)
|
||||
"delay": 1.0 # Delay between downloads to avoid rate limiting (default: 1.0)
|
||||
}
|
||||
"""
|
||||
global download_task, is_downloading, download_progress
|
||||
|
||||
if is_downloading:
|
||||
# Create a copy for JSON serialization
|
||||
response_progress = download_progress.copy()
|
||||
response_progress['processed_models'] = list(download_progress['processed_models'])
|
||||
response_progress['refreshed_models'] = list(download_progress['refreshed_models'])
|
||||
response_progress['failed_models'] = list(download_progress['failed_models'])
|
||||
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Download already in progress',
|
||||
'status': response_progress
|
||||
}, status=400)
|
||||
|
||||
try:
|
||||
# Parse the request body
|
||||
data = await request.json()
|
||||
output_dir = data.get('output_dir')
|
||||
optimize = data.get('optimize', True)
|
||||
model_types = data.get('model_types', ['lora', 'checkpoint'])
|
||||
delay = float(data.get('delay', 0.2)) # Default to 0.2 seconds
|
||||
|
||||
if not output_dir:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Missing output_dir parameter'
|
||||
}, status=400)
|
||||
|
||||
# Create the output directory
|
||||
os.makedirs(output_dir, exist_ok=True)
|
||||
|
||||
# Initialize progress tracking
|
||||
download_progress['total'] = 0
|
||||
download_progress['completed'] = 0
|
||||
download_progress['current_model'] = ''
|
||||
download_progress['status'] = 'running'
|
||||
download_progress['errors'] = []
|
||||
download_progress['last_error'] = None
|
||||
download_progress['start_time'] = time.time()
|
||||
download_progress['end_time'] = None
|
||||
|
||||
# Get the processed models list from a file if it exists
|
||||
progress_file = os.path.join(output_dir, '.download_progress.json')
|
||||
if os.path.exists(progress_file):
|
||||
try:
|
||||
with open(progress_file, 'r', encoding='utf-8') as f:
|
||||
saved_progress = json.load(f)
|
||||
download_progress['processed_models'] = set(saved_progress.get('processed_models', []))
|
||||
download_progress['failed_models'] = set(saved_progress.get('failed_models', []))
|
||||
logger.debug(f"Loaded previous progress, {len(download_progress['processed_models'])} models already processed, {len(download_progress['failed_models'])} models marked as failed")
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to load progress file: {e}")
|
||||
download_progress['processed_models'] = set()
|
||||
download_progress['failed_models'] = set()
|
||||
else:
|
||||
download_progress['processed_models'] = set()
|
||||
download_progress['failed_models'] = set()
|
||||
|
||||
# Start the download task
|
||||
is_downloading = True
|
||||
download_task = asyncio.create_task(
|
||||
DownloadManager._download_all_example_images(
|
||||
output_dir,
|
||||
optimize,
|
||||
model_types,
|
||||
delay
|
||||
)
|
||||
)
|
||||
|
||||
# Create a copy for JSON serialization
|
||||
response_progress = download_progress.copy()
|
||||
response_progress['processed_models'] = list(download_progress['processed_models'])
|
||||
response_progress['refreshed_models'] = list(download_progress['refreshed_models'])
|
||||
response_progress['failed_models'] = list(download_progress['failed_models'])
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'message': 'Download started',
|
||||
'status': response_progress
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to start example images download: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
@staticmethod
|
||||
async def get_status(request):
|
||||
"""Get the current status of example images download"""
|
||||
global download_progress
|
||||
|
||||
# Create a copy of the progress dict with the set converted to a list for JSON serialization
|
||||
response_progress = download_progress.copy()
|
||||
response_progress['processed_models'] = list(download_progress['processed_models'])
|
||||
response_progress['refreshed_models'] = list(download_progress['refreshed_models'])
|
||||
response_progress['failed_models'] = list(download_progress['failed_models'])
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'is_downloading': is_downloading,
|
||||
'status': response_progress
|
||||
})
|
||||
|
||||
@staticmethod
|
||||
async def pause_download(request):
|
||||
"""Pause the example images download"""
|
||||
global download_progress
|
||||
|
||||
if not is_downloading:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'No download in progress'
|
||||
}, status=400)
|
||||
|
||||
download_progress['status'] = 'paused'
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'message': 'Download paused'
|
||||
})
|
||||
|
||||
@staticmethod
|
||||
async def resume_download(request):
|
||||
"""Resume the example images download"""
|
||||
global download_progress
|
||||
|
||||
if not is_downloading:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'No download in progress'
|
||||
}, status=400)
|
||||
|
||||
if download_progress['status'] == 'paused':
|
||||
download_progress['status'] = 'running'
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'message': 'Download resumed'
|
||||
})
|
||||
else:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': f"Download is in '{download_progress['status']}' state, cannot resume"
|
||||
}, status=400)
|
||||
|
||||
@staticmethod
|
||||
async def _download_all_example_images(output_dir, optimize, model_types, delay):
|
||||
"""Download example images for all models"""
|
||||
global is_downloading, download_progress
|
||||
|
||||
# Get unified downloader
|
||||
downloader = await get_downloader()
|
||||
|
||||
try:
|
||||
# Get scanners
|
||||
scanners = []
|
||||
if 'lora' in model_types:
|
||||
lora_scanner = await ServiceRegistry.get_lora_scanner()
|
||||
scanners.append(('lora', lora_scanner))
|
||||
|
||||
if 'checkpoint' in model_types:
|
||||
checkpoint_scanner = await ServiceRegistry.get_checkpoint_scanner()
|
||||
scanners.append(('checkpoint', checkpoint_scanner))
|
||||
|
||||
if 'embedding' in model_types:
|
||||
embedding_scanner = await ServiceRegistry.get_embedding_scanner()
|
||||
scanners.append(('embedding', embedding_scanner))
|
||||
|
||||
# Get all models
|
||||
all_models = []
|
||||
for scanner_type, scanner in scanners:
|
||||
cache = await scanner.get_cached_data()
|
||||
if cache and cache.raw_data:
|
||||
for model in cache.raw_data:
|
||||
if model.get('sha256'):
|
||||
all_models.append((scanner_type, model, scanner))
|
||||
|
||||
# Update total count
|
||||
download_progress['total'] = len(all_models)
|
||||
logger.debug(f"Found {download_progress['total']} models to process")
|
||||
|
||||
# Process each model
|
||||
for i, (scanner_type, model, scanner) in enumerate(all_models):
|
||||
# Main logic for processing model is here, but actual operations are delegated to other classes
|
||||
was_remote_download = await DownloadManager._process_model(
|
||||
scanner_type, model, scanner,
|
||||
output_dir, optimize, downloader
|
||||
)
|
||||
|
||||
# Update progress
|
||||
download_progress['completed'] += 1
|
||||
|
||||
# Only add delay after remote download of models, and not after processing the last model
|
||||
if was_remote_download and i < len(all_models) - 1 and download_progress['status'] == 'running':
|
||||
await asyncio.sleep(delay)
|
||||
|
||||
# Mark as completed
|
||||
download_progress['status'] = 'completed'
|
||||
download_progress['end_time'] = time.time()
|
||||
logger.debug(f"Example images download completed: {download_progress['completed']}/{download_progress['total']} models processed")
|
||||
|
||||
except Exception as e:
|
||||
error_msg = f"Error during example images download: {str(e)}"
|
||||
logger.error(error_msg, exc_info=True)
|
||||
download_progress['errors'].append(error_msg)
|
||||
download_progress['last_error'] = error_msg
|
||||
download_progress['status'] = 'error'
|
||||
download_progress['end_time'] = time.time()
|
||||
|
||||
finally:
|
||||
# Save final progress to file
|
||||
try:
|
||||
DownloadManager._save_progress(output_dir)
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to save progress file: {e}")
|
||||
|
||||
# Set download status to not downloading
|
||||
is_downloading = False
|
||||
|
||||
@staticmethod
|
||||
async def _process_model(scanner_type, model, scanner, output_dir, optimize, downloader):
|
||||
"""Process a single model download"""
|
||||
global download_progress
|
||||
|
||||
# Check if download is paused
|
||||
while download_progress['status'] == 'paused':
|
||||
await asyncio.sleep(1)
|
||||
|
||||
# Check if download should continue
|
||||
if download_progress['status'] != 'running':
|
||||
logger.info(f"Download stopped: {download_progress['status']}")
|
||||
return False # Return False to indicate no remote download happened
|
||||
|
||||
model_hash = model.get('sha256', '').lower()
|
||||
model_name = model.get('model_name', 'Unknown')
|
||||
model_file_path = model.get('file_path', '')
|
||||
model_file_name = model.get('file_name', '')
|
||||
|
||||
try:
|
||||
# Update current model info
|
||||
download_progress['current_model'] = f"{model_name} ({model_hash[:8]})"
|
||||
|
||||
# Skip if already in failed models
|
||||
if model_hash in download_progress['failed_models']:
|
||||
logger.debug(f"Skipping known failed model: {model_name}")
|
||||
return False
|
||||
|
||||
# Skip if already processed AND directory exists with files
|
||||
if model_hash in download_progress['processed_models']:
|
||||
model_dir = os.path.join(output_dir, model_hash)
|
||||
has_files = os.path.exists(model_dir) and any(os.listdir(model_dir))
|
||||
if has_files:
|
||||
logger.debug(f"Skipping already processed model: {model_name}")
|
||||
return False
|
||||
else:
|
||||
logger.info(f"Model {model_name} marked as processed but folder empty or missing, reprocessing")
|
||||
# Remove from processed models since we need to reprocess
|
||||
download_progress['processed_models'].discard(model_hash)
|
||||
|
||||
# Create model directory
|
||||
model_dir = os.path.join(output_dir, model_hash)
|
||||
os.makedirs(model_dir, exist_ok=True)
|
||||
|
||||
# First check for local example images - local processing doesn't need delay
|
||||
local_images_processed = await ExampleImagesProcessor.process_local_examples(
|
||||
model_file_path, model_file_name, model_name, model_dir, optimize
|
||||
)
|
||||
|
||||
# If we processed local images, update metadata
|
||||
if local_images_processed:
|
||||
await MetadataUpdater.update_metadata_from_local_examples(
|
||||
model_hash, model, scanner_type, scanner, model_dir
|
||||
)
|
||||
download_progress['processed_models'].add(model_hash)
|
||||
return False # Return False to indicate no remote download happened
|
||||
|
||||
# If no local images, try to download from remote
|
||||
elif model.get('civitai') and model.get('civitai', {}).get('images'):
|
||||
images = model.get('civitai', {}).get('images', [])
|
||||
|
||||
success, is_stale = await ExampleImagesProcessor.download_model_images(
|
||||
model_hash, model_name, images, model_dir, optimize, downloader
|
||||
)
|
||||
|
||||
# If metadata is stale, try to refresh it
|
||||
if is_stale and model_hash not in download_progress['refreshed_models']:
|
||||
await MetadataUpdater.refresh_model_metadata(
|
||||
model_hash, model_name, scanner_type, scanner
|
||||
)
|
||||
|
||||
# Get the updated model data
|
||||
updated_model = await MetadataUpdater.get_updated_model(
|
||||
model_hash, scanner
|
||||
)
|
||||
|
||||
if updated_model and updated_model.get('civitai', {}).get('images'):
|
||||
# Retry download with updated metadata
|
||||
updated_images = updated_model.get('civitai', {}).get('images', [])
|
||||
success, _ = await ExampleImagesProcessor.download_model_images(
|
||||
model_hash, model_name, updated_images, model_dir, optimize, downloader
|
||||
)
|
||||
|
||||
download_progress['refreshed_models'].add(model_hash)
|
||||
|
||||
# Mark as processed if successful, or as failed if unsuccessful after refresh
|
||||
if success:
|
||||
download_progress['processed_models'].add(model_hash)
|
||||
else:
|
||||
# If we refreshed metadata and still failed, mark as permanently failed
|
||||
if model_hash in download_progress['refreshed_models']:
|
||||
download_progress['failed_models'].add(model_hash)
|
||||
logger.info(f"Marking model {model_name} as failed after metadata refresh")
|
||||
|
||||
return True # Return True to indicate a remote download happened
|
||||
else:
|
||||
# No civitai data or images available, mark as failed to avoid future attempts
|
||||
download_progress['failed_models'].add(model_hash)
|
||||
logger.debug(f"No civitai images available for model {model_name}, marking as failed")
|
||||
|
||||
# Save progress periodically
|
||||
if download_progress['completed'] % 10 == 0 or download_progress['completed'] == download_progress['total'] - 1:
|
||||
DownloadManager._save_progress(output_dir)
|
||||
|
||||
return False # Default return if no conditions met
|
||||
|
||||
except Exception as e:
|
||||
error_msg = f"Error processing model {model.get('model_name')}: {str(e)}"
|
||||
logger.error(error_msg, exc_info=True)
|
||||
download_progress['errors'].append(error_msg)
|
||||
download_progress['last_error'] = error_msg
|
||||
return False # Return False on exception
|
||||
|
||||
@staticmethod
|
||||
def _save_progress(output_dir):
|
||||
"""Save download progress to file"""
|
||||
global download_progress
|
||||
try:
|
||||
progress_file = os.path.join(output_dir, '.download_progress.json')
|
||||
|
||||
# Read existing progress file if it exists
|
||||
existing_data = {}
|
||||
if os.path.exists(progress_file):
|
||||
try:
|
||||
with open(progress_file, 'r', encoding='utf-8') as f:
|
||||
existing_data = json.load(f)
|
||||
except Exception as e:
|
||||
logger.warning(f"Failed to read existing progress file: {e}")
|
||||
|
||||
# Create new progress data
|
||||
progress_data = {
|
||||
'processed_models': list(download_progress['processed_models']),
|
||||
'refreshed_models': list(download_progress['refreshed_models']),
|
||||
'failed_models': list(download_progress['failed_models']),
|
||||
'completed': download_progress['completed'],
|
||||
'total': download_progress['total'],
|
||||
'last_update': time.time()
|
||||
}
|
||||
|
||||
# Preserve existing fields (especially naming_version)
|
||||
for key, value in existing_data.items():
|
||||
if key not in progress_data:
|
||||
progress_data[key] = value
|
||||
|
||||
# Write updated progress data
|
||||
with open(progress_file, 'w', encoding='utf-8') as f:
|
||||
json.dump(progress_data, f, indent=2)
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to save progress file: {e}")
|
||||
|
||||
@staticmethod
|
||||
async def start_force_download(request):
|
||||
"""
|
||||
Force download example images for specific models
|
||||
|
||||
Expects a JSON body with:
|
||||
{
|
||||
"model_hashes": ["hash1", "hash2", ...], # List of model hashes to download
|
||||
"output_dir": "path/to/output", # Base directory to save example images
|
||||
"optimize": true, # Whether to optimize images (default: true)
|
||||
"model_types": ["lora", "checkpoint"], # Model types to process (default: both)
|
||||
"delay": 1.0 # Delay between downloads (default: 1.0)
|
||||
}
|
||||
"""
|
||||
global download_task, is_downloading, download_progress
|
||||
|
||||
if is_downloading:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Download already in progress'
|
||||
}, status=400)
|
||||
|
||||
try:
|
||||
# Parse the request body
|
||||
data = await request.json()
|
||||
model_hashes = data.get('model_hashes', [])
|
||||
output_dir = data.get('output_dir')
|
||||
optimize = data.get('optimize', True)
|
||||
model_types = data.get('model_types', ['lora', 'checkpoint'])
|
||||
delay = float(data.get('delay', 0.2)) # Default to 0.2 seconds
|
||||
|
||||
if not model_hashes:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Missing model_hashes parameter'
|
||||
}, status=400)
|
||||
|
||||
if not output_dir:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Missing output_dir parameter'
|
||||
}, status=400)
|
||||
|
||||
# Create the output directory
|
||||
os.makedirs(output_dir, exist_ok=True)
|
||||
|
||||
# Initialize progress tracking
|
||||
download_progress['total'] = len(model_hashes)
|
||||
download_progress['completed'] = 0
|
||||
download_progress['current_model'] = ''
|
||||
download_progress['status'] = 'running'
|
||||
download_progress['errors'] = []
|
||||
download_progress['last_error'] = None
|
||||
download_progress['start_time'] = time.time()
|
||||
download_progress['end_time'] = None
|
||||
download_progress['processed_models'] = set()
|
||||
download_progress['refreshed_models'] = set()
|
||||
download_progress['failed_models'] = set()
|
||||
|
||||
# Set download status to downloading
|
||||
is_downloading = True
|
||||
|
||||
# Execute the download function directly instead of creating a background task
|
||||
result = await DownloadManager._download_specific_models_example_images_sync(
|
||||
model_hashes,
|
||||
output_dir,
|
||||
optimize,
|
||||
model_types,
|
||||
delay
|
||||
)
|
||||
|
||||
# Set download status to not downloading
|
||||
is_downloading = False
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'message': 'Force download completed',
|
||||
'result': result
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
# Set download status to not downloading
|
||||
is_downloading = False
|
||||
logger.error(f"Failed during forced example images download: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
@staticmethod
|
||||
async def _download_specific_models_example_images_sync(model_hashes, output_dir, optimize, model_types, delay):
|
||||
"""Download example images for specific models only - synchronous version"""
|
||||
global download_progress
|
||||
|
||||
# Get unified downloader
|
||||
downloader = await get_downloader()
|
||||
|
||||
try:
|
||||
# Get scanners
|
||||
scanners = []
|
||||
if 'lora' in model_types:
|
||||
lora_scanner = await ServiceRegistry.get_lora_scanner()
|
||||
scanners.append(('lora', lora_scanner))
|
||||
|
||||
if 'checkpoint' in model_types:
|
||||
checkpoint_scanner = await ServiceRegistry.get_checkpoint_scanner()
|
||||
scanners.append(('checkpoint', checkpoint_scanner))
|
||||
|
||||
if 'embedding' in model_types:
|
||||
embedding_scanner = await ServiceRegistry.get_embedding_scanner()
|
||||
scanners.append(('embedding', embedding_scanner))
|
||||
|
||||
# Find the specified models
|
||||
models_to_process = []
|
||||
for scanner_type, scanner in scanners:
|
||||
cache = await scanner.get_cached_data()
|
||||
if cache and cache.raw_data:
|
||||
for model in cache.raw_data:
|
||||
if model.get('sha256') in model_hashes:
|
||||
models_to_process.append((scanner_type, model, scanner))
|
||||
|
||||
# Update total count based on found models
|
||||
download_progress['total'] = len(models_to_process)
|
||||
logger.debug(f"Found {download_progress['total']} models to process")
|
||||
|
||||
# Send initial progress via WebSocket
|
||||
await ws_manager.broadcast({
|
||||
'type': 'example_images_progress',
|
||||
'processed': 0,
|
||||
'total': download_progress['total'],
|
||||
'status': 'running',
|
||||
'current_model': ''
|
||||
})
|
||||
|
||||
# Process each model
|
||||
success_count = 0
|
||||
for i, (scanner_type, model, scanner) in enumerate(models_to_process):
|
||||
# Force process this model regardless of previous status
|
||||
was_successful = await DownloadManager._process_specific_model(
|
||||
scanner_type, model, scanner,
|
||||
output_dir, optimize, downloader
|
||||
)
|
||||
|
||||
if was_successful:
|
||||
success_count += 1
|
||||
|
||||
# Update progress
|
||||
download_progress['completed'] += 1
|
||||
|
||||
# Send progress update via WebSocket
|
||||
await ws_manager.broadcast({
|
||||
'type': 'example_images_progress',
|
||||
'processed': download_progress['completed'],
|
||||
'total': download_progress['total'],
|
||||
'status': 'running',
|
||||
'current_model': download_progress['current_model']
|
||||
})
|
||||
|
||||
# Only add delay after remote download, and not after processing the last model
|
||||
if was_successful and i < len(models_to_process) - 1 and download_progress['status'] == 'running':
|
||||
await asyncio.sleep(delay)
|
||||
|
||||
# Mark as completed
|
||||
download_progress['status'] = 'completed'
|
||||
download_progress['end_time'] = time.time()
|
||||
logger.debug(f"Forced example images download completed: {download_progress['completed']}/{download_progress['total']} models processed")
|
||||
|
||||
# Send final progress via WebSocket
|
||||
await ws_manager.broadcast({
|
||||
'type': 'example_images_progress',
|
||||
'processed': download_progress['completed'],
|
||||
'total': download_progress['total'],
|
||||
'status': 'completed',
|
||||
'current_model': ''
|
||||
})
|
||||
|
||||
return {
|
||||
'total': download_progress['total'],
|
||||
'processed': download_progress['completed'],
|
||||
'successful': success_count,
|
||||
'errors': download_progress['errors']
|
||||
}
|
||||
|
||||
except Exception as e:
|
||||
error_msg = f"Error during forced example images download: {str(e)}"
|
||||
logger.error(error_msg, exc_info=True)
|
||||
download_progress['errors'].append(error_msg)
|
||||
download_progress['last_error'] = error_msg
|
||||
download_progress['status'] = 'error'
|
||||
download_progress['end_time'] = time.time()
|
||||
|
||||
# Send error status via WebSocket
|
||||
await ws_manager.broadcast({
|
||||
'type': 'example_images_progress',
|
||||
'processed': download_progress['completed'],
|
||||
'total': download_progress['total'],
|
||||
'status': 'error',
|
||||
'error': error_msg,
|
||||
'current_model': ''
|
||||
})
|
||||
|
||||
raise
|
||||
|
||||
finally:
|
||||
# No need to close any sessions since we use the global downloader
|
||||
pass
|
||||
|
||||
@staticmethod
|
||||
async def _process_specific_model(scanner_type, model, scanner, output_dir, optimize, downloader):
|
||||
"""Process a specific model for forced download, ignoring previous download status"""
|
||||
global download_progress
|
||||
|
||||
# Check if download is paused
|
||||
while download_progress['status'] == 'paused':
|
||||
await asyncio.sleep(1)
|
||||
|
||||
# Check if download should continue
|
||||
if download_progress['status'] != 'running':
|
||||
logger.info(f"Download stopped: {download_progress['status']}")
|
||||
return False
|
||||
|
||||
model_hash = model.get('sha256', '').lower()
|
||||
model_name = model.get('model_name', 'Unknown')
|
||||
model_file_path = model.get('file_path', '')
|
||||
model_file_name = model.get('file_name', '')
|
||||
|
||||
try:
|
||||
# Update current model info
|
||||
download_progress['current_model'] = f"{model_name} ({model_hash[:8]})"
|
||||
|
||||
# Create model directory
|
||||
model_dir = os.path.join(output_dir, model_hash)
|
||||
os.makedirs(model_dir, exist_ok=True)
|
||||
|
||||
# First check for local example images - local processing doesn't need delay
|
||||
local_images_processed = await ExampleImagesProcessor.process_local_examples(
|
||||
model_file_path, model_file_name, model_name, model_dir, optimize
|
||||
)
|
||||
|
||||
# If we processed local images, update metadata
|
||||
if local_images_processed:
|
||||
await MetadataUpdater.update_metadata_from_local_examples(
|
||||
model_hash, model, scanner_type, scanner, model_dir
|
||||
)
|
||||
download_progress['processed_models'].add(model_hash)
|
||||
return False # Return False to indicate no remote download happened
|
||||
|
||||
# If no local images, try to download from remote
|
||||
elif model.get('civitai') and model.get('civitai', {}).get('images'):
|
||||
images = model.get('civitai', {}).get('images', [])
|
||||
|
||||
success, is_stale, failed_images = await ExampleImagesProcessor.download_model_images_with_tracking(
|
||||
model_hash, model_name, images, model_dir, optimize, downloader
|
||||
)
|
||||
|
||||
# If metadata is stale, try to refresh it
|
||||
if is_stale and model_hash not in download_progress['refreshed_models']:
|
||||
await MetadataUpdater.refresh_model_metadata(
|
||||
model_hash, model_name, scanner_type, scanner
|
||||
)
|
||||
|
||||
# Get the updated model data
|
||||
updated_model = await MetadataUpdater.get_updated_model(
|
||||
model_hash, scanner
|
||||
)
|
||||
|
||||
if updated_model and updated_model.get('civitai', {}).get('images'):
|
||||
# Retry download with updated metadata
|
||||
updated_images = updated_model.get('civitai', {}).get('images', [])
|
||||
success, _, additional_failed_images = await ExampleImagesProcessor.download_model_images_with_tracking(
|
||||
model_hash, model_name, updated_images, model_dir, optimize, downloader
|
||||
)
|
||||
|
||||
# Combine failed images from both attempts
|
||||
failed_images.extend(additional_failed_images)
|
||||
|
||||
download_progress['refreshed_models'].add(model_hash)
|
||||
|
||||
# For forced downloads, remove failed images from metadata
|
||||
if failed_images:
|
||||
# Create a copy of images excluding failed ones
|
||||
await DownloadManager._remove_failed_images_from_metadata(
|
||||
model_hash, model_name, failed_images, scanner
|
||||
)
|
||||
|
||||
# Mark as processed
|
||||
if success or failed_images: # Mark as processed if we successfully downloaded some images or removed failed ones
|
||||
download_progress['processed_models'].add(model_hash)
|
||||
|
||||
return True # Return True to indicate a remote download happened
|
||||
else:
|
||||
logger.debug(f"No civitai images available for model {model_name}")
|
||||
return False
|
||||
|
||||
except Exception as e:
|
||||
error_msg = f"Error processing model {model.get('model_name')}: {str(e)}"
|
||||
logger.error(error_msg, exc_info=True)
|
||||
download_progress['errors'].append(error_msg)
|
||||
download_progress['last_error'] = error_msg
|
||||
return False # Return False on exception
|
||||
|
||||
@staticmethod
|
||||
async def _remove_failed_images_from_metadata(model_hash, model_name, failed_images, scanner):
|
||||
"""Remove failed images from model metadata"""
|
||||
try:
|
||||
# Get current model data
|
||||
model_data = await MetadataUpdater.get_updated_model(model_hash, scanner)
|
||||
if not model_data:
|
||||
logger.warning(f"Could not find model data for {model_name} to remove failed images")
|
||||
return
|
||||
|
||||
if not model_data.get('civitai', {}).get('images'):
|
||||
logger.warning(f"No images in metadata for {model_name}")
|
||||
return
|
||||
|
||||
# Get current images
|
||||
current_images = model_data['civitai']['images']
|
||||
|
||||
# Filter out failed images
|
||||
updated_images = [img for img in current_images if img.get('url') not in failed_images]
|
||||
|
||||
# If images were removed, update metadata
|
||||
if len(updated_images) < len(current_images):
|
||||
removed_count = len(current_images) - len(updated_images)
|
||||
logger.info(f"Removing {removed_count} failed images from metadata for {model_name}")
|
||||
|
||||
# Update the images list
|
||||
model_data['civitai']['images'] = updated_images
|
||||
|
||||
# Save metadata to file
|
||||
file_path = model_data.get('file_path')
|
||||
if file_path:
|
||||
# Create a copy of model data without 'folder' field
|
||||
model_copy = model_data.copy()
|
||||
model_copy.pop('folder', None)
|
||||
|
||||
# Write metadata to file
|
||||
await MetadataManager.save_metadata(file_path, model_copy)
|
||||
logger.info(f"Saved updated metadata for {model_name} after removing failed images")
|
||||
|
||||
# Update the scanner cache
|
||||
await scanner.update_single_model_cache(file_path, file_path, model_data)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error removing failed images from metadata for {model_name}: {e}", exc_info=True)
|
||||
208
py/utils/example_images_file_manager.py
Normal file
208
py/utils/example_images_file_manager.py
Normal file
@@ -0,0 +1,208 @@
|
||||
import logging
|
||||
import os
|
||||
import sys
|
||||
import subprocess
|
||||
from aiohttp import web
|
||||
from ..services.settings_manager import settings
|
||||
from ..utils.constants import SUPPORTED_MEDIA_EXTENSIONS
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class ExampleImagesFileManager:
|
||||
"""Manages access and operations for example image files"""
|
||||
|
||||
@staticmethod
|
||||
async def open_folder(request):
|
||||
"""
|
||||
Open the example images folder for a specific model
|
||||
|
||||
Expects a JSON request body with:
|
||||
{
|
||||
"model_hash": "sha256_hash" # SHA256 hash of the model
|
||||
}
|
||||
"""
|
||||
try:
|
||||
# Parse request body
|
||||
data = await request.json()
|
||||
model_hash = data.get('model_hash')
|
||||
|
||||
if not model_hash:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Missing model_hash parameter'
|
||||
}, status=400)
|
||||
|
||||
# Get example images path from settings
|
||||
example_images_path = settings.get('example_images_path')
|
||||
if not example_images_path:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'No example images path configured. Please set it in the settings panel first.'
|
||||
}, status=400)
|
||||
|
||||
# Construct folder path for this model
|
||||
model_folder = os.path.join(example_images_path, model_hash)
|
||||
model_folder = os.path.abspath(model_folder) # Get absolute path
|
||||
|
||||
# Path validation: ensure model_folder is under example_images_path
|
||||
if not model_folder.startswith(os.path.abspath(example_images_path)):
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Invalid model folder path'
|
||||
}, status=400)
|
||||
|
||||
# Check if folder exists
|
||||
if not os.path.exists(model_folder):
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'No example images found for this model. Download example images first.'
|
||||
}, status=404)
|
||||
|
||||
# Open folder in file explorer
|
||||
if os.name == 'nt': # Windows
|
||||
os.startfile(model_folder)
|
||||
elif os.name == 'posix': # macOS and Linux
|
||||
if sys.platform == 'darwin': # macOS
|
||||
subprocess.Popen(['open', model_folder])
|
||||
else: # Linux
|
||||
subprocess.Popen(['xdg-open', model_folder])
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'message': f'Opened example images folder for model {model_hash}'
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to open example images folder: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
@staticmethod
|
||||
async def get_files(request):
|
||||
"""
|
||||
Get the list of example image files for a specific model
|
||||
|
||||
Expects:
|
||||
- model_hash in query parameters
|
||||
|
||||
Returns:
|
||||
- List of image files and their paths
|
||||
"""
|
||||
try:
|
||||
# Get model_hash from query parameters
|
||||
model_hash = request.query.get('model_hash')
|
||||
|
||||
if not model_hash:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Missing model_hash parameter'
|
||||
}, status=400)
|
||||
|
||||
# Get example images path from settings
|
||||
example_images_path = settings.get('example_images_path')
|
||||
if not example_images_path:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'No example images path configured'
|
||||
}, status=400)
|
||||
|
||||
# Construct folder path for this model
|
||||
model_folder = os.path.join(example_images_path, model_hash)
|
||||
|
||||
# Check if folder exists
|
||||
if not os.path.exists(model_folder):
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'No example images found for this model',
|
||||
'files': []
|
||||
}, status=404)
|
||||
|
||||
# Get list of files in the folder
|
||||
files = []
|
||||
for file in os.listdir(model_folder):
|
||||
file_path = os.path.join(model_folder, file)
|
||||
if os.path.isfile(file_path):
|
||||
# Check if file is a supported media file
|
||||
file_ext = os.path.splitext(file)[1].lower()
|
||||
if (file_ext in SUPPORTED_MEDIA_EXTENSIONS['images'] or
|
||||
file_ext in SUPPORTED_MEDIA_EXTENSIONS['videos']):
|
||||
files.append({
|
||||
'name': file,
|
||||
'path': f'/example_images_static/{model_hash}/{file}',
|
||||
'extension': file_ext,
|
||||
'is_video': file_ext in SUPPORTED_MEDIA_EXTENSIONS['videos']
|
||||
})
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'files': files
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to get example image files: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
@staticmethod
|
||||
async def has_images(request):
|
||||
"""
|
||||
Check if the example images folder for a model exists and is not empty
|
||||
|
||||
Expects:
|
||||
- model_hash in query parameters
|
||||
|
||||
Returns:
|
||||
- Boolean indicating whether the folder exists and contains images/videos
|
||||
"""
|
||||
try:
|
||||
# Get model_hash from query parameters
|
||||
model_hash = request.query.get('model_hash')
|
||||
|
||||
if not model_hash:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Missing model_hash parameter'
|
||||
}, status=400)
|
||||
|
||||
# Get example images path from settings
|
||||
example_images_path = settings.get('example_images_path')
|
||||
if not example_images_path:
|
||||
return web.json_response({
|
||||
'has_images': False
|
||||
})
|
||||
|
||||
# Construct folder path for this model
|
||||
model_folder = os.path.join(example_images_path, model_hash)
|
||||
|
||||
# Check if folder exists
|
||||
if not os.path.exists(model_folder) or not os.path.isdir(model_folder):
|
||||
return web.json_response({
|
||||
'has_images': False
|
||||
})
|
||||
|
||||
# Check if folder contains any supported media files
|
||||
for file in os.listdir(model_folder):
|
||||
file_path = os.path.join(model_folder, file)
|
||||
if os.path.isfile(file_path):
|
||||
file_ext = os.path.splitext(file)[1].lower()
|
||||
if (file_ext in SUPPORTED_MEDIA_EXTENSIONS['images'] or
|
||||
file_ext in SUPPORTED_MEDIA_EXTENSIONS['videos']):
|
||||
return web.json_response({
|
||||
'has_images': True
|
||||
})
|
||||
|
||||
# If reached here, folder exists but has no supported media files
|
||||
return web.json_response({
|
||||
'has_images': False
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to check example images folder: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'has_images': False,
|
||||
'error': str(e)
|
||||
})
|
||||
390
py/utils/example_images_metadata.py
Normal file
390
py/utils/example_images_metadata.py
Normal file
@@ -0,0 +1,390 @@
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
from ..utils.metadata_manager import MetadataManager
|
||||
from ..utils.routes_common import ModelRouteUtils
|
||||
from ..utils.constants import SUPPORTED_MEDIA_EXTENSIONS
|
||||
from ..utils.exif_utils import ExifUtils
|
||||
from ..recipes.constants import GEN_PARAM_KEYS
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class MetadataUpdater:
|
||||
"""Handles updating model metadata related to example images"""
|
||||
|
||||
@staticmethod
|
||||
async def refresh_model_metadata(model_hash, model_name, scanner_type, scanner):
|
||||
"""Refresh model metadata from CivitAI
|
||||
|
||||
Args:
|
||||
model_hash: SHA256 hash of the model
|
||||
model_name: Model name (for logging)
|
||||
scanner_type: Scanner type ('lora' or 'checkpoint')
|
||||
scanner: Scanner instance for this model type
|
||||
|
||||
Returns:
|
||||
bool: True if metadata was successfully refreshed, False otherwise
|
||||
"""
|
||||
from ..utils.example_images_download_manager import download_progress
|
||||
|
||||
try:
|
||||
# Find the model in the scanner cache
|
||||
cache = await scanner.get_cached_data()
|
||||
model_data = None
|
||||
|
||||
for item in cache.raw_data:
|
||||
if item.get('sha256') == model_hash:
|
||||
model_data = item
|
||||
break
|
||||
|
||||
if not model_data:
|
||||
logger.warning(f"Model {model_name} with hash {model_hash} not found in cache")
|
||||
return False
|
||||
|
||||
file_path = model_data.get('file_path')
|
||||
if not file_path:
|
||||
logger.warning(f"Model {model_name} has no file path")
|
||||
return False
|
||||
|
||||
# Track that we're refreshing this model
|
||||
download_progress['refreshed_models'].add(model_hash)
|
||||
|
||||
# Use ModelRouteUtils to refresh metadata
|
||||
async def update_cache_func(old_path, new_path, metadata):
|
||||
return await scanner.update_single_model_cache(old_path, new_path, metadata)
|
||||
|
||||
success = await ModelRouteUtils.fetch_and_update_model(
|
||||
model_hash,
|
||||
file_path,
|
||||
model_data,
|
||||
update_cache_func
|
||||
)
|
||||
|
||||
if success:
|
||||
logger.info(f"Successfully refreshed metadata for {model_name}")
|
||||
return True
|
||||
else:
|
||||
logger.warning(f"Failed to refresh metadata for {model_name}")
|
||||
return False
|
||||
|
||||
except Exception as e:
|
||||
error_msg = f"Error refreshing metadata for {model_name}: {str(e)}"
|
||||
logger.error(error_msg, exc_info=True)
|
||||
download_progress['errors'].append(error_msg)
|
||||
download_progress['last_error'] = error_msg
|
||||
return False
|
||||
|
||||
@staticmethod
|
||||
async def get_updated_model(model_hash, scanner):
|
||||
"""Get updated model data
|
||||
|
||||
Args:
|
||||
model_hash: SHA256 hash of the model
|
||||
scanner: Scanner instance
|
||||
|
||||
Returns:
|
||||
dict: Updated model data or None if not found
|
||||
"""
|
||||
cache = await scanner.get_cached_data()
|
||||
for item in cache.raw_data:
|
||||
if item.get('sha256') == model_hash:
|
||||
return item
|
||||
return None
|
||||
|
||||
@staticmethod
|
||||
async def update_metadata_from_local_examples(model_hash, model, scanner_type, scanner, model_dir):
|
||||
"""Update model metadata with local example image information
|
||||
|
||||
Args:
|
||||
model_hash: SHA256 hash of the model
|
||||
model: Model data dictionary
|
||||
scanner_type: Scanner type ('lora' or 'checkpoint')
|
||||
scanner: Scanner instance for this model type
|
||||
model_dir: Model images directory
|
||||
|
||||
Returns:
|
||||
bool: True if metadata was successfully updated, False otherwise
|
||||
"""
|
||||
try:
|
||||
# Collect local image paths
|
||||
local_images_paths = []
|
||||
if os.path.exists(model_dir):
|
||||
for file in os.listdir(model_dir):
|
||||
file_path = os.path.join(model_dir, file)
|
||||
if os.path.isfile(file_path):
|
||||
file_ext = os.path.splitext(file)[1].lower()
|
||||
is_supported = (file_ext in SUPPORTED_MEDIA_EXTENSIONS['images'] or
|
||||
file_ext in SUPPORTED_MEDIA_EXTENSIONS['videos'])
|
||||
if is_supported:
|
||||
local_images_paths.append(file_path)
|
||||
|
||||
# Check if metadata update is needed (no civitai field or empty images)
|
||||
needs_update = not model.get('civitai') or not model.get('civitai', {}).get('images')
|
||||
|
||||
if needs_update and local_images_paths:
|
||||
logger.debug(f"Found {len(local_images_paths)} local example images for {model.get('model_name')}, updating metadata")
|
||||
|
||||
# Create or get civitai field
|
||||
if not model.get('civitai'):
|
||||
model['civitai'] = {}
|
||||
|
||||
# Create images array
|
||||
images = []
|
||||
|
||||
# Generate metadata for each local image/video
|
||||
for path in local_images_paths:
|
||||
# Determine if video or image
|
||||
file_ext = os.path.splitext(path)[1].lower()
|
||||
is_video = file_ext in SUPPORTED_MEDIA_EXTENSIONS['videos']
|
||||
|
||||
# Create image metadata entry
|
||||
image_entry = {
|
||||
"url": "", # Empty URL as required
|
||||
"nsfwLevel": 0,
|
||||
"width": 720, # Default dimensions
|
||||
"height": 1280,
|
||||
"type": "video" if is_video else "image",
|
||||
"meta": None,
|
||||
"hasMeta": False,
|
||||
"hasPositivePrompt": False
|
||||
}
|
||||
|
||||
# If it's an image, try to get actual dimensions (optional enhancement)
|
||||
try:
|
||||
from PIL import Image
|
||||
if not is_video and os.path.exists(path):
|
||||
with Image.open(path) as img:
|
||||
image_entry["width"], image_entry["height"] = img.size
|
||||
except:
|
||||
# If PIL fails or is unavailable, use default dimensions
|
||||
pass
|
||||
|
||||
images.append(image_entry)
|
||||
|
||||
# Update the model's civitai.images field
|
||||
model['civitai']['images'] = images
|
||||
|
||||
# Save metadata to .metadata.json file
|
||||
file_path = model.get('file_path')
|
||||
try:
|
||||
# Create a copy of model data without 'folder' field
|
||||
model_copy = model.copy()
|
||||
model_copy.pop('folder', None)
|
||||
|
||||
# Write metadata to file
|
||||
await MetadataManager.save_metadata(file_path, model_copy)
|
||||
logger.info(f"Saved metadata for {model.get('model_name')}")
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to save metadata for {model.get('model_name')}: {str(e)}")
|
||||
|
||||
# Save updated metadata to scanner cache
|
||||
success = await scanner.update_single_model_cache(file_path, file_path, model)
|
||||
if success:
|
||||
logger.info(f"Successfully updated metadata for {model.get('model_name')} with {len(images)} local examples")
|
||||
return True
|
||||
else:
|
||||
logger.warning(f"Failed to update metadata for {model.get('model_name')}")
|
||||
|
||||
return False
|
||||
except Exception as e:
|
||||
logger.error(f"Error updating metadata from local examples: {str(e)}", exc_info=True)
|
||||
return False
|
||||
|
||||
@staticmethod
|
||||
async def update_metadata_after_import(model_hash, model_data, scanner, newly_imported_paths):
|
||||
"""Update model metadata after importing example images
|
||||
|
||||
Args:
|
||||
model_hash: SHA256 hash of the model
|
||||
model_data: Model data dictionary
|
||||
scanner: Scanner instance (lora or checkpoint)
|
||||
newly_imported_paths: List of paths to newly imported files
|
||||
|
||||
Returns:
|
||||
tuple: (regular_images, custom_images) - Both image arrays
|
||||
"""
|
||||
try:
|
||||
# Ensure civitai field exists in model_data
|
||||
if not model_data.get('civitai'):
|
||||
model_data['civitai'] = {}
|
||||
|
||||
# Ensure customImages array exists
|
||||
if not model_data['civitai'].get('customImages'):
|
||||
model_data['civitai']['customImages'] = []
|
||||
|
||||
# Get current customImages array
|
||||
custom_images = model_data['civitai']['customImages']
|
||||
|
||||
# Add new image entry for each imported file
|
||||
for path_tuple in newly_imported_paths:
|
||||
path, short_id = path_tuple
|
||||
|
||||
# Determine if video or image
|
||||
file_ext = os.path.splitext(path)[1].lower()
|
||||
is_video = file_ext in SUPPORTED_MEDIA_EXTENSIONS['videos']
|
||||
|
||||
# Create image metadata entry
|
||||
image_entry = {
|
||||
"url": "", # Empty URL as requested
|
||||
"id": short_id,
|
||||
"nsfwLevel": 0,
|
||||
"width": 720, # Default dimensions
|
||||
"height": 1280,
|
||||
"type": "video" if is_video else "image",
|
||||
"meta": None,
|
||||
"hasMeta": False,
|
||||
"hasPositivePrompt": False
|
||||
}
|
||||
|
||||
# Extract and parse metadata if this is an image
|
||||
if not is_video:
|
||||
try:
|
||||
# Extract metadata from image
|
||||
extracted_metadata = ExifUtils.extract_image_metadata(path)
|
||||
|
||||
if extracted_metadata:
|
||||
# Parse the extracted metadata to get generation parameters
|
||||
parsed_meta = MetadataUpdater._parse_image_metadata(extracted_metadata)
|
||||
|
||||
if parsed_meta:
|
||||
image_entry["meta"] = parsed_meta
|
||||
image_entry["hasMeta"] = True
|
||||
image_entry["hasPositivePrompt"] = bool(parsed_meta.get("prompt", ""))
|
||||
logger.debug(f"Extracted metadata from {os.path.basename(path)}")
|
||||
except Exception as e:
|
||||
logger.warning(f"Failed to extract metadata from {os.path.basename(path)}: {e}")
|
||||
|
||||
# If it's an image, try to get actual dimensions
|
||||
try:
|
||||
from PIL import Image
|
||||
if not is_video and os.path.exists(path):
|
||||
with Image.open(path) as img:
|
||||
image_entry["width"], image_entry["height"] = img.size
|
||||
except:
|
||||
# If PIL fails or is unavailable, use default dimensions
|
||||
pass
|
||||
|
||||
# Append to existing customImages array
|
||||
custom_images.append(image_entry)
|
||||
|
||||
# Save metadata to .metadata.json file
|
||||
file_path = model_data.get('file_path')
|
||||
if file_path:
|
||||
try:
|
||||
# Create a copy of model data without 'folder' field
|
||||
model_copy = model_data.copy()
|
||||
model_copy.pop('folder', None)
|
||||
|
||||
# Write metadata to file
|
||||
await MetadataManager.save_metadata(file_path, model_copy)
|
||||
logger.info(f"Saved metadata for {model_data.get('model_name')}")
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to save metadata: {str(e)}")
|
||||
|
||||
# Save updated metadata to scanner cache
|
||||
if file_path:
|
||||
await scanner.update_single_model_cache(file_path, file_path, model_data)
|
||||
|
||||
# Get regular images array (might be None)
|
||||
regular_images = model_data['civitai'].get('images', [])
|
||||
|
||||
# Return both image arrays
|
||||
return regular_images, custom_images
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to update metadata after import: {e}", exc_info=True)
|
||||
return [], []
|
||||
|
||||
@staticmethod
|
||||
def _parse_image_metadata(user_comment):
|
||||
"""Parse metadata from image to extract generation parameters
|
||||
|
||||
Args:
|
||||
user_comment: Metadata string extracted from image
|
||||
|
||||
Returns:
|
||||
dict: Parsed metadata with generation parameters
|
||||
"""
|
||||
if not user_comment:
|
||||
return None
|
||||
|
||||
try:
|
||||
# Initialize metadata dictionary
|
||||
metadata = {}
|
||||
|
||||
# Split on Negative prompt if it exists
|
||||
if "Negative prompt:" in user_comment:
|
||||
parts = user_comment.split('Negative prompt:', 1)
|
||||
prompt = parts[0].strip()
|
||||
negative_and_params = parts[1] if len(parts) > 1 else ""
|
||||
else:
|
||||
# No negative prompt section
|
||||
param_start = re.search(r'Steps: \d+', user_comment)
|
||||
if param_start:
|
||||
prompt = user_comment[:param_start.start()].strip()
|
||||
negative_and_params = user_comment[param_start.start():]
|
||||
else:
|
||||
prompt = user_comment.strip()
|
||||
negative_and_params = ""
|
||||
|
||||
# Add prompt if it's in GEN_PARAM_KEYS
|
||||
if 'prompt' in GEN_PARAM_KEYS:
|
||||
metadata['prompt'] = prompt
|
||||
|
||||
# Extract negative prompt and parameters
|
||||
if negative_and_params:
|
||||
# If we split on "Negative prompt:", check for params section
|
||||
if "Negative prompt:" in user_comment:
|
||||
param_start = re.search(r'Steps: ', negative_and_params)
|
||||
if param_start:
|
||||
neg_prompt = negative_and_params[:param_start.start()].strip()
|
||||
if 'negative_prompt' in GEN_PARAM_KEYS:
|
||||
metadata['negative_prompt'] = neg_prompt
|
||||
params_section = negative_and_params[param_start.start():]
|
||||
else:
|
||||
if 'negative_prompt' in GEN_PARAM_KEYS:
|
||||
metadata['negative_prompt'] = negative_and_params.strip()
|
||||
params_section = ""
|
||||
else:
|
||||
# No negative prompt, entire section is params
|
||||
params_section = negative_and_params
|
||||
|
||||
# Extract generation parameters
|
||||
if params_section:
|
||||
# Extract basic parameters
|
||||
param_pattern = r'([A-Za-z\s]+): ([^,]+)'
|
||||
params = re.findall(param_pattern, params_section)
|
||||
|
||||
for key, value in params:
|
||||
clean_key = key.strip().lower().replace(' ', '_')
|
||||
|
||||
# Skip if not in recognized gen param keys
|
||||
if clean_key not in GEN_PARAM_KEYS:
|
||||
continue
|
||||
|
||||
# Convert numeric values
|
||||
if clean_key in ['steps', 'seed']:
|
||||
try:
|
||||
metadata[clean_key] = int(value.strip())
|
||||
except ValueError:
|
||||
metadata[clean_key] = value.strip()
|
||||
elif clean_key in ['cfg_scale']:
|
||||
try:
|
||||
metadata[clean_key] = float(value.strip())
|
||||
except ValueError:
|
||||
metadata[clean_key] = value.strip()
|
||||
else:
|
||||
metadata[clean_key] = value.strip()
|
||||
|
||||
# Extract size if available and add if a recognized key
|
||||
size_match = re.search(r'Size: (\d+)x(\d+)', params_section)
|
||||
if size_match and 'size' in GEN_PARAM_KEYS:
|
||||
width, height = size_match.groups()
|
||||
metadata['size'] = f"{width}x{height}"
|
||||
|
||||
# Return metadata if we have any entries
|
||||
return metadata if metadata else None
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error parsing image metadata: {e}", exc_info=True)
|
||||
return None
|
||||
318
py/utils/example_images_migration.py
Normal file
318
py/utils/example_images_migration.py
Normal file
@@ -0,0 +1,318 @@
|
||||
import asyncio
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
import json
|
||||
from ..services.settings_manager import settings
|
||||
from ..services.service_registry import ServiceRegistry
|
||||
from ..utils.metadata_manager import MetadataManager
|
||||
from ..utils.example_images_processor import ExampleImagesProcessor
|
||||
from ..utils.constants import SUPPORTED_MEDIA_EXTENSIONS
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
CURRENT_NAMING_VERSION = 2 # Increment this when naming conventions change
|
||||
|
||||
class ExampleImagesMigration:
|
||||
"""Handles migrations for example images naming conventions"""
|
||||
|
||||
@staticmethod
|
||||
async def check_and_run_migrations():
|
||||
"""Check if migrations are needed and run them in background"""
|
||||
example_images_path = settings.get('example_images_path')
|
||||
if not example_images_path or not os.path.exists(example_images_path):
|
||||
logger.debug("No example images path configured or path doesn't exist, skipping migrations")
|
||||
return
|
||||
|
||||
# Check current version from progress file
|
||||
current_version = 0
|
||||
progress_file = os.path.join(example_images_path, '.download_progress.json')
|
||||
if os.path.exists(progress_file):
|
||||
try:
|
||||
with open(progress_file, 'r', encoding='utf-8') as f:
|
||||
progress_data = json.load(f)
|
||||
current_version = progress_data.get('naming_version', 0)
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to load progress file for migration check: {e}")
|
||||
|
||||
# If current version is less than target version, start migration
|
||||
if current_version < CURRENT_NAMING_VERSION:
|
||||
logger.info(f"Starting example images naming migration from v{current_version} to v{CURRENT_NAMING_VERSION}")
|
||||
# Start migration in background task
|
||||
asyncio.create_task(
|
||||
ExampleImagesMigration.run_migrations(example_images_path, current_version, CURRENT_NAMING_VERSION)
|
||||
)
|
||||
|
||||
@staticmethod
|
||||
async def run_migrations(example_images_path, from_version, to_version):
|
||||
"""Run necessary migrations based on version difference"""
|
||||
try:
|
||||
# Get all model folders
|
||||
model_folders = []
|
||||
for item in os.listdir(example_images_path):
|
||||
item_path = os.path.join(example_images_path, item)
|
||||
if os.path.isdir(item_path) and len(item) == 64: # SHA256 hash is 64 chars
|
||||
model_folders.append(item_path)
|
||||
|
||||
logger.info(f"Found {len(model_folders)} model folders to check for migration")
|
||||
|
||||
# Apply migrations sequentially
|
||||
if from_version < 1 and to_version >= 1:
|
||||
await ExampleImagesMigration._migrate_to_v1(model_folders)
|
||||
|
||||
if from_version < 2 and to_version >= 2:
|
||||
await ExampleImagesMigration._migrate_to_v2(model_folders)
|
||||
|
||||
# Update version in progress file
|
||||
progress_file = os.path.join(example_images_path, '.download_progress.json')
|
||||
try:
|
||||
progress_data = {}
|
||||
if os.path.exists(progress_file):
|
||||
with open(progress_file, 'r', encoding='utf-8') as f:
|
||||
progress_data = json.load(f)
|
||||
|
||||
progress_data['naming_version'] = to_version
|
||||
|
||||
with open(progress_file, 'w', encoding='utf-8') as f:
|
||||
json.dump(progress_data, f, indent=2)
|
||||
|
||||
logger.info(f"Example images naming migration to v{to_version} completed")
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to update version in progress file: {e}")
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error during migration: {e}", exc_info=True)
|
||||
|
||||
@staticmethod
|
||||
async def _migrate_to_v1(model_folders):
|
||||
"""Migrate from 1-based to 0-based indexing"""
|
||||
count = 0
|
||||
for folder in model_folders:
|
||||
has_one_based = False
|
||||
has_zero_based = False
|
||||
files_to_rename = []
|
||||
|
||||
# Check naming pattern in this folder
|
||||
for file in os.listdir(folder):
|
||||
if re.match(r'image_1\.\w+$', file):
|
||||
has_one_based = True
|
||||
if re.match(r'image_0\.\w+$', file):
|
||||
has_zero_based = True
|
||||
|
||||
# Only migrate folders with 1-based indexing and no 0-based
|
||||
if has_one_based and not has_zero_based:
|
||||
# Create rename mapping
|
||||
for file in os.listdir(folder):
|
||||
match = re.match(r'image_(\d+)\.(\w+)$', file)
|
||||
if match:
|
||||
index = int(match.group(1))
|
||||
ext = match.group(2)
|
||||
if index > 0: # Only rename if index is positive
|
||||
files_to_rename.append((
|
||||
file,
|
||||
f"image_{index-1}.{ext}"
|
||||
))
|
||||
|
||||
# Use temporary names to avoid conflicts
|
||||
for old_name, new_name in files_to_rename:
|
||||
old_path = os.path.join(folder, old_name)
|
||||
temp_path = os.path.join(folder, f"temp_{old_name}")
|
||||
try:
|
||||
os.rename(old_path, temp_path)
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to rename {old_path} to {temp_path}: {e}")
|
||||
|
||||
# Rename from temporary names to final names
|
||||
for old_name, new_name in files_to_rename:
|
||||
temp_path = os.path.join(folder, f"temp_{old_name}")
|
||||
new_path = os.path.join(folder, new_name)
|
||||
try:
|
||||
os.rename(temp_path, new_path)
|
||||
logger.debug(f"Renamed {old_name} to {new_name} in {folder}")
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to rename {temp_path} to {new_path}: {e}")
|
||||
|
||||
count += 1
|
||||
|
||||
# Give other tasks a chance to run
|
||||
if count % 10 == 0:
|
||||
await asyncio.sleep(0)
|
||||
|
||||
logger.info(f"Migrated {count} folders from 1-based to 0-based indexing")
|
||||
|
||||
@staticmethod
|
||||
async def _migrate_to_v2(model_folders):
|
||||
"""
|
||||
Migrate to v2 naming scheme:
|
||||
- Move custom examples from images array to customImages array
|
||||
- Rename files from image_<index>.<ext> to custom_<short_id>.<ext>
|
||||
- Add id field to each custom image entry
|
||||
"""
|
||||
count = 0
|
||||
updated_models = 0
|
||||
migration_errors = 0
|
||||
|
||||
# Get scanner instances
|
||||
lora_scanner = await ServiceRegistry.get_lora_scanner()
|
||||
checkpoint_scanner = await ServiceRegistry.get_checkpoint_scanner()
|
||||
|
||||
# Wait until scanners are initialized
|
||||
scanners = [lora_scanner, checkpoint_scanner]
|
||||
for scanner in scanners:
|
||||
if scanner.is_initializing():
|
||||
logger.info("Waiting for scanners to complete initialization before starting migration...")
|
||||
initialized = False
|
||||
retry_count = 0
|
||||
while not initialized and retry_count < 120: # Wait up to 120 seconds
|
||||
await asyncio.sleep(1)
|
||||
initialized = not scanner.is_initializing()
|
||||
retry_count += 1
|
||||
|
||||
if not initialized:
|
||||
logger.warning("Scanner initialization timeout - proceeding with migration anyway")
|
||||
|
||||
logger.info(f"Starting migration to v2 naming scheme for {len(model_folders)} model folders")
|
||||
|
||||
for folder in model_folders:
|
||||
try:
|
||||
# Extract model hash from folder name
|
||||
model_hash = os.path.basename(folder)
|
||||
if not model_hash or len(model_hash) != 64:
|
||||
continue
|
||||
|
||||
# Find the model in scanner cache
|
||||
model_data = None
|
||||
scanner = None
|
||||
|
||||
for scan_obj in scanners:
|
||||
if scan_obj.has_hash(model_hash):
|
||||
cache = await scan_obj.get_cached_data()
|
||||
for item in cache.raw_data:
|
||||
if item.get('sha256') == model_hash:
|
||||
model_data = item
|
||||
scanner = scan_obj
|
||||
break
|
||||
if model_data:
|
||||
break
|
||||
|
||||
if not model_data or not scanner:
|
||||
logger.debug(f"Model with hash {model_hash} not found in cache, skipping migration")
|
||||
continue
|
||||
|
||||
# Clone model data to avoid modifying the cache directly
|
||||
model_metadata = model_data.copy()
|
||||
|
||||
# Check if model has civitai metadata
|
||||
if not model_metadata.get('civitai'):
|
||||
continue
|
||||
|
||||
# Get images array
|
||||
images = model_metadata.get('civitai', {}).get('images', [])
|
||||
if not images:
|
||||
continue
|
||||
|
||||
# Initialize customImages array if it doesn't exist
|
||||
if not model_metadata['civitai'].get('customImages'):
|
||||
model_metadata['civitai']['customImages'] = []
|
||||
|
||||
# Find custom examples (entries with empty url)
|
||||
custom_indices = []
|
||||
for i, image in enumerate(images):
|
||||
if image.get('url') == "":
|
||||
custom_indices.append(i)
|
||||
|
||||
if not custom_indices:
|
||||
continue
|
||||
|
||||
logger.debug(f"Found {len(custom_indices)} custom examples in {model_hash}")
|
||||
|
||||
# Process each custom example
|
||||
for index in custom_indices:
|
||||
try:
|
||||
image_entry = images[index]
|
||||
|
||||
# Determine media type based on the entry type
|
||||
media_type = 'videos' if image_entry.get('type') == 'video' else 'images'
|
||||
extensions_to_try = SUPPORTED_MEDIA_EXTENSIONS[media_type]
|
||||
|
||||
# Find the image file by trying possible extensions
|
||||
old_path = None
|
||||
old_filename = None
|
||||
found = False
|
||||
|
||||
for ext in extensions_to_try:
|
||||
test_path = os.path.join(folder, f"image_{index}{ext}")
|
||||
if os.path.exists(test_path):
|
||||
old_path = test_path
|
||||
old_filename = f"image_{index}{ext}"
|
||||
found = True
|
||||
break
|
||||
|
||||
if not found:
|
||||
logger.warning(f"Could not find file for index {index} in {model_hash}, skipping")
|
||||
continue
|
||||
|
||||
# Generate short ID for the custom example
|
||||
short_id = ExampleImagesProcessor.generate_short_id()
|
||||
|
||||
# Get file extension
|
||||
file_ext = os.path.splitext(old_path)[1]
|
||||
|
||||
# Create new filename
|
||||
new_filename = f"custom_{short_id}{file_ext}"
|
||||
new_path = os.path.join(folder, new_filename)
|
||||
|
||||
# Rename the file
|
||||
try:
|
||||
os.rename(old_path, new_path)
|
||||
logger.debug(f"Renamed {old_filename} to {new_filename} in {folder}")
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to rename {old_path} to {new_path}: {e}")
|
||||
continue
|
||||
|
||||
# Create a copy of the image entry with the id field
|
||||
custom_entry = image_entry.copy()
|
||||
custom_entry['id'] = short_id
|
||||
|
||||
# Add to customImages array
|
||||
model_metadata['civitai']['customImages'].append(custom_entry)
|
||||
|
||||
count += 1
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error migrating custom example at index {index} for {model_hash}: {e}")
|
||||
|
||||
# Remove custom examples from the original images array
|
||||
model_metadata['civitai']['images'] = [
|
||||
img for i, img in enumerate(images) if i not in custom_indices
|
||||
]
|
||||
|
||||
# Save the updated metadata
|
||||
file_path = model_data.get('file_path')
|
||||
if file_path:
|
||||
try:
|
||||
# Create a copy of model data without 'folder' field
|
||||
model_copy = model_metadata.copy()
|
||||
model_copy.pop('folder', None)
|
||||
|
||||
# Save metadata to file
|
||||
await MetadataManager.save_metadata(file_path, model_copy)
|
||||
|
||||
# Update scanner cache
|
||||
await scanner.update_single_model_cache(file_path, file_path, model_metadata)
|
||||
|
||||
updated_models += 1
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to save metadata for {model_hash}: {e}")
|
||||
migration_errors += 1
|
||||
|
||||
# Give other tasks a chance to run
|
||||
if count % 10 == 0:
|
||||
await asyncio.sleep(0)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error migrating folder {folder}: {e}")
|
||||
migration_errors += 1
|
||||
|
||||
logger.info(f"Migration to v2 complete: migrated {count} custom examples across {updated_models} models with {migration_errors} errors")
|
||||
626
py/utils/example_images_processor.py
Normal file
626
py/utils/example_images_processor.py
Normal file
@@ -0,0 +1,626 @@
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
import tempfile
|
||||
import random
|
||||
import string
|
||||
from aiohttp import web
|
||||
from ..utils.constants import SUPPORTED_MEDIA_EXTENSIONS
|
||||
from ..services.service_registry import ServiceRegistry
|
||||
from ..services.settings_manager import settings
|
||||
from .example_images_metadata import MetadataUpdater
|
||||
from ..utils.metadata_manager import MetadataManager
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class ExampleImagesProcessor:
|
||||
"""Processes and manipulates example images"""
|
||||
|
||||
@staticmethod
|
||||
def generate_short_id(length=8):
|
||||
"""Generate a short random alphanumeric identifier"""
|
||||
chars = string.ascii_lowercase + string.digits
|
||||
return ''.join(random.choice(chars) for _ in range(length))
|
||||
|
||||
@staticmethod
|
||||
def get_civitai_optimized_url(media_url):
|
||||
"""Convert Civitai media URL (image or video) to its optimized version"""
|
||||
base_pattern = r'(https://image\.civitai\.com/[^/]+/[^/]+)'
|
||||
match = re.match(base_pattern, media_url)
|
||||
|
||||
if match:
|
||||
base_url = match.group(1)
|
||||
return f"{base_url}/optimized=true"
|
||||
|
||||
return media_url
|
||||
|
||||
@staticmethod
|
||||
def _get_file_extension_from_content_or_headers(content, headers, fallback_url=None):
|
||||
"""Determine file extension from content magic bytes or headers"""
|
||||
# Check magic bytes for common formats
|
||||
if content:
|
||||
if content.startswith(b'\xFF\xD8\xFF'):
|
||||
return '.jpg'
|
||||
elif content.startswith(b'\x89PNG\r\n\x1A\n'):
|
||||
return '.png'
|
||||
elif content.startswith(b'GIF87a') or content.startswith(b'GIF89a'):
|
||||
return '.gif'
|
||||
elif content.startswith(b'RIFF') and b'WEBP' in content[:12]:
|
||||
return '.webp'
|
||||
elif content.startswith(b'\x00\x00\x00\x18ftypmp4') or content.startswith(b'\x00\x00\x00\x20ftypmp4'):
|
||||
return '.mp4'
|
||||
elif content.startswith(b'\x1A\x45\xDF\xA3'):
|
||||
return '.webm'
|
||||
|
||||
# Check Content-Type header
|
||||
if headers:
|
||||
content_type = headers.get('content-type', '').lower()
|
||||
type_map = {
|
||||
'image/jpeg': '.jpg',
|
||||
'image/png': '.png',
|
||||
'image/gif': '.gif',
|
||||
'image/webp': '.webp',
|
||||
'video/mp4': '.mp4',
|
||||
'video/webm': '.webm',
|
||||
'video/quicktime': '.mov'
|
||||
}
|
||||
if content_type in type_map:
|
||||
return type_map[content_type]
|
||||
|
||||
# Fallback to URL extension if available
|
||||
if fallback_url:
|
||||
filename = os.path.basename(fallback_url.split('?')[0])
|
||||
ext = os.path.splitext(filename)[1].lower()
|
||||
if ext in SUPPORTED_MEDIA_EXTENSIONS['images'] or ext in SUPPORTED_MEDIA_EXTENSIONS['videos']:
|
||||
return ext
|
||||
|
||||
# Default fallback
|
||||
return '.jpg'
|
||||
|
||||
@staticmethod
|
||||
async def download_model_images(model_hash, model_name, model_images, model_dir, optimize, downloader):
|
||||
"""Download images for a single model
|
||||
|
||||
Returns:
|
||||
tuple: (success, is_stale_metadata) - whether download was successful, whether metadata is stale
|
||||
"""
|
||||
model_success = True
|
||||
|
||||
for i, image in enumerate(model_images):
|
||||
image_url = image.get('url')
|
||||
if not image_url:
|
||||
continue
|
||||
|
||||
# Apply optimization for Civitai URLs if enabled
|
||||
original_url = image_url
|
||||
if optimize and 'civitai.com' in image_url:
|
||||
image_url = ExampleImagesProcessor.get_civitai_optimized_url(image_url)
|
||||
|
||||
# Download the file first to determine the actual file type
|
||||
try:
|
||||
logger.debug(f"Downloading media file {i} for {model_name}")
|
||||
|
||||
# Download using the unified downloader with headers
|
||||
success, content, headers = await downloader.download_to_memory(
|
||||
image_url,
|
||||
use_auth=False, # Example images don't need auth
|
||||
return_headers=True
|
||||
)
|
||||
|
||||
if success:
|
||||
# Determine file extension from content or headers
|
||||
media_ext = ExampleImagesProcessor._get_file_extension_from_content_or_headers(
|
||||
content, headers, original_url
|
||||
)
|
||||
|
||||
# Check if the detected file type is supported
|
||||
is_image = media_ext in SUPPORTED_MEDIA_EXTENSIONS['images']
|
||||
is_video = media_ext in SUPPORTED_MEDIA_EXTENSIONS['videos']
|
||||
|
||||
if not (is_image or is_video):
|
||||
logger.debug(f"Skipping unsupported file type: {media_ext}")
|
||||
continue
|
||||
|
||||
# Use 0-based indexing with the detected extension
|
||||
save_filename = f"image_{i}{media_ext}"
|
||||
save_path = os.path.join(model_dir, save_filename)
|
||||
|
||||
# Check if already downloaded
|
||||
if os.path.exists(save_path):
|
||||
logger.debug(f"File already exists: {save_path}")
|
||||
continue
|
||||
|
||||
# Save the file
|
||||
with open(save_path, 'wb') as f:
|
||||
f.write(content)
|
||||
|
||||
elif "404" in str(content):
|
||||
error_msg = f"Failed to download file: {image_url}, status code: 404 - Model metadata might be stale"
|
||||
logger.warning(error_msg)
|
||||
model_success = False # Mark the model as failed due to 404 error
|
||||
# Return early to trigger metadata refresh attempt
|
||||
return False, True # (success, is_metadata_stale)
|
||||
else:
|
||||
error_msg = f"Failed to download file: {image_url}, error: {content}"
|
||||
logger.warning(error_msg)
|
||||
model_success = False # Mark the model as failed
|
||||
except Exception as e:
|
||||
error_msg = f"Error downloading file {image_url}: {str(e)}"
|
||||
logger.error(error_msg)
|
||||
model_success = False # Mark the model as failed
|
||||
|
||||
return model_success, False # (success, is_metadata_stale)
|
||||
|
||||
@staticmethod
|
||||
async def download_model_images_with_tracking(model_hash, model_name, model_images, model_dir, optimize, downloader):
|
||||
"""Download images for a single model with tracking of failed image URLs
|
||||
|
||||
Returns:
|
||||
tuple: (success, is_stale_metadata, failed_images) - whether download was successful, whether metadata is stale, list of failed image URLs
|
||||
"""
|
||||
model_success = True
|
||||
failed_images = []
|
||||
|
||||
for i, image in enumerate(model_images):
|
||||
image_url = image.get('url')
|
||||
if not image_url:
|
||||
continue
|
||||
|
||||
# Apply optimization for Civitai URLs if enabled
|
||||
original_url = image_url
|
||||
if optimize and 'civitai.com' in image_url:
|
||||
image_url = ExampleImagesProcessor.get_civitai_optimized_url(image_url)
|
||||
|
||||
# Download the file first to determine the actual file type
|
||||
try:
|
||||
logger.debug(f"Downloading media file {i} for {model_name}")
|
||||
|
||||
# Download using the unified downloader with headers
|
||||
success, content, headers = await downloader.download_to_memory(
|
||||
image_url,
|
||||
use_auth=False, # Example images don't need auth
|
||||
return_headers=True
|
||||
)
|
||||
|
||||
if success:
|
||||
# Determine file extension from content or headers
|
||||
media_ext = ExampleImagesProcessor._get_file_extension_from_content_or_headers(
|
||||
content, headers, original_url
|
||||
)
|
||||
|
||||
# Check if the detected file type is supported
|
||||
is_image = media_ext in SUPPORTED_MEDIA_EXTENSIONS['images']
|
||||
is_video = media_ext in SUPPORTED_MEDIA_EXTENSIONS['videos']
|
||||
|
||||
if not (is_image or is_video):
|
||||
logger.debug(f"Skipping unsupported file type: {media_ext}")
|
||||
continue
|
||||
|
||||
# Use 0-based indexing with the detected extension
|
||||
save_filename = f"image_{i}{media_ext}"
|
||||
save_path = os.path.join(model_dir, save_filename)
|
||||
|
||||
# Check if already downloaded
|
||||
if os.path.exists(save_path):
|
||||
logger.debug(f"File already exists: {save_path}")
|
||||
continue
|
||||
|
||||
# Save the file
|
||||
with open(save_path, 'wb') as f:
|
||||
f.write(content)
|
||||
|
||||
elif "404" in str(content):
|
||||
error_msg = f"Failed to download file: {image_url}, status code: 404 - Model metadata might be stale"
|
||||
logger.warning(error_msg)
|
||||
model_success = False # Mark the model as failed due to 404 error
|
||||
failed_images.append(image_url) # Track failed URL
|
||||
# Return early to trigger metadata refresh attempt
|
||||
return False, True, failed_images # (success, is_metadata_stale, failed_images)
|
||||
else:
|
||||
error_msg = f"Failed to download file: {image_url}, error: {content}"
|
||||
logger.warning(error_msg)
|
||||
model_success = False # Mark the model as failed
|
||||
failed_images.append(image_url) # Track failed URL
|
||||
except Exception as e:
|
||||
error_msg = f"Error downloading file {image_url}: {str(e)}"
|
||||
logger.error(error_msg)
|
||||
model_success = False # Mark the model as failed
|
||||
failed_images.append(image_url) # Track failed URL
|
||||
|
||||
return model_success, False, failed_images # (success, is_metadata_stale, failed_images)
|
||||
|
||||
@staticmethod
|
||||
async def process_local_examples(model_file_path, model_file_name, model_name, model_dir, optimize):
|
||||
"""Process local example images
|
||||
|
||||
Returns:
|
||||
bool: True if local images were processed successfully, False otherwise
|
||||
"""
|
||||
try:
|
||||
if not model_file_path or not os.path.exists(os.path.dirname(model_file_path)):
|
||||
return False
|
||||
|
||||
model_dir_path = os.path.dirname(model_file_path)
|
||||
local_images = []
|
||||
|
||||
# Look for files with pattern: filename.example.*.ext
|
||||
if model_file_name:
|
||||
example_prefix = f"{model_file_name}.example."
|
||||
|
||||
if os.path.exists(model_dir_path):
|
||||
for file in os.listdir(model_dir_path):
|
||||
file_lower = file.lower()
|
||||
if file_lower.startswith(example_prefix.lower()):
|
||||
file_ext = os.path.splitext(file_lower)[1]
|
||||
is_supported = (file_ext in SUPPORTED_MEDIA_EXTENSIONS['images'] or
|
||||
file_ext in SUPPORTED_MEDIA_EXTENSIONS['videos'])
|
||||
|
||||
if is_supported:
|
||||
local_images.append(os.path.join(model_dir_path, file))
|
||||
|
||||
# Process local images if found
|
||||
if local_images:
|
||||
logger.info(f"Found {len(local_images)} local example images for {model_name}")
|
||||
|
||||
for local_image_path in local_images:
|
||||
# Extract index from filename
|
||||
file_name = os.path.basename(local_image_path)
|
||||
example_prefix = f"{model_file_name}.example."
|
||||
|
||||
try:
|
||||
# Extract the part between '.example.' and the file extension
|
||||
index_part = file_name[len(example_prefix):].split('.')[0]
|
||||
# Try to parse it as an integer
|
||||
index = int(index_part)
|
||||
local_ext = os.path.splitext(local_image_path)[1].lower()
|
||||
save_filename = f"image_{index}{local_ext}"
|
||||
except (ValueError, IndexError):
|
||||
# If we can't parse the index, fall back to sequential numbering
|
||||
logger.warning(f"Could not extract index from {file_name}, using sequential numbering")
|
||||
local_ext = os.path.splitext(local_image_path)[1].lower()
|
||||
save_filename = f"image_{len(local_images)}{local_ext}"
|
||||
|
||||
save_path = os.path.join(model_dir, save_filename)
|
||||
|
||||
# Skip if already exists in output directory
|
||||
if os.path.exists(save_path):
|
||||
logger.debug(f"File already exists in output: {save_path}")
|
||||
continue
|
||||
|
||||
# Copy the file
|
||||
with open(local_image_path, 'rb') as src_file:
|
||||
with open(save_path, 'wb') as dst_file:
|
||||
dst_file.write(src_file.read())
|
||||
|
||||
return True
|
||||
return False
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing local examples for {model_name}: {str(e)}")
|
||||
return False
|
||||
|
||||
@staticmethod
|
||||
async def import_images(request):
|
||||
"""
|
||||
Import local example images
|
||||
|
||||
Accepts:
|
||||
- multipart/form-data form with model_hash and files fields
|
||||
or
|
||||
- JSON request with model_hash and file_paths
|
||||
|
||||
Returns:
|
||||
- Success status and list of imported files
|
||||
"""
|
||||
try:
|
||||
model_hash = None
|
||||
files_to_import = []
|
||||
temp_files_to_cleanup = []
|
||||
|
||||
# Check if it's a multipart form-data request (direct file upload)
|
||||
if request.content_type and 'multipart/form-data' in request.content_type:
|
||||
reader = await request.multipart()
|
||||
|
||||
# First get model_hash
|
||||
field = await reader.next()
|
||||
if field.name == 'model_hash':
|
||||
model_hash = await field.text()
|
||||
|
||||
# Then process all files
|
||||
while True:
|
||||
field = await reader.next()
|
||||
if field is None:
|
||||
break
|
||||
|
||||
if field.name == 'files':
|
||||
# Create a temporary file with appropriate suffix for type detection
|
||||
file_name = field.filename
|
||||
file_ext = os.path.splitext(file_name)[1].lower()
|
||||
|
||||
with tempfile.NamedTemporaryFile(suffix=file_ext, delete=False) as tmp_file:
|
||||
temp_path = tmp_file.name
|
||||
temp_files_to_cleanup.append(temp_path) # Track for cleanup
|
||||
|
||||
# Write chunks to the temporary file
|
||||
while True:
|
||||
chunk = await field.read_chunk()
|
||||
if not chunk:
|
||||
break
|
||||
tmp_file.write(chunk)
|
||||
|
||||
# Add to the list of files to process
|
||||
files_to_import.append(temp_path)
|
||||
else:
|
||||
# Parse JSON request (legacy method using file paths)
|
||||
data = await request.json()
|
||||
model_hash = data.get('model_hash')
|
||||
files_to_import = data.get('file_paths', [])
|
||||
|
||||
if not model_hash:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Missing model_hash parameter'
|
||||
}, status=400)
|
||||
|
||||
if not files_to_import:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'No files provided to import'
|
||||
}, status=400)
|
||||
|
||||
# Get example images path
|
||||
example_images_path = settings.get('example_images_path')
|
||||
if not example_images_path:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'No example images path configured'
|
||||
}, status=400)
|
||||
|
||||
# Find the model and get current metadata
|
||||
lora_scanner = await ServiceRegistry.get_lora_scanner()
|
||||
checkpoint_scanner = await ServiceRegistry.get_checkpoint_scanner()
|
||||
embedding_scanner = await ServiceRegistry.get_embedding_scanner()
|
||||
|
||||
model_data = None
|
||||
scanner = None
|
||||
|
||||
# Check both scanners to find the model
|
||||
for scan_obj in [lora_scanner, checkpoint_scanner, embedding_scanner]:
|
||||
cache = await scan_obj.get_cached_data()
|
||||
for item in cache.raw_data:
|
||||
if item.get('sha256') == model_hash:
|
||||
model_data = item
|
||||
scanner = scan_obj
|
||||
break
|
||||
if model_data:
|
||||
break
|
||||
|
||||
if not model_data:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': f"Model with hash {model_hash} not found in cache"
|
||||
}, status=404)
|
||||
|
||||
# Create model folder
|
||||
model_folder = os.path.join(example_images_path, model_hash)
|
||||
os.makedirs(model_folder, exist_ok=True)
|
||||
|
||||
imported_files = []
|
||||
errors = []
|
||||
newly_imported_paths = []
|
||||
|
||||
# Process each file path
|
||||
for file_path in files_to_import:
|
||||
try:
|
||||
# Ensure the file exists
|
||||
if not os.path.isfile(file_path):
|
||||
errors.append(f"File not found: {file_path}")
|
||||
continue
|
||||
|
||||
# Check if file type is supported
|
||||
file_ext = os.path.splitext(file_path)[1].lower()
|
||||
if not (file_ext in SUPPORTED_MEDIA_EXTENSIONS['images'] or
|
||||
file_ext in SUPPORTED_MEDIA_EXTENSIONS['videos']):
|
||||
errors.append(f"Unsupported file type: {file_path}")
|
||||
continue
|
||||
|
||||
# Generate new filename using short ID instead of UUID
|
||||
short_id = ExampleImagesProcessor.generate_short_id()
|
||||
new_filename = f"custom_{short_id}{file_ext}"
|
||||
|
||||
dest_path = os.path.join(model_folder, new_filename)
|
||||
|
||||
# Copy the file
|
||||
import shutil
|
||||
shutil.copy2(file_path, dest_path)
|
||||
# Store both the dest_path and the short_id
|
||||
newly_imported_paths.append((dest_path, short_id))
|
||||
|
||||
# Add to imported files list
|
||||
imported_files.append({
|
||||
'name': new_filename,
|
||||
'path': f'/example_images_static/{model_hash}/{new_filename}',
|
||||
'extension': file_ext,
|
||||
'is_video': file_ext in SUPPORTED_MEDIA_EXTENSIONS['videos']
|
||||
})
|
||||
except Exception as e:
|
||||
errors.append(f"Error importing {file_path}: {str(e)}")
|
||||
|
||||
# Update metadata with new example images
|
||||
regular_images, custom_images = await MetadataUpdater.update_metadata_after_import(
|
||||
model_hash,
|
||||
model_data,
|
||||
scanner,
|
||||
newly_imported_paths
|
||||
)
|
||||
|
||||
return web.json_response({
|
||||
'success': len(imported_files) > 0,
|
||||
'message': f'Successfully imported {len(imported_files)} files' +
|
||||
(f' with {len(errors)} errors' if errors else ''),
|
||||
'files': imported_files,
|
||||
'errors': errors,
|
||||
'regular_images': regular_images,
|
||||
'custom_images': custom_images,
|
||||
"model_file_path": model_data.get('file_path', ''),
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to import example images: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
finally:
|
||||
# Clean up temporary files
|
||||
for temp_file in temp_files_to_cleanup:
|
||||
try:
|
||||
os.remove(temp_file)
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to remove temporary file {temp_file}: {e}")
|
||||
|
||||
@staticmethod
|
||||
async def delete_custom_image(request):
|
||||
"""
|
||||
Delete a custom example image for a model
|
||||
|
||||
Accepts:
|
||||
- JSON request with model_hash and short_id
|
||||
|
||||
Returns:
|
||||
- Success status and updated image lists
|
||||
"""
|
||||
try:
|
||||
# Parse request data
|
||||
data = await request.json()
|
||||
model_hash = data.get('model_hash')
|
||||
short_id = data.get('short_id')
|
||||
|
||||
if not model_hash or not short_id:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'Missing required parameters: model_hash and short_id'
|
||||
}, status=400)
|
||||
|
||||
# Get example images path
|
||||
example_images_path = settings.get('example_images_path')
|
||||
if not example_images_path:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': 'No example images path configured'
|
||||
}, status=400)
|
||||
|
||||
# Find the model and get current metadata
|
||||
lora_scanner = await ServiceRegistry.get_lora_scanner()
|
||||
checkpoint_scanner = await ServiceRegistry.get_checkpoint_scanner()
|
||||
embedding_scanner = await ServiceRegistry.get_embedding_scanner()
|
||||
|
||||
model_data = None
|
||||
scanner = None
|
||||
|
||||
# Check both scanners to find the model
|
||||
for scan_obj in [lora_scanner, checkpoint_scanner, embedding_scanner]:
|
||||
if scan_obj.has_hash(model_hash):
|
||||
cache = await scan_obj.get_cached_data()
|
||||
for item in cache.raw_data:
|
||||
if item.get('sha256') == model_hash:
|
||||
model_data = item
|
||||
scanner = scan_obj
|
||||
break
|
||||
if model_data:
|
||||
break
|
||||
|
||||
if not model_data:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': f"Model with hash {model_hash} not found in cache"
|
||||
}, status=404)
|
||||
|
||||
# Check if model has custom images
|
||||
if not model_data.get('civitai', {}).get('customImages'):
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': f"Model has no custom images"
|
||||
}, status=404)
|
||||
|
||||
# Find the custom image with matching short_id
|
||||
custom_images = model_data['civitai']['customImages']
|
||||
matching_image = None
|
||||
new_custom_images = []
|
||||
|
||||
for image in custom_images:
|
||||
if image.get('id') == short_id:
|
||||
matching_image = image
|
||||
else:
|
||||
new_custom_images.append(image)
|
||||
|
||||
if not matching_image:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': f"Custom image with id {short_id} not found"
|
||||
}, status=404)
|
||||
|
||||
# Find and delete the actual file
|
||||
model_folder = os.path.join(example_images_path, model_hash)
|
||||
file_deleted = False
|
||||
|
||||
if os.path.exists(model_folder):
|
||||
for filename in os.listdir(model_folder):
|
||||
if f"custom_{short_id}" in filename:
|
||||
file_path = os.path.join(model_folder, filename)
|
||||
try:
|
||||
os.remove(file_path)
|
||||
file_deleted = True
|
||||
logger.info(f"Deleted custom example file: {file_path}")
|
||||
break
|
||||
except Exception as e:
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': f"Failed to delete file: {str(e)}"
|
||||
}, status=500)
|
||||
|
||||
if not file_deleted:
|
||||
logger.warning(f"File for custom example with id {short_id} not found, but metadata will still be updated")
|
||||
|
||||
# Update metadata
|
||||
model_data['civitai']['customImages'] = new_custom_images
|
||||
|
||||
# Save updated metadata to file
|
||||
file_path = model_data.get('file_path')
|
||||
if file_path:
|
||||
try:
|
||||
# Create a copy of model data without 'folder' field
|
||||
model_copy = model_data.copy()
|
||||
model_copy.pop('folder', None)
|
||||
|
||||
# Write metadata to file
|
||||
await MetadataManager.save_metadata(file_path, model_copy)
|
||||
logger.debug(f"Saved updated metadata for {model_data.get('model_name')}")
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to save metadata: {str(e)}")
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': f"Failed to save metadata: {str(e)}"
|
||||
}, status=500)
|
||||
|
||||
# Update cache
|
||||
await scanner.update_single_model_cache(file_path, file_path, model_data)
|
||||
|
||||
# Get regular images array (might be None)
|
||||
regular_images = model_data['civitai'].get('images', [])
|
||||
|
||||
return web.json_response({
|
||||
'success': True,
|
||||
'regular_images': regular_images,
|
||||
'custom_images': new_custom_images,
|
||||
'model_file_path': model_data.get('file_path', '')
|
||||
})
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to delete custom example image: {e}", exc_info=True)
|
||||
return web.json_response({
|
||||
'success': False,
|
||||
'error': str(e)
|
||||
}, status=500)
|
||||
|
||||
|
||||
|
||||
@@ -31,7 +31,7 @@ class ExifUtils:
|
||||
# Method 2: Check EXIF UserComment field
|
||||
if img.format not in ['JPEG', 'TIFF', 'WEBP']:
|
||||
# For non-JPEG/TIFF/WEBP images, try to get EXIF through PIL
|
||||
exif = img._getexif()
|
||||
exif = img.getexif()
|
||||
if exif and piexif.ExifIFD.UserComment in exif:
|
||||
user_comment = exif[piexif.ExifIFD.UserComment]
|
||||
if isinstance(user_comment, bytes):
|
||||
@@ -147,7 +147,7 @@ class ExifUtils:
|
||||
"file_name": lora.get("file_name", ""),
|
||||
"hash": lora.get("hash", "").lower() if lora.get("hash") else "",
|
||||
"strength": float(lora.get("strength", 1.0)),
|
||||
"modelVersionId": lora.get("modelVersionId", ""),
|
||||
"modelVersionId": lora.get("modelVersionId", 0),
|
||||
"modelName": lora.get("modelName", ""),
|
||||
"modelVersionName": lora.get("modelVersionName", ""),
|
||||
}
|
||||
|
||||
@@ -1,13 +1,7 @@
|
||||
import logging
|
||||
import os
|
||||
import hashlib
|
||||
import json
|
||||
import time
|
||||
from typing import Dict, Optional, Type
|
||||
|
||||
from .model_utils import determine_base_model
|
||||
from .lora_metadata import extract_lora_metadata, extract_checkpoint_metadata
|
||||
from .models import BaseModelMetadata, LoraMetadata, CheckpointMetadata
|
||||
from .constants import PREVIEW_EXTENSIONS, CARD_PREVIEW_WIDTH
|
||||
from .exif_utils import ExifUtils
|
||||
|
||||
@@ -24,237 +18,67 @@ async def calculate_sha256(file_path: str) -> str:
|
||||
def find_preview_file(base_name: str, dir_path: str) -> str:
|
||||
"""Find preview file for given base name in directory"""
|
||||
|
||||
for ext in PREVIEW_EXTENSIONS:
|
||||
temp_extensions = PREVIEW_EXTENSIONS.copy()
|
||||
# Add example extension for compatibility
|
||||
# https://github.com/willmiao/ComfyUI-Lora-Manager/issues/225
|
||||
# The preview image will be optimized to lora-name.webp, so it won't affect other logic
|
||||
temp_extensions.append(".example.0.jpeg")
|
||||
for ext in temp_extensions:
|
||||
full_pattern = os.path.join(dir_path, f"{base_name}{ext}")
|
||||
if os.path.exists(full_pattern):
|
||||
# Check if this is an image and not already webp
|
||||
if ext.lower().endswith(('.jpg', '.jpeg', '.png')) and not ext.lower().endswith('.webp'):
|
||||
try:
|
||||
# Optimize the image to webp format
|
||||
webp_path = os.path.join(dir_path, f"{base_name}.webp")
|
||||
# TODO: disable the optimization for now, maybe add a config option later
|
||||
# if ext.lower().endswith(('.jpg', '.jpeg', '.png')) and not ext.lower().endswith('.webp'):
|
||||
# try:
|
||||
# # Optimize the image to webp format
|
||||
# webp_path = os.path.join(dir_path, f"{base_name}.webp")
|
||||
|
||||
# Use ExifUtils to optimize the image
|
||||
with open(full_pattern, 'rb') as f:
|
||||
image_data = f.read()
|
||||
# # Use ExifUtils to optimize the image
|
||||
# with open(full_pattern, 'rb') as f:
|
||||
# image_data = f.read()
|
||||
|
||||
optimized_data, _ = ExifUtils.optimize_image(
|
||||
image_data=image_data,
|
||||
target_width=CARD_PREVIEW_WIDTH,
|
||||
format='webp',
|
||||
quality=85,
|
||||
preserve_metadata=False # Changed from True to False
|
||||
)
|
||||
# optimized_data, _ = ExifUtils.optimize_image(
|
||||
# image_data=image_data,
|
||||
# target_width=CARD_PREVIEW_WIDTH,
|
||||
# format='webp',
|
||||
# quality=85,
|
||||
# preserve_metadata=False
|
||||
# )
|
||||
|
||||
# Save the optimized webp file
|
||||
with open(webp_path, 'wb') as f:
|
||||
f.write(optimized_data)
|
||||
# # Save the optimized webp file
|
||||
# with open(webp_path, 'wb') as f:
|
||||
# f.write(optimized_data)
|
||||
|
||||
logger.debug(f"Optimized preview image from {full_pattern} to {webp_path}")
|
||||
return webp_path.replace(os.sep, "/")
|
||||
except Exception as e:
|
||||
logger.error(f"Error optimizing preview image {full_pattern}: {e}")
|
||||
# Fall back to original file if optimization fails
|
||||
return full_pattern.replace(os.sep, "/")
|
||||
# logger.debug(f"Optimized preview image from {full_pattern} to {webp_path}")
|
||||
# return webp_path.replace(os.sep, "/")
|
||||
# except Exception as e:
|
||||
# logger.error(f"Error optimizing preview image {full_pattern}: {e}")
|
||||
# # Fall back to original file if optimization fails
|
||||
# return full_pattern.replace(os.sep, "/")
|
||||
|
||||
# Return the original path for webp images or non-image files
|
||||
return full_pattern.replace(os.sep, "/")
|
||||
|
||||
return ""
|
||||
|
||||
def get_preview_extension(preview_path: str) -> str:
|
||||
"""Get the complete preview extension from a preview file path
|
||||
|
||||
Args:
|
||||
preview_path: Path to the preview file
|
||||
|
||||
Returns:
|
||||
str: The complete extension (e.g., '.preview.png', '.png', '.webp')
|
||||
"""
|
||||
preview_path_lower = preview_path.lower()
|
||||
|
||||
# Check for compound extensions first (longer matches first)
|
||||
for ext in sorted(PREVIEW_EXTENSIONS, key=len, reverse=True):
|
||||
if preview_path_lower.endswith(ext.lower()):
|
||||
return ext
|
||||
|
||||
return os.path.splitext(preview_path)[1]
|
||||
|
||||
def normalize_path(path: str) -> str:
|
||||
"""Normalize file path to use forward slashes"""
|
||||
return path.replace(os.sep, "/") if path else path
|
||||
|
||||
async def get_file_info(file_path: str, model_class: Type[BaseModelMetadata] = LoraMetadata) -> Optional[BaseModelMetadata]:
|
||||
"""Get basic file information as a model metadata object"""
|
||||
# First check if file actually exists and resolve symlinks
|
||||
try:
|
||||
real_path = os.path.realpath(file_path)
|
||||
if not os.path.exists(real_path):
|
||||
return None
|
||||
except Exception as e:
|
||||
logger.error(f"Error checking file existence for {file_path}: {e}")
|
||||
return None
|
||||
|
||||
base_name = os.path.splitext(os.path.basename(file_path))[0]
|
||||
dir_path = os.path.dirname(file_path)
|
||||
|
||||
preview_url = find_preview_file(base_name, dir_path)
|
||||
|
||||
# Check if a .json file exists with SHA256 hash to avoid recalculation
|
||||
json_path = f"{os.path.splitext(file_path)[0]}.json"
|
||||
sha256 = None
|
||||
if os.path.exists(json_path):
|
||||
try:
|
||||
with open(json_path, 'r', encoding='utf-8') as f:
|
||||
json_data = json.load(f)
|
||||
if 'sha256' in json_data:
|
||||
sha256 = json_data['sha256'].lower()
|
||||
logger.debug(f"Using SHA256 from .json file for {file_path}")
|
||||
except Exception as e:
|
||||
logger.error(f"Error reading .json file for {file_path}: {e}")
|
||||
|
||||
# If SHA256 is still not found, check for a .sha256 file
|
||||
if sha256 is None:
|
||||
sha256_file = f"{os.path.splitext(file_path)[0]}.sha256"
|
||||
if os.path.exists(sha256_file):
|
||||
try:
|
||||
with open(sha256_file, 'r', encoding='utf-8') as f:
|
||||
sha256 = f.read().strip().lower()
|
||||
logger.debug(f"Using SHA256 from .sha256 file for {file_path}")
|
||||
except Exception as e:
|
||||
logger.error(f"Error reading .sha256 file for {file_path}: {e}")
|
||||
|
||||
try:
|
||||
# If we didn't get SHA256 from the .json file, calculate it
|
||||
if not sha256:
|
||||
start_time = time.time()
|
||||
sha256 = await calculate_sha256(real_path)
|
||||
logger.debug(f"Calculated SHA256 for {file_path} in {time.time() - start_time:.2f} seconds")
|
||||
|
||||
# Create default metadata based on model class
|
||||
if model_class == CheckpointMetadata:
|
||||
metadata = CheckpointMetadata(
|
||||
file_name=base_name,
|
||||
model_name=base_name,
|
||||
file_path=normalize_path(file_path),
|
||||
size=os.path.getsize(real_path),
|
||||
modified=os.path.getmtime(real_path),
|
||||
sha256=sha256,
|
||||
base_model="Unknown", # Will be updated later
|
||||
preview_url=normalize_path(preview_url),
|
||||
tags=[],
|
||||
modelDescription="",
|
||||
model_type="checkpoint"
|
||||
)
|
||||
|
||||
# Extract checkpoint-specific metadata
|
||||
# model_info = await extract_checkpoint_metadata(real_path)
|
||||
# metadata.base_model = model_info['base_model']
|
||||
# if 'model_type' in model_info:
|
||||
# metadata.model_type = model_info['model_type']
|
||||
|
||||
else: # Default to LoraMetadata
|
||||
metadata = LoraMetadata(
|
||||
file_name=base_name,
|
||||
model_name=base_name,
|
||||
file_path=normalize_path(file_path),
|
||||
size=os.path.getsize(real_path),
|
||||
modified=os.path.getmtime(real_path),
|
||||
sha256=sha256,
|
||||
base_model="Unknown", # Will be updated later
|
||||
usage_tips="{}",
|
||||
preview_url=normalize_path(preview_url),
|
||||
tags=[],
|
||||
modelDescription=""
|
||||
)
|
||||
|
||||
# Extract lora-specific metadata
|
||||
model_info = await extract_lora_metadata(real_path)
|
||||
metadata.base_model = model_info['base_model']
|
||||
|
||||
# Save metadata to file
|
||||
await save_metadata(file_path, metadata)
|
||||
|
||||
return metadata
|
||||
except Exception as e:
|
||||
logger.error(f"Error getting file info for {file_path}: {e}")
|
||||
return None
|
||||
|
||||
async def save_metadata(file_path: str, metadata: BaseModelMetadata) -> None:
|
||||
"""Save metadata to .metadata.json file"""
|
||||
metadata_path = f"{os.path.splitext(file_path)[0]}.metadata.json"
|
||||
try:
|
||||
metadata_dict = metadata.to_dict()
|
||||
metadata_dict['file_path'] = normalize_path(metadata_dict['file_path'])
|
||||
metadata_dict['preview_url'] = normalize_path(metadata_dict['preview_url'])
|
||||
|
||||
with open(metadata_path, 'w', encoding='utf-8') as f:
|
||||
json.dump(metadata_dict, f, indent=2, ensure_ascii=False)
|
||||
except Exception as e:
|
||||
print(f"Error saving metadata to {metadata_path}: {str(e)}")
|
||||
|
||||
async def load_metadata(file_path: str, model_class: Type[BaseModelMetadata] = LoraMetadata) -> Optional[BaseModelMetadata]:
|
||||
"""Load metadata from .metadata.json file"""
|
||||
metadata_path = f"{os.path.splitext(file_path)[0]}.metadata.json"
|
||||
try:
|
||||
if os.path.exists(metadata_path):
|
||||
with open(metadata_path, 'r', encoding='utf-8') as f:
|
||||
data = json.load(f)
|
||||
|
||||
needs_update = False
|
||||
|
||||
# Check and normalize base model name
|
||||
normalized_base_model = determine_base_model(data['base_model'])
|
||||
if data['base_model'] != normalized_base_model:
|
||||
data['base_model'] = normalized_base_model
|
||||
needs_update = True
|
||||
|
||||
# Compare paths without extensions
|
||||
stored_path_base = os.path.splitext(data['file_path'])[0]
|
||||
current_path_base = os.path.splitext(normalize_path(file_path))[0]
|
||||
if stored_path_base != current_path_base:
|
||||
data['file_path'] = normalize_path(file_path)
|
||||
needs_update = True
|
||||
|
||||
# TODO: optimize preview image to webp format if not already done
|
||||
preview_url = data.get('preview_url', '')
|
||||
if not preview_url or not os.path.exists(preview_url):
|
||||
base_name = os.path.splitext(os.path.basename(file_path))[0]
|
||||
dir_path = os.path.dirname(file_path)
|
||||
new_preview_url = normalize_path(find_preview_file(base_name, dir_path))
|
||||
if new_preview_url != preview_url:
|
||||
data['preview_url'] = new_preview_url
|
||||
needs_update = True
|
||||
else:
|
||||
# Compare preview paths without extensions
|
||||
stored_preview_base = os.path.splitext(preview_url)[0]
|
||||
current_preview_base = os.path.splitext(normalize_path(preview_url))[0]
|
||||
if stored_preview_base != current_preview_base:
|
||||
data['preview_url'] = normalize_path(preview_url)
|
||||
needs_update = True
|
||||
|
||||
# Ensure all fields are present
|
||||
if 'tags' not in data:
|
||||
data['tags'] = []
|
||||
needs_update = True
|
||||
|
||||
if 'modelDescription' not in data:
|
||||
data['modelDescription'] = ""
|
||||
needs_update = True
|
||||
|
||||
# For checkpoint metadata
|
||||
if model_class == CheckpointMetadata and 'model_type' not in data:
|
||||
data['model_type'] = "checkpoint"
|
||||
needs_update = True
|
||||
|
||||
# For lora metadata
|
||||
if model_class == LoraMetadata and 'usage_tips' not in data:
|
||||
data['usage_tips'] = "{}"
|
||||
needs_update = True
|
||||
|
||||
# Update preview_nsfw_level if needed
|
||||
civitai_data = data.get('civitai', {})
|
||||
civitai_images = civitai_data.get('images', []) if civitai_data else []
|
||||
if (data.get('preview_url') and
|
||||
data.get('preview_nsfw_level', 0) == 0 and
|
||||
civitai_images and
|
||||
civitai_images[0].get('nsfwLevel', 0) != 0):
|
||||
data['preview_nsfw_level'] = civitai_images[0]['nsfwLevel']
|
||||
# TODO: write to metadata file
|
||||
# needs_update = True
|
||||
|
||||
if needs_update:
|
||||
save_metadata(file_path, model_class.from_dict(data))
|
||||
|
||||
return model_class.from_dict(data)
|
||||
|
||||
except Exception as e:
|
||||
print(f"Error loading metadata from {metadata_path}: {str(e)}")
|
||||
return None
|
||||
|
||||
async def update_civitai_metadata(file_path: str, civitai_data: Dict) -> None:
|
||||
"""Update metadata file with Civitai data"""
|
||||
metadata = await load_metadata(file_path)
|
||||
metadata['civitai'] = civitai_data
|
||||
await save_metadata(file_path, metadata)
|
||||
return path.replace(os.sep, "/") if path else path
|
||||
@@ -1,8 +1,9 @@
|
||||
from safetensors import safe_open
|
||||
from typing import Dict
|
||||
from typing import Dict, List, Tuple
|
||||
from .model_utils import determine_base_model
|
||||
import os
|
||||
import logging
|
||||
import json
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@@ -80,4 +81,53 @@ async def extract_checkpoint_metadata(file_path: str) -> dict:
|
||||
except Exception as e:
|
||||
logger.error(f"Error extracting checkpoint metadata for {file_path}: {e}")
|
||||
# Return default values
|
||||
return {'base_model': 'Unknown', 'model_type': 'checkpoint'}
|
||||
return {'base_model': 'Unknown', 'model_type': 'checkpoint'}
|
||||
|
||||
async def extract_trained_words(file_path: str) -> Tuple[List[Tuple[str, int]], str]:
|
||||
"""Extract trained words from a safetensors file and sort by frequency
|
||||
|
||||
Args:
|
||||
file_path: Path to the safetensors file
|
||||
|
||||
Returns:
|
||||
Tuple of:
|
||||
- List of (word, frequency) tuples sorted by frequency (highest first)
|
||||
- class_tokens value (or None if not found)
|
||||
"""
|
||||
class_tokens = None
|
||||
|
||||
try:
|
||||
with safe_open(file_path, framework="pt", device="cpu") as f:
|
||||
metadata = f.metadata()
|
||||
|
||||
# Extract class_tokens from ss_datasets if present
|
||||
if metadata and "ss_datasets" in metadata:
|
||||
try:
|
||||
datasets_data = json.loads(metadata["ss_datasets"])
|
||||
# Look for class_tokens in the first subset
|
||||
if datasets_data and isinstance(datasets_data, list) and datasets_data[0].get("subsets"):
|
||||
subsets = datasets_data[0].get("subsets", [])
|
||||
if subsets and isinstance(subsets, list) and len(subsets) > 0:
|
||||
class_tokens = subsets[0].get("class_tokens")
|
||||
except Exception as e:
|
||||
logger.error(f"Error parsing ss_datasets for class_tokens: {str(e)}")
|
||||
|
||||
# Extract tag frequency as before
|
||||
if metadata and "ss_tag_frequency" in metadata:
|
||||
# Parse the JSON string into a dictionary
|
||||
tag_data = json.loads(metadata["ss_tag_frequency"])
|
||||
|
||||
# The structure may have an outer key (like "image_dir" or "img")
|
||||
# We need to get the inner dictionary with the actual word frequencies
|
||||
if tag_data:
|
||||
# Get the first key (usually "image_dir" or "img")
|
||||
first_key = list(tag_data.keys())[0]
|
||||
words_dict = tag_data[first_key]
|
||||
|
||||
# Sort words by frequency (highest first)
|
||||
sorted_words = sorted(words_dict.items(), key=lambda x: x[1], reverse=True)
|
||||
return sorted_words, class_tokens
|
||||
except Exception as e:
|
||||
logger.error(f"Error extracting trained words from {file_path}: {str(e)}")
|
||||
|
||||
return [], class_tokens
|
||||
264
py/utils/metadata_manager.py
Normal file
264
py/utils/metadata_manager.py
Normal file
@@ -0,0 +1,264 @@
|
||||
from datetime import datetime
|
||||
import os
|
||||
import json
|
||||
import logging
|
||||
from typing import Dict, Optional, Type, Union
|
||||
|
||||
from .models import BaseModelMetadata, LoraMetadata
|
||||
from .file_utils import normalize_path, find_preview_file, calculate_sha256
|
||||
from .lora_metadata import extract_lora_metadata, extract_checkpoint_metadata
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class MetadataManager:
|
||||
"""
|
||||
Centralized manager for all metadata operations.
|
||||
|
||||
This class is responsible for:
|
||||
1. Loading metadata safely with fallback mechanisms
|
||||
2. Saving metadata with atomic operations
|
||||
3. Creating default metadata for models
|
||||
4. Handling unknown fields gracefully
|
||||
"""
|
||||
|
||||
@staticmethod
|
||||
async def load_metadata(file_path: str, model_class: Type[BaseModelMetadata] = LoraMetadata) -> Optional[BaseModelMetadata]:
|
||||
"""
|
||||
Load metadata safely.
|
||||
|
||||
Returns:
|
||||
tuple: (metadata, should_skip)
|
||||
- metadata: BaseModelMetadata instance or None
|
||||
- should_skip: True if corrupted metadata file exists and model should be skipped
|
||||
"""
|
||||
metadata_path = f"{os.path.splitext(file_path)[0]}.metadata.json"
|
||||
|
||||
# Check if metadata file exists
|
||||
if not os.path.exists(metadata_path):
|
||||
return None, False
|
||||
|
||||
try:
|
||||
with open(metadata_path, 'r', encoding='utf-8') as f:
|
||||
data = json.load(f)
|
||||
|
||||
# Create model instance
|
||||
metadata = model_class.from_dict(data)
|
||||
|
||||
# Normalize paths
|
||||
await MetadataManager._normalize_metadata_paths(metadata, file_path)
|
||||
|
||||
return metadata, False
|
||||
|
||||
except (json.JSONDecodeError, Exception) as e:
|
||||
error_type = "Invalid JSON" if isinstance(e, json.JSONDecodeError) else "Parse error"
|
||||
logger.error(f"{error_type} in metadata file: {metadata_path}. Error: {str(e)}. Skipping model to preserve existing data.")
|
||||
return None, True # should_skip = True
|
||||
|
||||
@staticmethod
|
||||
async def save_metadata(path: str, metadata: Union[BaseModelMetadata, Dict]) -> bool:
|
||||
"""
|
||||
Save metadata with atomic write operations.
|
||||
|
||||
Args:
|
||||
path: Path to the model file or directly to the metadata file
|
||||
metadata: Metadata to save (either BaseModelMetadata object or dict)
|
||||
|
||||
Returns:
|
||||
bool: Success or failure
|
||||
"""
|
||||
# Determine if the input is a metadata path or a model file path
|
||||
if path.endswith('.metadata.json'):
|
||||
metadata_path = path
|
||||
else:
|
||||
# Use existing logic for model file paths
|
||||
file_path = path
|
||||
metadata_path = f"{os.path.splitext(file_path)[0]}.metadata.json"
|
||||
temp_path = f"{metadata_path}.tmp"
|
||||
|
||||
try:
|
||||
# Convert to dict if needed
|
||||
if isinstance(metadata, BaseModelMetadata):
|
||||
metadata_dict = metadata.to_dict()
|
||||
# Preserve unknown fields if present
|
||||
if hasattr(metadata, '_unknown_fields'):
|
||||
metadata_dict.update(metadata._unknown_fields)
|
||||
else:
|
||||
metadata_dict = metadata.copy()
|
||||
|
||||
# Normalize paths
|
||||
if 'file_path' in metadata_dict:
|
||||
metadata_dict['file_path'] = normalize_path(metadata_dict['file_path'])
|
||||
if 'preview_url' in metadata_dict:
|
||||
metadata_dict['preview_url'] = normalize_path(metadata_dict['preview_url'])
|
||||
|
||||
# Write to temporary file first
|
||||
with open(temp_path, 'w', encoding='utf-8') as f:
|
||||
json.dump(metadata_dict, f, indent=2, ensure_ascii=False)
|
||||
|
||||
# Atomic rename operation
|
||||
os.replace(temp_path, metadata_path)
|
||||
return True
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error saving metadata to {metadata_path}: {str(e)}")
|
||||
# Clean up temporary file if it exists
|
||||
if os.path.exists(temp_path):
|
||||
try:
|
||||
os.remove(temp_path)
|
||||
except:
|
||||
pass
|
||||
return False
|
||||
|
||||
@staticmethod
|
||||
async def create_default_metadata(file_path: str, model_class: Type[BaseModelMetadata] = LoraMetadata) -> Optional[BaseModelMetadata]:
|
||||
"""
|
||||
Create basic metadata structure for a model file.
|
||||
This replaces the old get_file_info function with a more appropriately named method.
|
||||
|
||||
Args:
|
||||
file_path: Path to the model file
|
||||
model_class: Class to instantiate
|
||||
|
||||
Returns:
|
||||
BaseModelMetadata instance or None if file doesn't exist
|
||||
"""
|
||||
# First check if file actually exists and resolve symlinks
|
||||
try:
|
||||
real_path = os.path.realpath(file_path)
|
||||
if not os.path.exists(real_path):
|
||||
return None
|
||||
except Exception as e:
|
||||
logger.error(f"Error checking file existence for {file_path}: {e}")
|
||||
return None
|
||||
|
||||
try:
|
||||
base_name = os.path.splitext(os.path.basename(file_path))[0]
|
||||
dir_path = os.path.dirname(file_path)
|
||||
|
||||
# Find preview image
|
||||
preview_url = find_preview_file(base_name, dir_path)
|
||||
|
||||
# Calculate file hash
|
||||
sha256 = await calculate_sha256(real_path)
|
||||
|
||||
# Create instance based on model type
|
||||
if model_class.__name__ == "CheckpointMetadata":
|
||||
metadata = model_class(
|
||||
file_name=base_name,
|
||||
model_name=base_name,
|
||||
file_path=normalize_path(file_path),
|
||||
size=os.path.getsize(real_path),
|
||||
modified=datetime.now().timestamp(),
|
||||
sha256=sha256,
|
||||
base_model="Unknown",
|
||||
preview_url=normalize_path(preview_url),
|
||||
tags=[],
|
||||
modelDescription="",
|
||||
model_type="checkpoint",
|
||||
from_civitai=True
|
||||
)
|
||||
elif model_class.__name__ == "EmbeddingMetadata":
|
||||
metadata = model_class(
|
||||
file_name=base_name,
|
||||
model_name=base_name,
|
||||
file_path=normalize_path(file_path),
|
||||
size=os.path.getsize(real_path),
|
||||
modified=datetime.now().timestamp(),
|
||||
sha256=sha256,
|
||||
base_model="Unknown",
|
||||
preview_url=normalize_path(preview_url),
|
||||
tags=[],
|
||||
modelDescription="",
|
||||
from_civitai=True
|
||||
)
|
||||
else: # Default to LoraMetadata
|
||||
metadata = model_class(
|
||||
file_name=base_name,
|
||||
model_name=base_name,
|
||||
file_path=normalize_path(file_path),
|
||||
size=os.path.getsize(real_path),
|
||||
modified=datetime.now().timestamp(),
|
||||
sha256=sha256,
|
||||
base_model="Unknown",
|
||||
preview_url=normalize_path(preview_url),
|
||||
tags=[],
|
||||
modelDescription="",
|
||||
from_civitai=True,
|
||||
usage_tips="{}"
|
||||
)
|
||||
|
||||
# Try to extract model-specific metadata
|
||||
# await MetadataManager._enrich_metadata(metadata, real_path)
|
||||
|
||||
# Save the created metadata
|
||||
await MetadataManager.save_metadata(file_path, metadata)
|
||||
|
||||
return metadata
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error creating default metadata for {file_path}: {e}")
|
||||
return None
|
||||
|
||||
@staticmethod
|
||||
async def _enrich_metadata(metadata: BaseModelMetadata, file_path: str) -> None:
|
||||
"""
|
||||
Enrich metadata with model-specific information
|
||||
|
||||
Args:
|
||||
metadata: Metadata to enrich
|
||||
file_path: Path to the model file
|
||||
"""
|
||||
try:
|
||||
if metadata.__class__.__name__ == "LoraMetadata":
|
||||
model_info = await extract_lora_metadata(file_path)
|
||||
metadata.base_model = model_info['base_model']
|
||||
|
||||
# elif metadata.__class__.__name__ == "CheckpointMetadata":
|
||||
# model_info = await extract_checkpoint_metadata(file_path)
|
||||
# metadata.base_model = model_info['base_model']
|
||||
# if 'model_type' in model_info:
|
||||
# metadata.model_type = model_info['model_type']
|
||||
except Exception as e:
|
||||
logger.error(f"Error enriching metadata: {str(e)}")
|
||||
|
||||
@staticmethod
|
||||
async def _normalize_metadata_paths(metadata: BaseModelMetadata, file_path: str) -> None:
|
||||
"""
|
||||
Normalize paths in metadata object
|
||||
|
||||
Args:
|
||||
metadata: Metadata object to update
|
||||
file_path: Current file path for the model
|
||||
"""
|
||||
need_update = False
|
||||
|
||||
# Check if file_name matches the actual file name
|
||||
base_name = os.path.splitext(os.path.basename(file_path))[0]
|
||||
if metadata.file_name != base_name:
|
||||
metadata.file_name = base_name
|
||||
need_update = True
|
||||
|
||||
# Check if file path is different from what's in metadata
|
||||
if normalize_path(file_path) != metadata.file_path:
|
||||
metadata.file_path = normalize_path(file_path)
|
||||
need_update = True
|
||||
|
||||
# Check if preview exists at the current location
|
||||
preview_url = metadata.preview_url
|
||||
if preview_url:
|
||||
# Get directory parts of both paths
|
||||
file_dir = os.path.dirname(file_path)
|
||||
preview_dir = os.path.dirname(preview_url)
|
||||
|
||||
# Update preview if it doesn't exist OR if model and preview are in different directories
|
||||
if not os.path.exists(preview_url) or file_dir != preview_dir:
|
||||
base_name = os.path.splitext(os.path.basename(file_path))[0]
|
||||
dir_path = os.path.dirname(file_path)
|
||||
new_preview_url = find_preview_file(base_name, dir_path)
|
||||
if new_preview_url:
|
||||
metadata.preview_url = normalize_path(new_preview_url)
|
||||
need_update = True
|
||||
|
||||
# If path attributes were changed, save the metadata back to disk
|
||||
if need_update:
|
||||
await MetadataManager.save_metadata(file_path, metadata)
|
||||
@@ -1,5 +1,5 @@
|
||||
from dataclasses import dataclass, asdict
|
||||
from typing import Dict, Optional, List
|
||||
from dataclasses import dataclass, asdict, field
|
||||
from typing import Dict, Optional, List, Any
|
||||
from datetime import datetime
|
||||
import os
|
||||
from .model_utils import determine_base_model
|
||||
@@ -11,7 +11,7 @@ class BaseModelMetadata:
|
||||
model_name: str # The model's name defined by the creator
|
||||
file_path: str # Full path to the model file
|
||||
size: int # File size in bytes
|
||||
modified: float # Last modified timestamp
|
||||
modified: float # Timestamp when the model was added to the management system
|
||||
sha256: str # SHA256 hash of the file
|
||||
base_model: str # Base model type (SD1.5/SD2.1/SDXL/etc.)
|
||||
preview_url: str # Preview image URL
|
||||
@@ -24,6 +24,7 @@ class BaseModelMetadata:
|
||||
civitai_deleted: bool = False # Whether deleted from Civitai
|
||||
favorite: bool = False # Whether the model is a favorite
|
||||
exclude: bool = False # Whether to exclude this model from the cache
|
||||
_unknown_fields: Dict[str, Any] = field(default_factory=dict, repr=False, compare=False) # Store unknown fields
|
||||
|
||||
def __post_init__(self):
|
||||
# Initialize empty lists to avoid mutable default parameter issue
|
||||
@@ -34,16 +35,43 @@ class BaseModelMetadata:
|
||||
def from_dict(cls, data: Dict) -> 'BaseModelMetadata':
|
||||
"""Create instance from dictionary"""
|
||||
data_copy = data.copy()
|
||||
return cls(**data_copy)
|
||||
|
||||
# Use cached fields if available, otherwise compute them
|
||||
if not hasattr(cls, '_known_fields_cache'):
|
||||
known_fields = set()
|
||||
for c in cls.mro():
|
||||
if hasattr(c, '__annotations__'):
|
||||
known_fields.update(c.__annotations__.keys())
|
||||
cls._known_fields_cache = known_fields
|
||||
|
||||
known_fields = cls._known_fields_cache
|
||||
|
||||
# Extract fields that match our class attributes
|
||||
fields_to_use = {k: v for k, v in data_copy.items() if k in known_fields}
|
||||
|
||||
# Store unknown fields separately
|
||||
unknown_fields = {k: v for k, v in data_copy.items() if k not in known_fields and not k.startswith('_')}
|
||||
|
||||
# Create instance with known fields
|
||||
instance = cls(**fields_to_use)
|
||||
|
||||
# Add unknown fields as a separate attribute
|
||||
instance._unknown_fields = unknown_fields
|
||||
|
||||
return instance
|
||||
|
||||
def to_dict(self) -> Dict:
|
||||
"""Convert to dictionary for JSON serialization"""
|
||||
return asdict(self)
|
||||
|
||||
@property
|
||||
def modified_datetime(self) -> datetime:
|
||||
"""Convert modified timestamp to datetime object"""
|
||||
return datetime.fromtimestamp(self.modified)
|
||||
result = asdict(self)
|
||||
|
||||
# Remove private fields
|
||||
result = {k: v for k, v in result.items() if not k.startswith('_')}
|
||||
|
||||
# Add back unknown fields if they exist
|
||||
if hasattr(self, '_unknown_fields'):
|
||||
result.update(self._unknown_fields)
|
||||
|
||||
return result
|
||||
|
||||
def update_civitai_info(self, civitai_data: Dict) -> None:
|
||||
"""Update Civitai information"""
|
||||
@@ -55,6 +83,50 @@ class BaseModelMetadata:
|
||||
self.size = os.path.getsize(file_path)
|
||||
self.modified = os.path.getmtime(file_path)
|
||||
self.file_path = file_path.replace(os.sep, '/')
|
||||
# Update file_name when file_path changes
|
||||
self.file_name = os.path.splitext(os.path.basename(file_path))[0]
|
||||
|
||||
@staticmethod
|
||||
def generate_unique_filename(target_dir: str, base_name: str, extension: str, hash_provider: callable = None) -> str:
|
||||
"""Generate a unique filename to avoid conflicts
|
||||
|
||||
Args:
|
||||
target_dir: Target directory path
|
||||
base_name: Base filename without extension
|
||||
extension: File extension including the dot
|
||||
hash_provider: A callable that returns the SHA256 hash when needed
|
||||
|
||||
Returns:
|
||||
str: Unique filename that doesn't conflict with existing files
|
||||
"""
|
||||
original_filename = f"{base_name}{extension}"
|
||||
target_path = os.path.join(target_dir, original_filename)
|
||||
|
||||
# If no conflict, return original filename
|
||||
if not os.path.exists(target_path):
|
||||
return original_filename
|
||||
|
||||
# Only compute hash when needed
|
||||
if hash_provider:
|
||||
sha256_hash = hash_provider()
|
||||
else:
|
||||
sha256_hash = "0000"
|
||||
|
||||
# Generate short hash (first 4 characters of SHA256)
|
||||
short_hash = sha256_hash[:4] if sha256_hash else "0000"
|
||||
|
||||
# Try with short hash suffix
|
||||
unique_filename = f"{base_name}-{short_hash}{extension}"
|
||||
unique_path = os.path.join(target_dir, unique_filename)
|
||||
|
||||
# If still conflicts, add incremental number
|
||||
counter = 1
|
||||
while os.path.exists(unique_path):
|
||||
unique_filename = f"{base_name}-{short_hash}-{counter}{extension}"
|
||||
unique_path = os.path.join(target_dir, unique_filename)
|
||||
counter += 1
|
||||
|
||||
return unique_filename
|
||||
|
||||
@dataclass
|
||||
class LoraMetadata(BaseModelMetadata):
|
||||
@@ -95,7 +167,7 @@ class LoraMetadata(BaseModelMetadata):
|
||||
@dataclass
|
||||
class CheckpointMetadata(BaseModelMetadata):
|
||||
"""Represents the metadata structure for a Checkpoint model"""
|
||||
model_type: str = "checkpoint" # Model type (checkpoint, inpainting, etc.)
|
||||
model_type: str = "checkpoint" # Model type (checkpoint, diffusion_model, etc.)
|
||||
|
||||
@classmethod
|
||||
def from_civitai_info(cls, version_info: Dict, file_info: Dict, save_path: str) -> 'CheckpointMetadata':
|
||||
@@ -130,3 +202,41 @@ class CheckpointMetadata(BaseModelMetadata):
|
||||
modelDescription=description
|
||||
)
|
||||
|
||||
@dataclass
|
||||
class EmbeddingMetadata(BaseModelMetadata):
|
||||
"""Represents the metadata structure for an Embedding model"""
|
||||
model_type: str = "embedding" # Model type (embedding, textual_inversion, etc.)
|
||||
|
||||
@classmethod
|
||||
def from_civitai_info(cls, version_info: Dict, file_info: Dict, save_path: str) -> 'EmbeddingMetadata':
|
||||
"""Create EmbeddingMetadata instance from Civitai version info"""
|
||||
file_name = file_info['name']
|
||||
base_model = determine_base_model(version_info.get('baseModel', ''))
|
||||
model_type = version_info.get('type', 'embedding')
|
||||
|
||||
# Extract tags and description if available
|
||||
tags = []
|
||||
description = ""
|
||||
if 'model' in version_info:
|
||||
if 'tags' in version_info['model']:
|
||||
tags = version_info['model']['tags']
|
||||
if 'description' in version_info['model']:
|
||||
description = version_info['model']['description']
|
||||
|
||||
return cls(
|
||||
file_name=os.path.splitext(file_name)[0],
|
||||
model_name=version_info.get('model').get('name', os.path.splitext(file_name)[0]),
|
||||
file_path=save_path.replace(os.sep, '/'),
|
||||
size=file_info.get('sizeKB', 0) * 1024,
|
||||
modified=datetime.now().timestamp(),
|
||||
sha256=file_info['hashes'].get('SHA256', '').lower(),
|
||||
base_model=base_model,
|
||||
preview_url=None, # Will be updated after preview download
|
||||
preview_nsfw_level=0,
|
||||
from_civitai=True,
|
||||
civitai=version_info,
|
||||
model_type=model_type,
|
||||
tags=tags,
|
||||
modelDescription=description
|
||||
)
|
||||
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -4,6 +4,8 @@ import sys
|
||||
import time
|
||||
import asyncio
|
||||
import logging
|
||||
import datetime
|
||||
import shutil
|
||||
from typing import Dict, Set
|
||||
|
||||
from ..config import config
|
||||
@@ -26,6 +28,7 @@ class UsageStats:
|
||||
|
||||
# Default stats file name
|
||||
STATS_FILENAME = "lora_manager_stats.json"
|
||||
BACKUP_SUFFIX = ".backup"
|
||||
|
||||
def __new__(cls):
|
||||
if cls._instance is None:
|
||||
@@ -39,8 +42,8 @@ class UsageStats:
|
||||
|
||||
# Initialize stats storage
|
||||
self.stats = {
|
||||
"checkpoints": {}, # sha256 -> count
|
||||
"loras": {}, # sha256 -> count
|
||||
"checkpoints": {}, # sha256 -> { total: count, history: { date: count } }
|
||||
"loras": {}, # sha256 -> { total: count, history: { date: count } }
|
||||
"total_executions": 0,
|
||||
"last_save_time": 0
|
||||
}
|
||||
@@ -59,17 +62,80 @@ class UsageStats:
|
||||
self._bg_task = asyncio.create_task(self._background_processor())
|
||||
|
||||
self._initialized = True
|
||||
logger.info("Usage statistics tracker initialized")
|
||||
logger.debug("Usage statistics tracker initialized")
|
||||
|
||||
def _get_stats_file_path(self) -> str:
|
||||
"""Get the path to the stats JSON file"""
|
||||
if not config.loras_roots or len(config.loras_roots) == 0:
|
||||
# Fallback to temporary directory if no lora roots
|
||||
return os.path.join(config.temp_directory, self.STATS_FILENAME)
|
||||
# If no lora roots are available, we can't save stats
|
||||
# This will be handled by the caller
|
||||
raise RuntimeError("No LoRA root directories configured. Cannot initialize usage statistics.")
|
||||
|
||||
# Use the first lora root
|
||||
return os.path.join(config.loras_roots[0], self.STATS_FILENAME)
|
||||
|
||||
def _backup_old_stats(self):
|
||||
"""Backup the old stats file before conversion"""
|
||||
if os.path.exists(self._stats_file_path):
|
||||
backup_path = f"{self._stats_file_path}{self.BACKUP_SUFFIX}"
|
||||
try:
|
||||
shutil.copy2(self._stats_file_path, backup_path)
|
||||
logger.info(f"Backed up old stats file to {backup_path}")
|
||||
return True
|
||||
except Exception as e:
|
||||
logger.error(f"Failed to backup stats file: {e}")
|
||||
return False
|
||||
|
||||
def _convert_old_format(self, old_stats):
|
||||
"""Convert old stats format to new format with history"""
|
||||
new_stats = {
|
||||
"checkpoints": {},
|
||||
"loras": {},
|
||||
"total_executions": old_stats.get("total_executions", 0),
|
||||
"last_save_time": old_stats.get("last_save_time", time.time())
|
||||
}
|
||||
|
||||
# Get today's date in YYYY-MM-DD format
|
||||
today = datetime.datetime.now().strftime("%Y-%m-%d")
|
||||
|
||||
# Convert checkpoint stats
|
||||
if "checkpoints" in old_stats and isinstance(old_stats["checkpoints"], dict):
|
||||
for hash_id, count in old_stats["checkpoints"].items():
|
||||
new_stats["checkpoints"][hash_id] = {
|
||||
"total": count,
|
||||
"history": {
|
||||
today: count
|
||||
}
|
||||
}
|
||||
|
||||
# Convert lora stats
|
||||
if "loras" in old_stats and isinstance(old_stats["loras"], dict):
|
||||
for hash_id, count in old_stats["loras"].items():
|
||||
new_stats["loras"][hash_id] = {
|
||||
"total": count,
|
||||
"history": {
|
||||
today: count
|
||||
}
|
||||
}
|
||||
|
||||
logger.info("Successfully converted stats from old format to new format with history")
|
||||
return new_stats
|
||||
|
||||
def _is_old_format(self, stats):
|
||||
"""Check if the stats are in the old format (direct count values)"""
|
||||
# Check if any lora or checkpoint entry is a direct number instead of an object
|
||||
if "loras" in stats and isinstance(stats["loras"], dict):
|
||||
for hash_id, data in stats["loras"].items():
|
||||
if isinstance(data, (int, float)):
|
||||
return True
|
||||
|
||||
if "checkpoints" in stats and isinstance(stats["checkpoints"], dict):
|
||||
for hash_id, data in stats["checkpoints"].items():
|
||||
if isinstance(data, (int, float)):
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
def _load_stats(self):
|
||||
"""Load existing statistics from file"""
|
||||
try:
|
||||
@@ -77,19 +143,28 @@ class UsageStats:
|
||||
with open(self._stats_file_path, 'r', encoding='utf-8') as f:
|
||||
loaded_stats = json.load(f)
|
||||
|
||||
# Update our stats with loaded data
|
||||
if isinstance(loaded_stats, dict):
|
||||
# Update individual sections to maintain structure
|
||||
if "checkpoints" in loaded_stats and isinstance(loaded_stats["checkpoints"], dict):
|
||||
self.stats["checkpoints"] = loaded_stats["checkpoints"]
|
||||
|
||||
if "loras" in loaded_stats and isinstance(loaded_stats["loras"], dict):
|
||||
self.stats["loras"] = loaded_stats["loras"]
|
||||
|
||||
if "total_executions" in loaded_stats:
|
||||
self.stats["total_executions"] = loaded_stats["total_executions"]
|
||||
|
||||
logger.info(f"Loaded usage statistics from {self._stats_file_path}")
|
||||
# Check if old format and needs conversion
|
||||
if self._is_old_format(loaded_stats):
|
||||
logger.info("Detected old stats format, performing conversion")
|
||||
self._backup_old_stats()
|
||||
self.stats = self._convert_old_format(loaded_stats)
|
||||
else:
|
||||
# Update our stats with loaded data (already in new format)
|
||||
if isinstance(loaded_stats, dict):
|
||||
# Update individual sections to maintain structure
|
||||
if "checkpoints" in loaded_stats and isinstance(loaded_stats["checkpoints"], dict):
|
||||
self.stats["checkpoints"] = loaded_stats["checkpoints"]
|
||||
|
||||
if "loras" in loaded_stats and isinstance(loaded_stats["loras"], dict):
|
||||
self.stats["loras"] = loaded_stats["loras"]
|
||||
|
||||
if "total_executions" in loaded_stats:
|
||||
self.stats["total_executions"] = loaded_stats["total_executions"]
|
||||
|
||||
if "last_save_time" in loaded_stats:
|
||||
self.stats["last_save_time"] = loaded_stats["last_save_time"]
|
||||
|
||||
logger.debug(f"Loaded usage statistics from {self._stats_file_path}")
|
||||
except Exception as e:
|
||||
logger.error(f"Error loading usage statistics: {e}")
|
||||
|
||||
@@ -174,15 +249,18 @@ class UsageStats:
|
||||
# Increment total executions count
|
||||
self.stats["total_executions"] += 1
|
||||
|
||||
# Get today's date in YYYY-MM-DD format
|
||||
today = datetime.datetime.now().strftime("%Y-%m-%d")
|
||||
|
||||
# Process checkpoints
|
||||
if MODELS in metadata and isinstance(metadata[MODELS], dict):
|
||||
await self._process_checkpoints(metadata[MODELS])
|
||||
await self._process_checkpoints(metadata[MODELS], today)
|
||||
|
||||
# Process loras
|
||||
if LORAS in metadata and isinstance(metadata[LORAS], dict):
|
||||
await self._process_loras(metadata[LORAS])
|
||||
await self._process_loras(metadata[LORAS], today)
|
||||
|
||||
async def _process_checkpoints(self, models_data):
|
||||
async def _process_checkpoints(self, models_data, today_date):
|
||||
"""Process checkpoint models from metadata"""
|
||||
try:
|
||||
# Get checkpoint scanner service
|
||||
@@ -208,12 +286,24 @@ class UsageStats:
|
||||
# Get hash for this checkpoint
|
||||
model_hash = checkpoint_scanner.get_hash_by_filename(model_filename)
|
||||
if model_hash:
|
||||
# Update stats for this checkpoint
|
||||
self.stats["checkpoints"][model_hash] = self.stats["checkpoints"].get(model_hash, 0) + 1
|
||||
# Update stats for this checkpoint with date tracking
|
||||
if model_hash not in self.stats["checkpoints"]:
|
||||
self.stats["checkpoints"][model_hash] = {
|
||||
"total": 0,
|
||||
"history": {}
|
||||
}
|
||||
|
||||
# Increment total count
|
||||
self.stats["checkpoints"][model_hash]["total"] += 1
|
||||
|
||||
# Increment today's count
|
||||
if today_date not in self.stats["checkpoints"][model_hash]["history"]:
|
||||
self.stats["checkpoints"][model_hash]["history"][today_date] = 0
|
||||
self.stats["checkpoints"][model_hash]["history"][today_date] += 1
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing checkpoint usage: {e}", exc_info=True)
|
||||
|
||||
async def _process_loras(self, loras_data):
|
||||
async def _process_loras(self, loras_data, today_date):
|
||||
"""Process LoRA models from metadata"""
|
||||
try:
|
||||
# Get LoRA scanner service
|
||||
@@ -239,8 +329,20 @@ class UsageStats:
|
||||
# Get hash for this LoRA
|
||||
lora_hash = lora_scanner.get_hash_by_filename(lora_name)
|
||||
if lora_hash:
|
||||
# Update stats for this LoRA
|
||||
self.stats["loras"][lora_hash] = self.stats["loras"].get(lora_hash, 0) + 1
|
||||
# Update stats for this LoRA with date tracking
|
||||
if lora_hash not in self.stats["loras"]:
|
||||
self.stats["loras"][lora_hash] = {
|
||||
"total": 0,
|
||||
"history": {}
|
||||
}
|
||||
|
||||
# Increment total count
|
||||
self.stats["loras"][lora_hash]["total"] += 1
|
||||
|
||||
# Increment today's count
|
||||
if today_date not in self.stats["loras"][lora_hash]["history"]:
|
||||
self.stats["loras"][lora_hash]["history"][today_date] = 0
|
||||
self.stats["loras"][lora_hash]["history"][today_date] += 1
|
||||
except Exception as e:
|
||||
logger.error(f"Error processing LoRA usage: {e}", exc_info=True)
|
||||
|
||||
@@ -251,9 +353,11 @@ class UsageStats:
|
||||
async def get_model_usage_count(self, model_type, sha256):
|
||||
"""Get usage count for a specific model by hash"""
|
||||
if model_type == "checkpoint":
|
||||
return self.stats["checkpoints"].get(sha256, 0)
|
||||
if sha256 in self.stats["checkpoints"]:
|
||||
return self.stats["checkpoints"][sha256]["total"]
|
||||
elif model_type == "lora":
|
||||
return self.stats["loras"].get(sha256, 0)
|
||||
if sha256 in self.stats["loras"]:
|
||||
return self.stats["loras"][sha256]["total"]
|
||||
return 0
|
||||
|
||||
async def process_execution(self, prompt_id):
|
||||
|
||||
@@ -1,85 +1,56 @@
|
||||
from difflib import SequenceMatcher
|
||||
import requests
|
||||
import tempfile
|
||||
import re
|
||||
from bs4 import BeautifulSoup
|
||||
import os
|
||||
from typing import Dict
|
||||
from ..services.service_registry import ServiceRegistry
|
||||
from ..config import config
|
||||
from ..services.settings_manager import settings
|
||||
from .constants import CIVITAI_MODEL_TAGS
|
||||
import asyncio
|
||||
|
||||
def download_twitter_image(url):
|
||||
"""Download image from a URL containing twitter:image meta tag
|
||||
def get_lora_info(lora_name):
|
||||
"""Get the lora path and trigger words from cache"""
|
||||
async def _get_lora_info_async():
|
||||
scanner = await ServiceRegistry.get_lora_scanner()
|
||||
cache = await scanner.get_cached_data()
|
||||
|
||||
for item in cache.raw_data:
|
||||
if item.get('file_name') == lora_name:
|
||||
file_path = item.get('file_path')
|
||||
if file_path:
|
||||
for root in config.loras_roots:
|
||||
root = root.replace(os.sep, '/')
|
||||
if file_path.startswith(root):
|
||||
relative_path = os.path.relpath(file_path, root).replace(os.sep, '/')
|
||||
# Get trigger words from civitai metadata
|
||||
civitai = item.get('civitai', {})
|
||||
trigger_words = civitai.get('trainedWords', []) if civitai else []
|
||||
return relative_path, trigger_words
|
||||
return lora_name, []
|
||||
|
||||
Args:
|
||||
url (str): The URL to download image from
|
||||
|
||||
Returns:
|
||||
str: Path to downloaded temporary image file
|
||||
"""
|
||||
try:
|
||||
# Download page content
|
||||
response = requests.get(url)
|
||||
response.raise_for_status()
|
||||
# Check if we're already in an event loop
|
||||
loop = asyncio.get_running_loop()
|
||||
# If we're in a running loop, we need to use a different approach
|
||||
# Create a new thread to run the async code
|
||||
import concurrent.futures
|
||||
|
||||
# Parse HTML
|
||||
soup = BeautifulSoup(response.text, 'html.parser')
|
||||
def run_in_thread():
|
||||
new_loop = asyncio.new_event_loop()
|
||||
asyncio.set_event_loop(new_loop)
|
||||
try:
|
||||
return new_loop.run_until_complete(_get_lora_info_async())
|
||||
finally:
|
||||
new_loop.close()
|
||||
|
||||
# Find twitter:image meta tag
|
||||
meta_tag = soup.find('meta', attrs={'property': 'twitter:image'})
|
||||
if not meta_tag:
|
||||
return None
|
||||
with concurrent.futures.ThreadPoolExecutor() as executor:
|
||||
future = executor.submit(run_in_thread)
|
||||
return future.result()
|
||||
|
||||
image_url = meta_tag['content']
|
||||
|
||||
# Download image
|
||||
image_response = requests.get(image_url)
|
||||
image_response.raise_for_status()
|
||||
|
||||
# Save to temp file
|
||||
with tempfile.NamedTemporaryFile(delete=False, suffix='.jpg') as temp_file:
|
||||
temp_file.write(image_response.content)
|
||||
return temp_file.name
|
||||
|
||||
except Exception as e:
|
||||
print(f"Error downloading twitter image: {e}")
|
||||
return None
|
||||
except RuntimeError:
|
||||
# No event loop is running, we can use asyncio.run()
|
||||
return asyncio.run(_get_lora_info_async())
|
||||
|
||||
def download_civitai_image(url):
|
||||
"""Download image from a URL containing avatar image with specific class and style attributes
|
||||
|
||||
Args:
|
||||
url (str): The URL to download image from
|
||||
|
||||
Returns:
|
||||
str: Path to downloaded temporary image file
|
||||
"""
|
||||
try:
|
||||
# Download page content
|
||||
response = requests.get(url)
|
||||
response.raise_for_status()
|
||||
|
||||
# Parse HTML
|
||||
soup = BeautifulSoup(response.text, 'html.parser')
|
||||
|
||||
# Find image with specific class and style attributes
|
||||
image = soup.select_one('img.EdgeImage_image__iH4_q.max-h-full.w-auto.max-w-full')
|
||||
|
||||
if not image or 'src' not in image.attrs:
|
||||
return None
|
||||
|
||||
image_url = image['src']
|
||||
|
||||
# Download image
|
||||
image_response = requests.get(image_url)
|
||||
image_response.raise_for_status()
|
||||
|
||||
# Save to temp file
|
||||
with tempfile.NamedTemporaryFile(delete=False, suffix='.jpg') as temp_file:
|
||||
temp_file.write(image_response.content)
|
||||
return temp_file.name
|
||||
|
||||
except Exception as e:
|
||||
print(f"Error downloading civitai avatar: {e}")
|
||||
return None
|
||||
|
||||
def fuzzy_match(text: str, pattern: str, threshold: float = 0.7) -> bool:
|
||||
def fuzzy_match(text: str, pattern: str, threshold: float = 0.85) -> bool:
|
||||
"""
|
||||
Check if text matches pattern using fuzzy matching.
|
||||
Returns True if similarity ratio is above threshold.
|
||||
@@ -142,7 +113,7 @@ def calculate_recipe_fingerprint(loras):
|
||||
# Get the hash - use modelVersionId as fallback if hash is empty
|
||||
hash_value = lora.get("hash", "").lower()
|
||||
if not hash_value and lora.get("isDeleted", False) and lora.get("modelVersionId"):
|
||||
hash_value = lora.get("modelVersionId")
|
||||
hash_value = str(lora.get("modelVersionId"))
|
||||
|
||||
# Skip entries without a valid hash
|
||||
if not hash_value:
|
||||
@@ -160,3 +131,95 @@ def calculate_recipe_fingerprint(loras):
|
||||
fingerprint = "|".join([f"{hash_value}:{strength}" for hash_value, strength in valid_loras])
|
||||
|
||||
return fingerprint
|
||||
|
||||
def calculate_relative_path_for_model(model_data: Dict, model_type: str = 'lora') -> str:
|
||||
"""Calculate relative path for existing model using template from settings
|
||||
|
||||
Args:
|
||||
model_data: Model data from scanner cache
|
||||
model_type: Type of model ('lora', 'checkpoint', 'embedding')
|
||||
|
||||
Returns:
|
||||
Relative path string (empty string for flat structure)
|
||||
"""
|
||||
# Get path template from settings for specific model type
|
||||
path_template = settings.get_download_path_template(model_type)
|
||||
|
||||
# If template is empty, return empty path (flat structure)
|
||||
if not path_template:
|
||||
return ''
|
||||
|
||||
# Get base model name from model metadata
|
||||
civitai_data = model_data.get('civitai', {})
|
||||
|
||||
# For CivitAI models, prefer civitai data only if 'id' exists; for non-CivitAI models, use model_data directly
|
||||
if civitai_data and civitai_data.get('id') is not None:
|
||||
base_model = model_data.get('base_model', '')
|
||||
# Get author from civitai creator data
|
||||
creator_info = civitai_data.get('creator') or {}
|
||||
author = creator_info.get('username') or 'Anonymous'
|
||||
else:
|
||||
# Fallback to model_data fields for non-CivitAI models
|
||||
base_model = model_data.get('base_model', '')
|
||||
author = 'Anonymous' # Default for non-CivitAI models
|
||||
|
||||
model_tags = model_data.get('tags', [])
|
||||
|
||||
# Apply mapping if available
|
||||
base_model_mappings = settings.get('base_model_path_mappings', {})
|
||||
mapped_base_model = base_model_mappings.get(base_model, base_model)
|
||||
|
||||
# Find the first Civitai model tag that exists in model_tags
|
||||
first_tag = ''
|
||||
for civitai_tag in CIVITAI_MODEL_TAGS:
|
||||
if civitai_tag in model_tags:
|
||||
first_tag = civitai_tag
|
||||
break
|
||||
|
||||
# If no Civitai model tag found, fallback to first tag
|
||||
if not first_tag and model_tags:
|
||||
first_tag = model_tags[0]
|
||||
|
||||
if not first_tag:
|
||||
first_tag = 'no tags' # Default if no tags available
|
||||
|
||||
# Format the template with available data
|
||||
formatted_path = path_template
|
||||
formatted_path = formatted_path.replace('{base_model}', mapped_base_model)
|
||||
formatted_path = formatted_path.replace('{first_tag}', first_tag)
|
||||
formatted_path = formatted_path.replace('{author}', author)
|
||||
|
||||
return formatted_path
|
||||
|
||||
def remove_empty_dirs(path):
|
||||
"""Recursively remove empty directories starting from the given path.
|
||||
|
||||
Args:
|
||||
path (str): Root directory to start cleaning from
|
||||
|
||||
Returns:
|
||||
int: Number of empty directories removed
|
||||
"""
|
||||
removed_count = 0
|
||||
|
||||
if not os.path.isdir(path):
|
||||
return removed_count
|
||||
|
||||
# List all files in directory
|
||||
files = os.listdir(path)
|
||||
|
||||
# Process all subdirectories first
|
||||
for file in files:
|
||||
full_path = os.path.join(path, file)
|
||||
if os.path.isdir(full_path):
|
||||
removed_count += remove_empty_dirs(full_path)
|
||||
|
||||
# Check if directory is now empty (after processing subdirectories)
|
||||
if not os.listdir(path):
|
||||
try:
|
||||
os.rmdir(path)
|
||||
removed_count += 1
|
||||
except OSError:
|
||||
pass
|
||||
|
||||
return removed_count
|
||||
|
||||
@@ -1,20 +1,19 @@
|
||||
[project]
|
||||
name = "comfyui-lora-manager"
|
||||
description = "LoRA Manager for ComfyUI - Access it at http://localhost:8188/loras for managing LoRA models with previews and metadata integration."
|
||||
version = "0.8.15"
|
||||
description = "Revolutionize your workflow with the ultimate LoRA companion for ComfyUI!"
|
||||
version = "0.9.3"
|
||||
license = {file = "LICENSE"}
|
||||
dependencies = [
|
||||
"aiohttp",
|
||||
"jinja2",
|
||||
"safetensors",
|
||||
"watchdog",
|
||||
"beautifulsoup4",
|
||||
"piexif",
|
||||
"Pillow",
|
||||
"olefile", # for getting rid of warning message
|
||||
"requests",
|
||||
"toml",
|
||||
"natsort"
|
||||
"natsort",
|
||||
"GitPython",
|
||||
"aiosqlite"
|
||||
]
|
||||
|
||||
[project.urls]
|
||||
@@ -24,4 +23,4 @@ Repository = "https://github.com/willmiao/ComfyUI-Lora-Manager"
|
||||
[tool.comfy]
|
||||
PublisherId = "willmiao"
|
||||
DisplayName = "ComfyUI-Lora-Manager"
|
||||
Icon = ""
|
||||
Icon = "https://github.com/willmiao/ComfyUI-Lora-Manager/blob/main/static/images/android-chrome-512x512.png?raw=true"
|
||||
|
||||
38
refs/civitai.sql
Normal file
38
refs/civitai.sql
Normal file
@@ -0,0 +1,38 @@
|
||||
CREATE TABLE models (
|
||||
id INTEGER PRIMARY KEY,
|
||||
name TEXT NOT NULL,
|
||||
type TEXT NOT NULL,
|
||||
username TEXT,
|
||||
data TEXT NOT NULL,
|
||||
created_at INTEGER NOT NULL,
|
||||
updated_at INTEGER NOT NULL
|
||||
) STRICT;
|
||||
CREATE TABLE model_versions (
|
||||
id INTEGER PRIMARY KEY,
|
||||
model_id INTEGER NOT NULL,
|
||||
position INTEGER NOT NULL,
|
||||
name TEXT NOT NULL,
|
||||
base_model TEXT NOT NULL,
|
||||
published_at INTEGER,
|
||||
data TEXT NOT NULL,
|
||||
created_at INTEGER NOT NULL,
|
||||
updated_at INTEGER NOT NULL
|
||||
) STRICT;
|
||||
CREATE INDEX model_versions_model_id_idx ON model_versions (model_id);
|
||||
CREATE TABLE model_files (
|
||||
id INTEGER PRIMARY KEY,
|
||||
model_id INTEGER NOT NULL,
|
||||
version_id INTEGER NOT NULL,
|
||||
type TEXT NOT NULL,
|
||||
sha256 TEXT,
|
||||
data TEXT NOT NULL,
|
||||
created_at INTEGER NOT NULL,
|
||||
updated_at INTEGER NOT NULL
|
||||
) STRICT;
|
||||
CREATE INDEX model_files_model_id_idx ON model_files (model_id);
|
||||
CREATE INDEX model_files_version_id_idx ON model_files (version_id);
|
||||
CREATE TABLE archived_model_files (
|
||||
file_id INTEGER PRIMARY KEY,
|
||||
model_id INTEGER NOT NULL,
|
||||
version_id INTEGER NOT NULL
|
||||
) STRICT;
|
||||
265
refs/output.json
265
refs/output.json
@@ -1,11 +1,258 @@
|
||||
{
|
||||
"loras": "<lora:ck-neon-retrowave-IL-000012:0.8> <lora:aorunIllstrious:1> <lora:ck-shadow-circuit-IL-000012:0.78> <lora:MoriiMee_Gothic_Niji_Style_Illustrious_r1:0.45> <lora:ck-nc-cyberpunk-IL-000011:0.4>",
|
||||
"prompt": "in the style of ck-rw, aorun, scales, makeup, bare shoulders, pointy ears, dress, claws, in the style of cksc, artist:moriimee, in the style of cknc, masterpiece, best quality, good quality, very aesthetic, absurdres, newest, 8K, depth of field, focused subject, close up, stylized, in gold and neon shades, wabi sabi, 1girl, rainbow angel wings, looking at viewer, dynamic angle, from below, from side, relaxing",
|
||||
"negative_prompt": "bad quality, worst quality, worst detail, sketch ,signature, watermark, patreon logo, nsfw",
|
||||
"steps": "20",
|
||||
"sampler": "euler_ancestral",
|
||||
"cfg_scale": "8",
|
||||
"seed": "241",
|
||||
"size": "832x1216",
|
||||
"clip_skip": "2"
|
||||
"id": 649516,
|
||||
"name": "Cynthia -シロナ - Pokemon Diamond and Pearl - PDXL LORA",
|
||||
"description": "<p><strong>Warning: Without Adetailer eyes are fucked (rainbow color and artefact)</strong></p><p><span style=\"color:rgb(193, 194, 197)\">Trained on </span><a target=\"_blank\" rel=\"ugc\" href=\"https://civitai.com/models/257749/horsefucker-diffusion-v6-xl\"><strong>Pony Diffusion V6 XL</strong></a> with 63 pictures.<br />Best result with weight between : 0.8-1.</p><p><span style=\"color:rgb(193, 194, 197)\">Basic prompts : </span><code>1girl, cynthia \\(pokemon\\), blonde hair, hair over one eye, very long hair, grey eyes, eyelashes, hair ornament</code> <br /><span style=\"color:rgb(193, 194, 197)\">Outfit prompts : </span><code>fur collar, black coat, fur-trimmed coat, long sleeves, black pants, black shirt, high heels</code></p><p>Reviews are really appreciated, i love to see the community use my work, that's why I share it.<br />If you like my work, you can tip me <a target=\"_blank\" rel=\"ugc\" href=\"https://ko-fi.com/konan49773\"><strong>here.</strong></a></p><p>Got a specific request ? I'm open for commission on my <a target=\"_blank\" rel=\"ugc\" href=\"https://ko-fi.com/konan49773/commissions\"><strong>kofi</strong></a> or<strong> </strong><a target=\"_blank\" rel=\"ugc\" href=\"https://www.fiverr.com/konanai/create-lora-model-for-you\"><strong>fiverr gig</strong></a> *! If you provide enough data, OCs are accepted</p>",
|
||||
"allowNoCredit": true,
|
||||
"allowCommercialUse": [
|
||||
"Image",
|
||||
"RentCivit"
|
||||
],
|
||||
"allowDerivatives": true,
|
||||
"allowDifferentLicense": true,
|
||||
"type": "LORA",
|
||||
"minor": false,
|
||||
"sfwOnly": false,
|
||||
"poi": false,
|
||||
"nsfw": false,
|
||||
"nsfwLevel": 29,
|
||||
"availability": "Public",
|
||||
"cosmetic": null,
|
||||
"supportsGeneration": true,
|
||||
"stats": {
|
||||
"downloadCount": 811,
|
||||
"favoriteCount": 0,
|
||||
"thumbsUpCount": 175,
|
||||
"thumbsDownCount": 0,
|
||||
"commentCount": 4,
|
||||
"ratingCount": 0,
|
||||
"rating": 0,
|
||||
"tippedAmountCount": 10
|
||||
},
|
||||
"creator": {
|
||||
"username": "Konan",
|
||||
"image": "https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/7cd552a1-60fe-4baf-a0e4-f7d5d5381711/width=96/Konan.jpeg"
|
||||
},
|
||||
"tags": [
|
||||
"anime",
|
||||
"character",
|
||||
"cynthia",
|
||||
"woman",
|
||||
"pokemon",
|
||||
"pokegirl"
|
||||
],
|
||||
"modelVersions": [
|
||||
{
|
||||
"id": 726676,
|
||||
"index": 0,
|
||||
"name": "v1.0",
|
||||
"baseModel": "Pony",
|
||||
"createdAt": "2024-08-16T01:13:16.099Z",
|
||||
"publishedAt": "2024-08-16T01:14:44.984Z",
|
||||
"status": "Published",
|
||||
"availability": "Public",
|
||||
"nsfwLevel": 29,
|
||||
"trainedWords": [
|
||||
"1girl, cynthia \\(pokemon\\), blonde hair, hair over one eye, very long hair, grey eyes, eyelashes, hair ornament",
|
||||
"fur collar, black coat, fur-trimmed coat, long sleeves, black pants, black shirt, high heels"
|
||||
],
|
||||
"covered": true,
|
||||
"stats": {
|
||||
"downloadCount": 811,
|
||||
"ratingCount": 0,
|
||||
"rating": 0,
|
||||
"thumbsUpCount": 175,
|
||||
"thumbsDownCount": 0
|
||||
},
|
||||
"files": [
|
||||
{
|
||||
"id": 641092,
|
||||
"sizeKB": 56079.65234375,
|
||||
"name": "CynthiaXL.safetensors",
|
||||
"type": "Model",
|
||||
"pickleScanResult": "Success",
|
||||
"pickleScanMessage": "No Pickle imports",
|
||||
"virusScanResult": "Success",
|
||||
"virusScanMessage": null,
|
||||
"scannedAt": "2024-08-16T01:17:19.087Z",
|
||||
"metadata": {
|
||||
"format": "SafeTensor"
|
||||
},
|
||||
"hashes": {},
|
||||
"downloadUrl": "https://civitai.com/api/download/models/726676",
|
||||
"primary": true
|
||||
}
|
||||
],
|
||||
"images": [
|
||||
{
|
||||
"url": "https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/b346d757-2b59-4aeb-9f09-3bee2724519d/width=1248/24511993.jpeg",
|
||||
"nsfwLevel": 1,
|
||||
"width": 1248,
|
||||
"height": 1824,
|
||||
"hash": "UqNc==RP.9s+~pxvIst7kWWBWBjY%MWBt7WB",
|
||||
"type": "image",
|
||||
"minor": false,
|
||||
"poi": false,
|
||||
"hasMeta": true,
|
||||
"hasPositivePrompt": true,
|
||||
"onSite": false,
|
||||
"remixOfId": null
|
||||
},
|
||||
{
|
||||
"url": "https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/fc132ac0-cc1c-4b68-a1d7-5b97b0996ac2/width=1248/24511997.jpeg",
|
||||
"nsfwLevel": 1,
|
||||
"width": 1248,
|
||||
"height": 1824,
|
||||
"hash": "UMGSS+?tTw.60MIX9cbb~WxHRRR-NEtLRiR%",
|
||||
"type": "image",
|
||||
"minor": false,
|
||||
"poi": false,
|
||||
"hasMeta": true,
|
||||
"hasPositivePrompt": true,
|
||||
"onSite": false,
|
||||
"remixOfId": null
|
||||
},
|
||||
{
|
||||
"url": "https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/7b3237d1-e672-466a-85d0-cc5dd42ab130/width=1160/24512001.jpeg",
|
||||
"nsfwLevel": 4,
|
||||
"width": 1160,
|
||||
"height": 1696,
|
||||
"hash": "U9NA6f~o00%h00wvIYt74:ER-=D%5600DiE1",
|
||||
"type": "image",
|
||||
"minor": false,
|
||||
"poi": false,
|
||||
"hasMeta": true,
|
||||
"hasPositivePrompt": true,
|
||||
"onSite": false,
|
||||
"remixOfId": null
|
||||
},
|
||||
{
|
||||
"url": "https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/ccd7d11d-4fa9-4434-85a1-fb999312e60d/width=1248/24511991.jpeg",
|
||||
"nsfwLevel": 1,
|
||||
"width": 1248,
|
||||
"height": 1824,
|
||||
"hash": "UyNTg.j?~qxu?aoLRkj]%MfkM{jZaya}a#ax",
|
||||
"type": "image",
|
||||
"minor": false,
|
||||
"poi": false,
|
||||
"hasMeta": true,
|
||||
"hasPositivePrompt": true,
|
||||
"onSite": false,
|
||||
"remixOfId": null
|
||||
},
|
||||
{
|
||||
"url": "https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/1743be6d-7fe5-4b55-9f19-c931618fa259/width=1248/24511996.jpeg",
|
||||
"nsfwLevel": 4,
|
||||
"width": 1248,
|
||||
"height": 1824,
|
||||
"hash": "UGOC~n^+?w~6Tx_4oM^$yYEkMds74:9F#*xY",
|
||||
"type": "image",
|
||||
"minor": false,
|
||||
"poi": false,
|
||||
"hasMeta": true,
|
||||
"hasPositivePrompt": true,
|
||||
"onSite": false,
|
||||
"remixOfId": null
|
||||
},
|
||||
{
|
||||
"url": "https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/91693c98-d037-4489-882c-100eb26019a0/width=1160/24512010.jpeg",
|
||||
"nsfwLevel": 4,
|
||||
"width": 1160,
|
||||
"height": 1696,
|
||||
"hash": "UJI}kp^-Kl%hXAIX4;Nf^+M|9GRP0Mt8%L%2",
|
||||
"type": "image",
|
||||
"minor": false,
|
||||
"poi": false,
|
||||
"hasMeta": true,
|
||||
"hasPositivePrompt": true,
|
||||
"onSite": false,
|
||||
"remixOfId": null
|
||||
},
|
||||
{
|
||||
"url": "https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/49c7a294-ac5b-4832-98e5-2acd0f1a8782/width=1248/24512017.jpeg",
|
||||
"nsfwLevel": 4,
|
||||
"width": 1248,
|
||||
"height": 1824,
|
||||
"hash": "UML;8Qn|9G%3mnWA4nWFMf%N?Hae~qog-oNF",
|
||||
"type": "image",
|
||||
"minor": false,
|
||||
"poi": false,
|
||||
"hasMeta": true,
|
||||
"hasPositivePrompt": true,
|
||||
"onSite": false,
|
||||
"remixOfId": null
|
||||
},
|
||||
{
|
||||
"url": "https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/d7b442f2-6ead-4a7a-9578-54d9ec2ff148/width=1248/24512015.jpeg",
|
||||
"nsfwLevel": 1,
|
||||
"width": 1248,
|
||||
"height": 1824,
|
||||
"hash": "UPGR#kt8xw%M0LWC9bWC?wxtR*NLM^jrxWM|",
|
||||
"type": "image",
|
||||
"minor": false,
|
||||
"poi": false,
|
||||
"hasMeta": true,
|
||||
"hasPositivePrompt": true,
|
||||
"onSite": false,
|
||||
"remixOfId": null
|
||||
},
|
||||
{
|
||||
"url": "https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/d840f1e9-3dd3-4531-b83a-1ba2c6b7feaa/width=1160/24512004.jpeg",
|
||||
"nsfwLevel": 8,
|
||||
"width": 1160,
|
||||
"height": 1696,
|
||||
"hash": "ULNm1i_39wi^*I%hDiM_tlo#xuV?^kNIxCs,",
|
||||
"type": "image",
|
||||
"minor": false,
|
||||
"poi": false,
|
||||
"hasMeta": true,
|
||||
"hasPositivePrompt": true,
|
||||
"onSite": false,
|
||||
"remixOfId": null
|
||||
},
|
||||
{
|
||||
"url": "https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/520387ae-c176-43e3-92bd-5cd2a672475e/width=1248/24512012.jpeg",
|
||||
"nsfwLevel": 4,
|
||||
"width": 1248,
|
||||
"height": 1824,
|
||||
"hash": "URM%l.%M.9Ip~poIkExu_3V@M|xuD%oJM{D*",
|
||||
"type": "image",
|
||||
"minor": false,
|
||||
"poi": false,
|
||||
"hasMeta": true,
|
||||
"hasPositivePrompt": true,
|
||||
"onSite": false,
|
||||
"remixOfId": null
|
||||
},
|
||||
{
|
||||
"url": "https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/9ea28b94-f326-4776-83ff-851cc203c627/width=1248/24511988.jpeg",
|
||||
"nsfwLevel": 1,
|
||||
"width": 1248,
|
||||
"height": 1824,
|
||||
"hash": "U-PZloog_Nxut6j]WXWB-;j?IVa#ofaxj]j]",
|
||||
"type": "image",
|
||||
"minor": false,
|
||||
"poi": false,
|
||||
"hasMeta": true,
|
||||
"hasPositivePrompt": true,
|
||||
"onSite": false,
|
||||
"remixOfId": null
|
||||
},
|
||||
{
|
||||
"url": "https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/2e749dbb-7d5a-48f1-8e29-fea5022a5fe9/width=1248/24522268.jpeg",
|
||||
"nsfwLevel": 16,
|
||||
"width": 1248,
|
||||
"height": 1824,
|
||||
"hash": "UPLgtm9Z0z=|0yRRE2-A9rWAoNE1~DwOr=t7",
|
||||
"type": "image",
|
||||
"minor": false,
|
||||
"poi": false,
|
||||
"hasMeta": true,
|
||||
"hasPositivePrompt": true,
|
||||
"onSite": false,
|
||||
"remixOfId": null
|
||||
}
|
||||
],
|
||||
"downloadUrl": "https://civitai.com/api/download/models/726676"
|
||||
}
|
||||
]
|
||||
}
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user